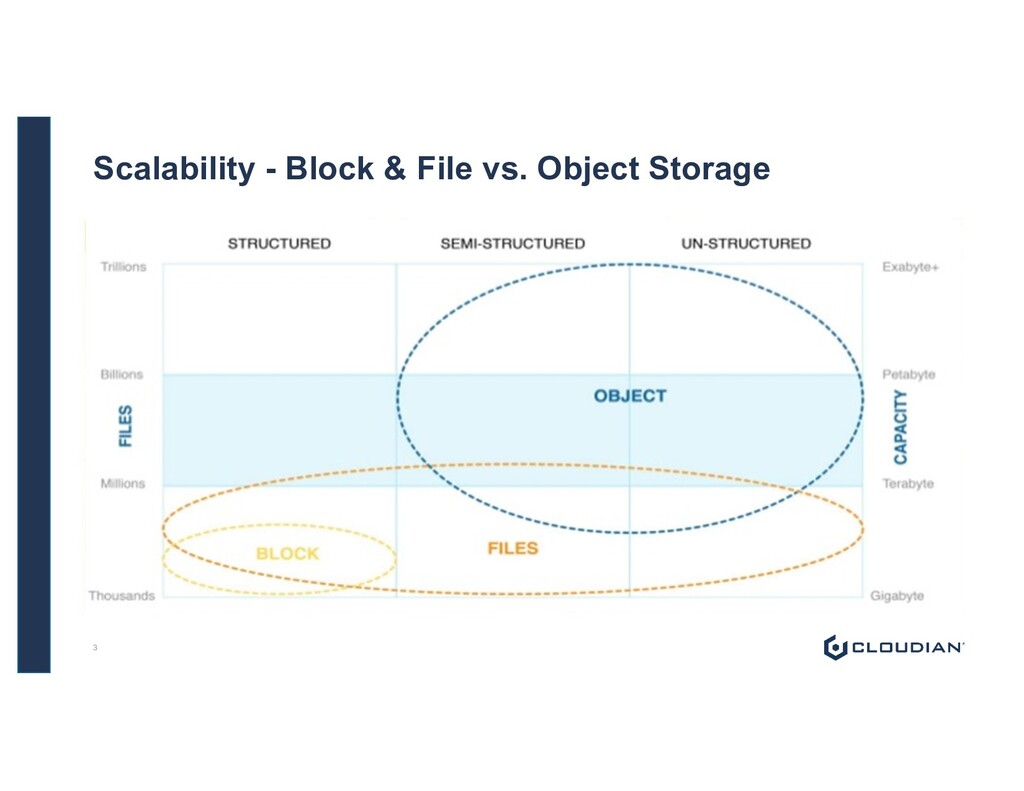
Scalability • Cost of storing and accessing data • Cost of managing storage infrastructure • Different way to access data with S3 API • Stores Metadata with data to facilitate intelligent data – do more with your data • Provides greater data protection capabilities • Provides single namespace regardless of geography • Maximises data availability 2
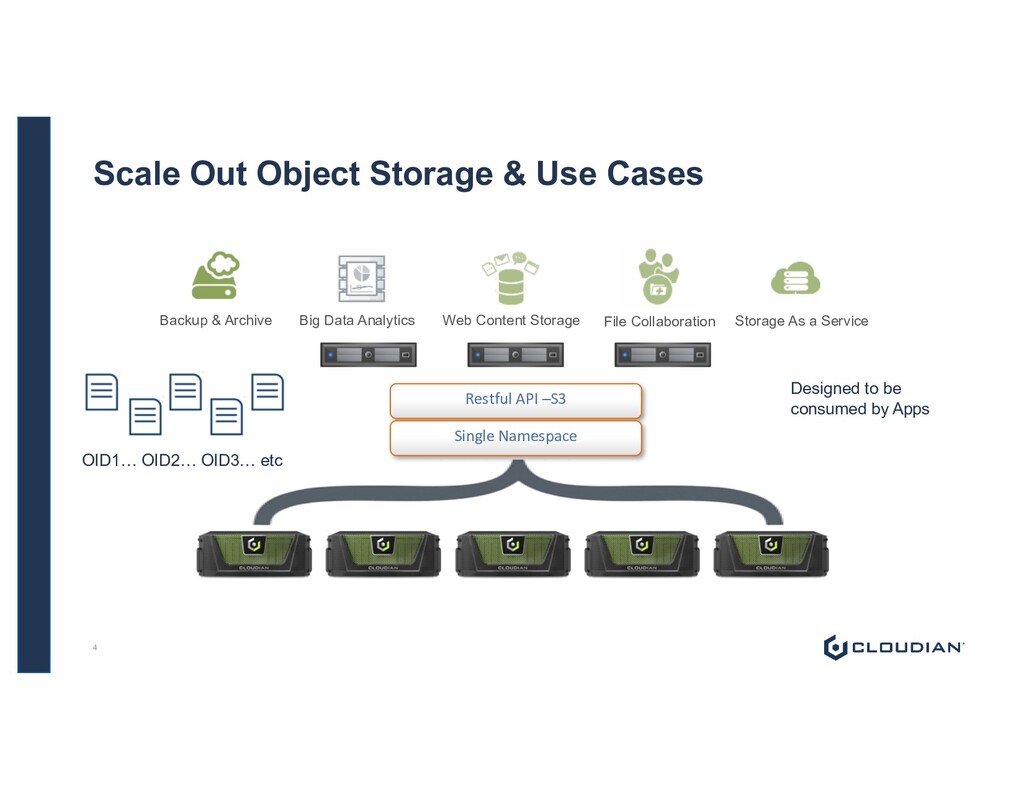
Single Namespace Backup & Archive Big Data Analytics File Collaboration Web Content Storage Storage As a Service 4 Designed to be consumed by Apps OID1… OID2… OID3… etc
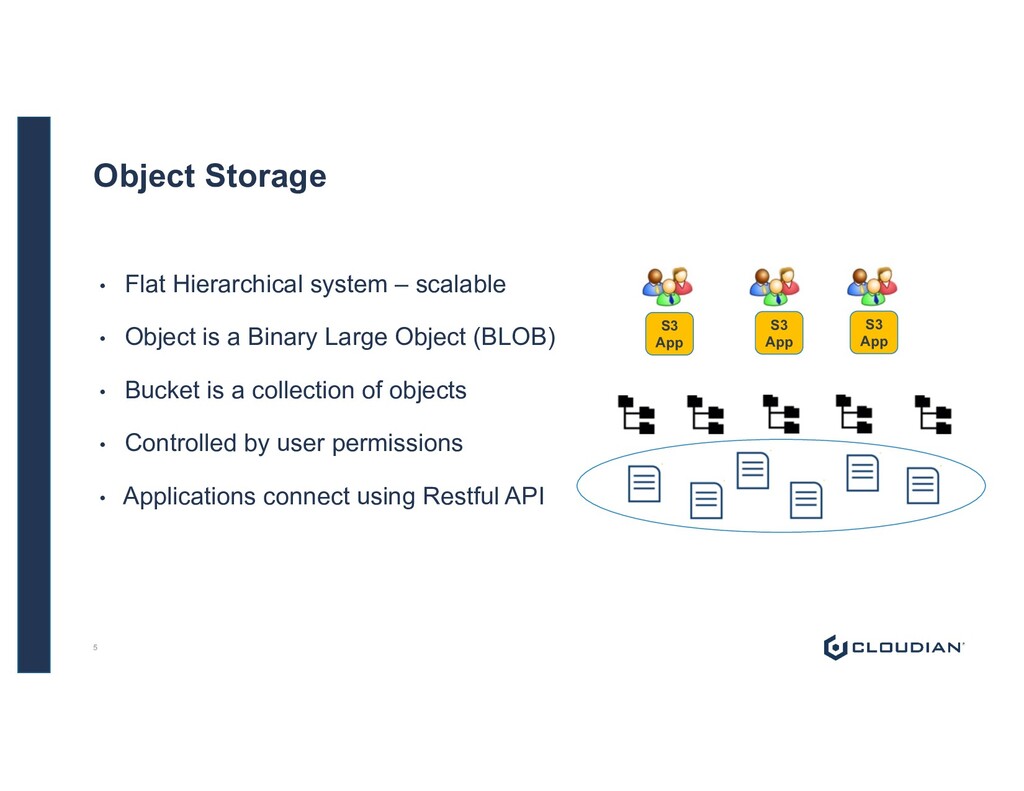
is a Binary Large Object (BLOB) • Bucket is a collection of objects • Controlled by user permissions • Applications connect using Restful API S3 App S3 App S3 App 5
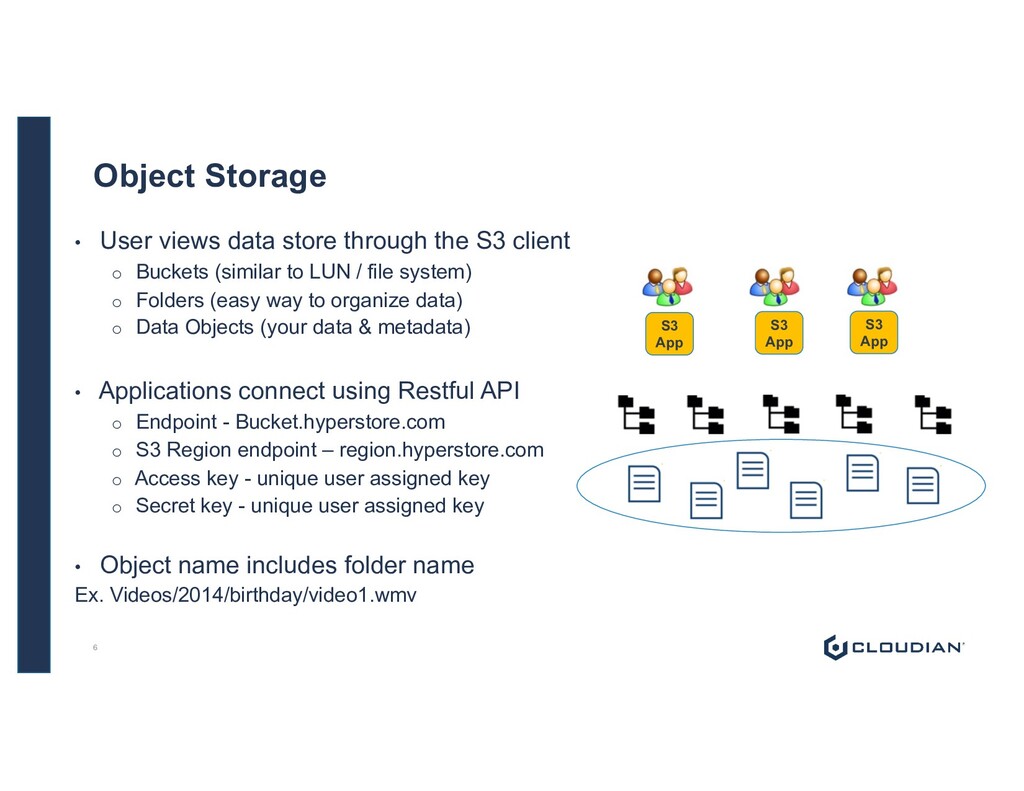
Buckets (similar to LUN / file system) o Folders (easy way to organize data) o Data Objects (your data & metadata) • Applications connect using Restful API o Endpoint - Bucket.hyperstore.com o S3 Region endpoint – region.hyperstore.com o Access key - unique user assigned key o Secret key - unique user assigned key • Object name includes folder name Ex. Videos/2014/birthday/video1.wmv 6 Object Storage S3 App S3 App S3 App
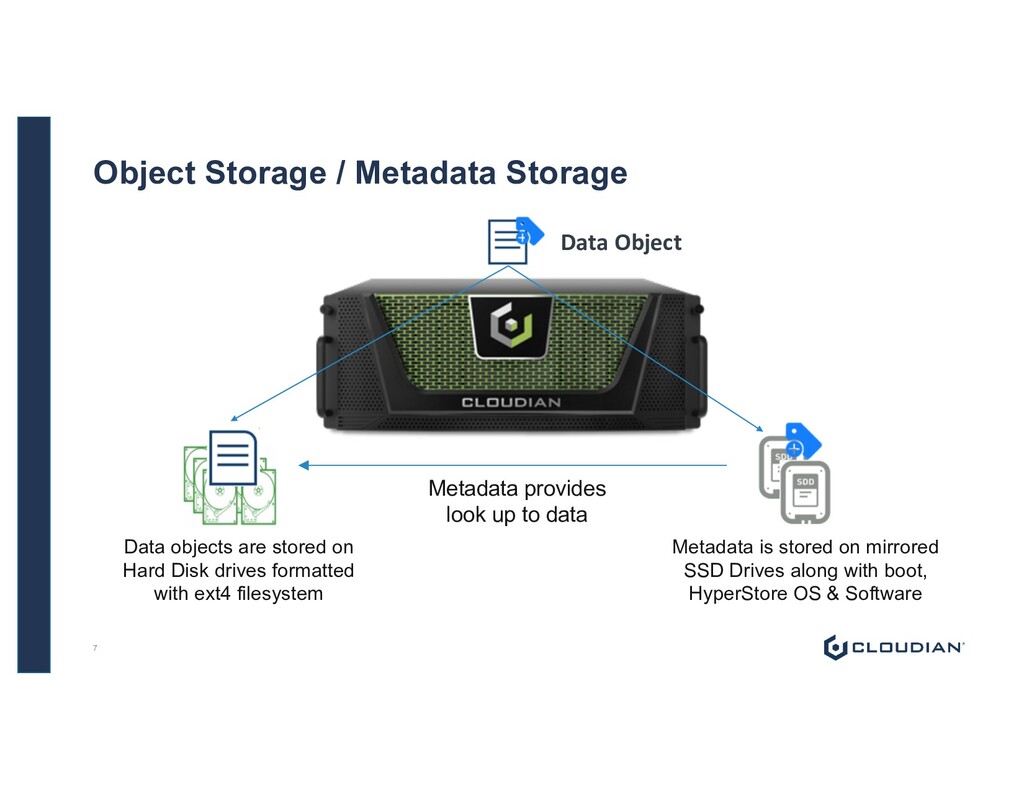
Hard Disk drives formatted with ext4 filesystem Metadata is stored on mirrored SSD Drives along with boot, HyperStore OS & Software Metadata provides look up to data Data Object 7
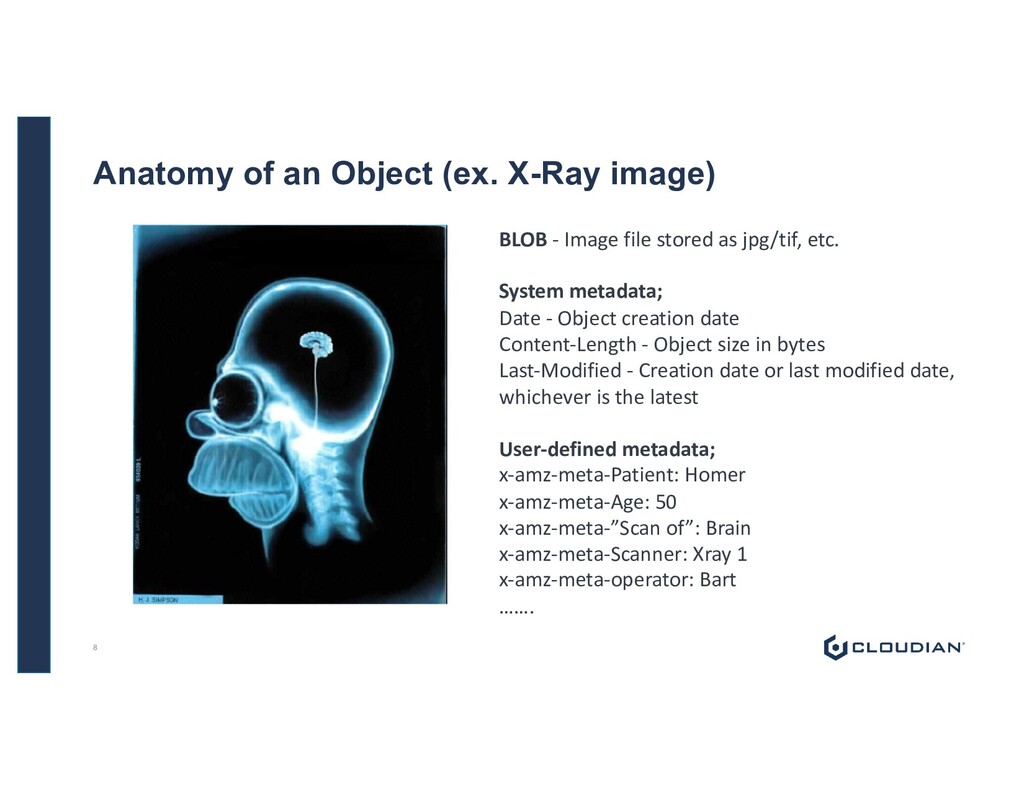
file stored as jpg/tif, etc. System metadata; Date - Object creation date Content-Length - Object size in bytes Last-Modified - Creation date or last modified date, whichever is the latest User-defined metadata; x-amz-meta-Patient: Homer x-amz-meta-Age: 50 x-amz-meta-”Scan of”: Brain x-amz-meta-Scanner: Xray 1 x-amz-meta-operator: Bart ……. 8
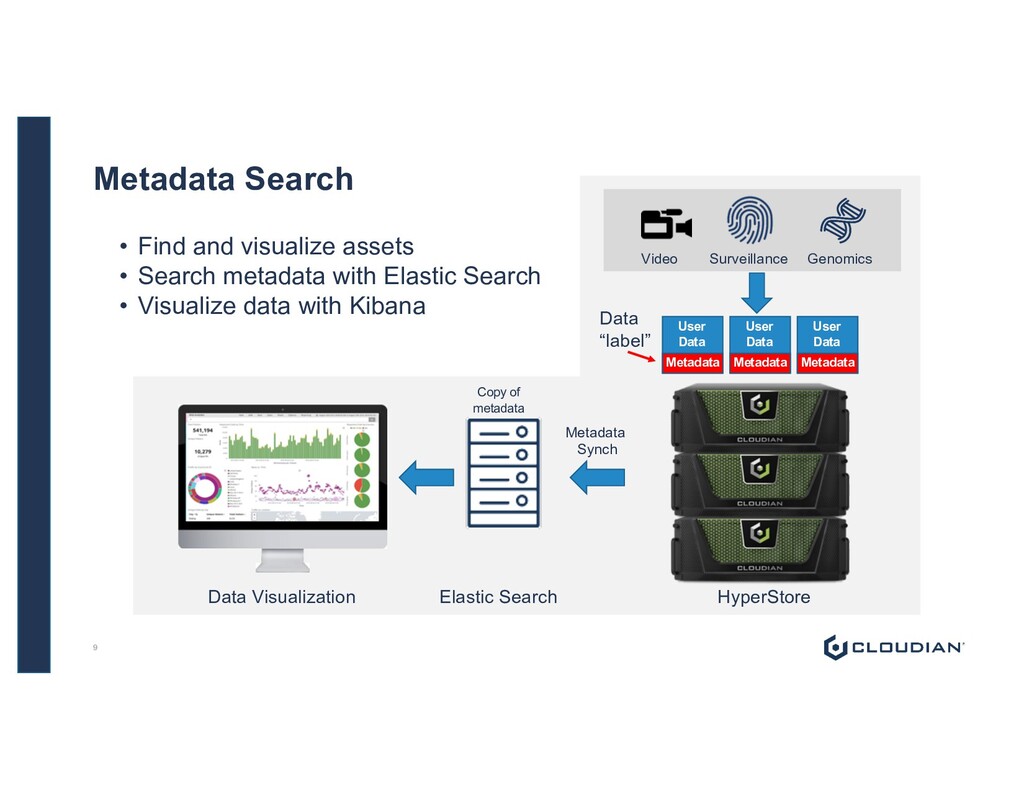
Data Metadata Metadata Synch Elastic Search Data Visualization • Find and visualize assets • Search metadata with Elastic Search • Visualize data with Kibana HyperStore Data “label” Copy of metadata Video Surveillance Genomics
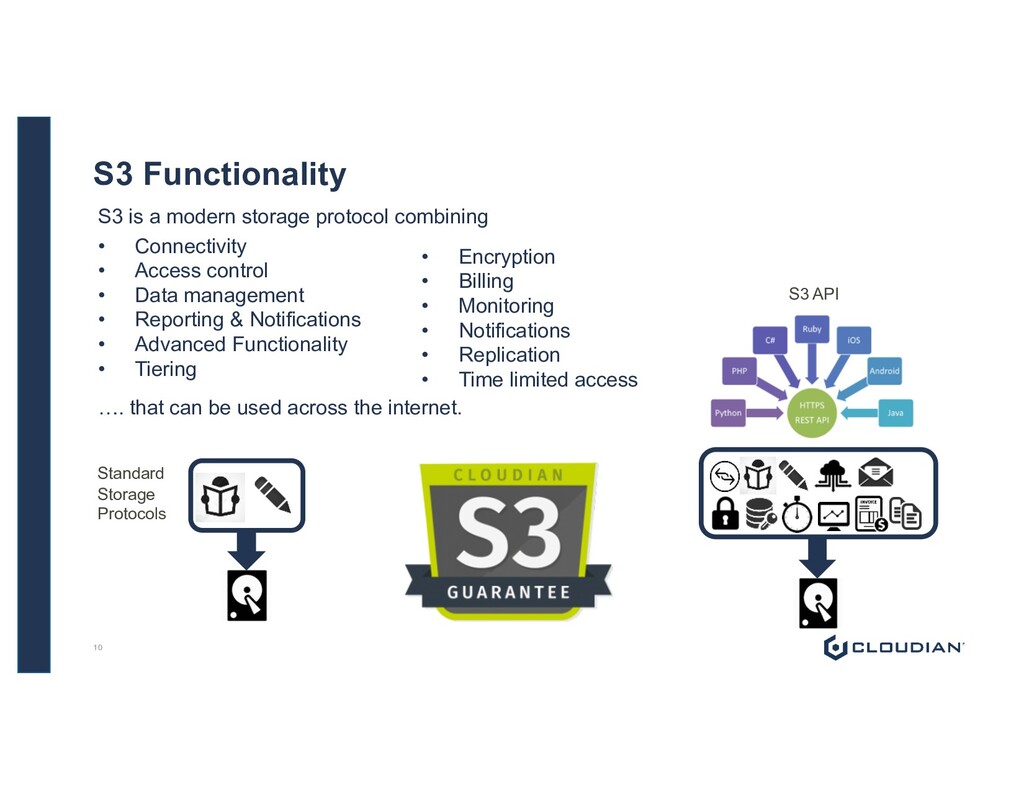
Connectivity • Access control • Data management • Reporting & Notifications • Advanced Functionality • Tiering • Encryption • Billing • Monitoring • Notifications • Replication • Time limited access …. that can be used across the internet. Standard Storage Protocols S3 API 10
at Amazon; world’s largest object storage environment 2. MSPs worldwide adopting S3 for cloud storage services 3. Hundreds of applications now support S3, many more in development S3 Compatibility = Investment Protection
More scalable Example: Multi-part upload Inherently interoperable & scalable architecture Gateway Architecture OBJECT PART 1 PART 2 PART 3 PART 4 PART n … Gateway Gateway Competition Bottleneck Native S3 API – Why It Matters Lost in Translation? OBJECT PART 1 PART 2 PART 3 PART 4 PART n … Native S3 Connect Load is distributed, no translation
Splunk deployments to meet your needs • Minimize data on local storage, while maintaining the fast indexing and search capabilities SmartStore • Decouples storage and compute layers • Elastically scale compute on-demand for search and indexing workloads • Grow storage independently to accommodate retention requirements • Cost savings with more flexible storage options How? • S3 support
is no longer tied to indexer hardware • Separation of storage and compute • Indexer failures is no longer tied to storage failures • Local storage is now simply a search cache • No longer need to size local storage • used to store - 90days, 6 months, 3 yrs etc • Just need enough local storage for search (1- 7 days)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}