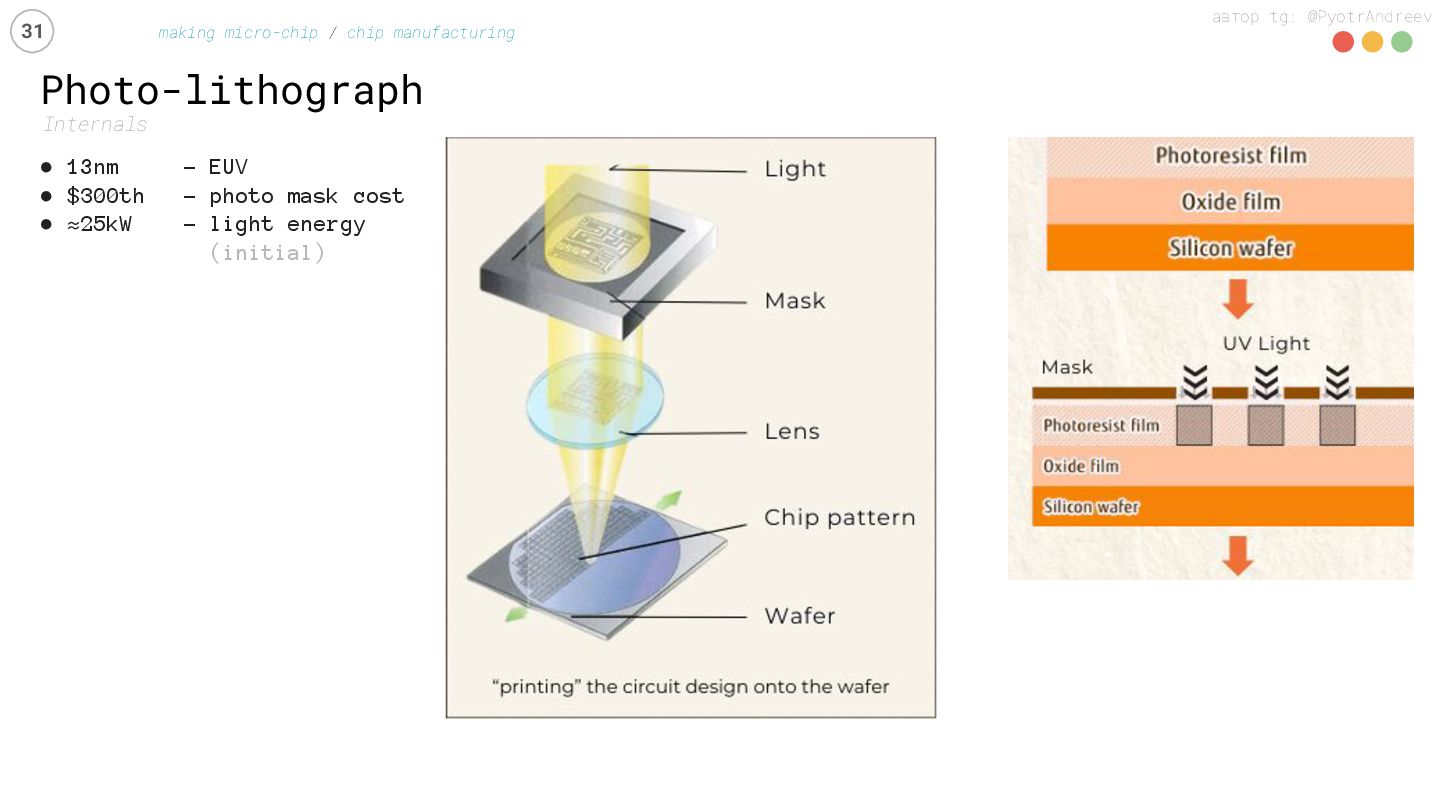
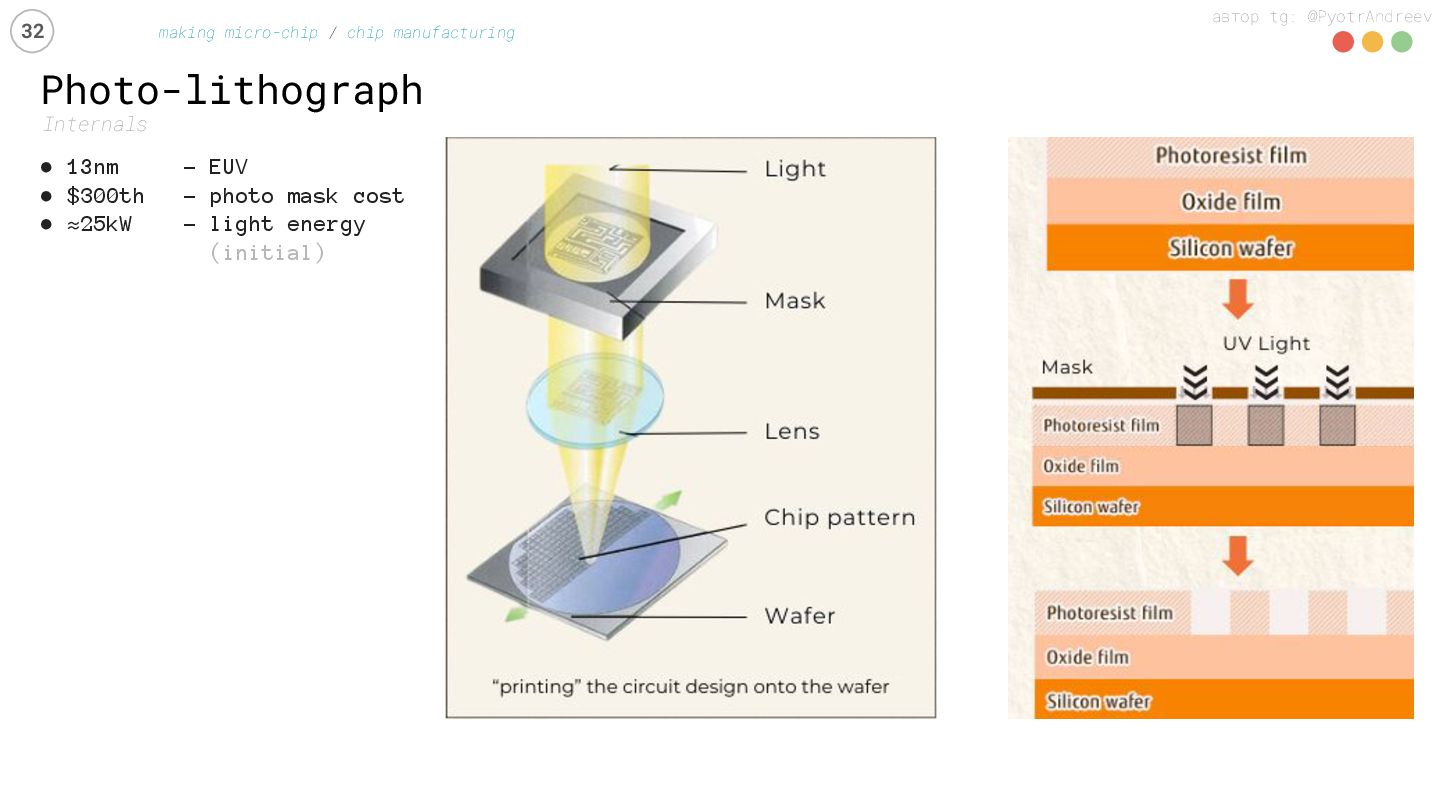
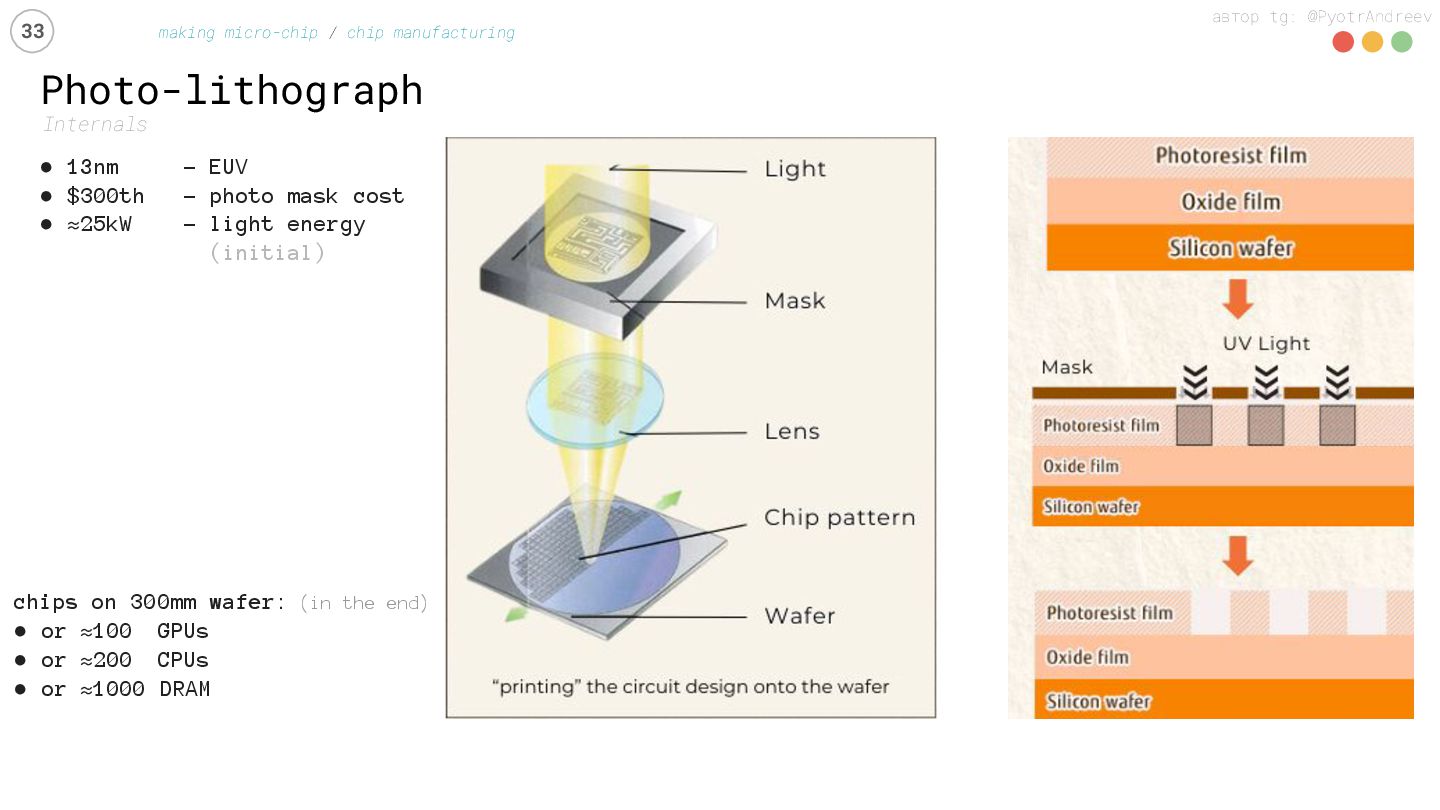
manufacturing • 13nm – EUV • $300th – photo mask cost • ≈25kW - light energy (initial) chips on 300mm wafer: (in the end) • or ≈100 GPUs • or ≈200 CPUs • or ≈1000 DRAM
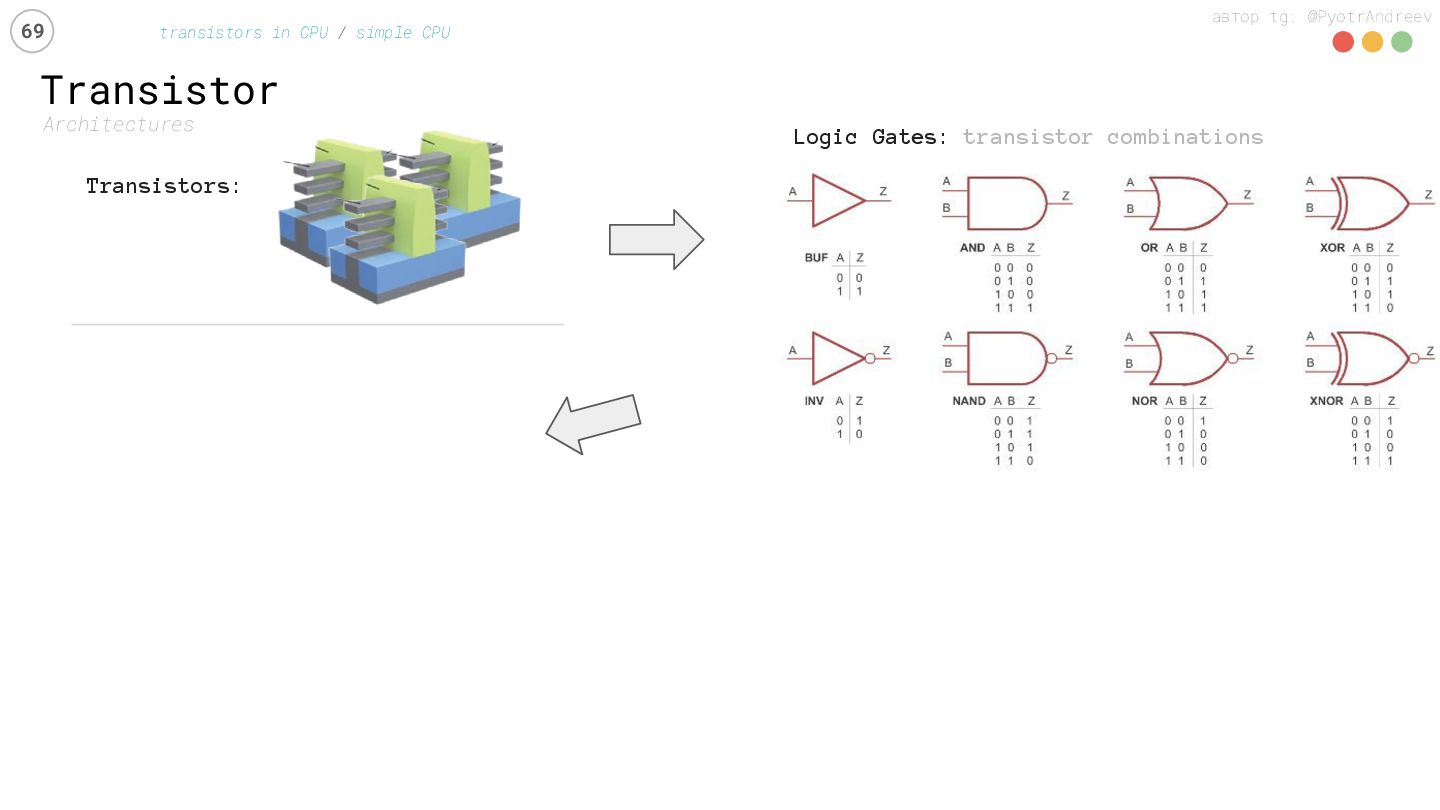
transistors in CPU / simple CPU Transistors: elementary Math: sum, mul, … Units: logic gate combinations IP Core: unit combinations Core: IP Core combinations
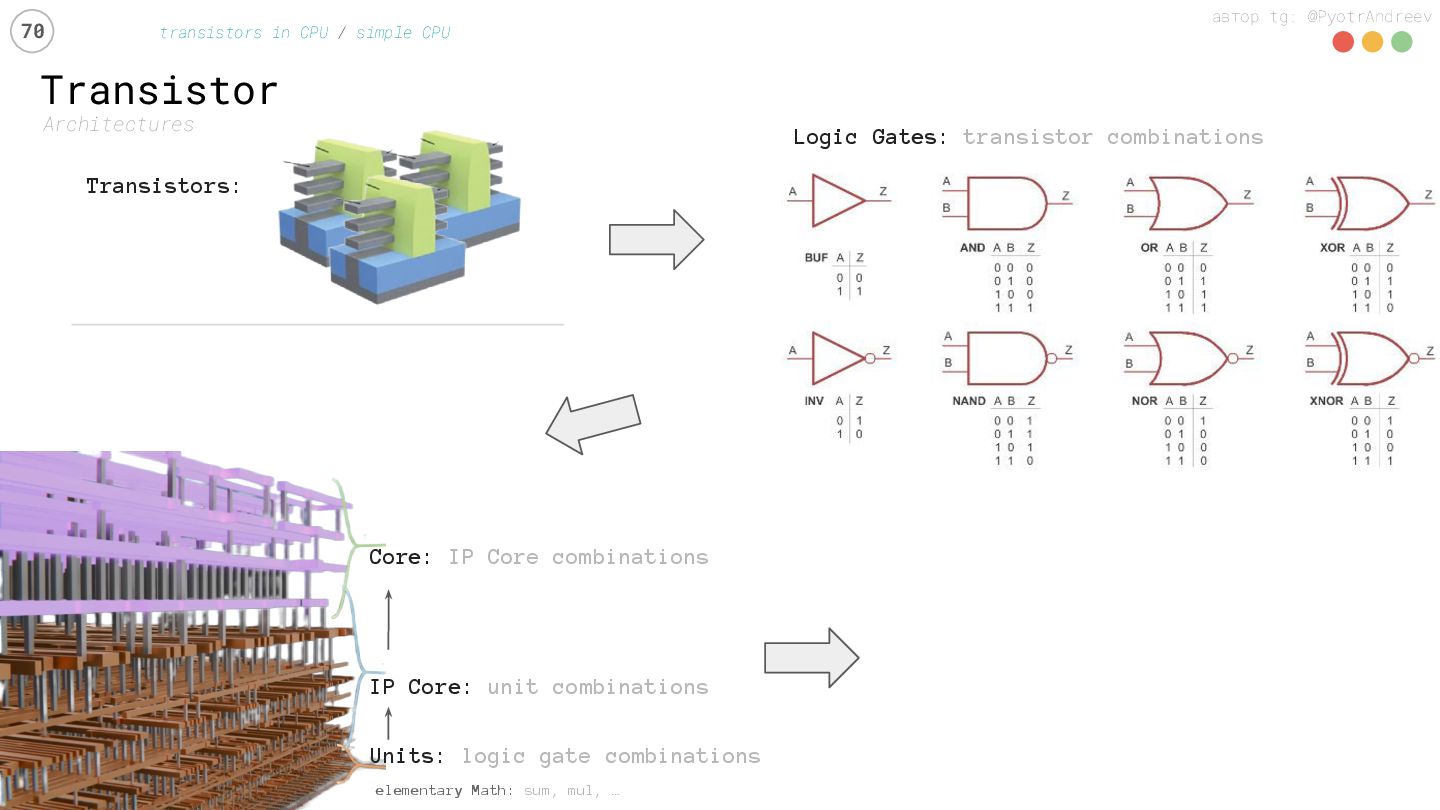
transistors in CPU / simple CPU Transistors: Chip: elementary Math: sum, mul, … Units: logic gate combinations IP Core: unit combinations Core: IP Core combinations
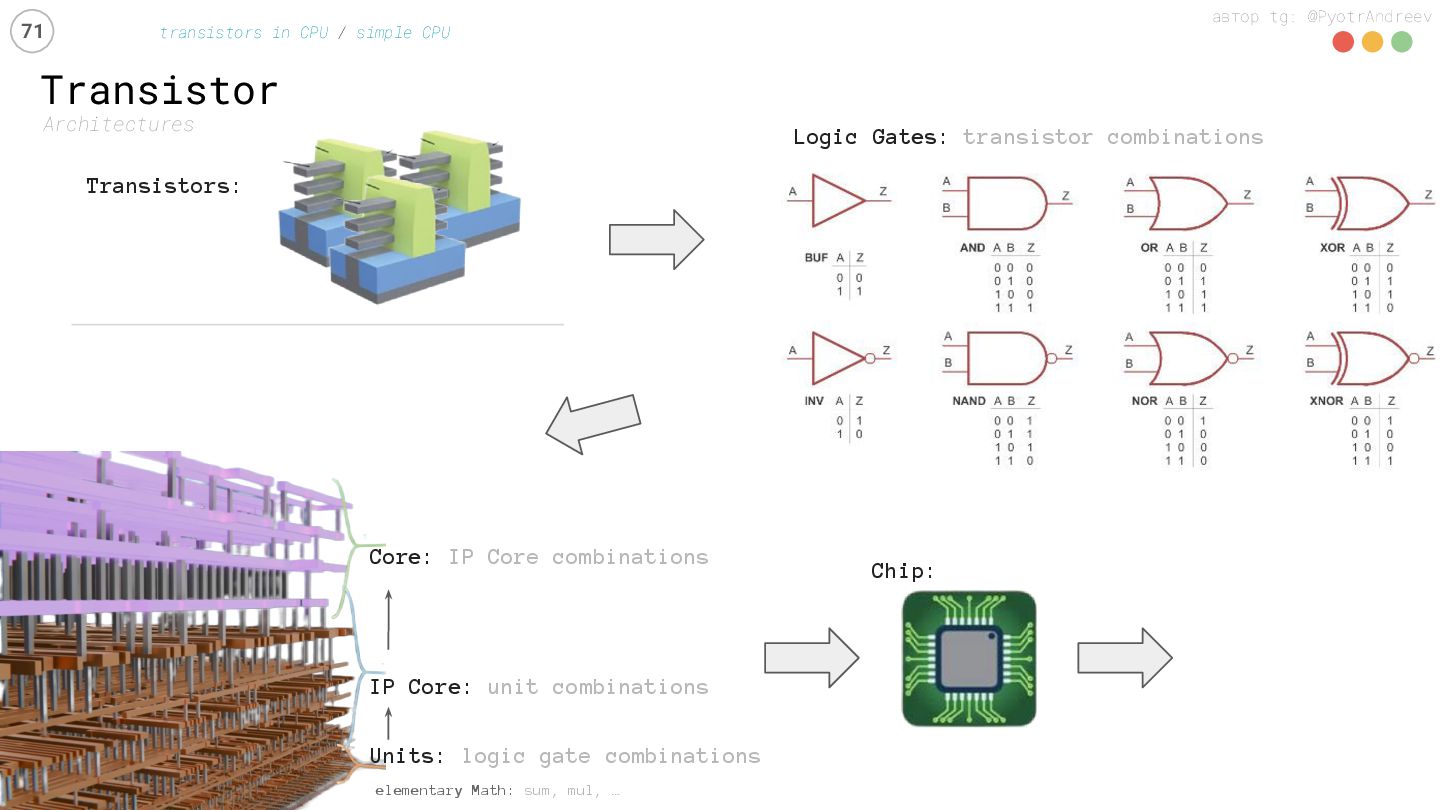
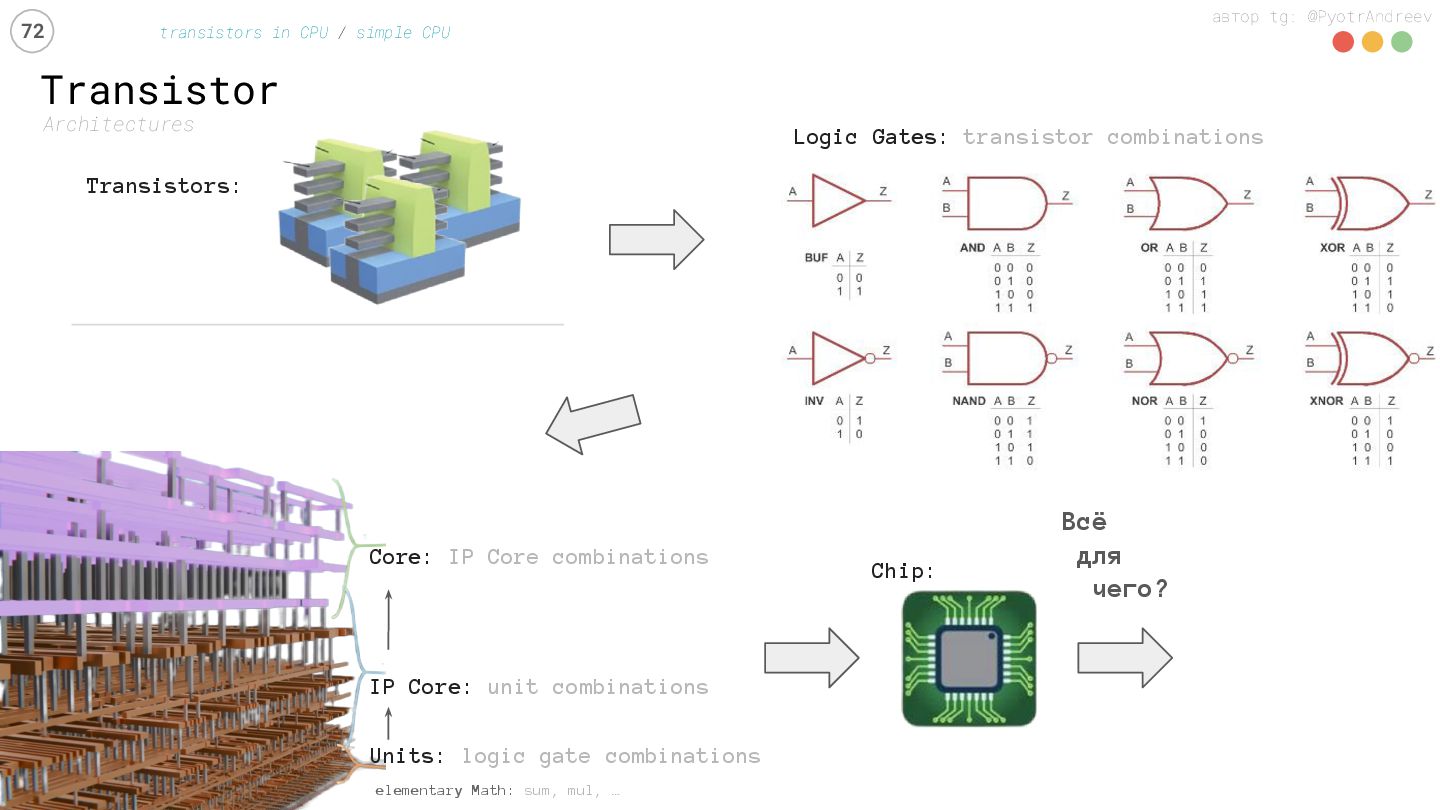
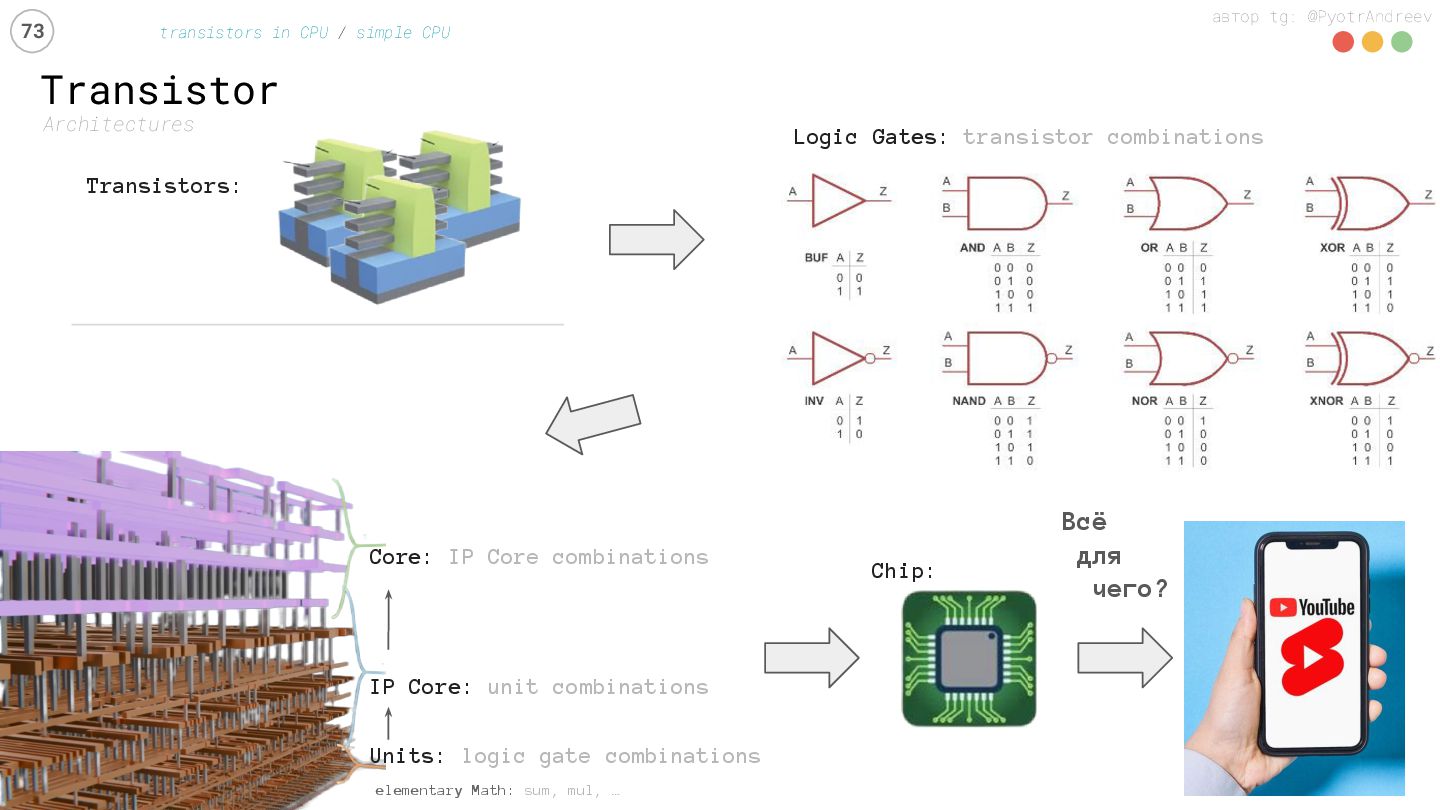
transistors in CPU / simple CPU Transistors: Chip: elementary Math: sum, mul, … Units: logic gate combinations IP Core: unit combinations Core: IP Core combinations Всё для чего?
transistors in CPU / simple CPU Transistors: Chip: elementary Math: sum, mul, … Units: logic gate combinations IP Core: unit combinations Core: IP Core combinations Всё для чего?
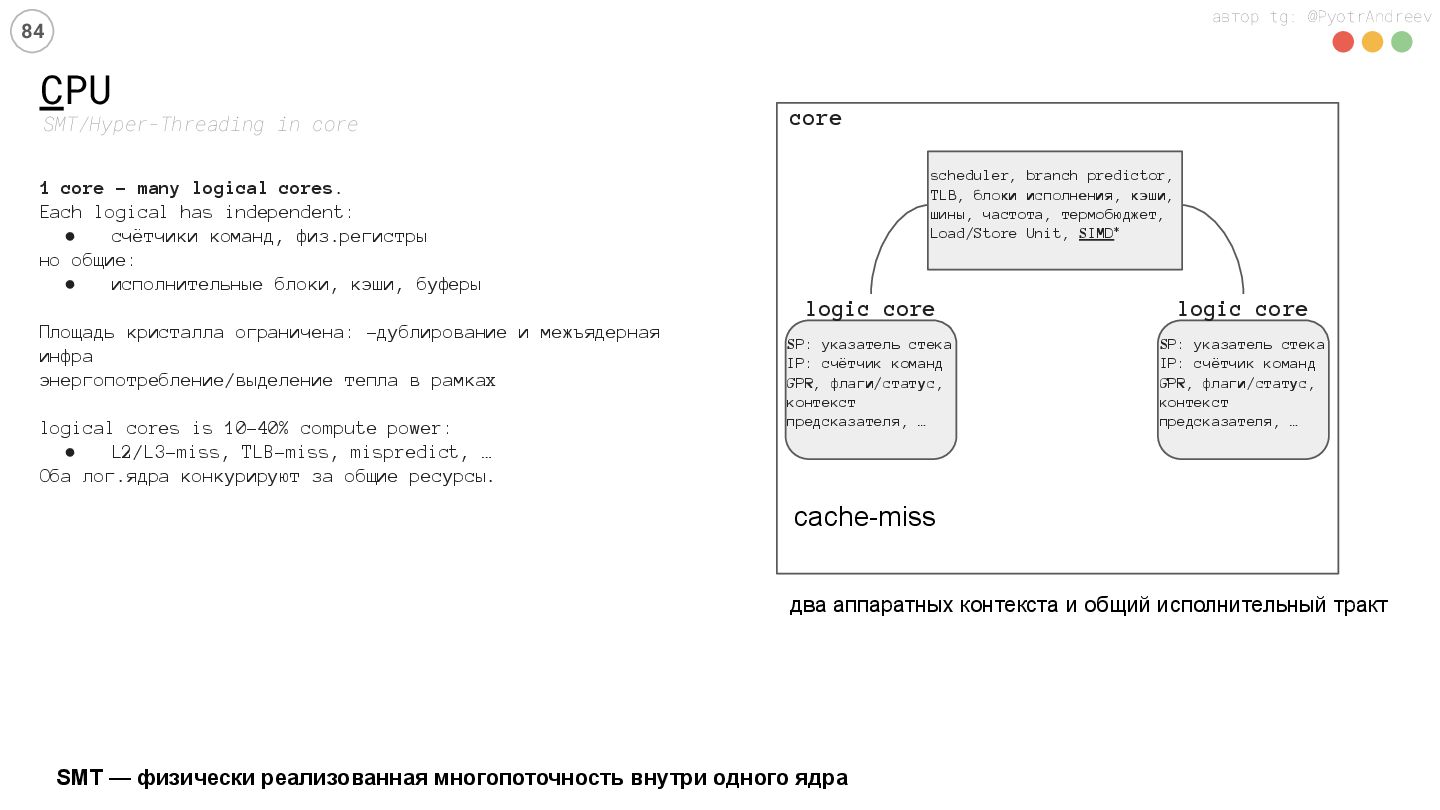
ядер – решение общих задача • сильные ядра + предсказание ветвлений, большие кеши • параллельность: ядра + векторизация + … • лучше для: одной большой задачи за раз CPU architecture / CPU works / G/CPU schemes GPU: много, просто, одновременно CPU: мало, сложно, быстро
ядер – решение общих задача • сильные ядра + предсказание ветвлений, большие кеши • параллельность: ядра + векторизация + … • лучше для: одной большой задачи за раз CPU architecture / CPU works / G/CPU schemes • ~ 100 спец.ядер: • оптимизация: пропускная способность • параллельность: ~ 10th потоков • лучше для: many the same independent simple tasks GPU: много, просто, одновременно CPU: мало, сложно, быстро
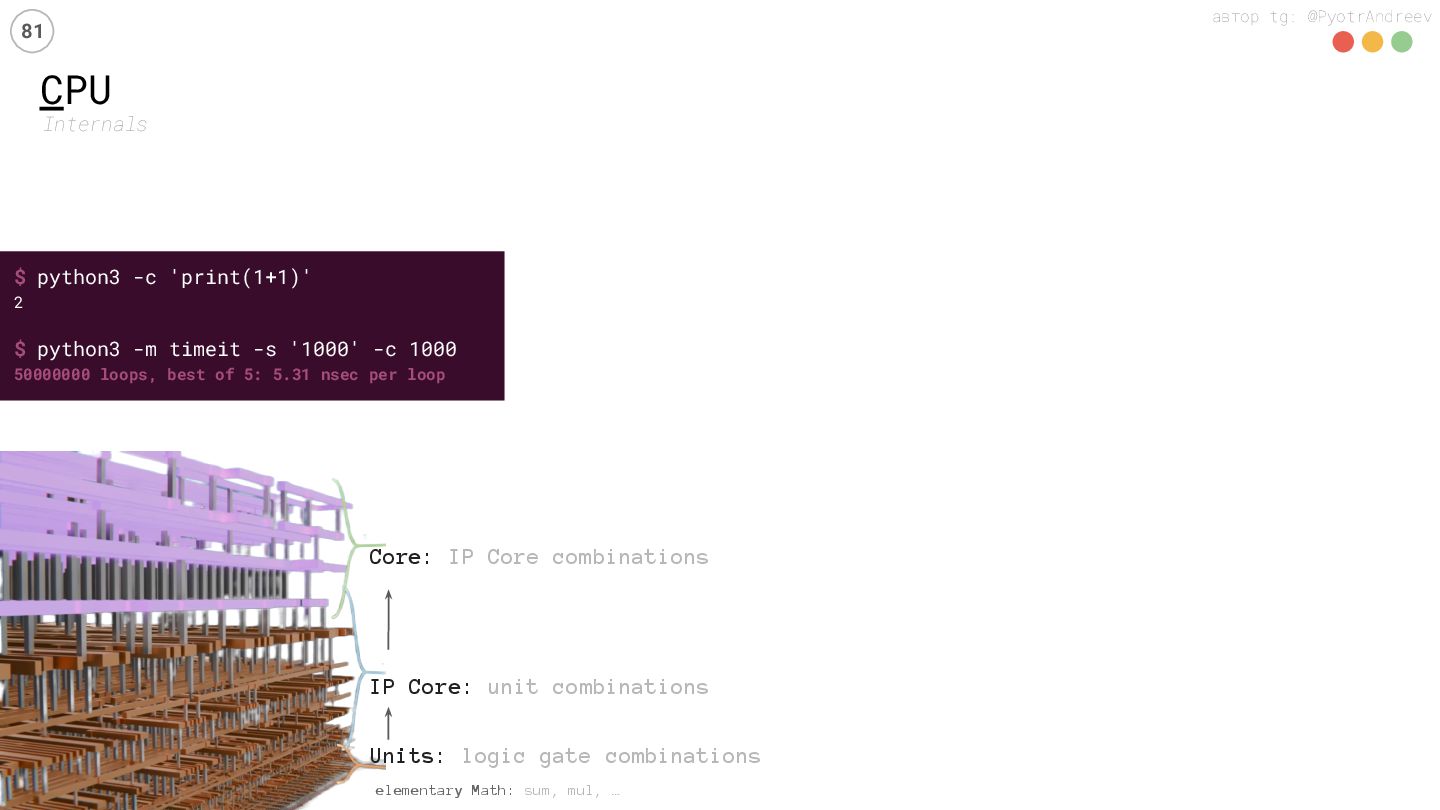
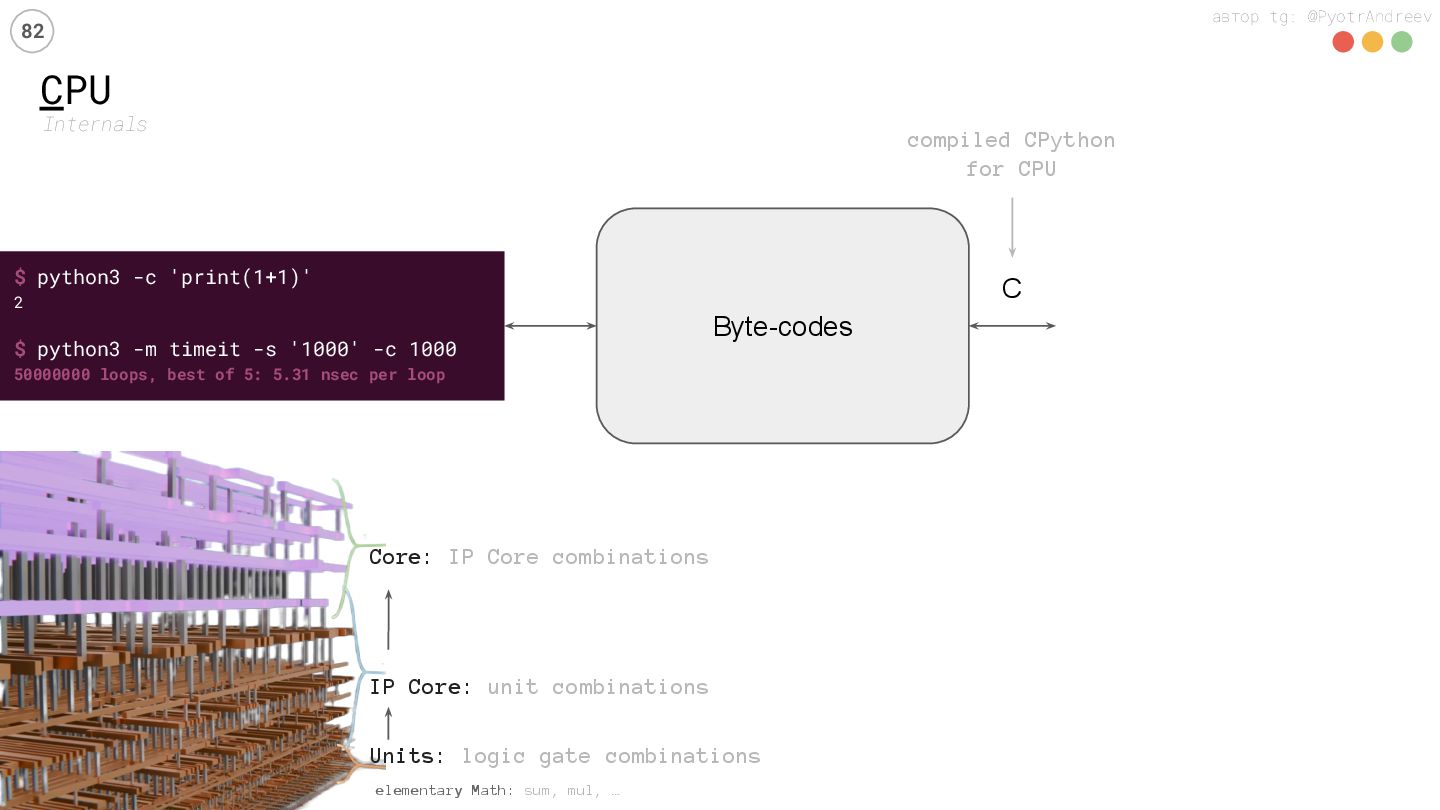
… Units: logic gate combinations IP Core: unit combinations Core: IP Core combinations $ python3 -c 'print(1+1)' 2 $ python3 -m timeit -s '1000' -c 1000 50000000 loops, best of 5: 5.31 nsec per loop Byte-codes C compiled CPython for CPU
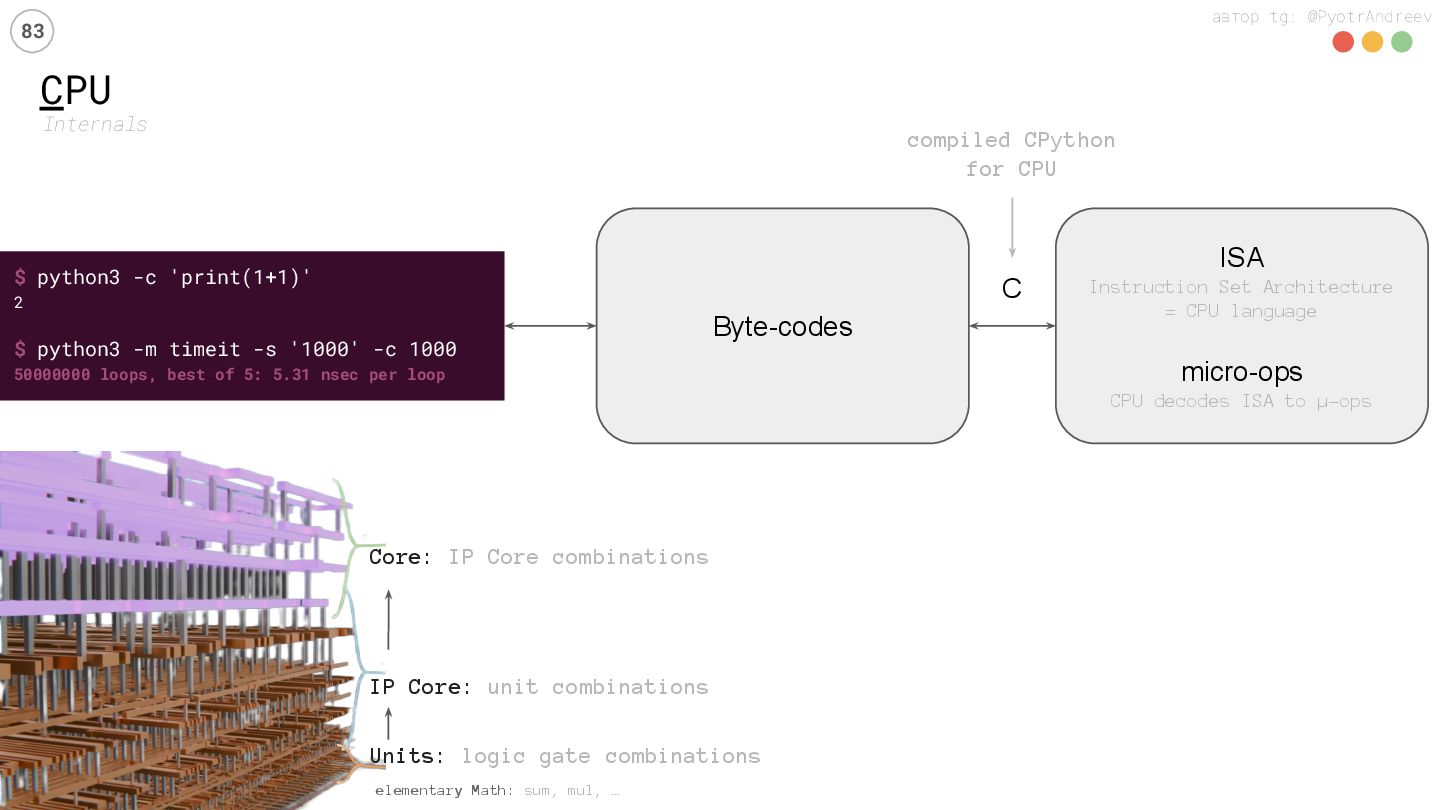
… Units: logic gate combinations IP Core: unit combinations Core: IP Core combinations $ python3 -c 'print(1+1)' 2 $ python3 -m timeit -s '1000' -c 1000 50000000 loops, best of 5: 5.31 nsec per loop Byte-codes ISA Instruction Set Architecture = CPU language micro-ops CPU decodes ISA to µ-ops C compiled CPython for CPU
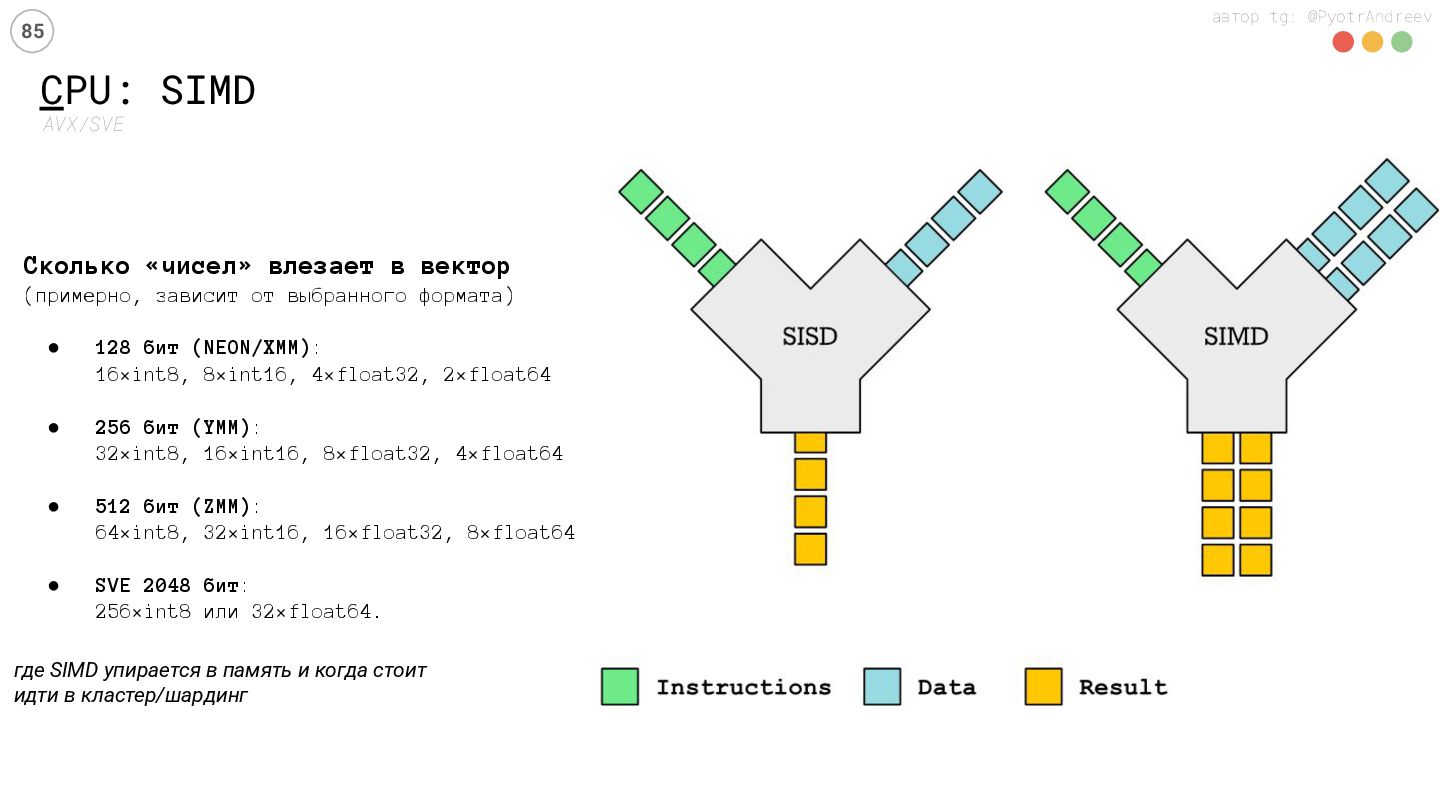
в вектор (примерно, зависит от выбранного формата) • 128 бит (NEON/XMM): 16×int8, 8×int16, 4×float32, 2×float64 • 256 бит (YMM): 32×int8, 16×int16, 8×float32, 4×float64 • 512 бит (ZMM): 64×int8, 32×int16, 16×float32, 8×float64 • SVE 2048 бит: 256×int8 или 32×float64. где SIMD упирается в память и когда стоит идти в кластер/шардинг
{kind=link}
{kind=link}
{kind=link}
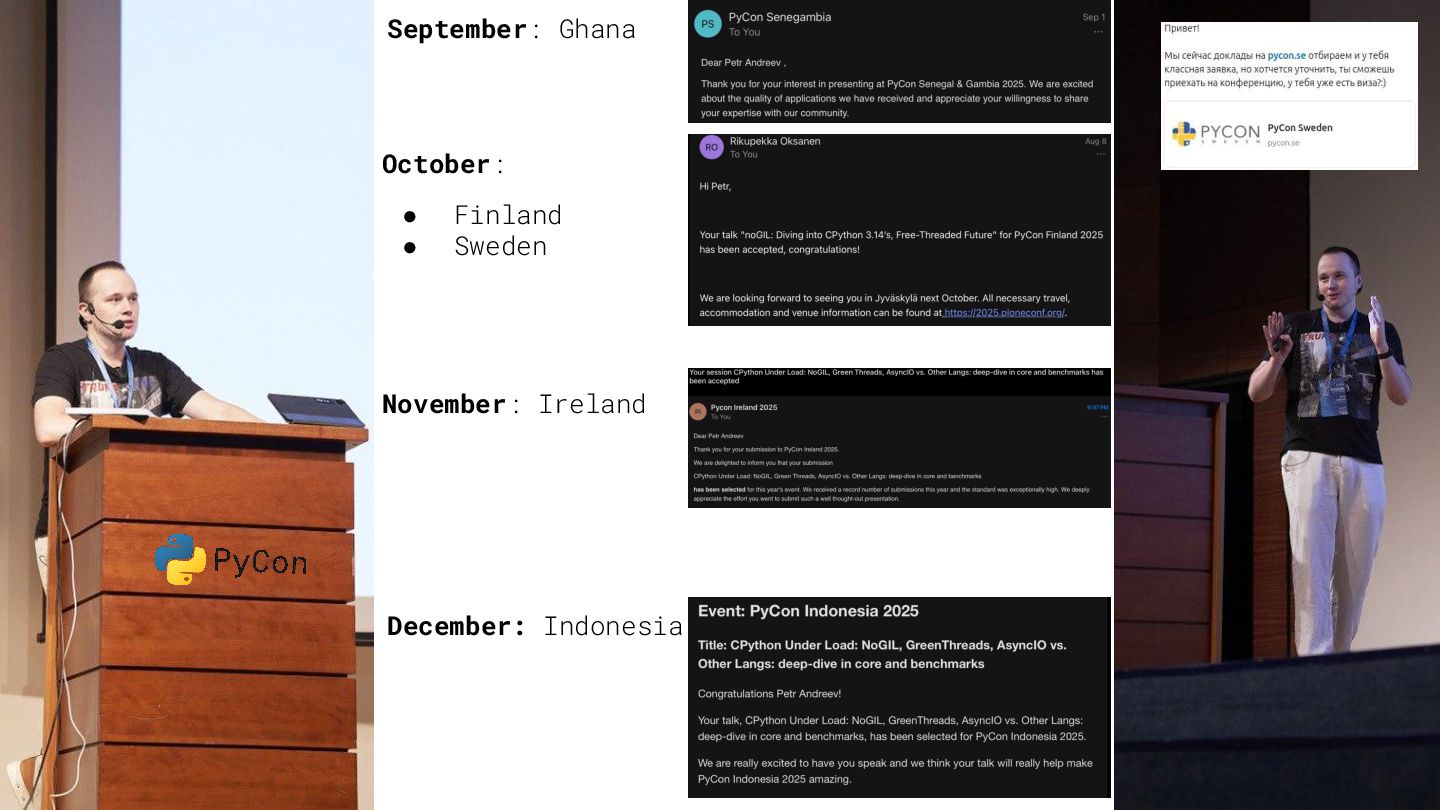{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
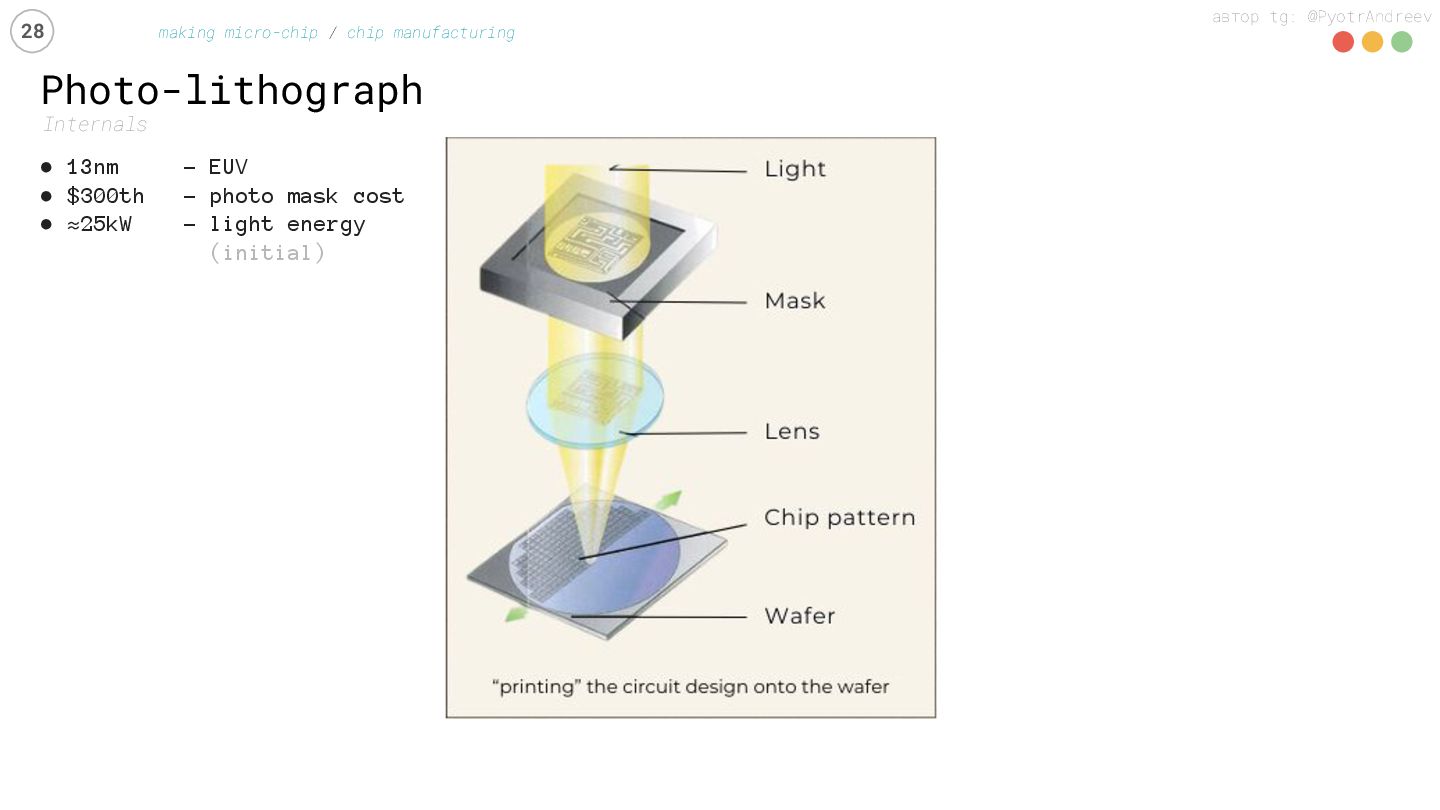{kind=link}
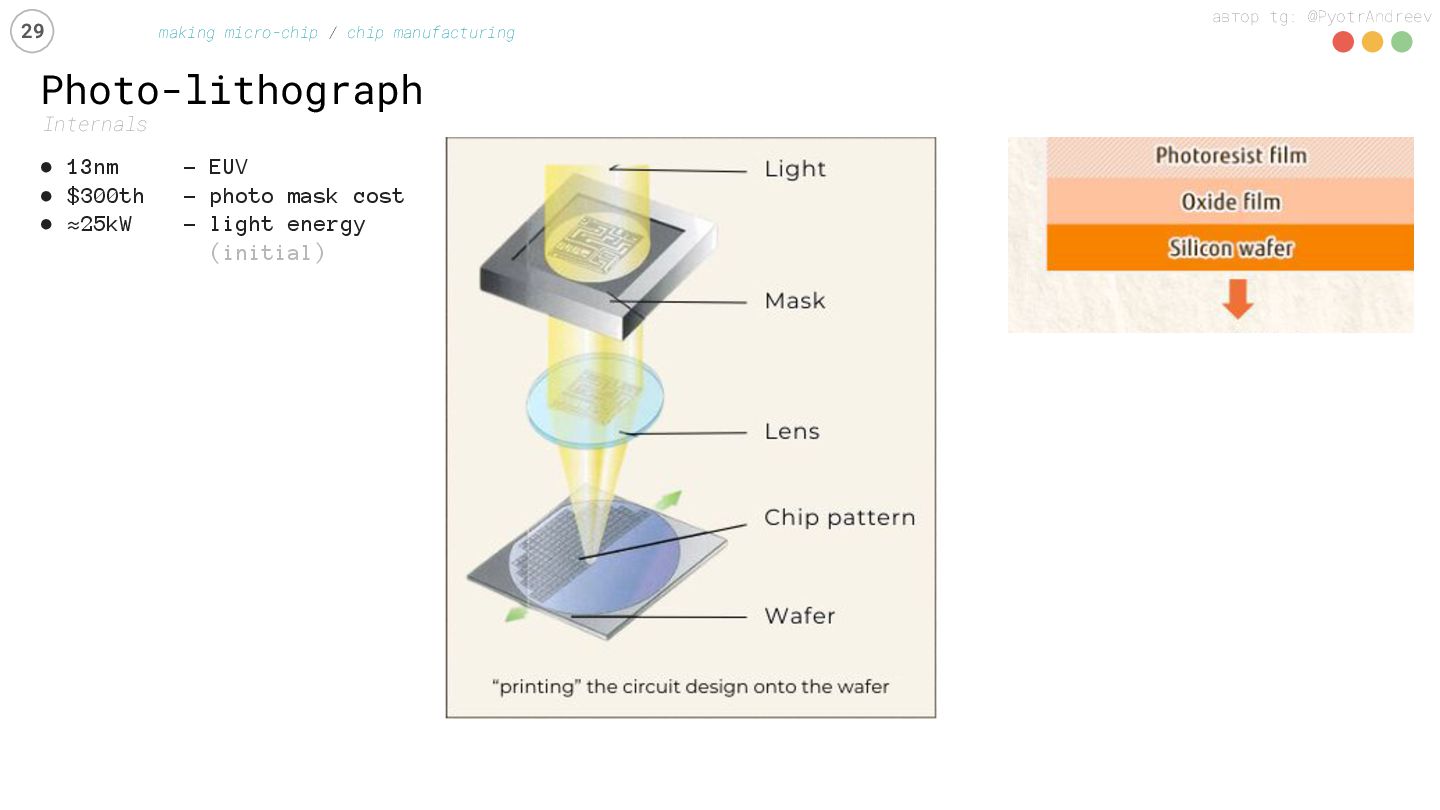{kind=link}
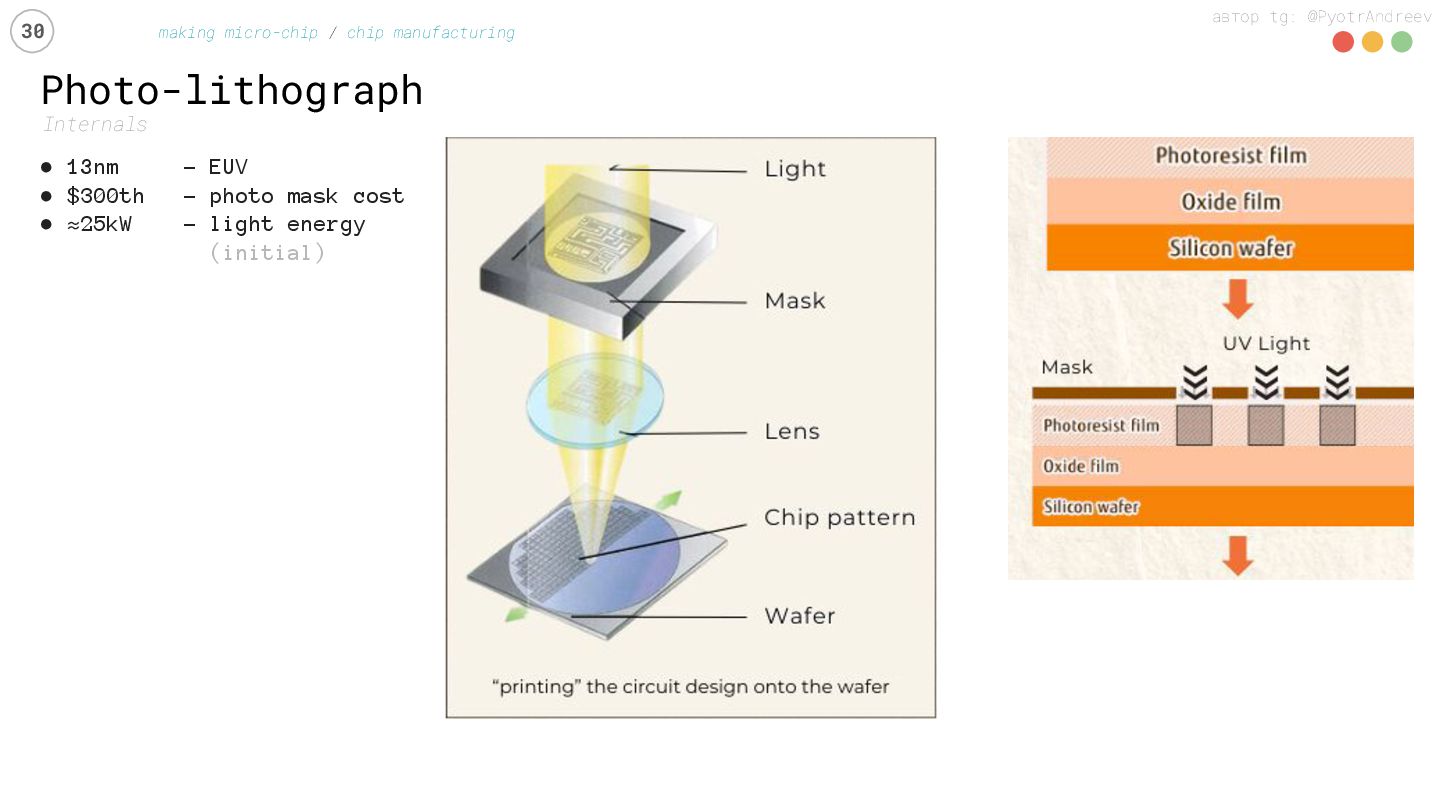{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
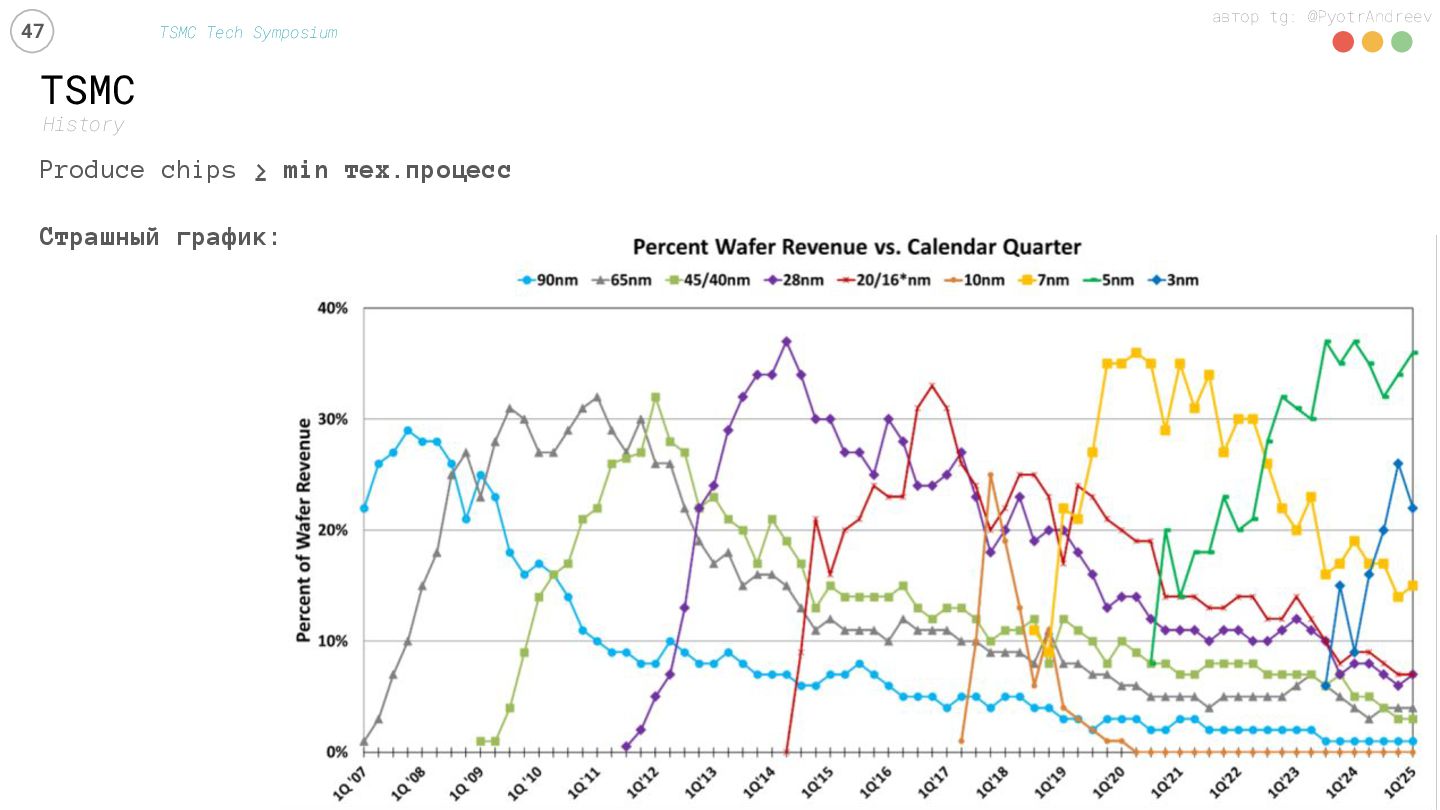{kind=link}
{kind=link}
{kind=link}
{kind=link}
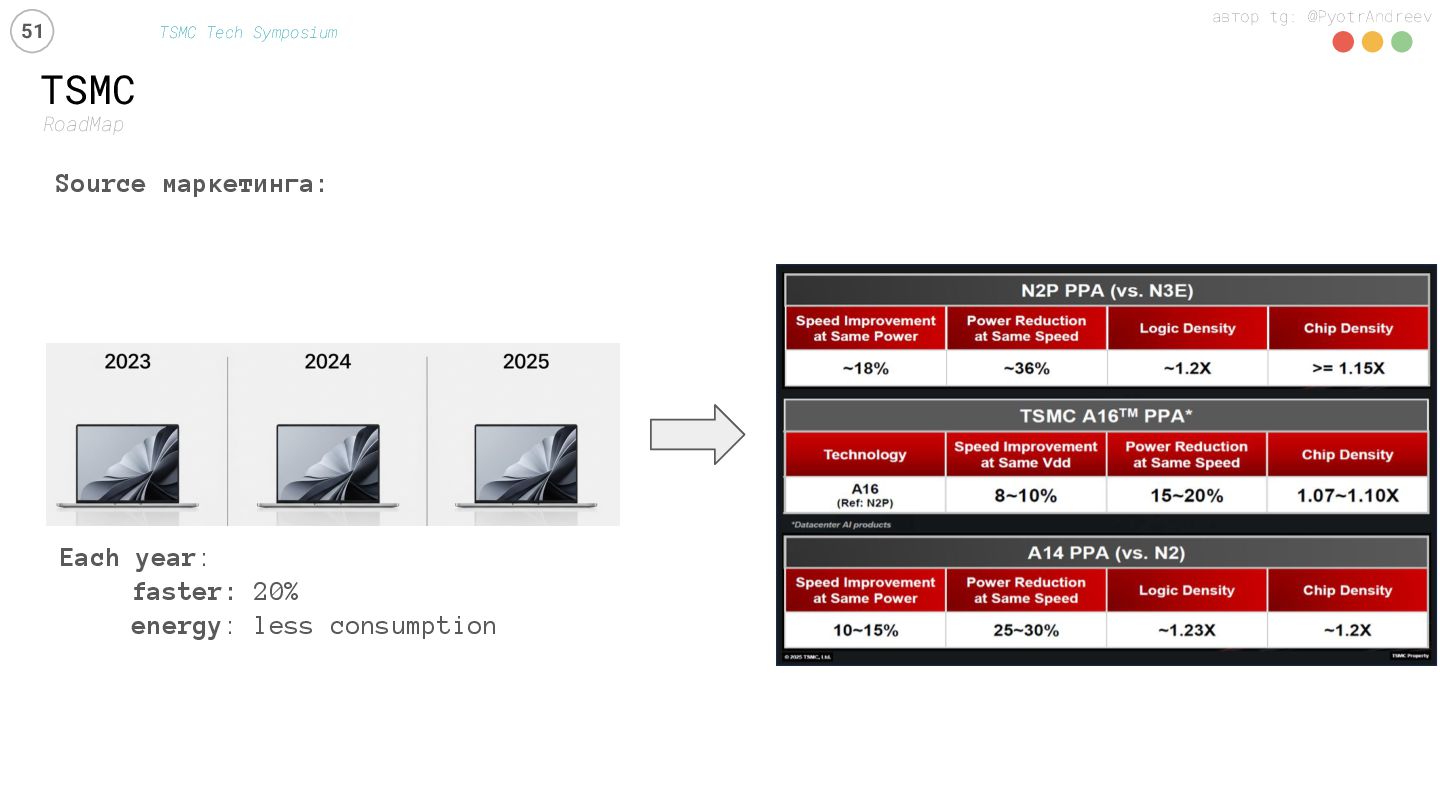{kind=link}
{kind=link}
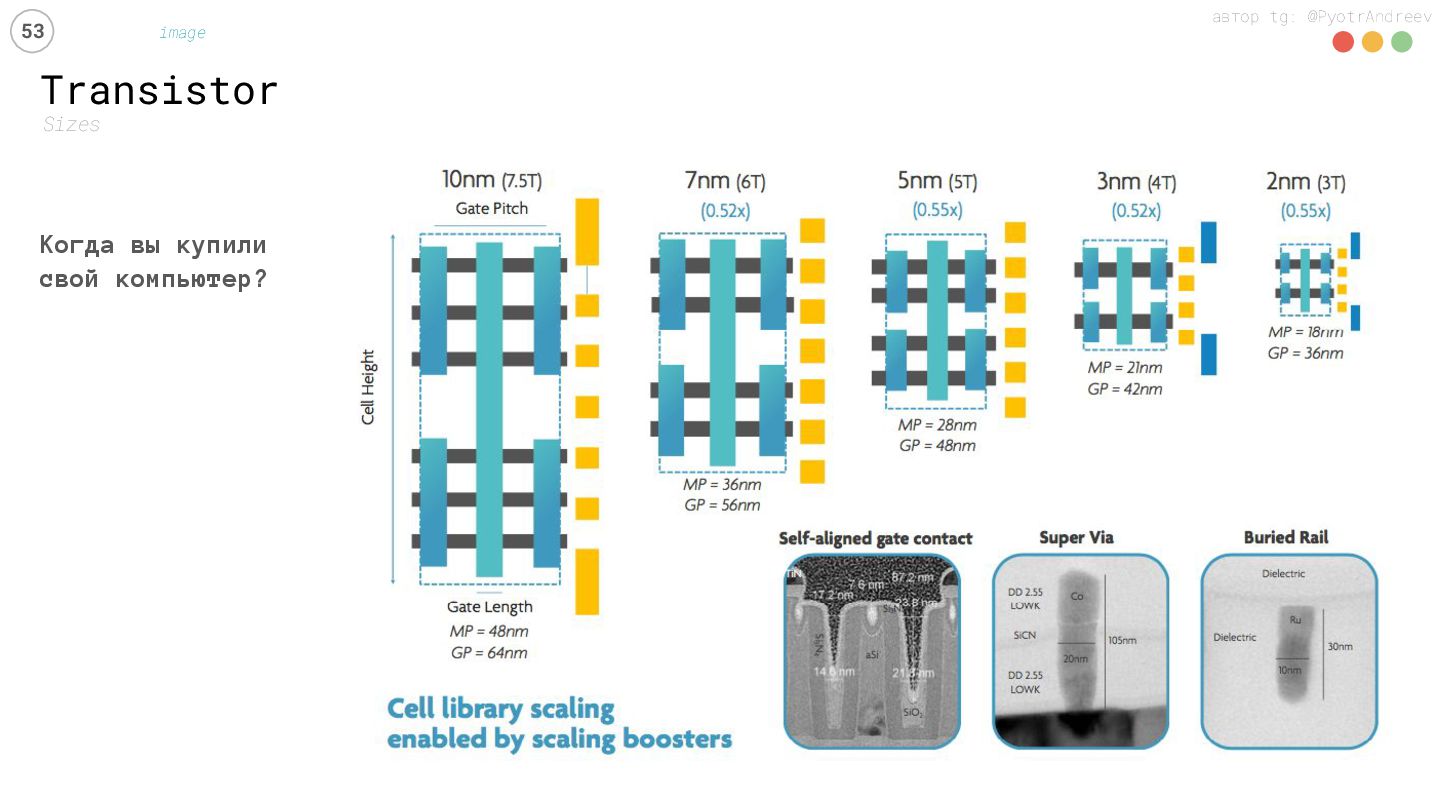{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
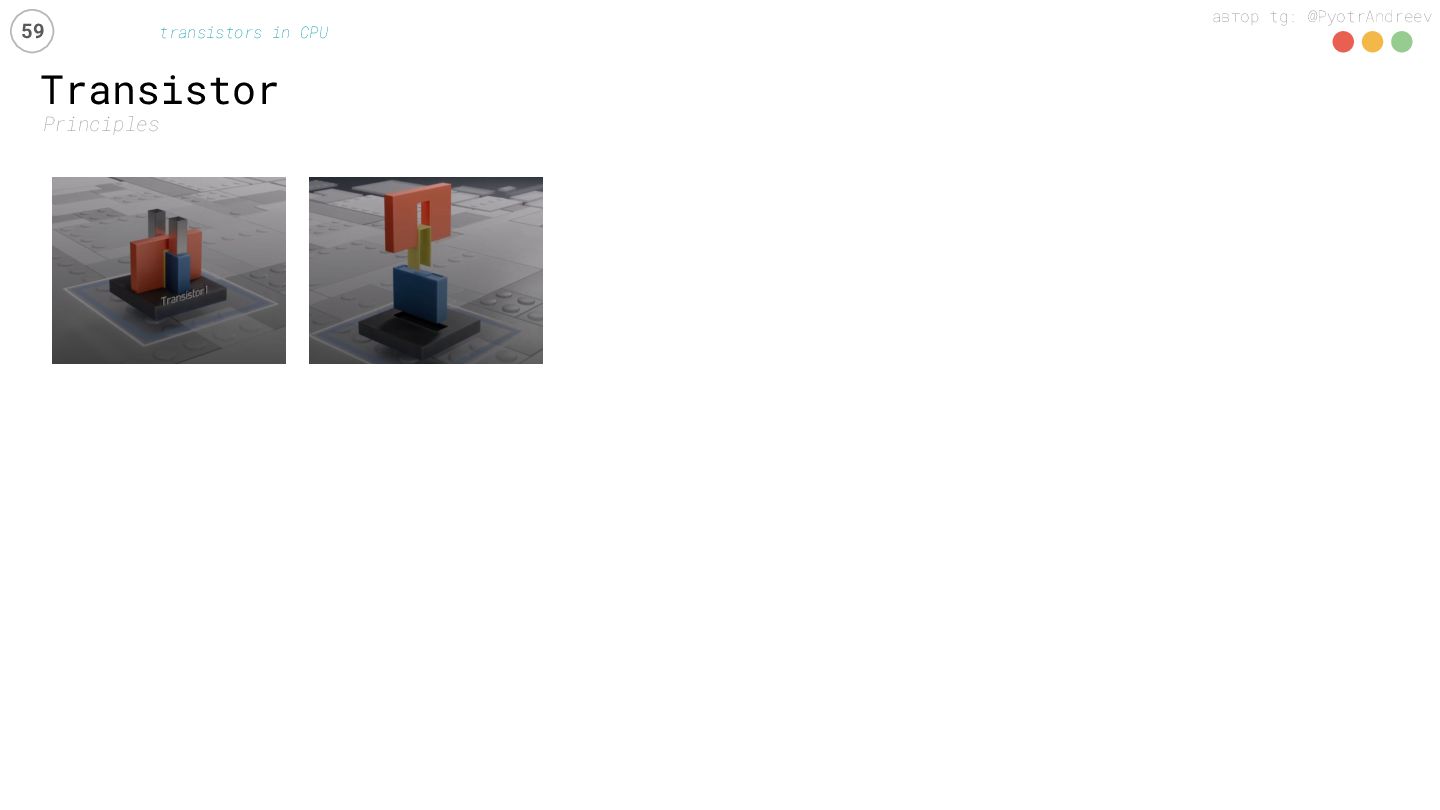{kind=link}
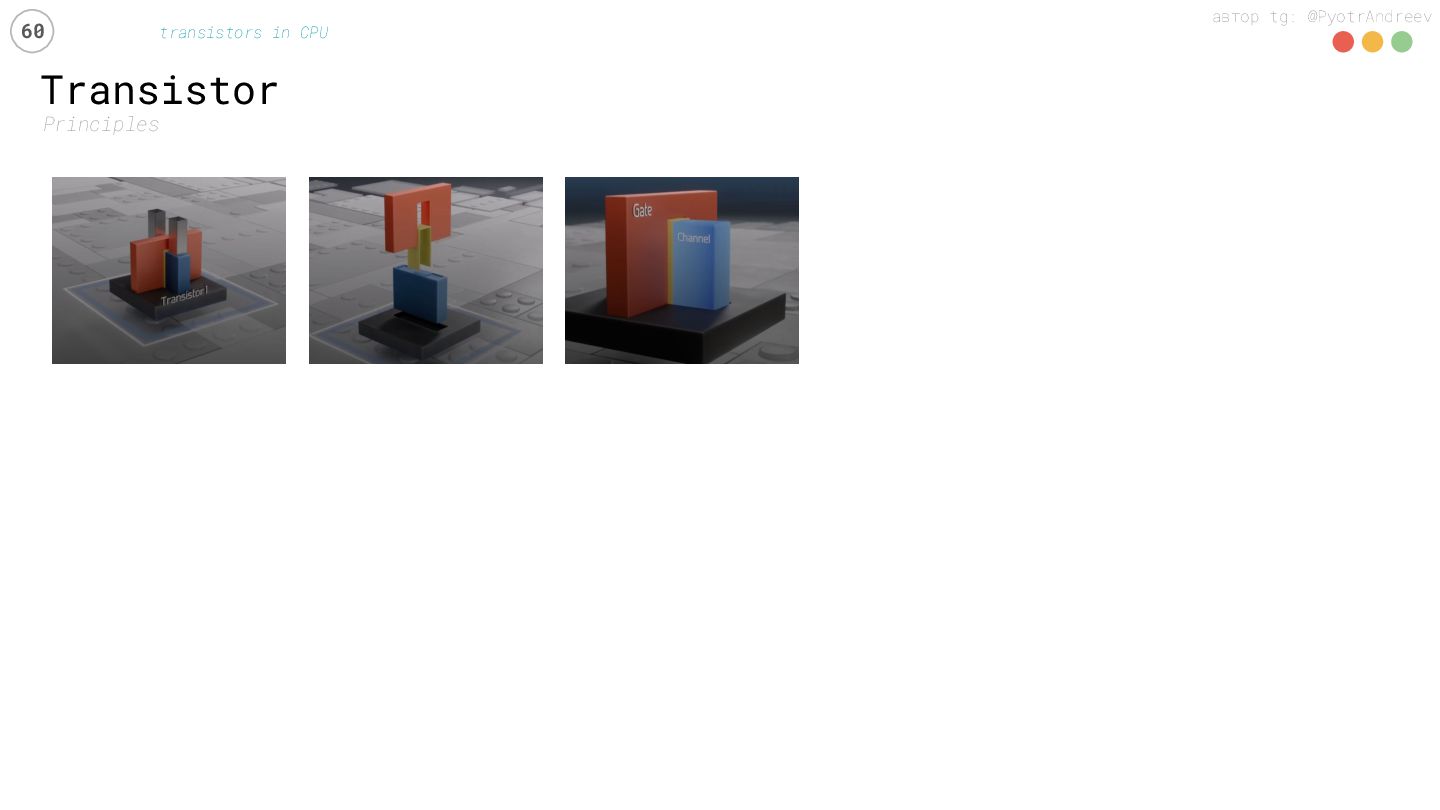{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
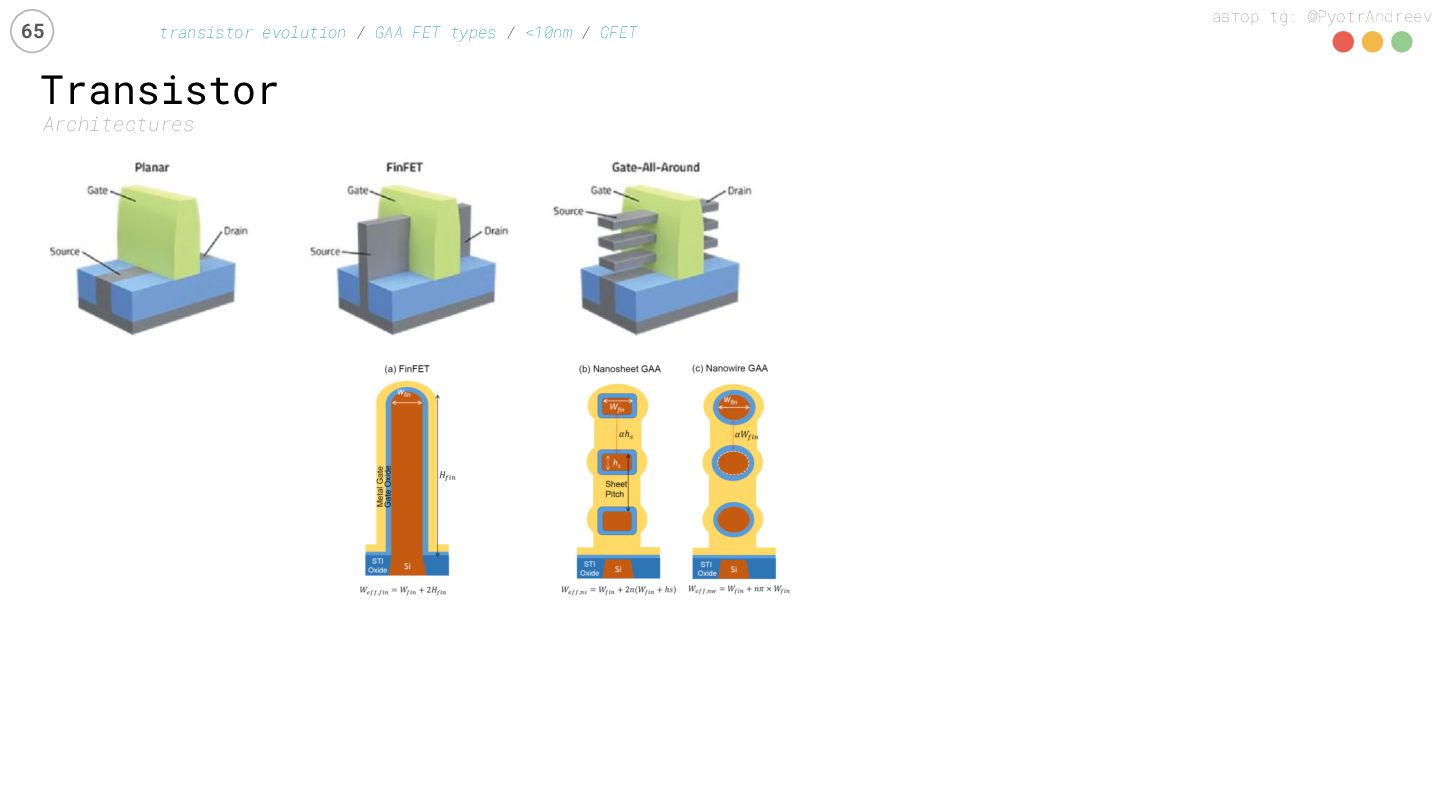{kind=link}
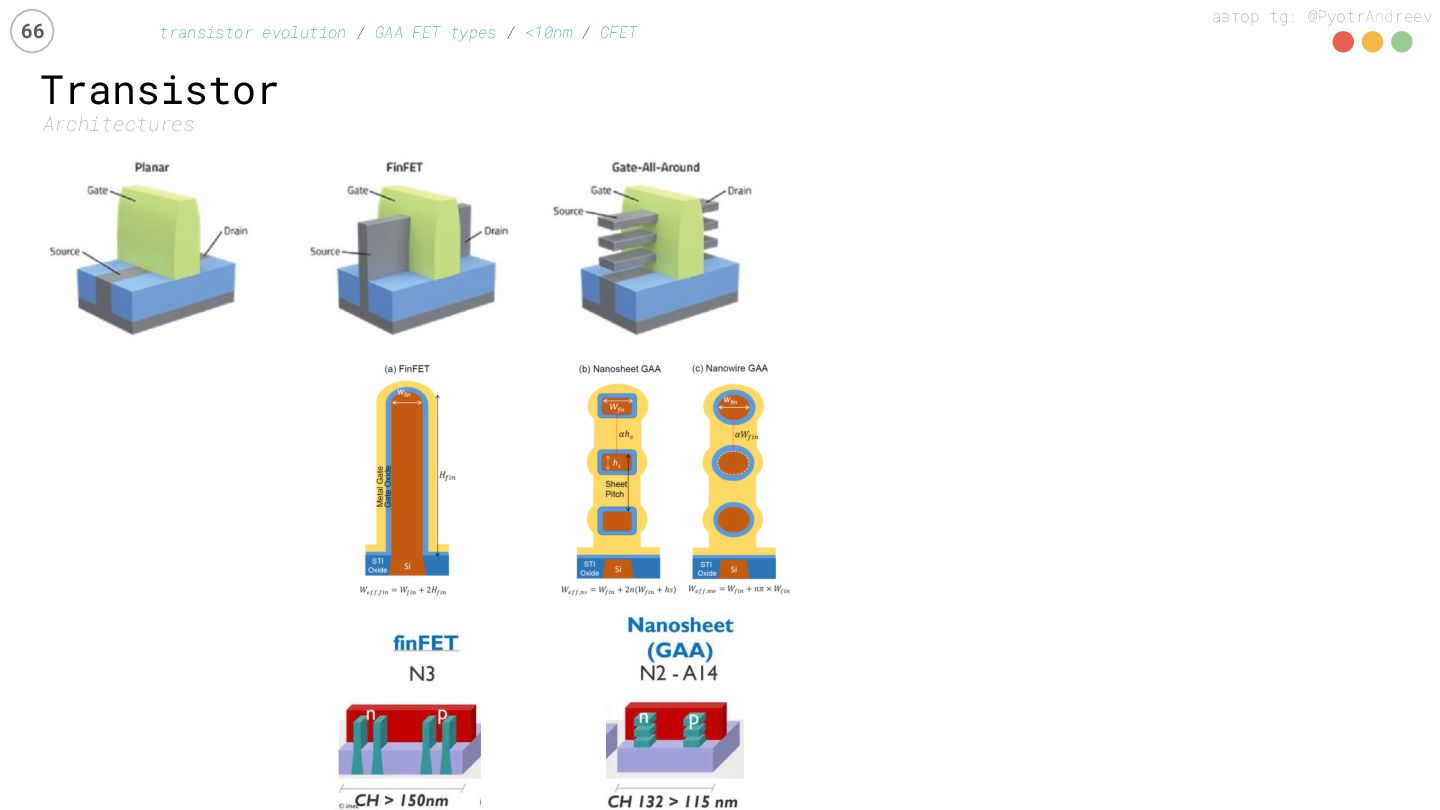{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
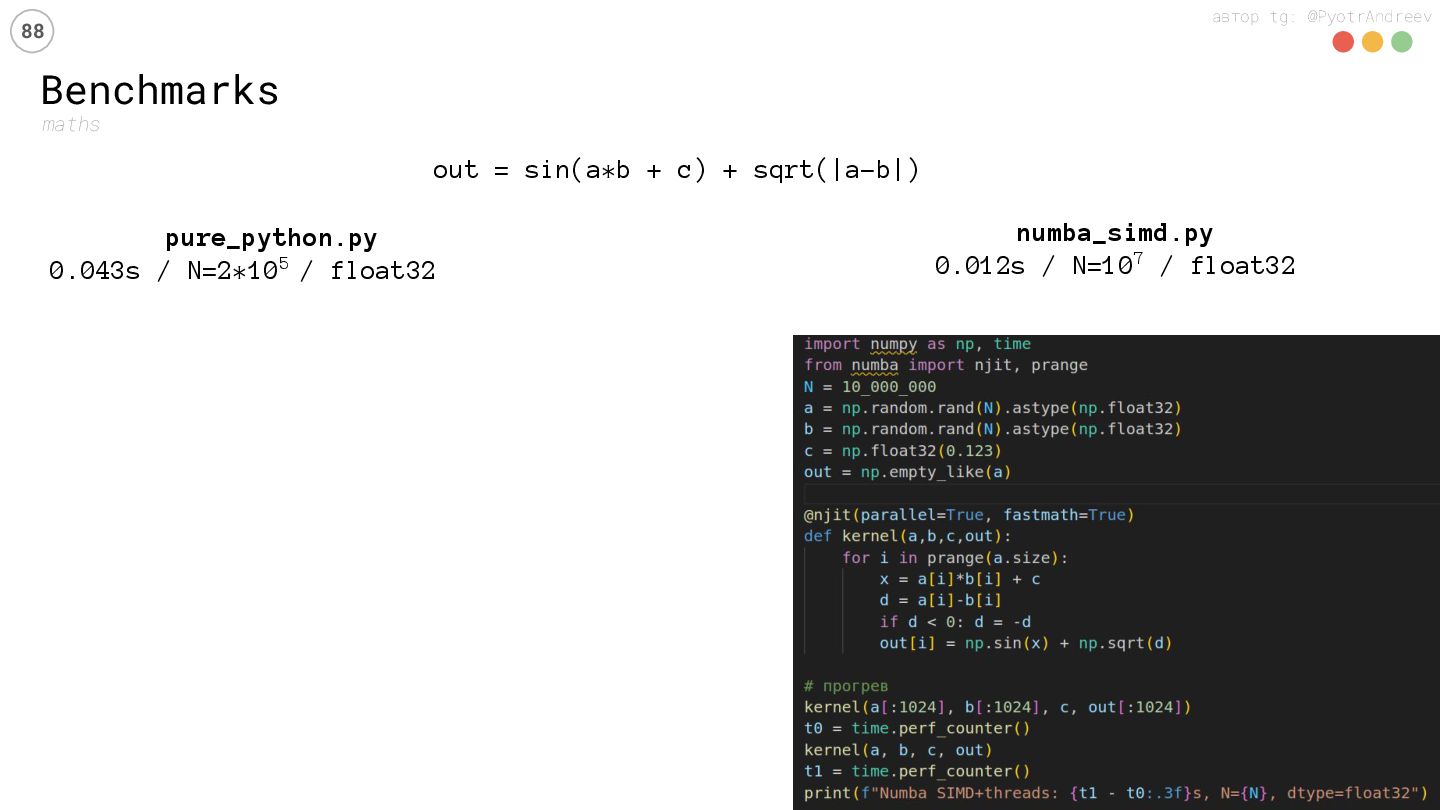{kind=link}
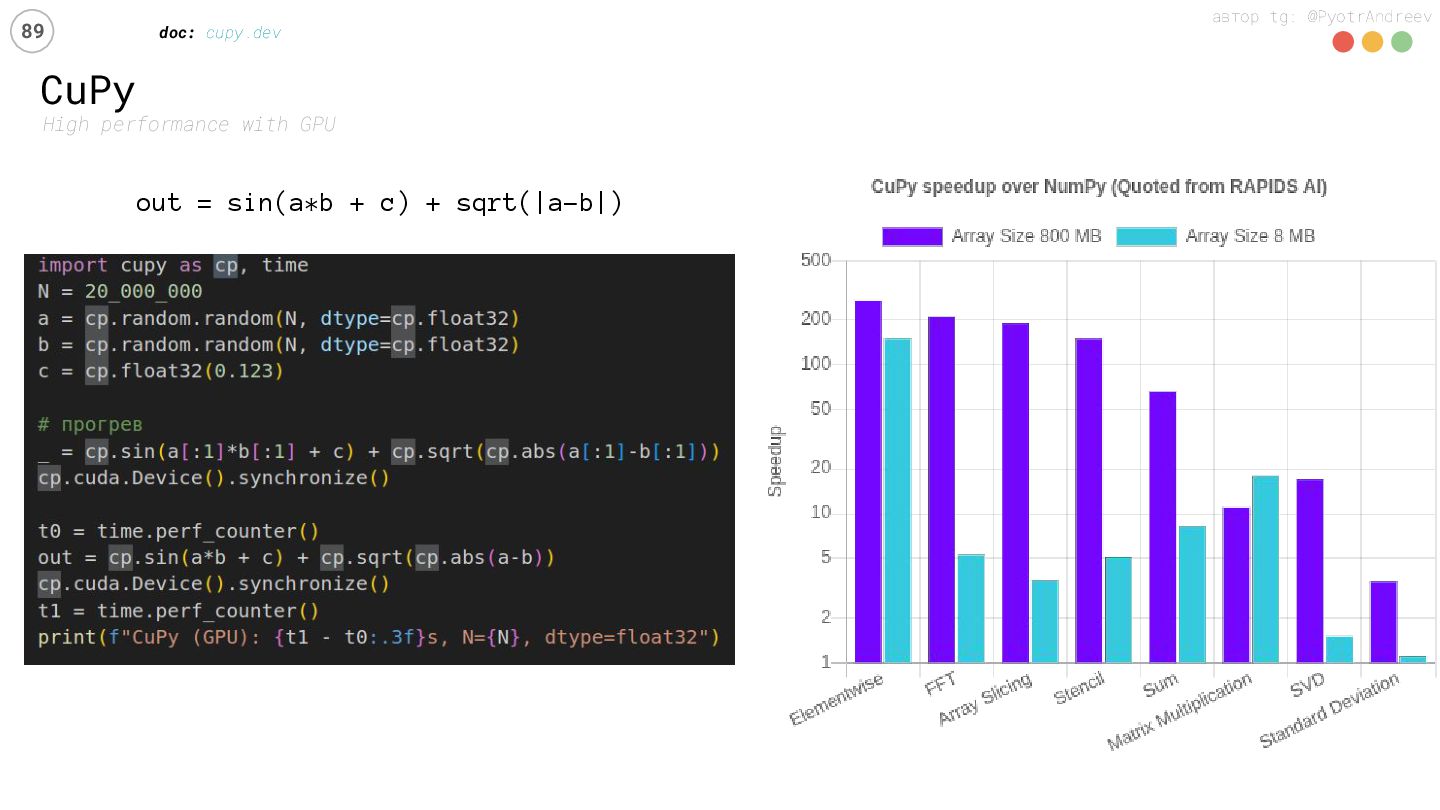{kind=link}
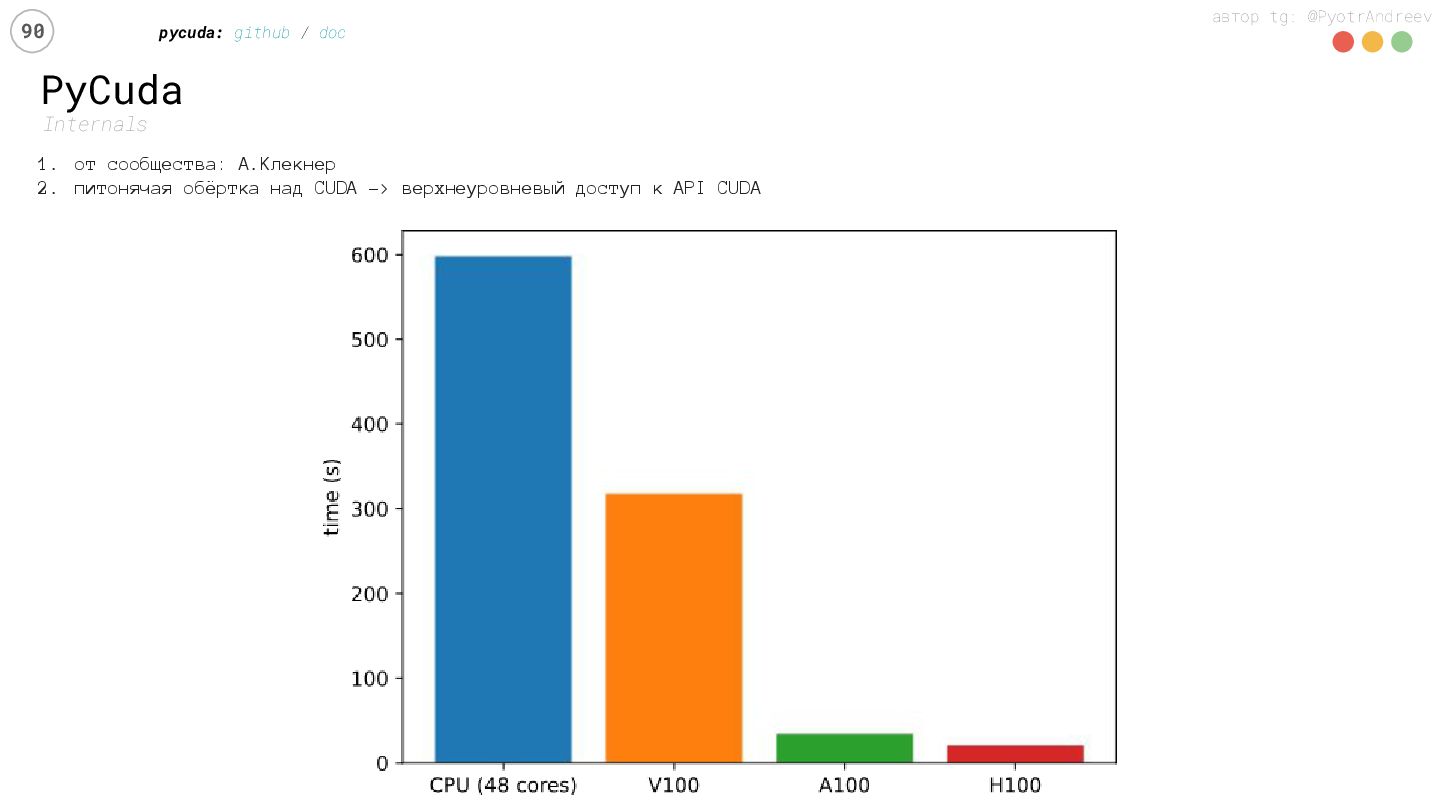{kind=link}
{kind=link}