Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
210629 Stockmark Tech Meetup #1 AWSを活用したCPU/GPU...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Stockmark
July 02, 2021
Technology
740
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
210629 Stockmark Tech Meetup #1 AWSを活用したCPU/GPU環境の並列化
Stockmark
July 02, 2021
More Decks by Stockmark
See All by Stockmark
LLM開発・活用の舞台裏@2024.04.25
stockmark
0
710
ストックマークデザイナー採用LT/ Stockmark desginer recruiting LT
stockmark
0
380
ストックマークテックミートアップ#8 / Stockmark Tech MeetUp#8
stockmark
0
200
Stockmark Designer Recruiting Pitch
stockmark
1
1.5k
AWSを活用した機械翻訳のためのGPU並列処理環境の構築/aso
stockmark
0
1.3k
Stockmark_Recruiting Guidebook
stockmark
3
210k
Other Decks in Technology
See All in Technology
AICoEでAIネイティブ組織への進化
yukiogawa
0
210
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
24
10k
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
490
「休む」重要さ
smt7174
6
1.6k
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
750
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
410
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
0
130
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
310
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1k
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
220
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
1
140
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
950
Featured
See All Featured
Utilizing Notion as your number one productivity tool
mfonobong
4
450
We Are The Robots
honzajavorek
0
280
The Curious Case for Waylosing
cassininazir
1
440
Building Adaptive Systems
keathley
44
3.1k
Designing Experiences People Love
moore
143
24k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
Google's AI Overviews - The New Search
badams
0
1.1k
YesSQL, Process and Tooling at Scale
rocio
174
15k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Embracing the Ebb and Flow
colly
88
5.1k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.2k
Transcript
Stockmark Tech meetup #1 テックブログで語られなかった 試行錯誤の数々を公開! 〜AWSを活用したCPU/GPU環境の並列化〜 ストックマーク株式会社 Anews Engineer 麻生
晋併 2021/06/29
ストックマークのプロダクト:「Anews」 • 国内外30,000メディアの記事を毎日収集 • 最先端の自然言語処理で個人や組織のミッションに即した記事をレコメンド
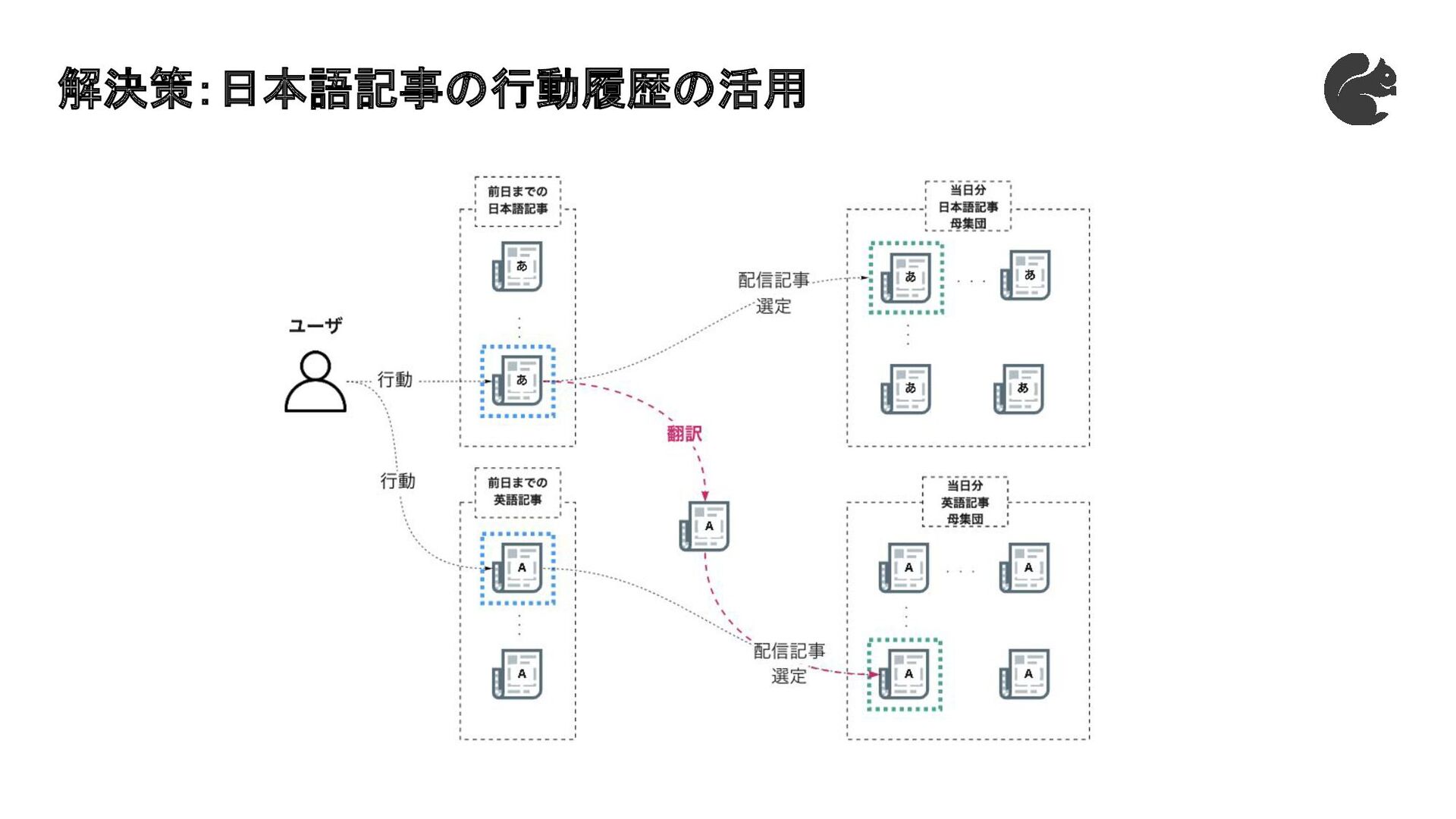
課題:英語記事のレコメンド精度の向上 • ユーザーの過去記事へのアクションから当日配信する記事を選定 • 英語記事は読まれない → 精度が上がらない → 読まれないまま... 読むのが大変なので
精度が高くないなら 読みたくない。
解決策:日本語記事の行動履歴の活用
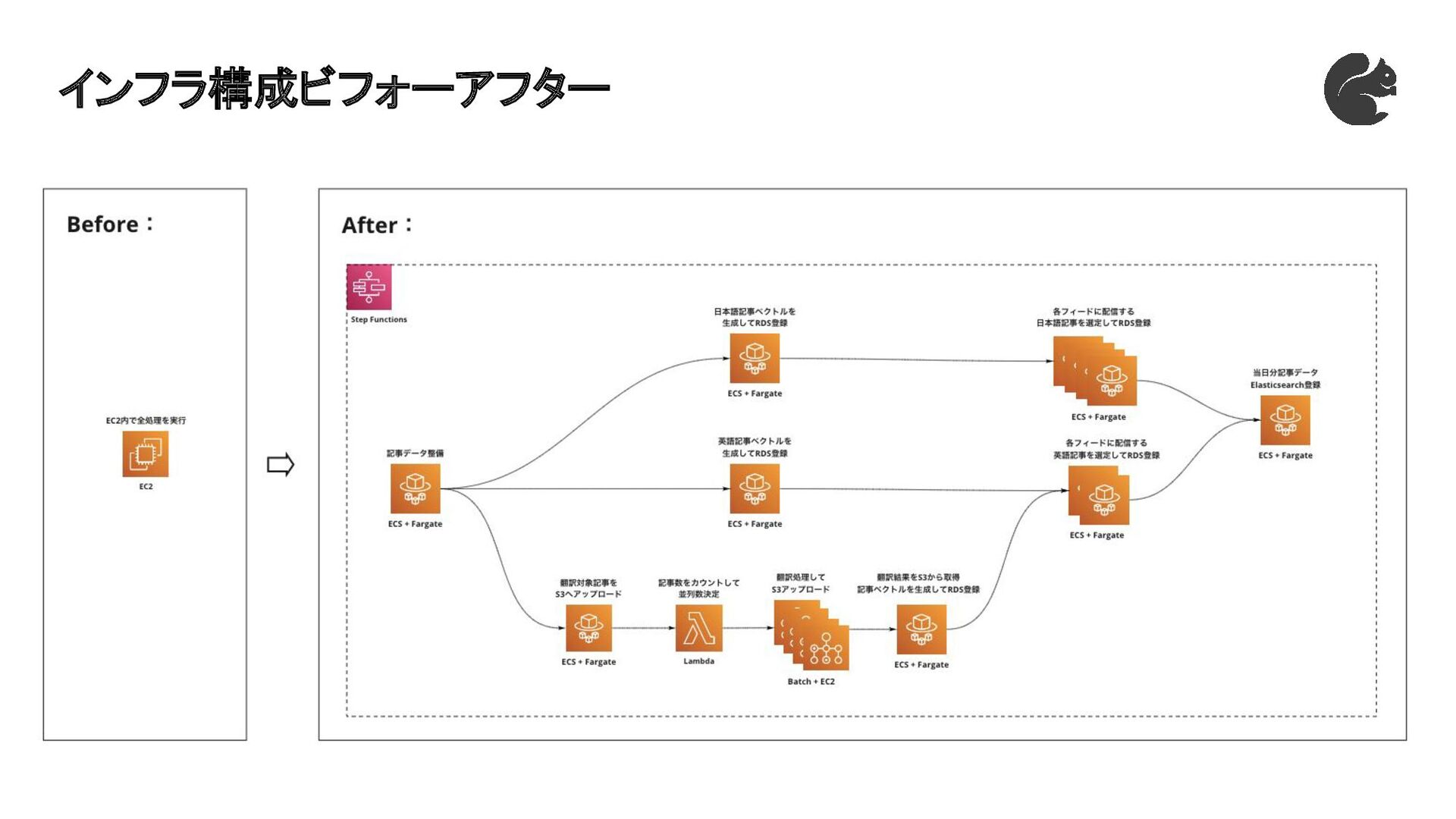
翻訳のためのインフラ見直し(現状:EC2インスタンス1台) POINT1:翻訳用のGPU並列処理環境の追加 • 翻訳はGPU環境を複数用意して並列処理しないと処理時間がかかりすぎる POINT2:既存処理環境(CPU環境)と翻訳処理環境(GPU環境)の分離 • GPU不要の既存処理をGPU環境で実行するとコストがかかりすぎる POINT3:ワークフローエンジンの導入 • サーバを跨いだワークフローの管理が必要
インフラ選定結果 翻訳処理環境(GPU環境):AWS Batch + Amazon EC2 • GPUを利用可能、かつ、配列ジョブで並列処理を実装しやすいことからを採用 • 並列数を記事数に応じて変えるため、事前に
Lambda で必要な並列数を算出 既存処理環境(CPU環境):Amazon ECS + AWS Fargate • EC2は他サービスと連携しづらいため既存処理環境も差し替え • 既に一部タスクを ECS + Fargate で実行できる状態にしていたので他タスクへ拡張 ワークフローエンジン:AWS Step Functions • AWSサービスとの連携しやすさ+社内での利用実績から採用
インフラ構成ビフォーアフター
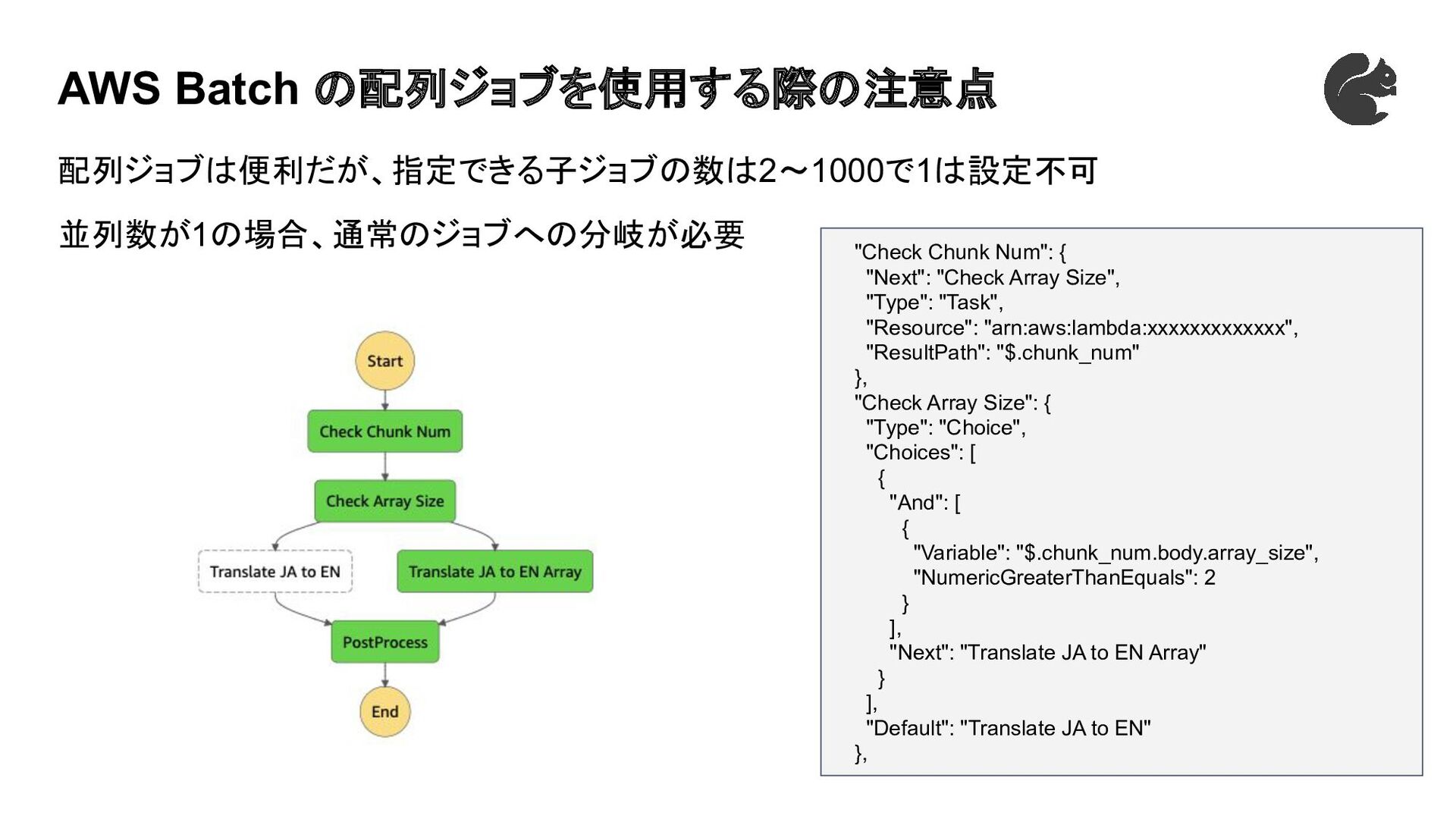
AWS Batch の配列ジョブを使用する際の注意点 配列ジョブは便利だが、指定できる子ジョブの数は2〜1000で1は設定不可 並列数が1の場合、通常のジョブへの分岐が必要 "Check Chunk Num": { "Next":
"Check Array Size", "Type": "Task", "Resource": "arn:aws:lambda:xxxxxxxxxxxxx", "ResultPath": "$.chunk_num" }, "Check Array Size": { "Type": "Choice", "Choices": [ { "And": [ { "Variable": "$.chunk_num.body.array_size", "NumericGreaterThanEquals": 2 } ], "Next": "Translate JA to EN Array" } ], "Default": "Translate JA to EN" },
インフラ再構築のポイント Infrastructure as Code (IaC) • コードで書いてある通りにインフラの追加・削除・変更が可能 → 開発環境で試行錯誤しやすい、本番環境反映時の負担軽減とミス防止 •
コードが設計書としても機能する → 引き継ぎしやすい CI/CD • GitHub で特定のタグを付与すると CodeBuild で自動デプロイ用のワークフローが実行され る(CPU/GPU環境別のイメージのbuild&push、ECSとBatchの定義更新) → 開発環境/本番環境へのデプロイ時の負担軽減とミス防止
ここからテックブログ後の話...
バッチの高速化 フィード生成(配信記事の選定)の処理時間がユーザー数に比例する 1フィード1コンテナで処理 <組織別> ・キーワードフィード(日) ・キーワードフィード(英) ・関連フィード(日) ・関連フィード(英) ・見逃しフィード <ユーザー別>
・パーソナルフィード(日) ・パーソナルフィード(英)
バッチの高速化 目的 • ユーザ数が増えても一定時間でバッチ処理が終わるようにする 手段 • 処理対象のテーマ数/ユーザー数に応じて並列数が上がる仕組みにする 選択肢 • Step
Functions の Map ステートを使用する ◦ ECS Fargate ◦ Lambda • AWS Batch の配列ジョブを使用する ◦ AWS Batch(EC2) ◦ AWS Batch(Fargate)
Step Functions の Map ステート Map ステート • 配列を渡すと配列の各要素を入力として共通の処理を実行できる •
各タスクが処理対象のユーザーを識別できるように配列を与えれば良い (例:[0, 1, 2,..] → 0はid:1-999のユーザ、1はid:1000-1999のユーザ...) 候補1:Map ステート + ECS Fargate • 現行インフラの延長でできそうだったので最初に検討 候補2:Map ステート + Lambda • フィード生成処理をFargateではなくLambdaで実行するパターン 並列数決定Lambda フィード生成
Step Functions の Map ステート:検討結果 候補1:Map ステート + ECS Fargate
→ ❌ • RunTask API(ECSタスクをコールするAPI)の制約により断念 ◦ Mapステートは並列数の数だけAPIを呼び出すが、APIの呼び出しは同一アカウントで1 秒につき1回までという制限がある 候補2:Map ステート + Lambda → ❌ • Lambdaのメモリ10GBの制限がネックになるのが見えていたのであまり検討してない
AWS Batch の配列ジョブ 配列ジョブ • ジョブ送信時に指定した数で子ジョブを生成し、各ジョブで共通の処理を実行できる • 各ジョブには0から始まるAWS_BATCH_ARRAY_JOB_INDEXが振られる 候補1:配列ジョブ +
EC2 • 使い方は翻訳処理とほぼ同じ 候補2:配列ジョブ + Fargate • EC2ではなくFargateを使うパターン (再掲)翻訳処理のフロー
AWS Batch の配列ジョブ:検討結果 候補1:配列ジョブ + EC2 → ❌ • 処理自体は可能だが、ホストを考慮した工夫が必要
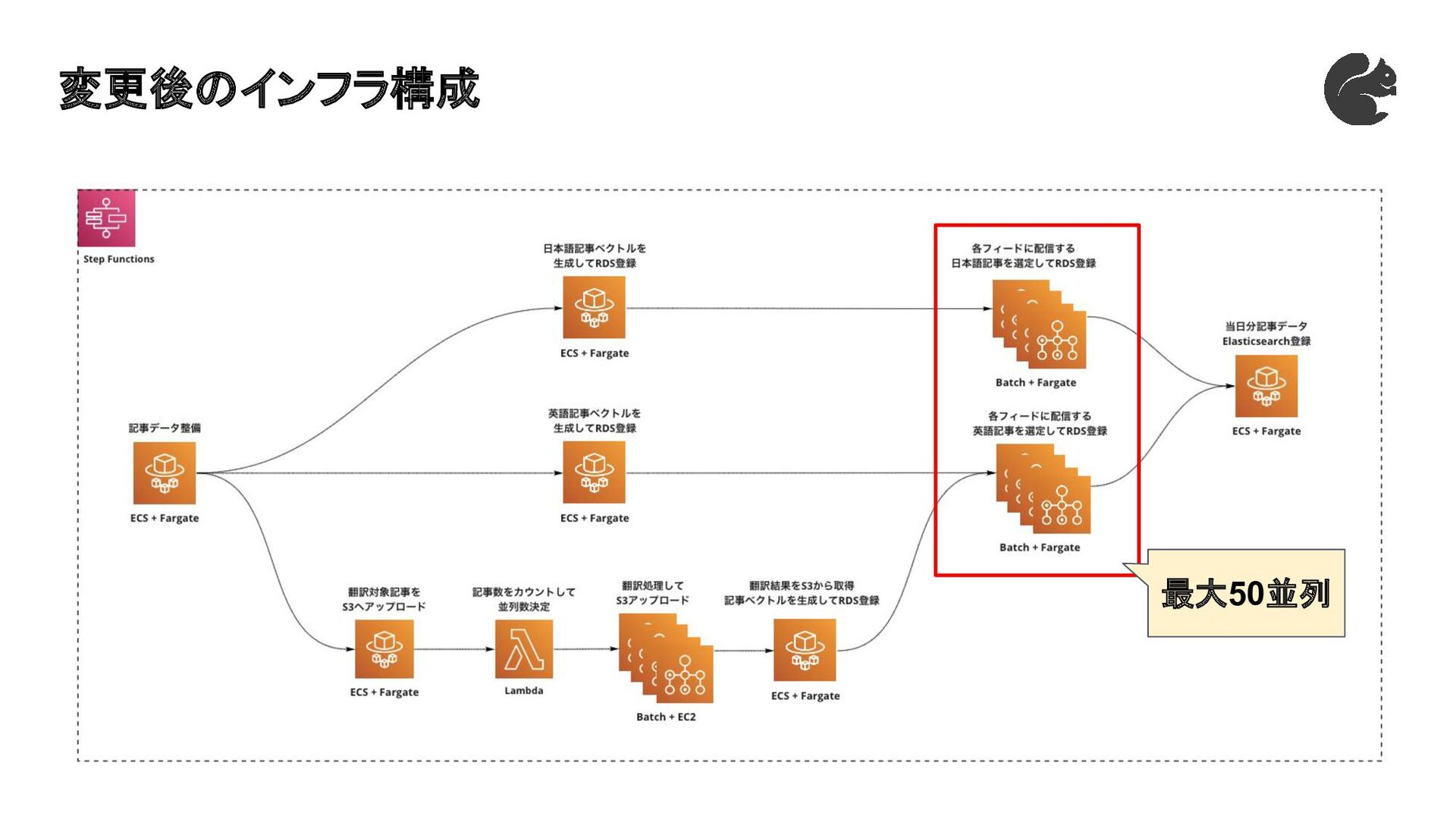
◦ 1インスタンス上で複数のコンテナが大量の書き込み(モデル/辞書のDL)をすると、EBS のI/Oのパフォーマンスが低下し、ジョブ終了時にAWS Batchが行うコンテナチェックがタ イムアウトする ◦ EBSへ課金する、1インスタンス1コンテナしか起動できないようなインスタンスタイプを選 択する、イメージにモデル/辞書を入れておく(未検証)、等が必要 候補2:配列ジョブ + Fargate → ⭕ • ホストの考慮が不要、かつインスタンスの起動がないので高速 注:FargateはGPUを利用できないので翻訳処理では引き続きEC2を利用
変更後のインフラ構成 最大50並列
サーバレスな並列処理環境について得た知見 並列処理をする場合は1〜3の順番で環境を検討すると良い(2021/06時点では) 1. Step Functions の Map ステート + Lambda
• vCPU:6、メモリ:10GB、タイムアウト:15分 の制約内で処理できる場合 2. AWS Batch の配列ジョブ + Fargate • vCPU:4、メモリ:30GB の制約内で処理できる場合 3. AWS Batch の配列ジョブ + EC2 • 1, 2で対応できない場合(GPUなど) 並列数を増やす代わりに1タスクあたりの 負荷を減らせば、1,2でかなりの範囲をカ バーできる
まとめ 翻訳処理の導入(GPU並列処理環境の構築) • 英語記事のレコメンド精度を上げるために翻訳処理を導入 • ベクトル生成、フィード生成処理を ECS Fargate + Step
Functions に移行 • 翻訳用に AWS Batch(EC2)の配列ジョブを採用 バッチの高速化(CPU並列処理環境の構築) • ユーザー数の増加に耐えるよう、フィード生成処理を並列化 • フィード生成処理を ECS Fargate から AWS Batch(Fargate)の配列ジョブへ移行
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}