“Got an NLP problem nowadays? Use transformers! Just download a pretrained model from the hub!” - every blog article ever
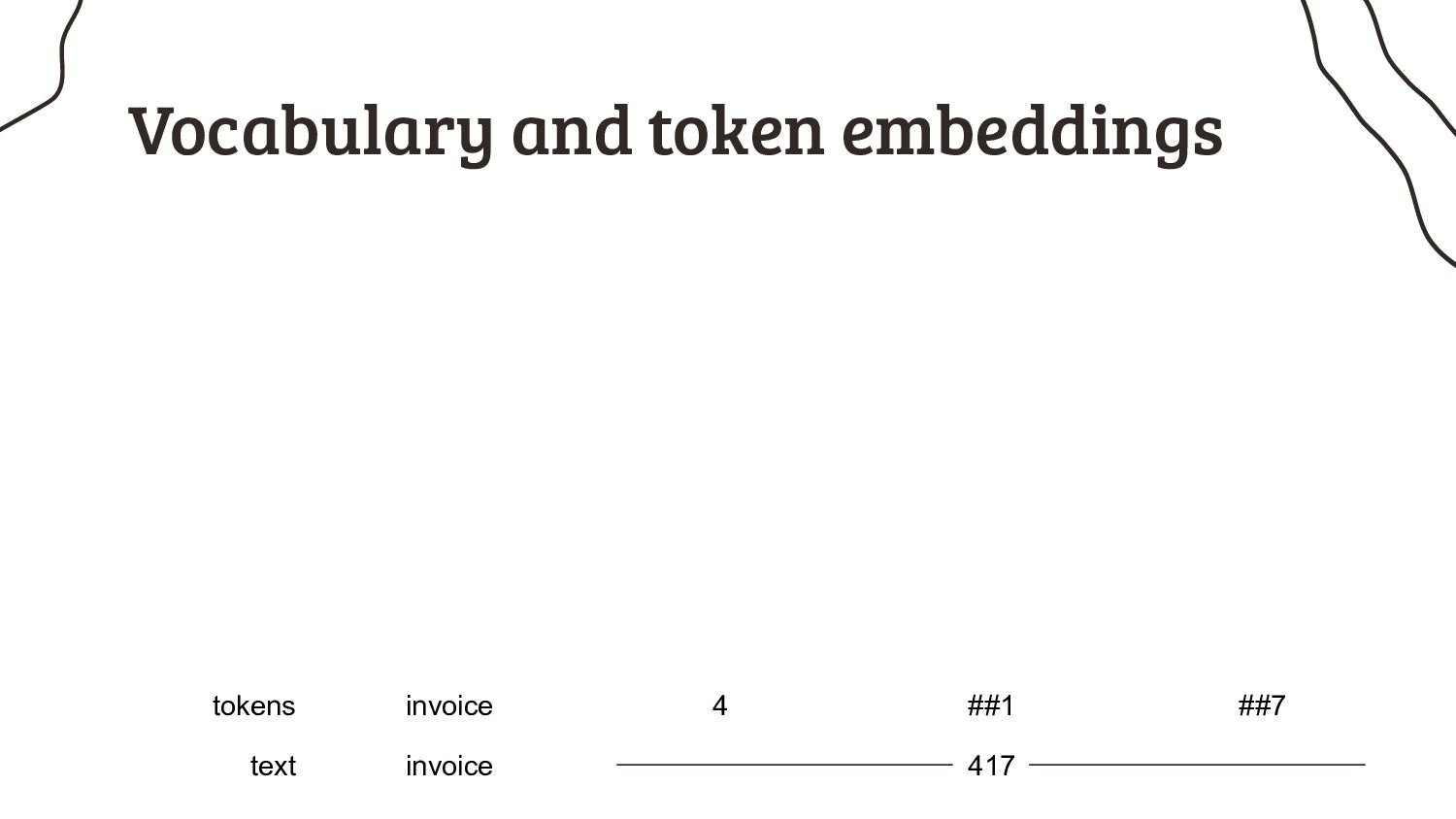
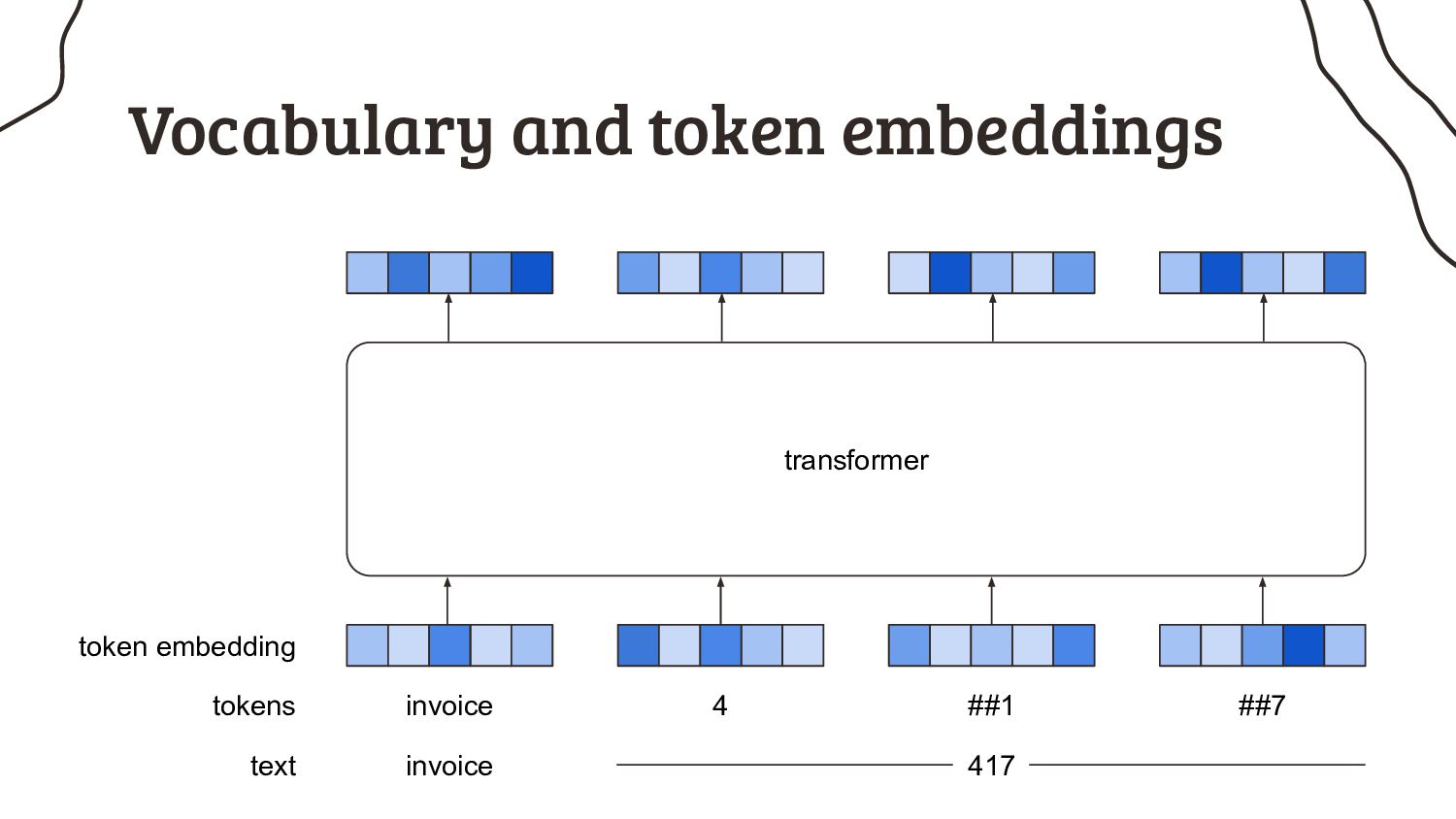
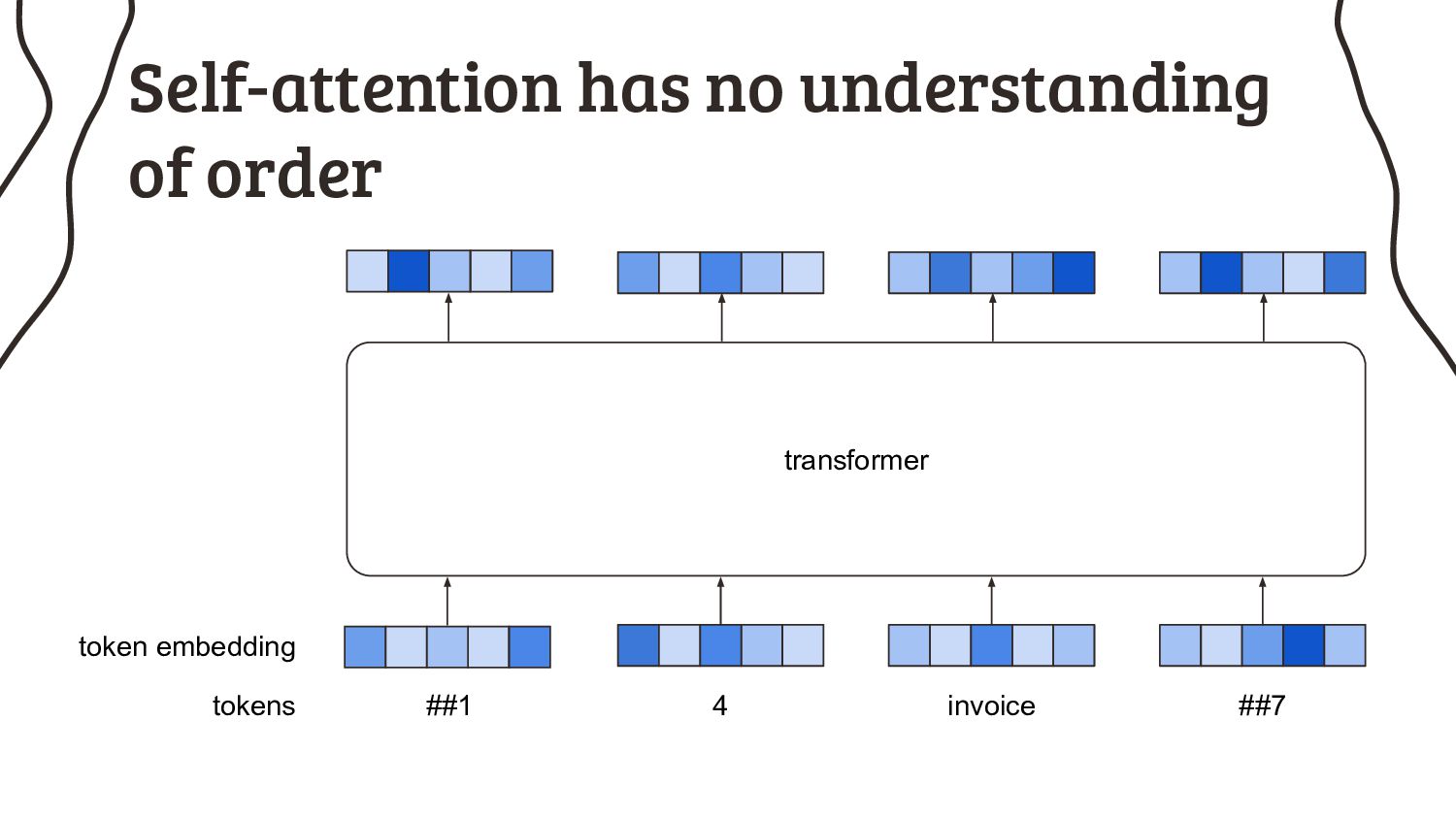
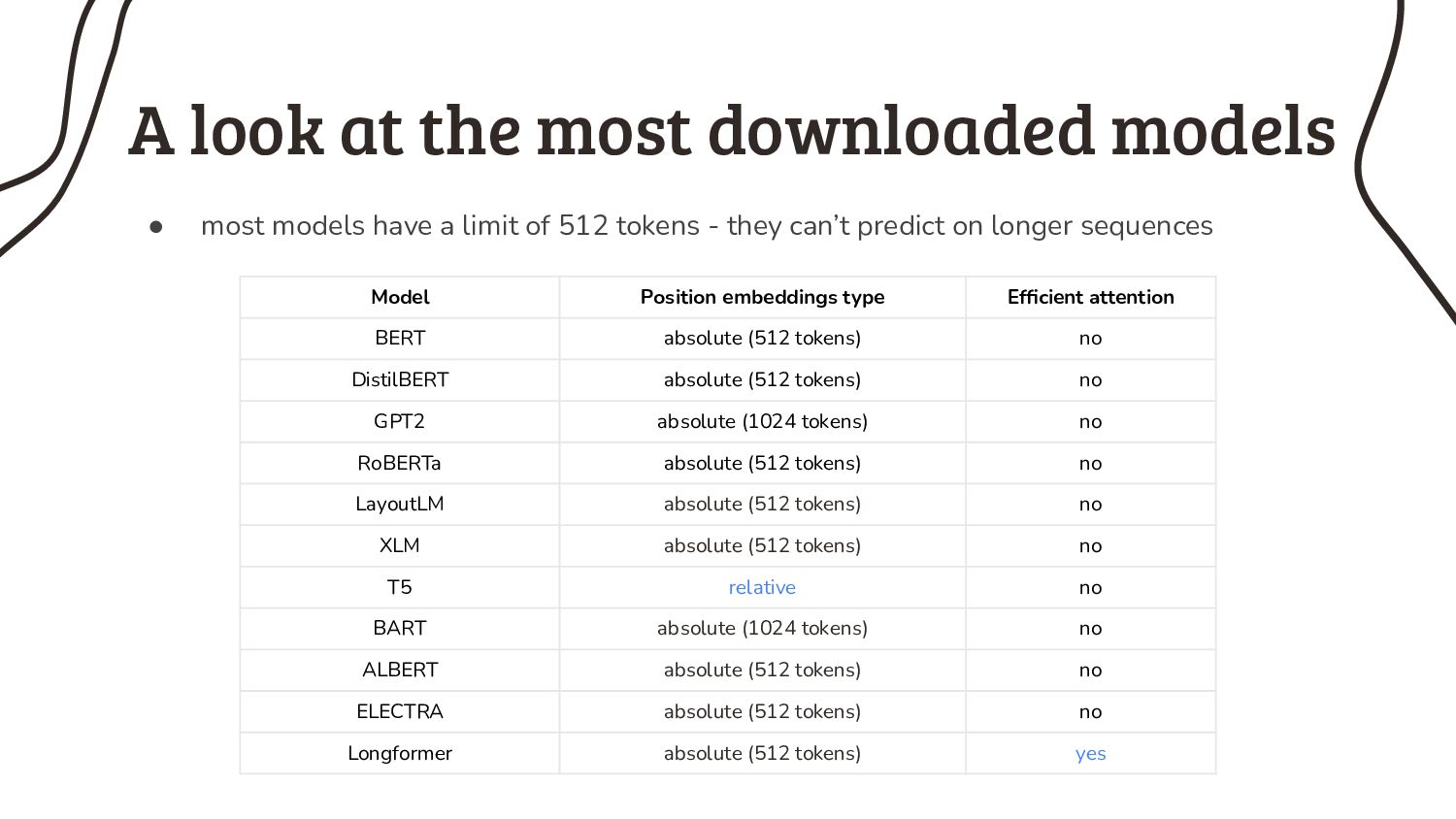
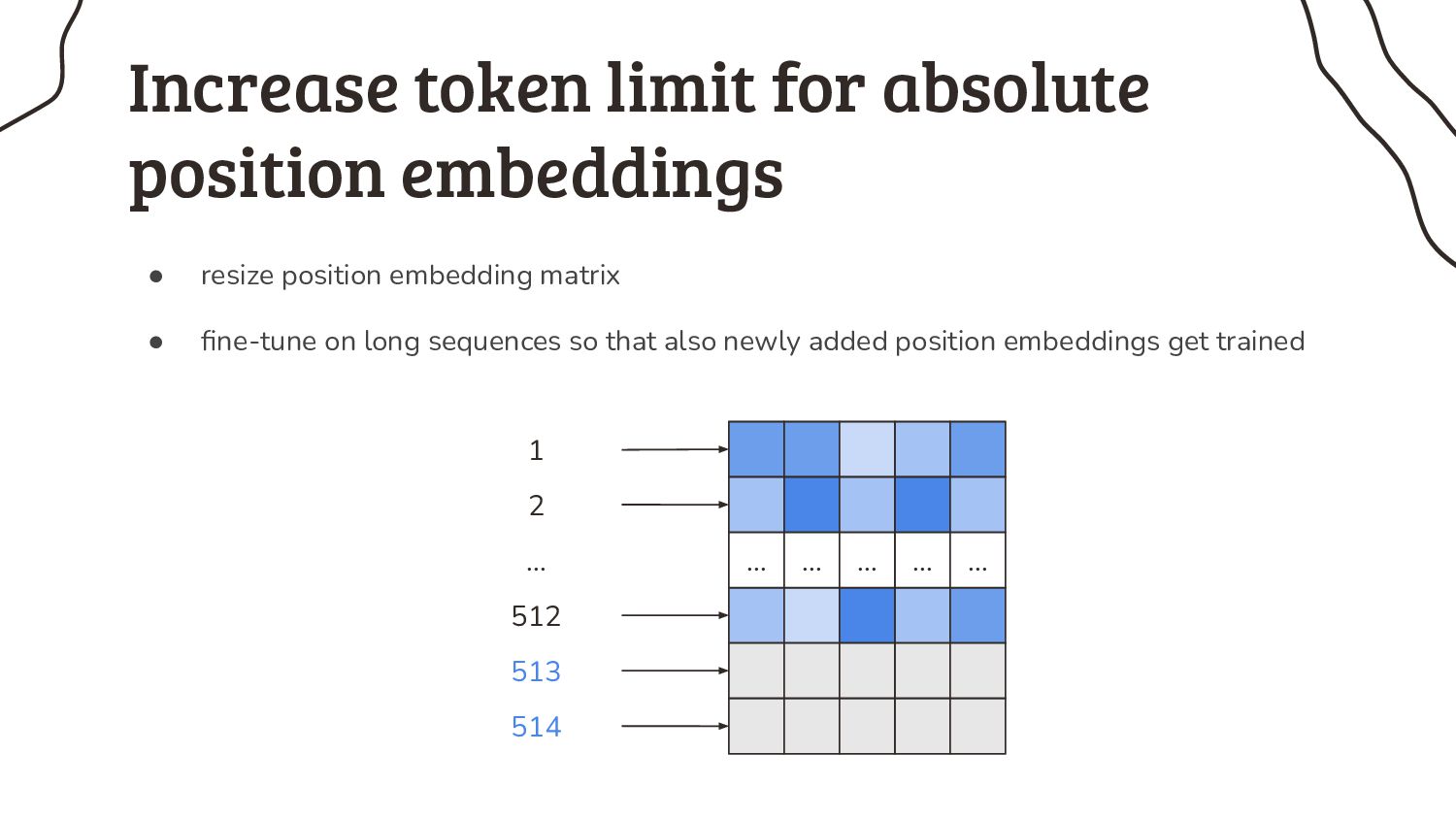
As if it’s that easy, because nearly all pretrained models have a very annoying limitation: they can only process short input sequences. Not every NLP practitioner happens to work on tweets, but instead many of us have to deal with longer input sequences. What started as a minor design choice for BERT, got cemented by the research community over the years and now turns out to be my biggest headache: the 512 tokens limit.
In this talk, we’ll ask a lot of dumb questions and get an equal number of unsatisfying answers:
1. How much text actually fits into 512 tokens? Spoiler: not enough to solve my use case, and I bet a lot of your use cases, too.
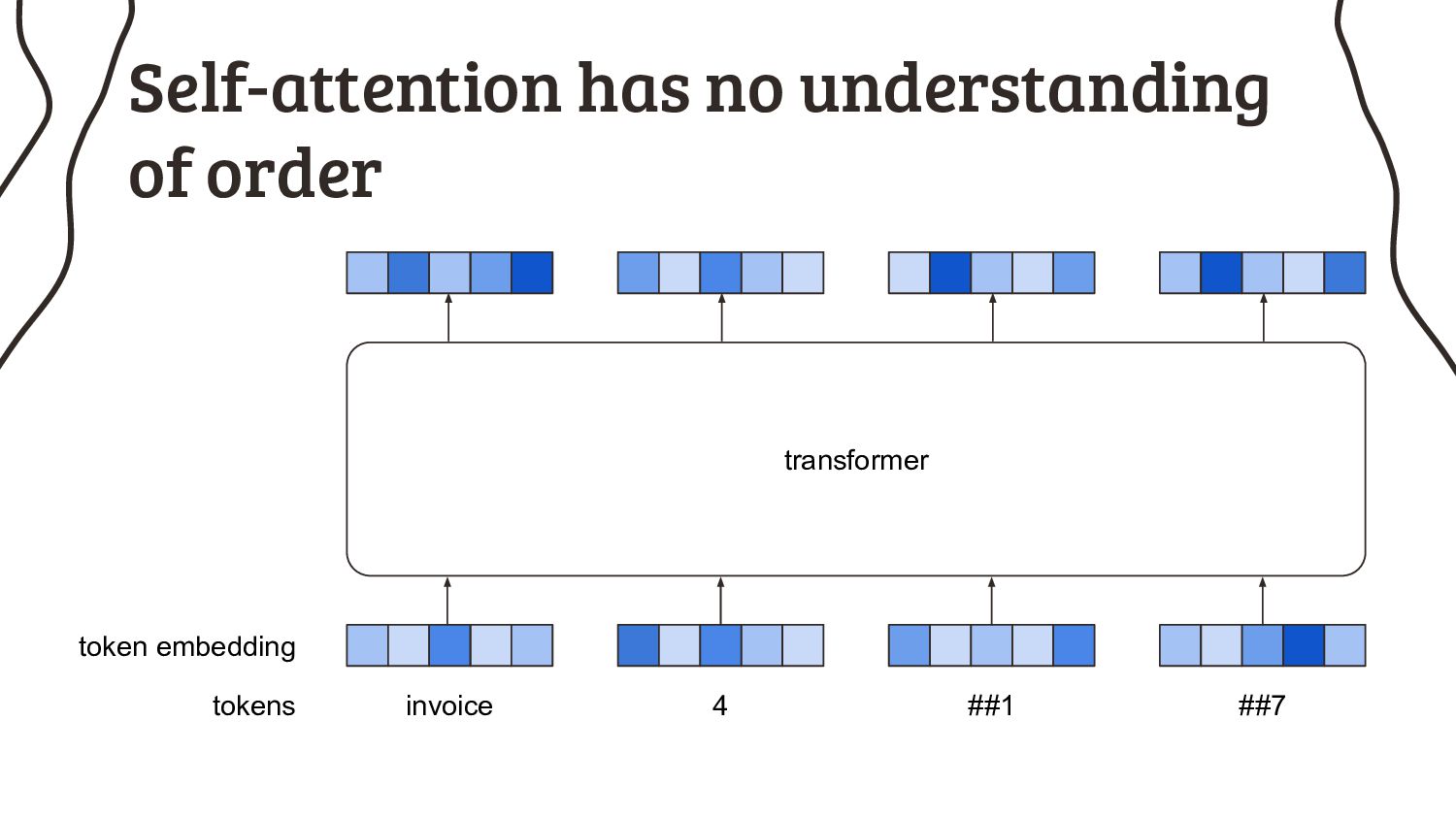
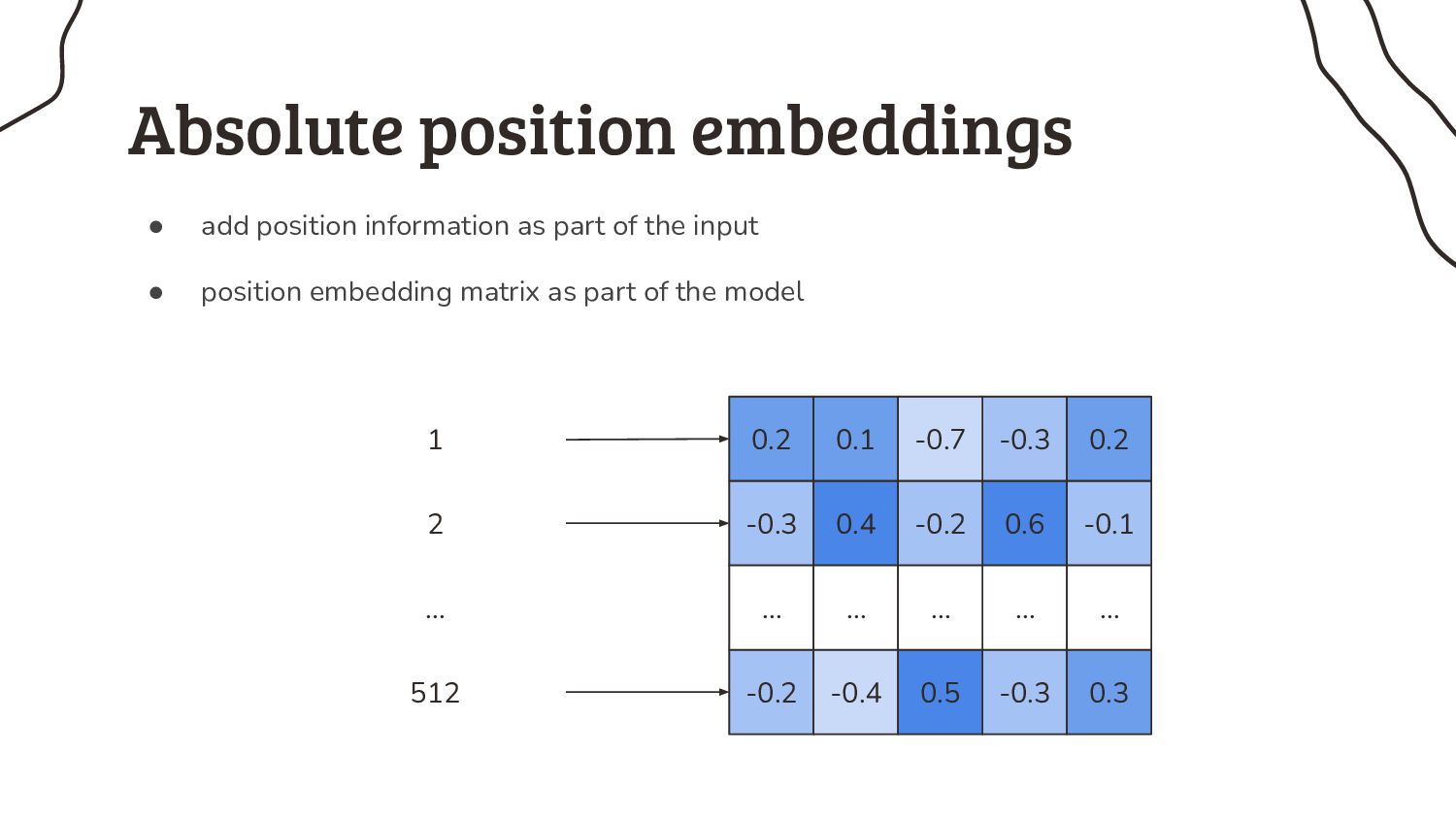
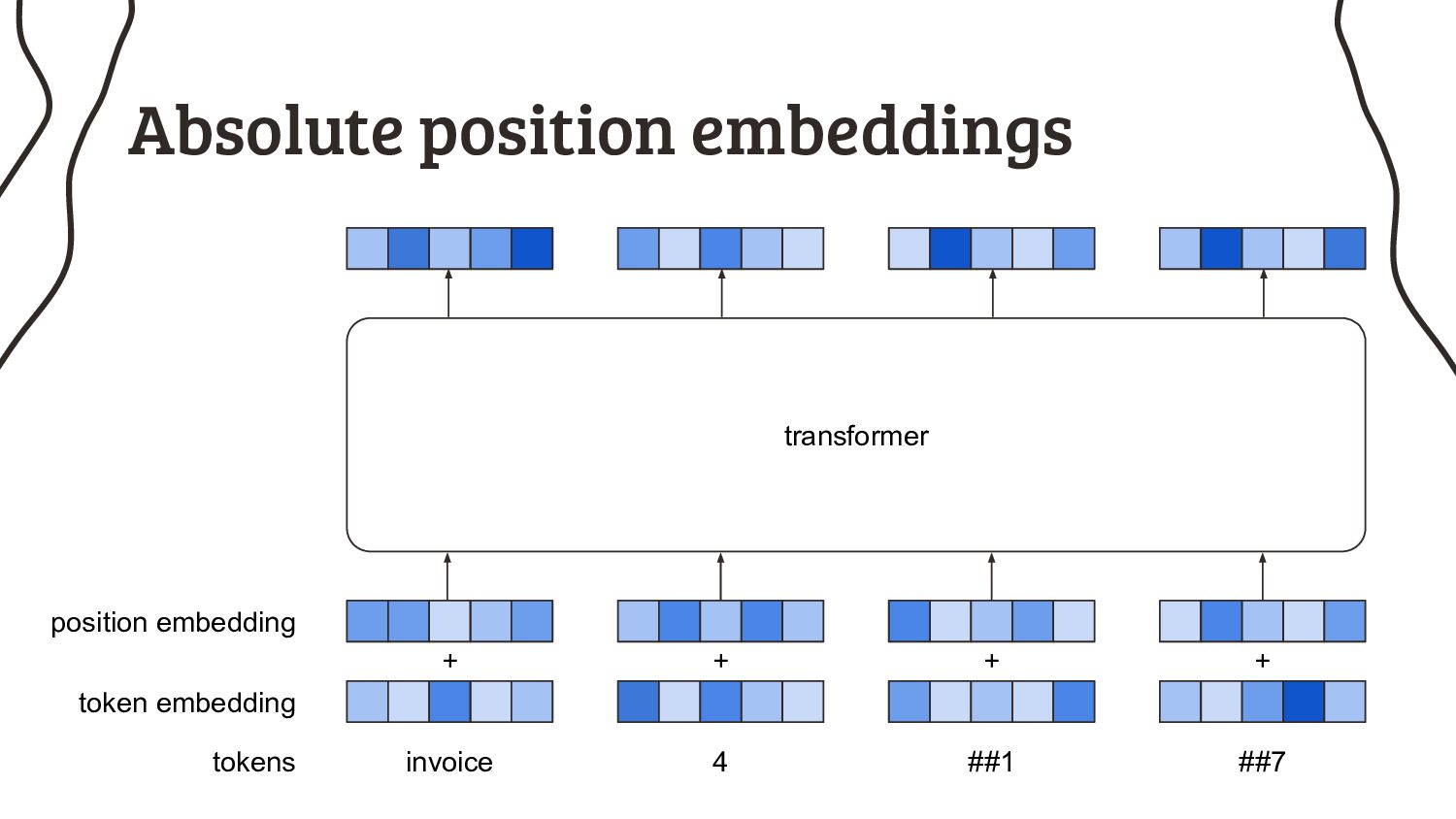
2. I can feed a sequence of any length into an RNN, why do transformers even have a limit? We’ll look into the architecture in more detail to understand that.
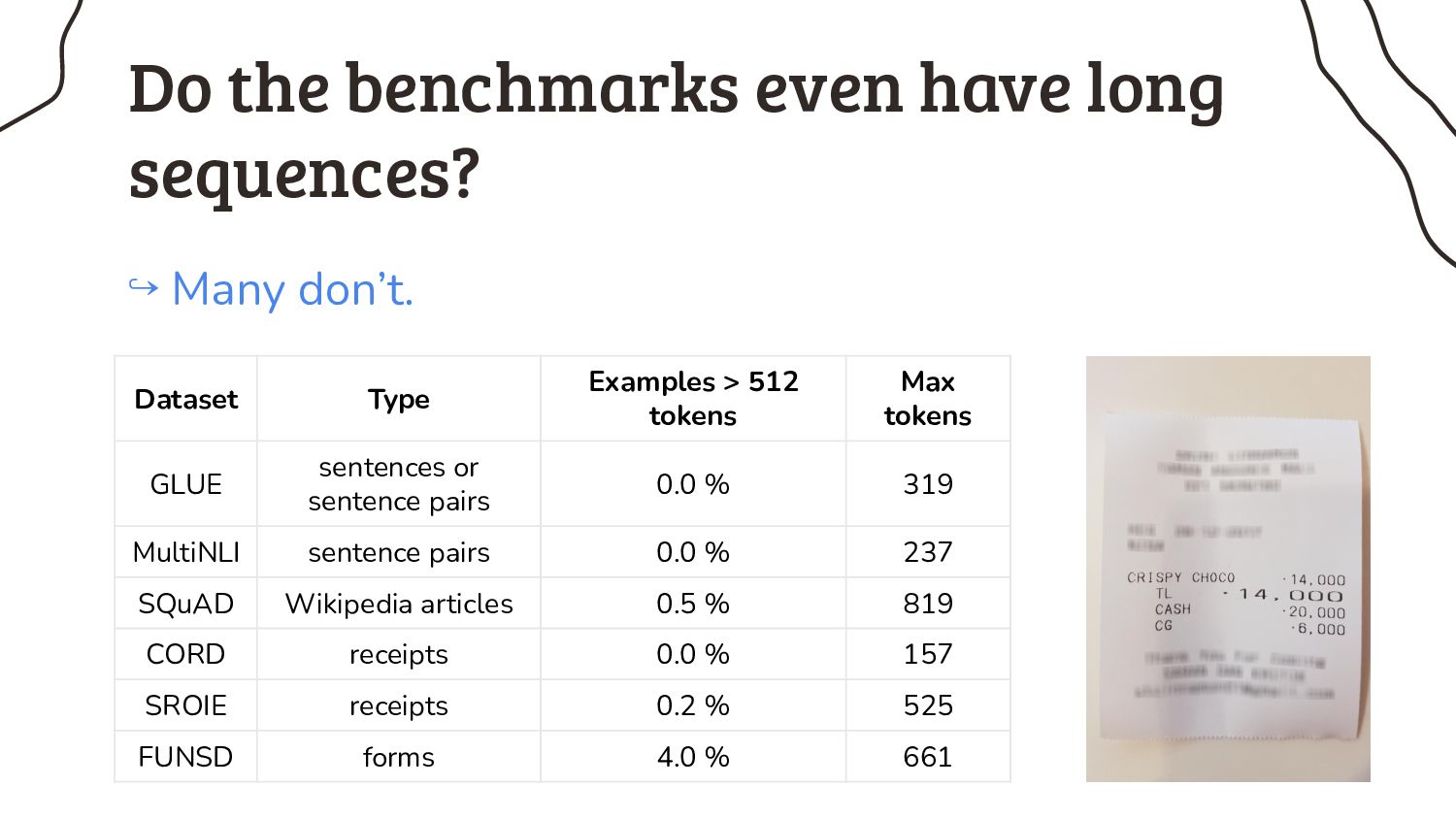
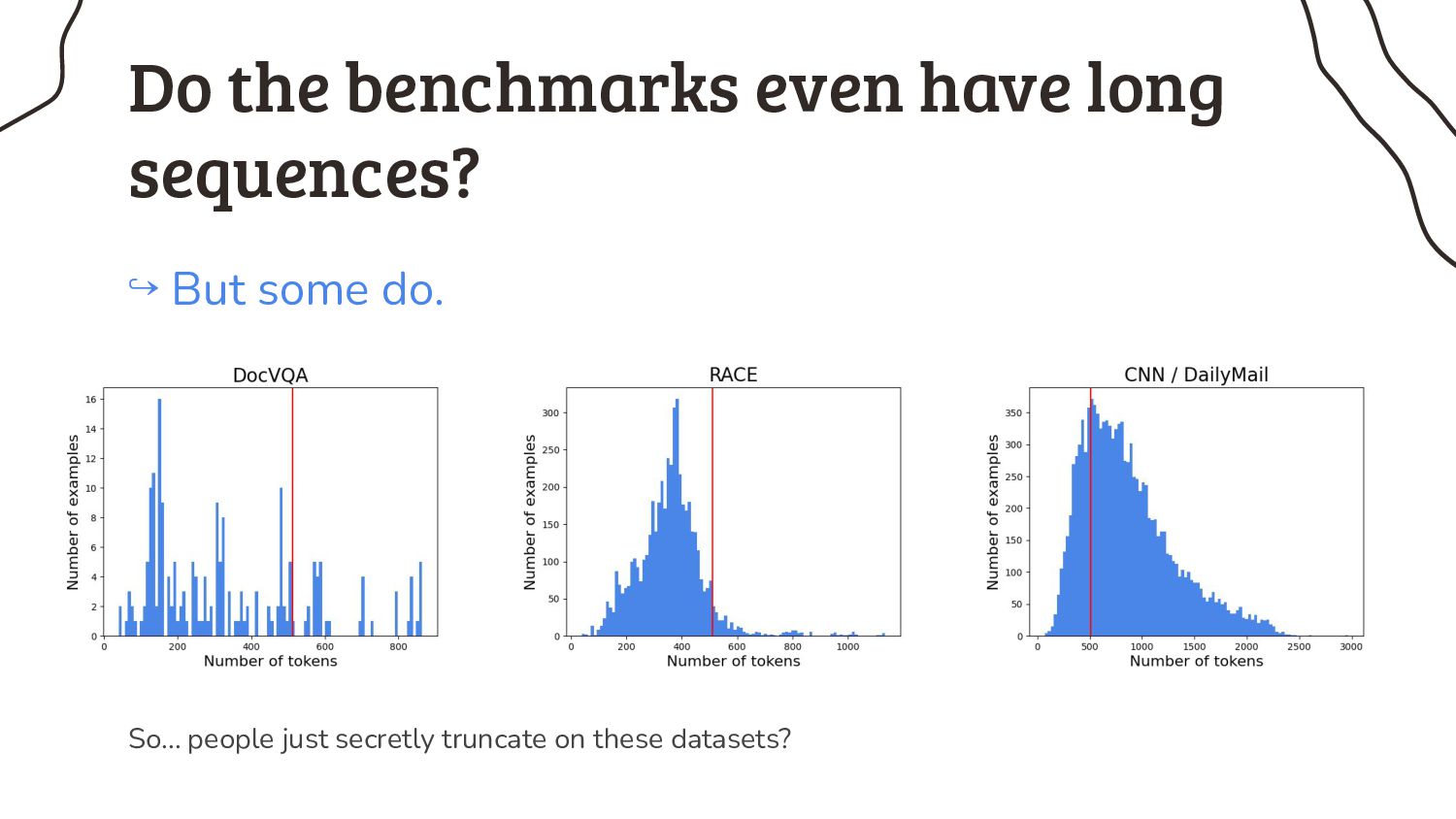
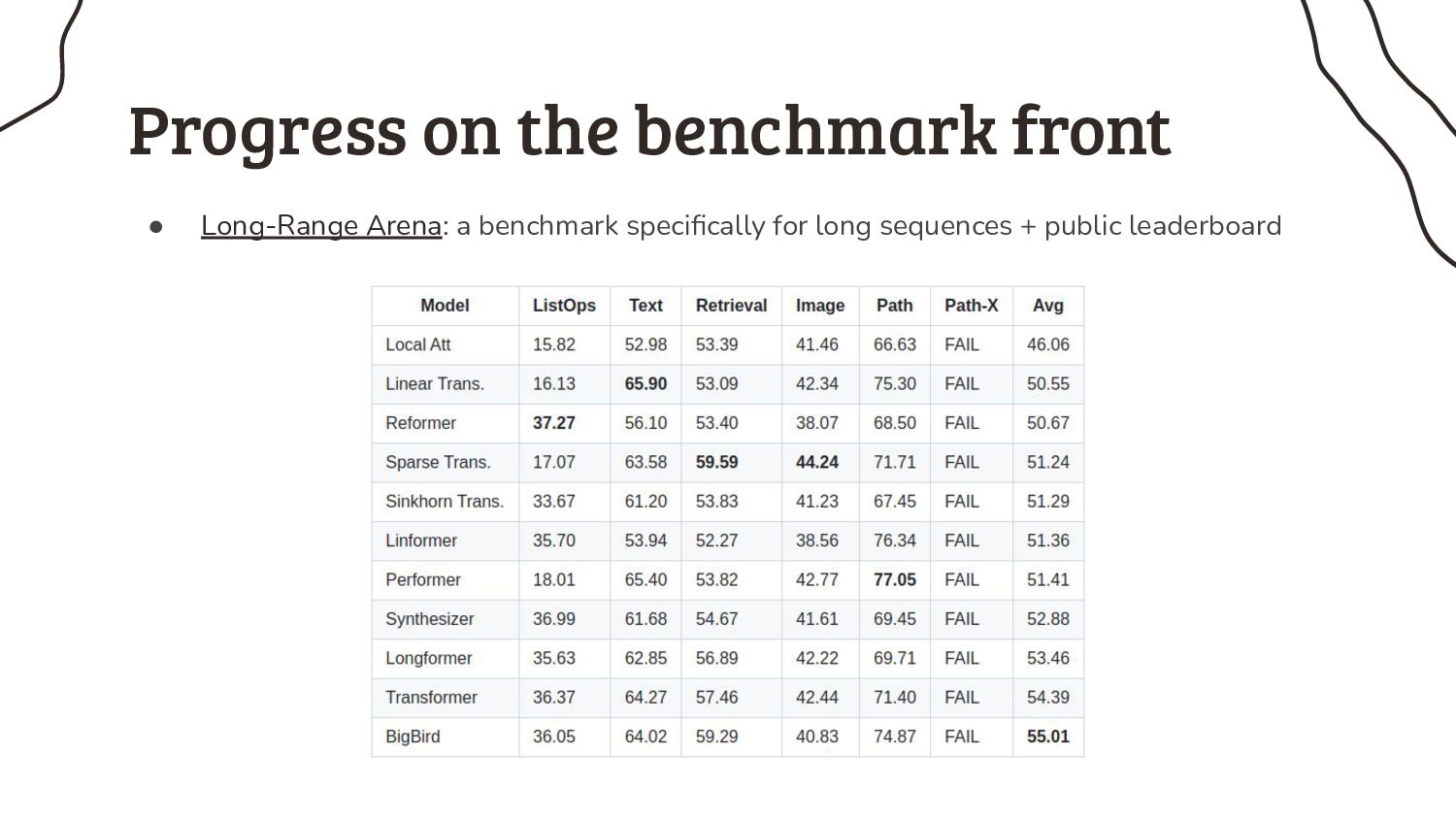
3. Somebody smart must have thought about this sequence length issue before, or not? Prepare yourself for a rant about benchmarks in NLP research.
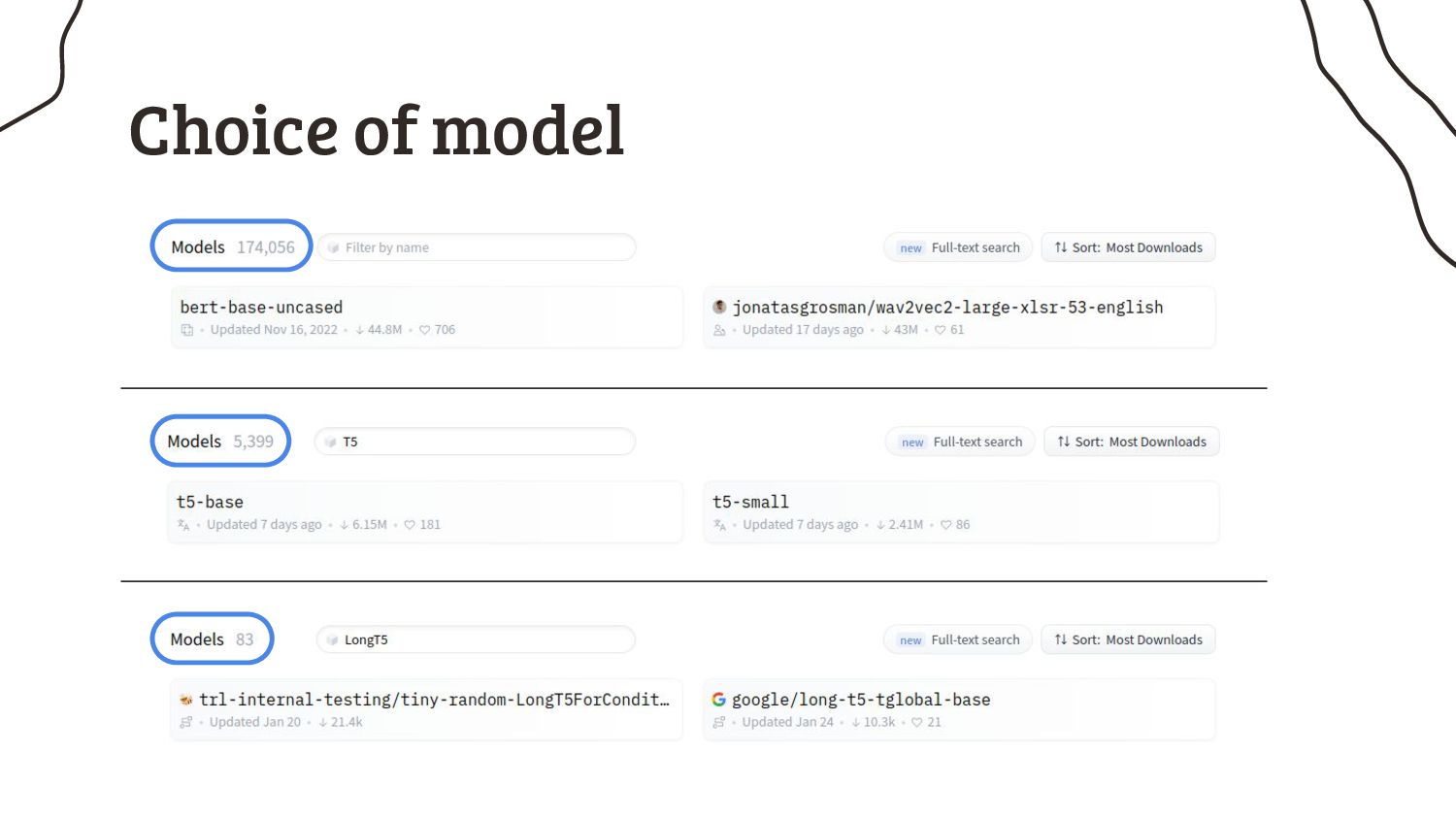
4. So what can we do to handle longer input sequences? Enjoy my collection of mediocre workarounds.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}