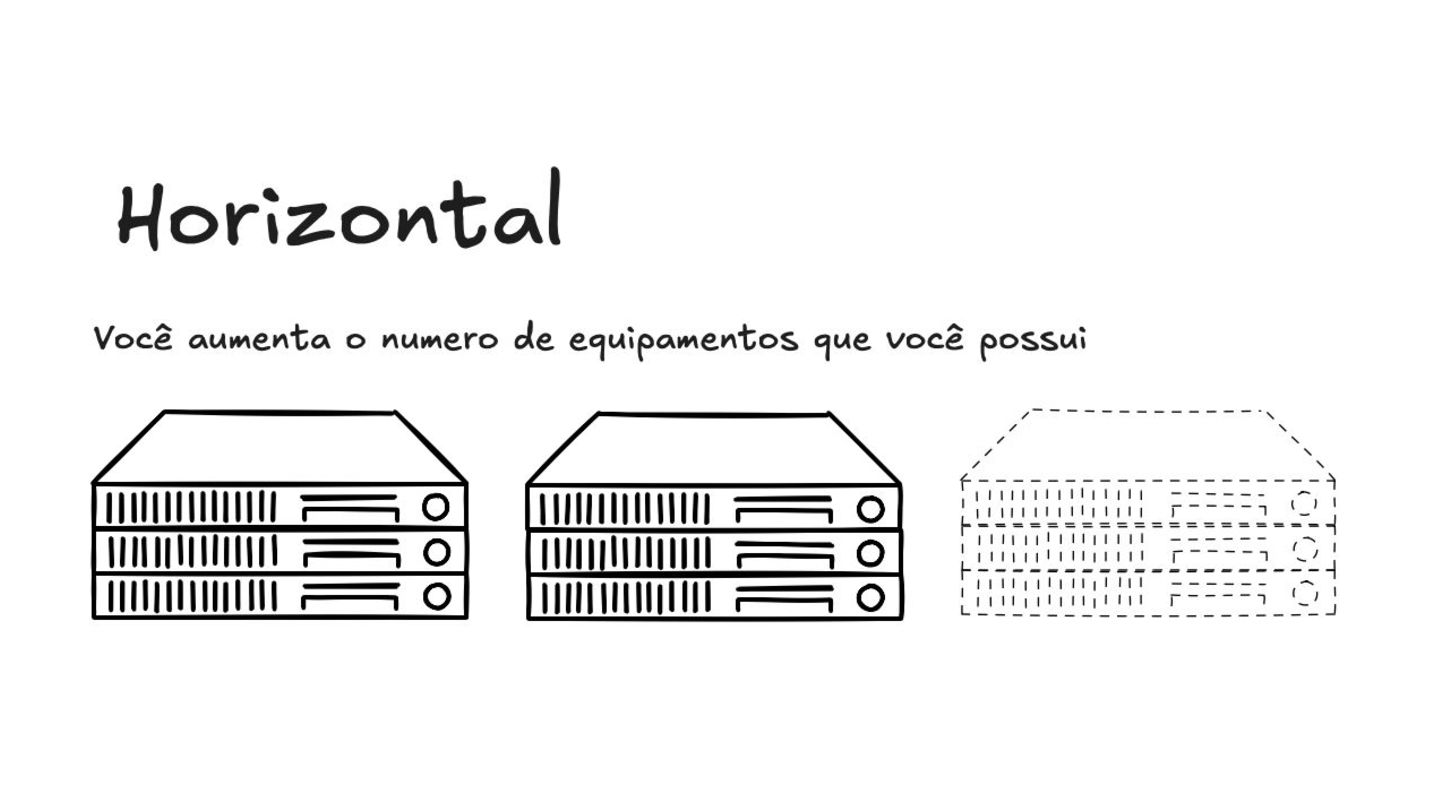
Na minha palestra, apresentada na SoftWeek 2025 e na PHPeste 2025, eu abordo a realidade de que sistemas de software falham e como podemos projetá-los para serem resilientes. Comecei a conversa falando sobre como a complexidade da infraestrutura aumenta os pontos de falha.
A partir daí, eu mergulho em três padrões de design essenciais para lidar com a instabilidade de sistemas distribuídos:
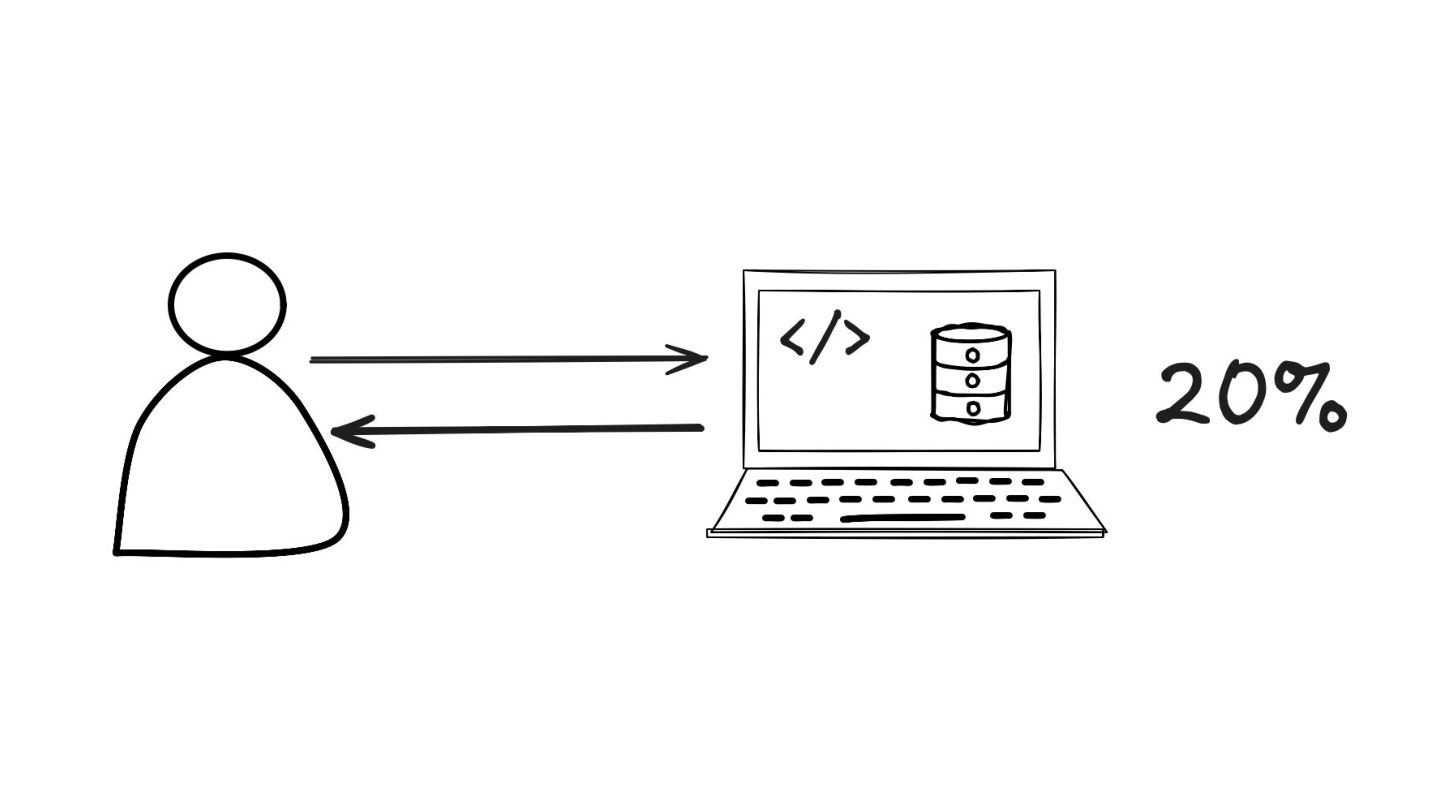
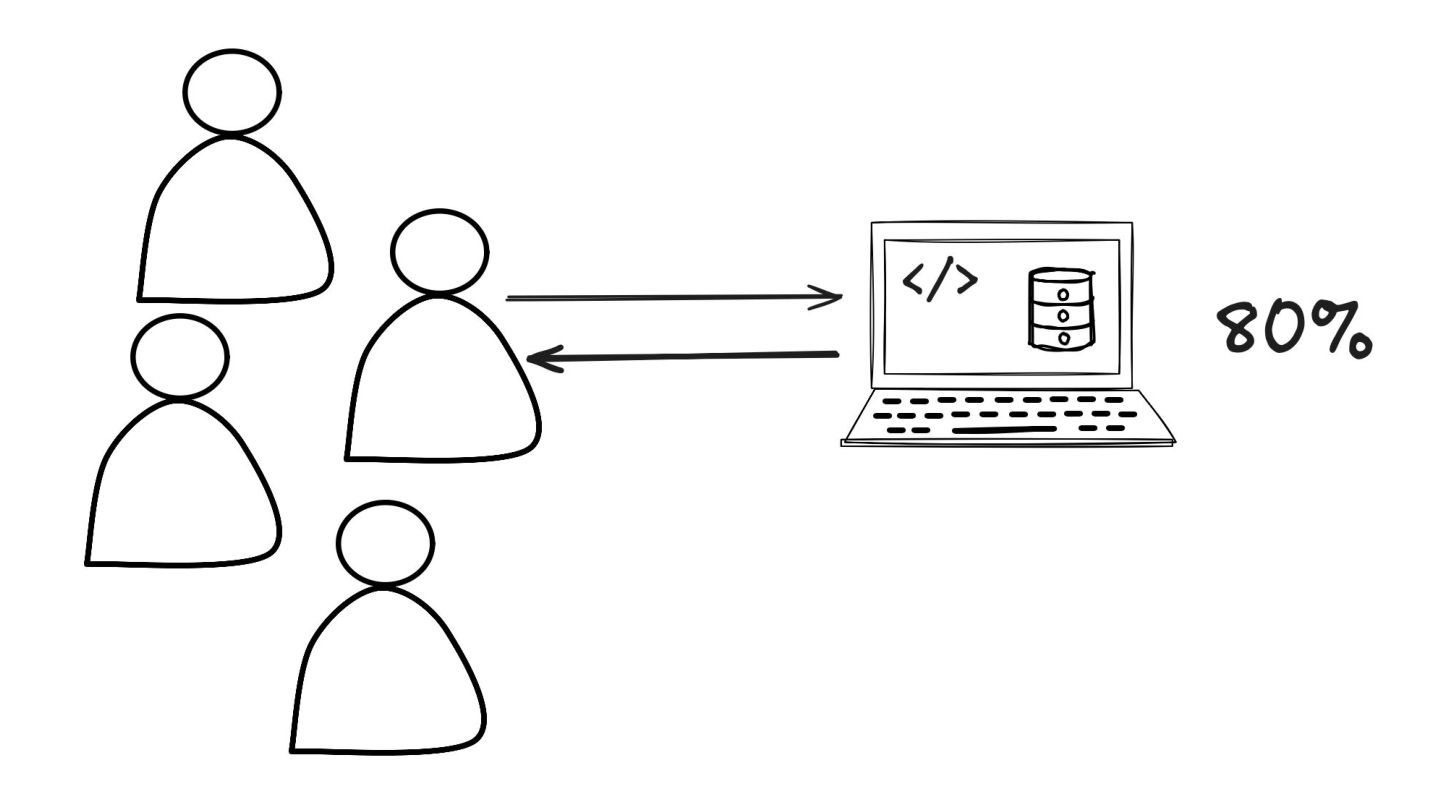
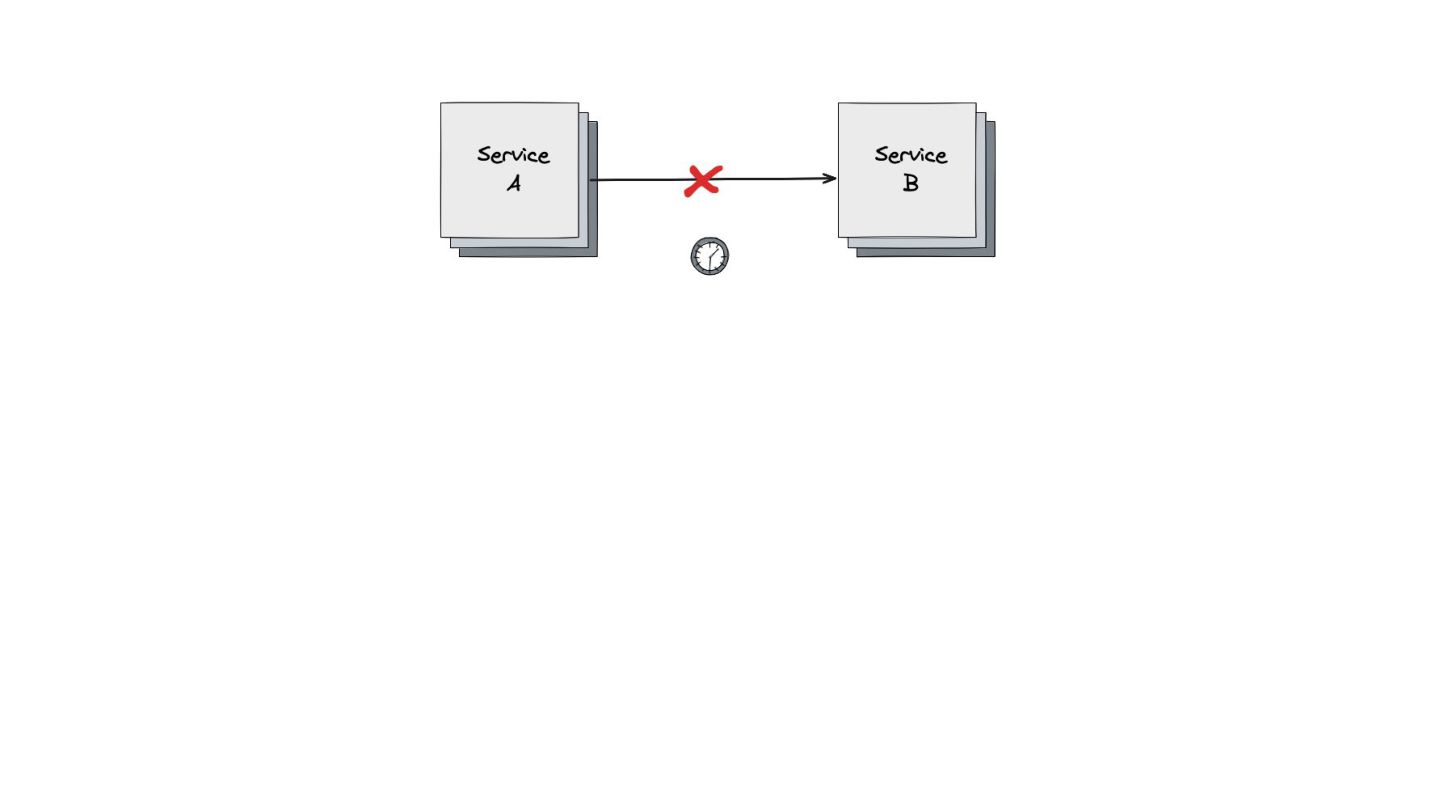
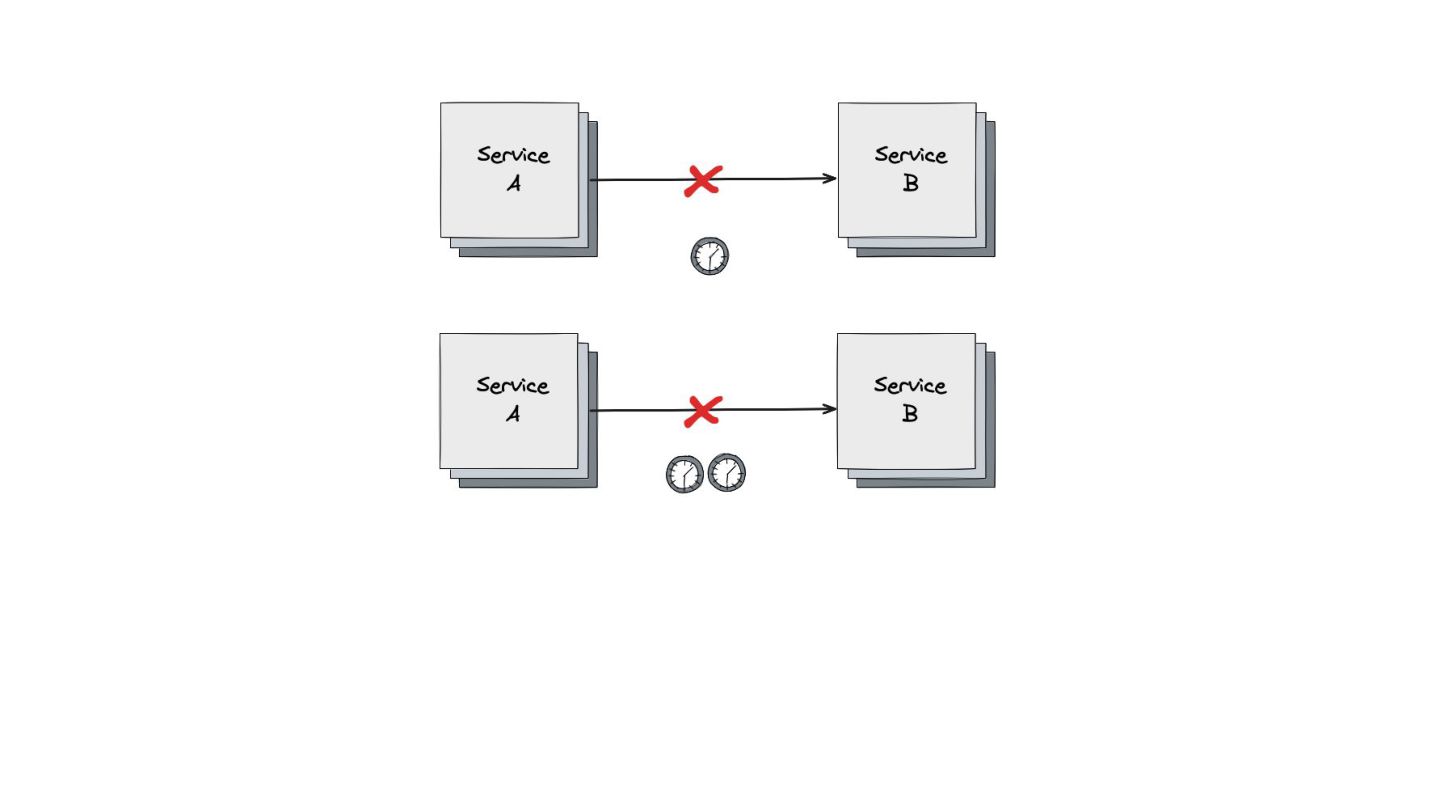
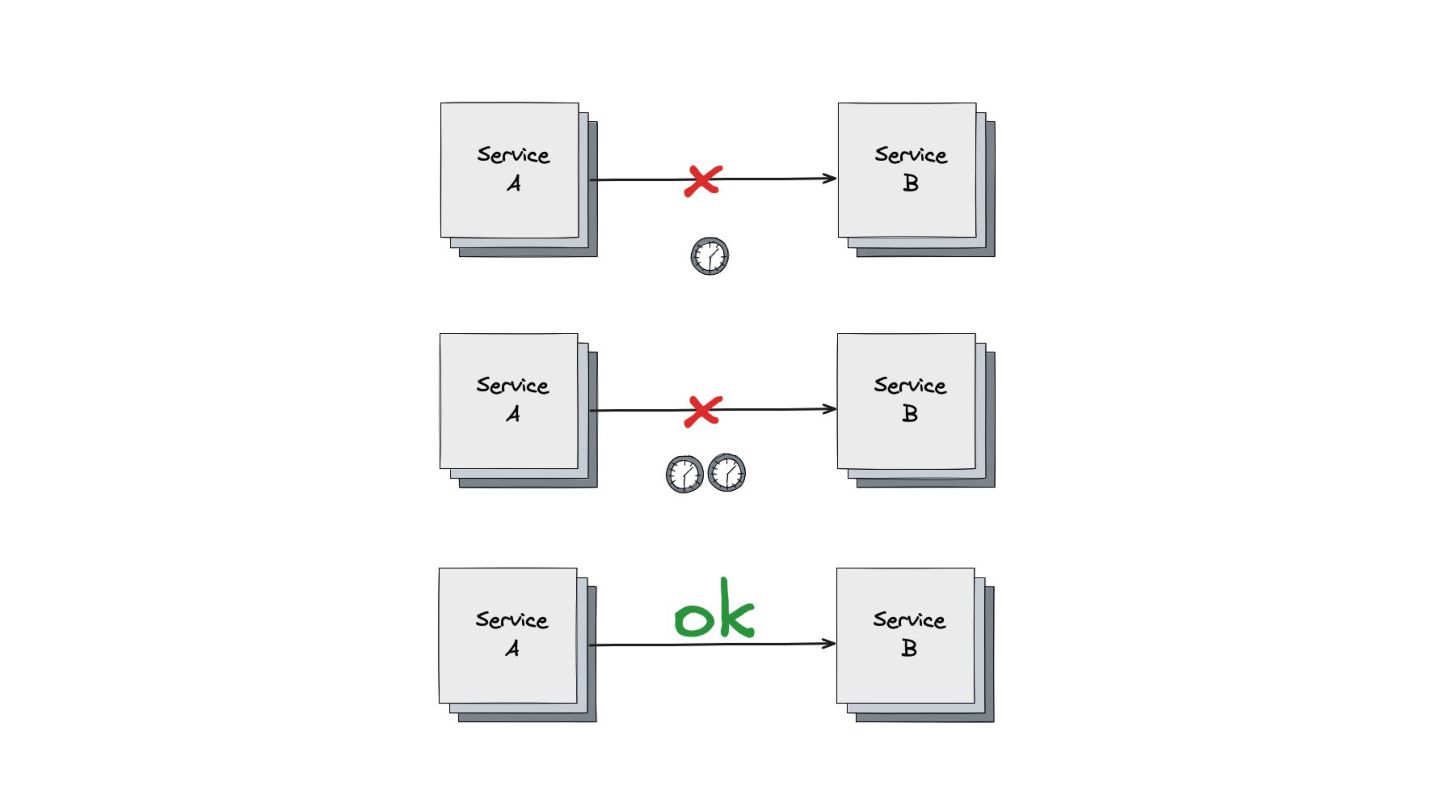
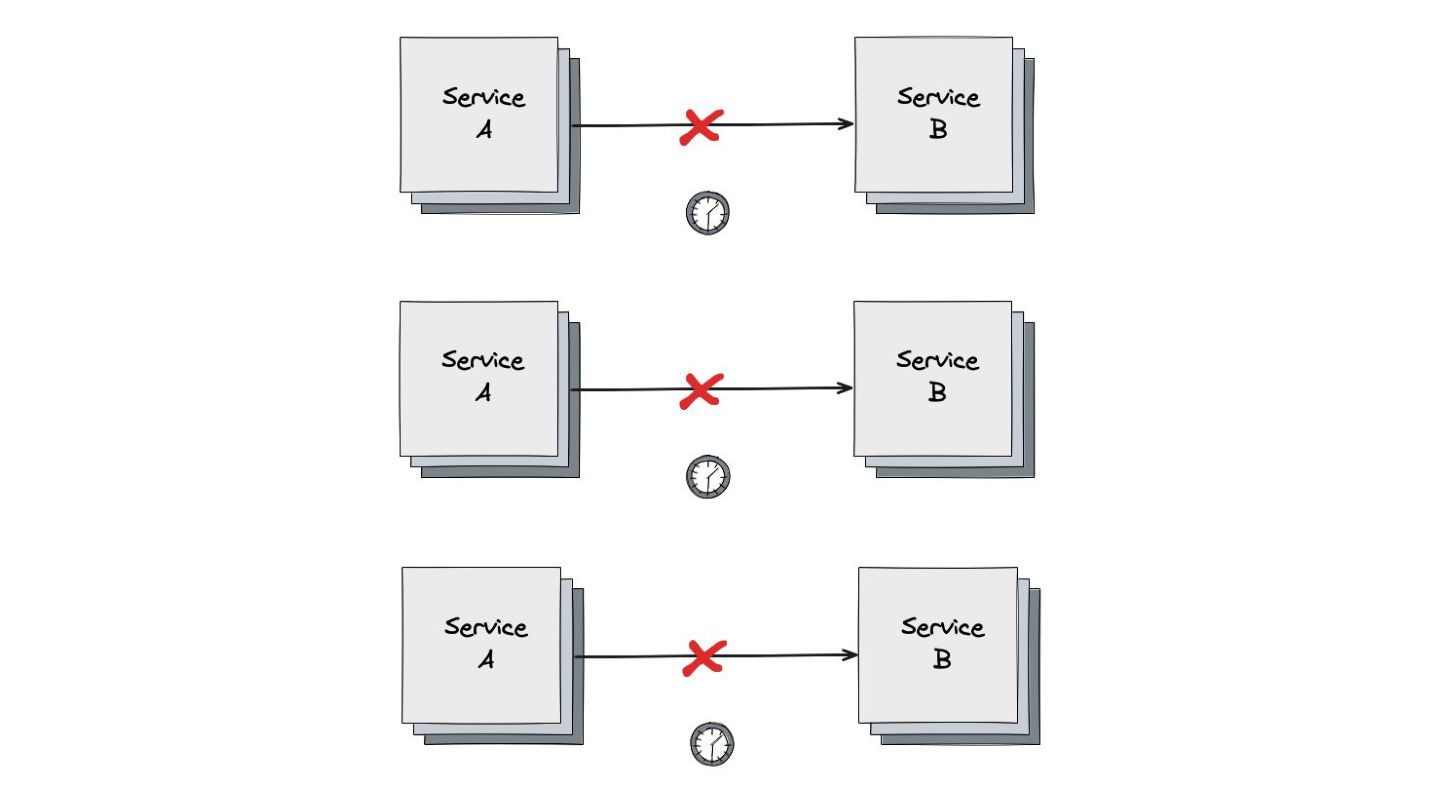
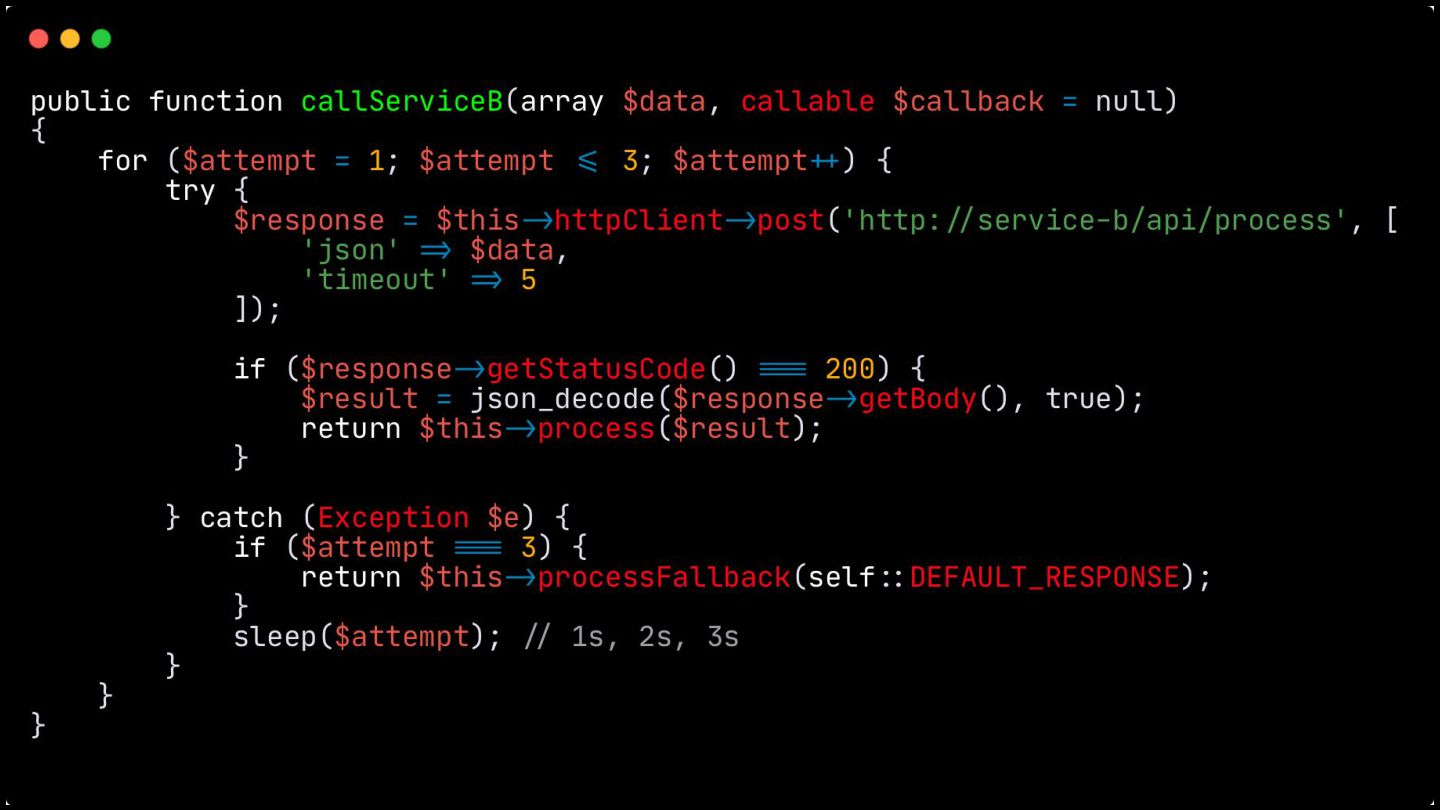
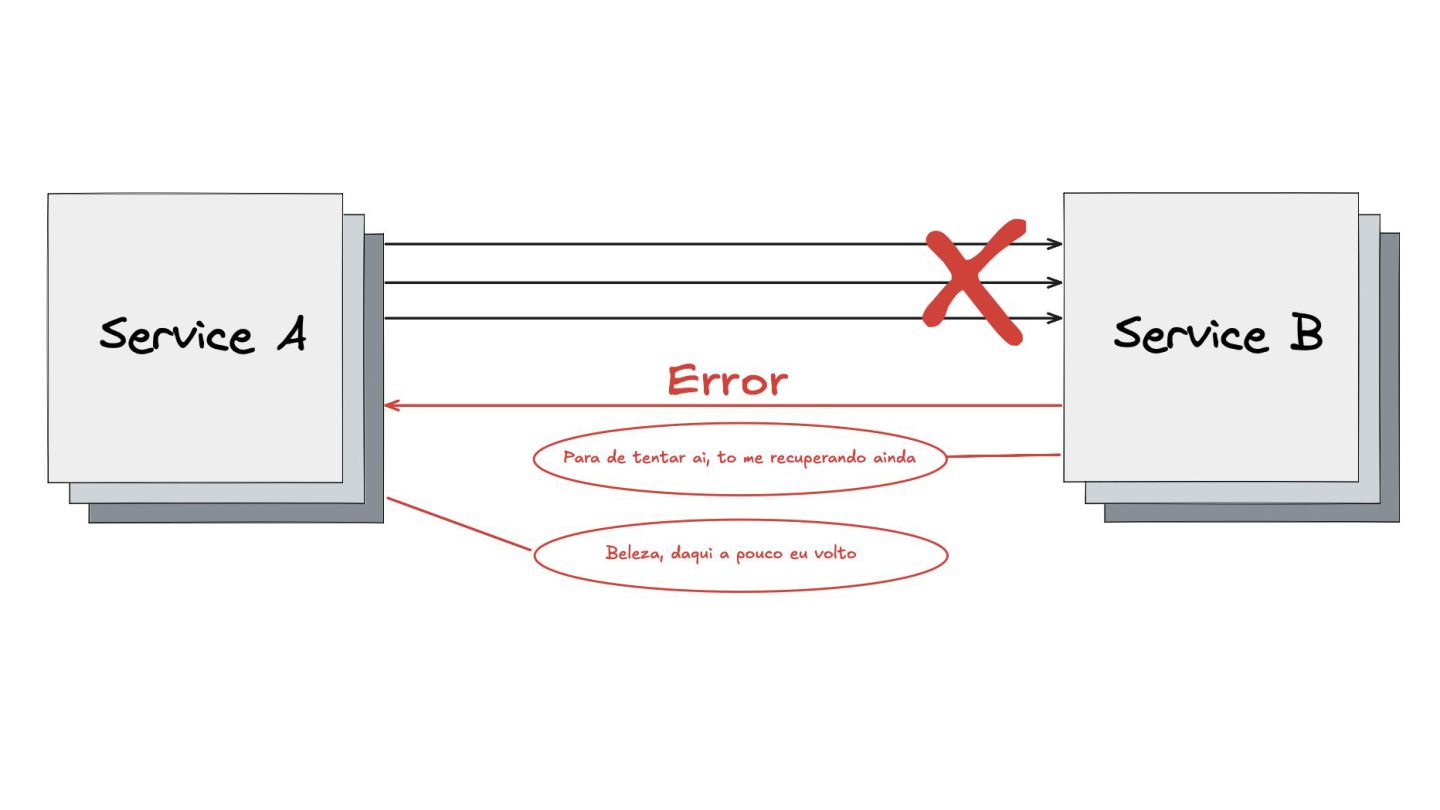
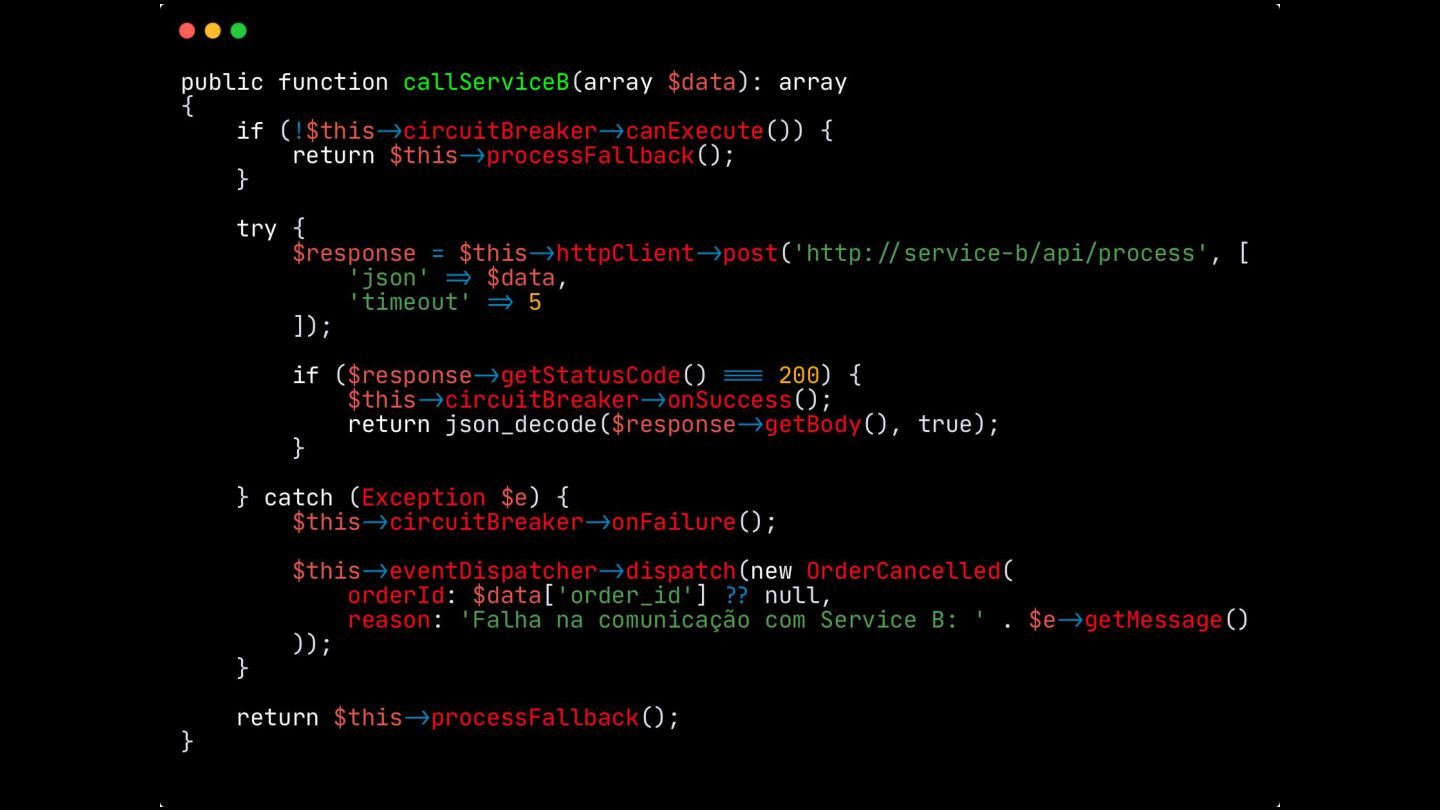
Retry: Mostrei como este padrão lida com falhas temporárias, como timeouts ou perda de pacotes. Expliquei a importância do exponential backoff e do jitter para evitar sobrecarga nos serviços que estão se recuperando.
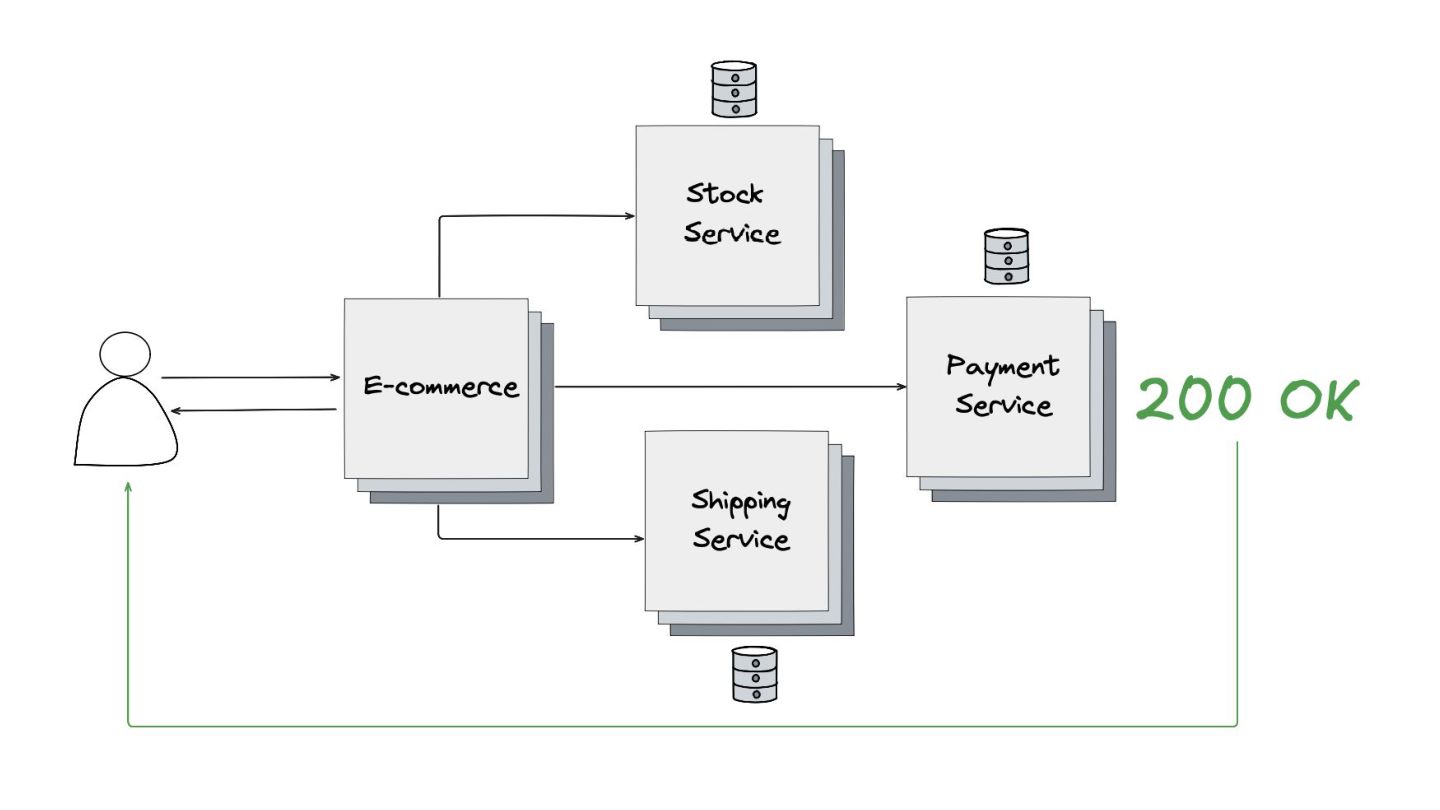
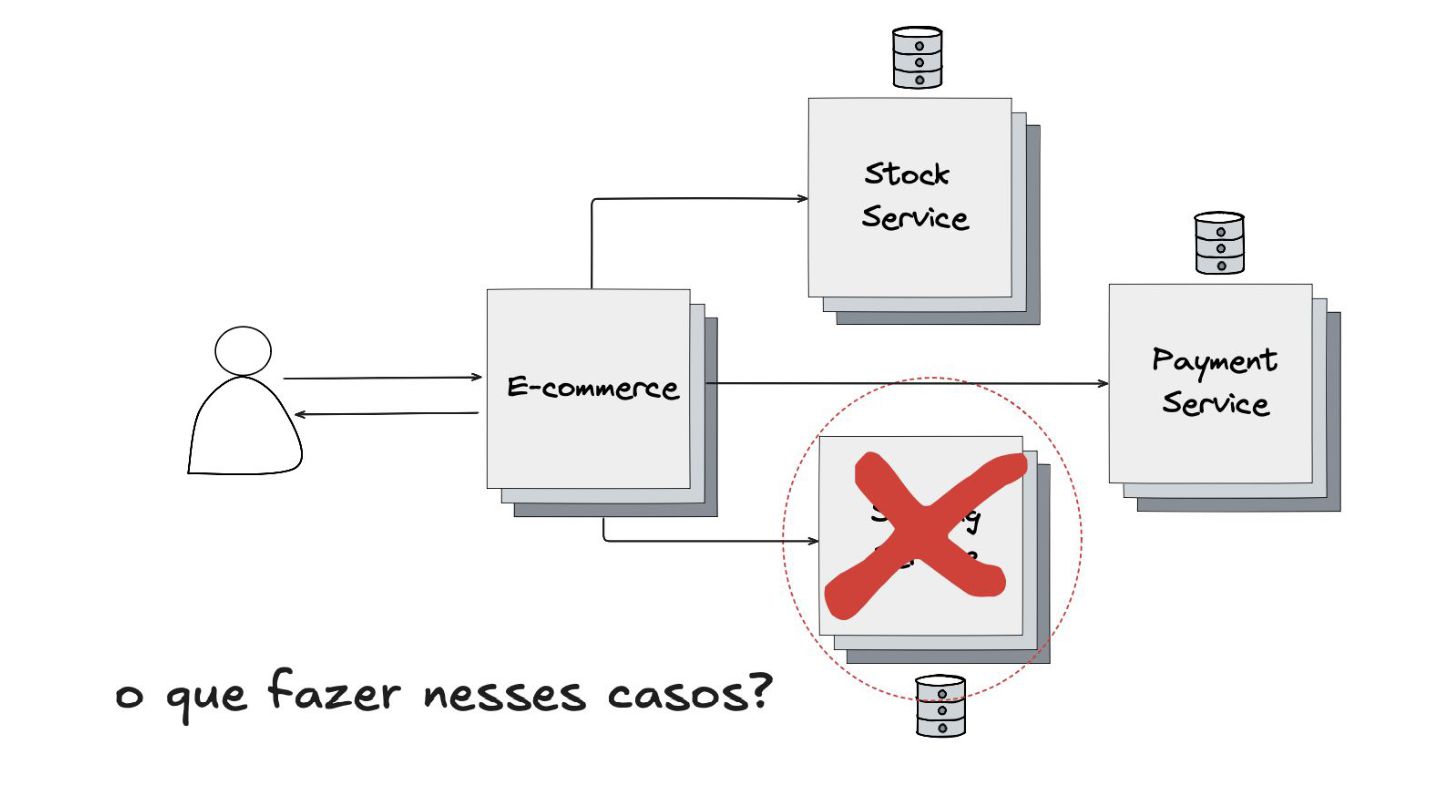
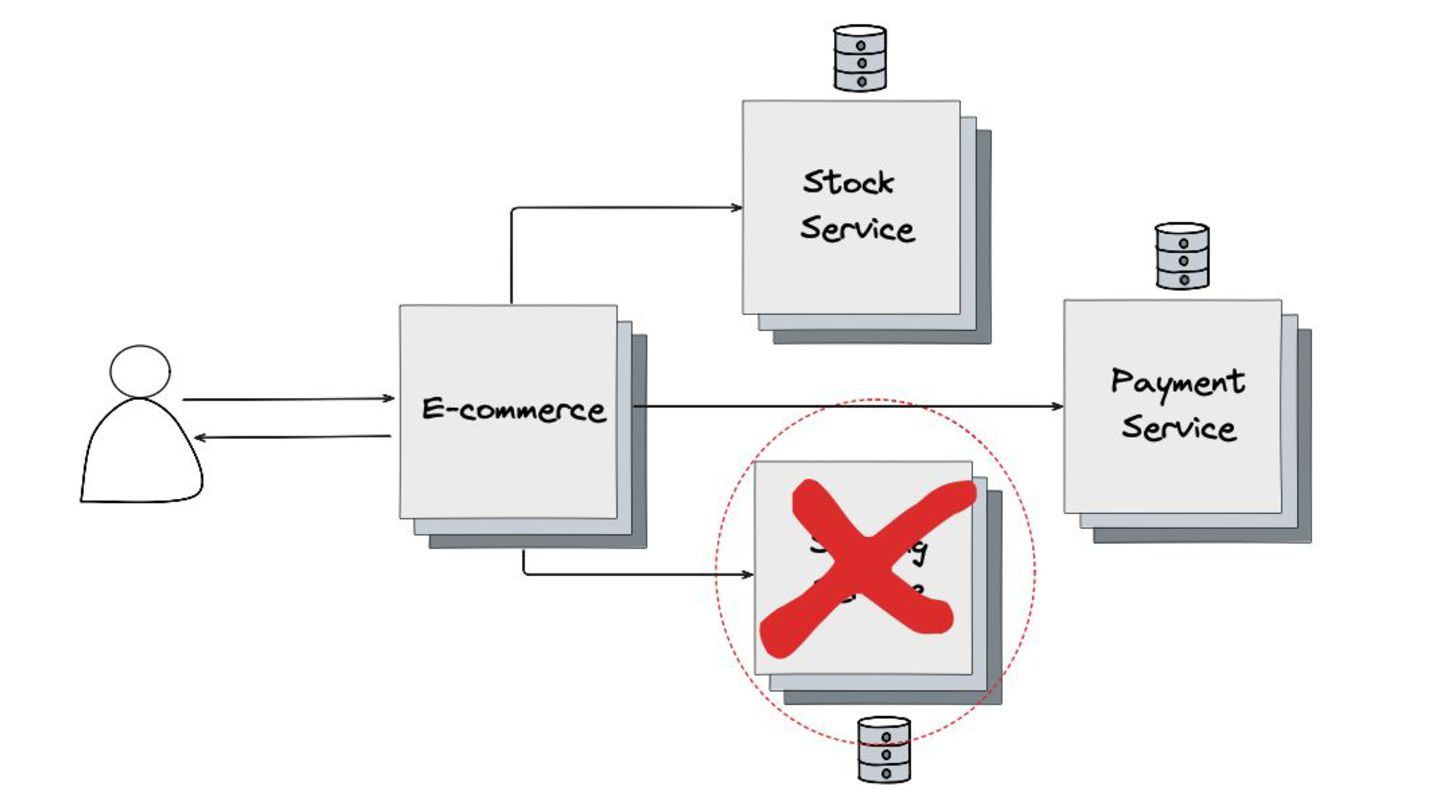
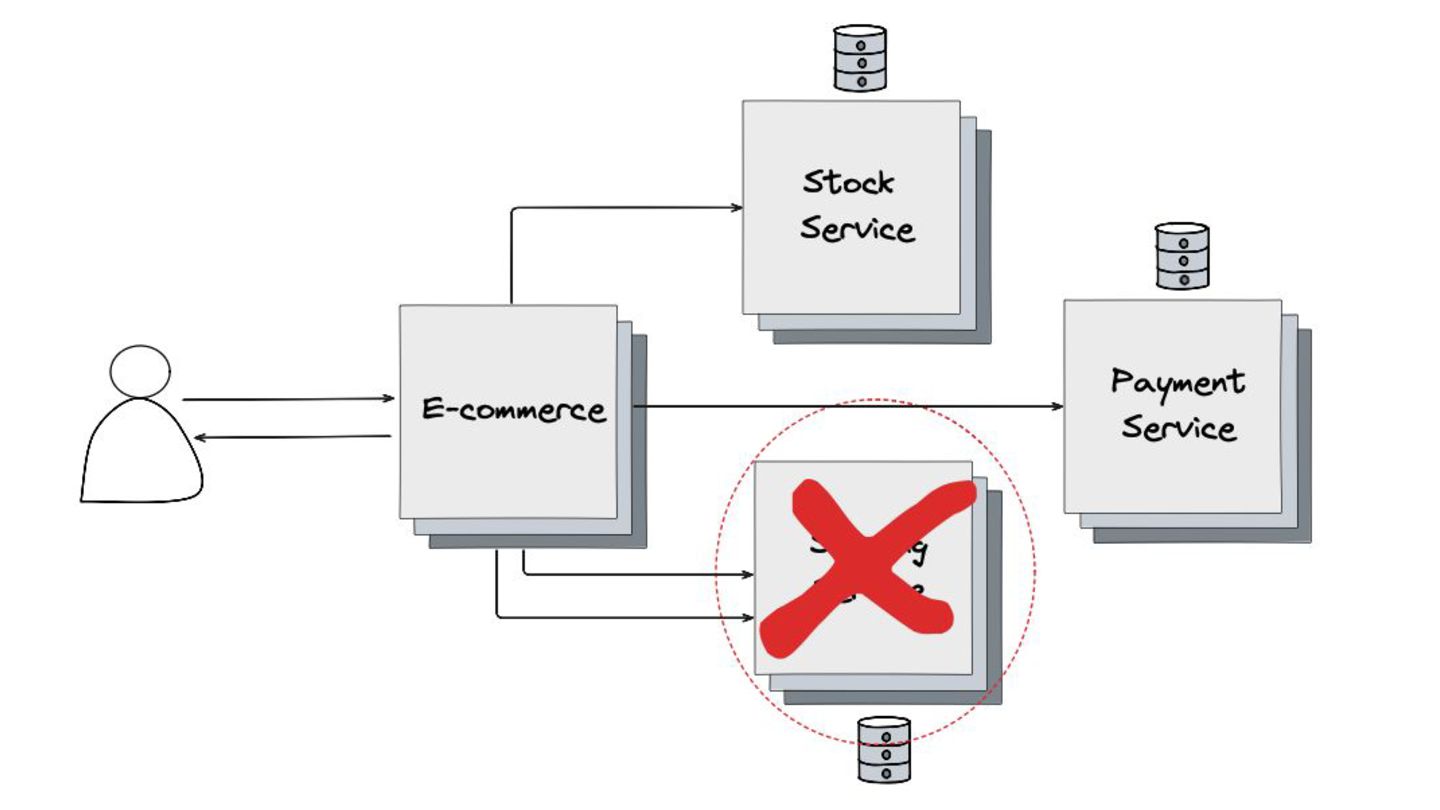
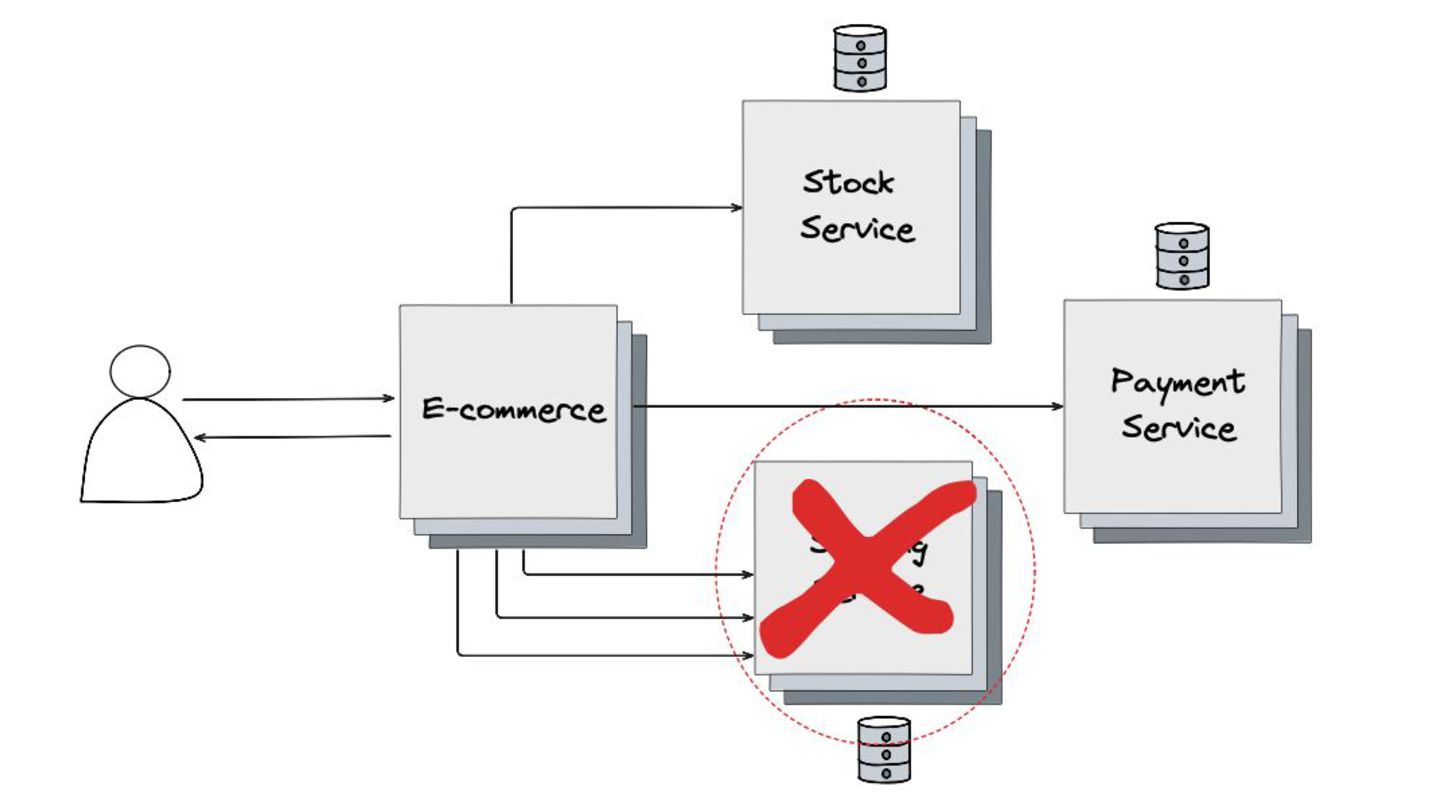
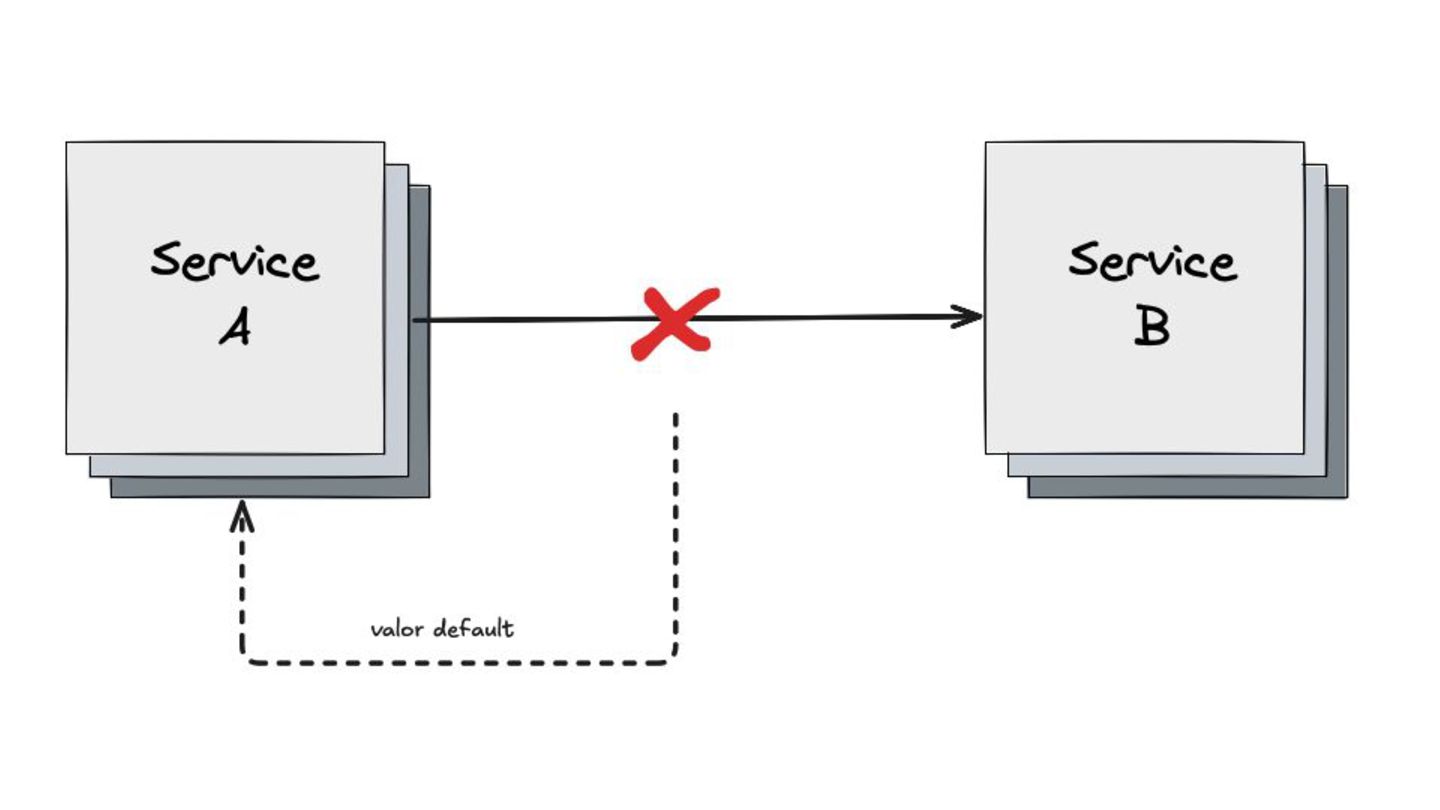
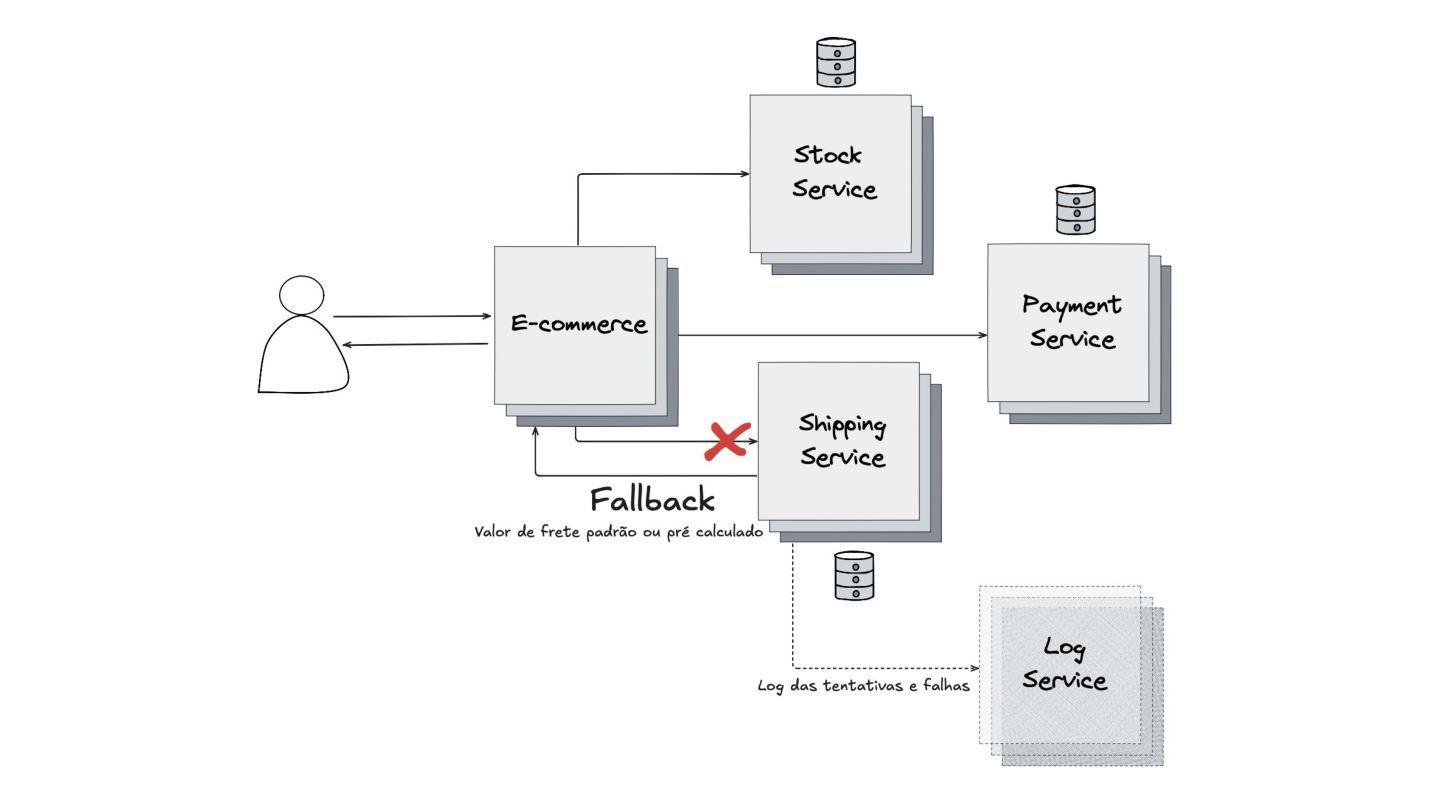
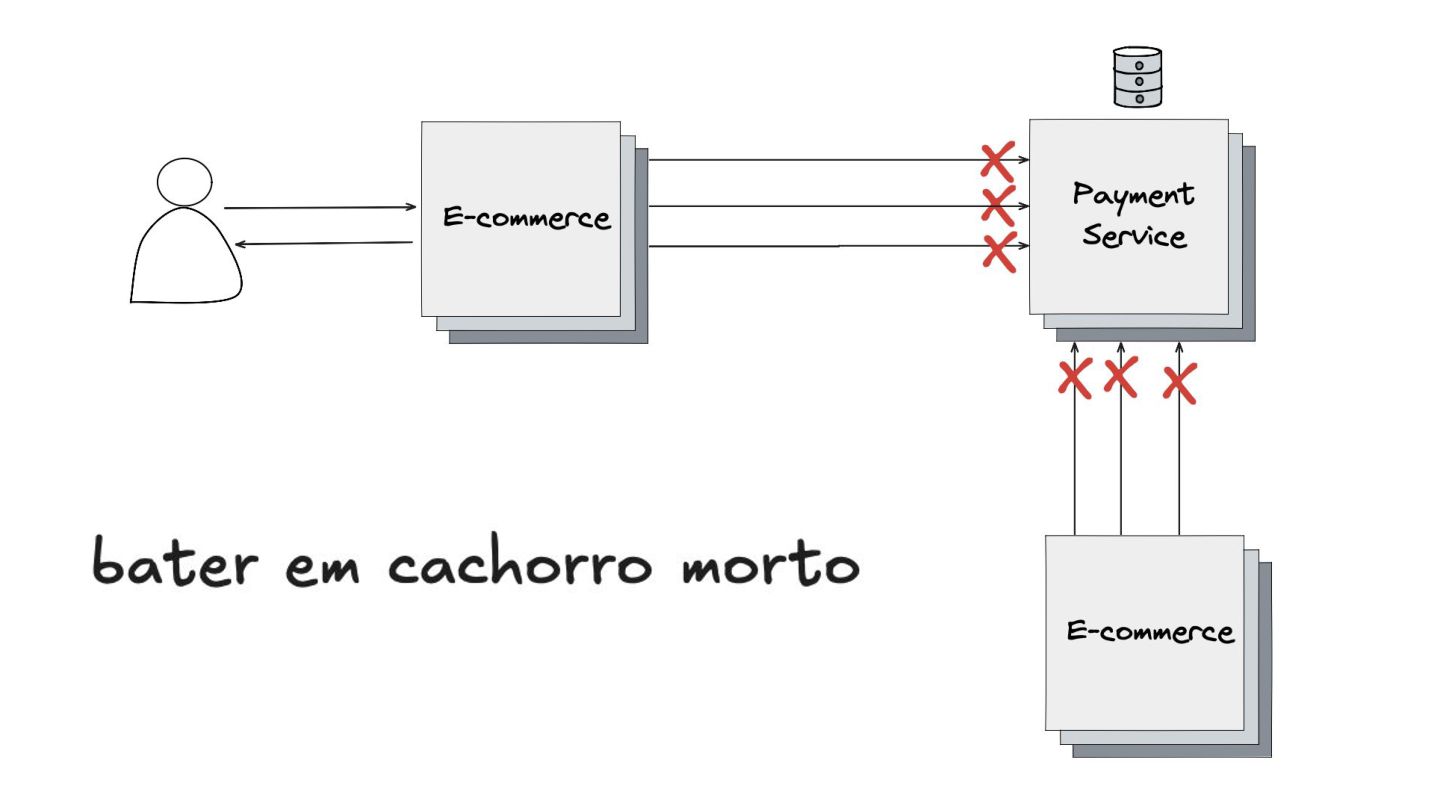
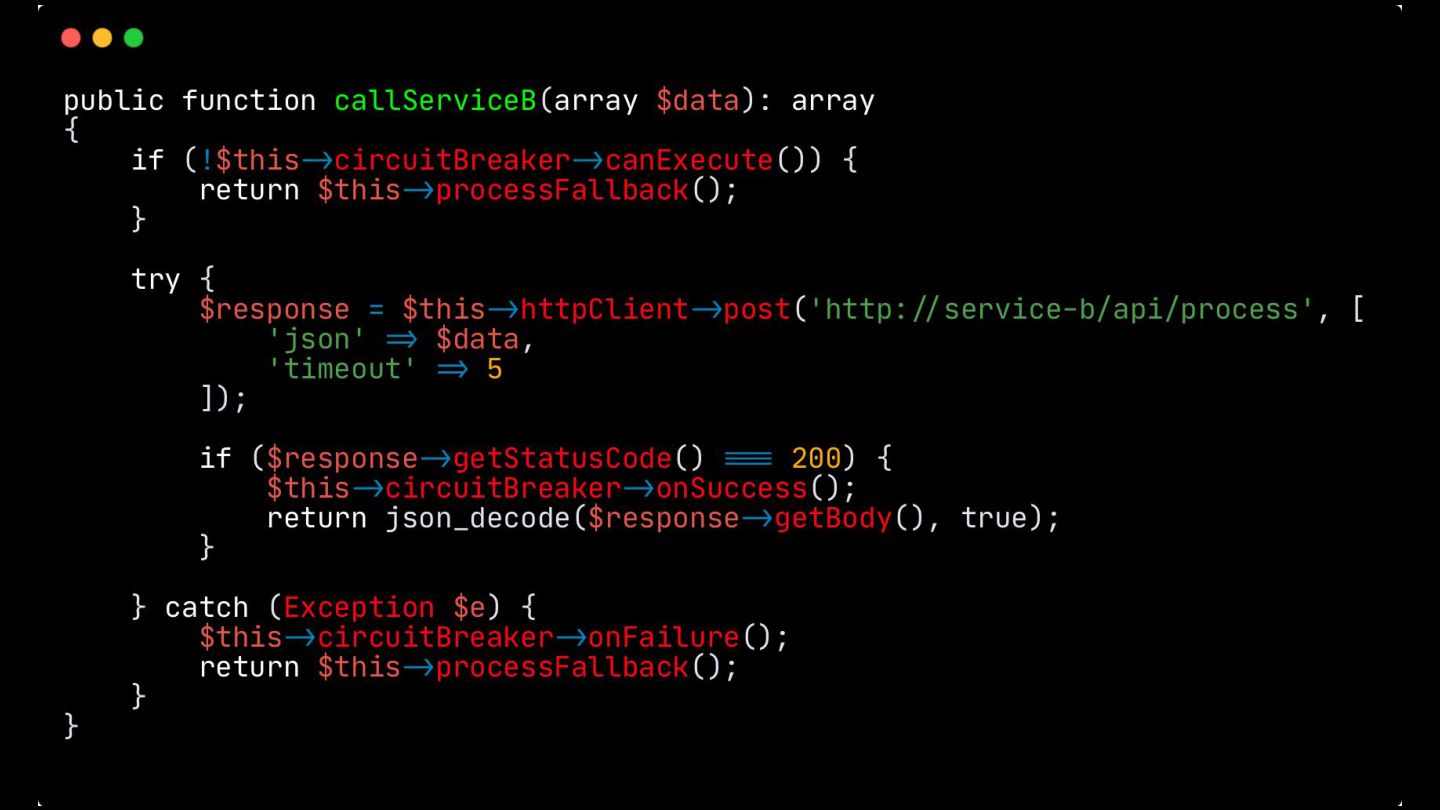
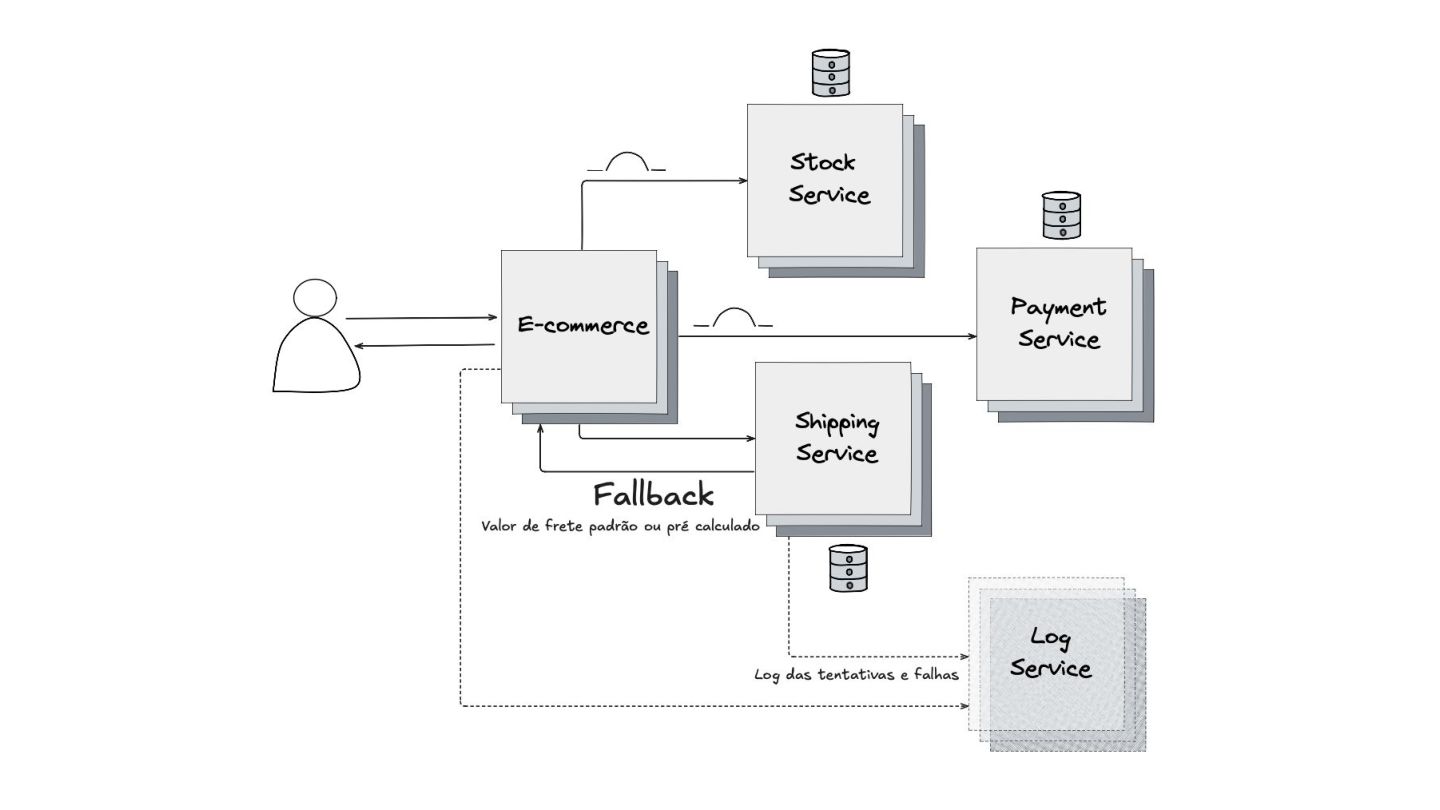
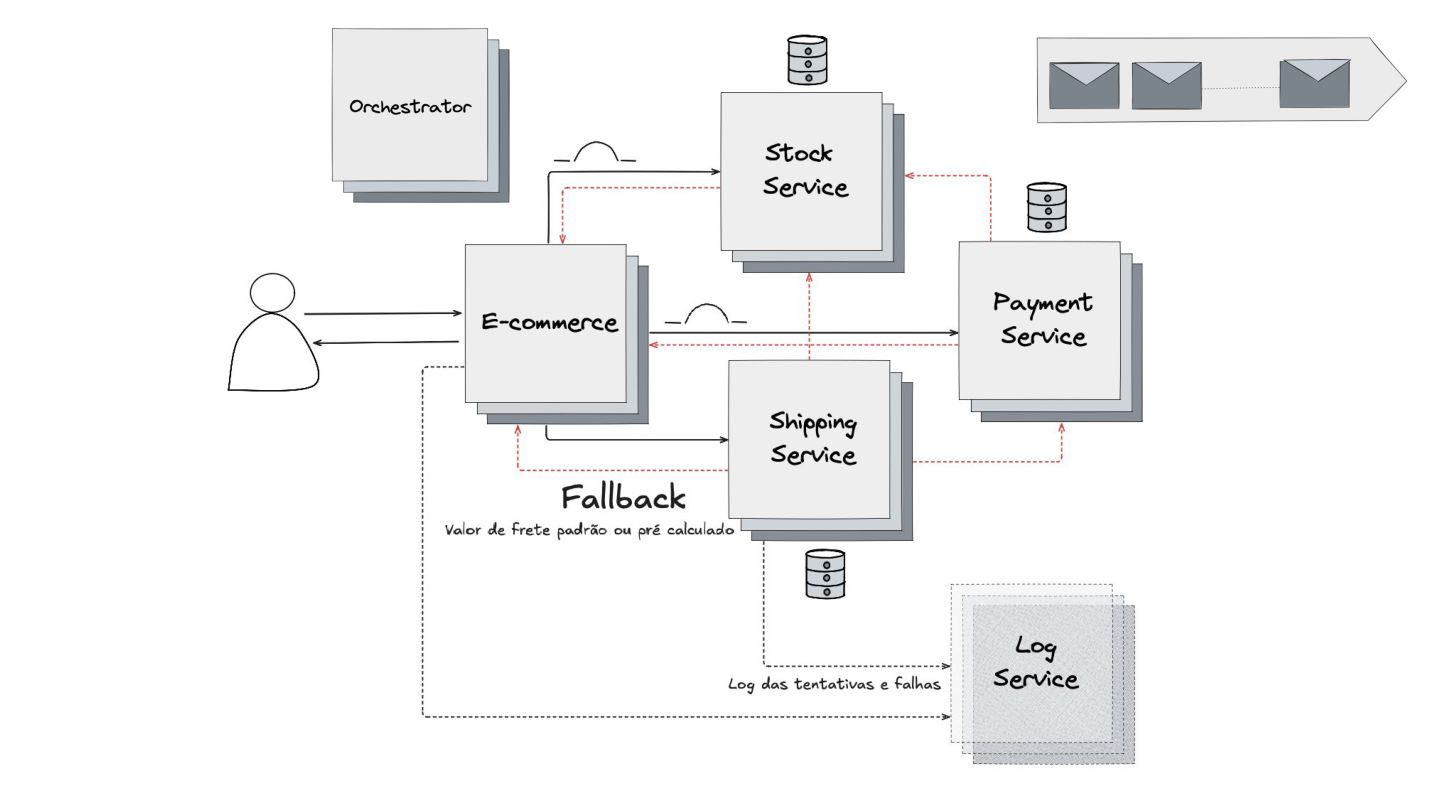
Fallback: Abordei este padrão, que visa garantir a alta disponibilidade mesmo quando um serviço crítico falha. O objetivo é retornar uma resposta alternativa, como um valor padrão ou um dado em cache, para evitar que o sistema pare completamente.
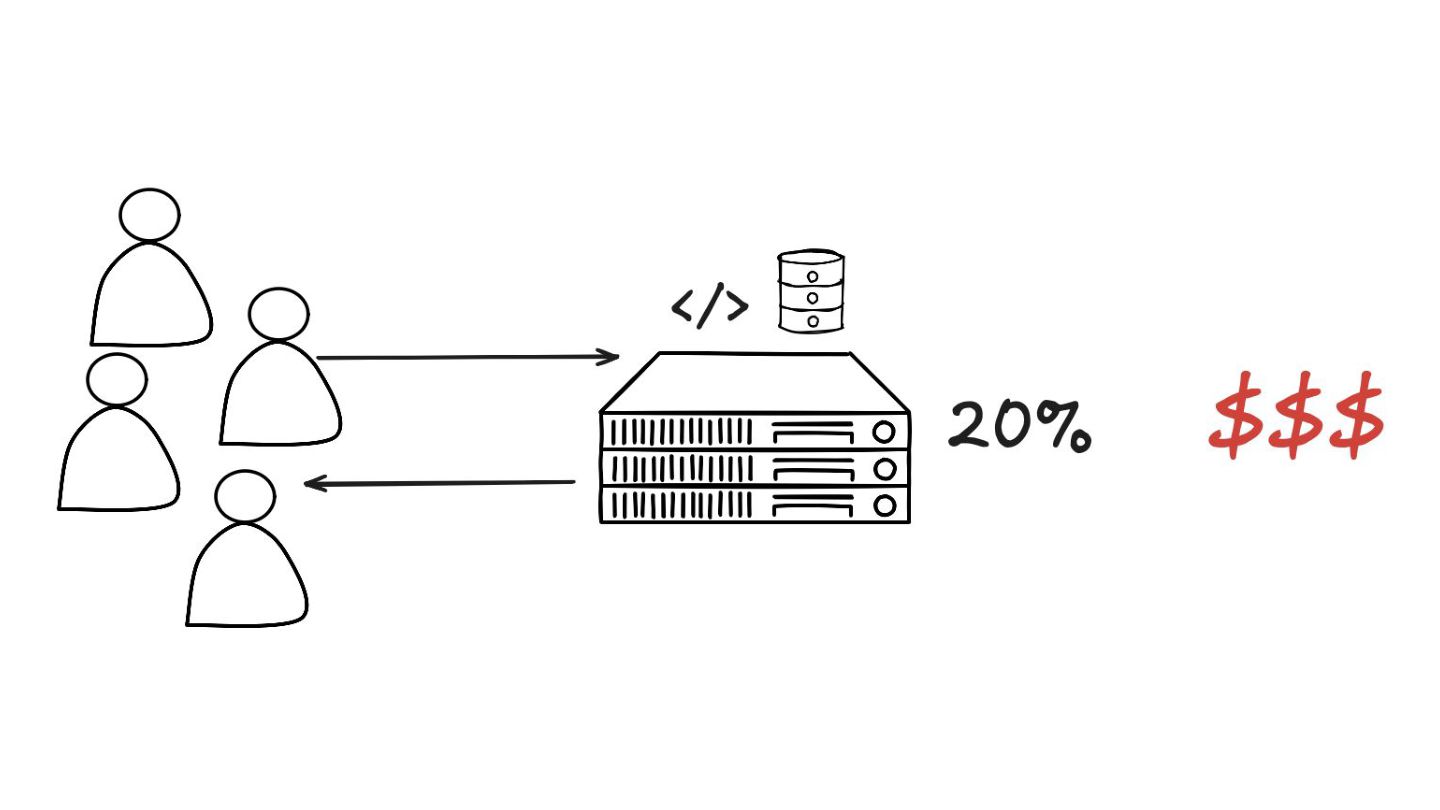
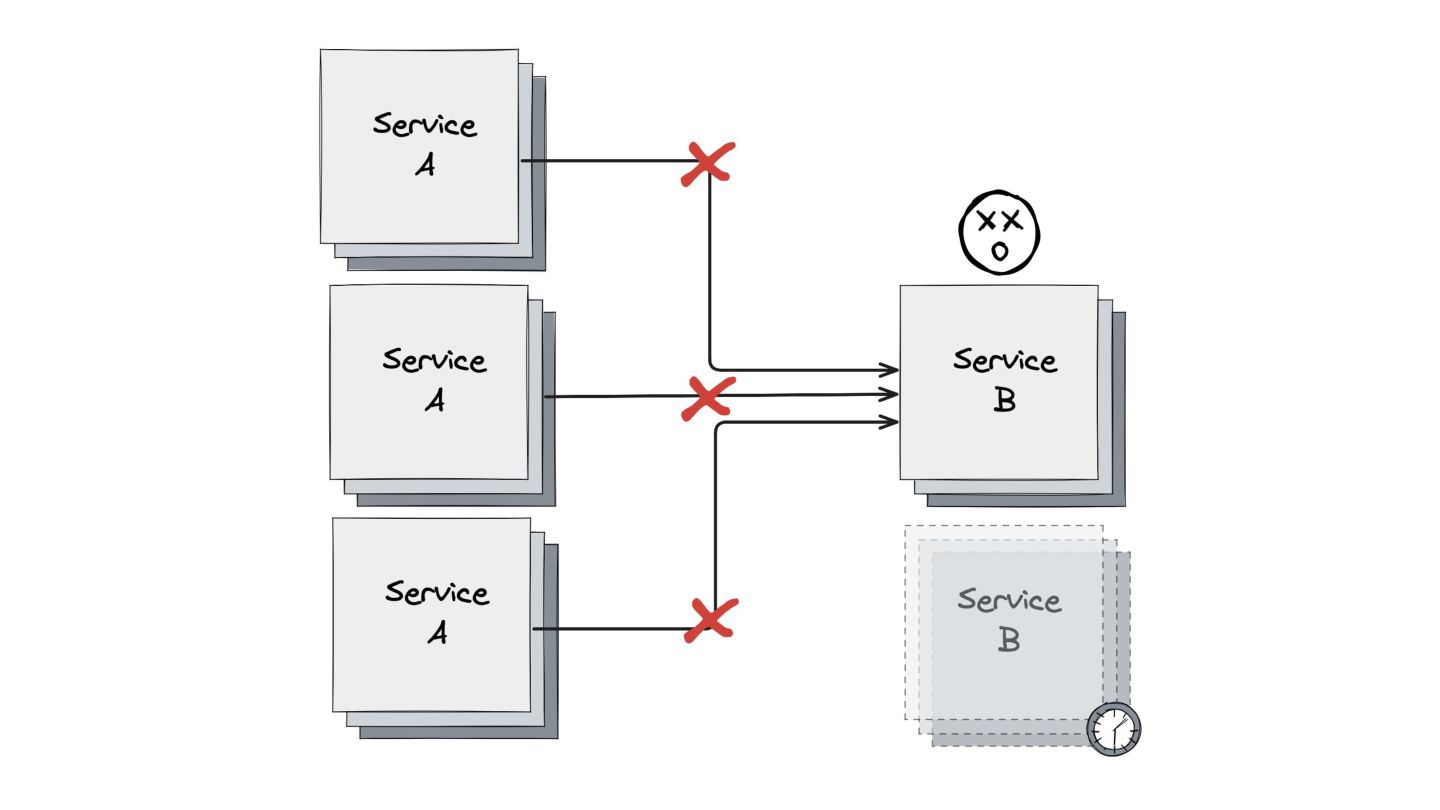
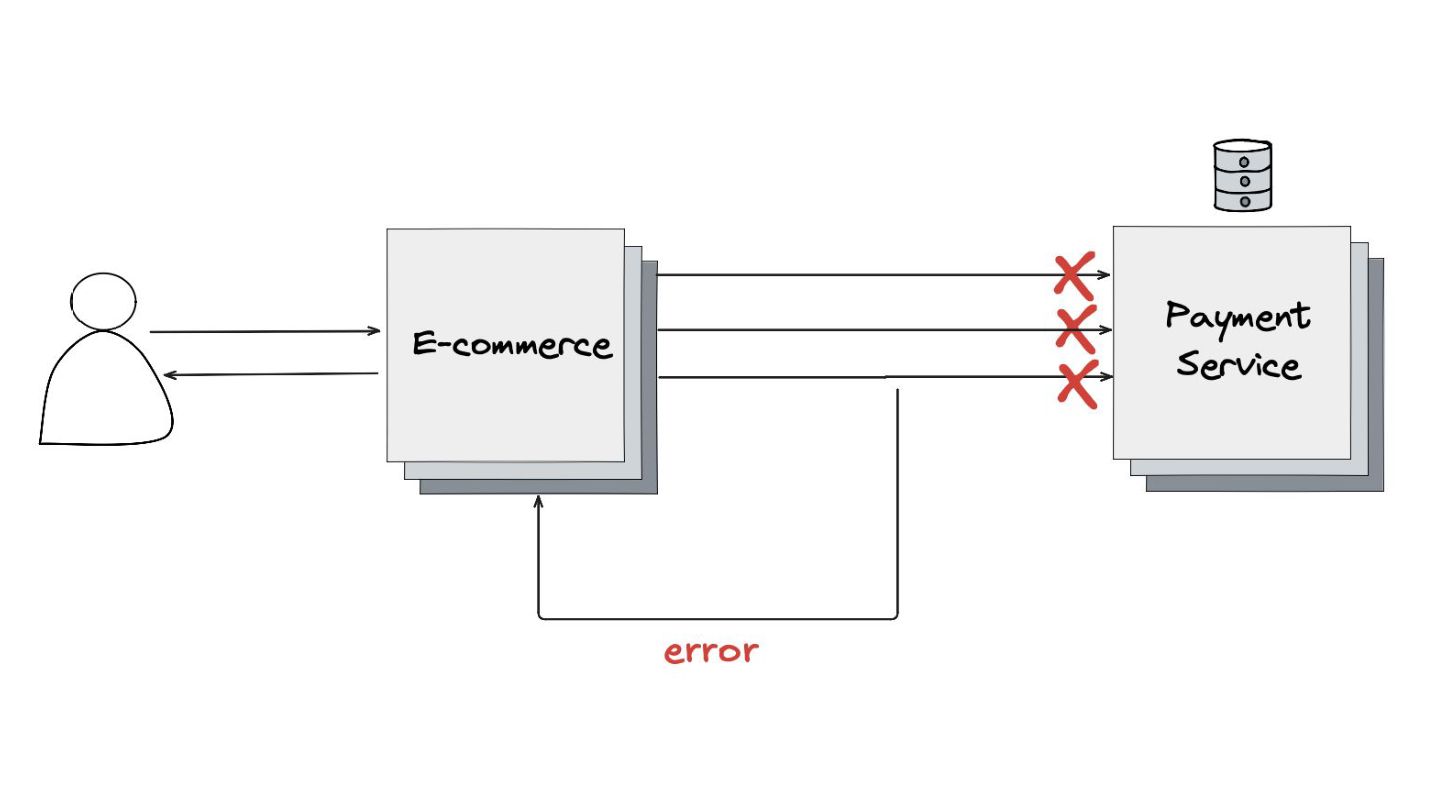
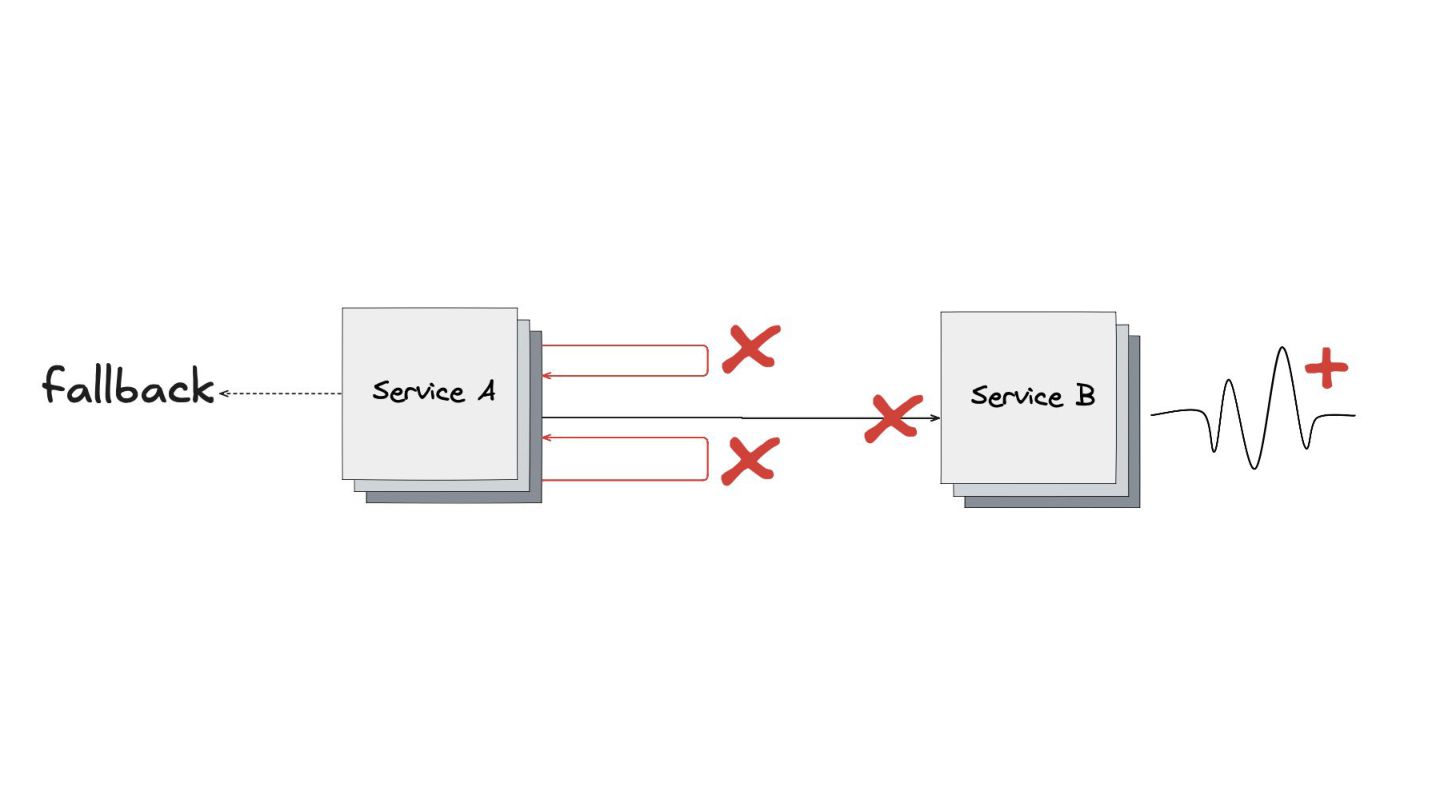
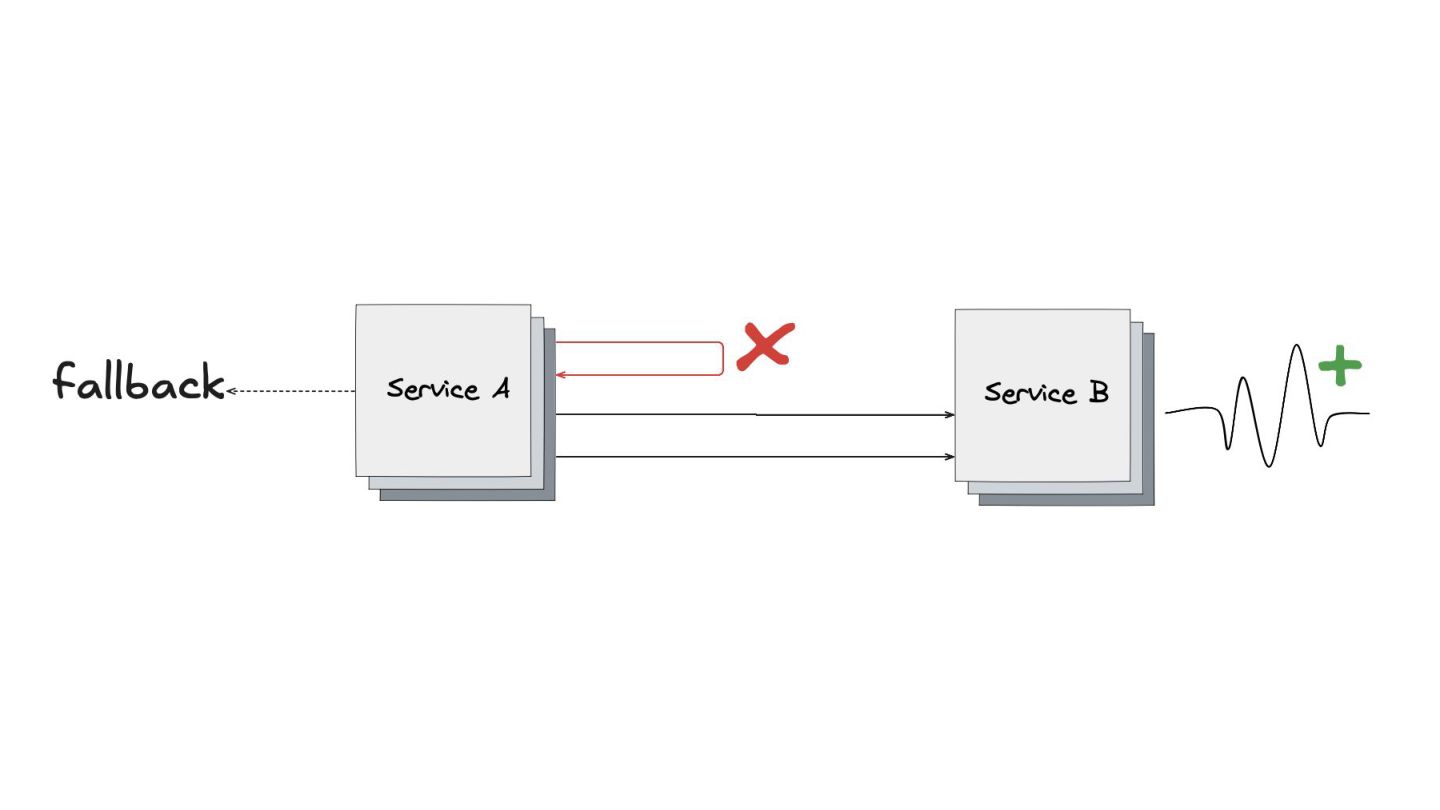
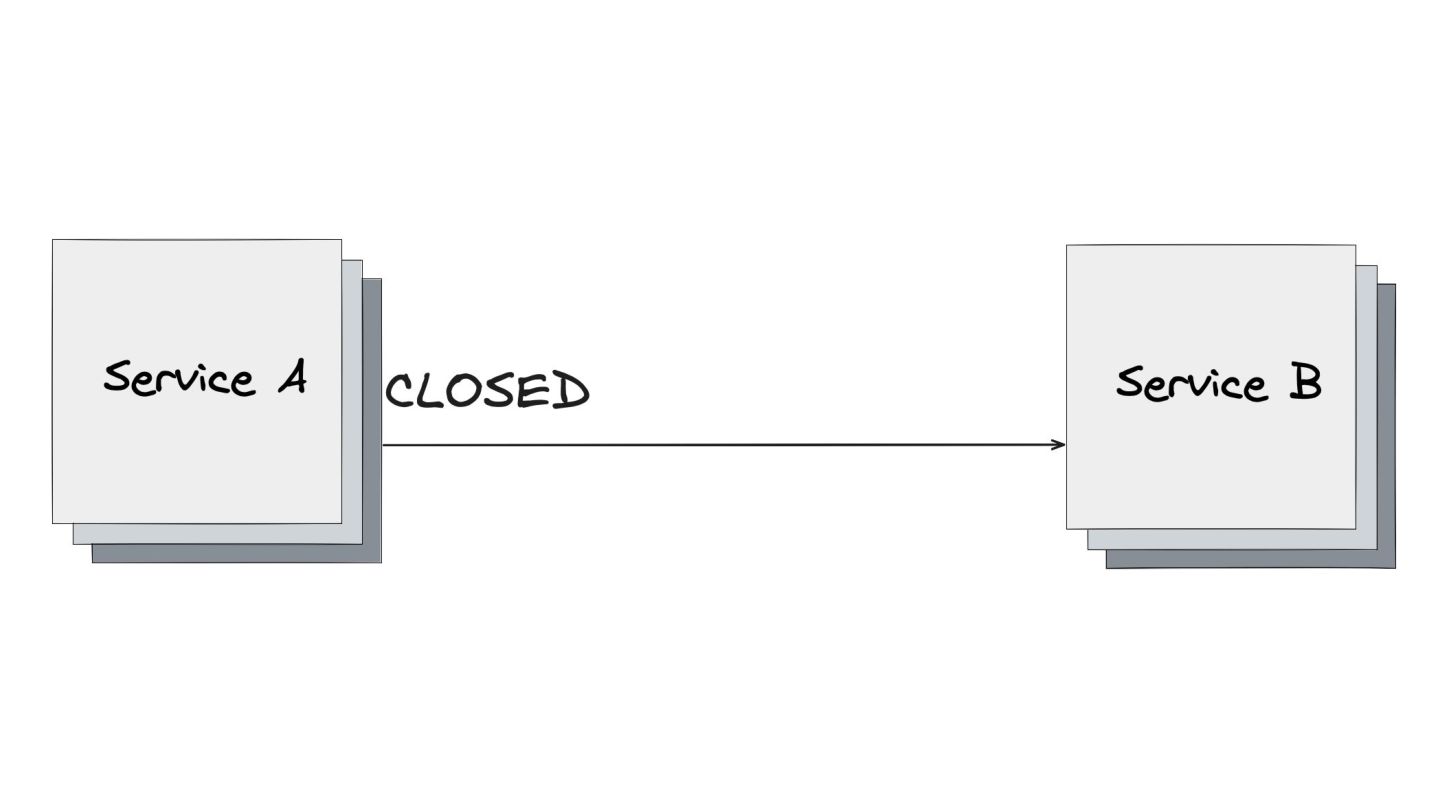
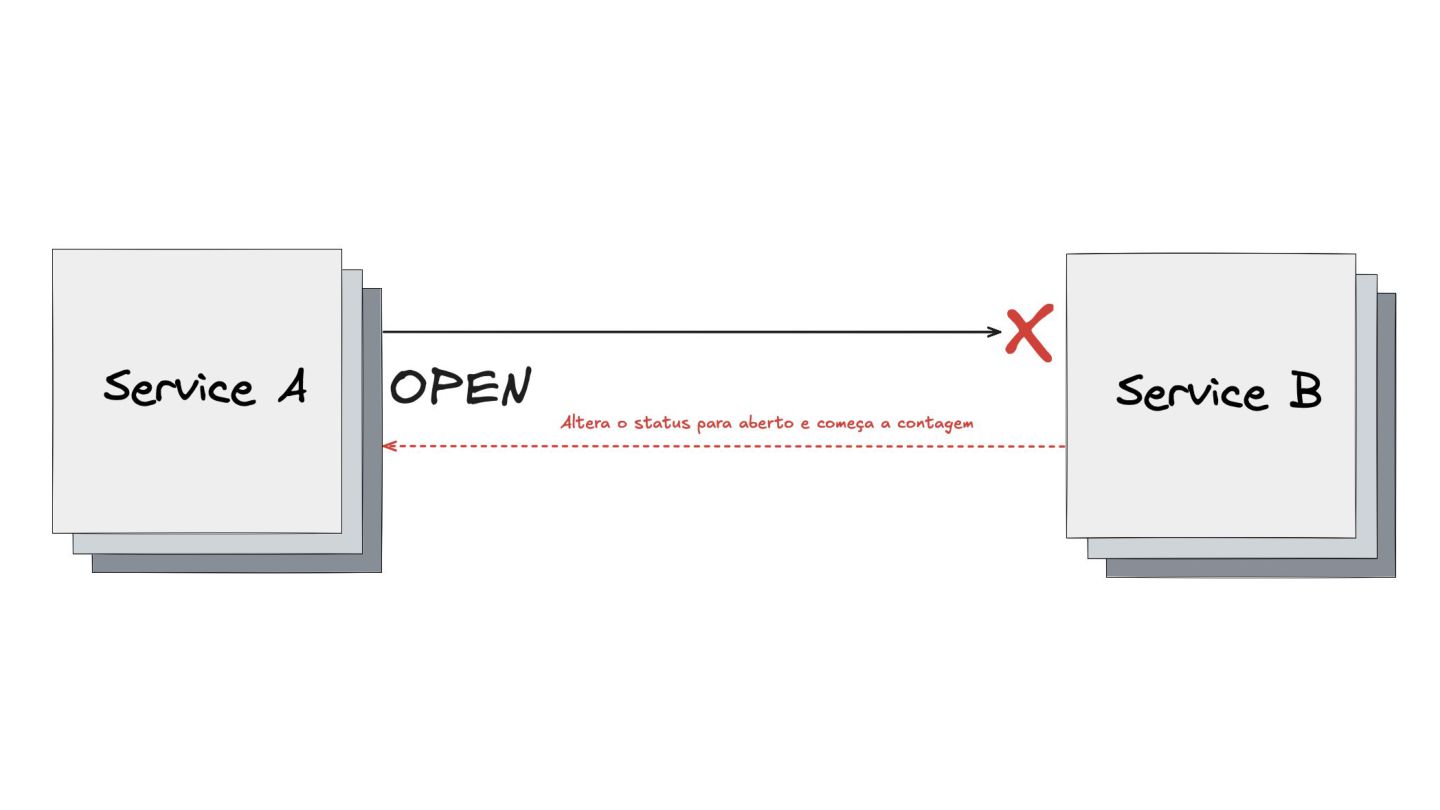
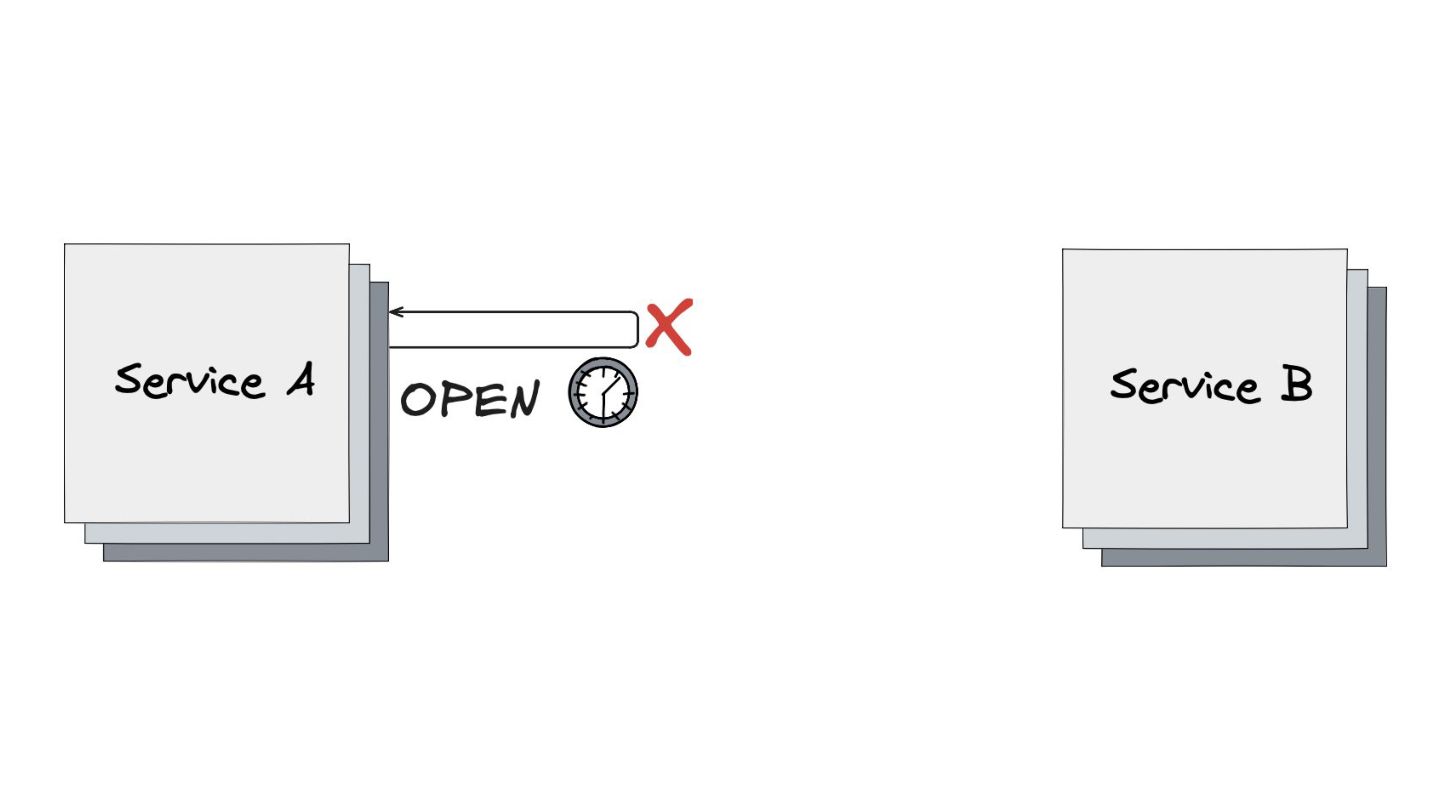
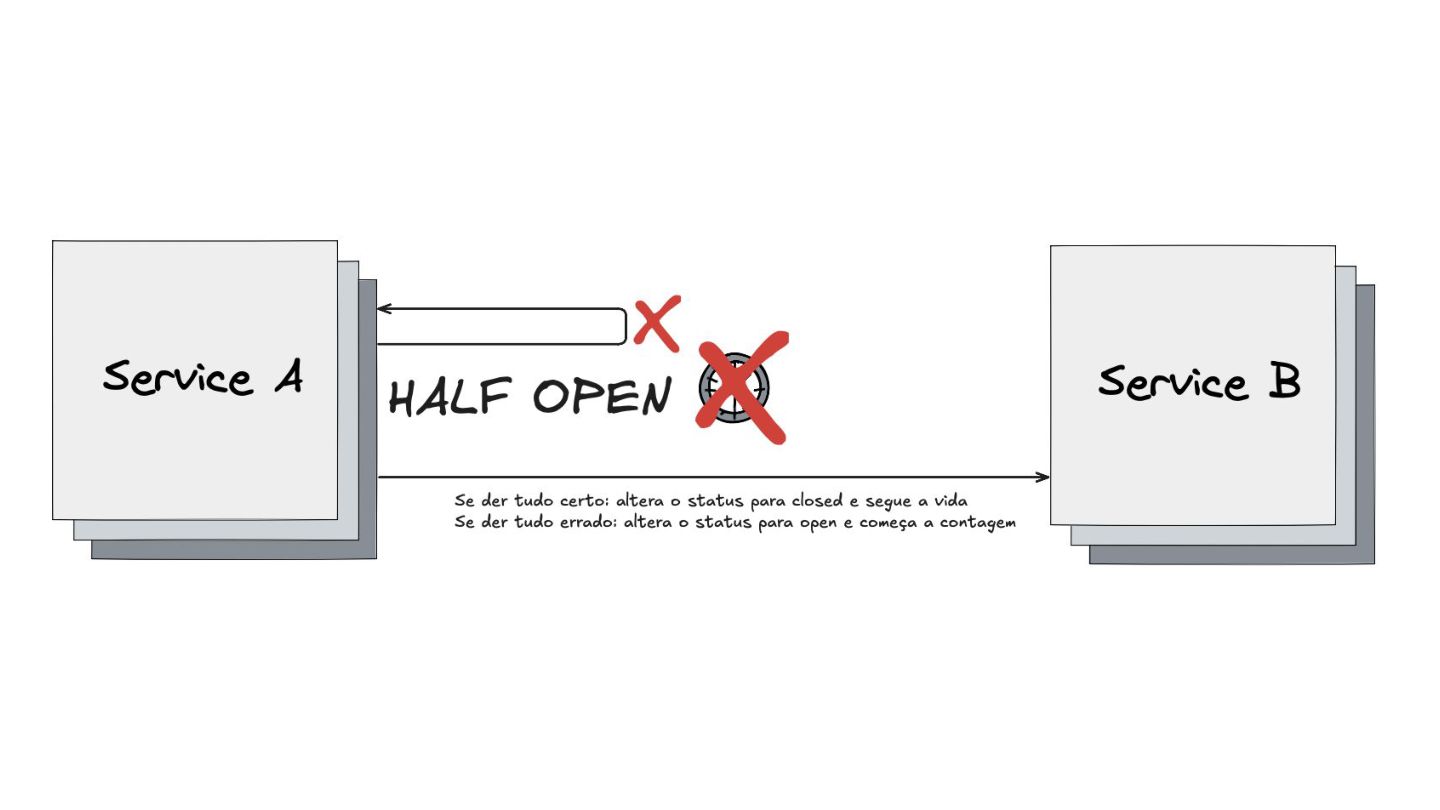
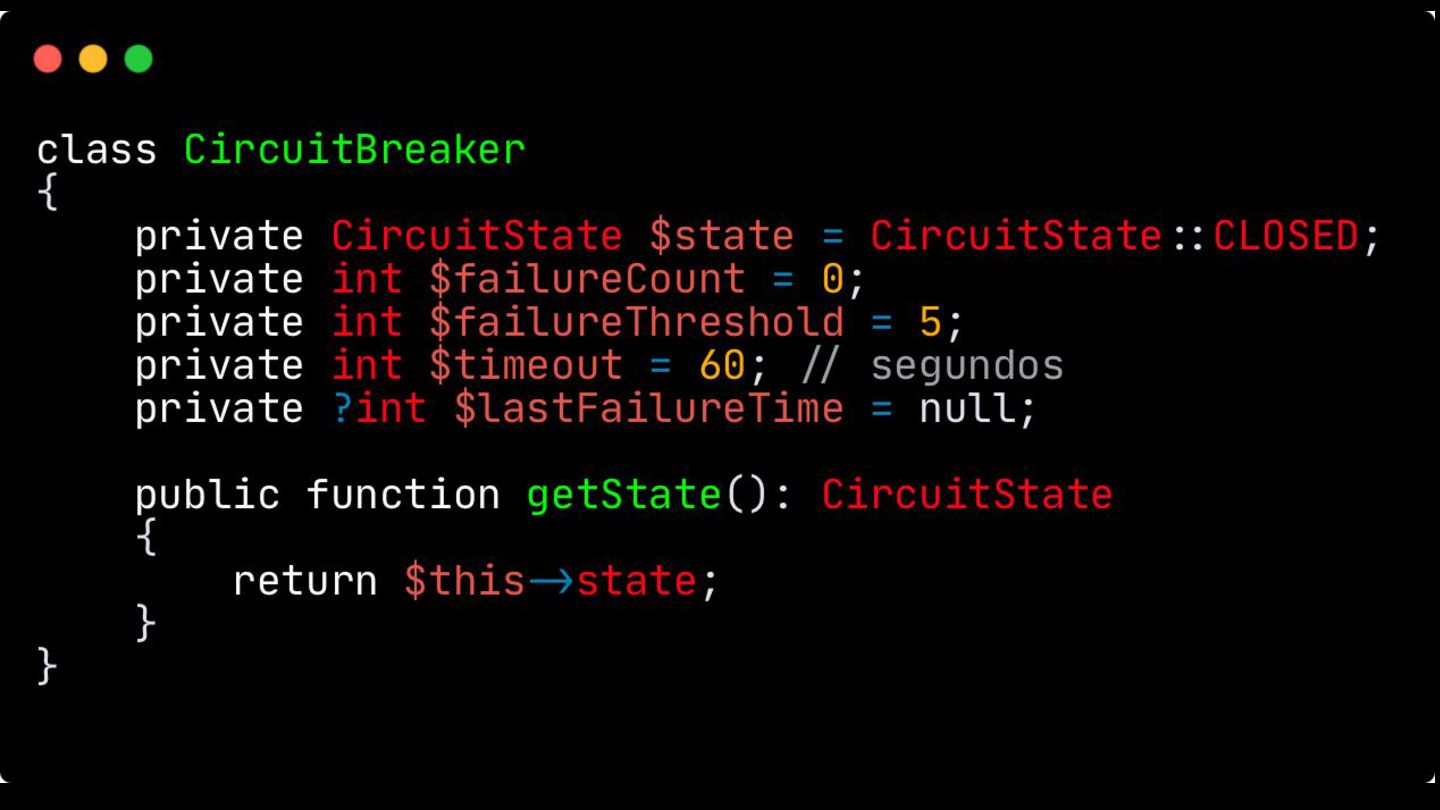
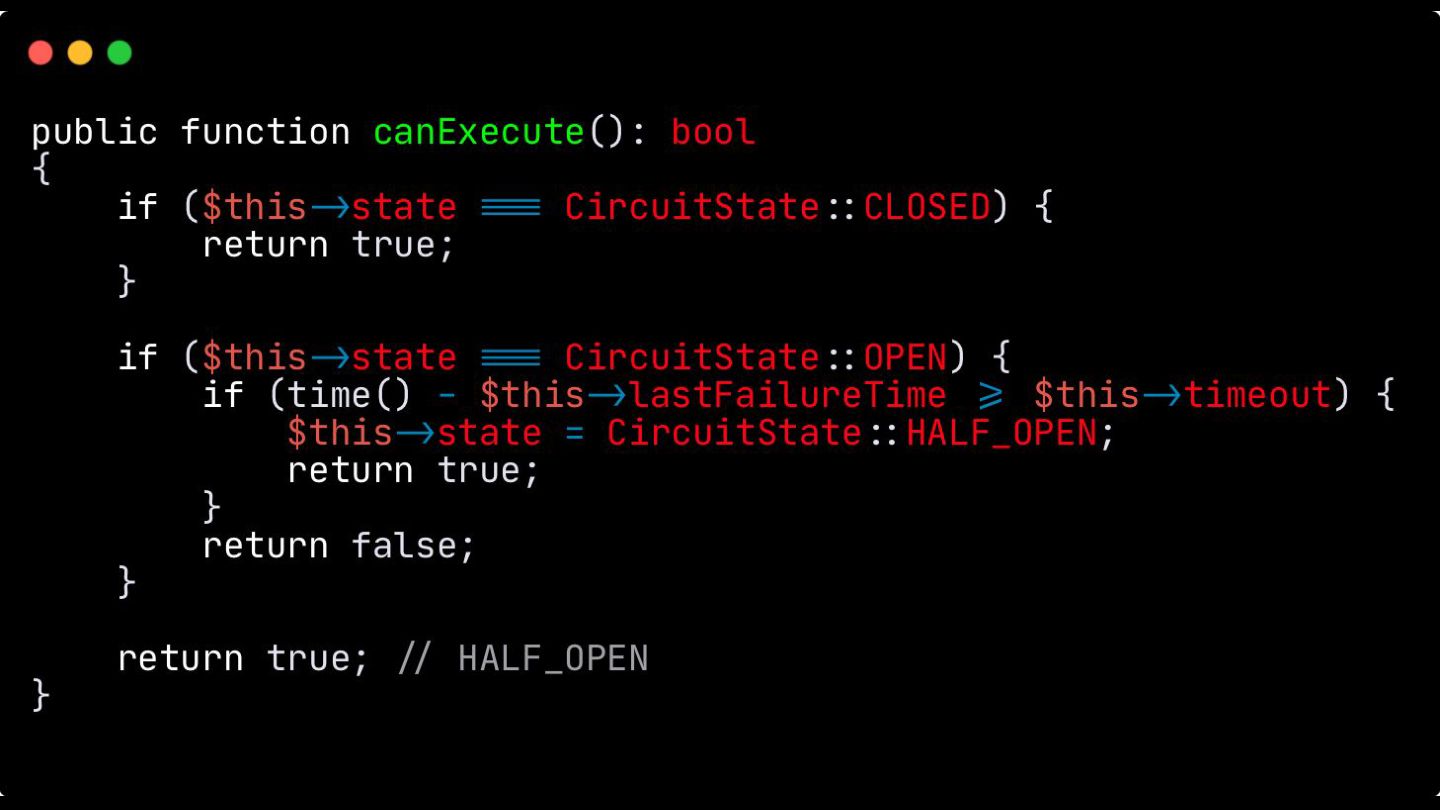
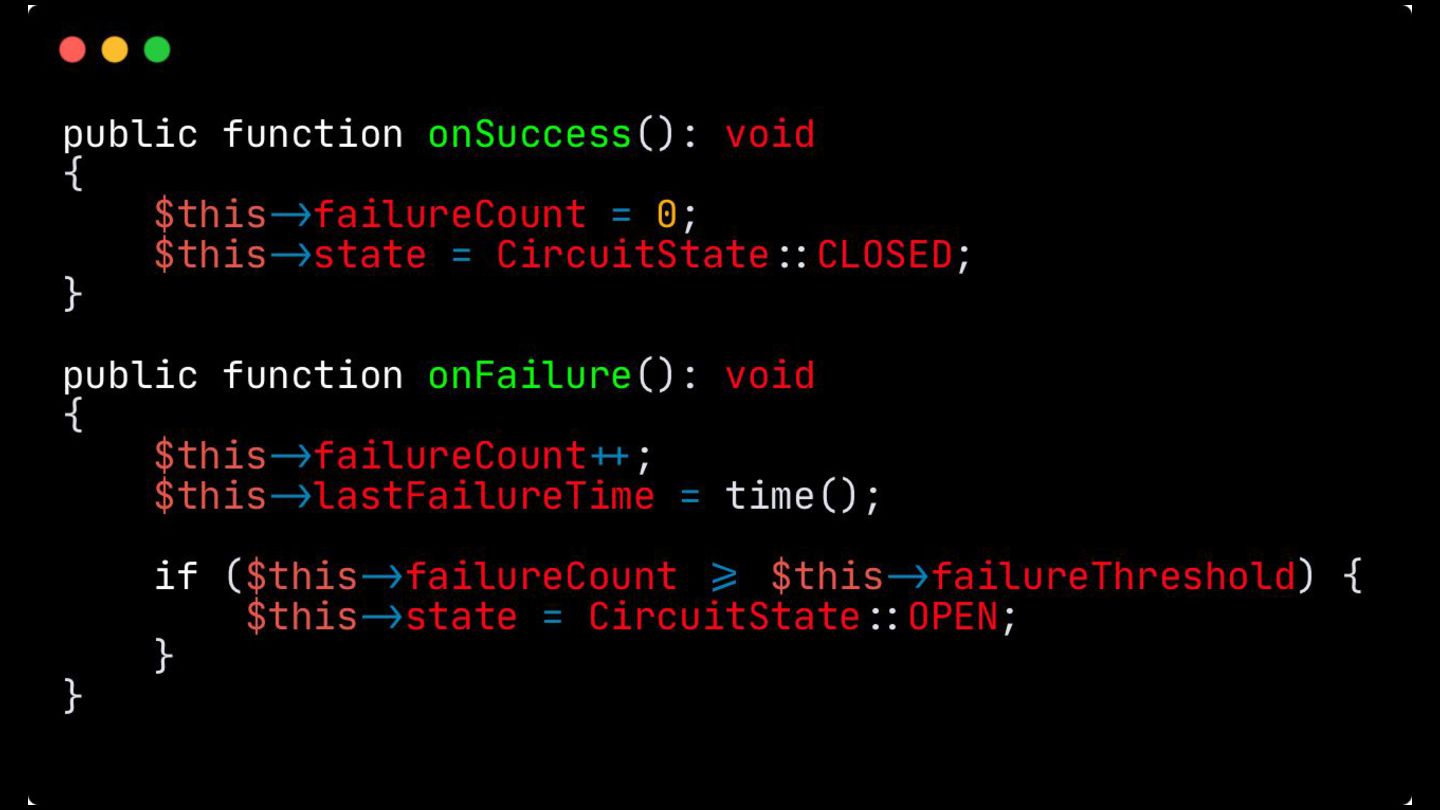
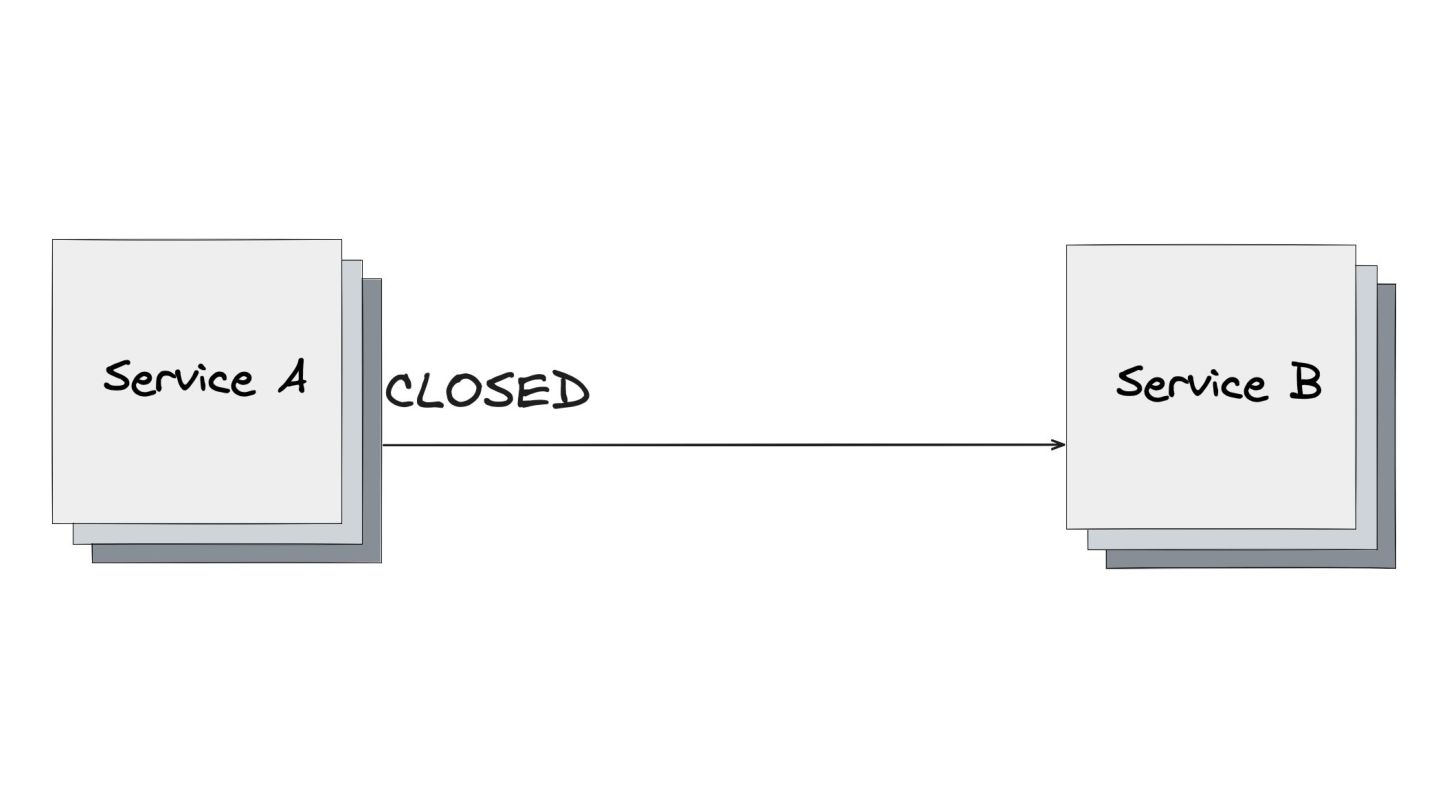
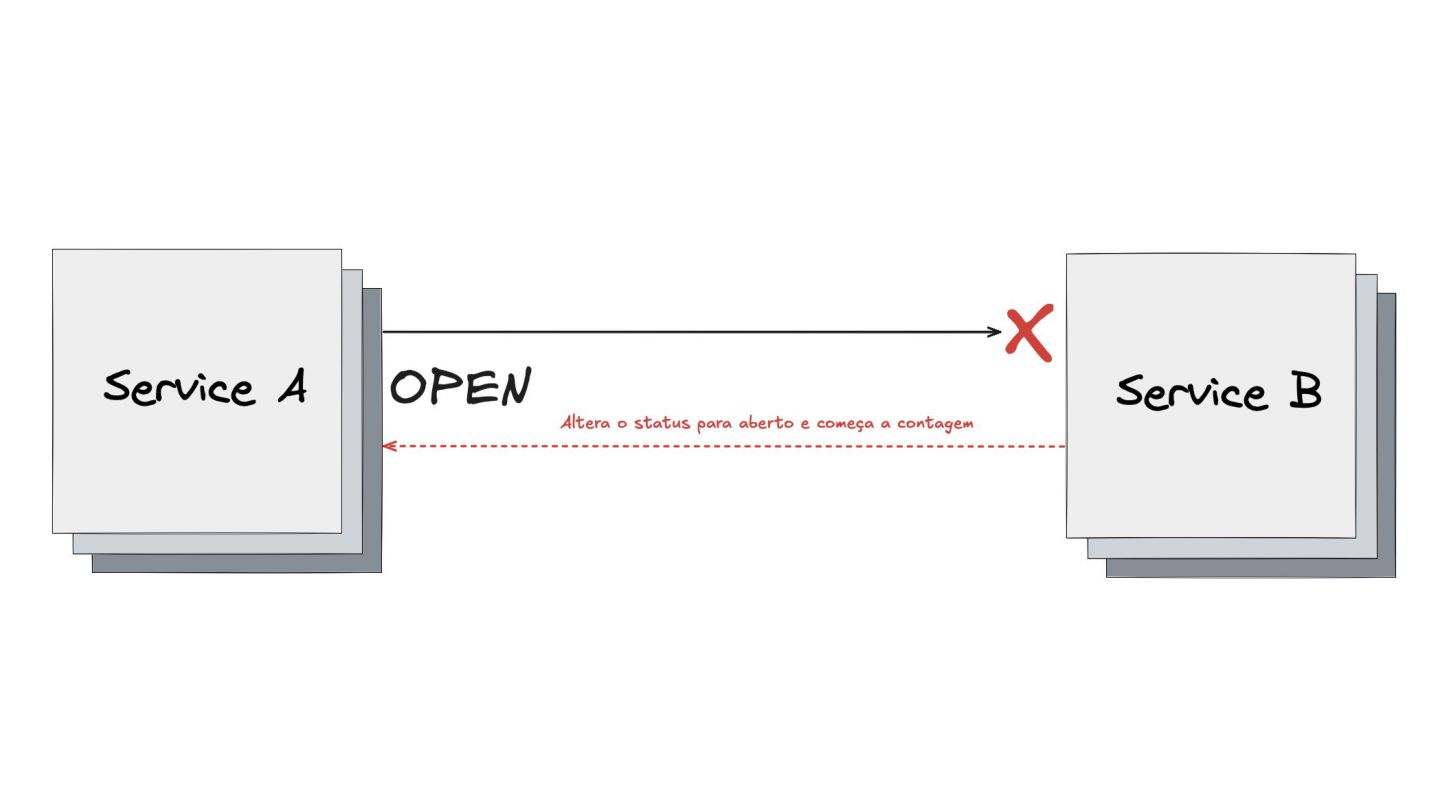
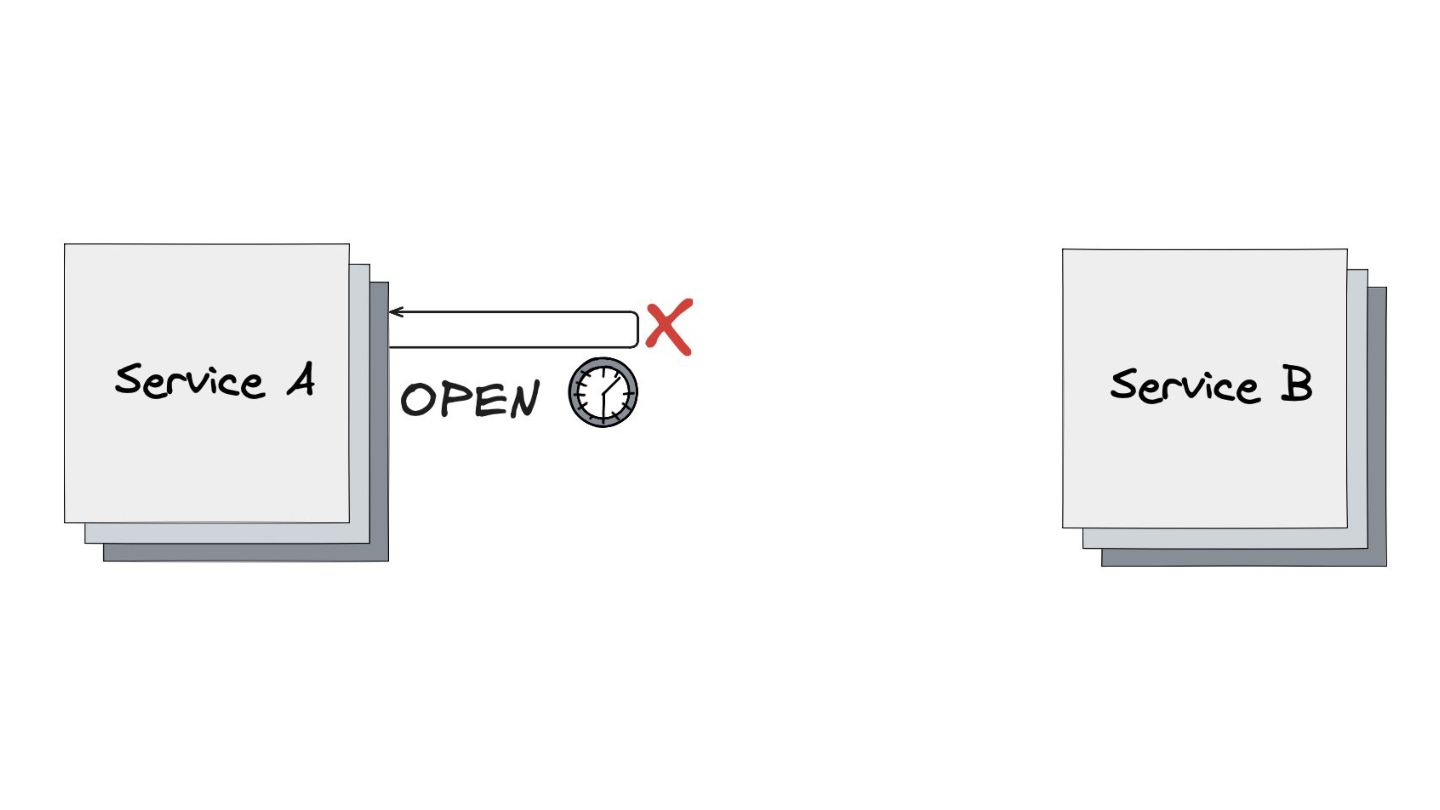
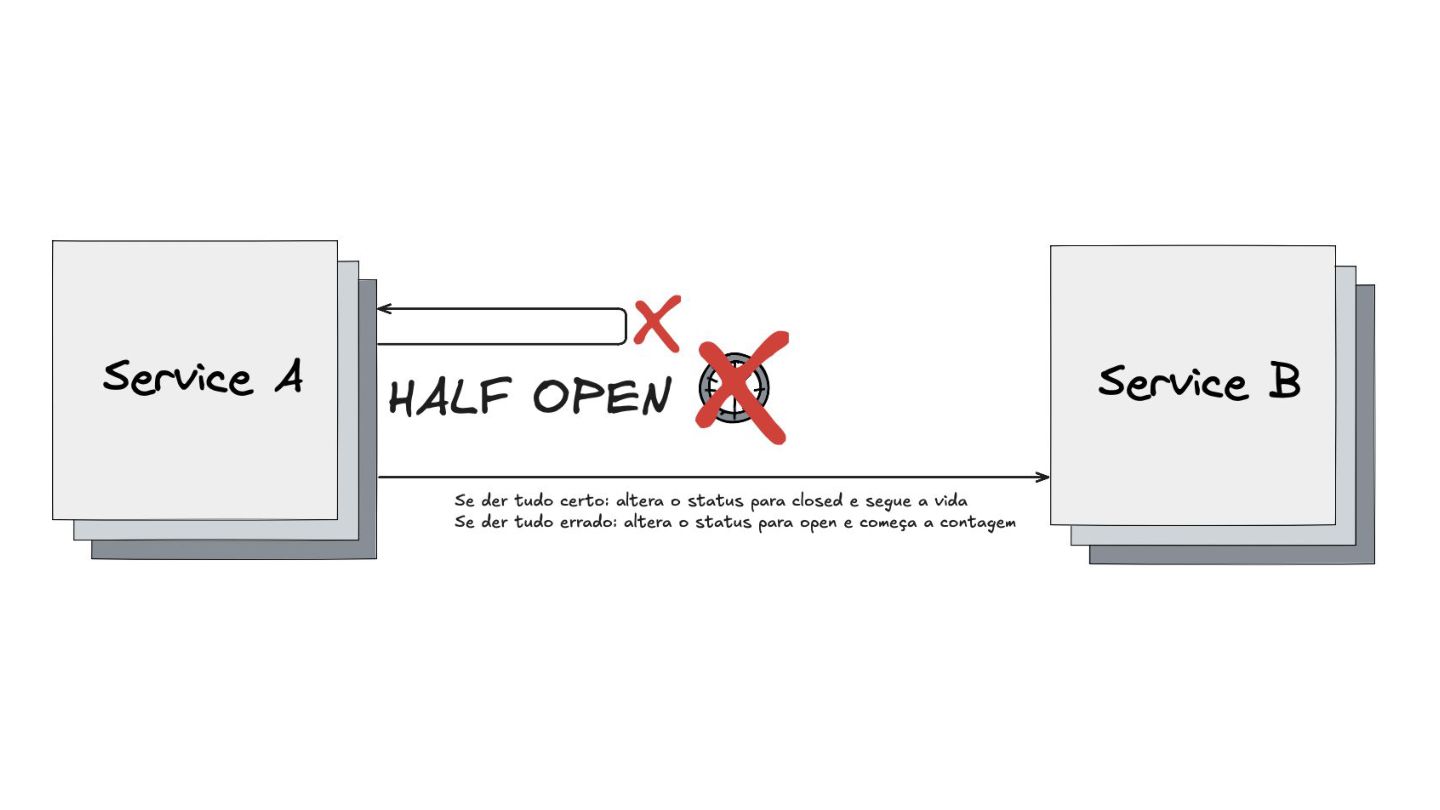
Circuit Breaker: Inspirado em disjuntores elétricos , este padrão evita uma cascata de falhas. Ele interrompe as chamadas para um serviço instável depois de um certo número de erros e só tenta novamente após um período de teste.
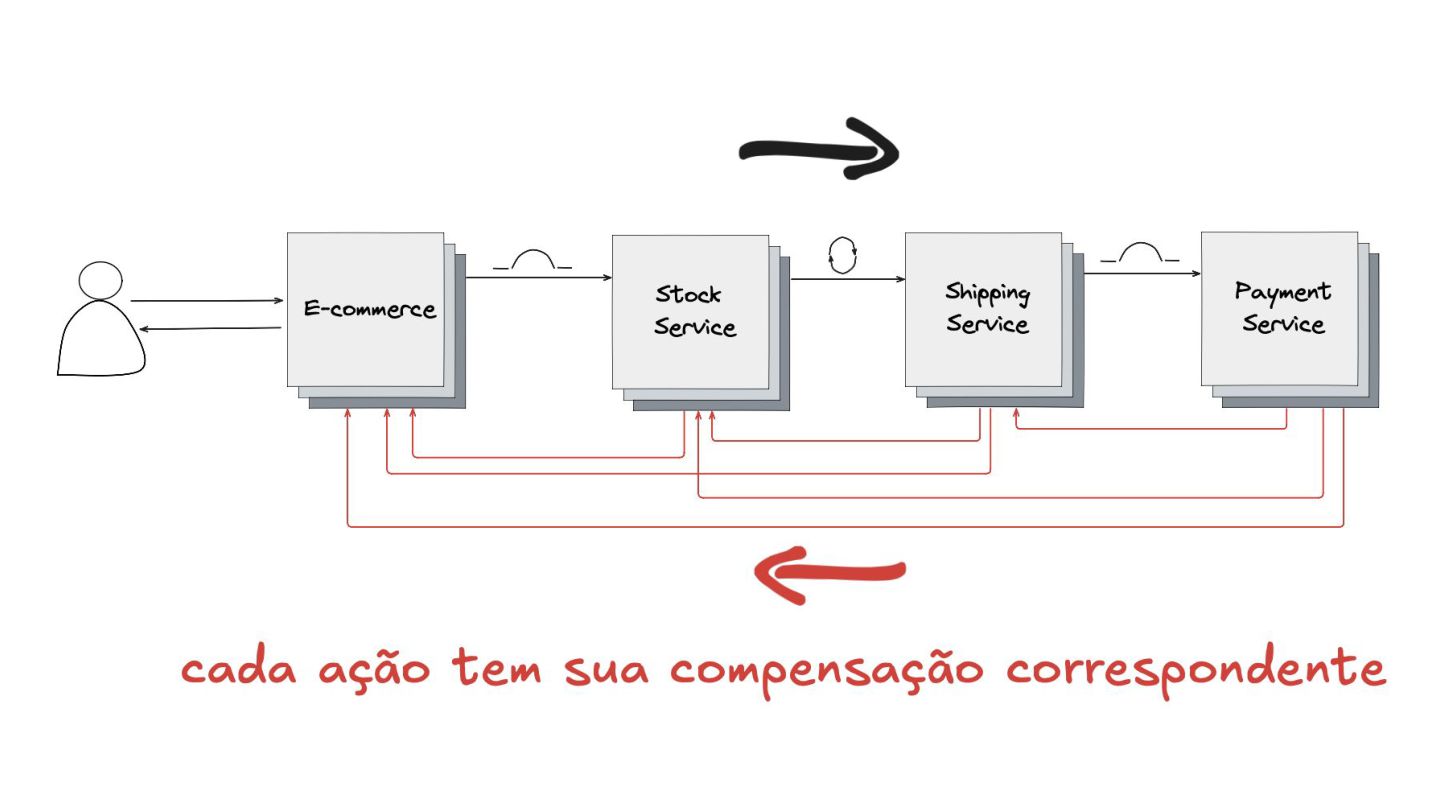
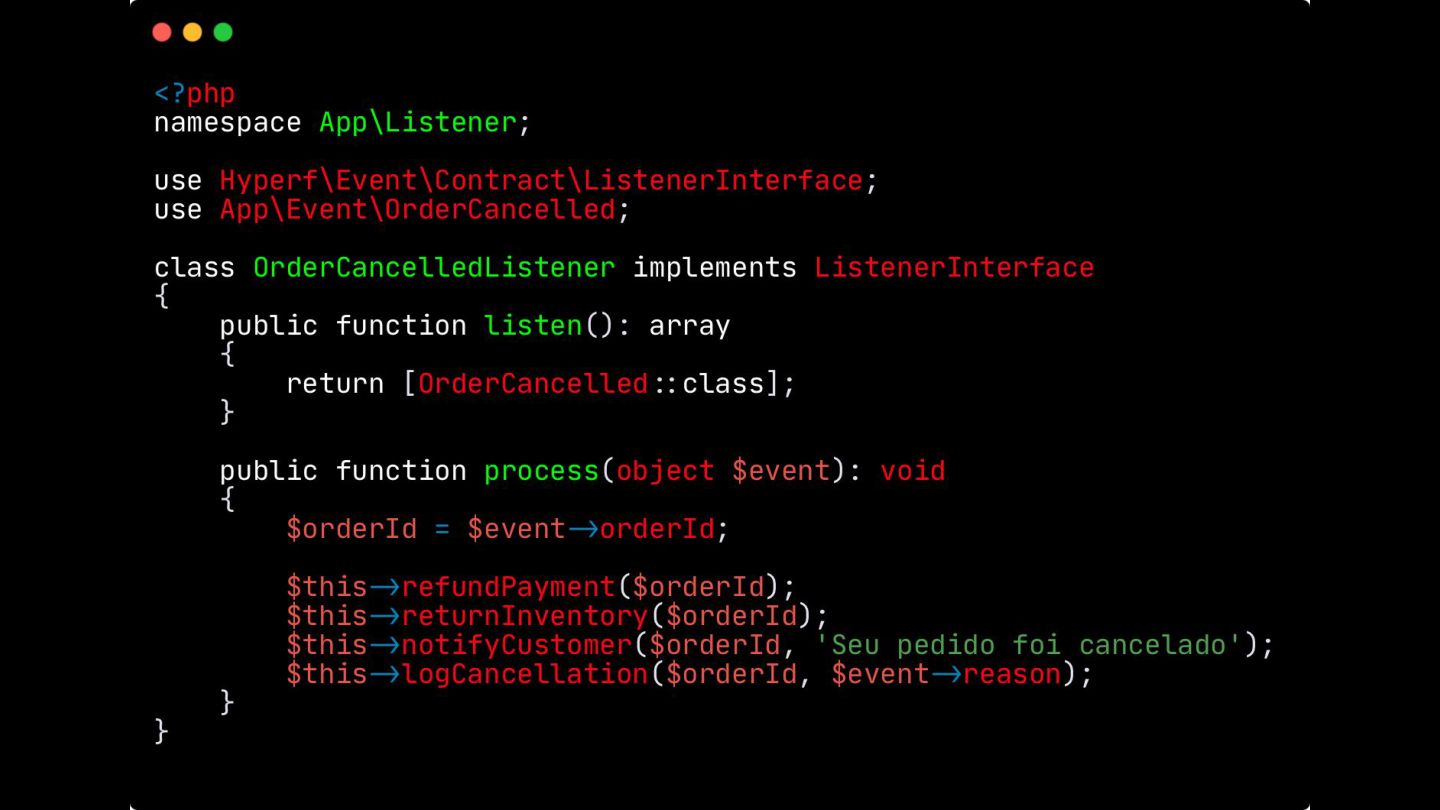
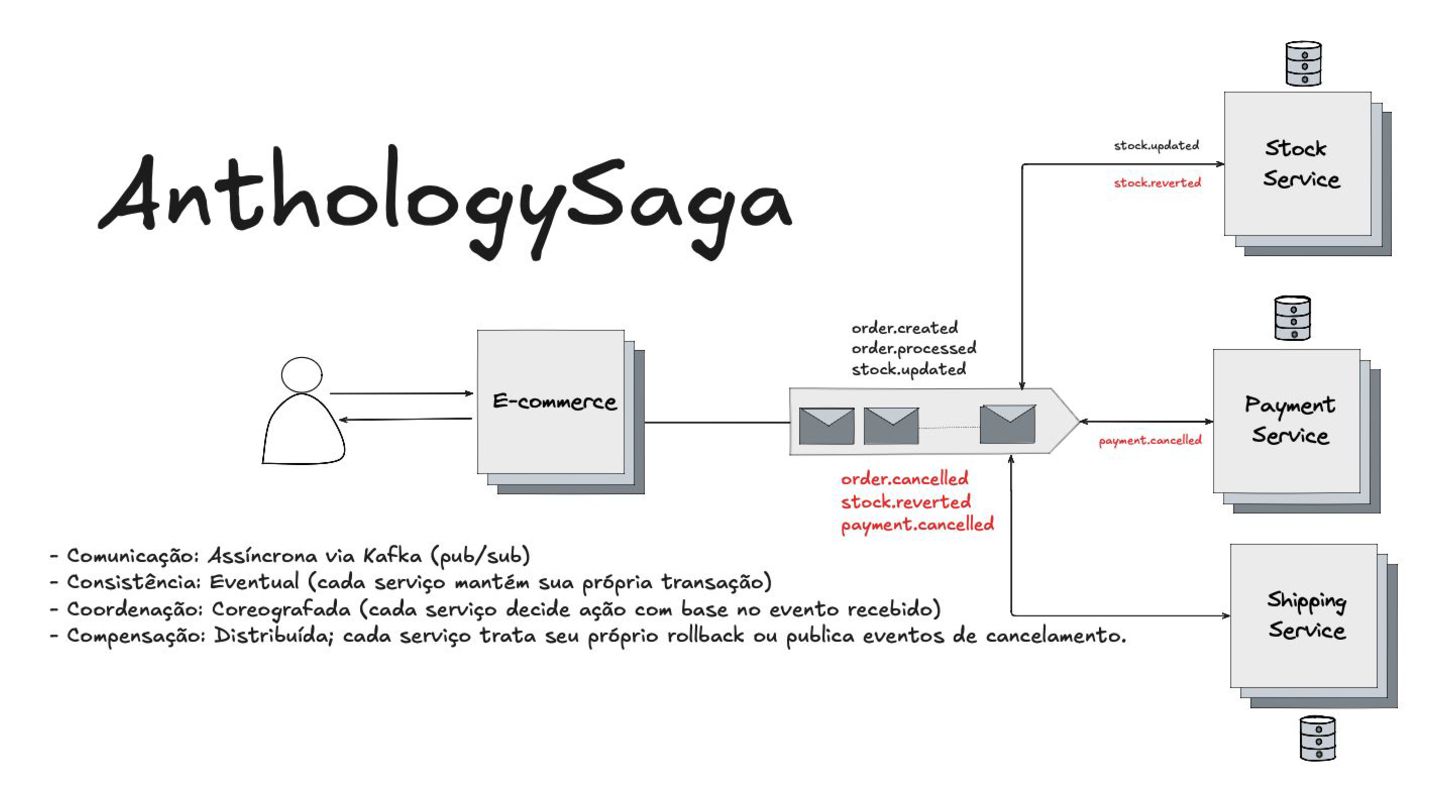
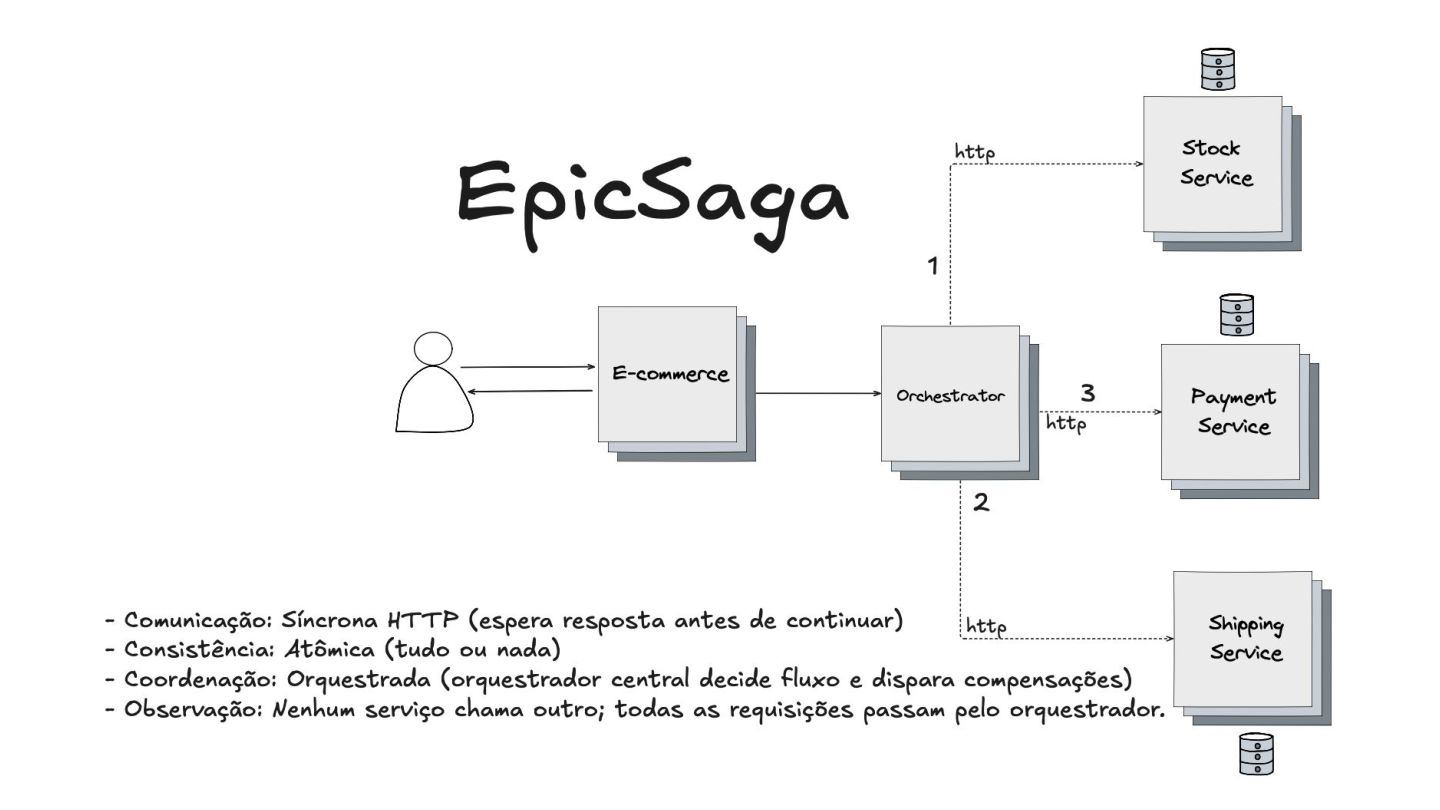
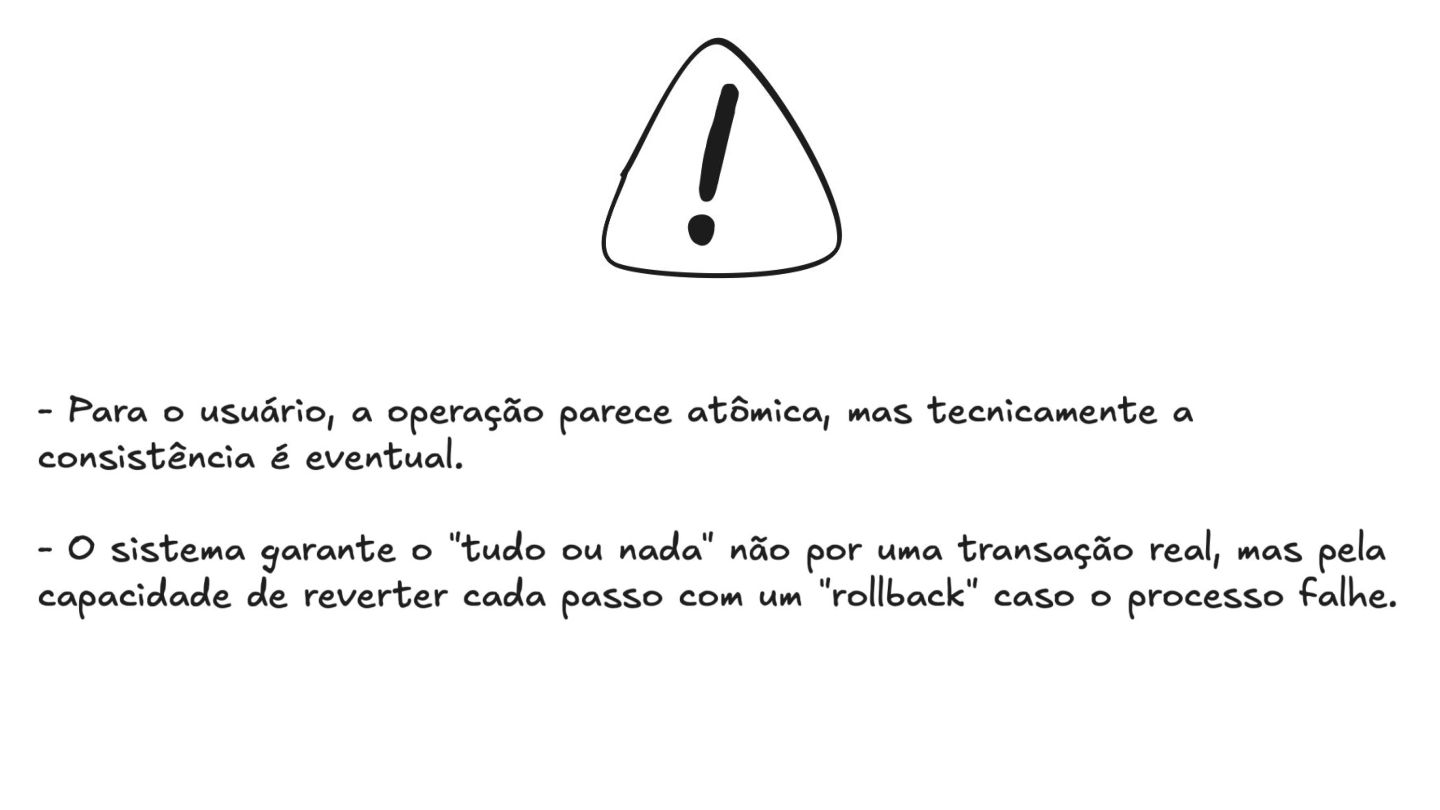
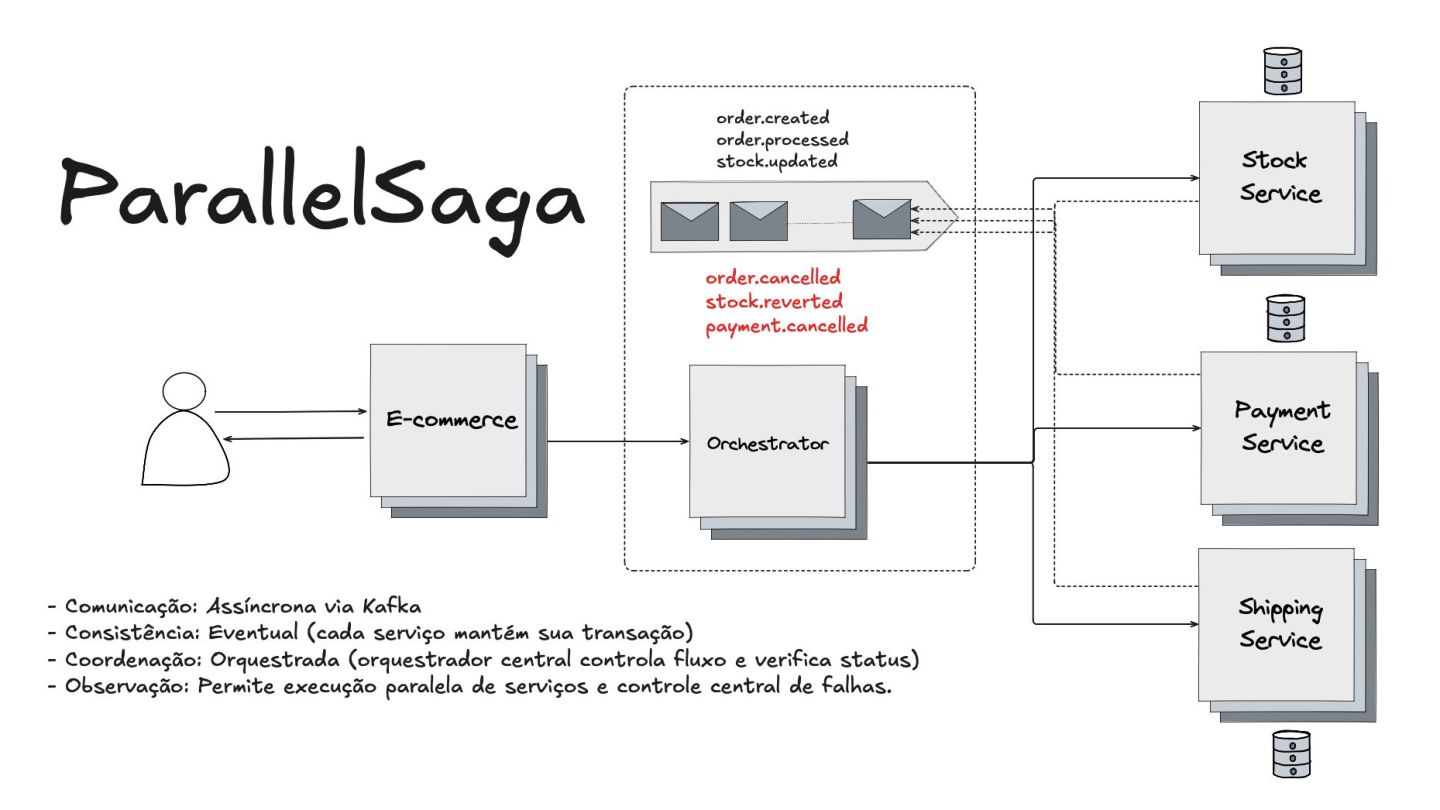
Apresentei também o padrão Saga, uma forma de garantir a consistência das transações em sistemas distribuídos. Eu mostrei como cada ação tem uma compensação correspondente para "desfazer" operações em caso de falha. Em seguida, diferenciei os modelos de comunicação assíncrona (Choreographed Saga) e síncrona (Orchestrated Saga), mostrando soluções para diferentes cenários.
Para finalizar, a minha principal mensagem é que não existe uma "bala de prata" para todos os problemas. O crucial é identificar o que faz mais sentido para o seu contexto e projetar sistemas que não apenas esperam a falha, mas também se recuperam dela de forma controlada.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}