logs, web snapshots • Keep per-node costs down to afford more nodes • Commodity x86 servers, storage (SAS), GbE LAN • Open source software: O(1) costs • O(1) operations • Accept failure as a background noise • Support computation in each server Written for location aware applications -MapReduce, Pregel/Giraph & others that can tolerate partial failures Page 4
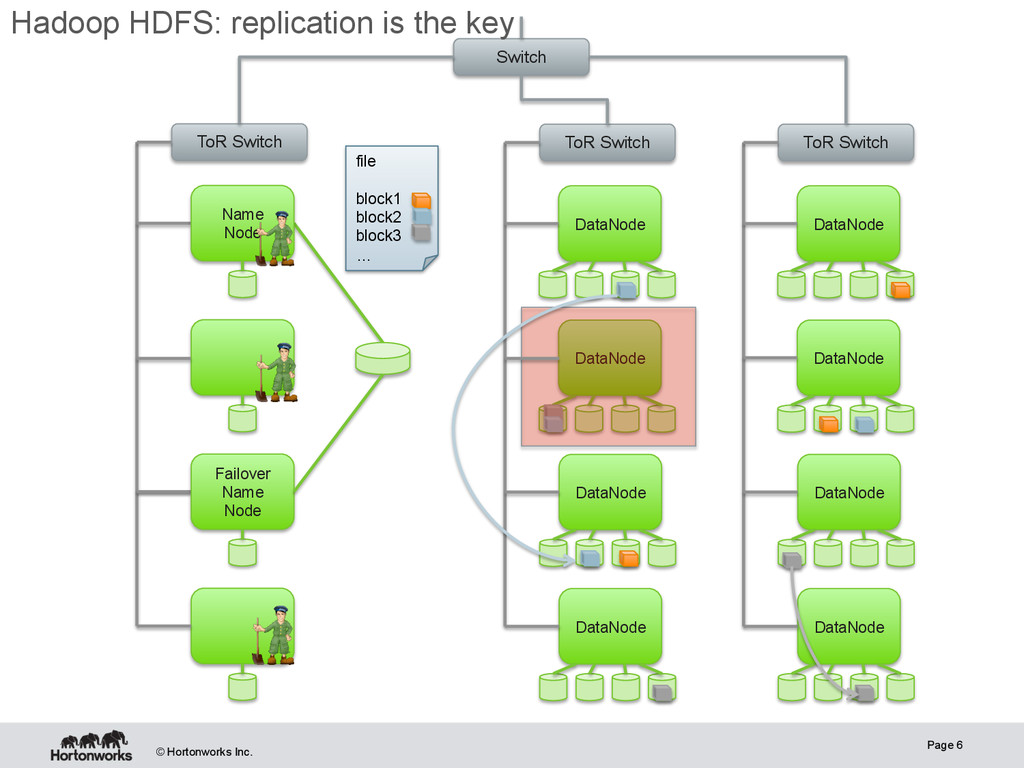
on Linux, Unix, Windows • Replication rather than RAID – break file into blocks – store across servers and racks – delivers bandwidth and more locations for work • Background work handles failures – replication of under-replicated blocks – rebalancing of unbalanced servers – checksum verification of stored files Location data for work schedulers Page 5
Switch DataNode DataNode DataNode DataNode ToR Switch Switch ToR Switch Failover Name Node Name Node file block1 block2 block3 … Hadoop HDFS: replication is the key
solid state storage technologies emerging • When will HDDs go away? • How to take advantage of mixed storage • SSD retains the HDD metaphor, hides the details (access bus, wear levelling) Page 7 We need to give the OS and DFS control of the storage, work with the application
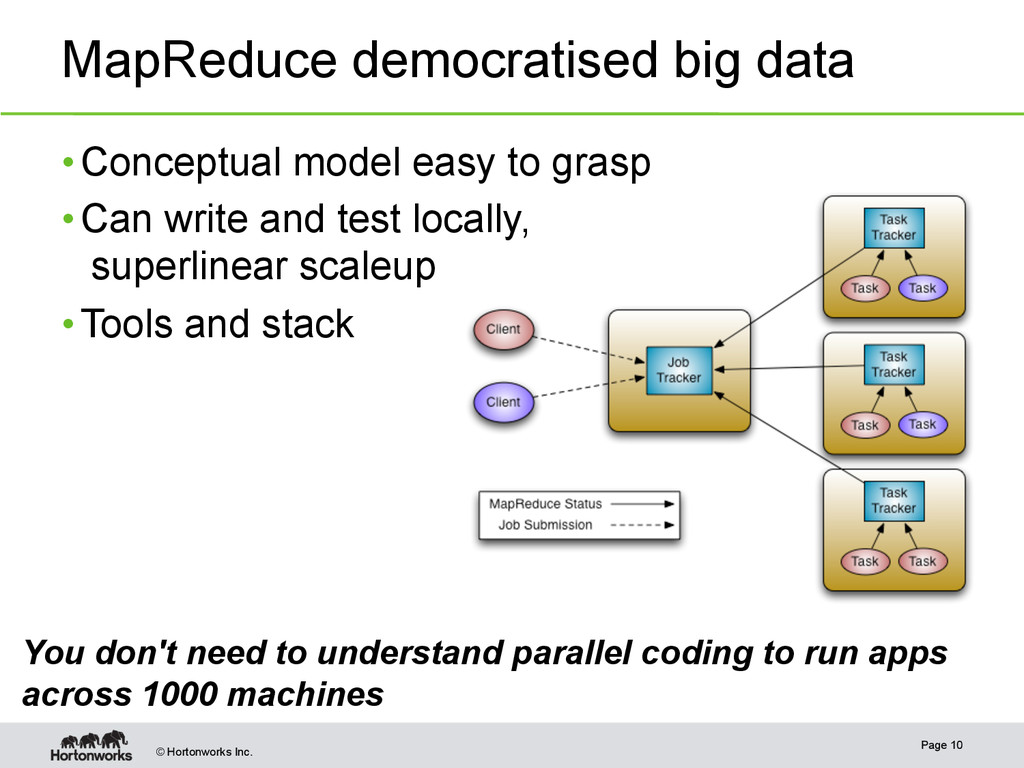
pairs 2. Reduce: <k,[v1 , v2 ,.. vn ]> è <k,v'> • Map trivially parallelisable on blocks in a file • Reduce parallelise on keys • MapReduce engine can execute Map and Reduce sequences against data • HDFS provides data location for work placement Page 9
to grasp • Can write and test locally, superlinear scaleup • Tools and stack Page 10 You don't need to understand parallel coding to run apps across 1000 machines
business @ Hortonworks + Cloudera • Full time projects at others: LinkedIn, IBM, MSFT, VMWare • Single developers can't compete “worked on my VM” • Small test runs take too long • Review-then-Commit neglects everyone's patches • at-scale tests on limited OS/JVM/Network setups Page 24
is the data in HDFS Ø the worth of all companies whose data it is Ø cost to individuals of data loss Ø cost to governments of losing their data Scheduling performance worth $100Ks to individual organisations Reliability costs time & support, even when Hadoop recovers Page 25
Kernel, Filesystem • Memory options (huge pages, vm stickiness, … ) • Scheduling • FS: performance vs durability • slow uptake of ext4 • interest in ZFS • RHAT and MSFT engagement bodes well for OS support Page 26
esp. • Web layer: stuck in old Jetty version for Java6; known weaknesses resurfacing in webhdfs • Google guava • protobuf: protoc versions in OS; protbuf.jar update hell Networking • IPv4 only for now • hostname, getLocalHostname, DNS caching • Exception wrapping & diags: (hosts, ports, wiki links) Page 27
7+ baseline; Java 8 tested • Adopt Java 7 file IO APIs for file:// fs • Client-side code to implement Closeable • OSGi containers for hosting YARN apps/ MR jobs • Move up all the JARs we depend on • Move to Jersey for REST/Web • Gradual switch to SLF4J logging • Language features? multiple catch probably best Page 30
for language level feature adoption, sell the JRE 8 runtime as a superior platform to 7. GC and perf enhancements are landing here, not in 7 • design callbacks and classes for Lambda expressions • s/{Thread,Runnable}/r/java.util.concurrent • add libraries for Java 8-only. Twill? Get Hadoop developers experienced with writing Java 8 apps –even small ones– The further up the stack the faster moving you can be Page 32
Hadoop test suites are in svn 2. testing hadoop releases against Java 8+ will catch regressions (issue: whose fault?) 3. Same for HBase & other common in-cluster apps. 4. Apache have jenkins-managed builds; could adopt java 8 machines/VMs with help. (issue: who worries) Getting people to care about breaking builds on future Java versions/other platforms always trouble. Page 33
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}