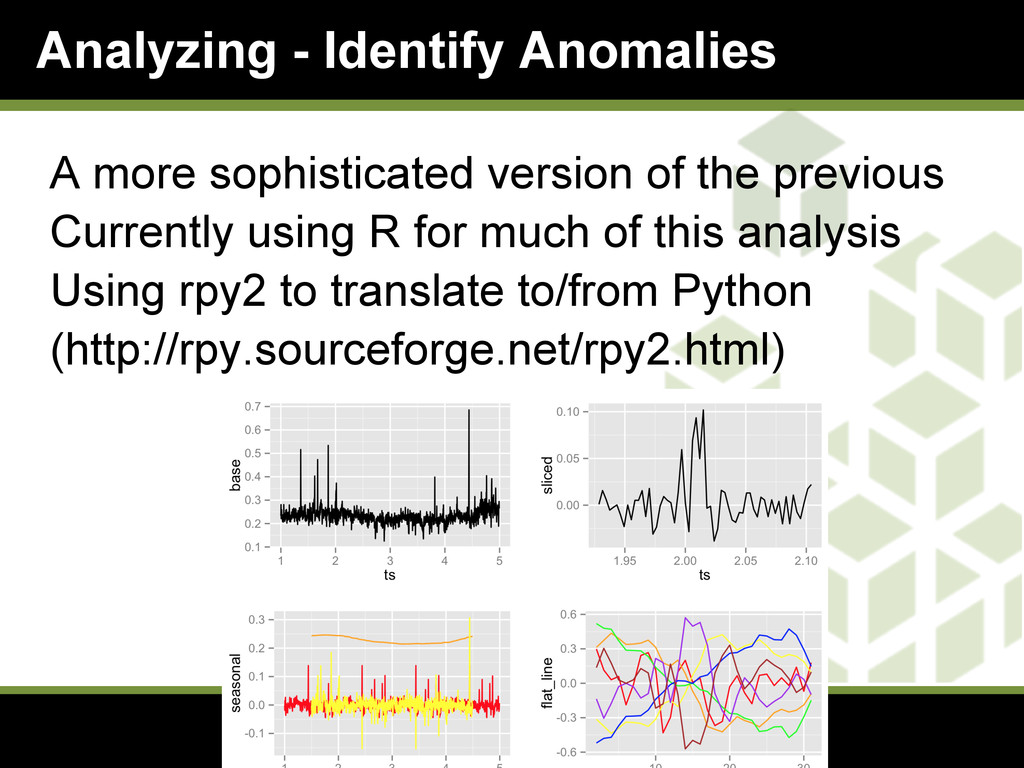
In his presentation (first delivered at the Boston AWS meetup on June 10th, 2013), Stackdriver's Patrick Eaton describes the role of analytics in the Stackdriver Intelligent Monitoring service. He highlights three techniques that we use and share a little bit about the tools and algorithms behind the analysis
![Analytics in AWS Patrick Eaton, PhD [email protected] @PatrickREaton](https://files.speakerdeck.com/presentations/5553e7a0b4fb013088542a4035e60419/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
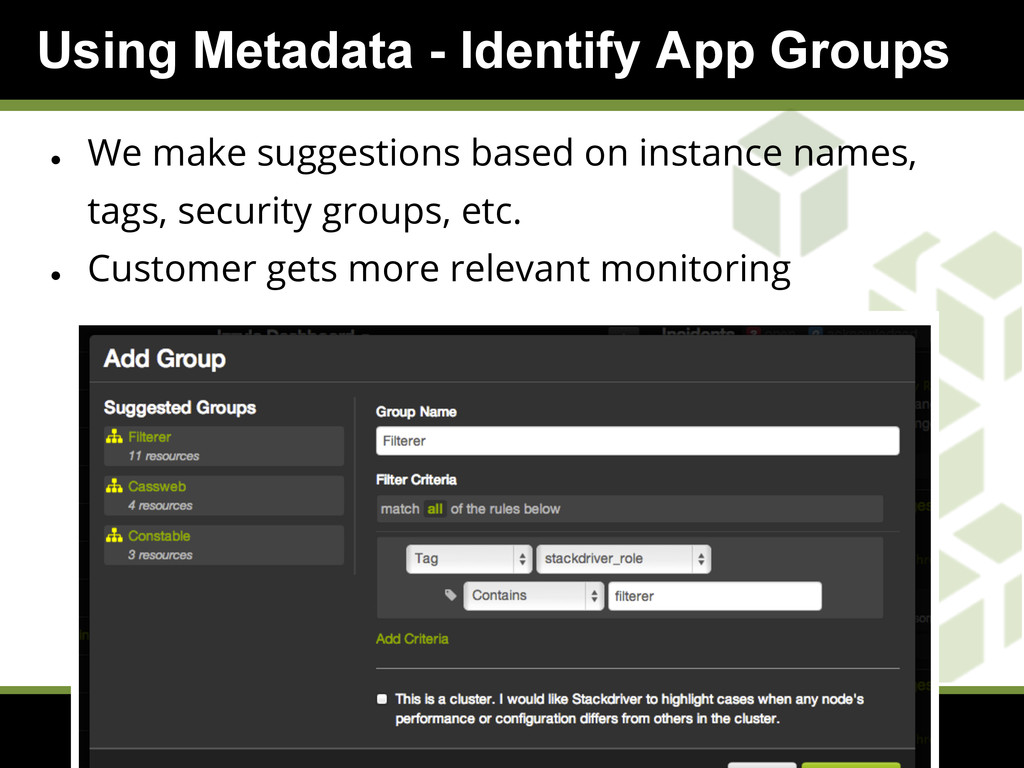{kind=link}
{kind=link}
{kind=link}
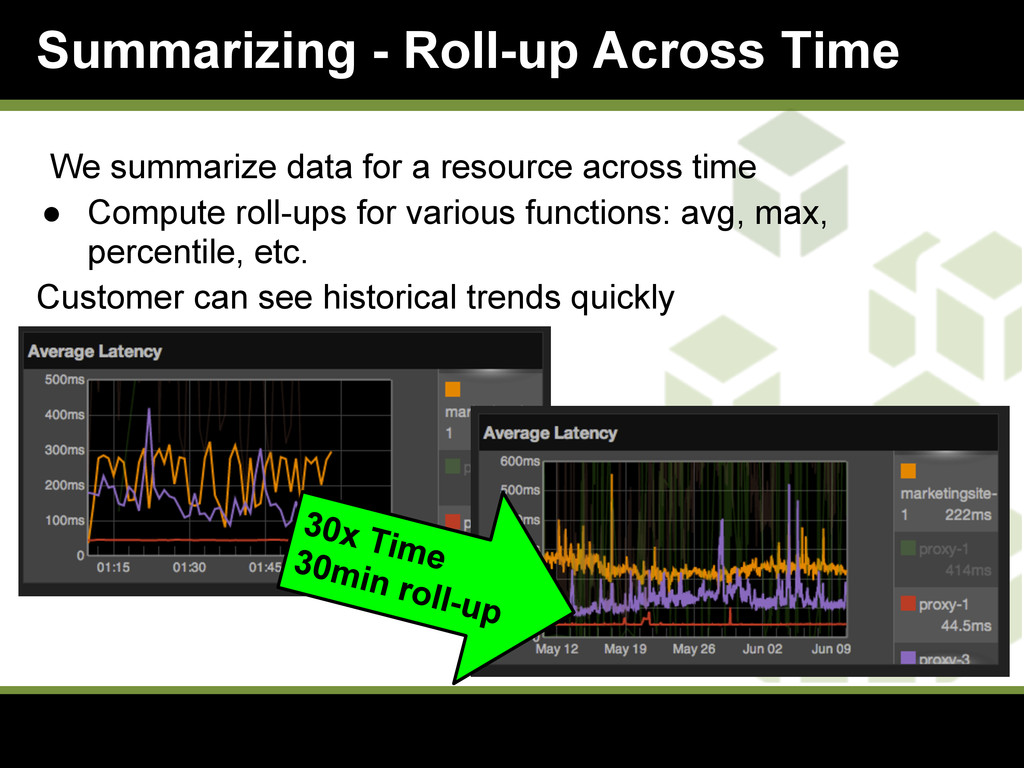{kind=link}
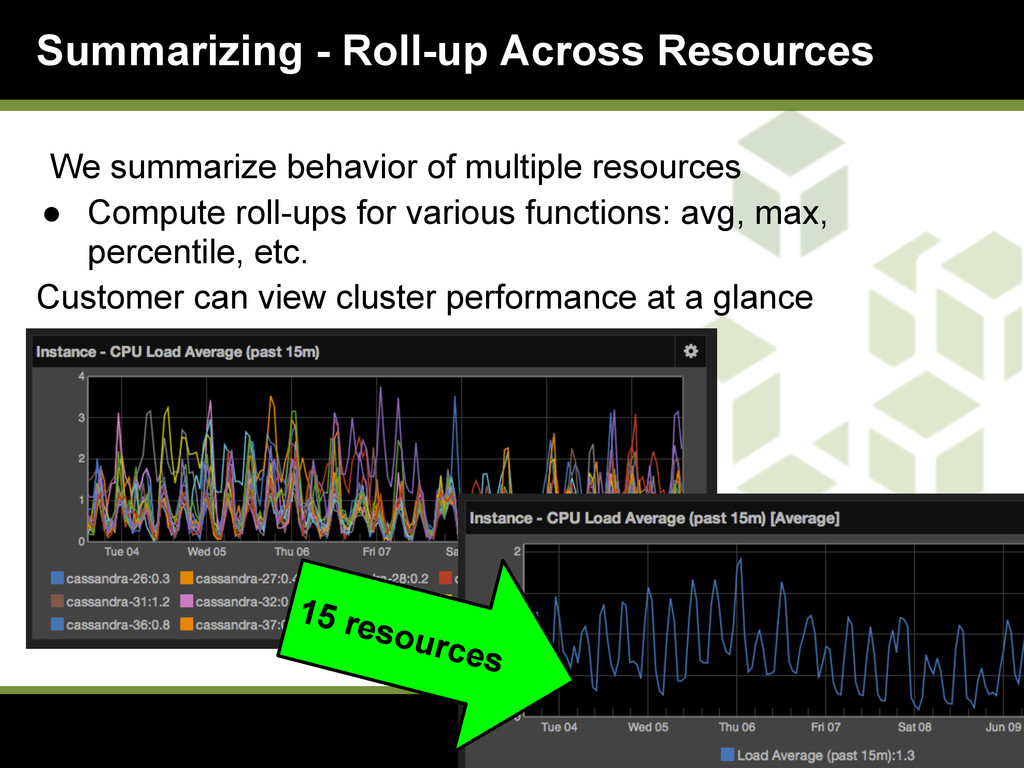{kind=link}
{kind=link}
{kind=link}
{kind=link}
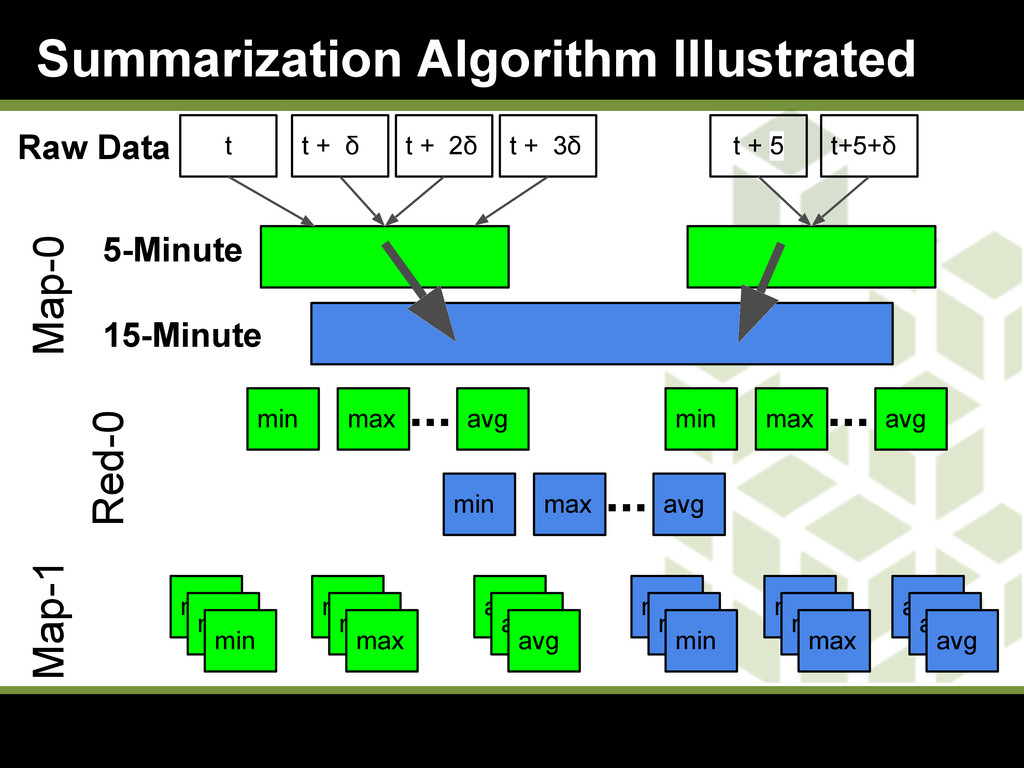{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Yes, we are hiring! Patrick Eaton - [email protected]](https://files.speakerdeck.com/presentations/5553e7a0b4fb013088542a4035e60419/slide_17.jpg){kind=link}