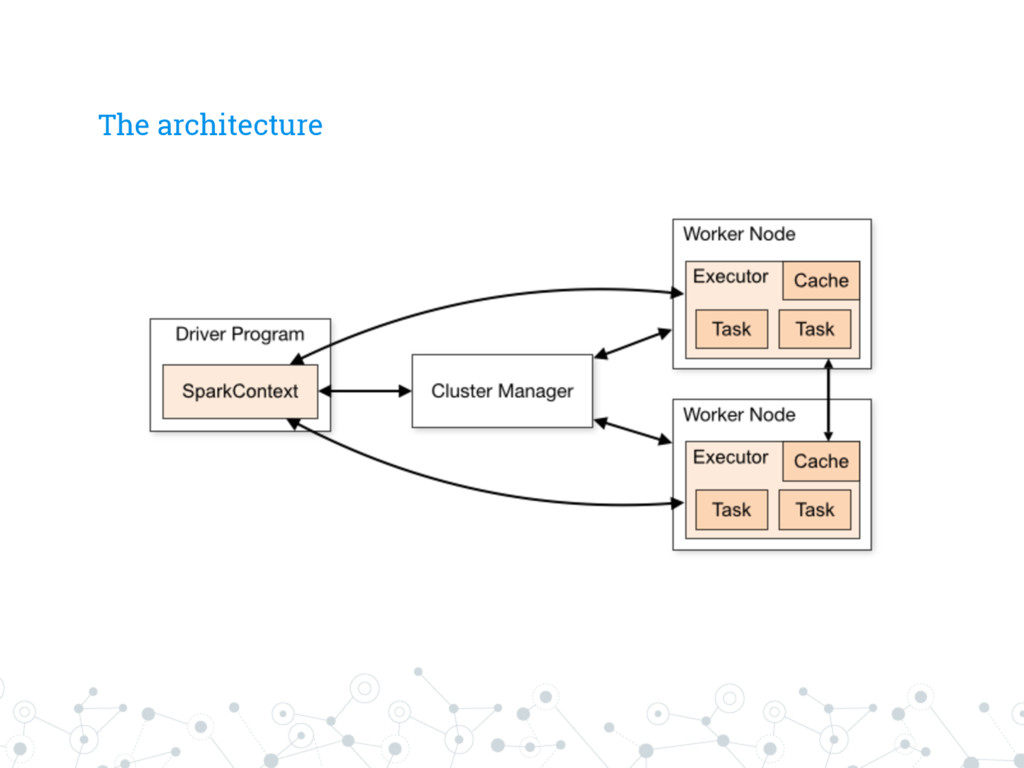
on top of an existing Hadoop deployment. Builds heavily on simple functional programming ideas. Computes and caches data in- memory to deliver blazing performances.
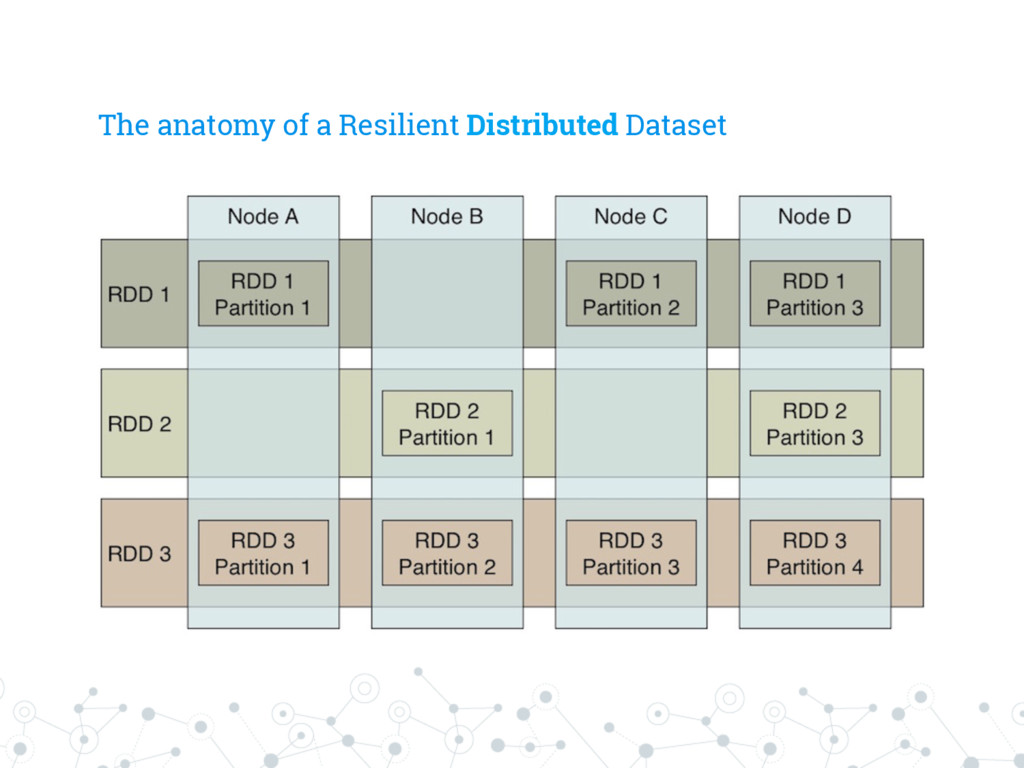
collection ◎ Very natural to use for Scala devs By the user’s point of view, the RDD is effectively a collection, hiding all the details of its distribution throughout the cluster.
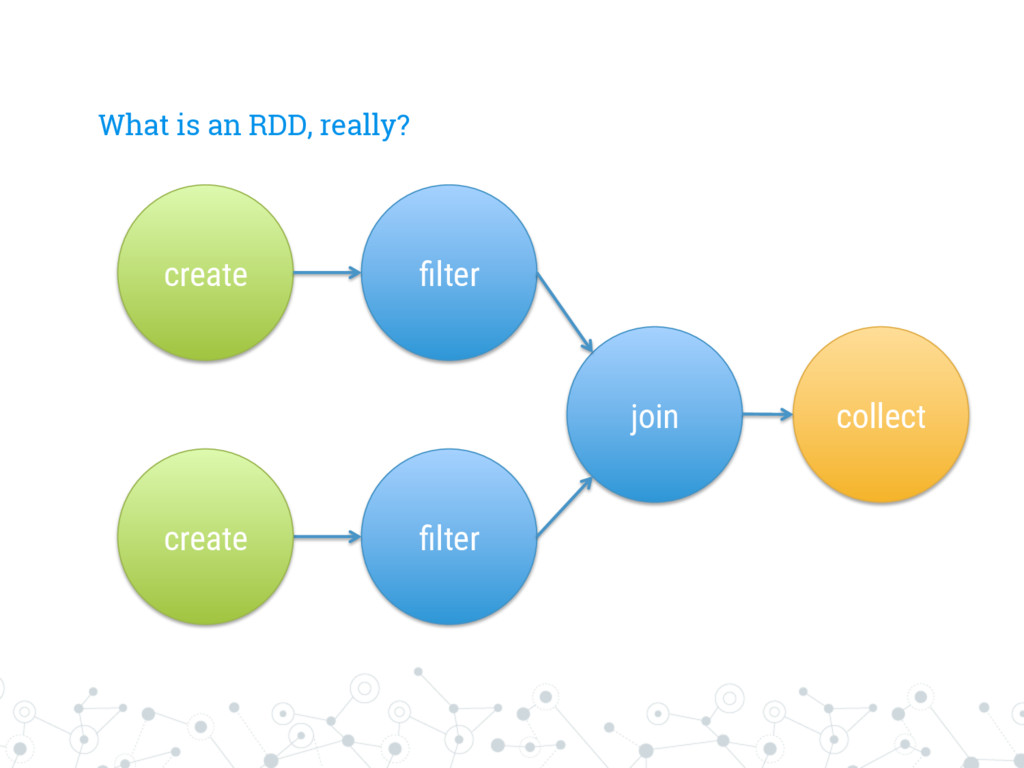
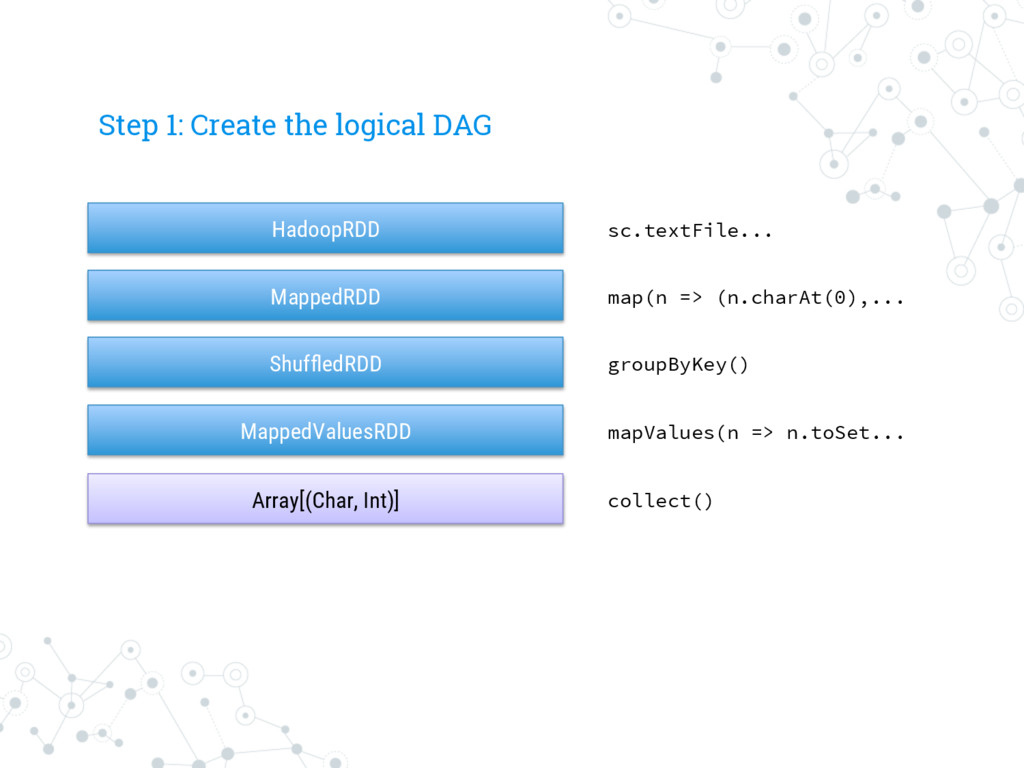
each step e.g.: u map u flatMap u filter What can I do with an RDD? Actions They are “terminal” operations, actually calling for the execution to extract a value e.g.: u collect u reduce
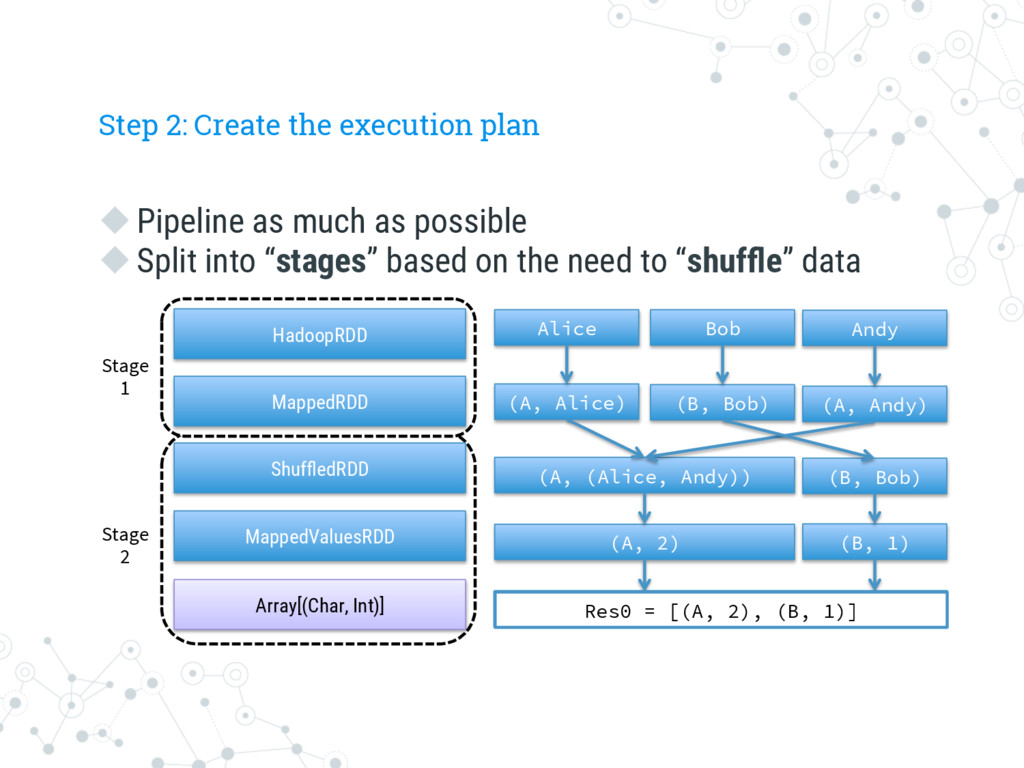
possible u Split into “stages” based on the need to “shuffle” data HadoopRDD MappedRDD ShuffledRDD MappedValuesRDD Array[(Char, Int)] Alice Bob Andy (A, Alice) (B, Bob) (A, Andy) (A, (Alice, Andy)) (B, Bob) (A, 2) Res0 = [(A, 2),….] (B, 1) Stage 1 Res0 = [(A, 2), (B, 1)] Stage 2
lazy, immutable representation of computation, rather than an actual collection of data, RDDs achieve resiliency by simply being re-executed when their results are lost*. * because distributed systems and Murphy’s Law are best buddies.
{kind=link}
{kind=link}
![Hello! I am Stefano Baghino Software Engineer @ DATABIZ [email protected]](https://files.speakerdeck.com/presentations/25ed964cb8b940a2824d00465c70a153/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Any questions? You can find me at: @stefanobaghino [email protected]](https://files.speakerdeck.com/presentations/25ed964cb8b940a2824d00465c70a153/slide_37.jpg){kind=link}