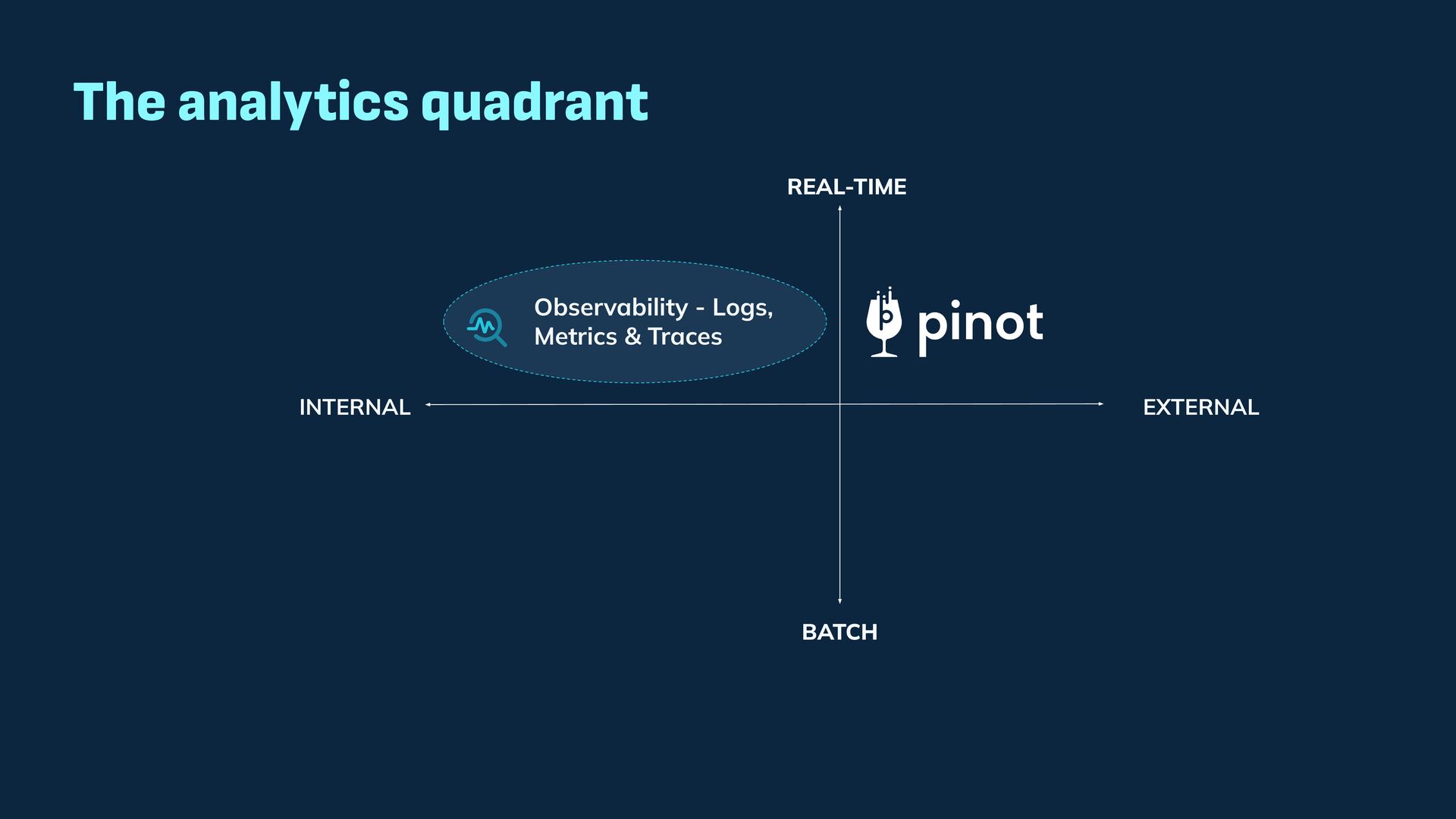
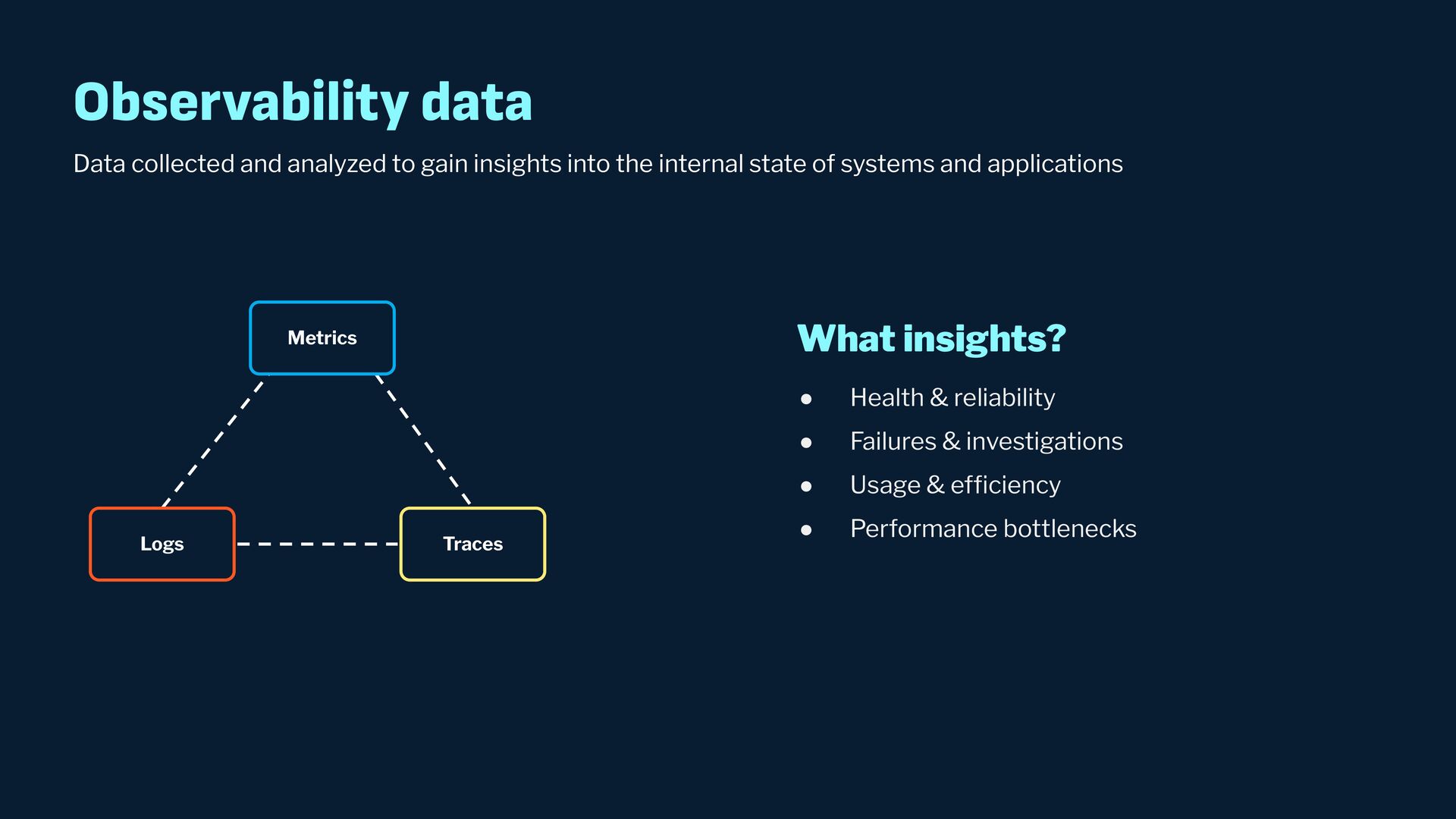
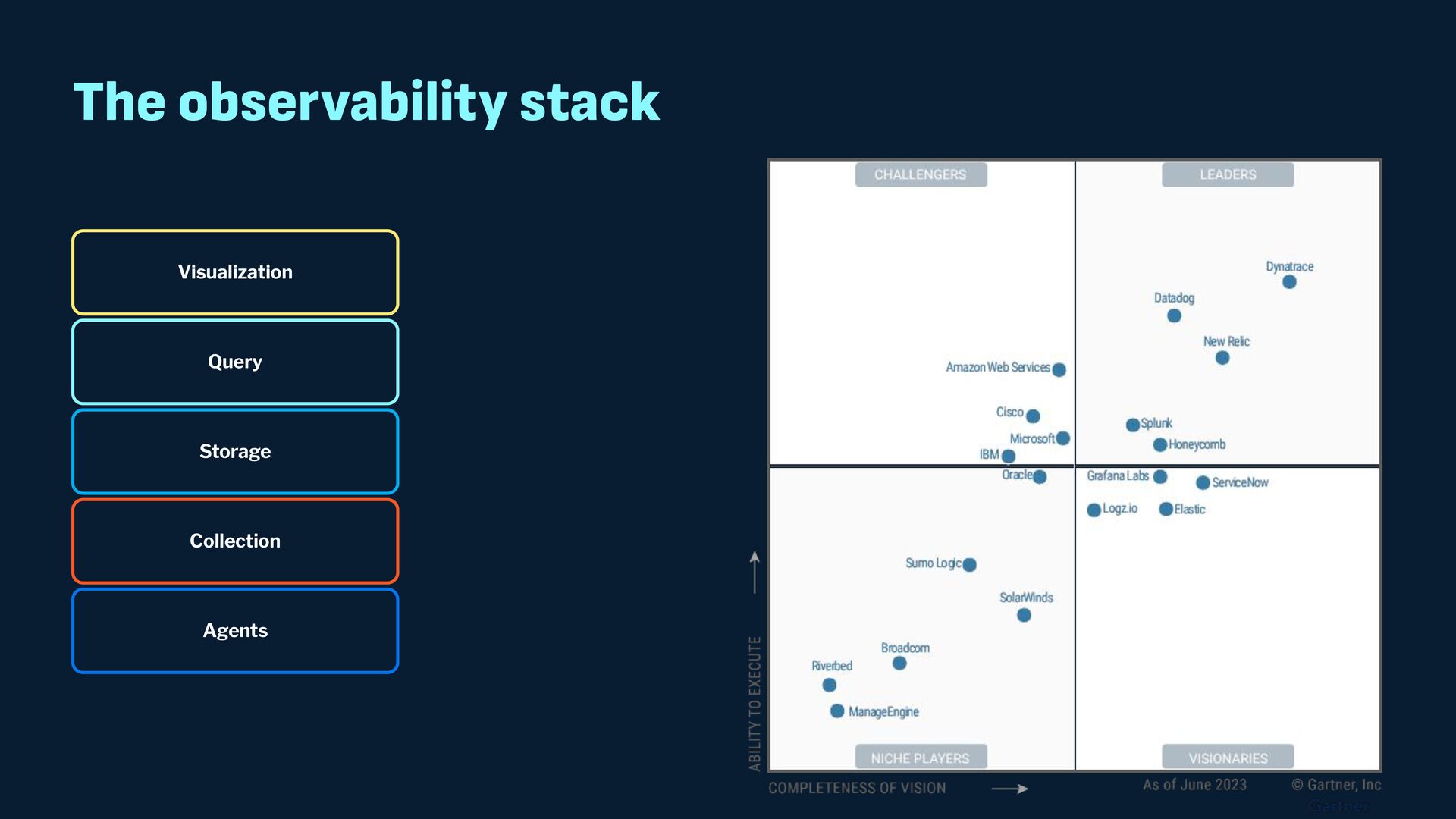
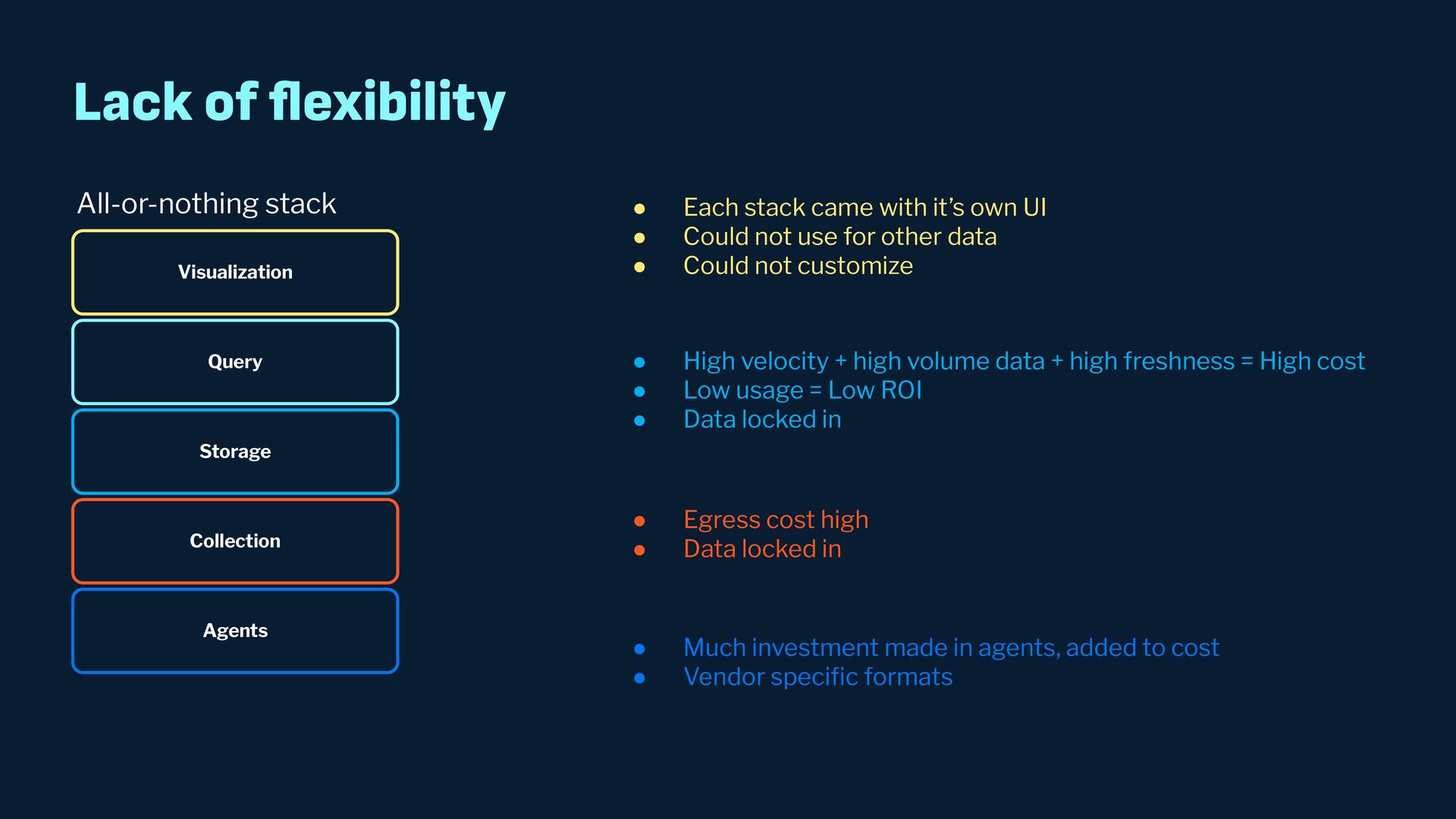
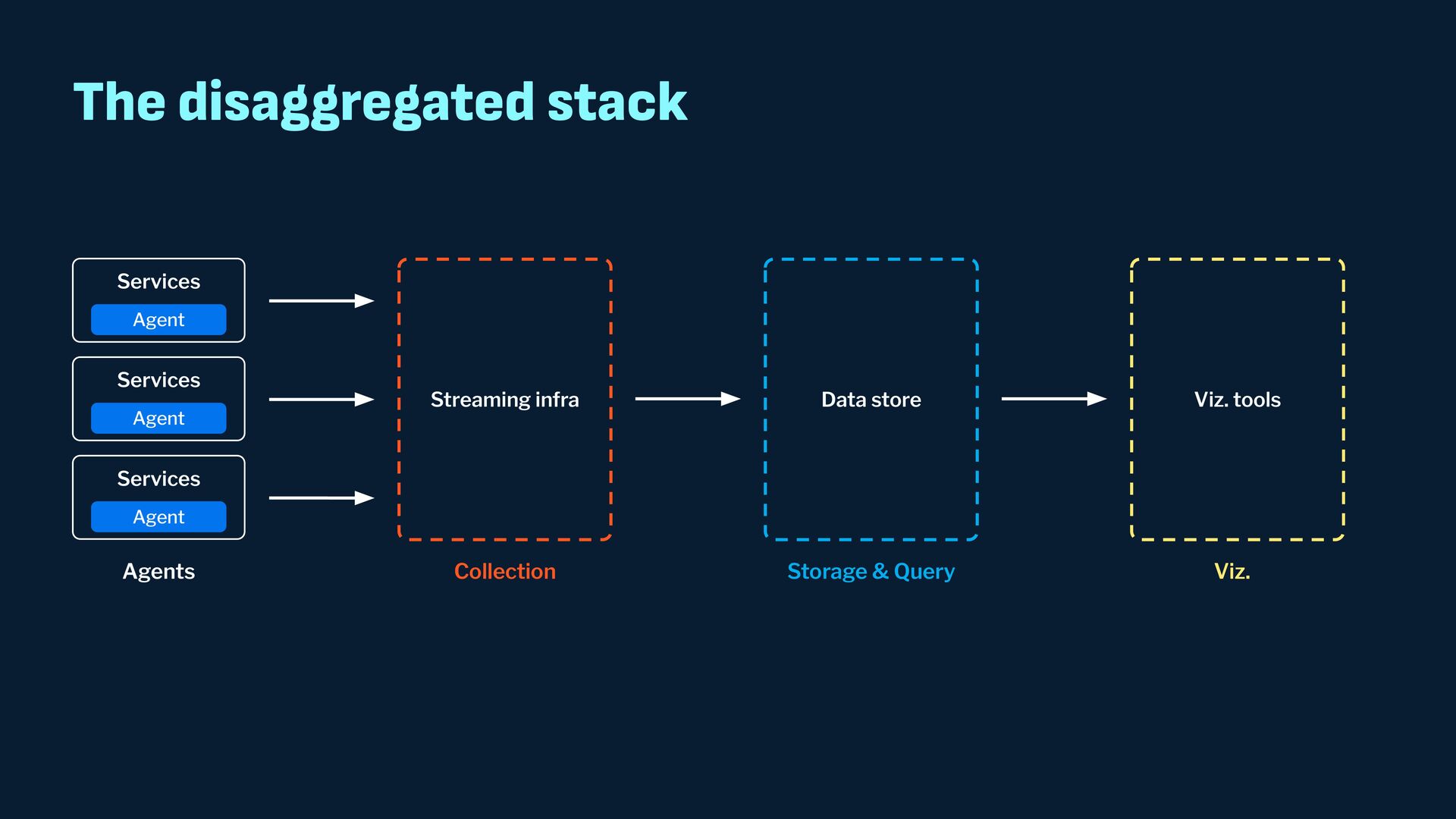
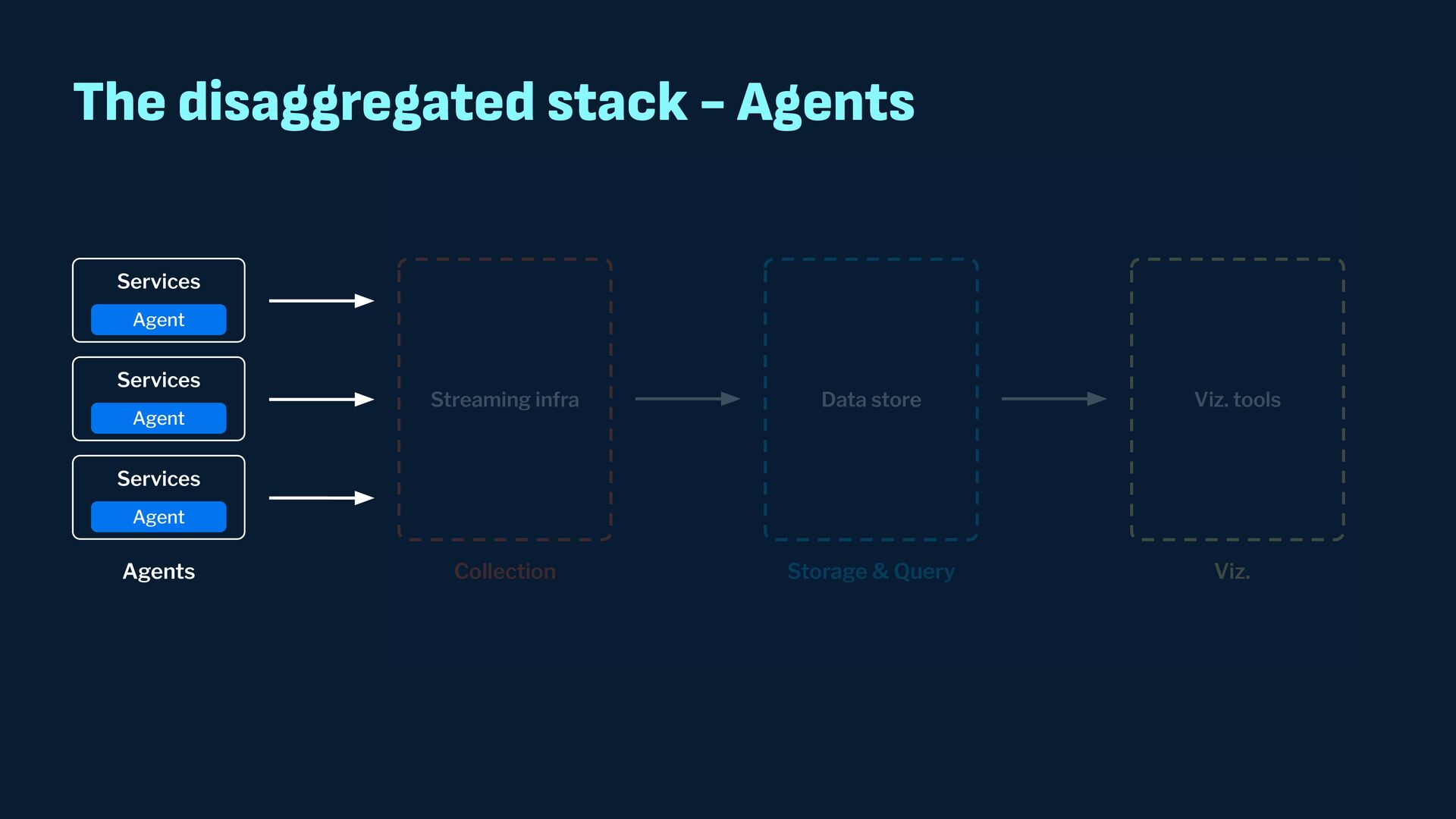
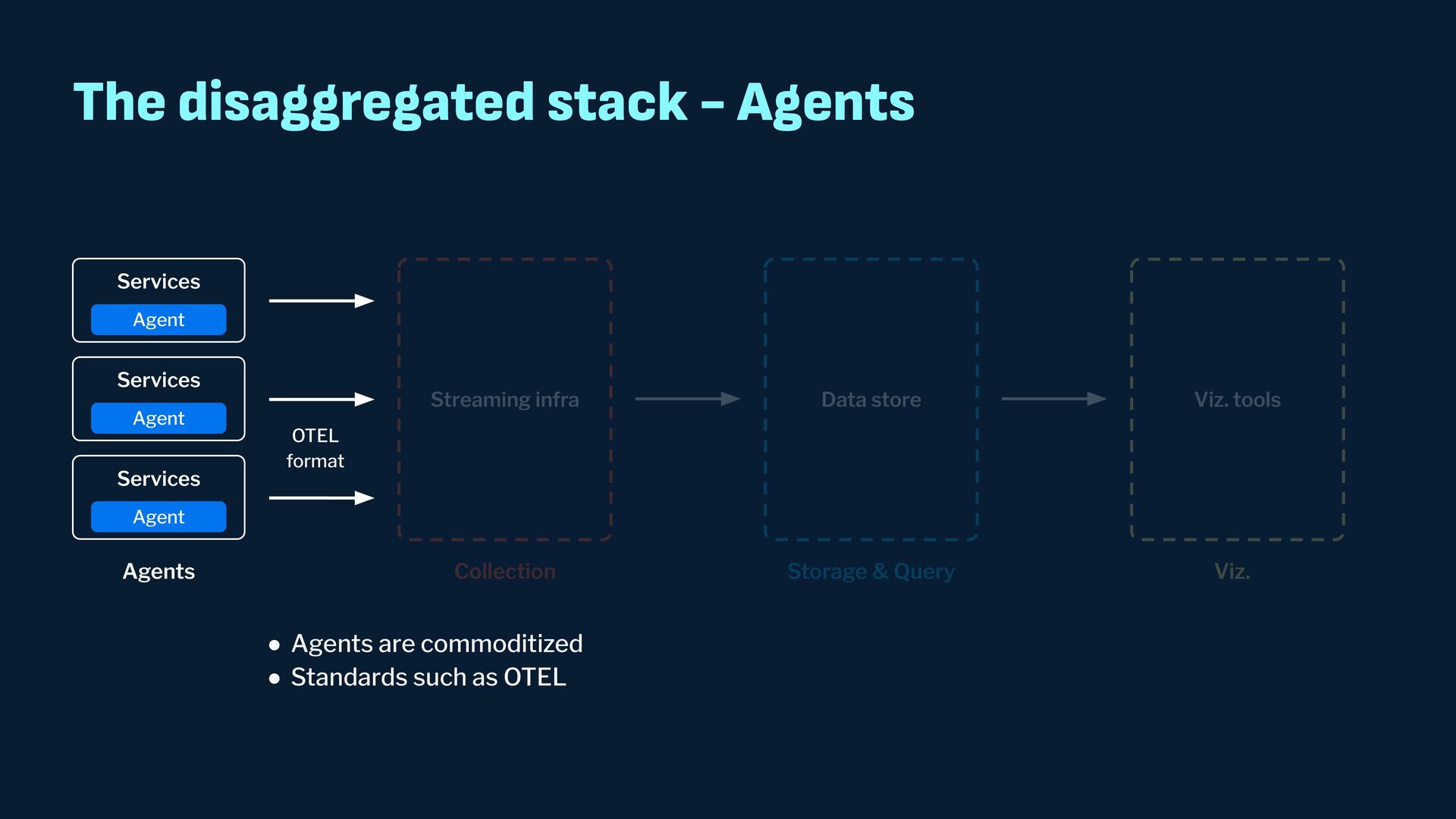
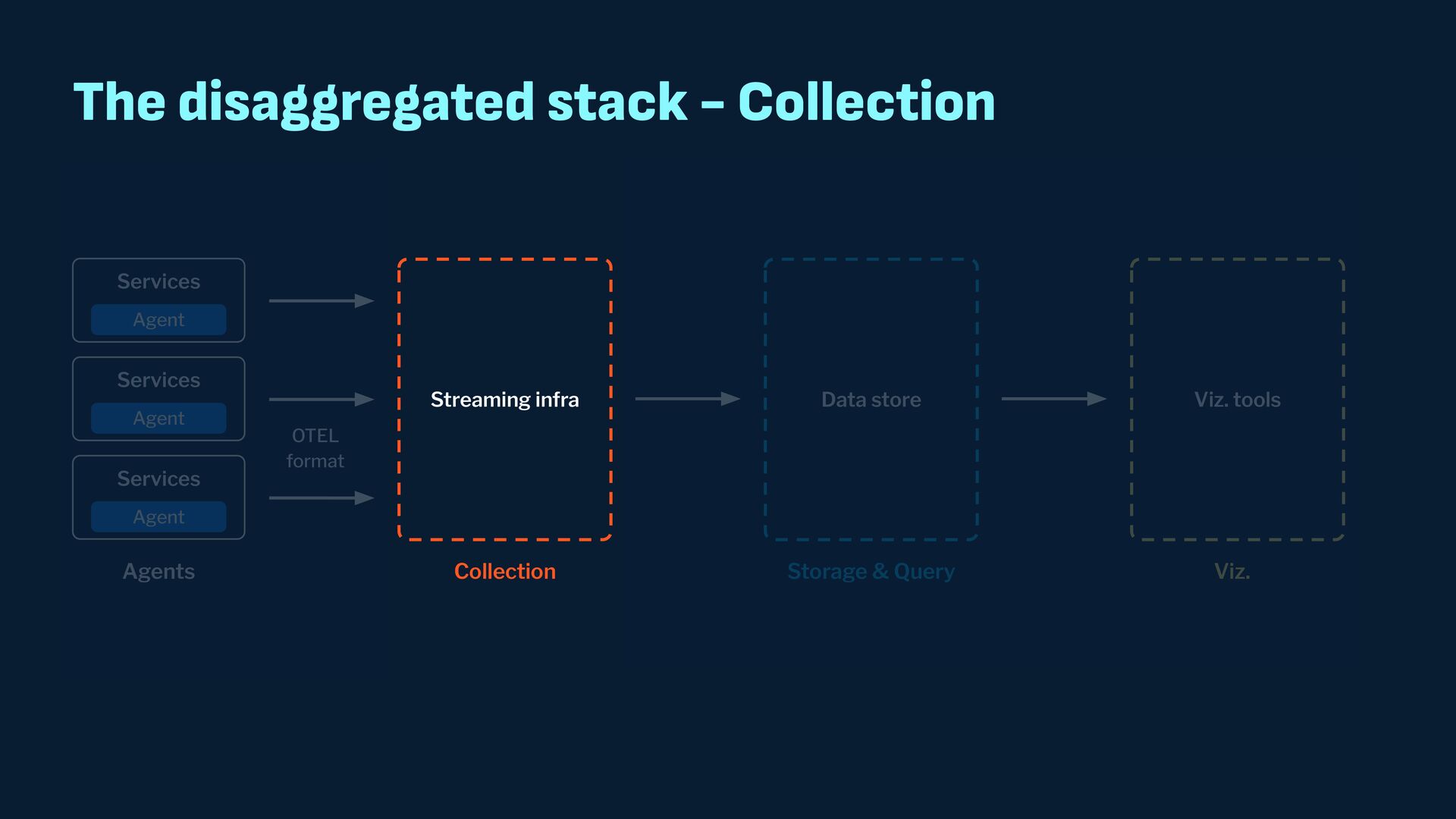
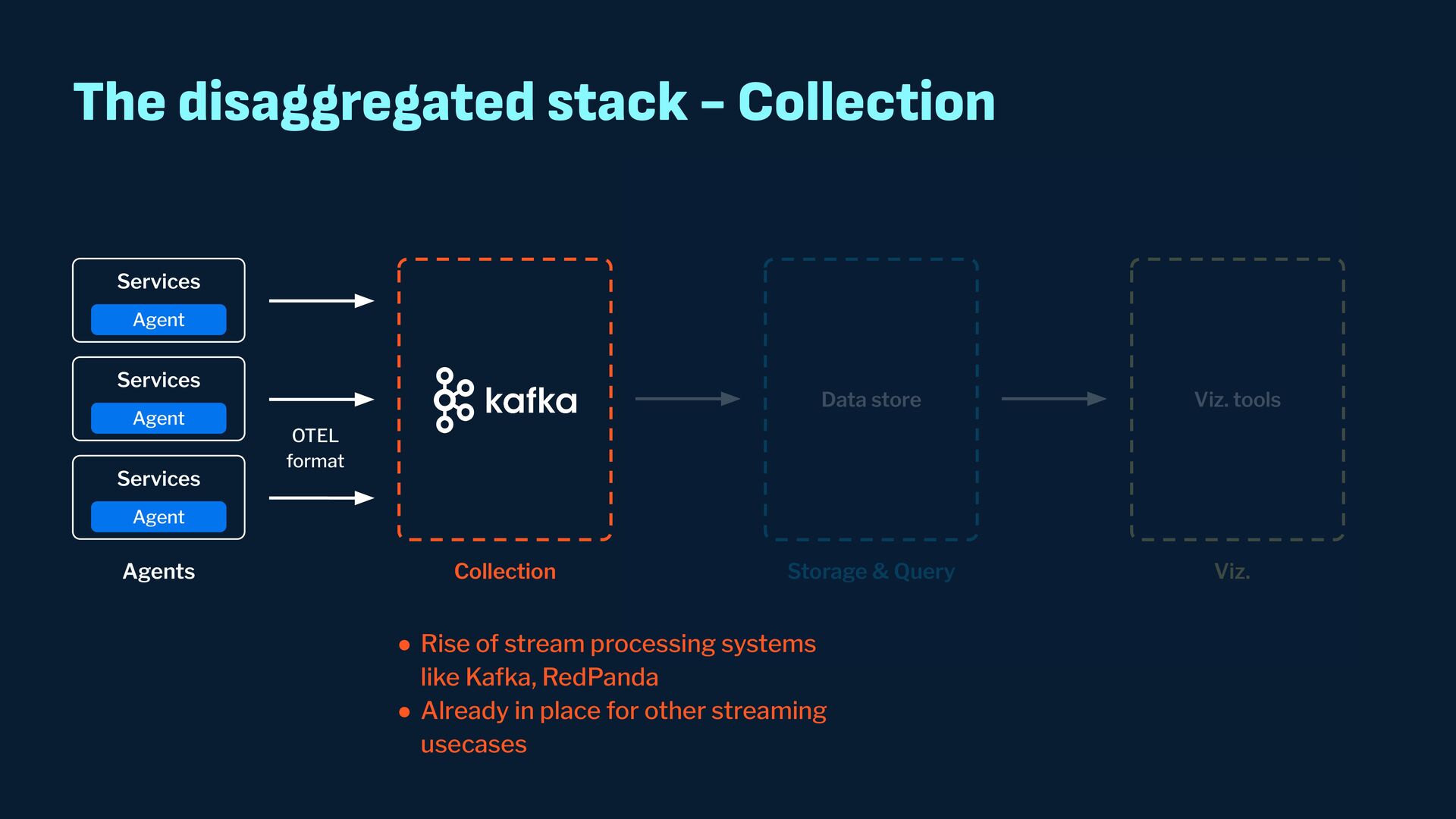
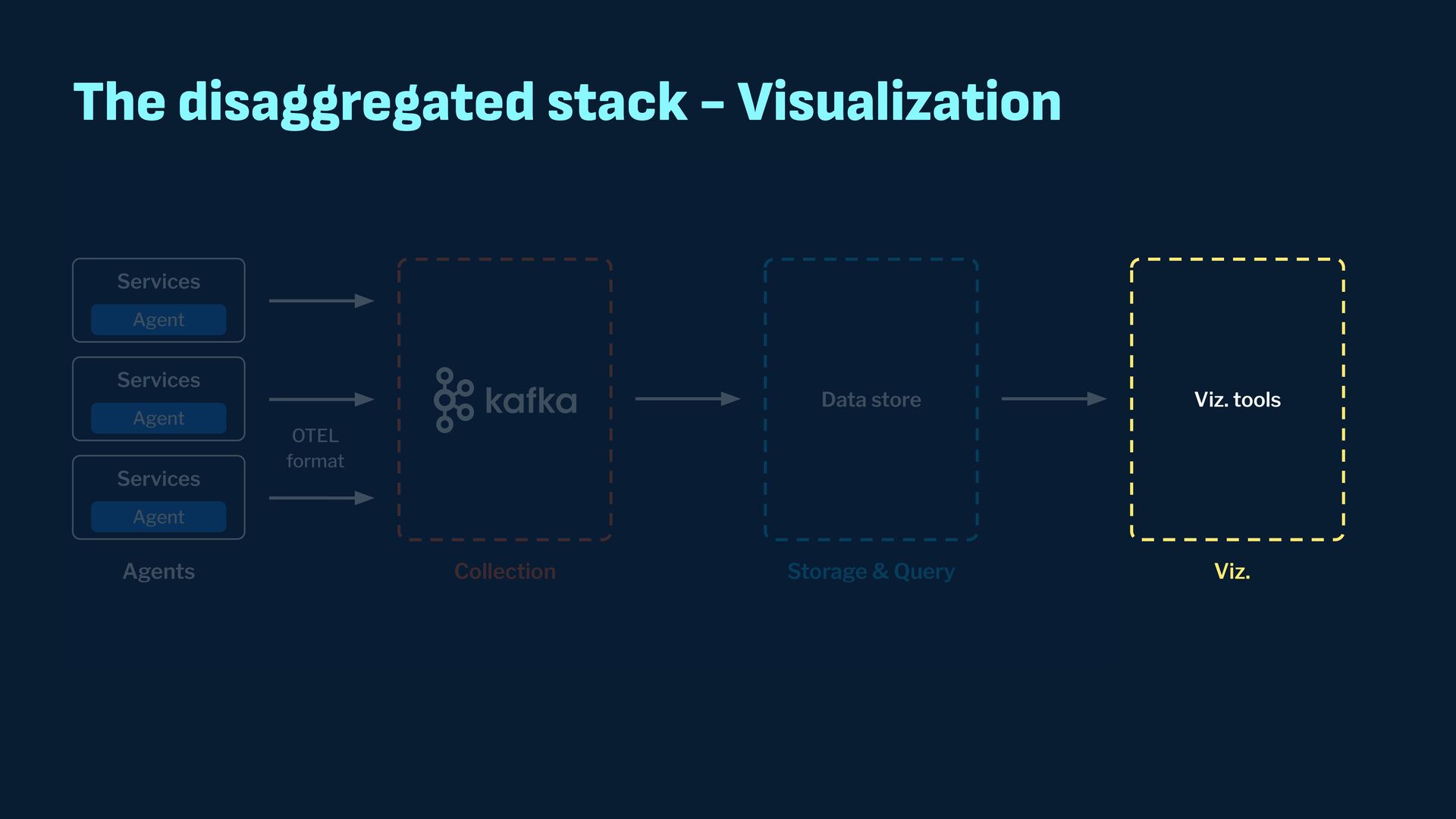
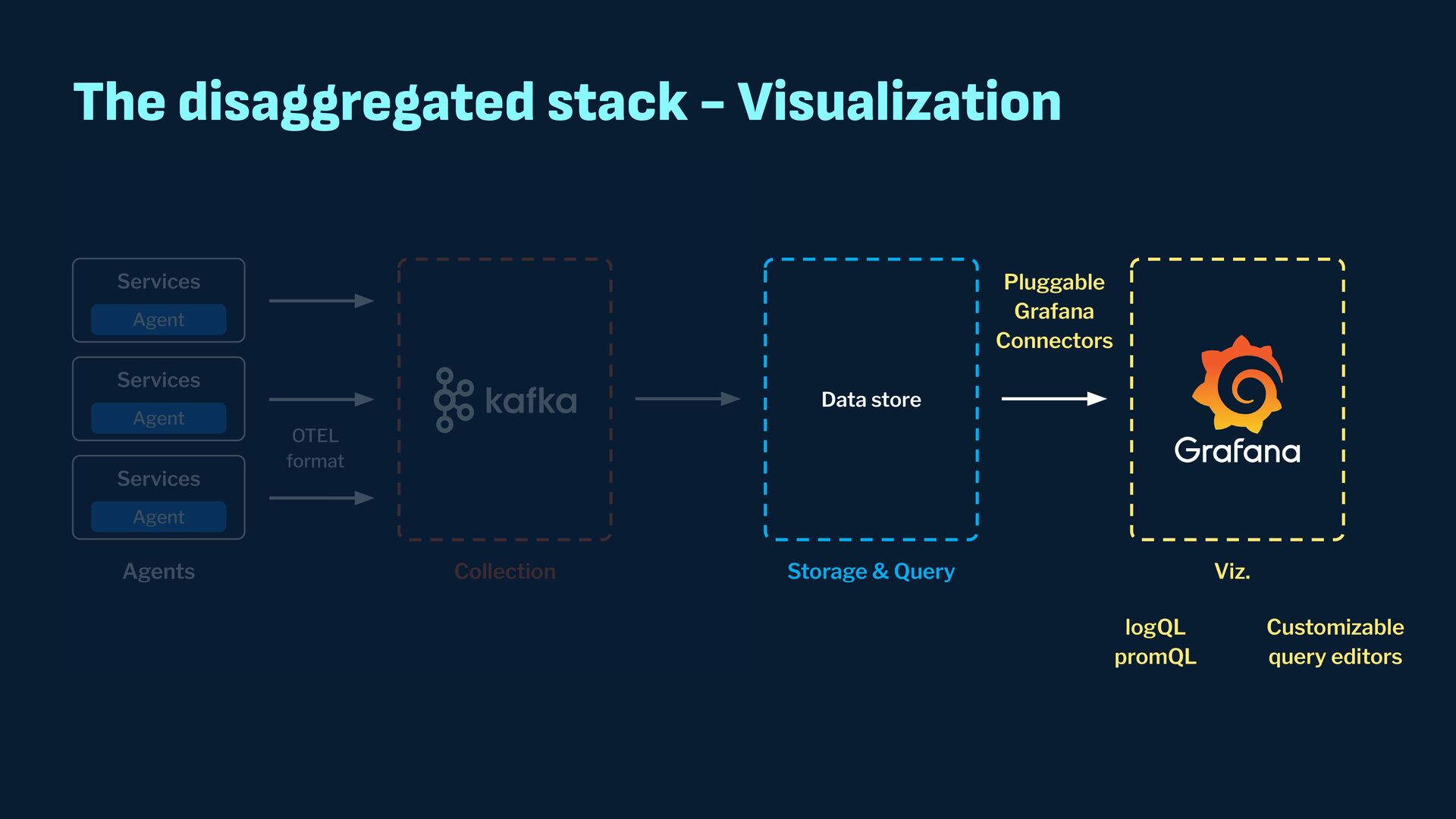
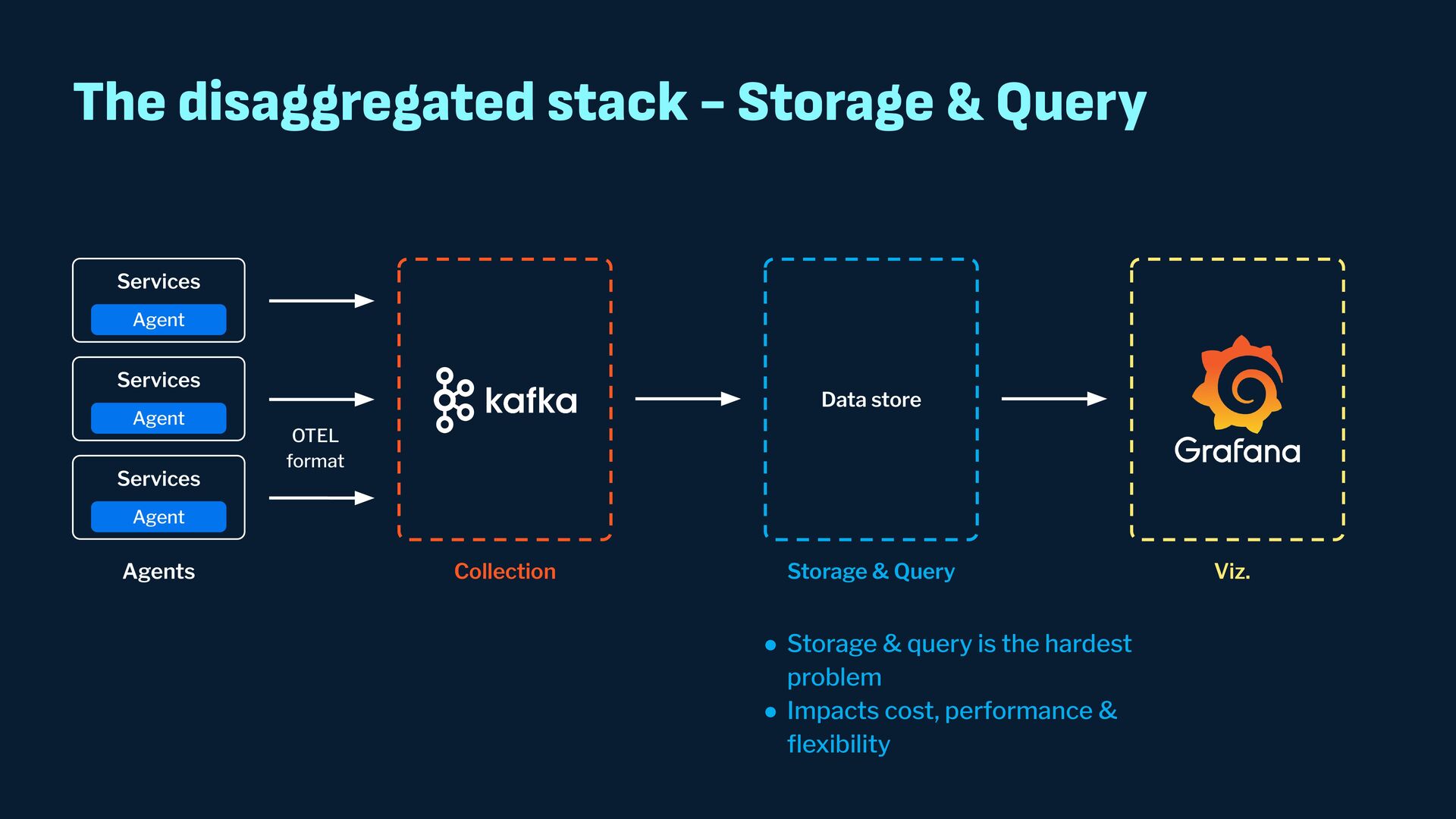
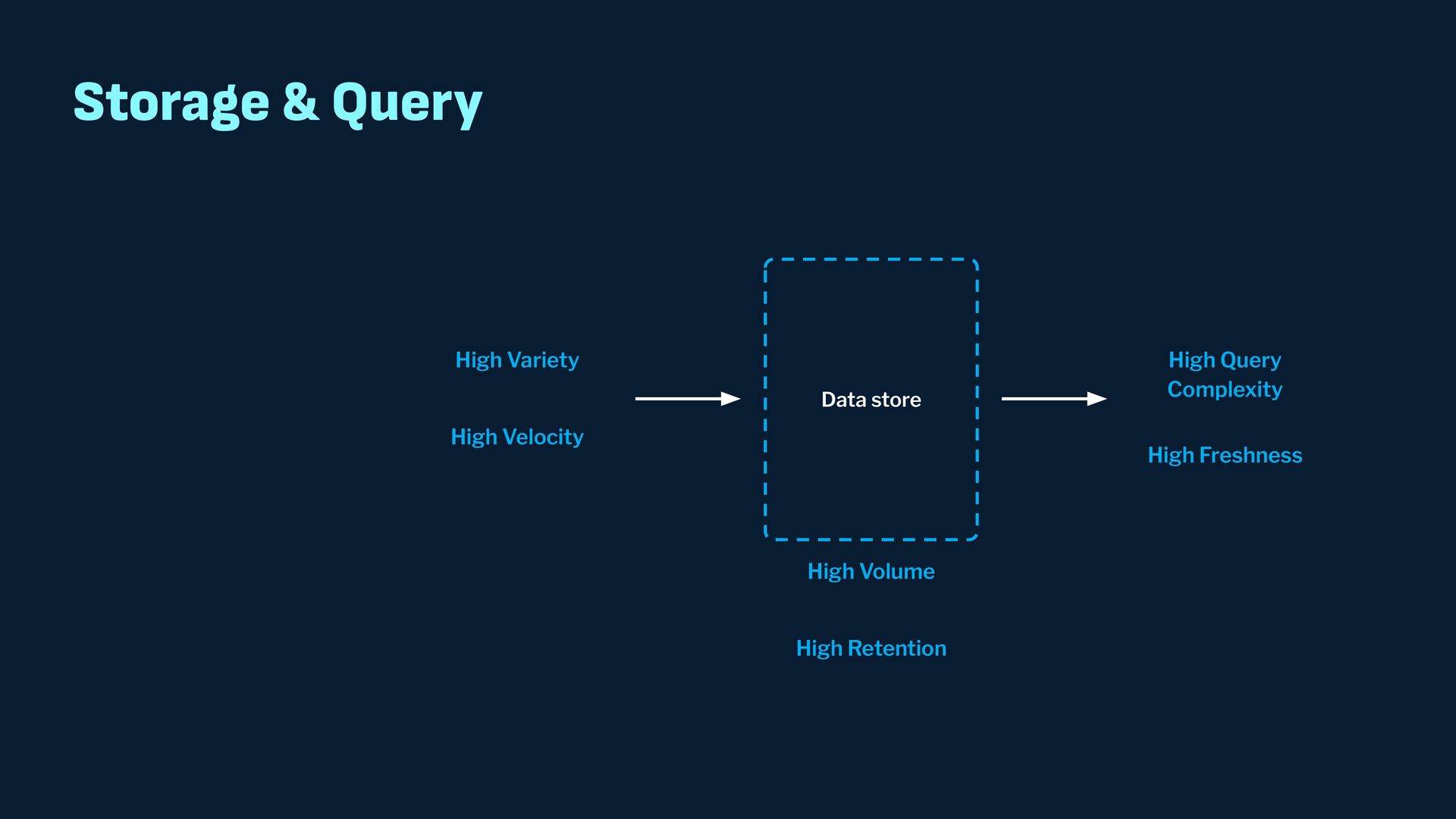
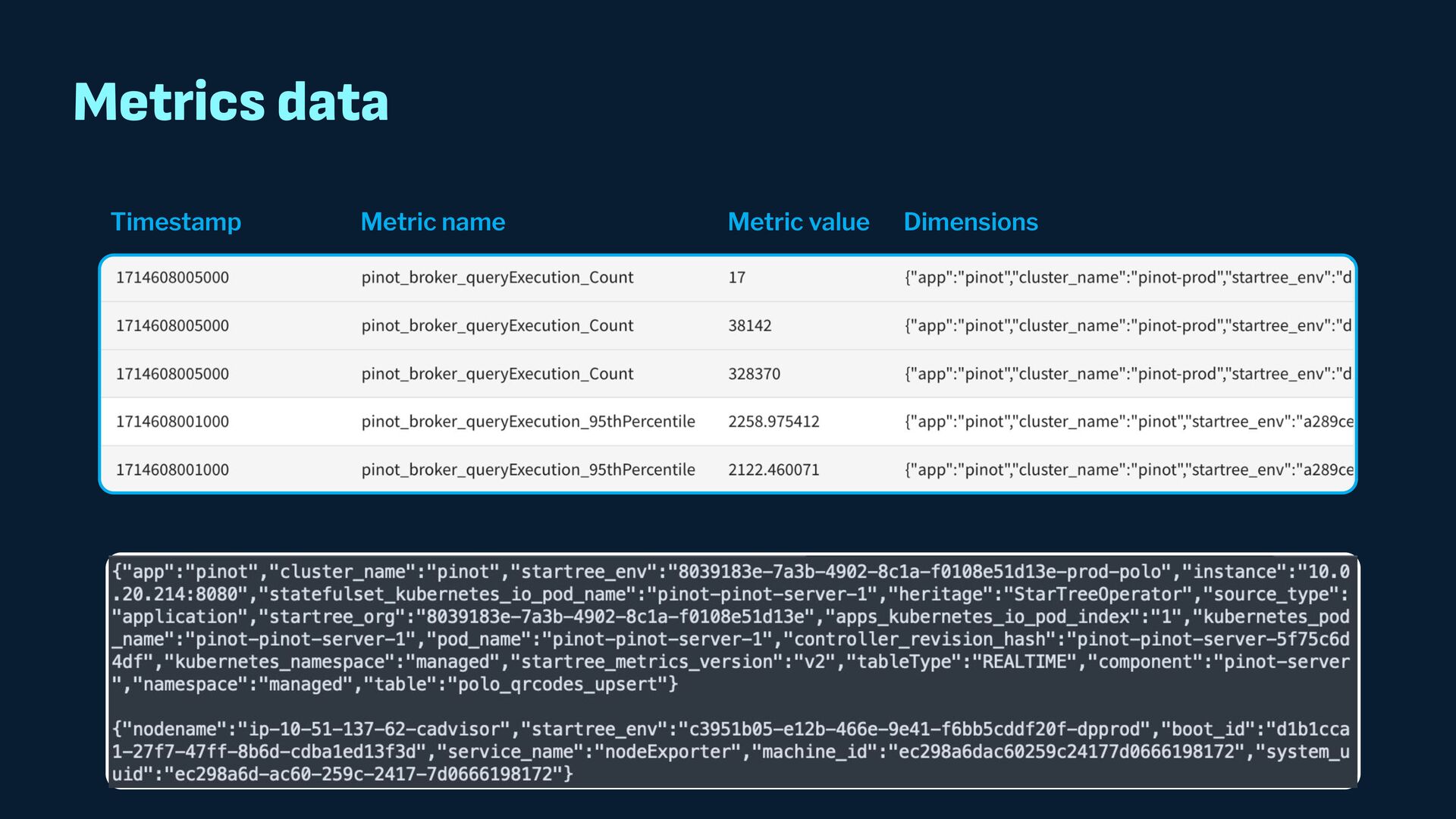
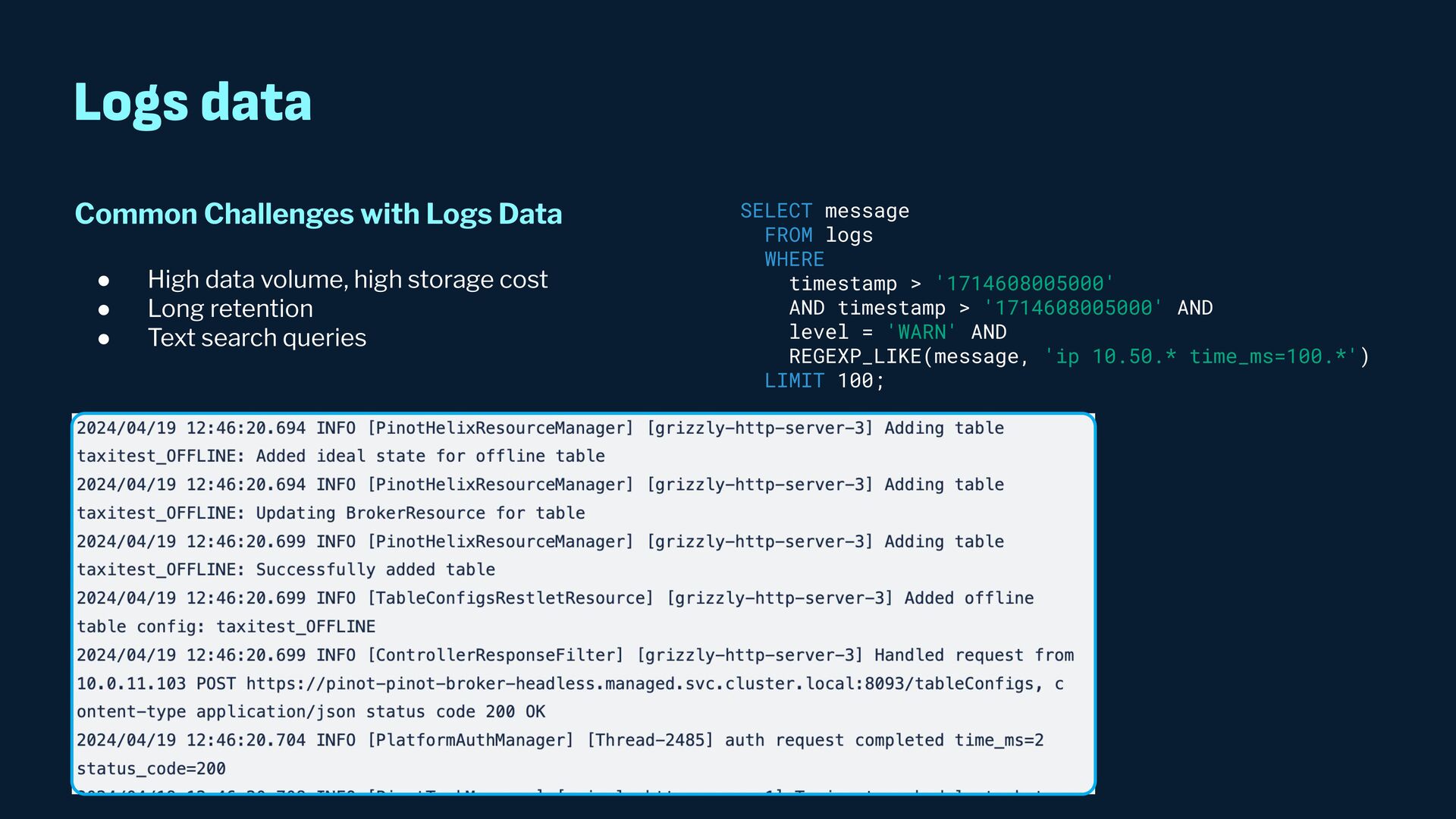
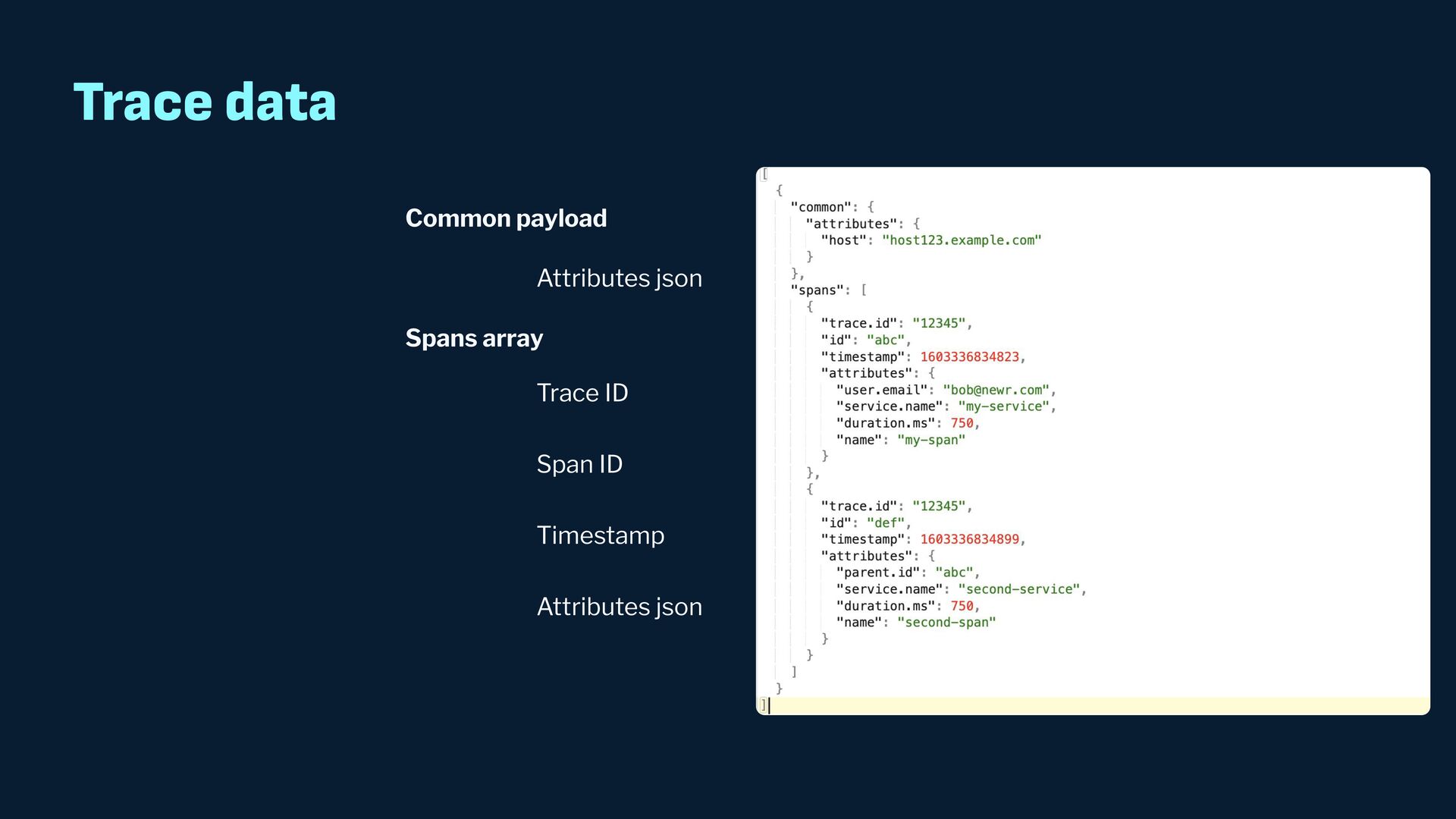
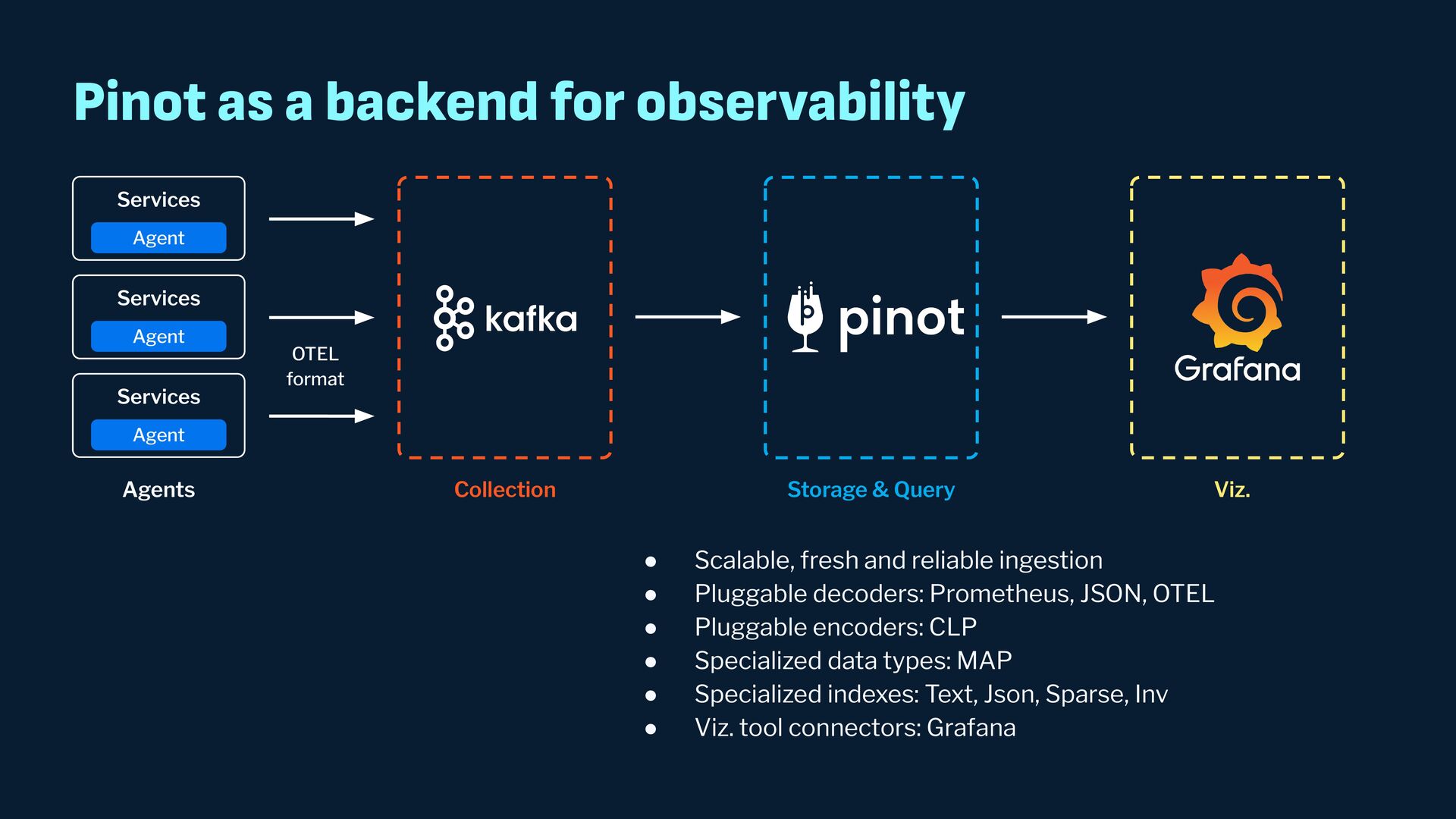
Observability data has become some of the most common types of data being generated and stored within the software industry. At the most basic level we have time series and log data, which are used not just for observability but also in business analytics and customer behavior data mining. Shortly after metrics and logs, trace data also became heavily used to provide deeper insights into applications and distributed systems. In this presentation, we will survey the observability ecosystem and common architectures to ingest, store, query and visualize metrics, logs and traces. We will then cover how we expanded Pinot's feature set to allow it to become an observability storage and analytics engine that can power observability platforms such as Grafana.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
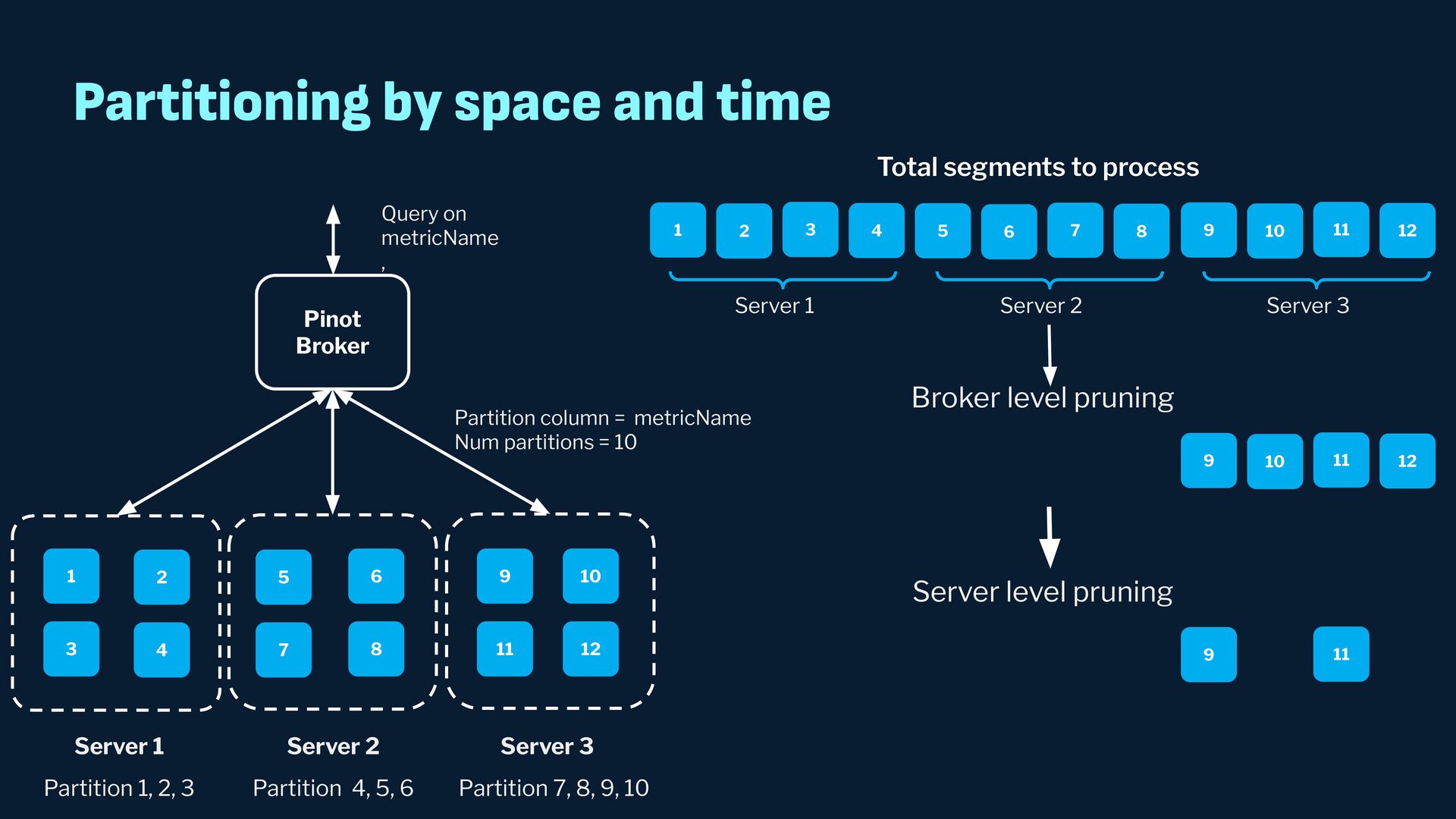{kind=link}
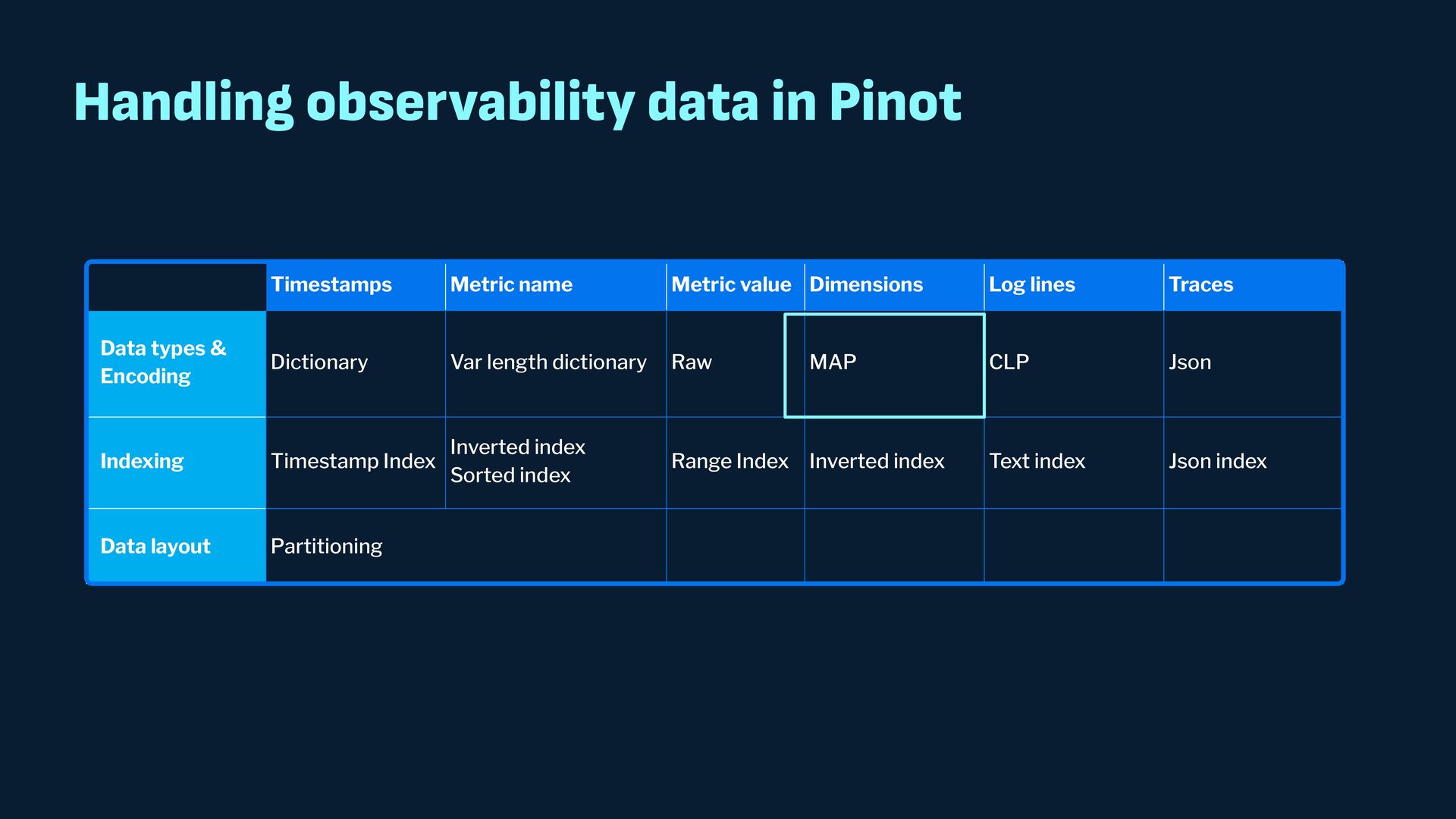{kind=link}
{kind=link}
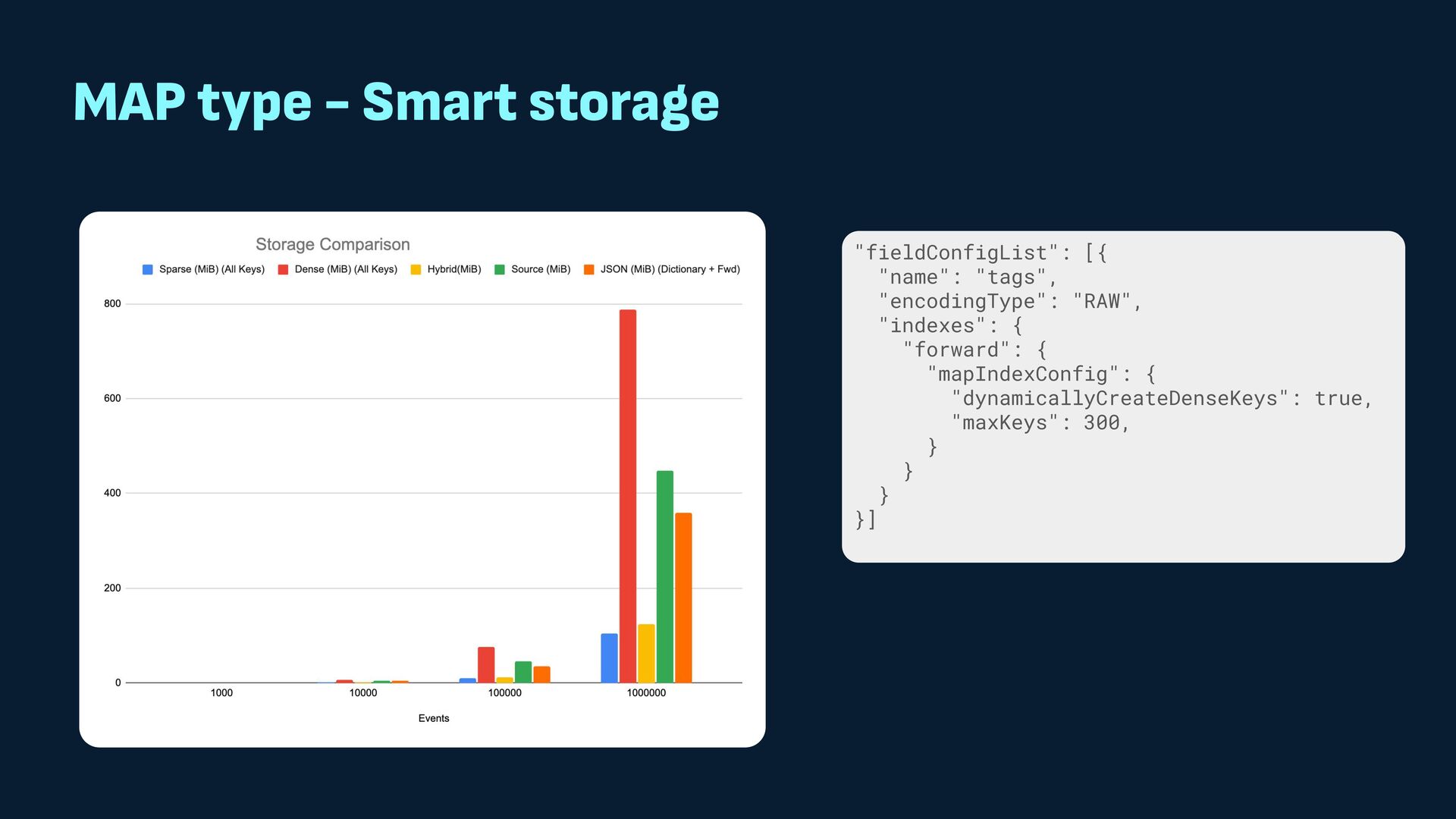{kind=link}
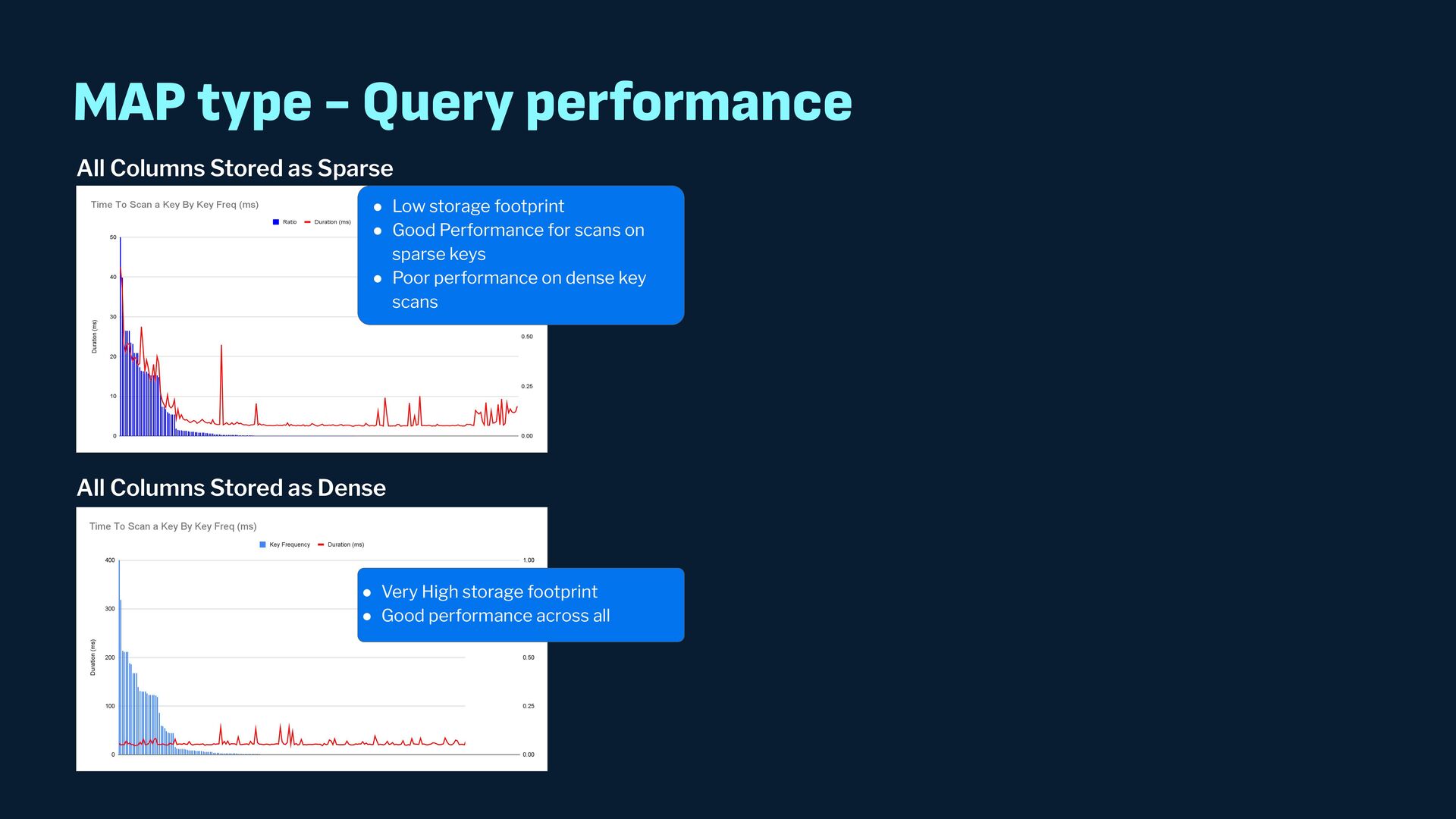{kind=link}
{kind=link}
![Log Compression with CLP Log line: 2024-05-01T00:07:45.000 INFO [BrokerRequestHandler] Broker](https://files.speakerdeck.com/presentations/70e38a846a924a88b8755d42f23712b8/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
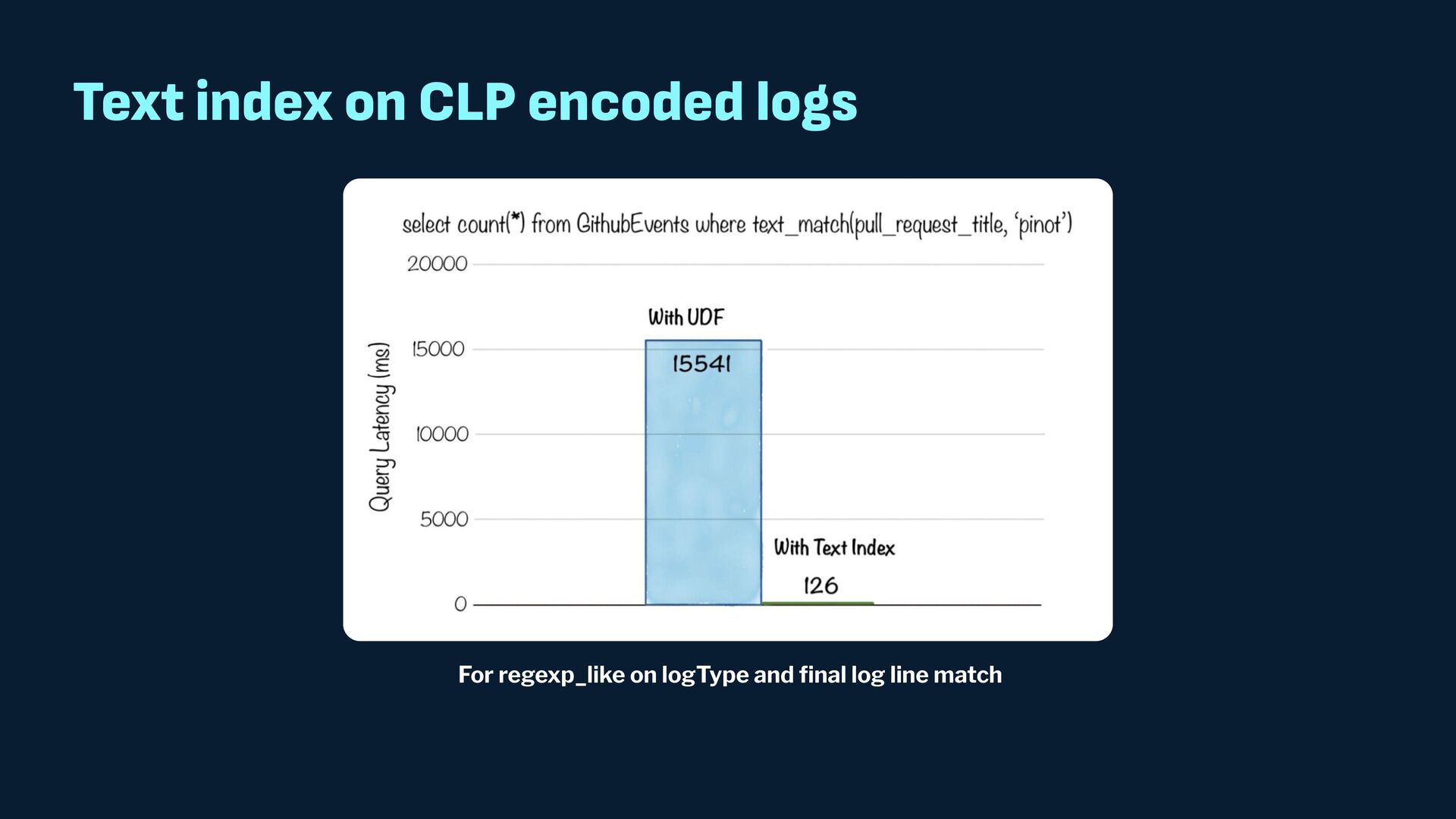{kind=link}
{kind=link}
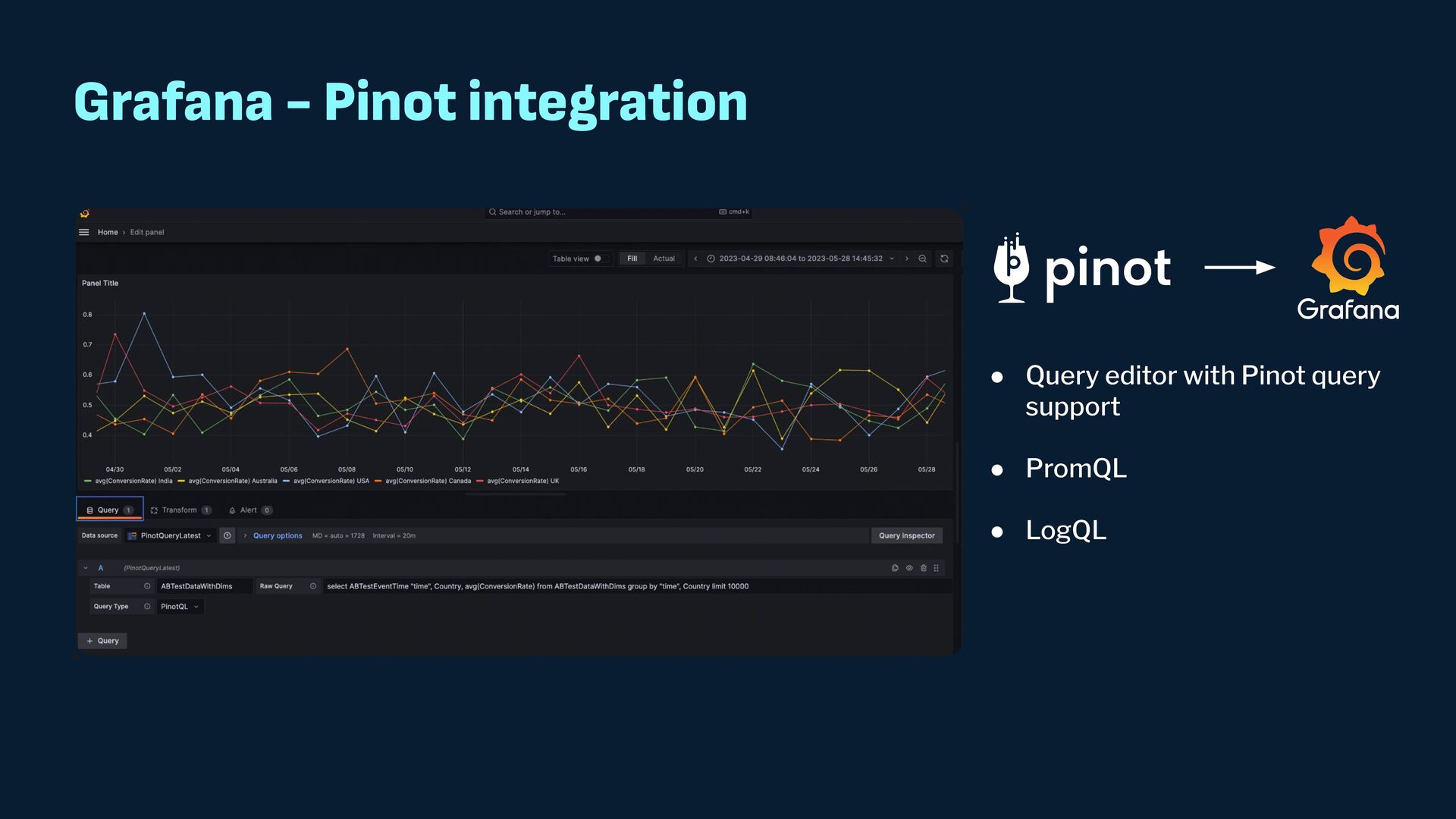{kind=link}
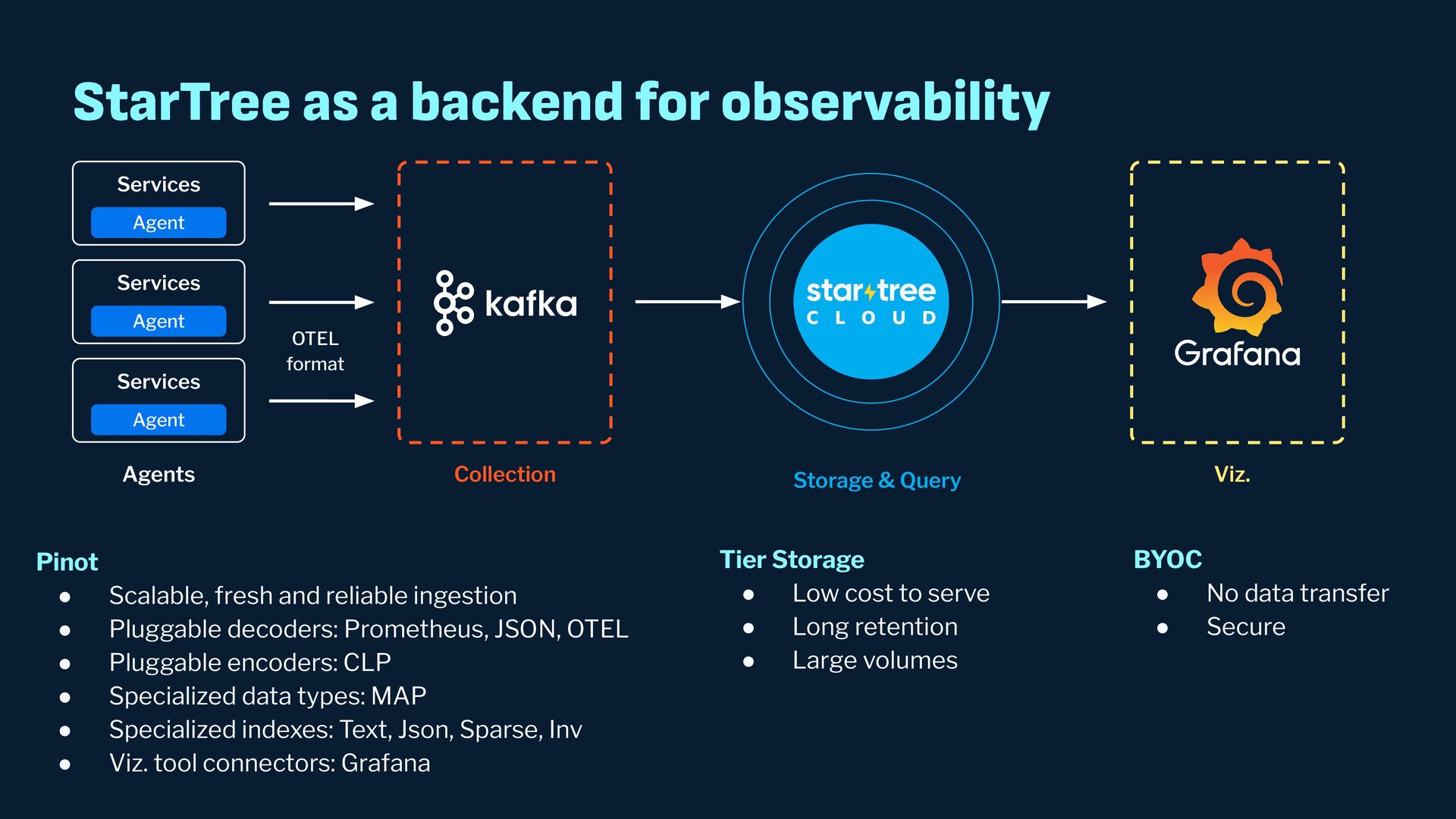{kind=link}
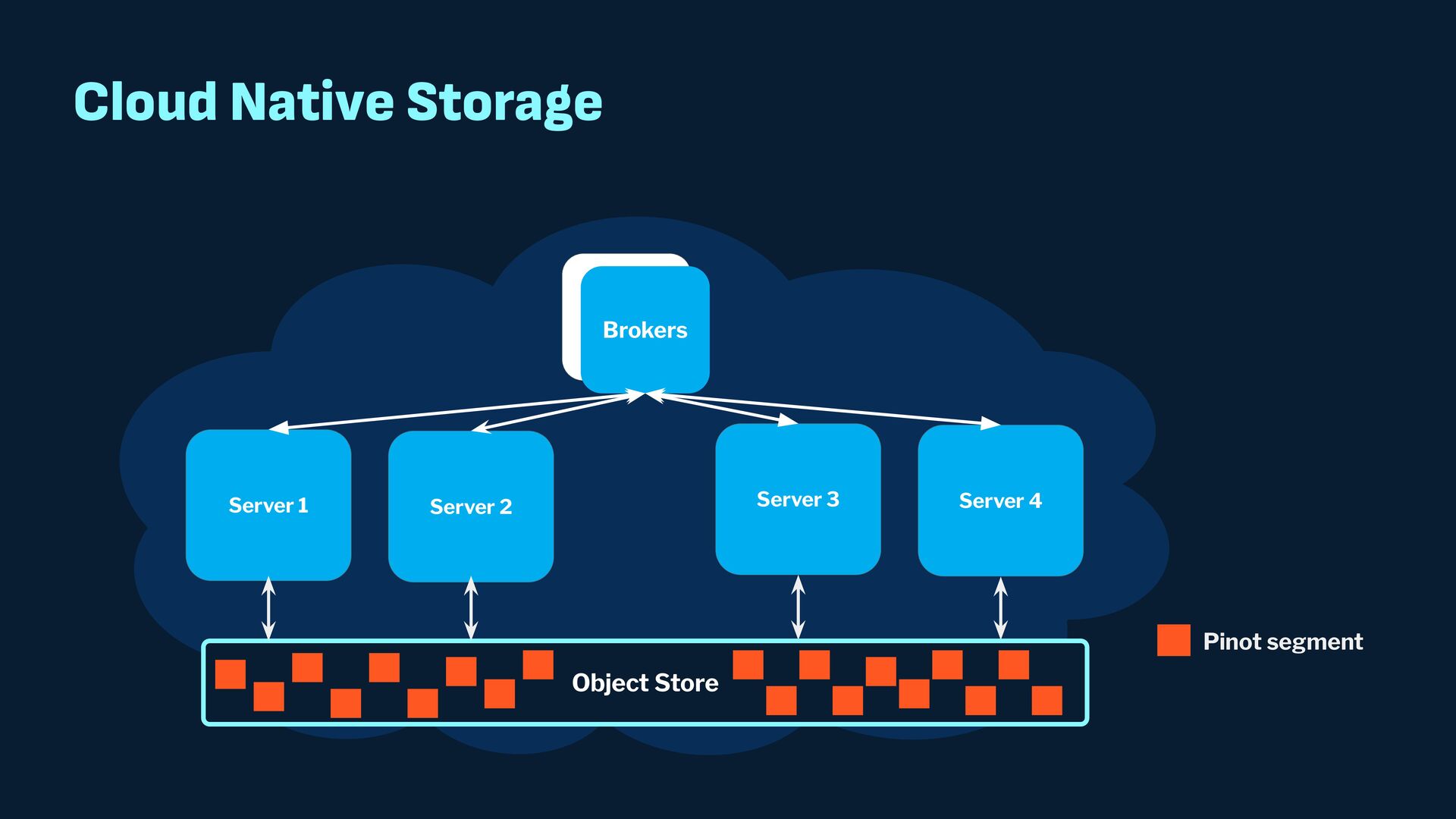{kind=link}
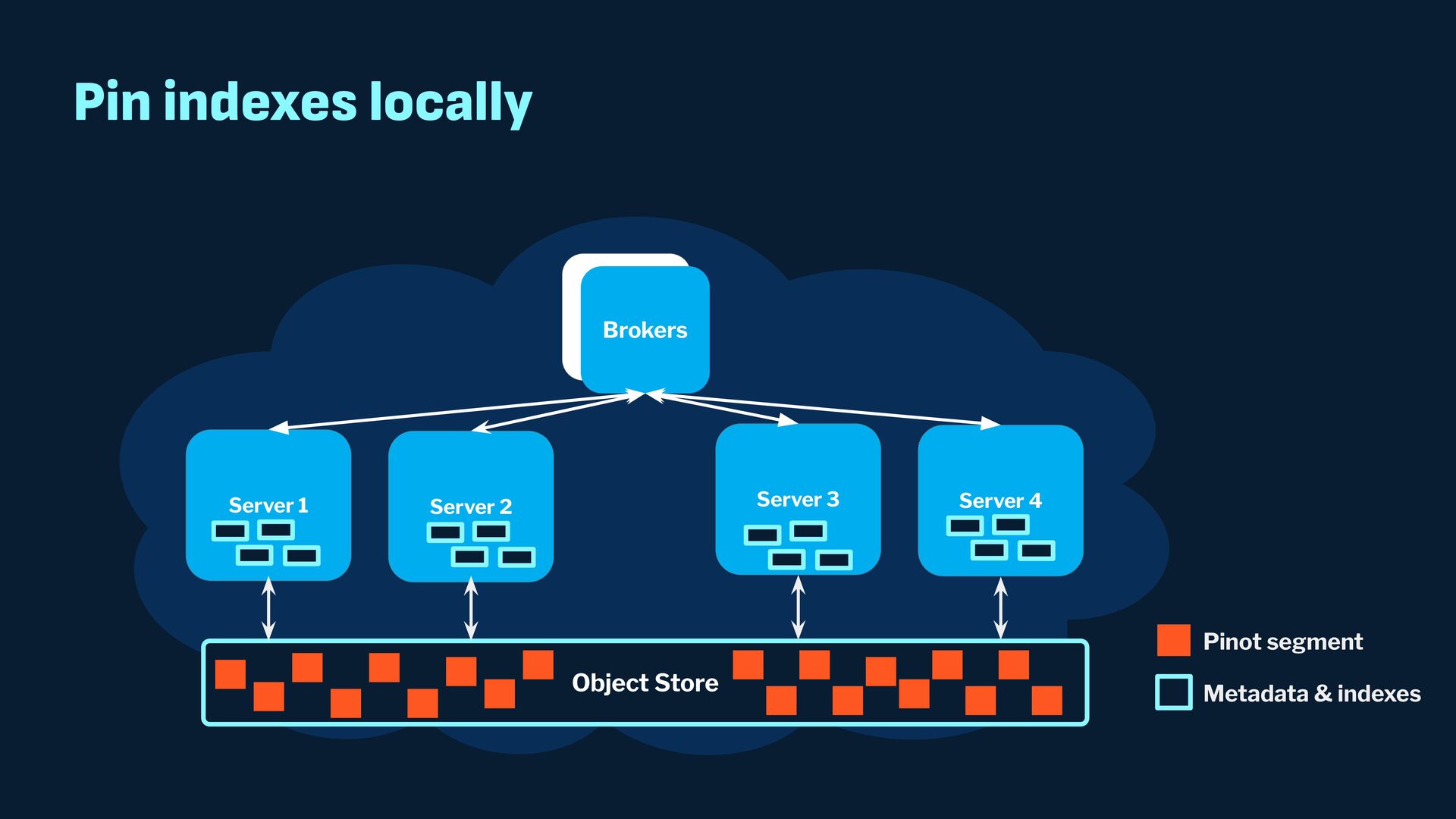{kind=link}
{kind=link}
{kind=link}
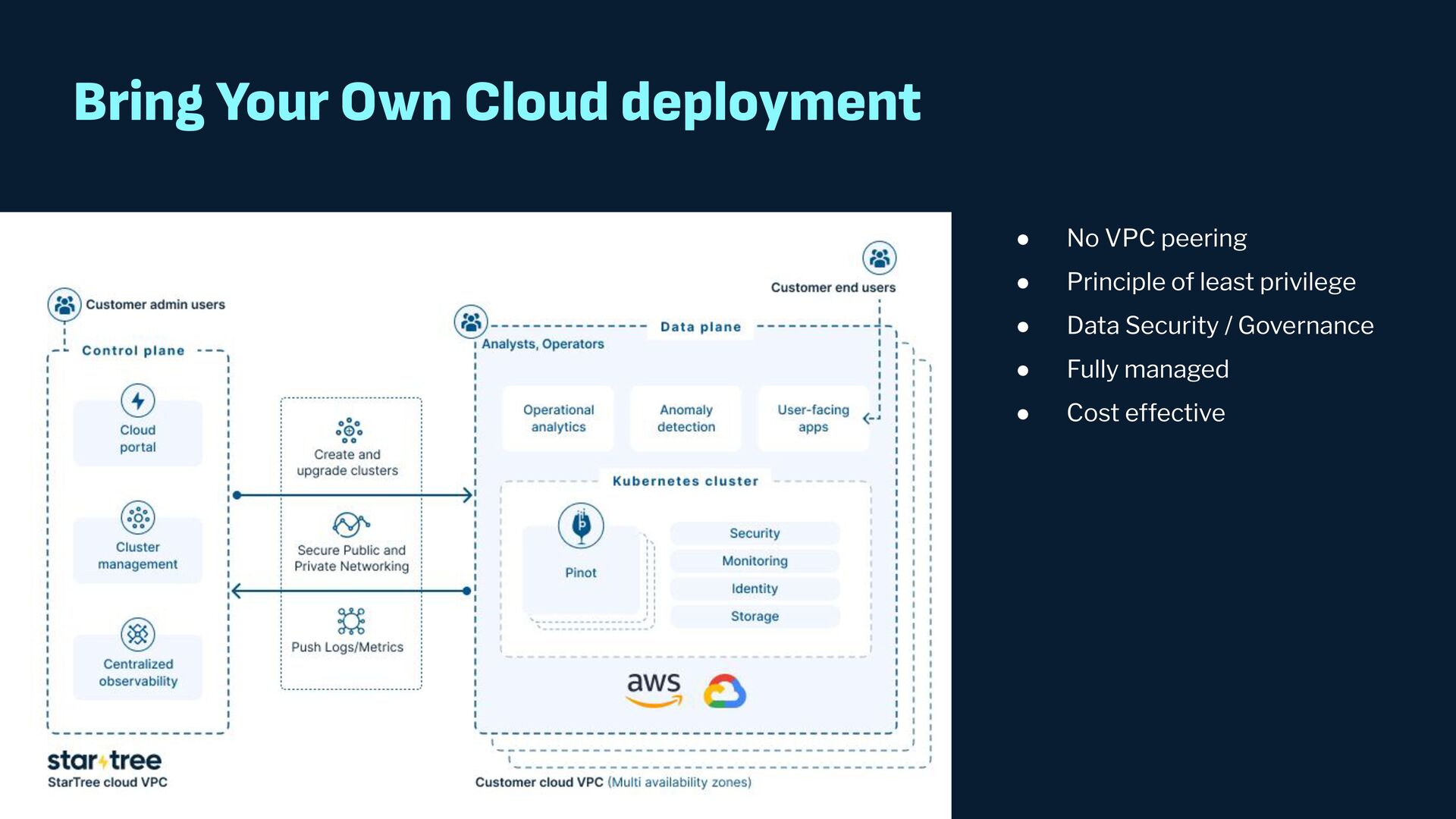{kind=link}
{kind=link}