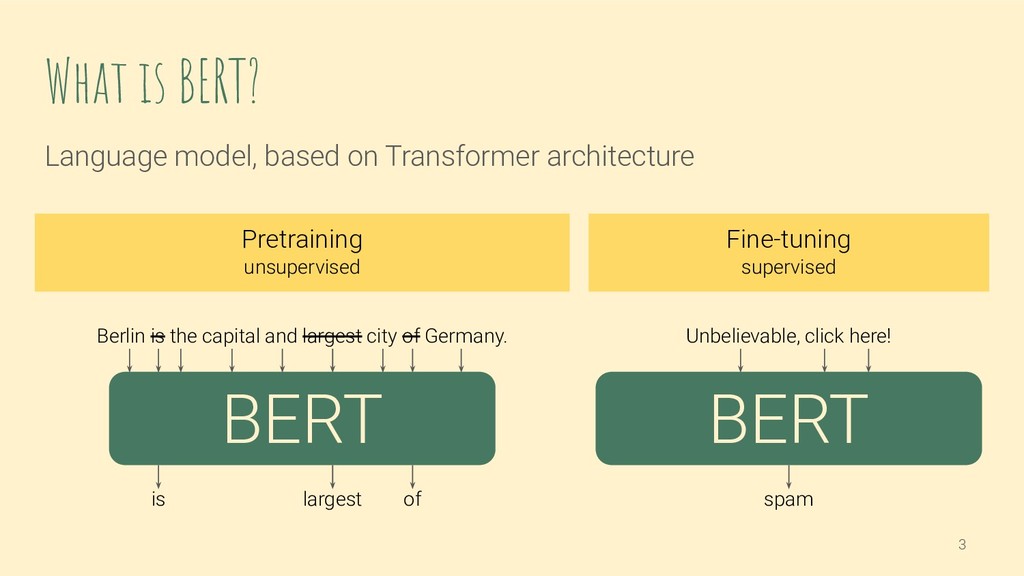
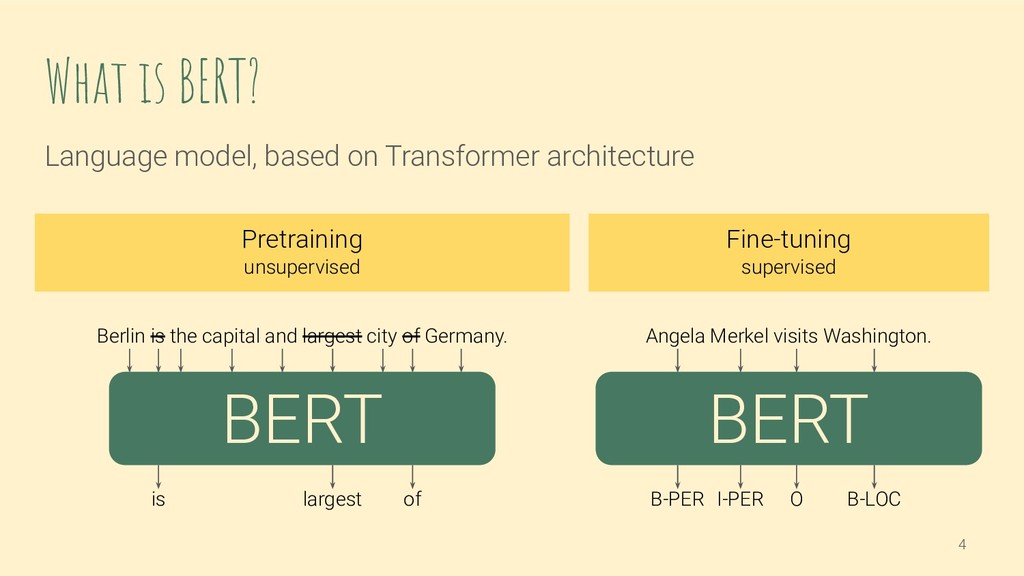
Large pre-trained language models play an important role in recent NLP research. They can learn general language features from unlabeled data, and then be easily fine-tuned for any supervised NLP task, e.g. classification or named entity recognition. BERT (Bidirectional Encoder Representations from Transformers) is one example of a language model, pre-trained weights are available for everyone to use.
BERT has been shown to successfully transfer knowledge from pre-training to many different NLP benchmark tasks. How good can this transfer work for non-English or domain-specific texts, though?
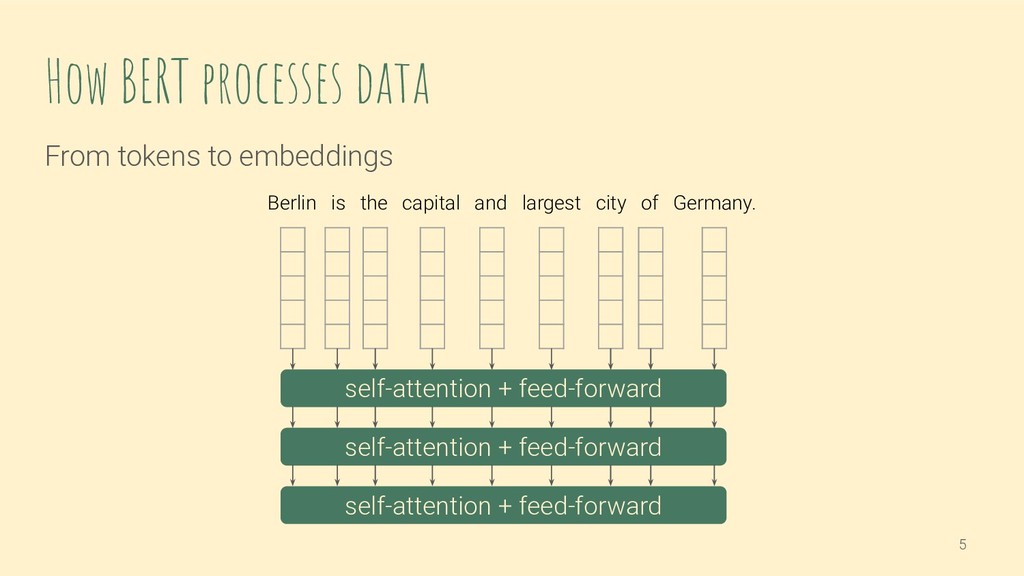
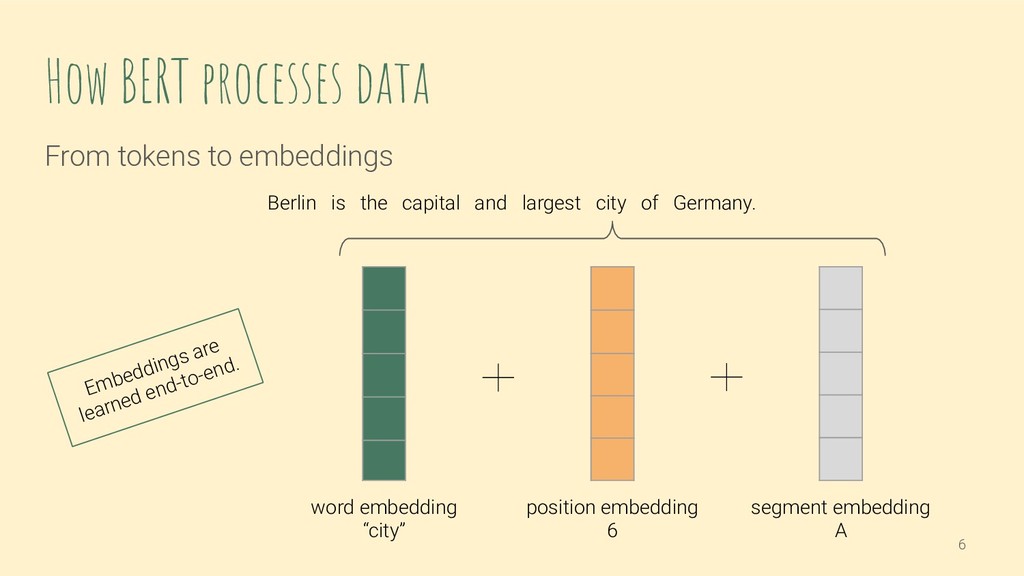
We will have a look at how exactly input text is fed to and processed by BERT. Prior knowledge of the BERT architecture is therefore not necessary, but we assume some experience with deep learning and NLP. This introduction gives the background to discuss the limitations you will face when fine-tuning a pre-trained BERT on your data, e.g. related to vocabulary and input text length.
An alternative solution compared to simple fine-tuning is to train your own version of BERT from scratch, thus overcoming some of the discussed limitations. The hope for improving performance is countered by time and hardware requirements that training from scratch brings with it. I was curious enough to give it a try and want to share the findings from this experiment. We will go over the achieved improvements and the actual effort - so you can decide whether you should try to train your own BERT.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}