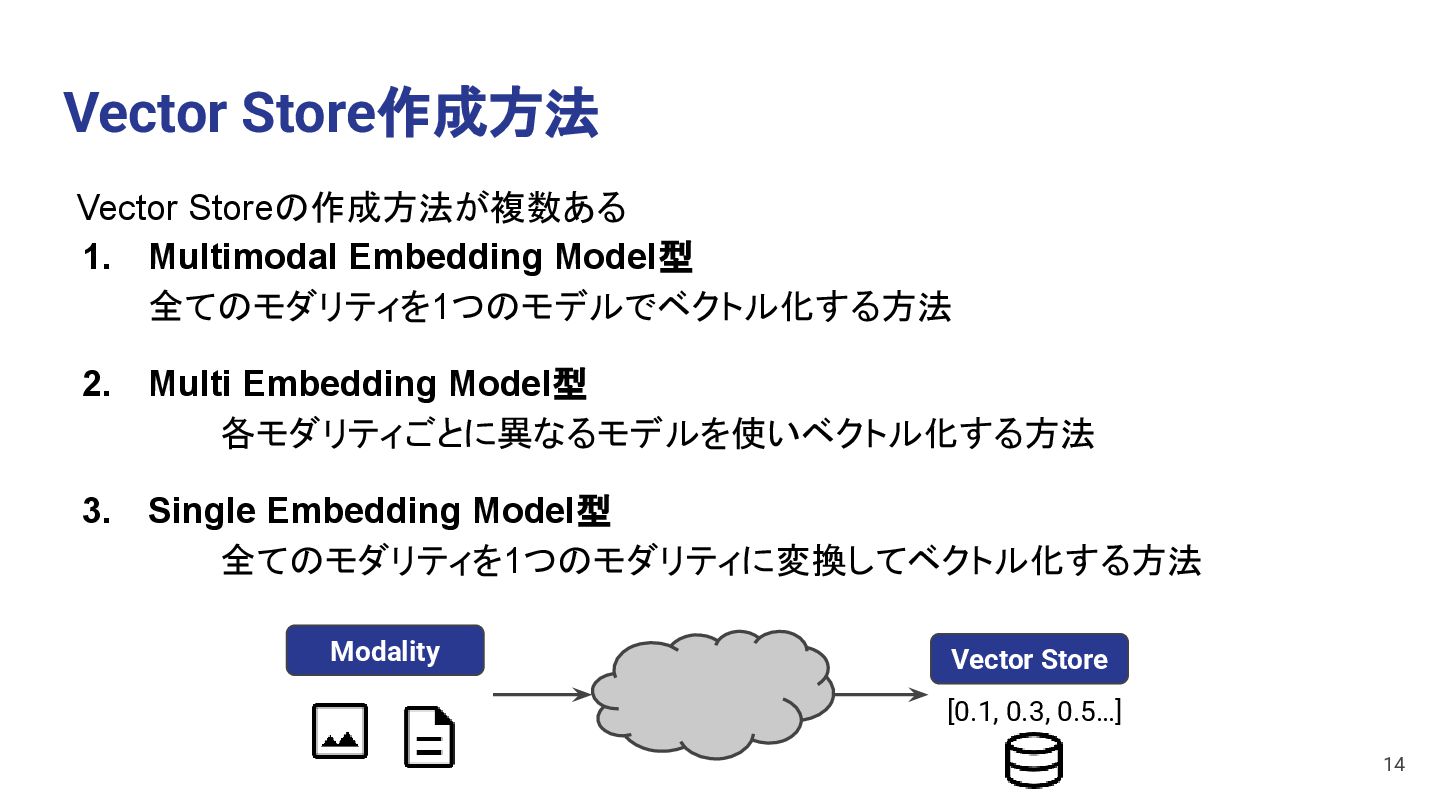
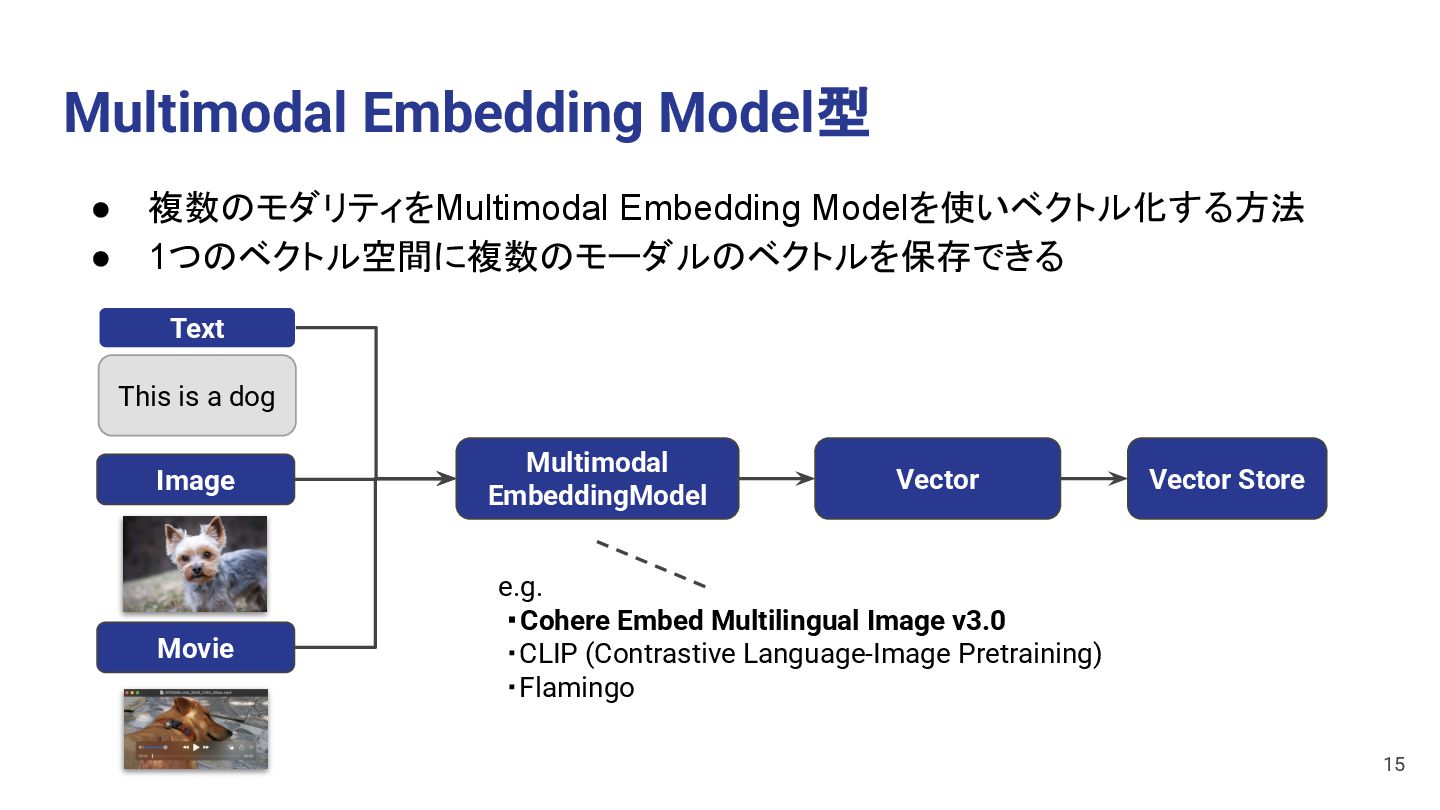
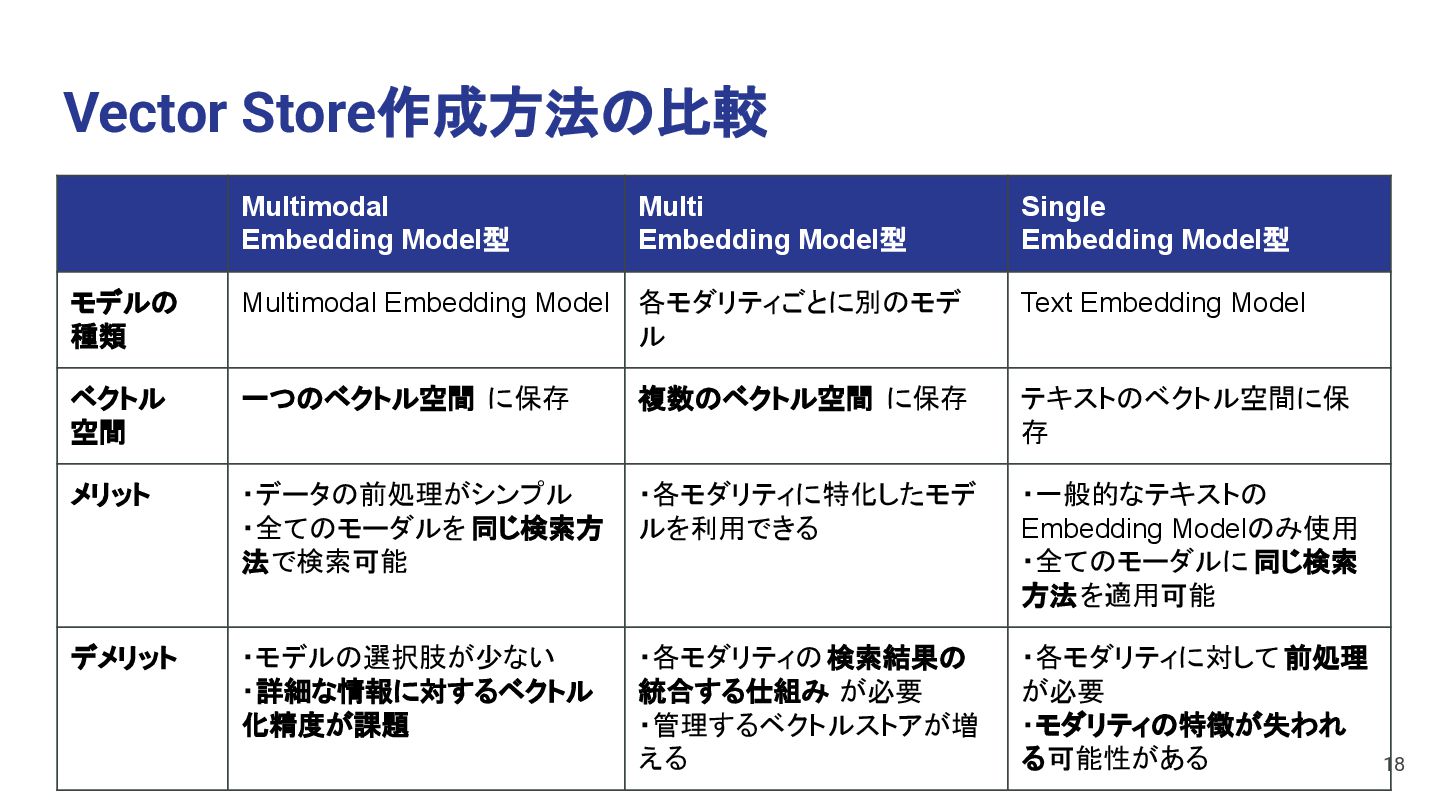
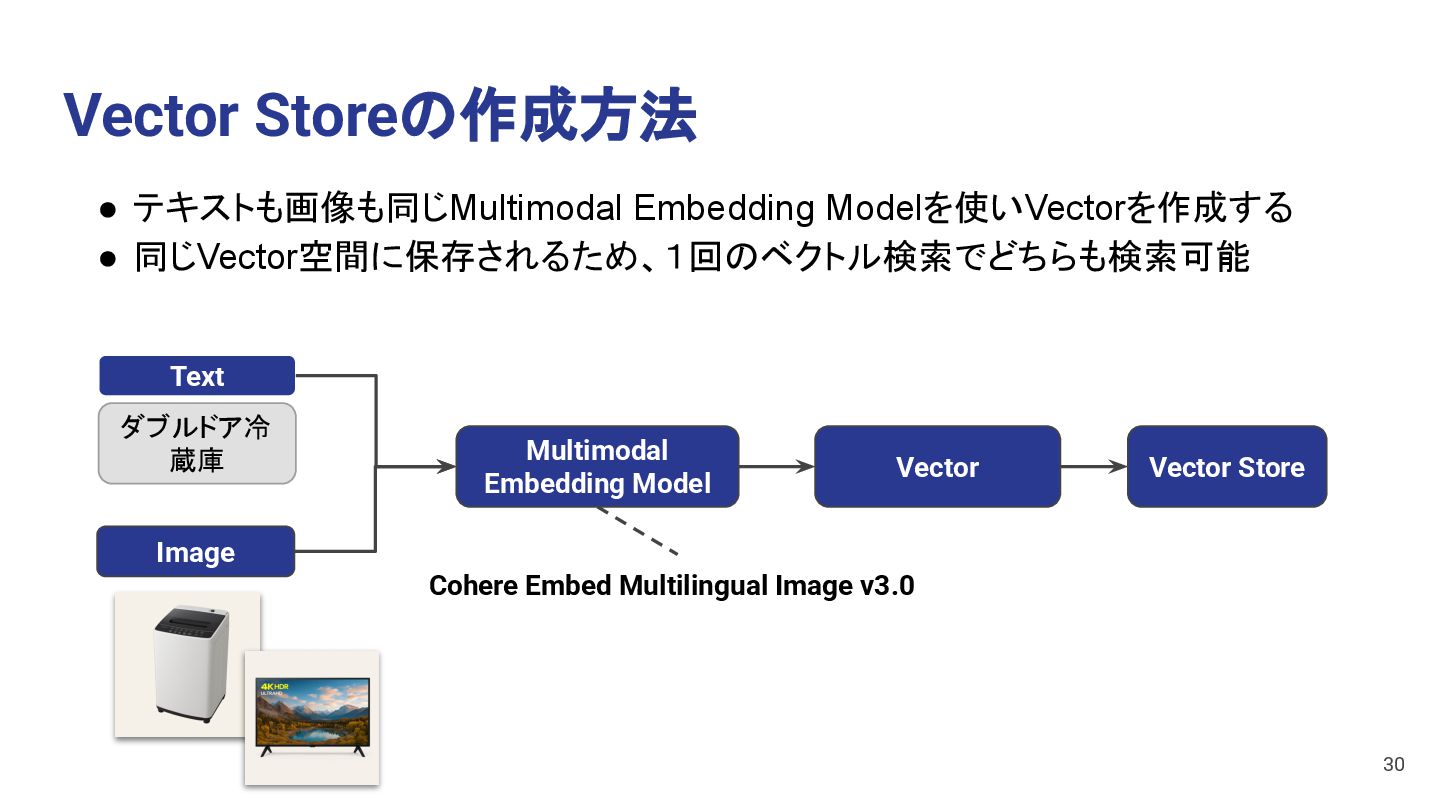
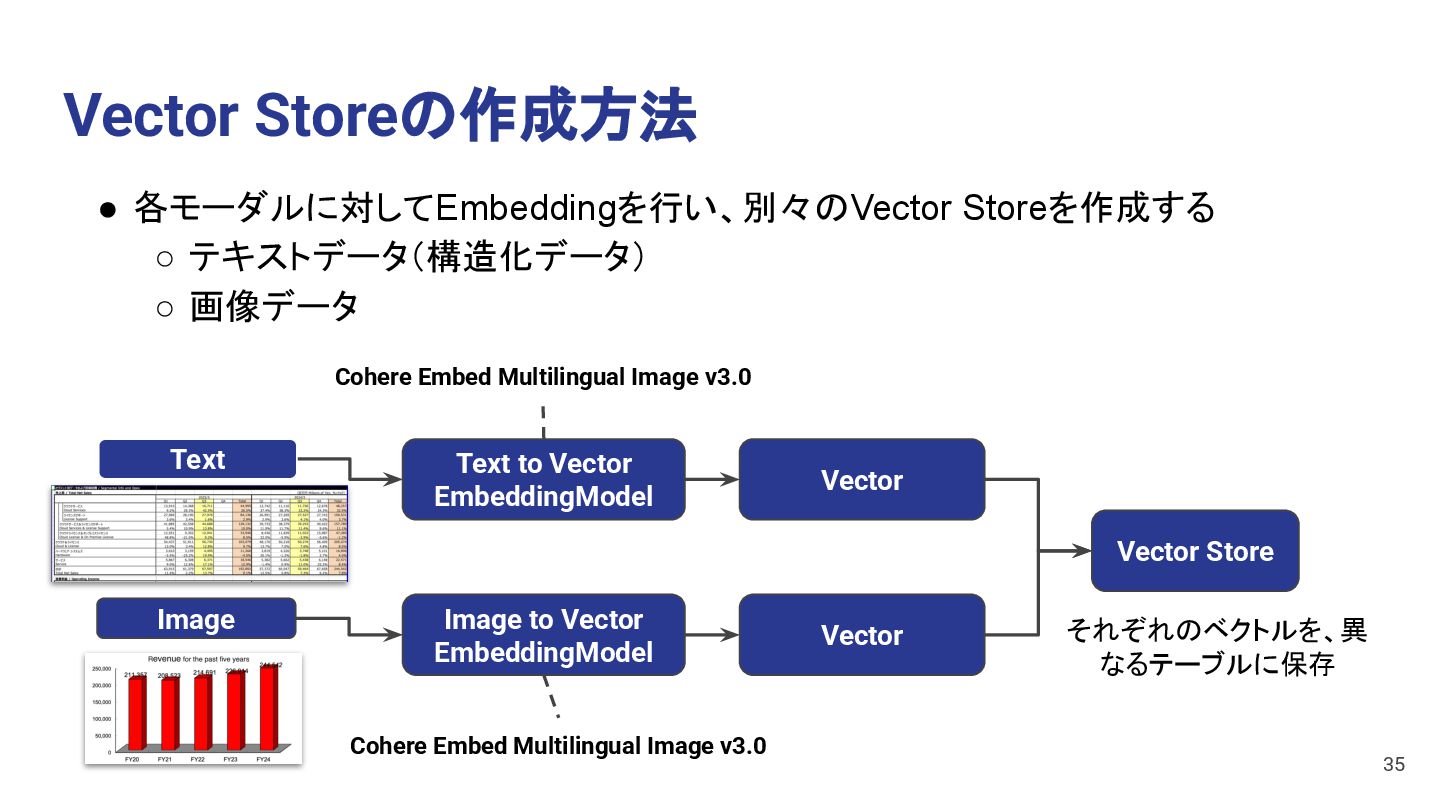
a dog Movie Vector Store • 複数のモダリティをMultimodal Embedding Modelを使いベクトル化する方法 • 1つのベクトル空間に複数のモーダルのベクトルを保存できる 15 e.g. ・Cohere Embed Multilingual Image v3.0 ・CLIP (Contrastive Language-Image Pretraining) ・Flamingo
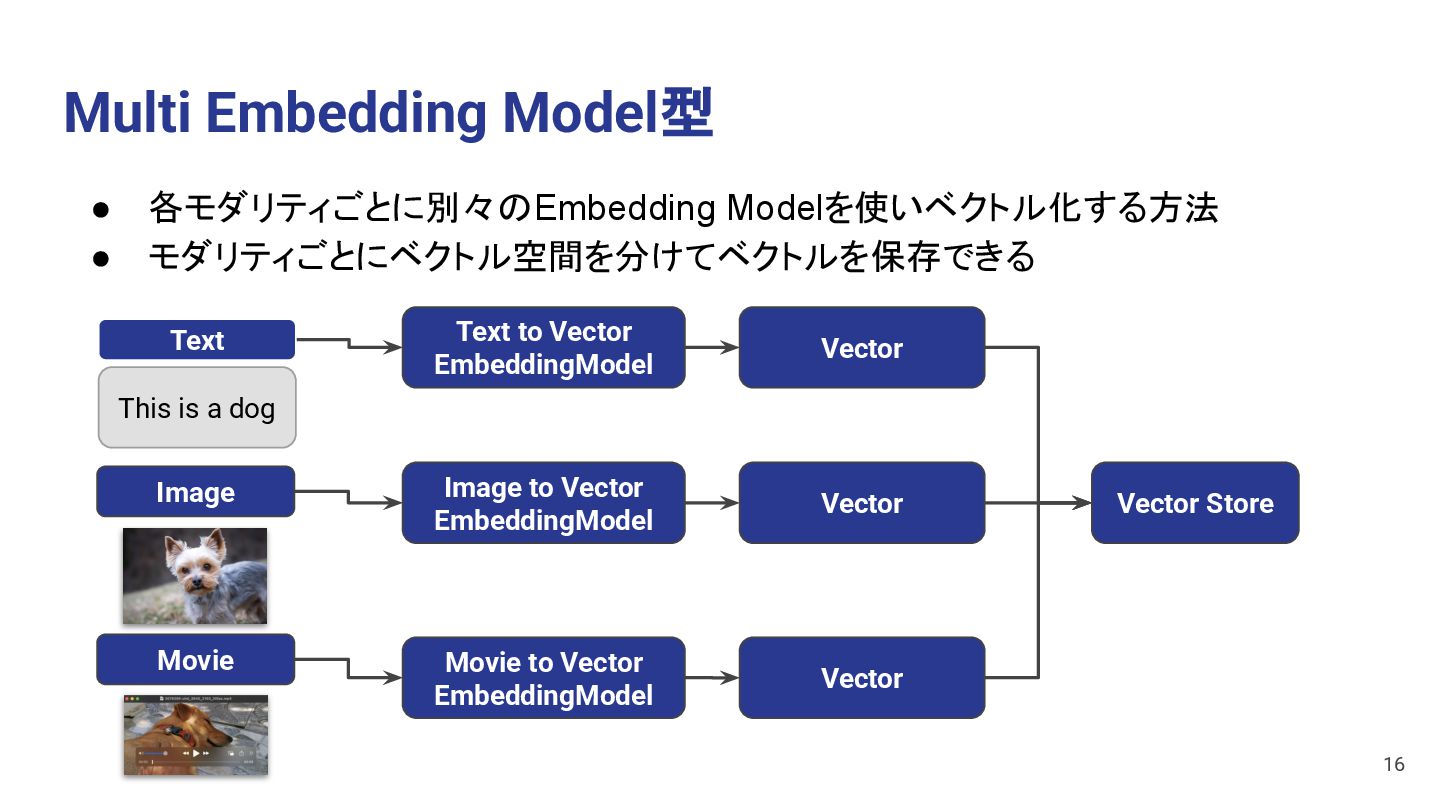
Image to Vector EmbeddingModel Movie to Vector EmbeddingModel Vector Vector Text Image This is a dog Movie • 各モダリティごとに別々のEmbedding Modelを使いベクトル化する方法 • モダリティごとにベクトル空間を分けてベクトルを保存できる 16
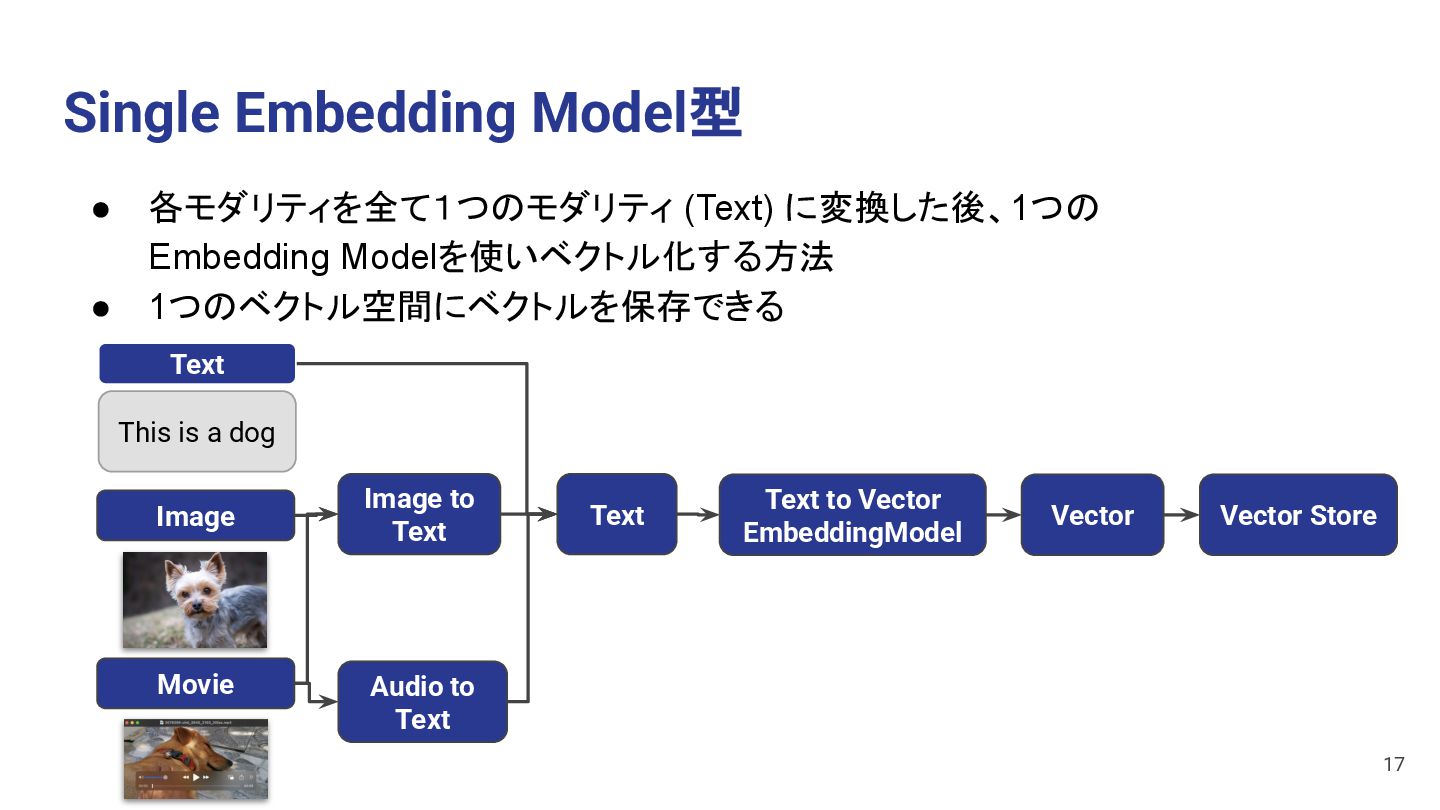
Image to Text Audio to Text Text Text Image This is a dog Movie • 各モダリティを全て1つのモダリティ (Text) に変換した後、1つの Embedding Modelを使いベクトル化する方法 • 1つのベクトル空間にベクトルを保存できる 17
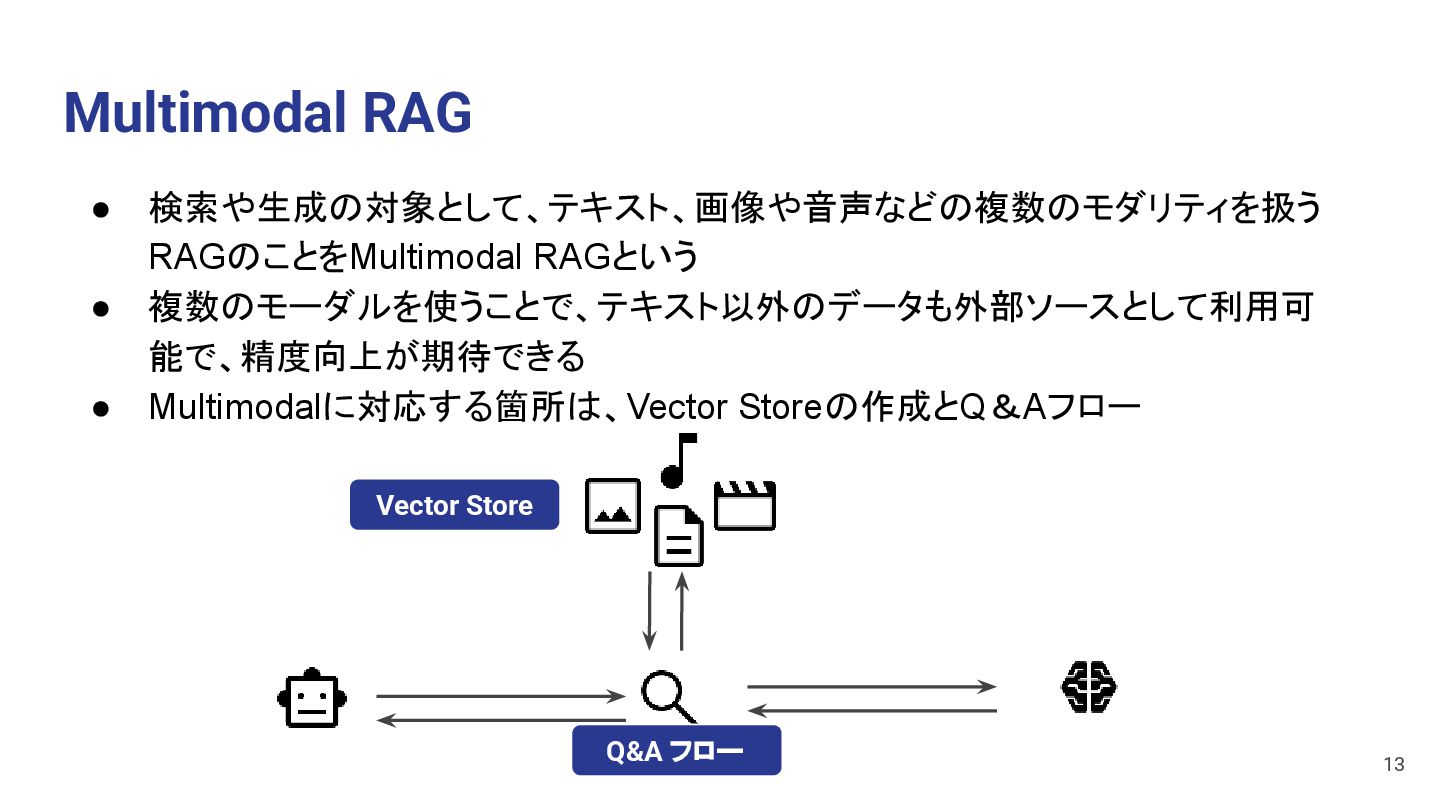
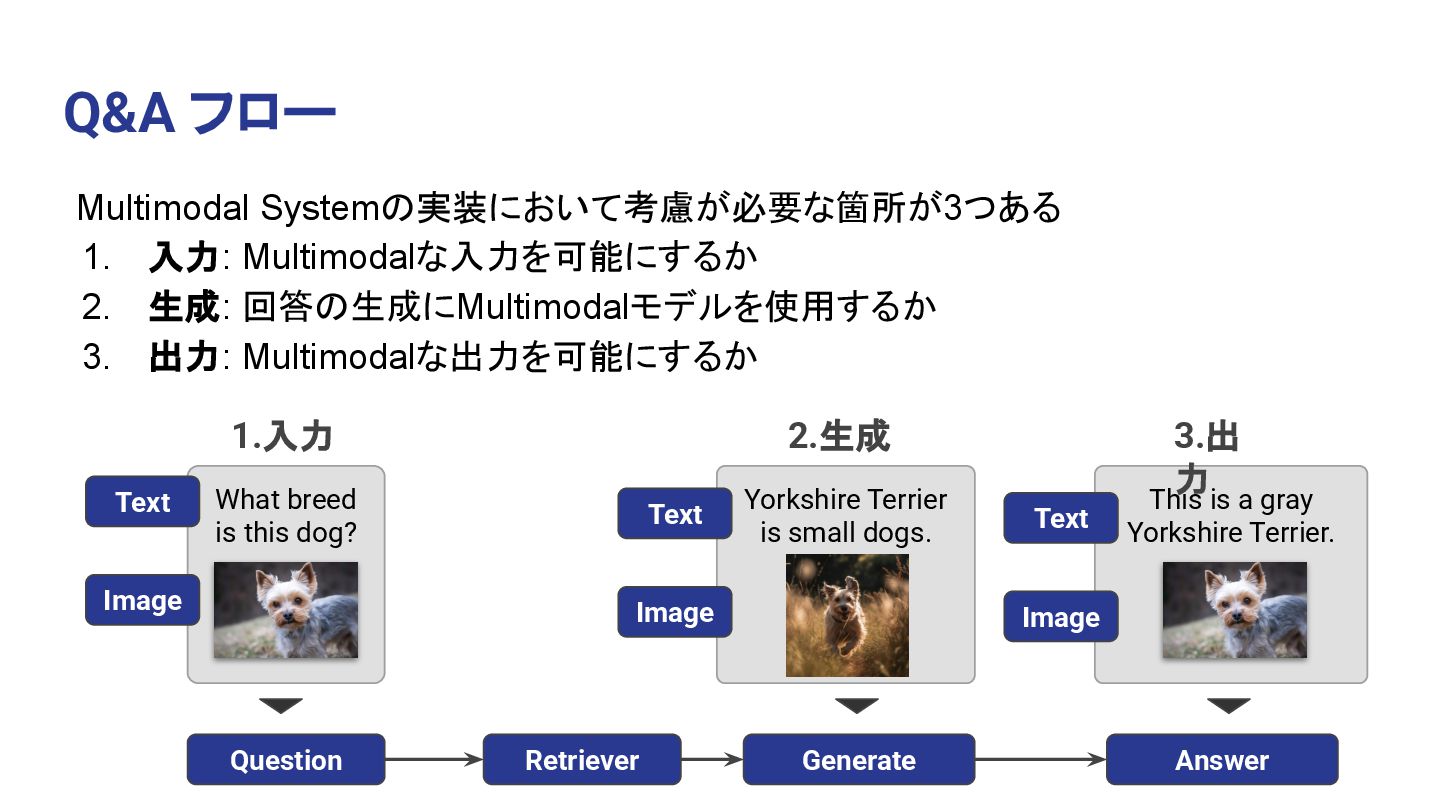
回答の生成にMultimodalモデルを使用するか 3. 出力: Multimodalな出力を可能にするか Retriever Generate Answer What breed is this dog? This is a gray Yorkshire Terrier. Yorkshire Terrier is small dogs. 1.入力 3.出 力 2.生成 Image Text Image Text Image Text
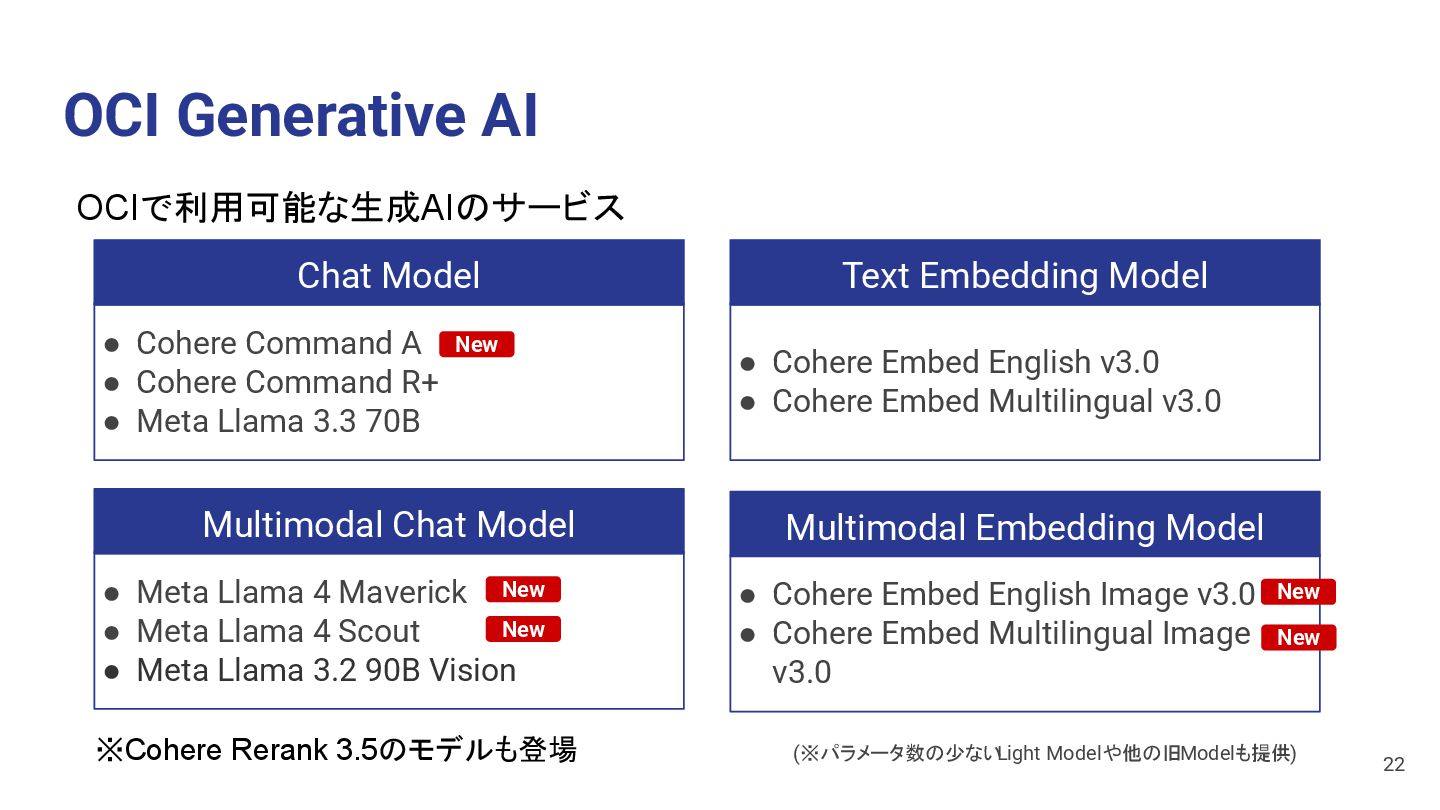
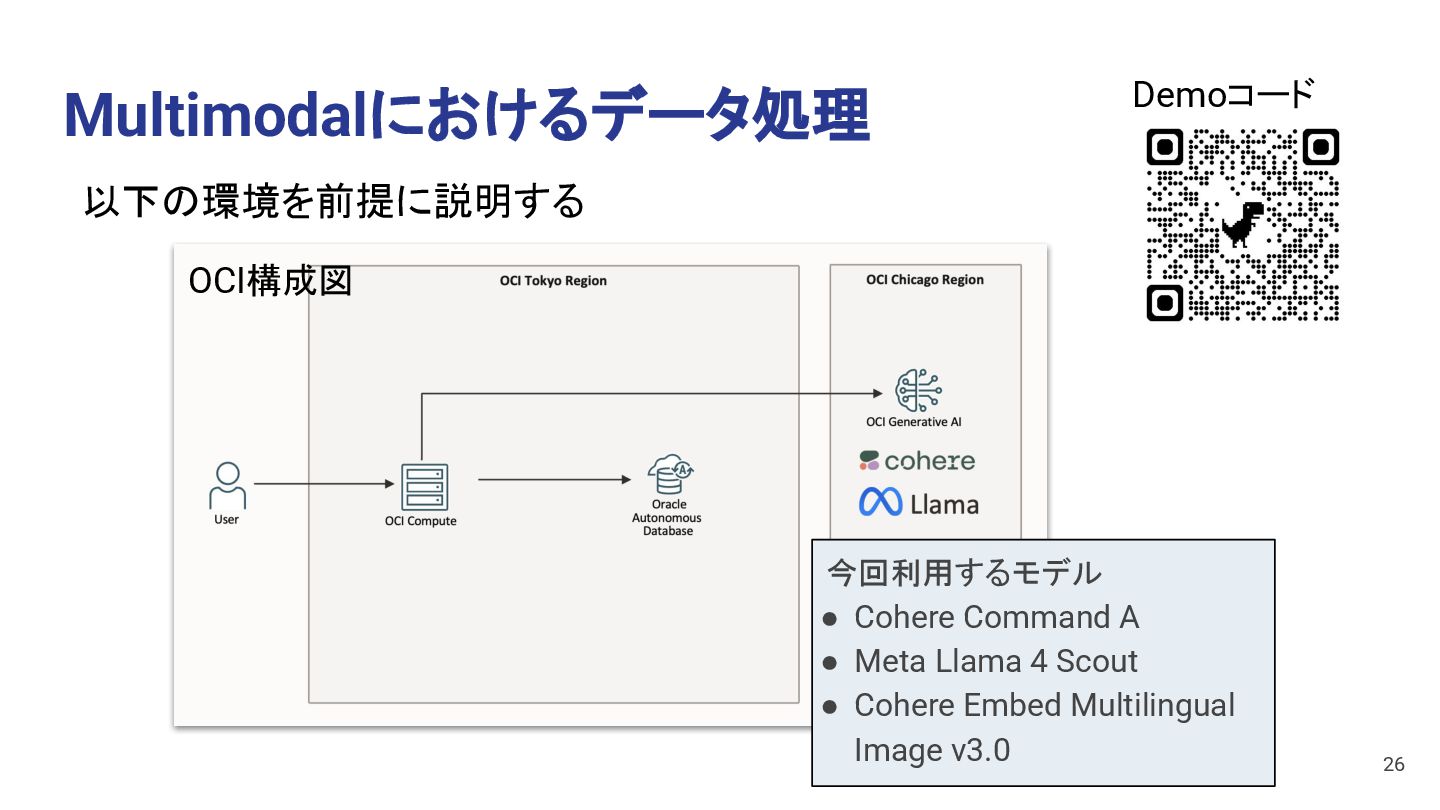
Command R+ • Meta Llama 3.3 70B Chat Model • Cohere Embed English v3.0 • Cohere Embed Multilingual v3.0 Text Embedding Model • Cohere Embed English Image v3.0 • Cohere Embed Multilingual Image v3.0 Multimodal Embedding Model (※パラメータ数の少ない Light Modelや他の旧Modelも提供) • Meta Llama 4 Maverick • Meta Llama 4 Scout • Meta Llama 3.2 90B Vision Multimodal Chat Model New New New New New 22 ※Cohere Rerank 3.5のモデルも登場
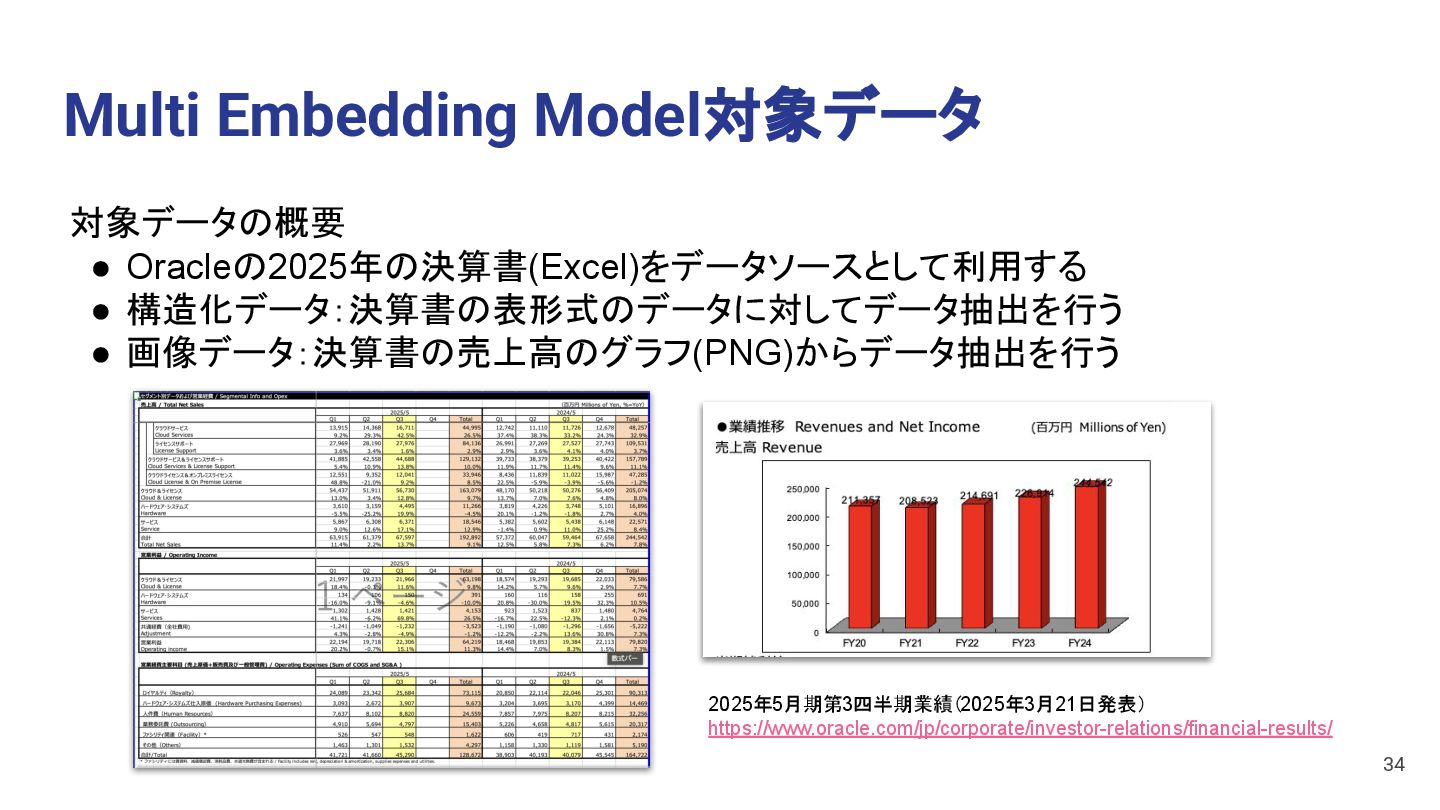
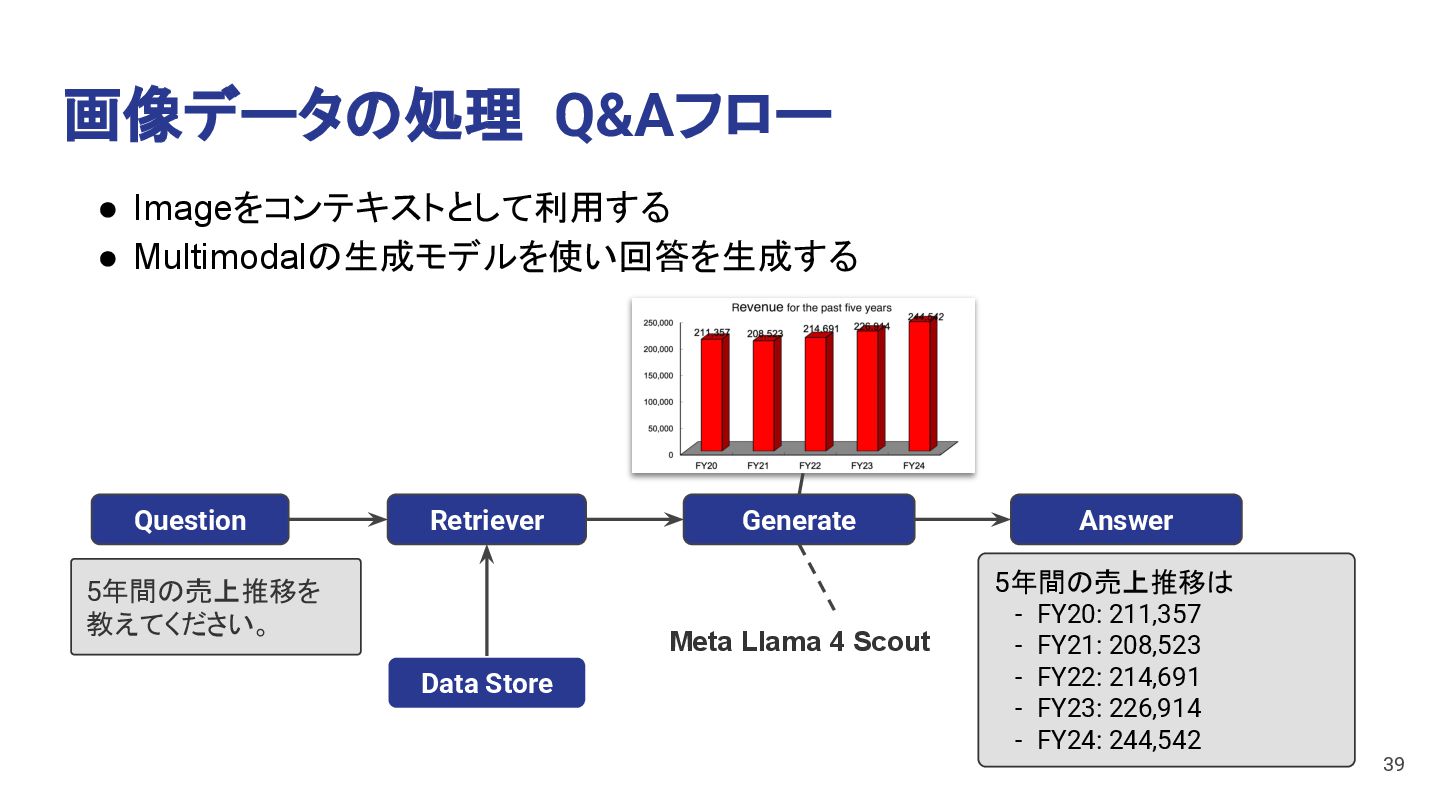
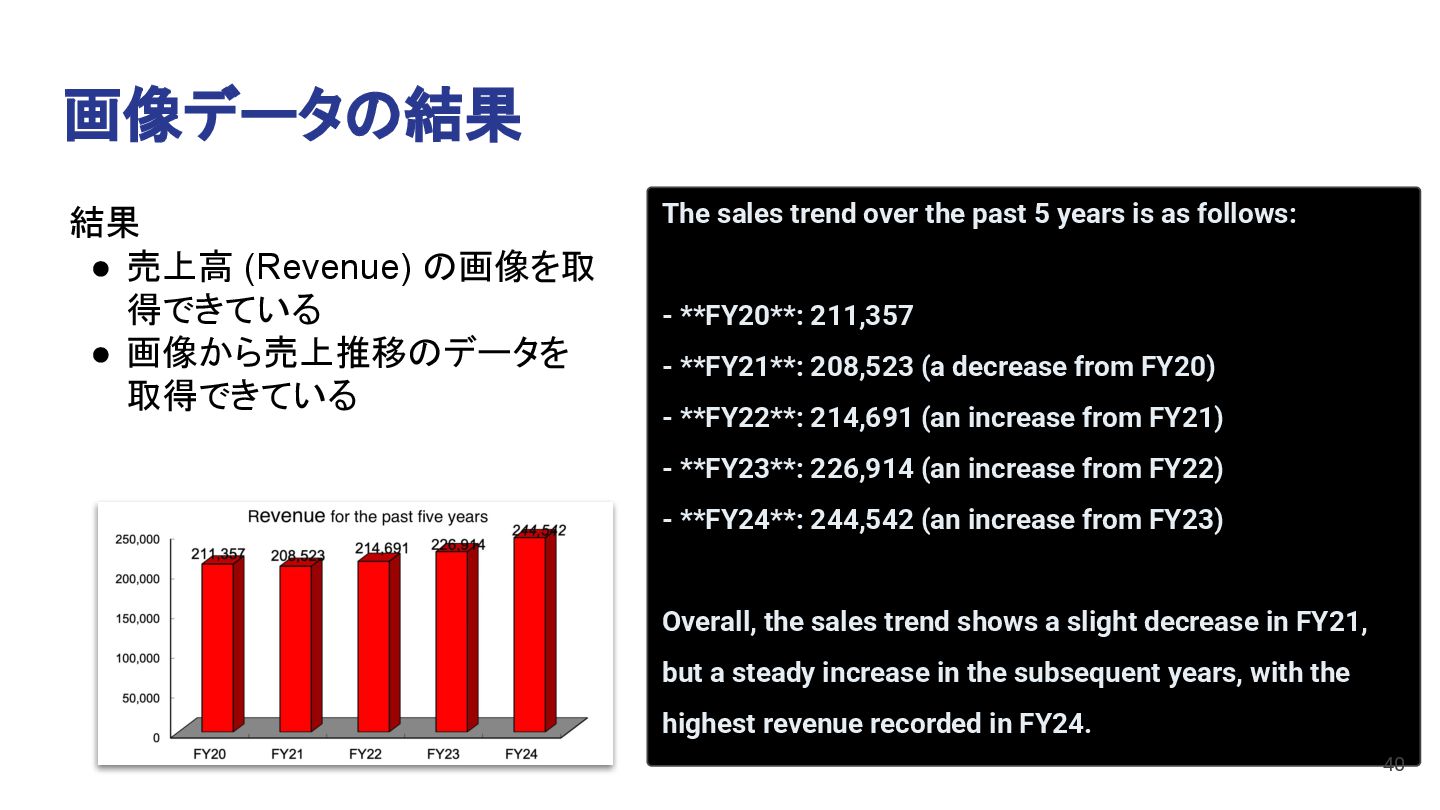
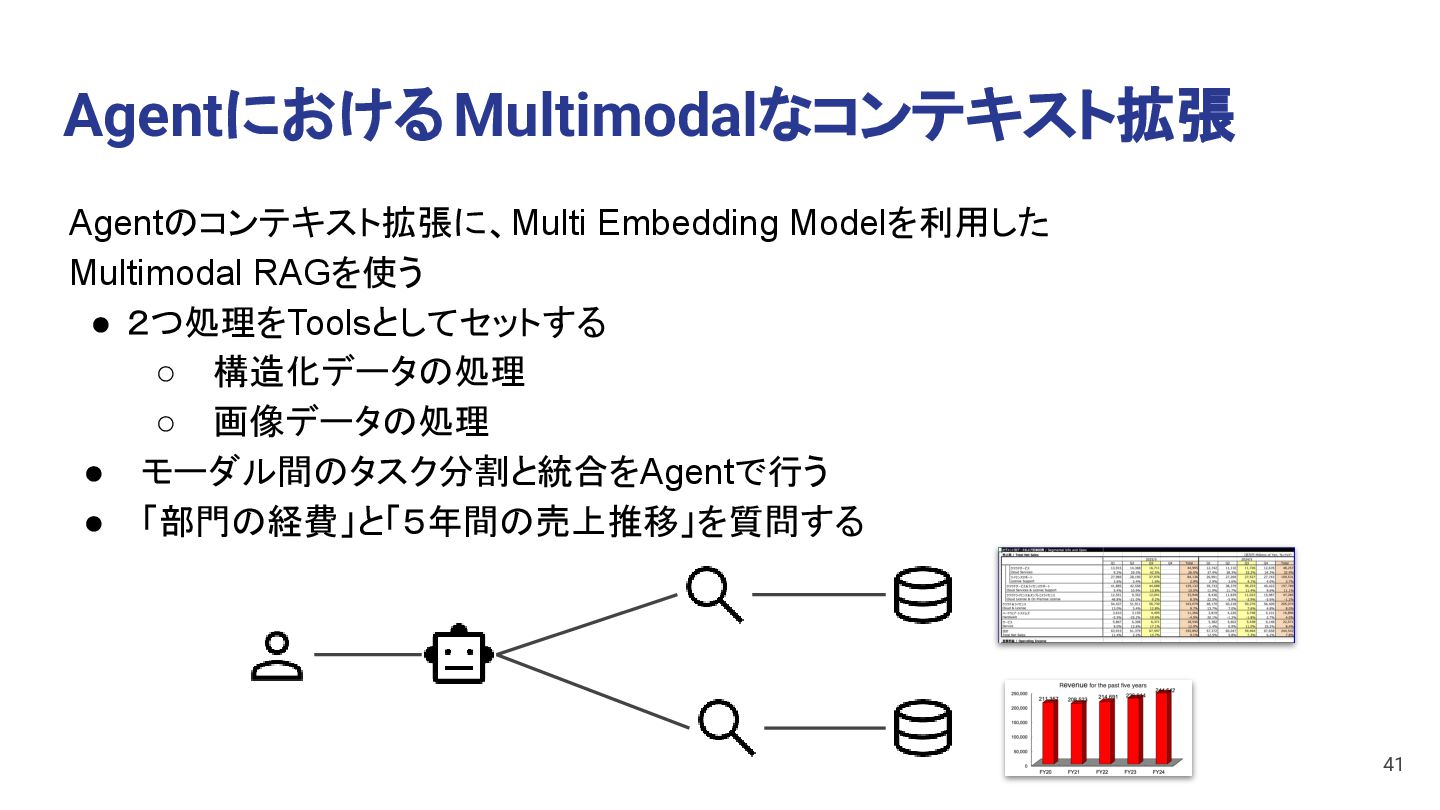
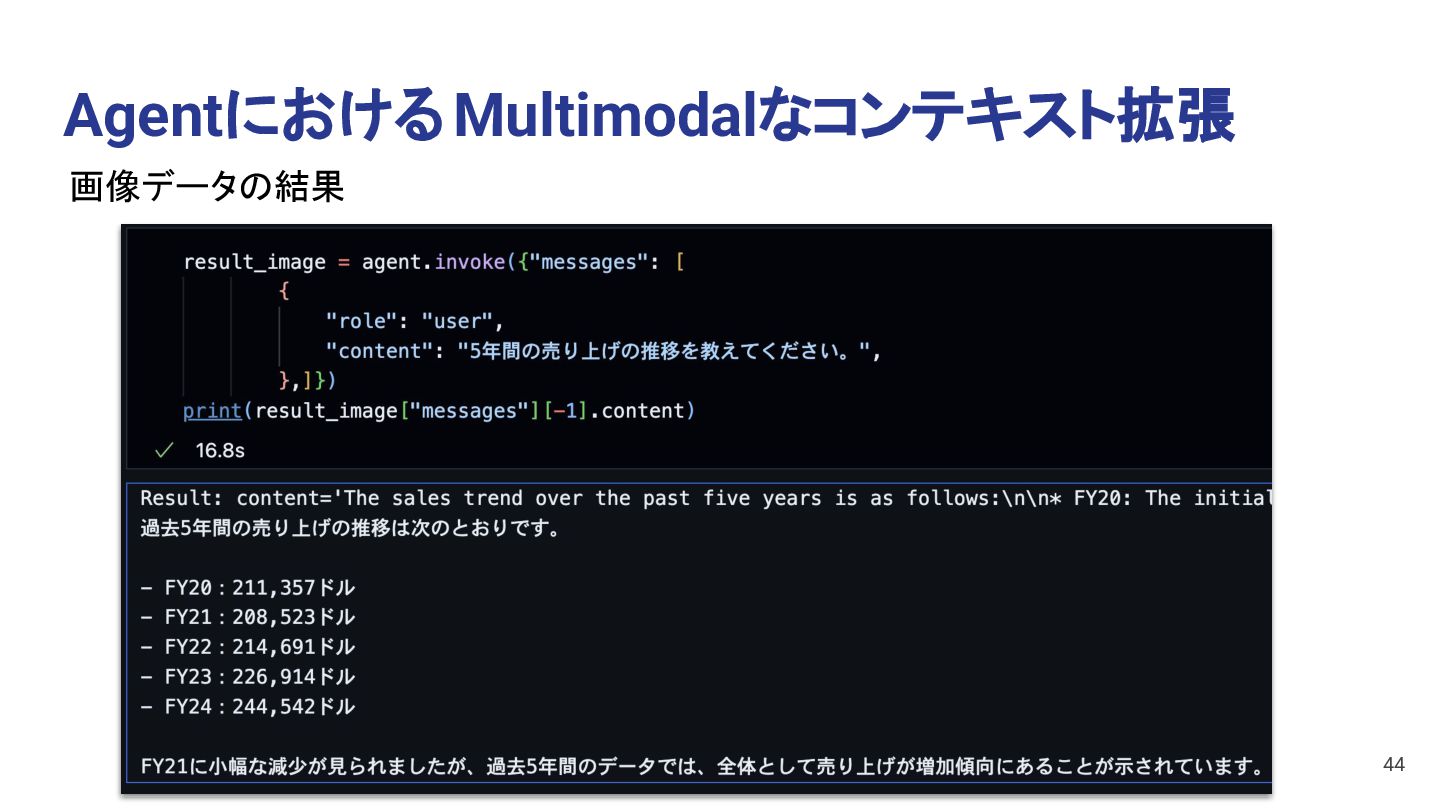
The sales trend over the past 5 years is as follows: - **FY20**: 211,357 - **FY21**: 208,523 (a decrease from FY20) - **FY22**: 214,691 (an increase from FY21) - **FY23**: 226,914 (an increase from FY22) - **FY24**: 244,542 (an increase from FY23) Overall, the sales trend shows a slight decrease in FY21, but a steady increase in the subsequent years, with the highest revenue recorded in FY24. 40
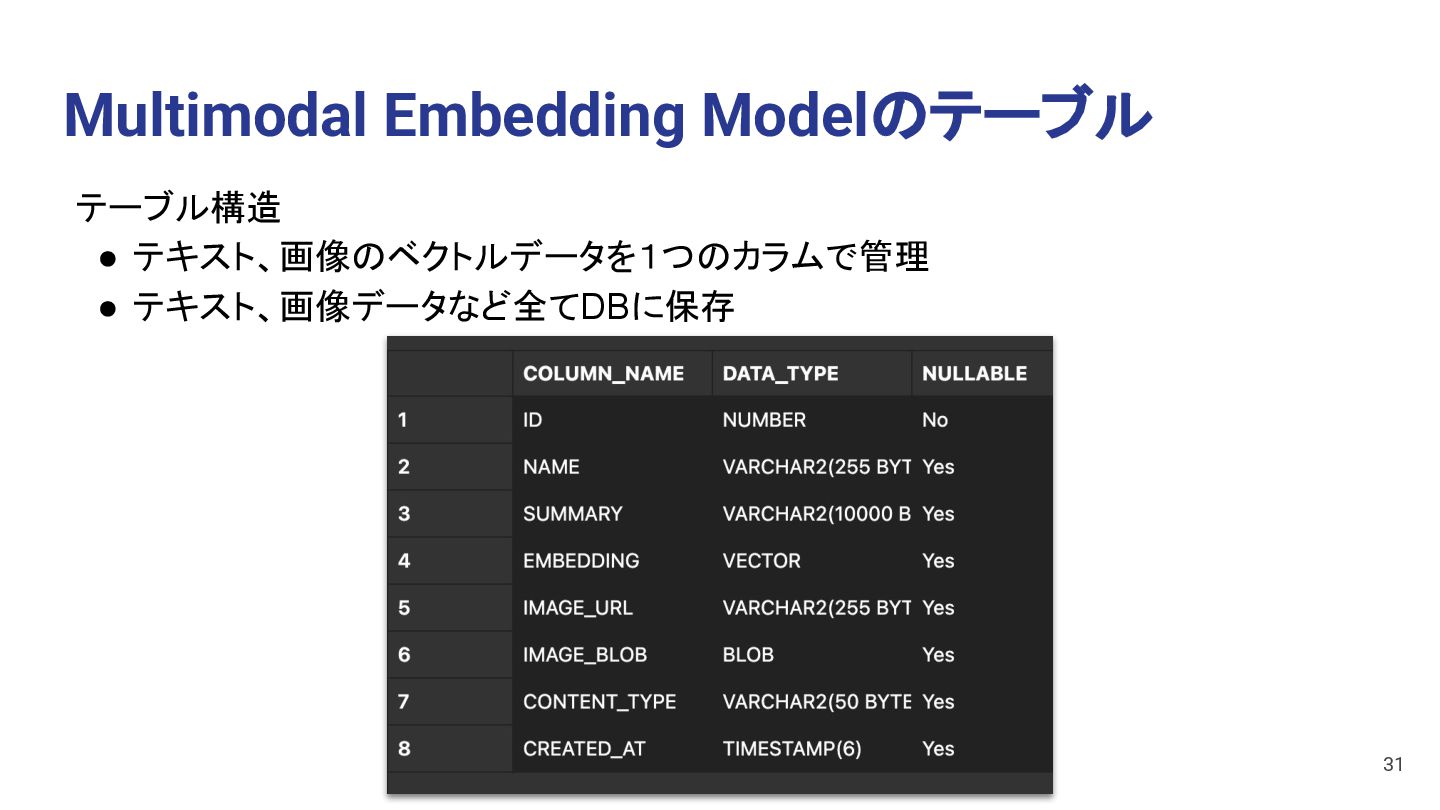
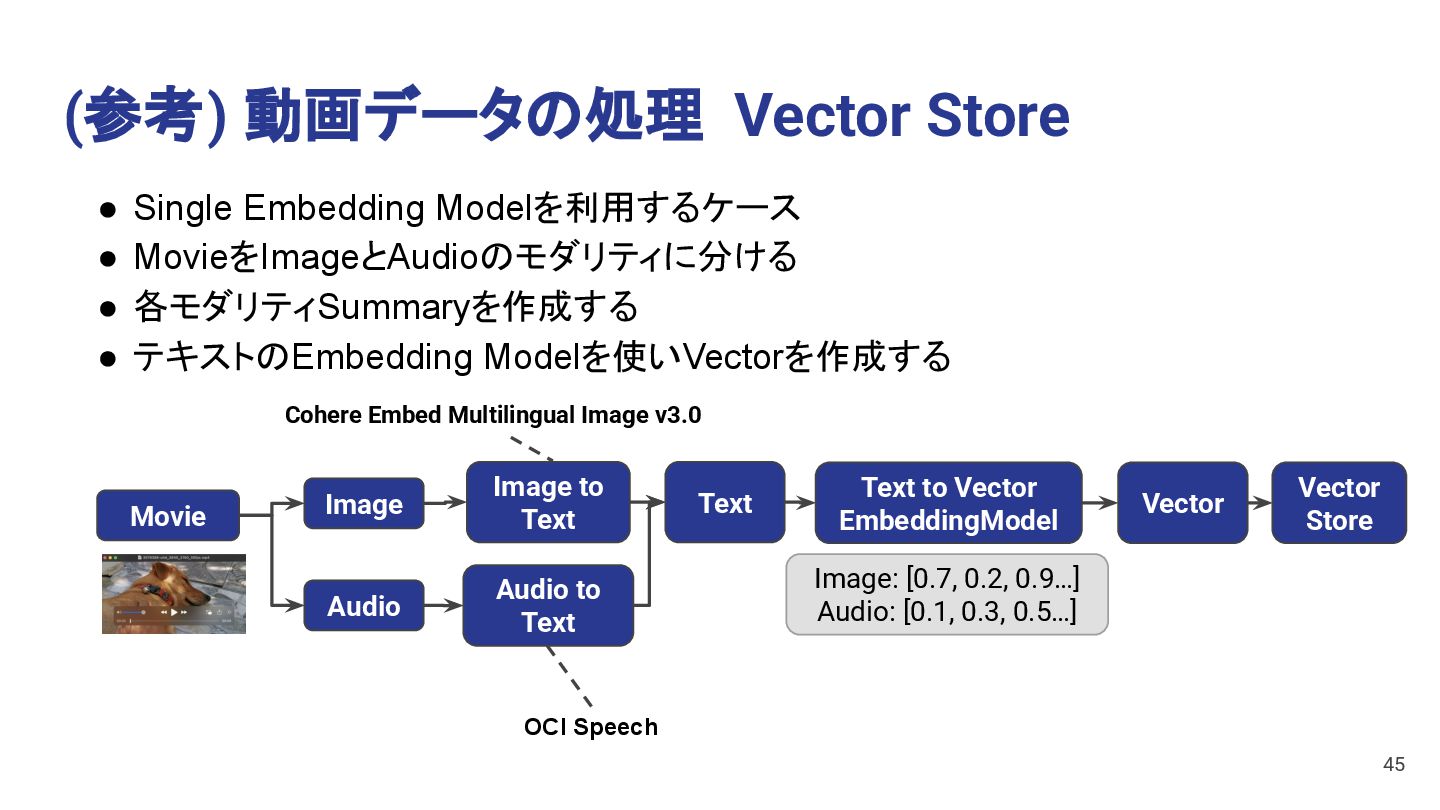
to Text Text • Single Embedding Modelを利用するケース • MovieをImageとAudioのモダリティに分ける • 各モダリティSummaryを作成する • テキストのEmbedding Modelを使いVectorを作成する Image: [0.7, 0.2, 0.9…] Audio: [0.1, 0.3, 0.5…] Vector Store Audio to Text Movie Image Audio OCI Speech 45 Cohere Embed Multilingual Image v3.0
• マルチモーダル画像検索アプリを作ってみた! ◦ https://qiita.com/yuji-arakawa/items/70470b348c90adb82b7f • Announcing Cohere Command A and Rerank models on OCI Generative AI ◦ https://blogs.oracle.com/ai-and-datascience/post/cohere-command-a-rerank-oci-gen-ai • Announcing Meta Llama 4 model support on OCI Generative AI ◦ https://blogs.oracle.com/ai-and-datascience/post/announcing-meta-llama-4-support-oci-generative-ai • マルチモーダル / AI Agent / LLMOps 3つの技術トレンドで理解するLLMの今後の展望 ◦ https://speakerdeck.com/hirosatogamo/llmops-3tunoji-shu-torendodeli-jie-surullmnojin-hou-nozhan-wang • Mixture of Experts Explained ◦ https://huggingface.co/blog/moe 47
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}