players are supporting it. Available on the cloud from Spark makers, Databricks. Also available for Click to Deploy on Google Compute Engine*. * https://cloud.google.com/solutions/hadoop/click-to-deploy
the Resilient Distributed Dataset From the user’s point of view, the RDD is effectively a collection, hiding all the details of its distribution throughout the cluster.
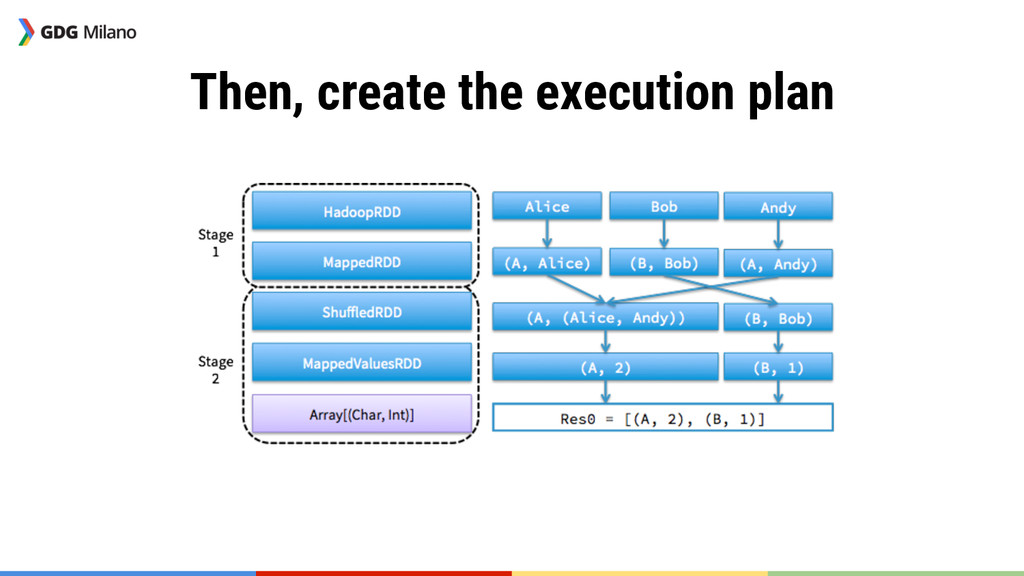
new RDD, extending the graph at each step (map, flatMap, filter and the like) Actions They are “terminal” operations, executing the graph (like collect or reduce)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
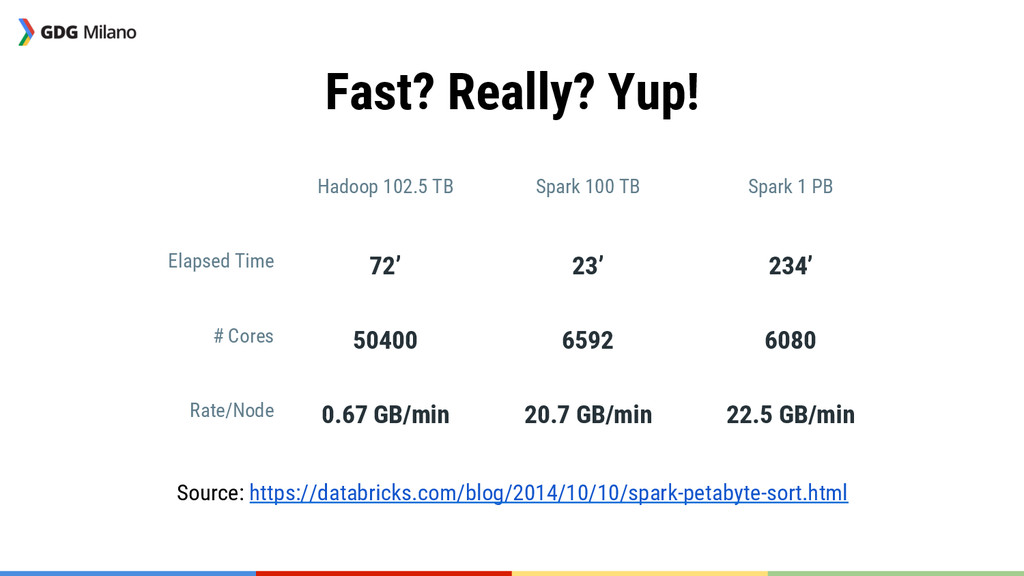{kind=link}
{kind=link}
{kind=link}
{kind=link}
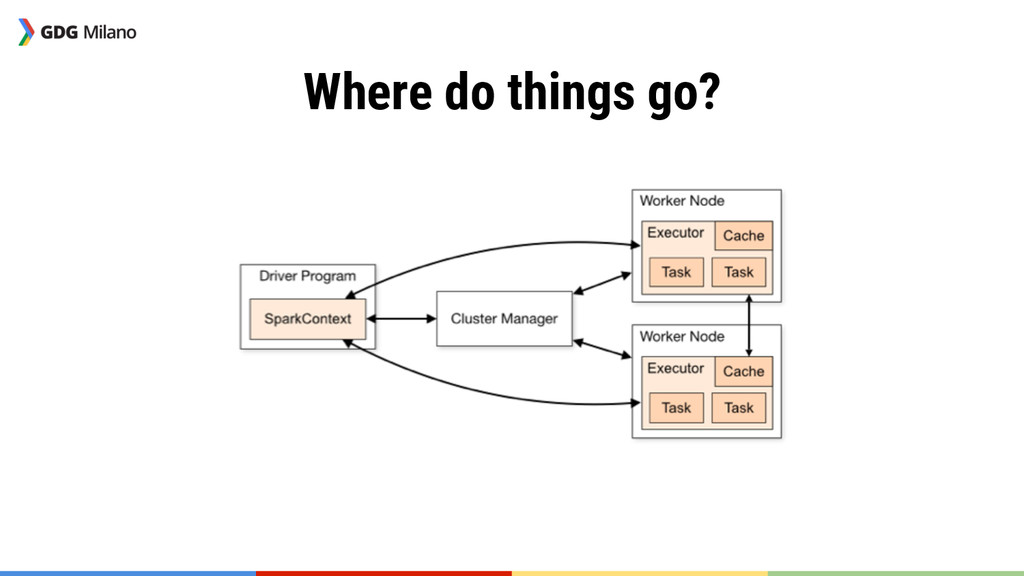{kind=link}
{kind=link}
{kind=link}
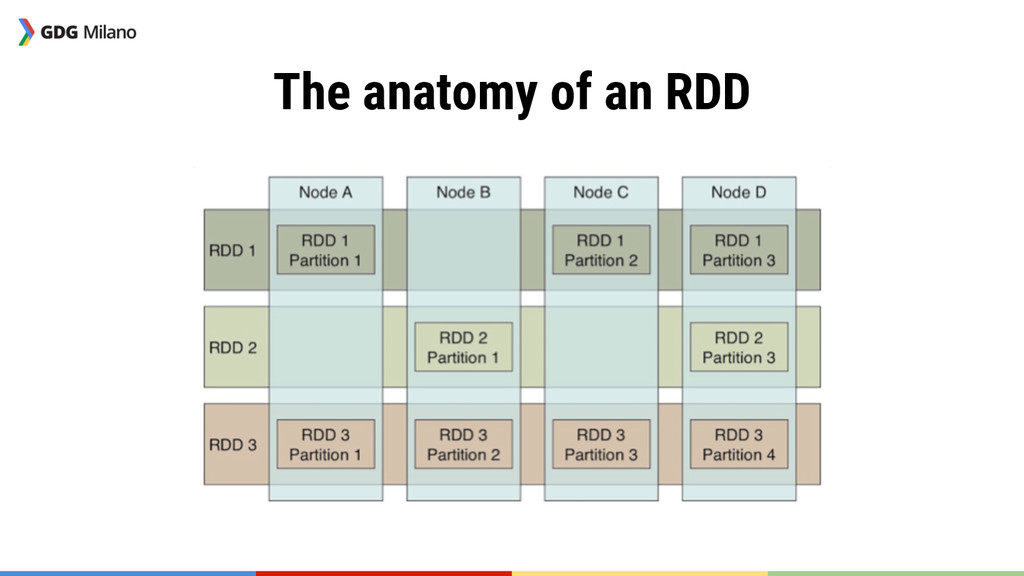{kind=link}
{kind=link}
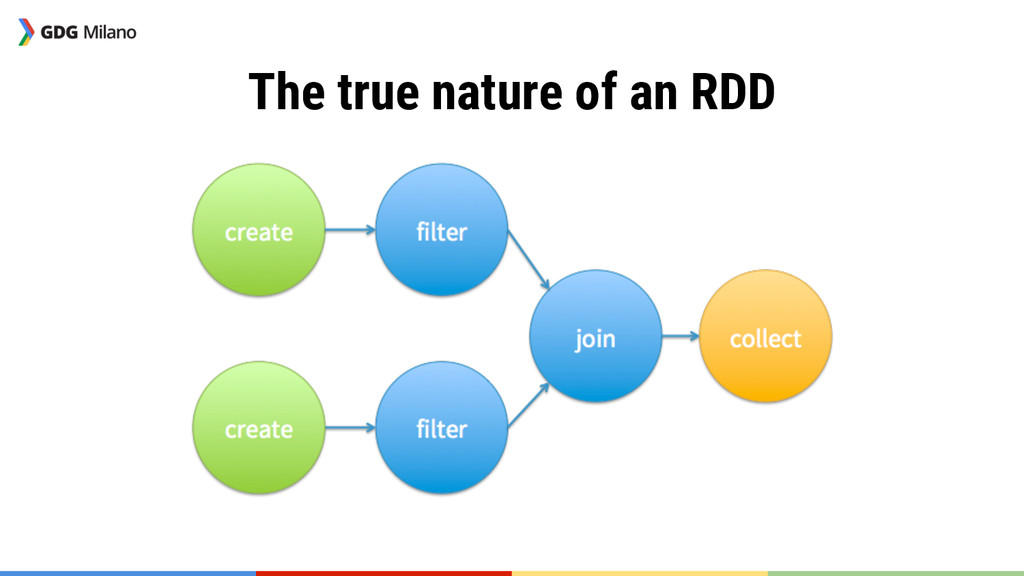{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}