In this presentation (first delivered at the Boston AWS meetup on April 8th, 2013), we highlight our reasons for choosing Cassandra versus other platforms and describe the novel architecture that allows us to tolerate inevitable failures that one would expect running at scale on AWS.
![Running Cassandra in AWS Patrick Eaton, PhD [email protected] @PatrickREaton Joey](https://files.speakerdeck.com/presentations/ef4642f0b4fc0130946502d040a74214/slide_0.jpg){kind=link}
{kind=link}
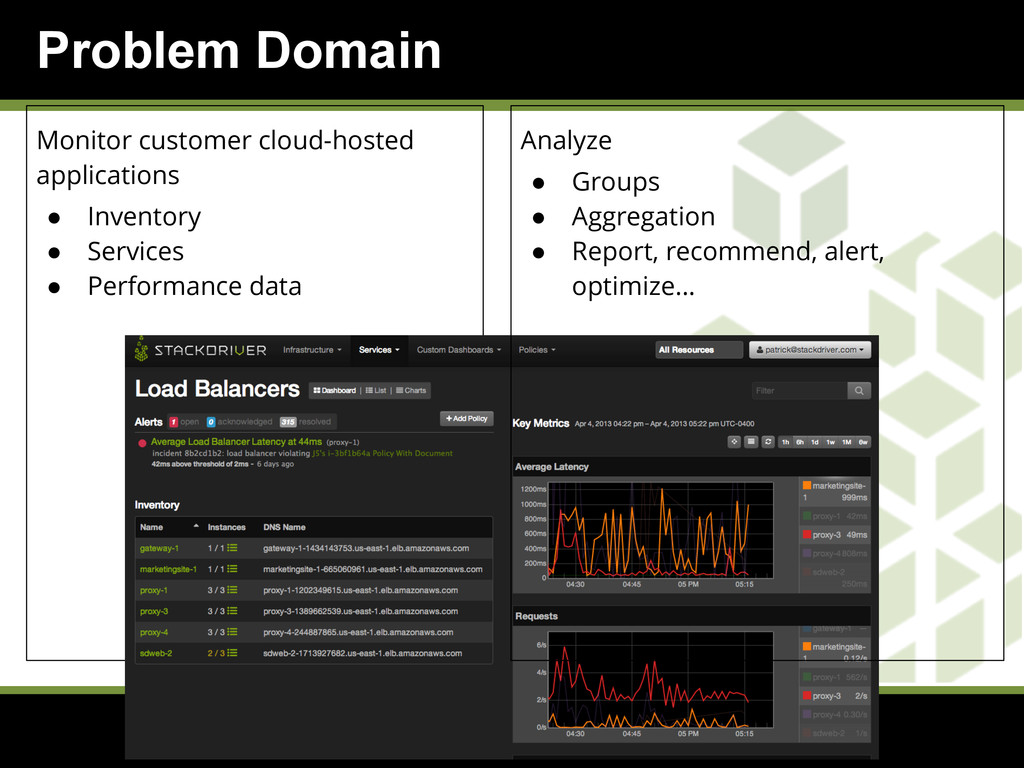{kind=link}
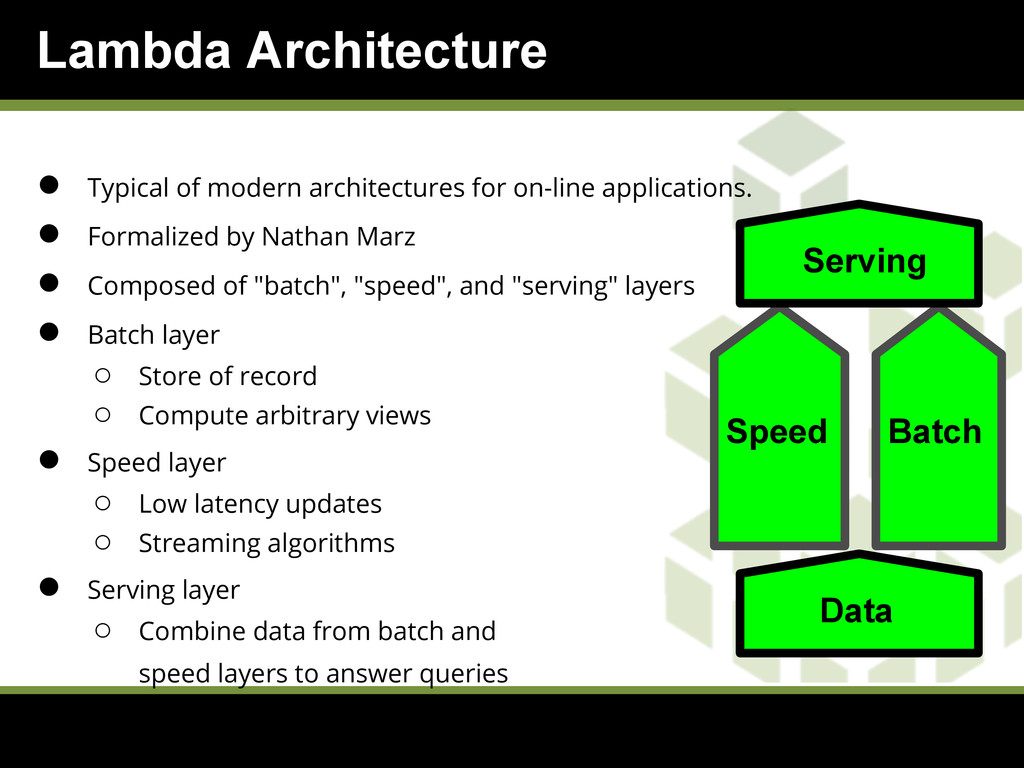{kind=link}
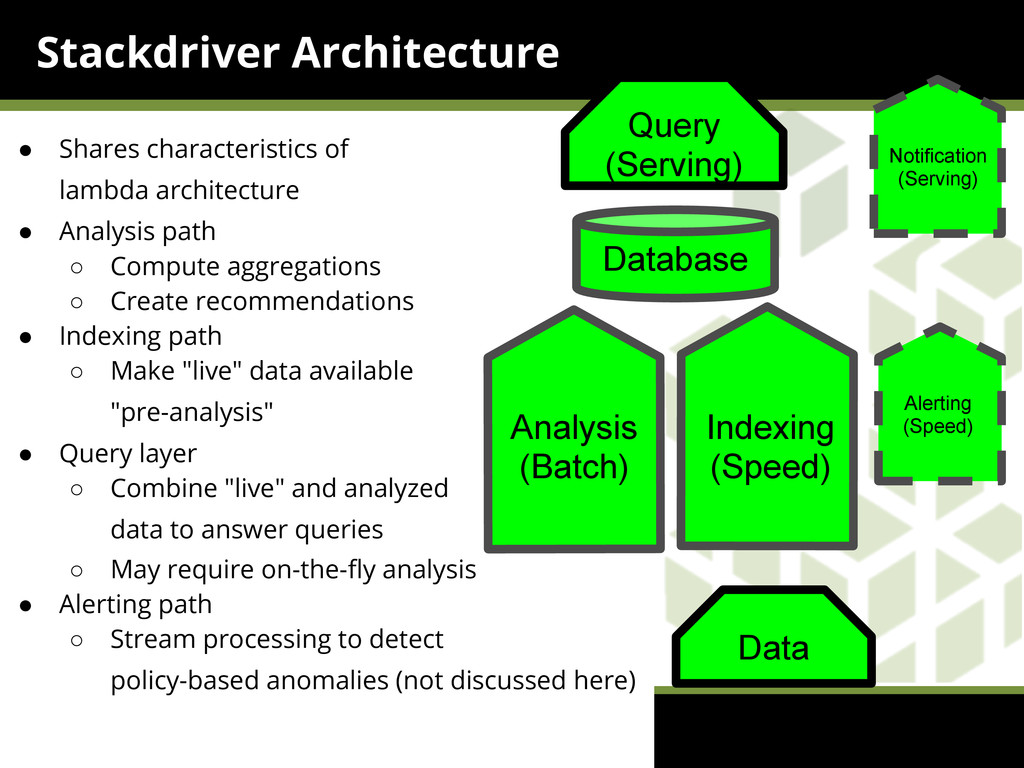{kind=link}
{kind=link}
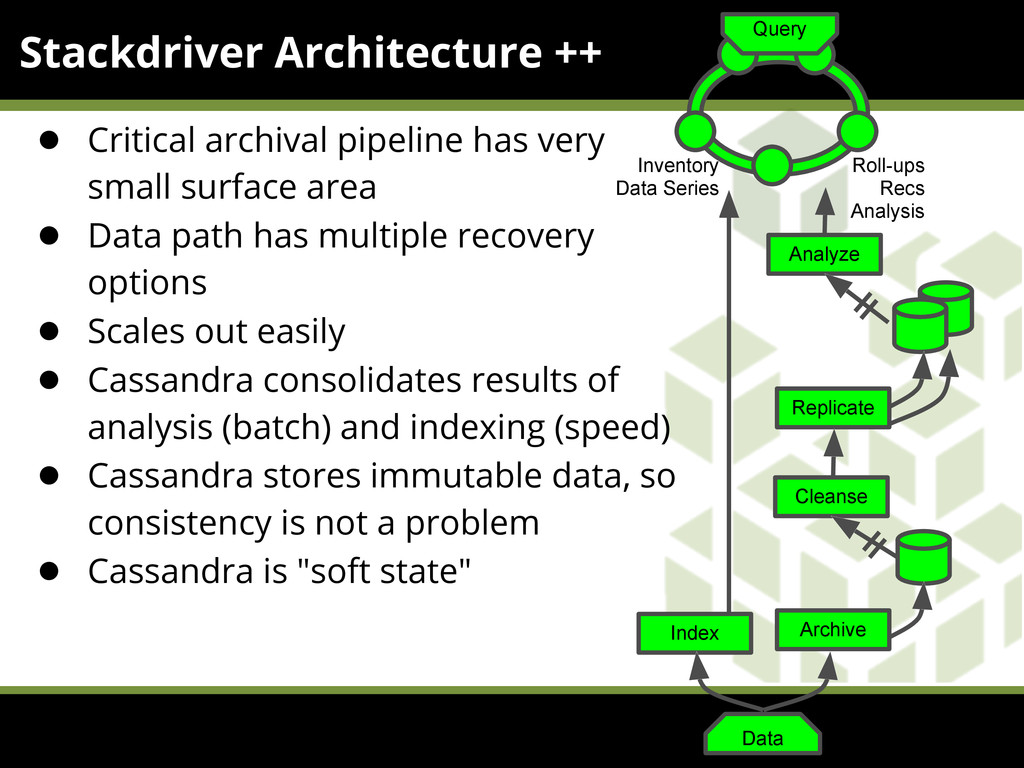{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Yes, we are hiring! Patrick Eaton - [email protected]](https://files.speakerdeck.com/presentations/ef4642f0b4fc0130946502d040a74214/slide_14.jpg){kind=link}