a month based on a 3 month average, and we’ll need a redesign of the storage system in 18 months” Wow, you are a dextrous & proactive, a consummate professional! Have some more money and servers.
it correctly? Yup, we have seen 37 crashes this morning. Looks like users with Cyrillic names are affected. ETA on a fix is less than one hour. Hey, users are reporting a crash when updating their profile...
of code and not paying attention Hmm. Our 99th percentile page load time has actually improved by 10% over the last 3 months. Show me the page that seems slow and we will analyze whats going on.
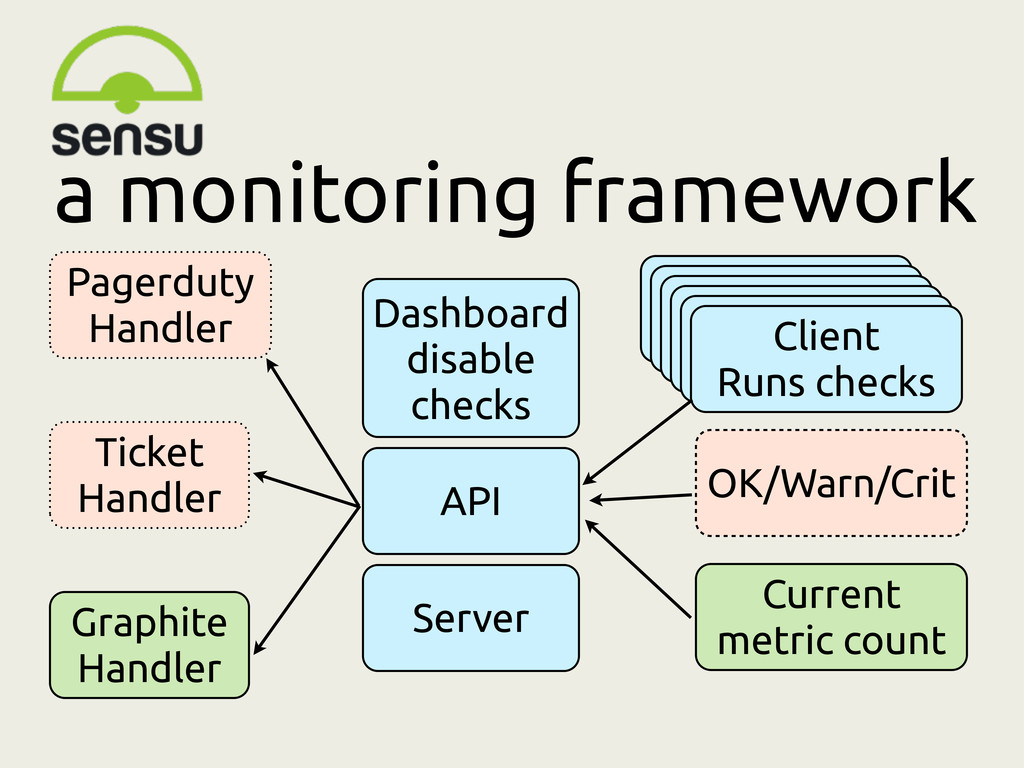
event correlation, capacity planning • Alerting - putting an event in the audit log, waking someone up for an emergency, opening a ticket to be addressed next week.
- revenue, signups, cancellations, engagement • Raw server health (disk space, memory, IO) • Application health (open DB connections, page render time, rate of each HTTP status code, did backups happen last night?) • User experience (javascript errors, app server exceptions, load times) • Vacuum metrics from other places into your system (YouTube likes, AWS Load Balancers)
maybe only contract devs - just use a bunch of SaaS products. Valid approach. • Bootstrapping? • HIPAA or PCI data protection? • Any fulltime devs? • Consider running some of your own monitoring tools. Business folks love ‘em too
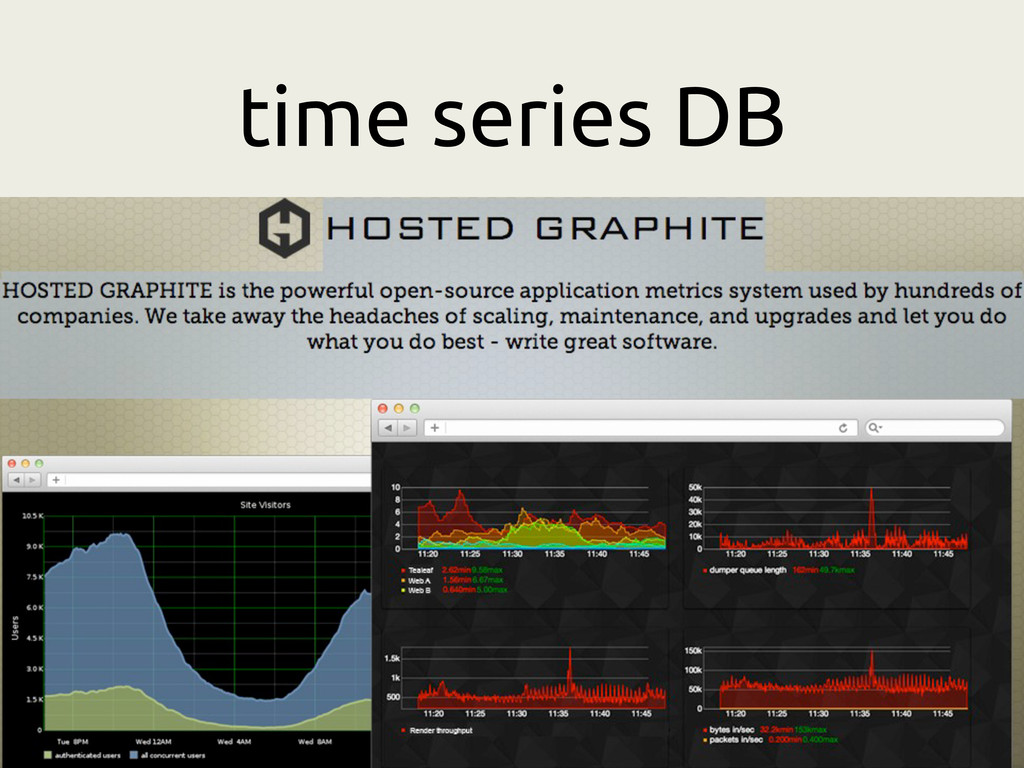
to Nagios, emerged from needs of cloudy app architecture. #monitoringsucks • Graphite is a time series database. Successor to RRD, originally written at orbitz.com. Amazingly flexible, surging in popularity (Github, hosted services)
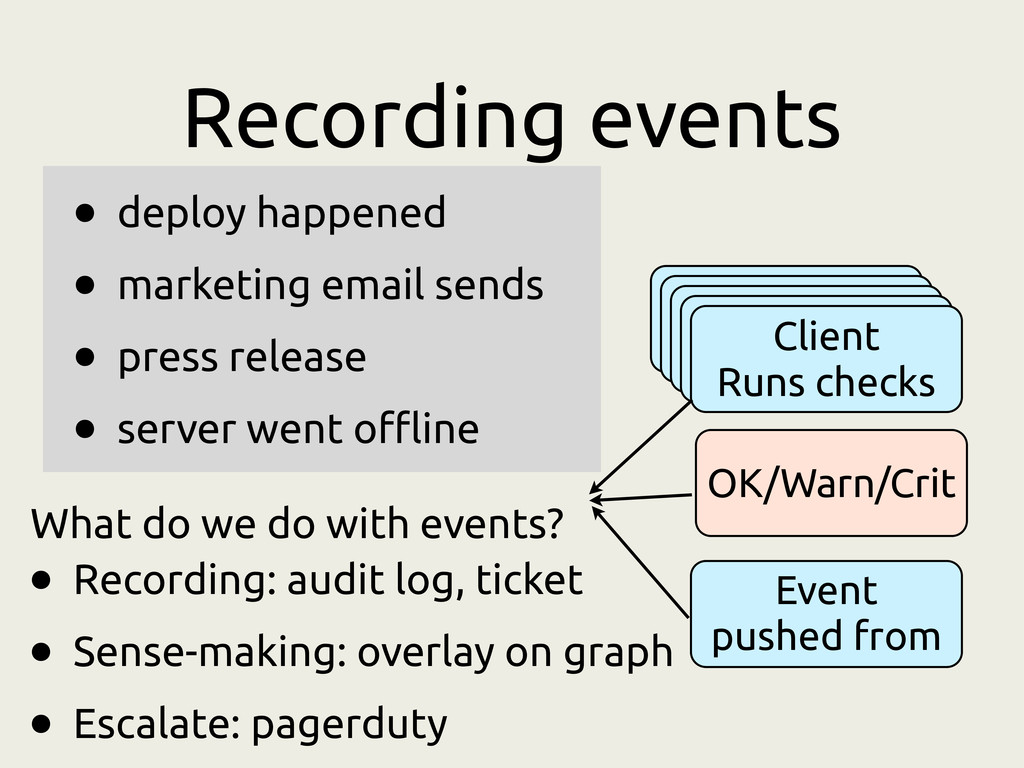
press release • server went offline What do we do with events? Event pushed from Client Runs checks Client Runs checks Client Runs checks Client Runs checks Client Runs checks OK/Warn/Crit • Recording: audit log, ticket • Sense-making: overlay on graph • Escalate: pagerduty
• new signups rate • Facebook likes Current metric count • Record: time series db • Sense-making: Draw graphs • Remix: derivative, sum, time shift • Inception: alert on thresholds (disk full, error rate changing too rapidly) What do we do with metrics?
Graphite. This is a statistics aggregator, makes it easier to measure correctly. counters (gives you rate+count), sampling, timers with histograms, guages, uniques. https://github.com/reinh/statsd statsd-ruby gem
will never set up monitoring infra • You will never keep it updated • Unless it is is *easy* • 50 lines of chef-solo and 10 minutes later the entire system springs to life Use configuration management
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}