Apps in Java with Jakarta Syed M Shaaf Developer Advocate @ Red Hat Technical Editor @ InfoQ Bazlur Rahman Java Champion 🏆 Staff Software Developer at DNAstack
can’t translate and lack context outside of system boundaries. (e.g. sentiment) • Generating content is costly and sometimes hard. • Rapid data growth • Rising Expectations: Customers demand instant, personalized solutions. • Inefficiency: Manual processes increase costs and slow operations. • Skill Gaps: Limited expertise in AI adoption. Systems, Data, Networks and a Solution?
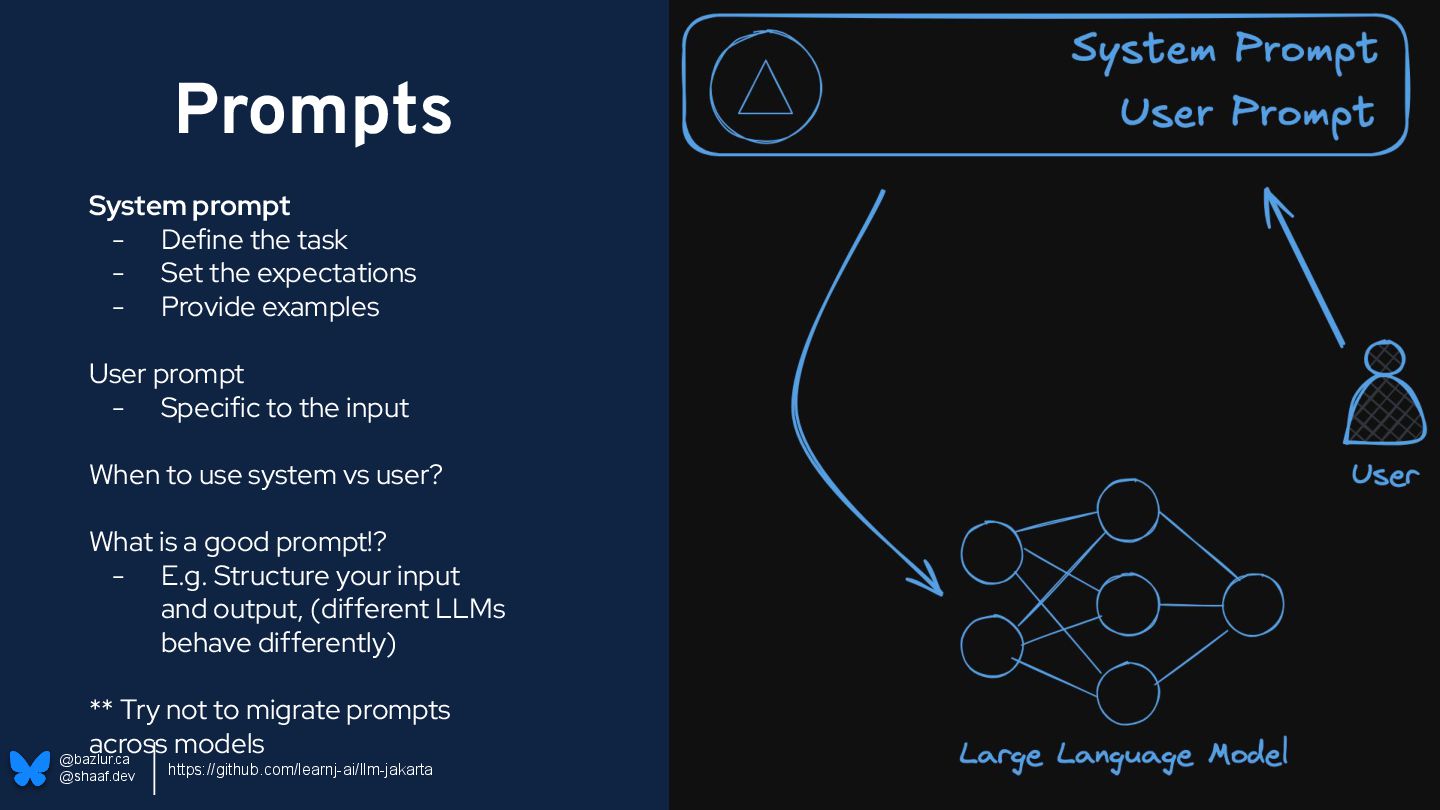
- Set the expectations - Provide examples User prompt - Specific to the input When to use system vs user? What is a good prompt!? - E.g. Structure your input and output, (different LLMs behave differently) ** Try not to migrate prompts across models
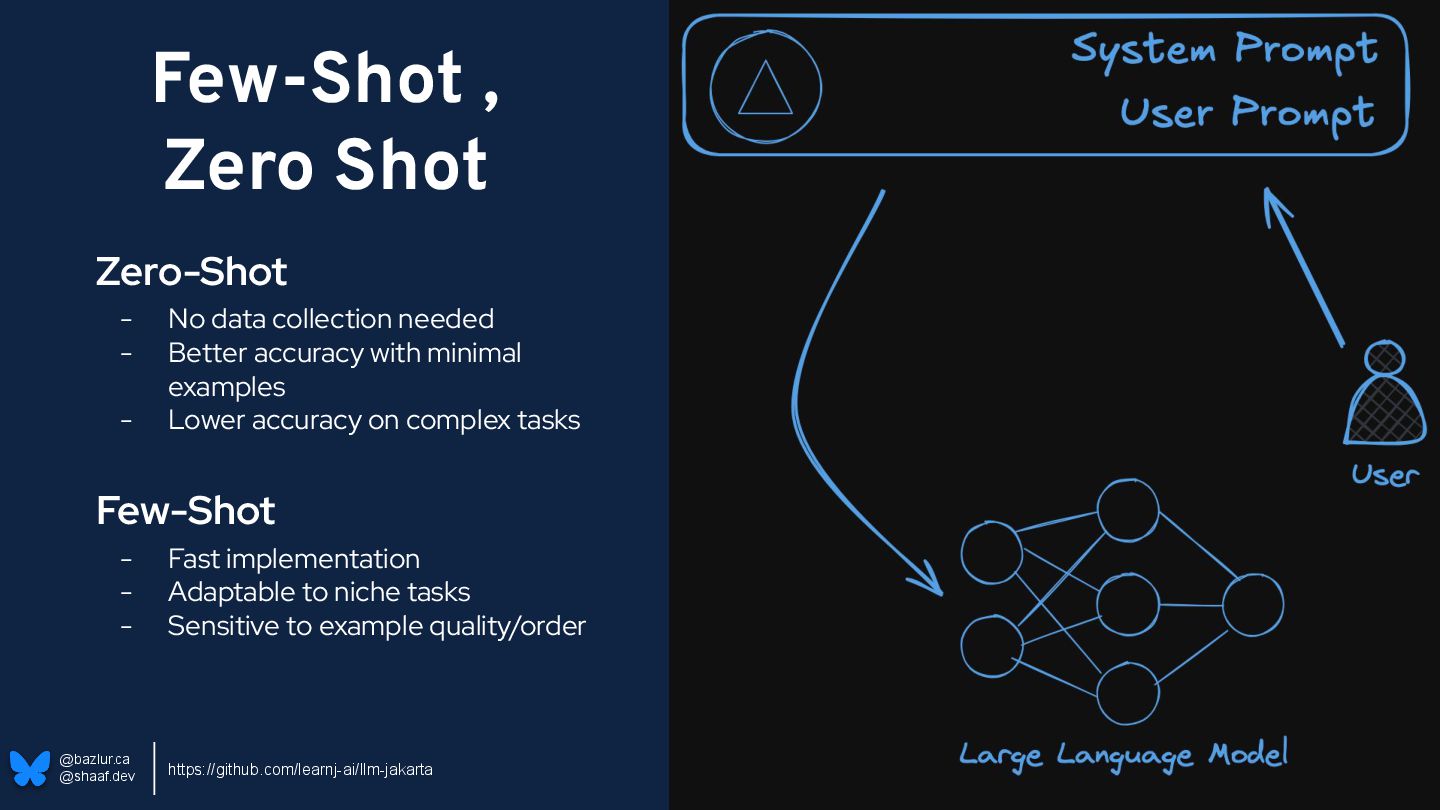
data collection needed - Better accuracy with minimal examples - Lower accuracy on complex tasks Few-Shot - Fast implementation - Adaptable to niche tasks - Sensitive to example quality/order
of the data? How do I want to split? Per document Chapter Sentence How many tokens do I want to end up with? How much overlap is there between segments?
aim for semantic coherence but have variable chunk sizes. Character (especially recursive) and Word splitters offer size control but risk breaking semantic meaning. Line splitters are for specific line-oriented formats. Regex splitters provide maximum flexibility for known structures.
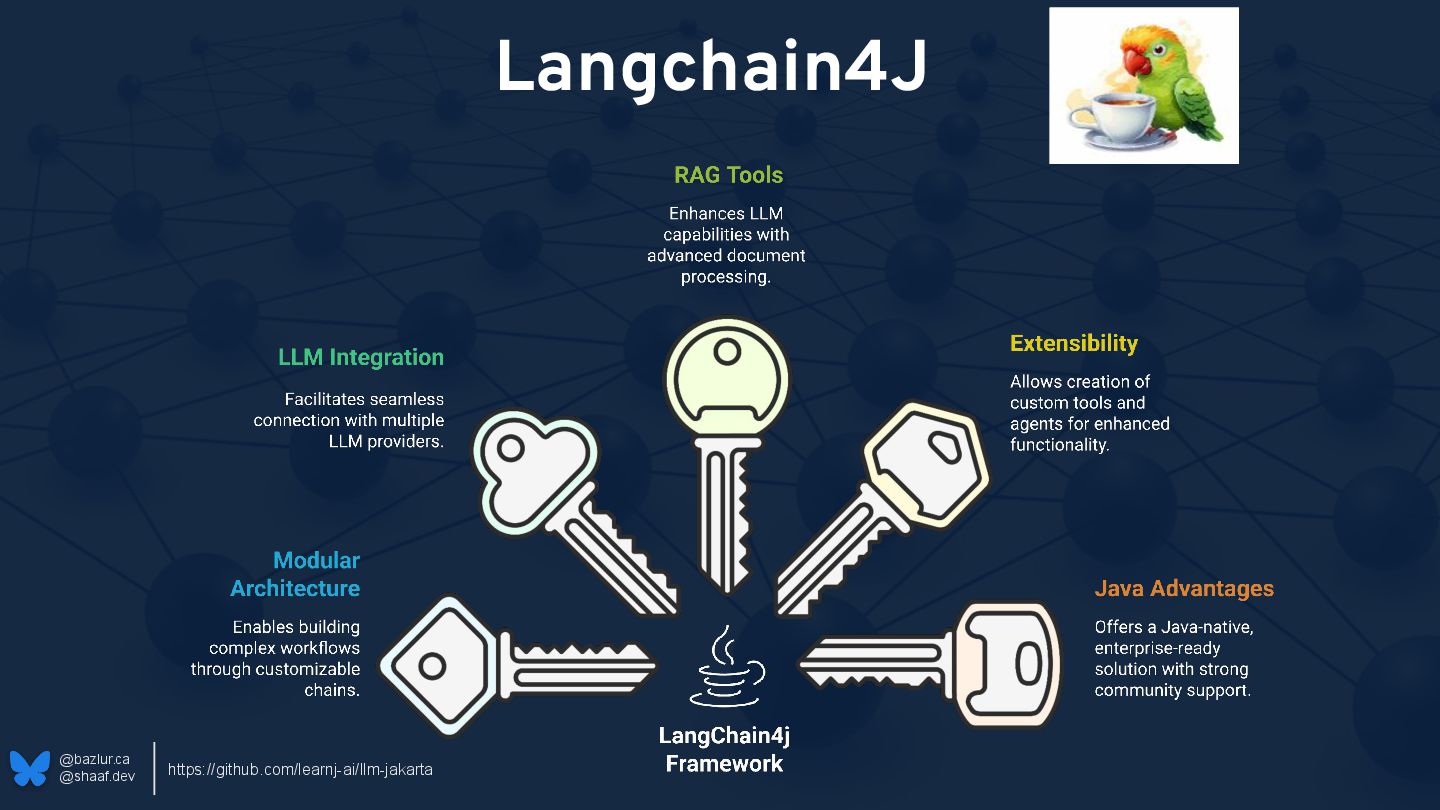
Hat Bazlur Rahman Java Champion 🏆 Empowering Developers through Speaking 🗣 Writing ✍ Mentoring 🤝 & Community Building 🌍 Published Author 📖 Contributing Editor at InfoQ and Foojay.IO fosstodon.org/@shaaf sshaaf https://www.linkedin.com/in/shaaf/ shaaf.dev https://bsky.app/profile/shaaf.dev https://x.com/bazlur_rahman rokon12 https://www.linkedin.com/in/bazlur/ https://bazlur.ca/ https://bsky.app/profile/bazlur.ca Source for the demo https://github.com/learnj-ai/llm-jakarta https://docs.langchain4j.dev/ LangChain4J
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}