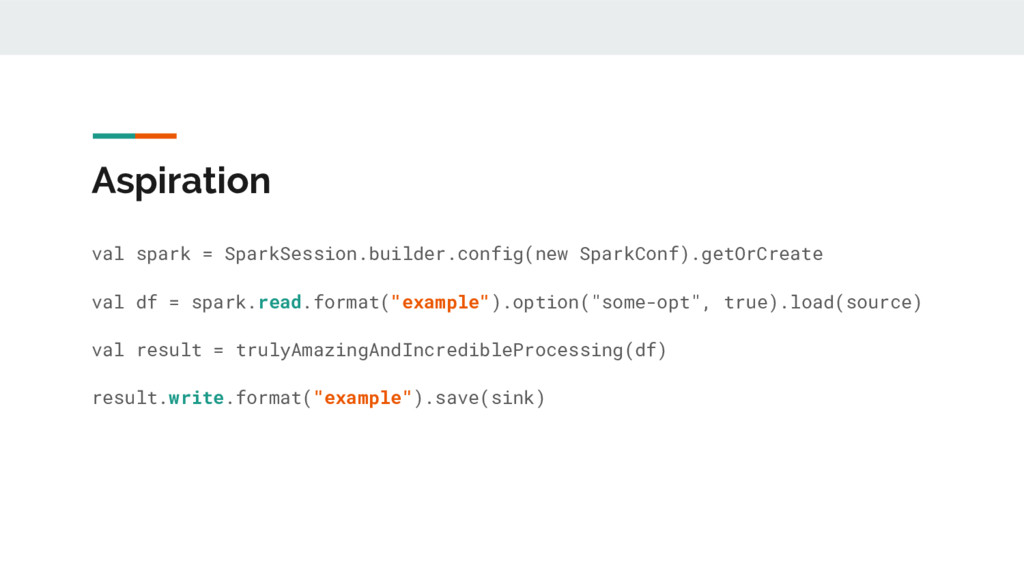
An introduction to the Spark Data Source API, which allows new data sources to be exposed for consumption through Spark SQL itself. You will be able to go beyond natively supported formats like JSON or CSV and query your favorite non-relational database or even your own web services through the convenient and familiar interface of SQL, using Spark itself as a distributed query engine.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}