2018 года. Начал со своих проектов, разработал игровой чат-бот на базе API популярной социальной сети, бесплатно получил трафик, пару месяцев держал 40к MAU, потом похоронил проект. Далее работал в документообороте, финтех и сейчас в Звуке. команда поиска HiFi-стриминг Звук
подкасты, аудиокниги, эксклюзивные плейлисты и раздел для детей ✦ Слушайте Звук в приложении, на сайте zvuk.com, в автомобилях с поддержкой CarPlay и Android Auto ✦ А также в онлайн-кинотеатре Оkko и на колонках SberBoom
трех направлениях: HiFi-стриминг Звук, Звук СТУДИО и Звук Бизнес Пионеры высокого качества. Звук первым среди российских стримингов предоставил пользователям возможность слушать музыку в HiFi-качестве Звук Гиперперсонализация
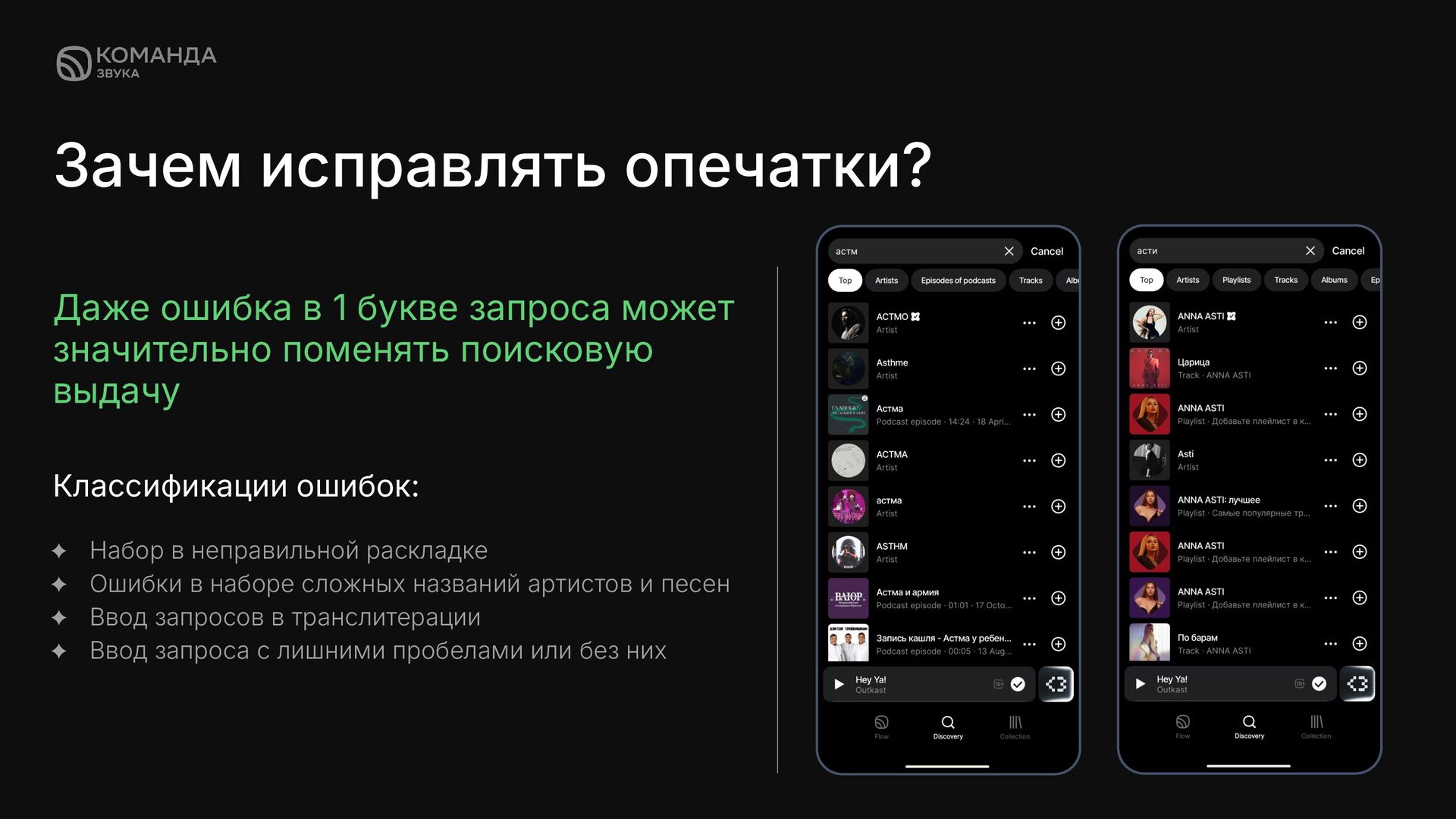
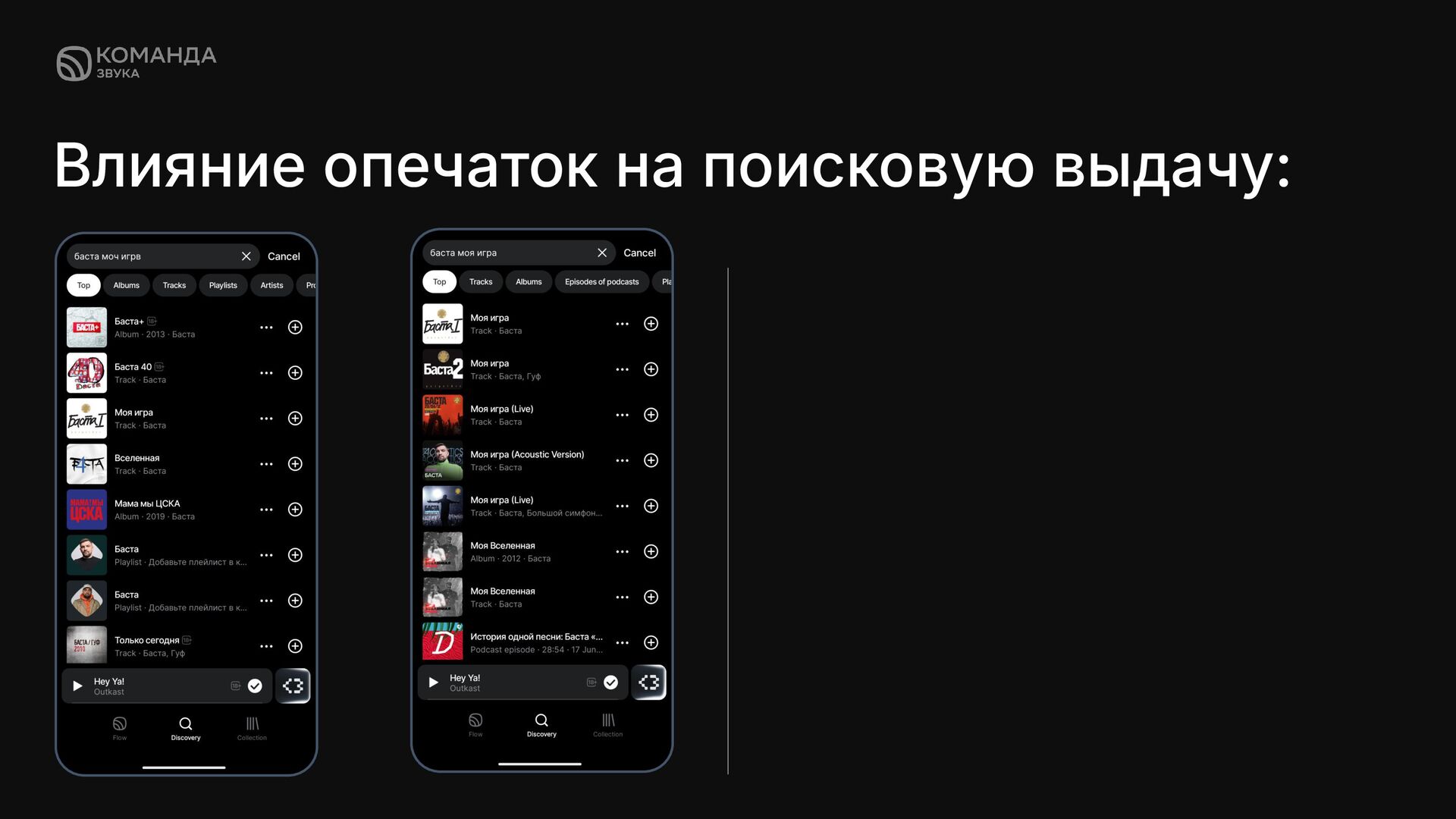
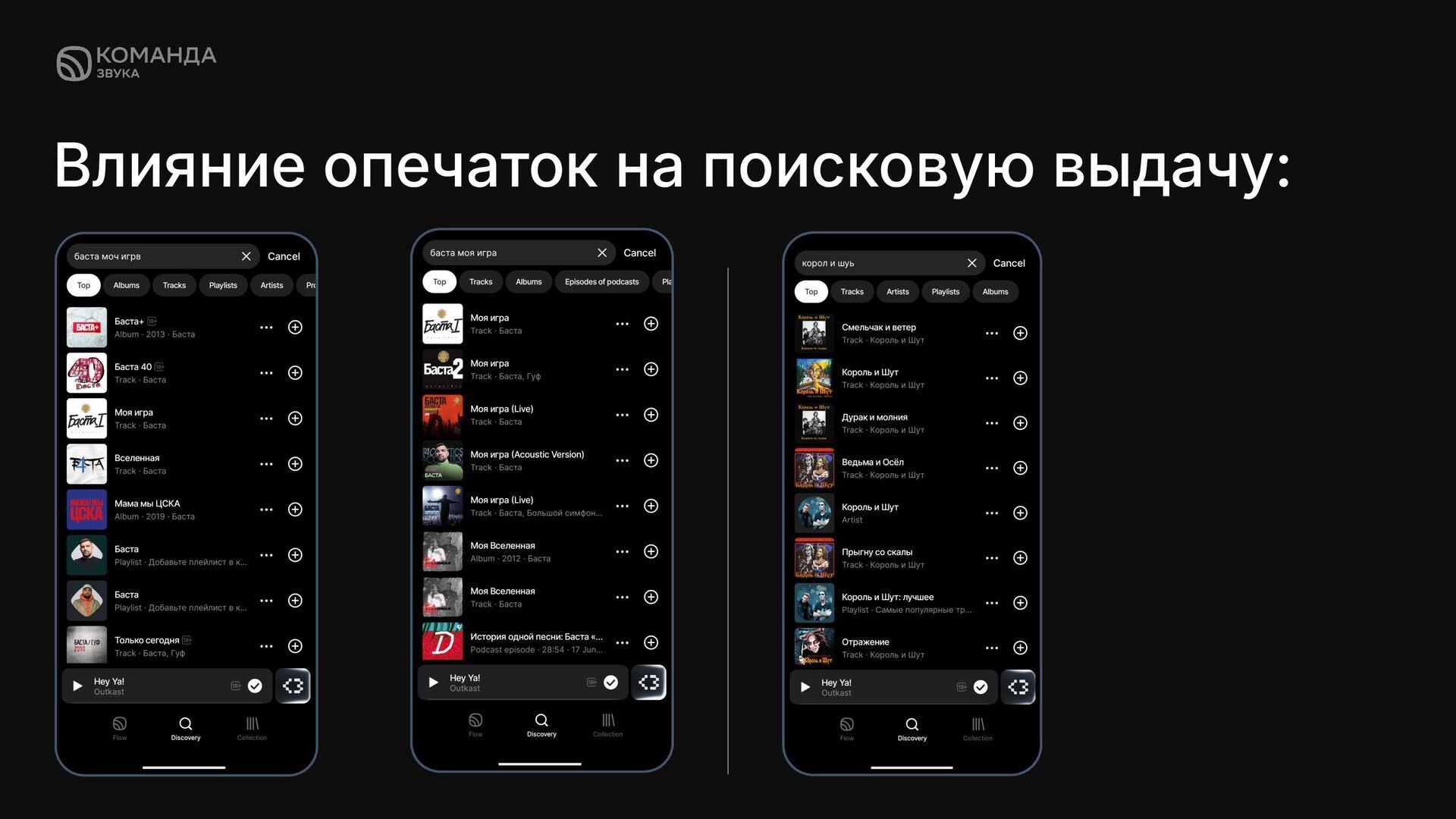
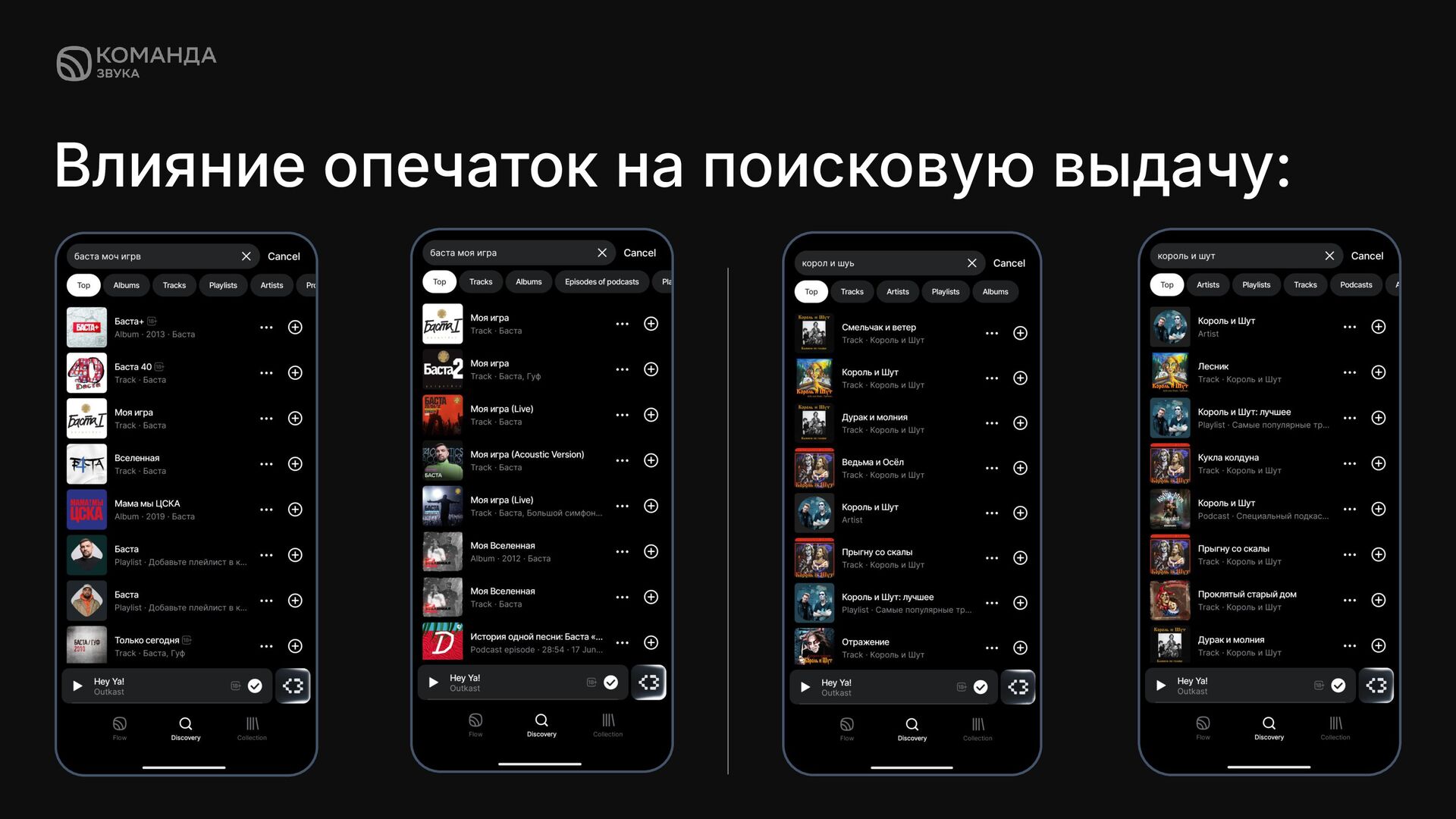
✦ Ошибки в наборе сложных названий артистов и песен ✦ Ввод запросов в транслитерации ✦ Ввод запроса с лишними пробелами или без них Даже ошибка в 1 букве запроса может значительно поменять поисковую выдачу
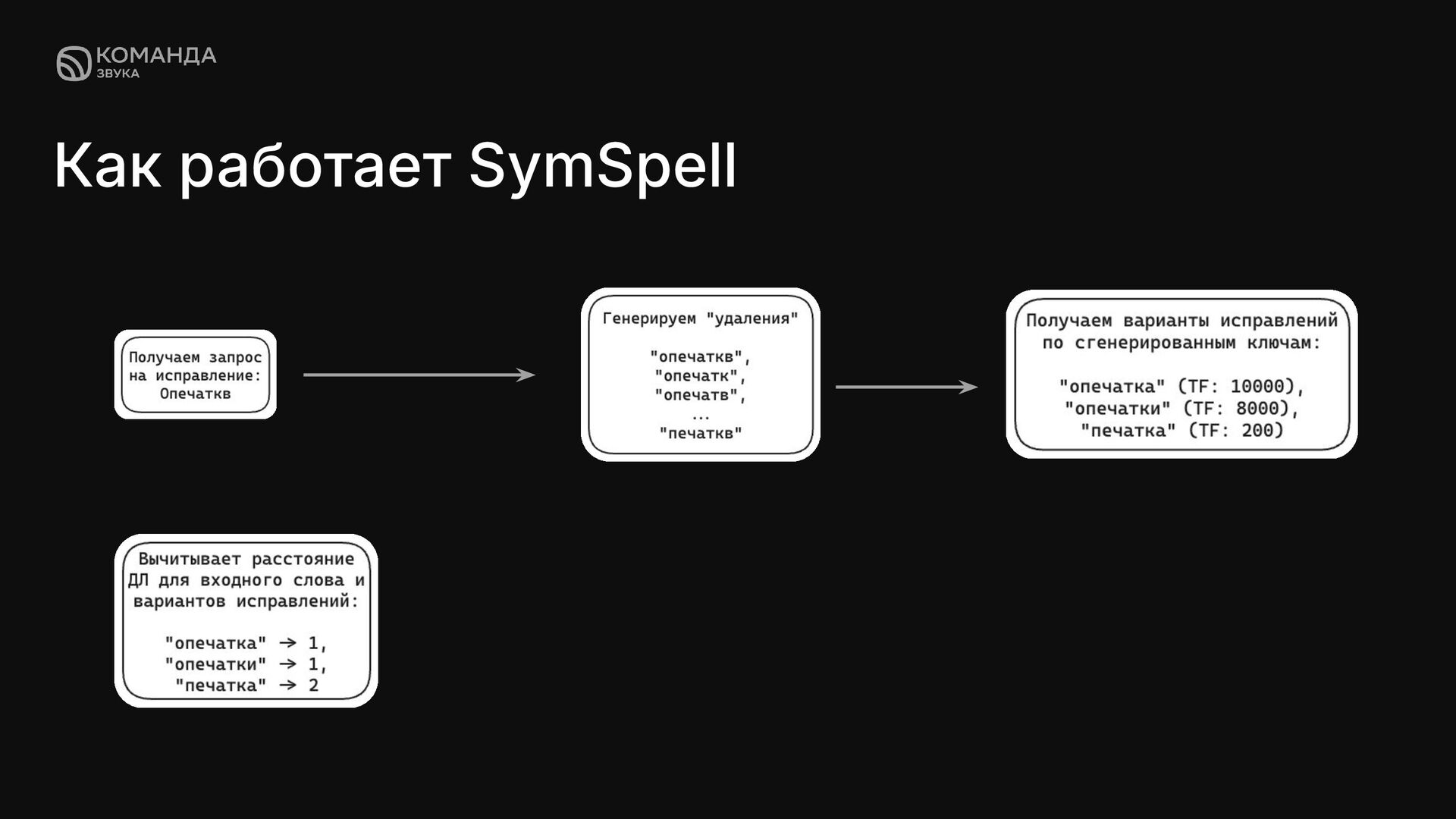
хранящаяся в Elasticsearch Терм отдельное нормализованное слово из текста Корпус совокупность текстовых данных Расстояние Дамерау- Левенштейна это мера разницы двух строк символов, определяемая как минимальное количество операций вставки, удаления, замены и транспозиции (перестановки двух соседних символов), необходимых для перевода одной строки в другую.
хранящаяся в Elasticsearch Терм отдельное нормализованное слово из текста Корпус совокупность текстовых данных Расстояние Дамерау- Левенштейна это мера разницы двух строк символов, определяемая как минимальное количество операций вставки, удаления, замены и транспозиции (перестановки двух соседних символов), необходимых для перевода одной строки в другую. TFIDF (term frequency, - inverse document frequency) статистическая мера, используемая для оценки важности слова в контексте документа), являющегося частью коллекции документов или корпуса). Вес некоторого слова пропорционален частоте употребления этого слова в документе и обратно пропорционален частоте употребления слова во всех документах коллекции.
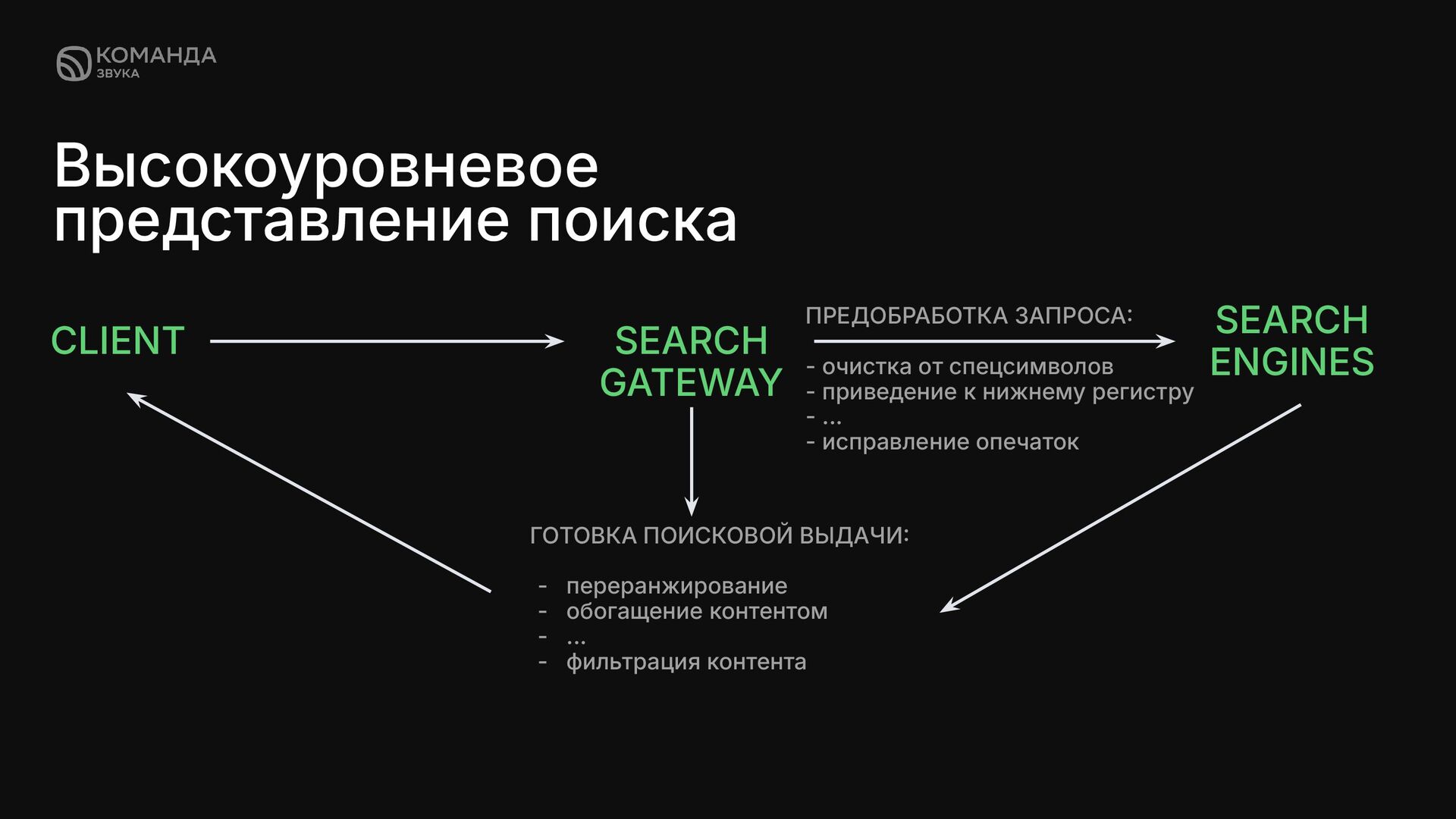
02 Должна учитывать корпус домена Должна легко масштабироваться, обеспечивать высокую пропускную способность Итеративное обновление справочника, коррекция исходя из “трендовˮ 03 04
запроса. Для генерация вариантов исправления ES использует TFIDF индекс для нахождения наиболее близкого терма. Плюсы: ✦ Функционал встроен в Elasticsearch, не требуется использовать дополнительные инструменты ✦ Упрощается актуализация данных т.к. уже выстроены процессы индексации нового контента Минусы: ✦ Сложно учитывать пользовательские сигналы (популярные опечатки, изменение трендов) ✦ Медленная работа - 100ms на датасете названий треков
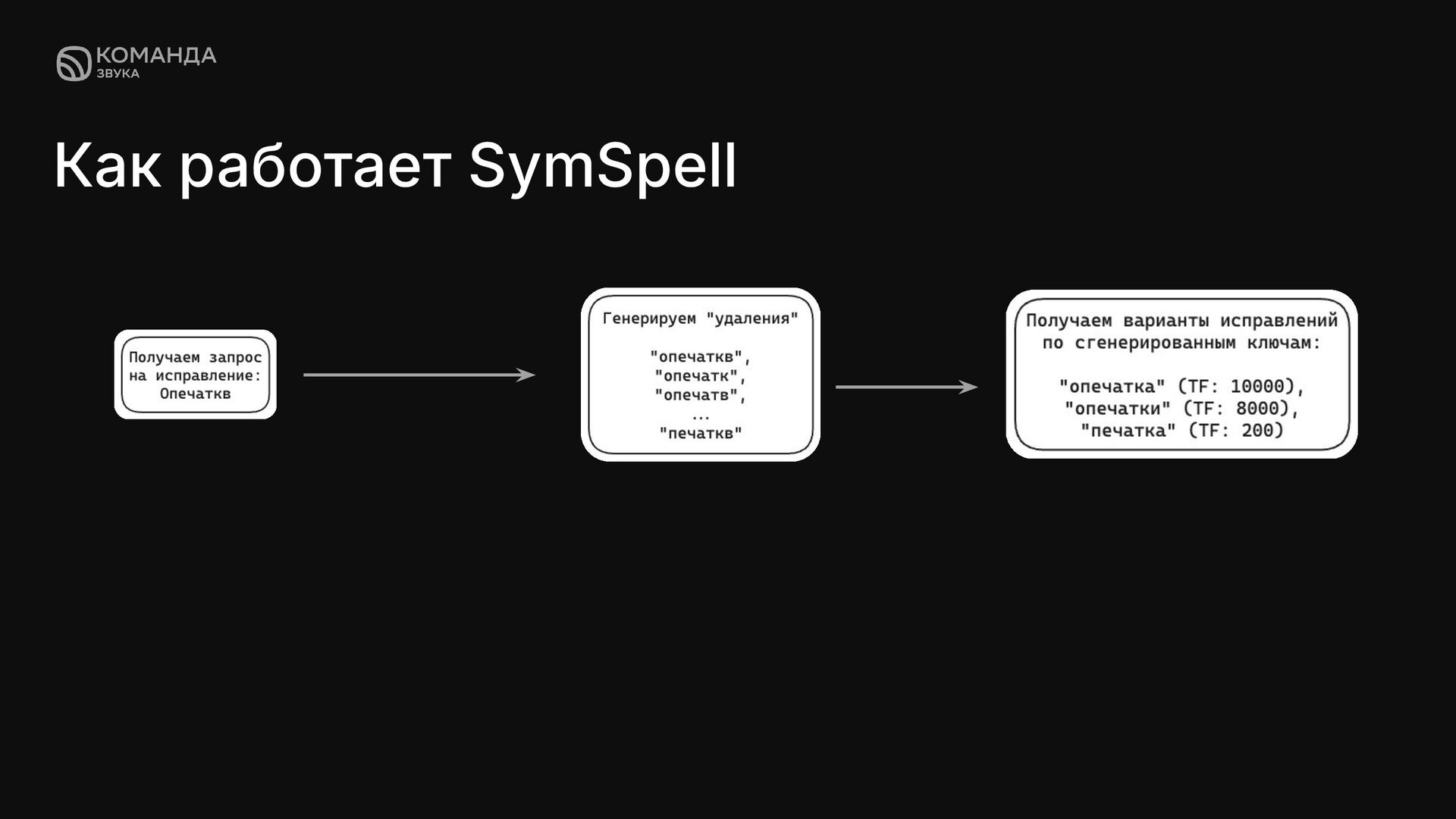
с предварительно рассчитанными возможными исправлениями. Она использует словарь с частотностью слов и позволяет очень быстро находить исправления благодаря заранее построенной структуре данных. Плюсы: ✦ Самая быстрая генерация вариантов исправления из существующих инструментов 1ms при расстоянии Дамерау — Левенштейна = 1 ✦ Не зависит от языка текста запроса ✦ Есть возможность использовать свой датасет Минусы: ✦ Необходимо собирать и постоянно обновлять датасет для оптимальной работы алгоритма
реализацию алгоритма SymSpell совместно с языковой моделью. Исправления учитывают контекст. Существуют биндинги к большинству популярных языков программирования. Плюсы: ✦ Высокое качество исправления с учетом лингвистических особенностей Минусы: ✦ Невозможно итеративное дообучение модели ✦ Для наиболее качественного исправления нужны модели для каждого языка отдельно
✦ Позволяет формировать справочник данными нашего домена ✦ Можем итеративно модифицировать справочник ✦ Высокая гибкость, можем применять любые инструменты “вокругˮ алгоритма Минусы: ✦ Не учитывает контекст предложения, надо что-то придумывать и достраивать ✦ Нет готовой библиотеки, которая поддерживает абстрактное хранилище для справочника
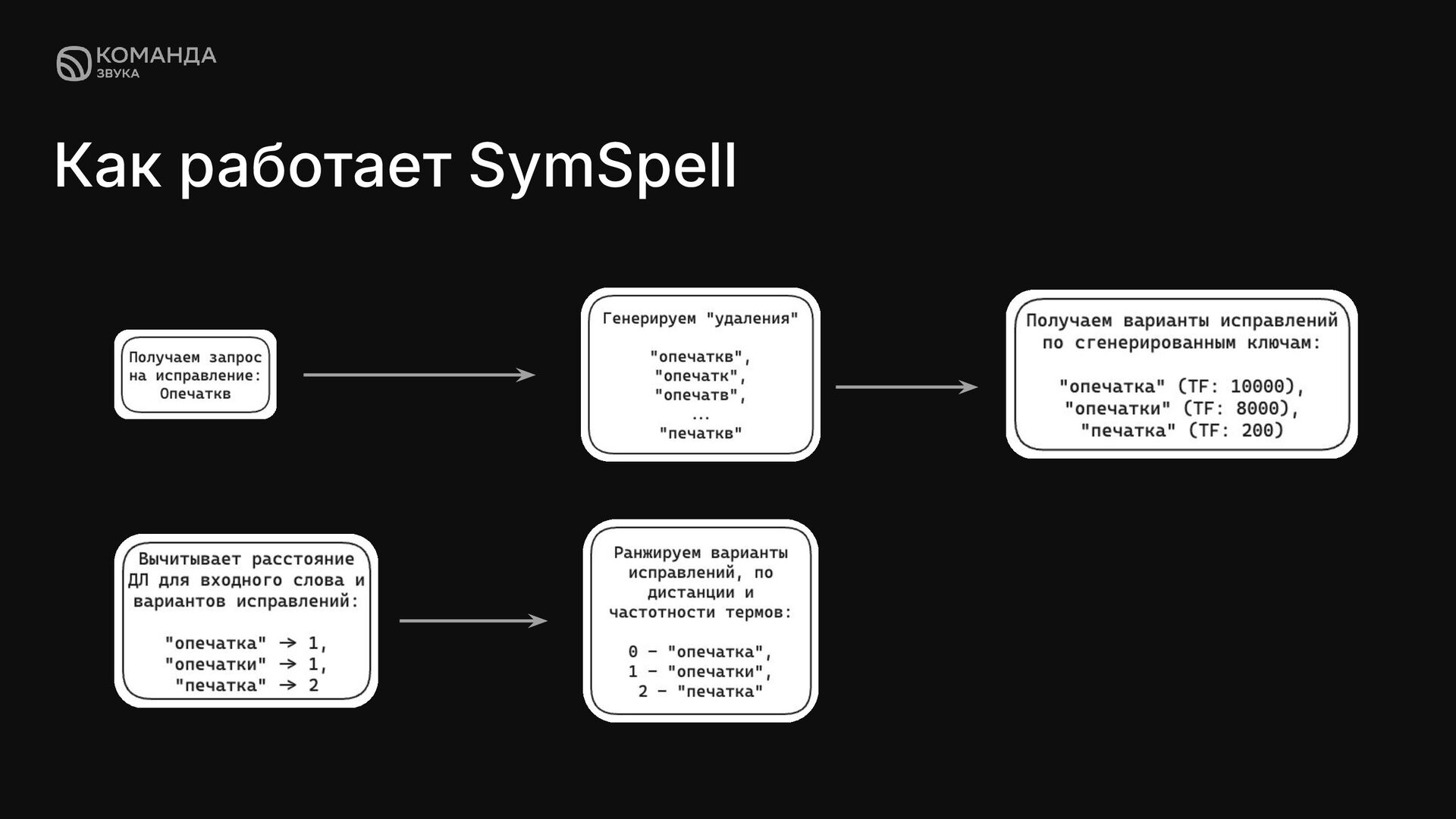
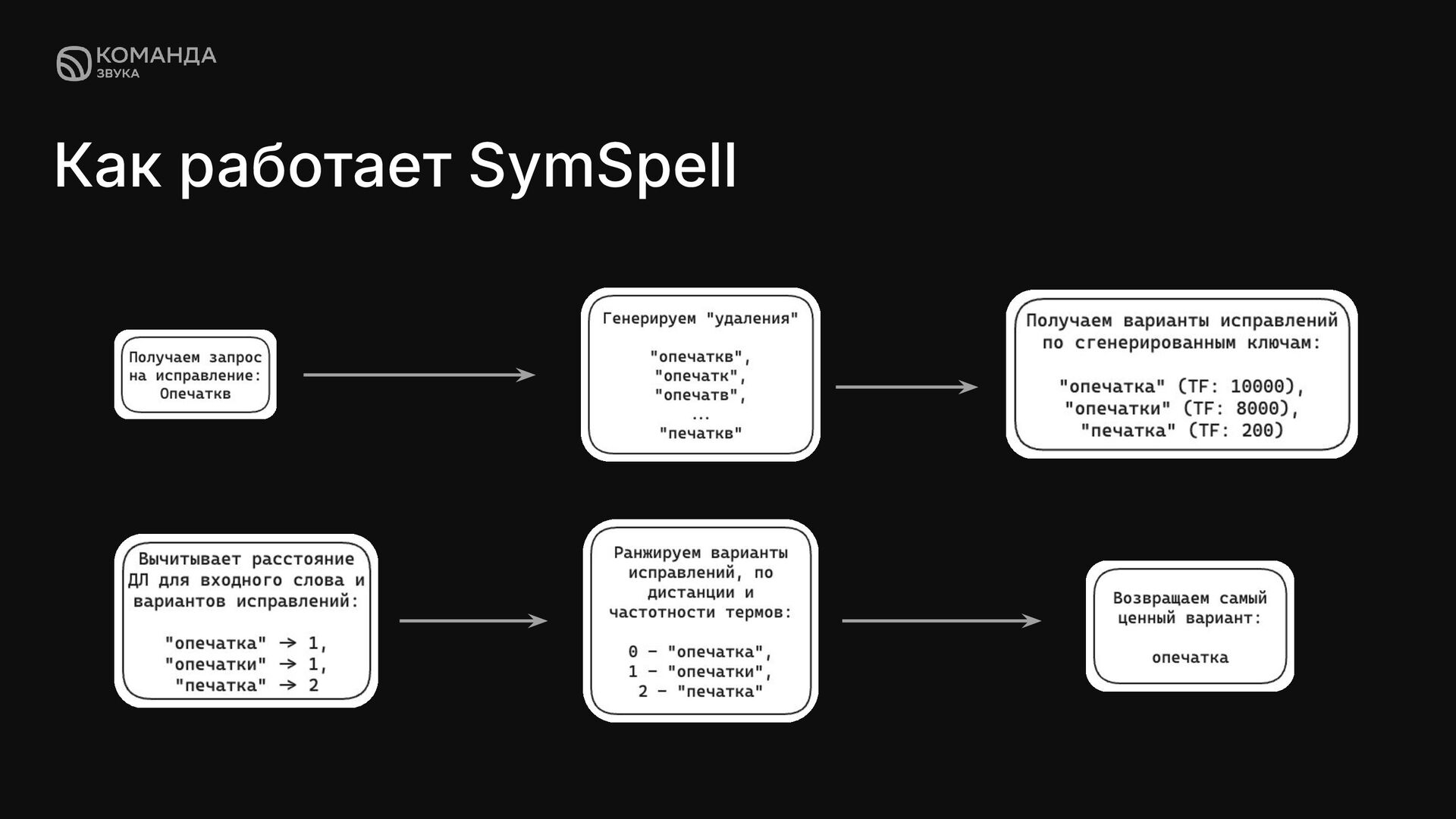
суть в том, что для каждого слова в корпусе вычисляются все варианты, полученные удалением до заданного количества символов (например, при одной или двух ошибках). А для быстрого поиска вариантов исправлений, используется HashMap.
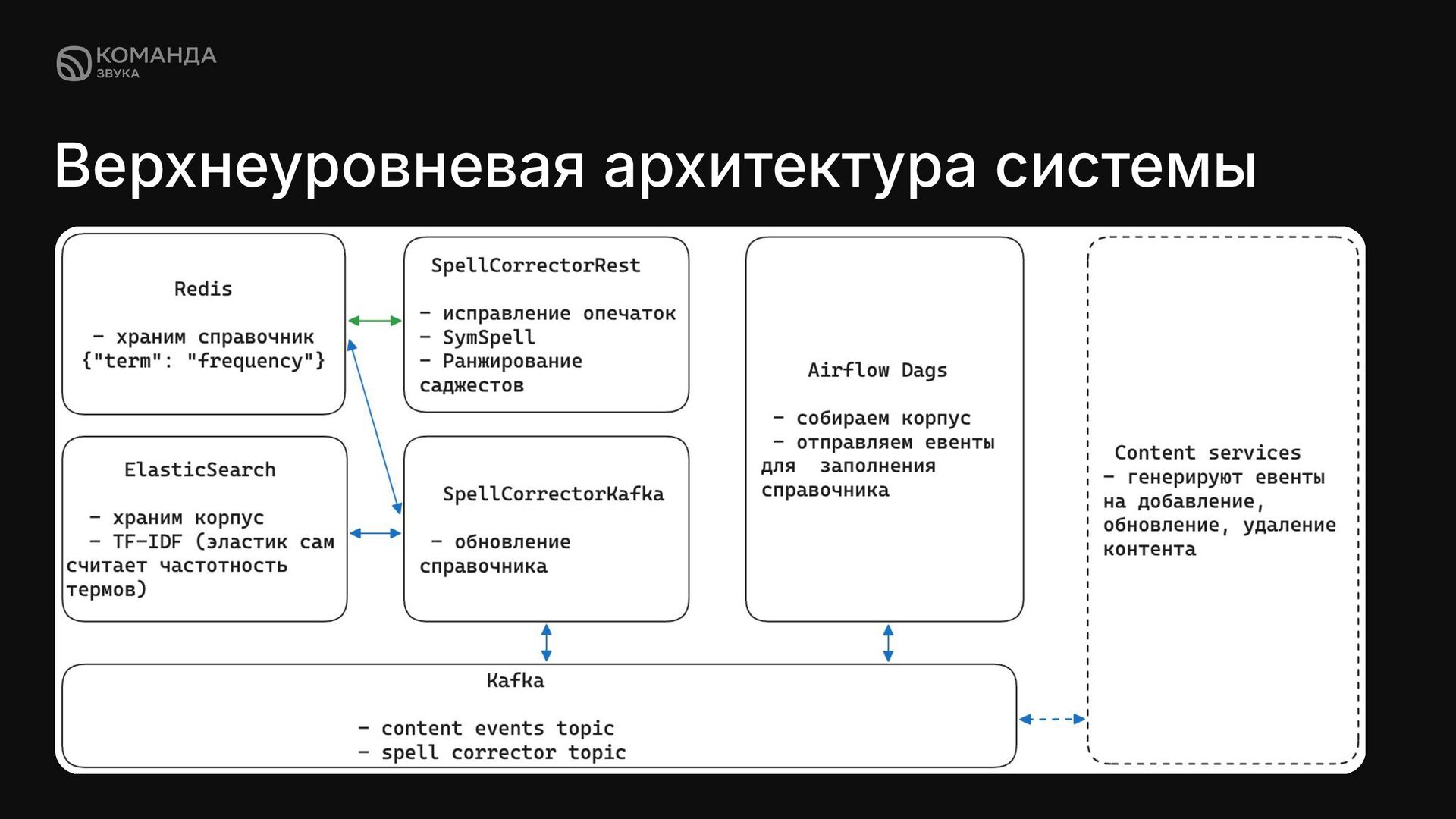
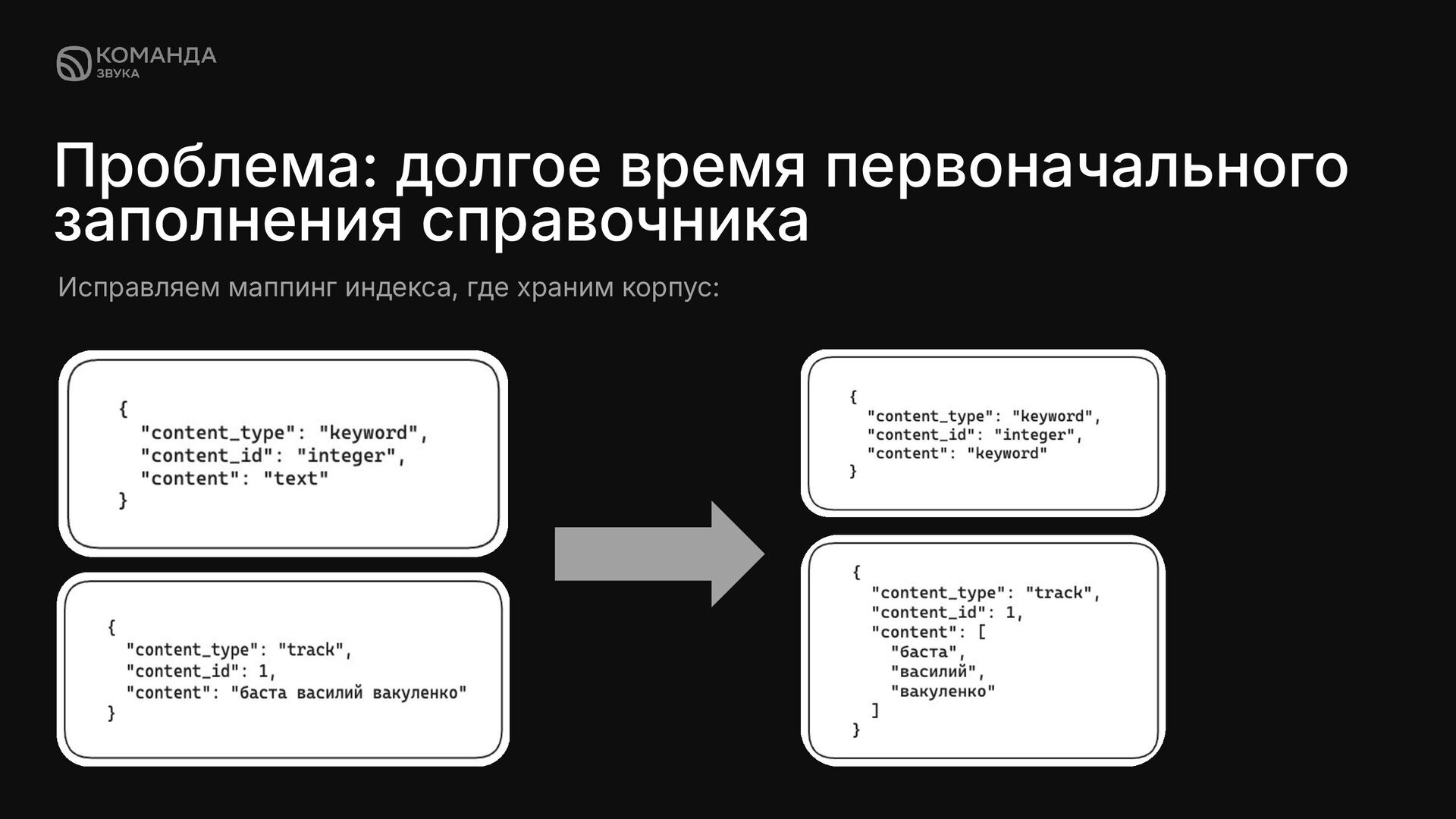
в кафку только по уникальным словам. ✦ Тем самым уменьшить объем сообщений в десятки раз. ✦ Получаем выигрыш c 3 дней до 7 часов долгое время первоначального заполнения справочника Тело запроса: Тело ответа:
в кафку только по уникальным словам. ✦ Тем самым уменьшить объем сообщений в десятки раз. ✦ Получаем выигрыш c 3 дней до 7 часов долгое время первоначального заполнения справочника Тело запроса: Тело ответа:
из ключа ✦ Делаем фильтрацию термов по frequency при добавлении новых слов в словарь, не добавляем редко встречаемые Проблема: слишком большой справочник
из ключа ✦ Делаем фильтрацию термов по frequency при добавлении новых слов в словарь, не добавляем редко встречаемые с 110кк → 33кк записей с 12 гб → 2.7 гб ОЗУ Результатом словарь “худеетˮ: Проблема: слишком большой справочник
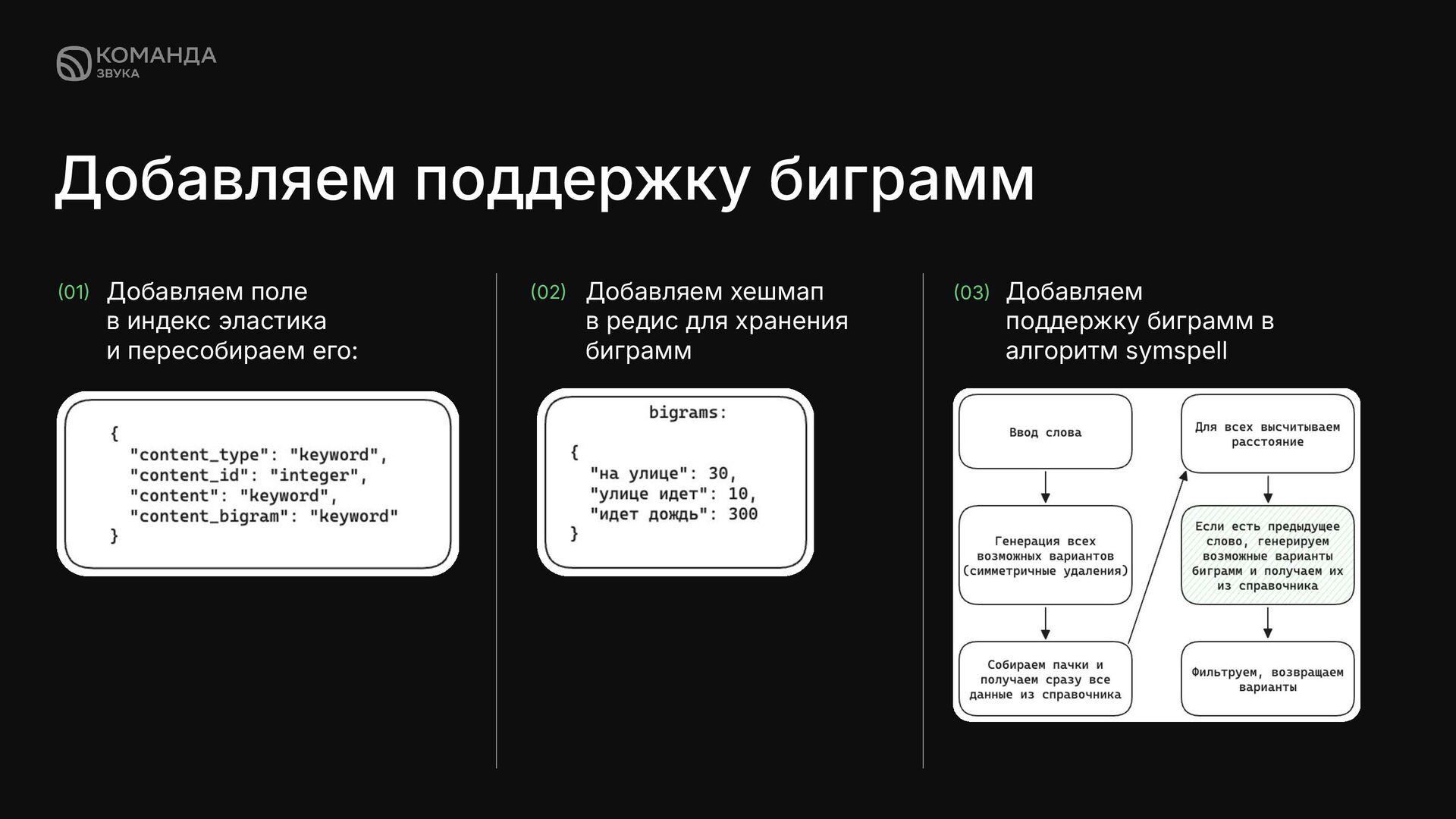
контекст. Одно слово исправляем нормально, предложения из 2+ слов - плохо ✦ Слишком много мусора в корпусе, есть слова с ошибками Решения ✦ Дешевый способ учета контекста — добавить биграммы в алгоритм ✦ Не учитывать низкочастотные термы при добавлении ✦ поменять алгоритм ранжирования, не просто сортировать по расстоянию и частоте, а ранжировать на основе формулы с нормализацией и весами
элементов (слов, символов или других единиц) в тексте. Биграммы, частный случай н-грамм, последовательности из двух подряд идущих слов - помогают уловить взаимосвязи между парами последовательных слов. Примеры биграмм для предожения “На улице идет дождьˮ: ✦ на улице ✦ улице идет ✦ идет дождь
для кандидата c fb(c) — показатель частотности биграммы для кандидата c max(ft) — максимальная частотность терма среди всех кандидатов max(fb) — максимальная частотность биграммы среди всех кандидатов
для кандидата c fb(c) — показатель частотности биграммы для кандидата c d(c)— редакционное расстояние между вводимым словом и кандидатом c max(ft) — максимальная частотность терма среди всех кандидатов max(fb) — максимальная частотность биграммы среди всех кандидатов dmax — максимальное допустимое расстояние
для кандидата c fb(c) — показатель частотности биграммы для кандидата c d(c)— редакционное расстояние между вводимым словом и кандидатом c max(ft) — максимальная частотность терма среди всех кандидатов max(fb) — максимальная частотность биграммы среди всех кандидатов dmax — максимальное допустимое расстояние wt, wb, wd — веса для компонентов
над следующими вариантами улучшений и производить еще несколько итераций доработок. Возможные точки расширения: ✦ добавление компоненты популярность в ранжировании ✦ Сделать кастомную функцию расчета расстояния на базе расстояния между символами QWERTY клавиатур и/или фонетической близости (Soundex like) ✦ Полноценная ML для переранжирования (тут можно добавить учет дополнительных сигналов от пользователей), оставить symspell только для поднятия вариантов исправлений
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}