ABSTRACT:
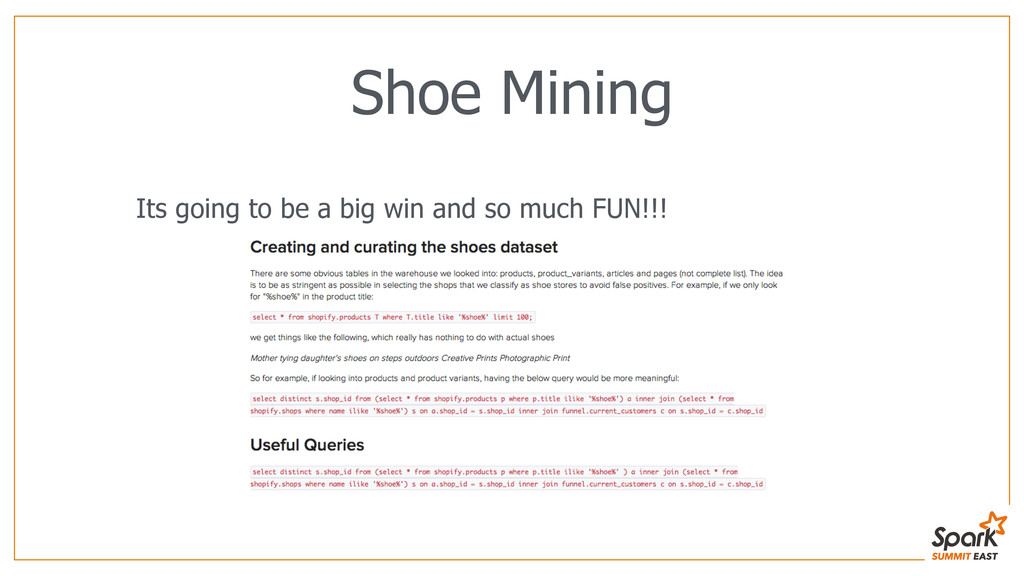
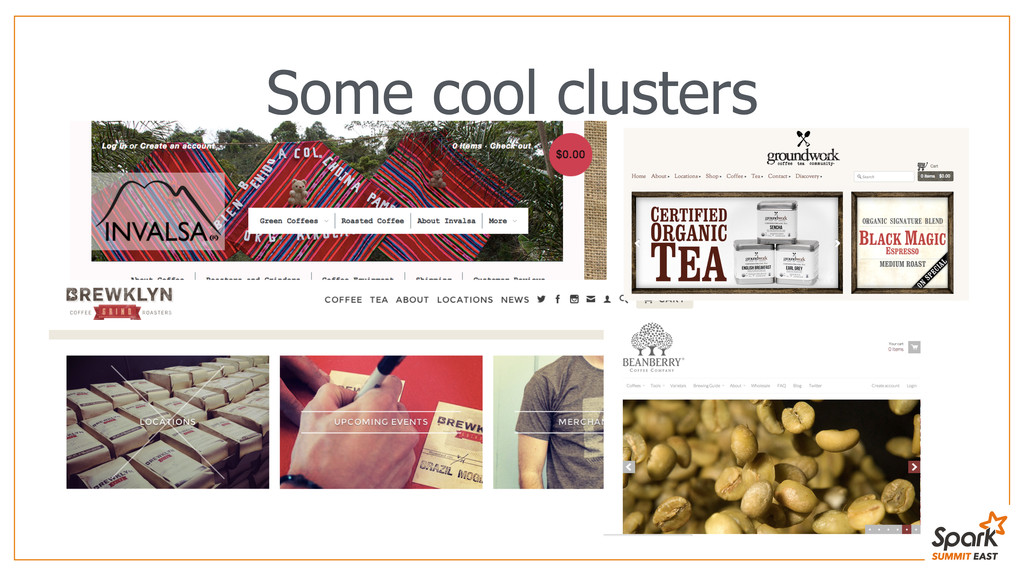
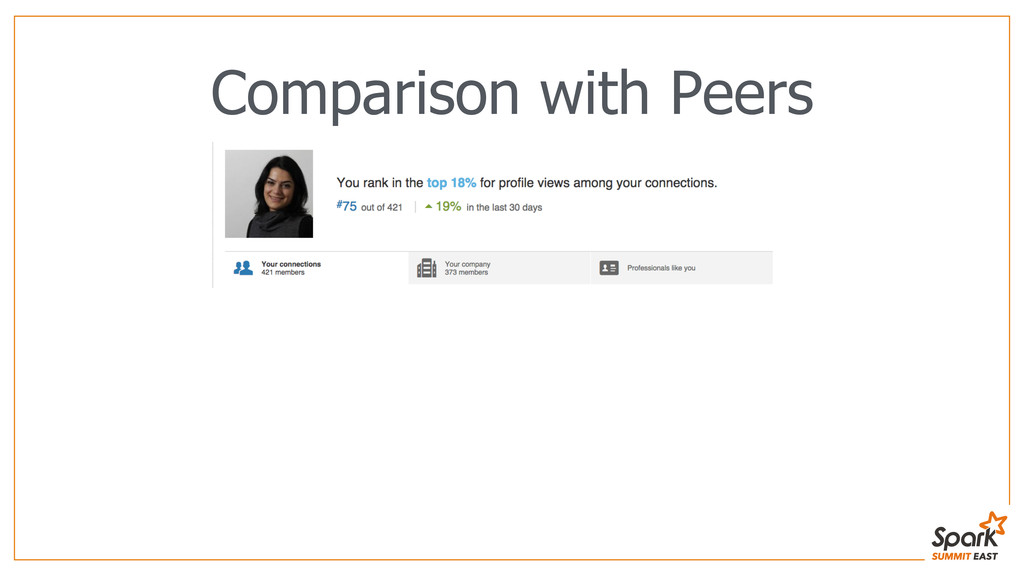
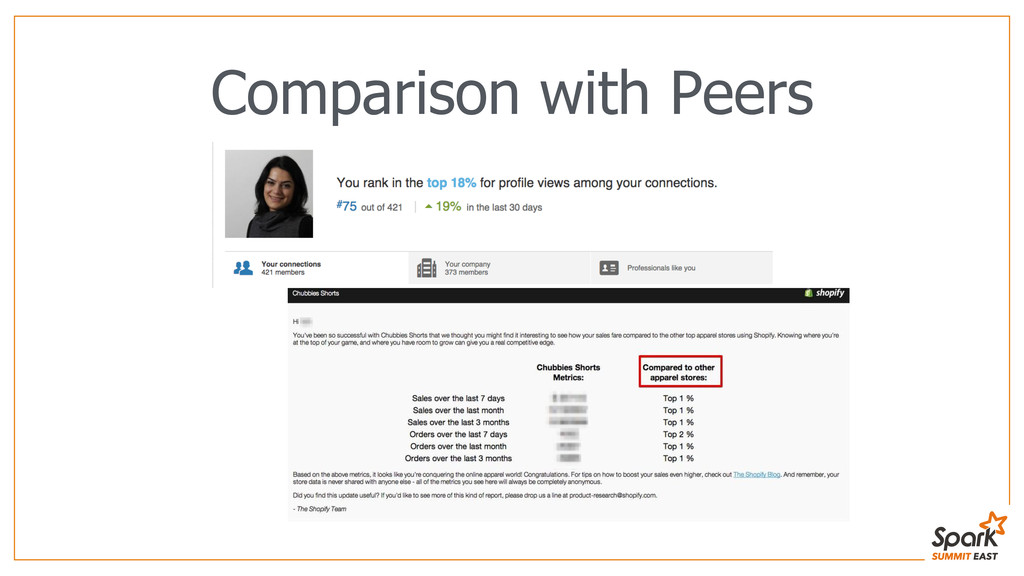
Shopify is the world’s fastest growing e-commerce platform with more than 120k active stores and surpassing $5,000,000,000 in Gross Merchandise Volume. At Shopify, we help emerging small businesses get off the ground and grow into successful companies. Individual businesses can sell a variety of products and services, both online and offline in a single store. The data team at Shopify provides business intelligence (BI) reporting as well as data-driven insights using machine learning and statistical analysis that go beyond BI reports to help merchants be more successful. I joined Shopify’s data team a year ago and what started as a personal project for me, finding stores that sell shoes, turned into a bigger problem: What types of products are sold by our stores? The question became critical when we needed to select eligible stores for a business partnership and our data warehouse kept timing out running data mining queries. During the same time we started using Spark technology and moved our operational data to HDFS. We were able to use the power of distributed computing to mine through millions of records of data: Spark was able to process 67 million records while I went to get a fresh cup of coffee. We were able to successfully categorize our stores based on their products and get the list of partnership-eligible stores. Later on, using Spark’s machine learning library, together with classification data obtained through Amazon’s Mechanical Turk, we were able to form clusters of similar stores and provide industry specific success metrics to them. The ease of use and accessibility of Spark has made me an avid fan and I’d like to share this data journey and the experience that exceeded my expectations.
BIO:
Solmaz is a data analyst at Shopify, providing data-driven insights to the world’s fastest growing e-commerce platform. With multiple graduate degrees in machine learning and computer science, she has employed her skills in cancer research, finance and e-commerce for the past 8 years. At Shopify she used Apache Spark to categorize more than 100k stores based on their products and provided industry specific success metrics to stores. She has a passion for building high quality data warehouses that ensure accuracy and agility of analysis. Prior to Shopify, she worked at Morgan Stanley as an analyst and a developer.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}