Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文読み会 / HIGITCLASS: Keyword-Driven Hierarchical...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
stssg
February 17, 2020
Research
0
550
論文読み会 / HIGITCLASS: Keyword-Driven Hierarchical Classification of GitHub Repositories
IEEE ICDM 2019 論文読み会
stssg
February 17, 2020
Tweet
Share
Other Decks in Research
See All in Research
Proposal of an Information Delivery Method for Electronic Paper Signage Using Human Mobility as the Communication Medium / ICCE-Asia 2025
yumulab
0
170
ブレグマン距離最小化に基づくリース表現量推定: バイアス除去学習の統一理論
masakat0
0
140
空間音響処理における物理法則に基づく機械学習
skoyamalab
0
190
説明可能な機械学習と数理最適化
kelicht
2
940
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
330
社内データ分析AIエージェントを できるだけ使いやすくする工夫
fufufukakaka
1
900
An Open and Reproducible Deep Research Agent for Long-Form Question Answering
ikuyamada
0
280
When Learned Data Structures Meet Computer Vision
matsui_528
1
2.9k
"主観で終わらせない"定性データ活用 ― プロダクトディスカバリーを加速させるインサイトマネジメント / Utilizing qualitative data that "doesn't end with subjectivity" - Insight management that accelerates product discovery
kaminashi
15
20k
学習型データ構造:機械学習を内包する新しいデータ構造の設計と解析
matsui_528
6
3.2k
地域丸ごとデイサービス「Go トレ」の紹介
smartfukushilab1
0
920
Grounding Text Complexity Control in Defined Linguistic Difficulty [Keynote@*SEM2025]
yukiar
0
110
Featured
See All Featured
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
67
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
330
The Spectacular Lies of Maps
axbom
PRO
1
520
Believing is Seeing
oripsolob
1
57
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
120
Abbi's Birthday
coloredviolet
1
4.8k
We Have a Design System, Now What?
morganepeng
54
8k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
24k
It's Worth the Effort
3n
188
29k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3k
Transcript
論文紹介 2020/02/17 須賀 聖 @IEEE ICDM 2019論文読み会
HIGITCLASS: Keyword-Driven Hierarchical Classification of GitHub Repositories Yu Zhang, Frank
F. Xu, Sha Li, Yu Meng, Xuan Wang, Qi Li, Jiawei Han 2
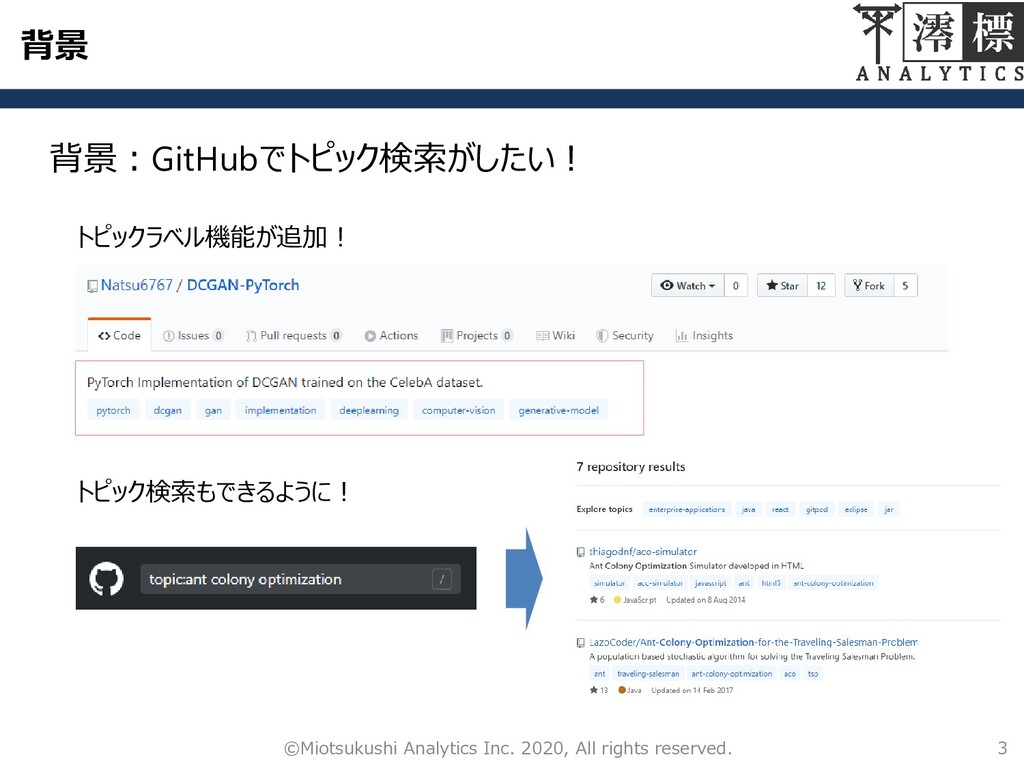
背景 3 ©Miotsukushi Analytics Inc. 2020, All rights reserved. 背景:GitHubでトピック検索がしたい!
トピックラベル機能が追加! トピック検索もできるように!
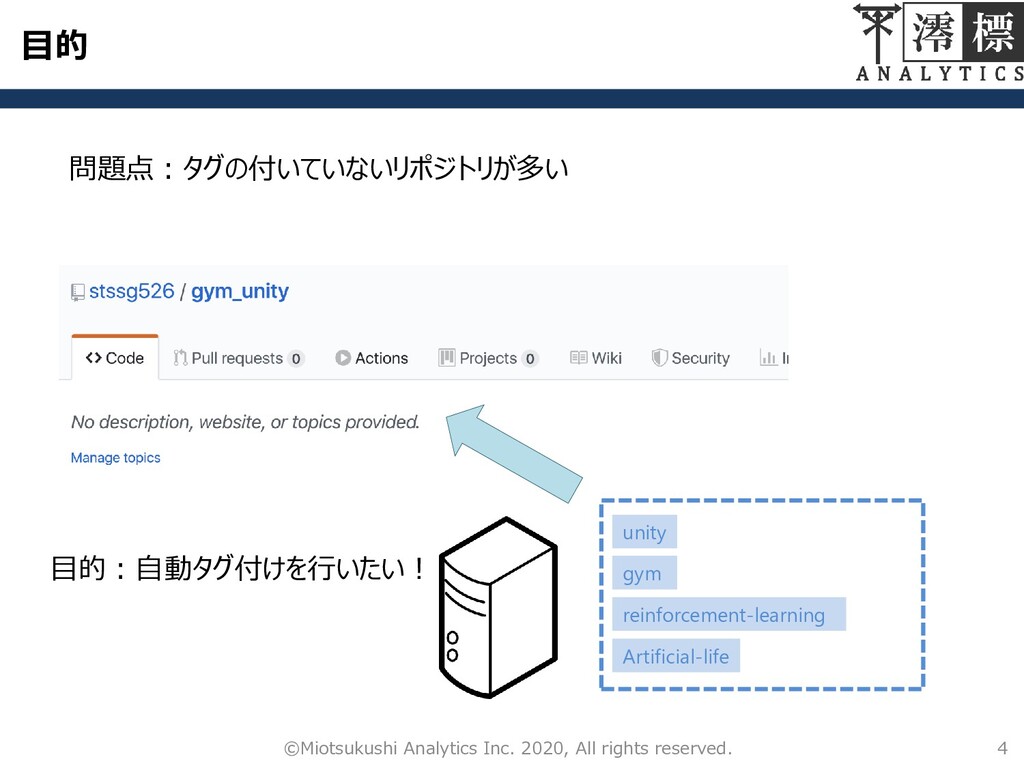
目的 4 ©Miotsukushi Analytics Inc. 2020, All rights reserved. 問題点:タグの付いていないリポジトリが多い
目的:自動タグ付けを行いたい! unity gym reinforcement-learning Artificial-life
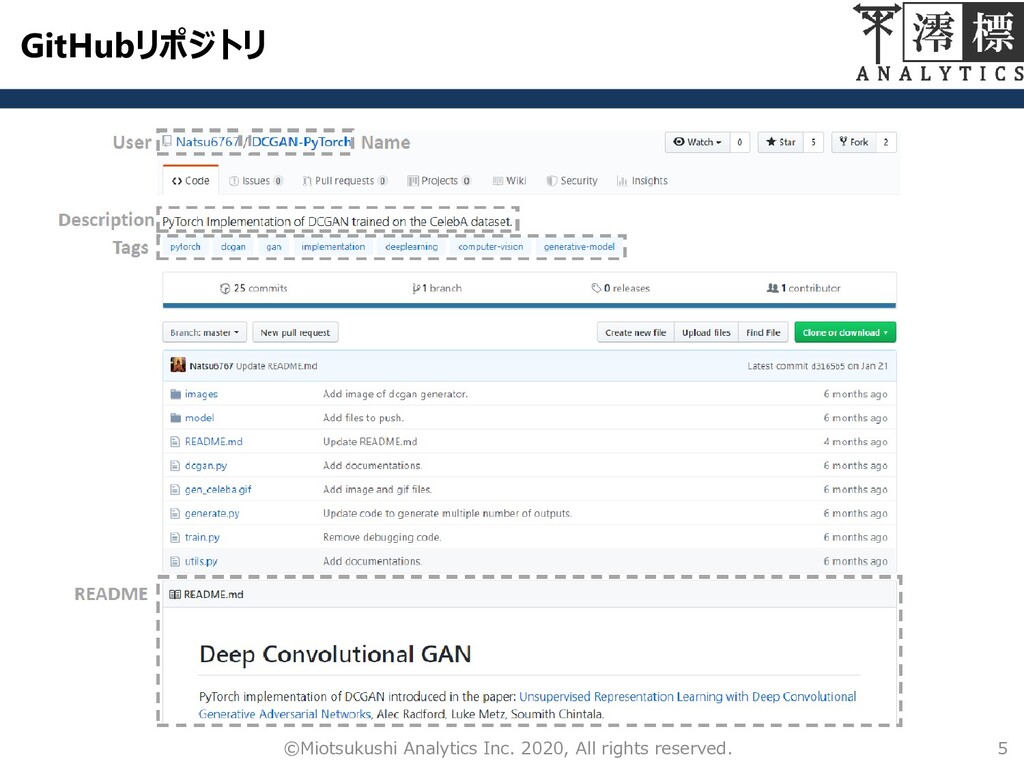
GitHubリポジトリ 5 ©Miotsukushi Analytics Inc. 2020, All rights reserved.
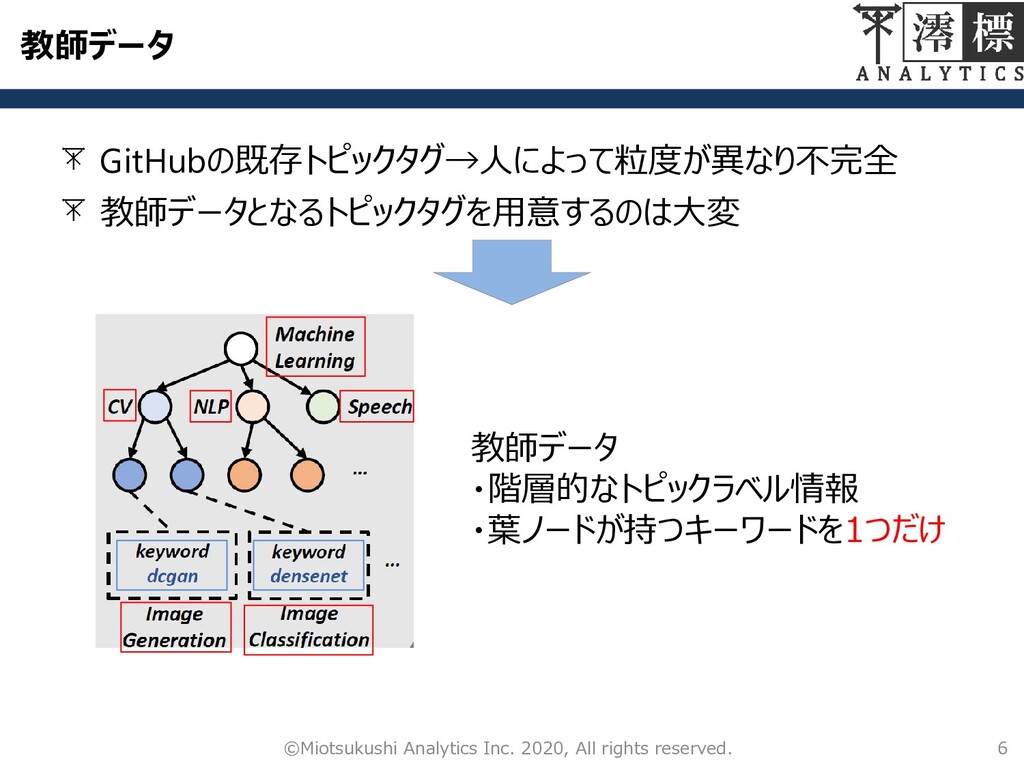
教師データ GitHubの既存トピックタグ→人によって粒度が異なり不完全 6 ©Miotsukushi Analytics Inc. 2020, All rights reserved.
教師データとなるトピックタグを用意するのは大変 教師データ ・階層的なトピックラベル情報 ・葉ノードが持つキーワードを1つだけ
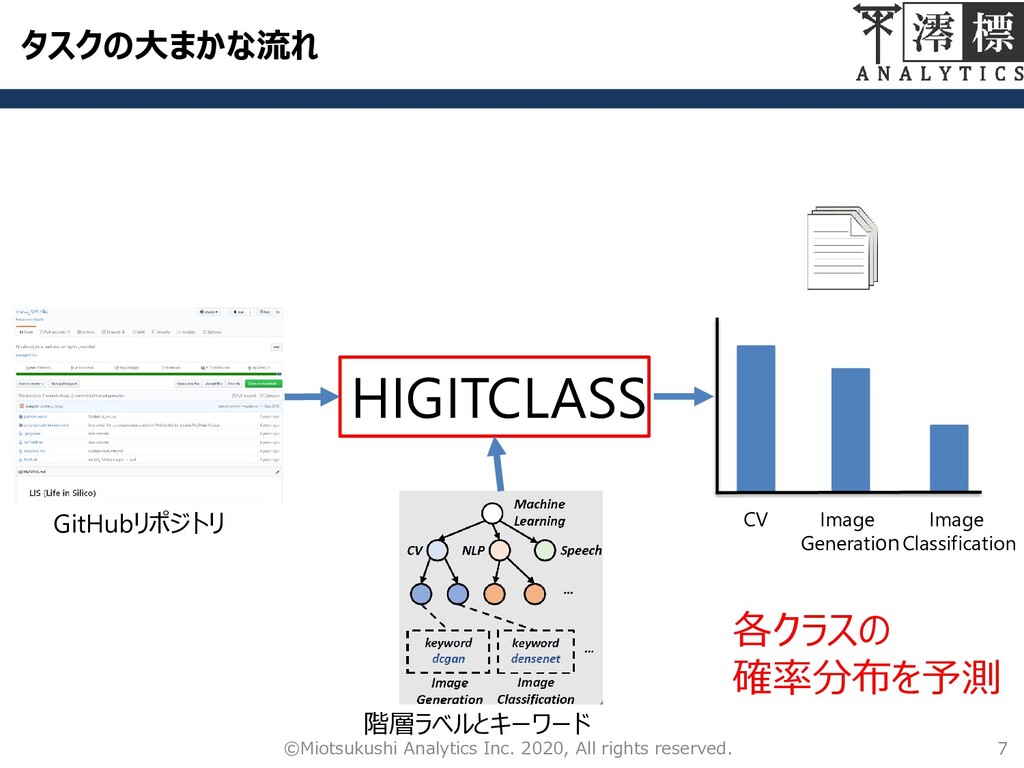
タスクの大まかな流れ 7 ©Miotsukushi Analytics Inc. 2020, All rights reserved. HIGITCLASS
GitHubリポジトリ 階層ラベルとキーワード 各クラスの 確率分布を予測 Image Generation Image Classification CV
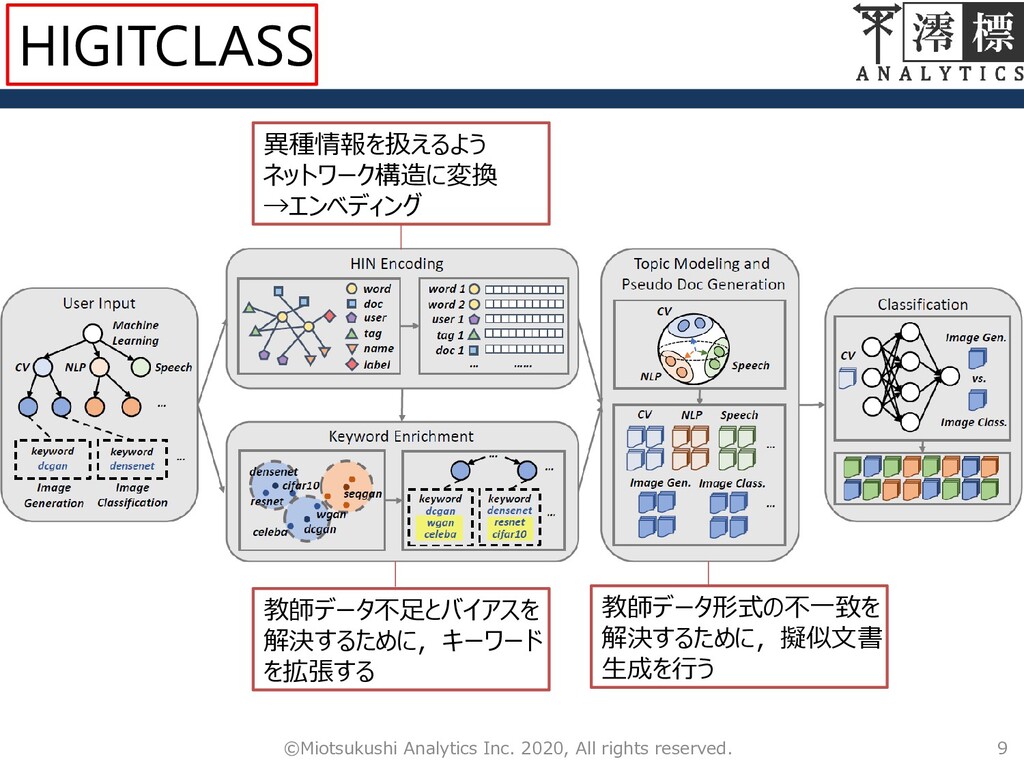
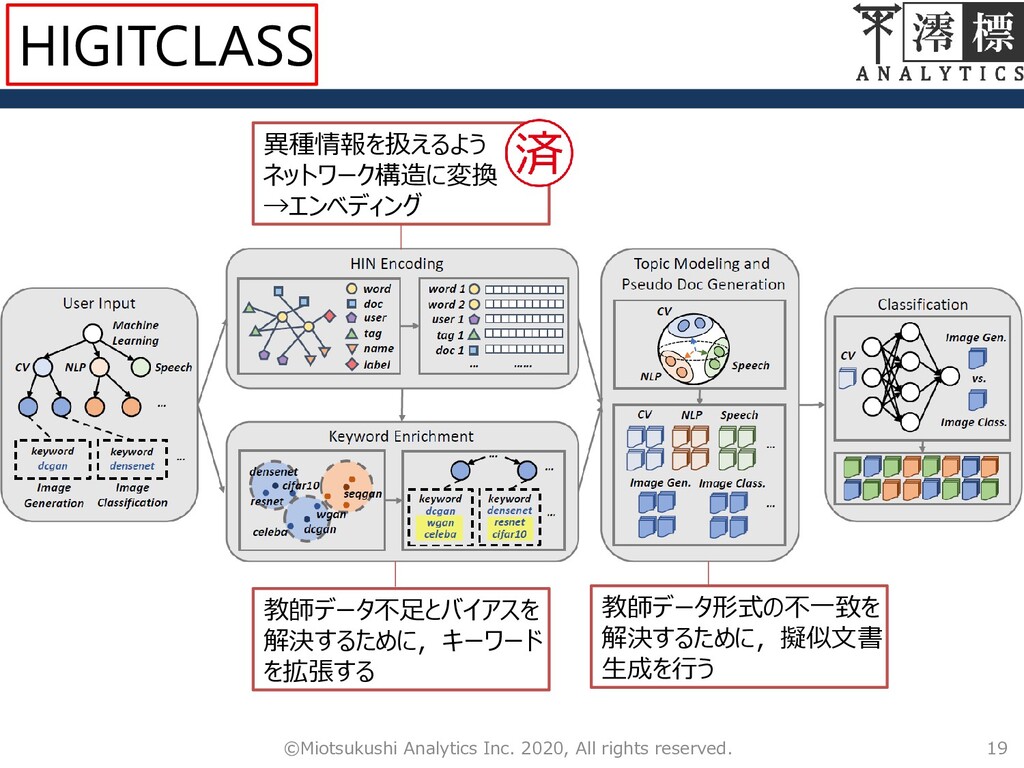
チャレンジング性 リポジトリデータがマルチモーダル信号である – 異なる性質を持つデータを入力値として扱いたい! (User,Name,Description,Tag,README…) 教師データ不足とバイアス – 葉ノードのキーワードは1つのみ 教師データのフォーマットが合わない 8
©Miotsukushi Analytics Inc. 2020, All rights reserved. CV Image-Generation
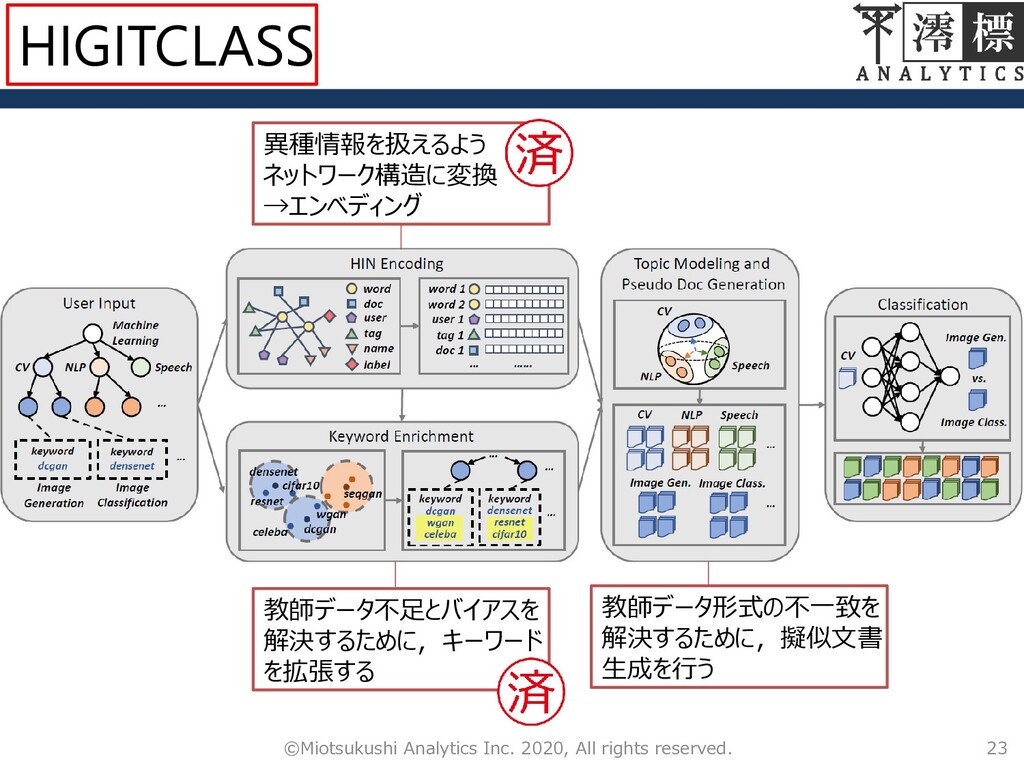
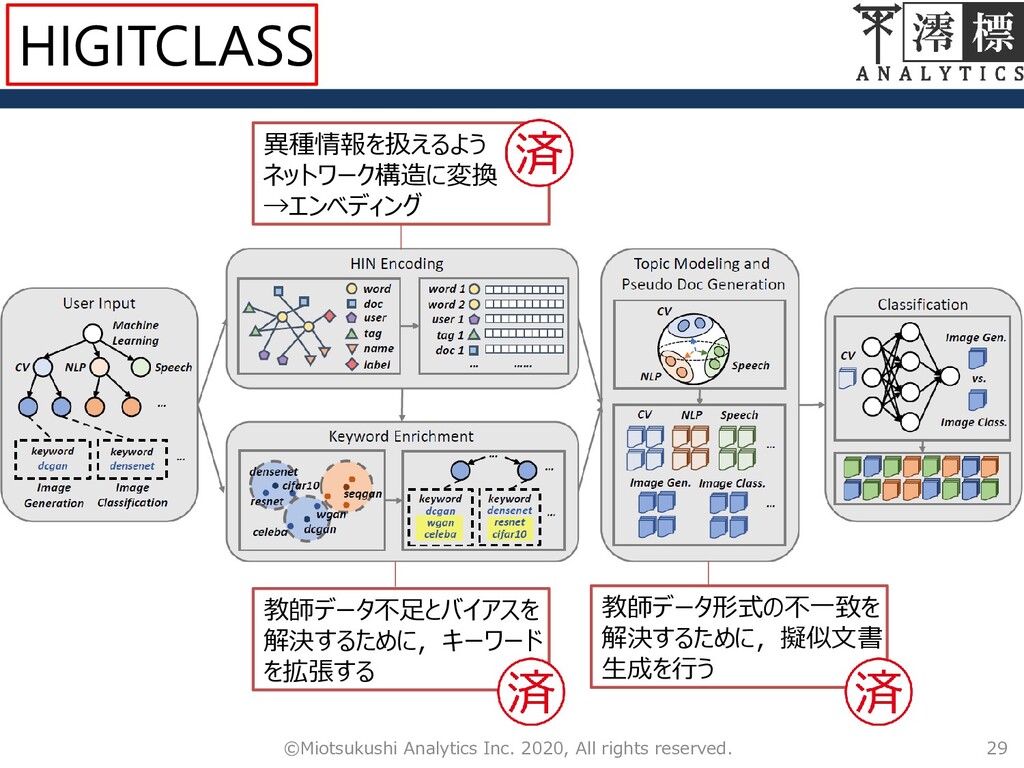
9 ©Miotsukushi Analytics Inc. 2020, All rights reserved. 異種情報を扱えるよう ネットワーク構造に変換
→エンベディング 教師データ不足とバイアスを 解決するために,キーワード を拡張する 教師データ形式の不一致を 解決するために,擬似文書 生成を行う HIGITCLASS
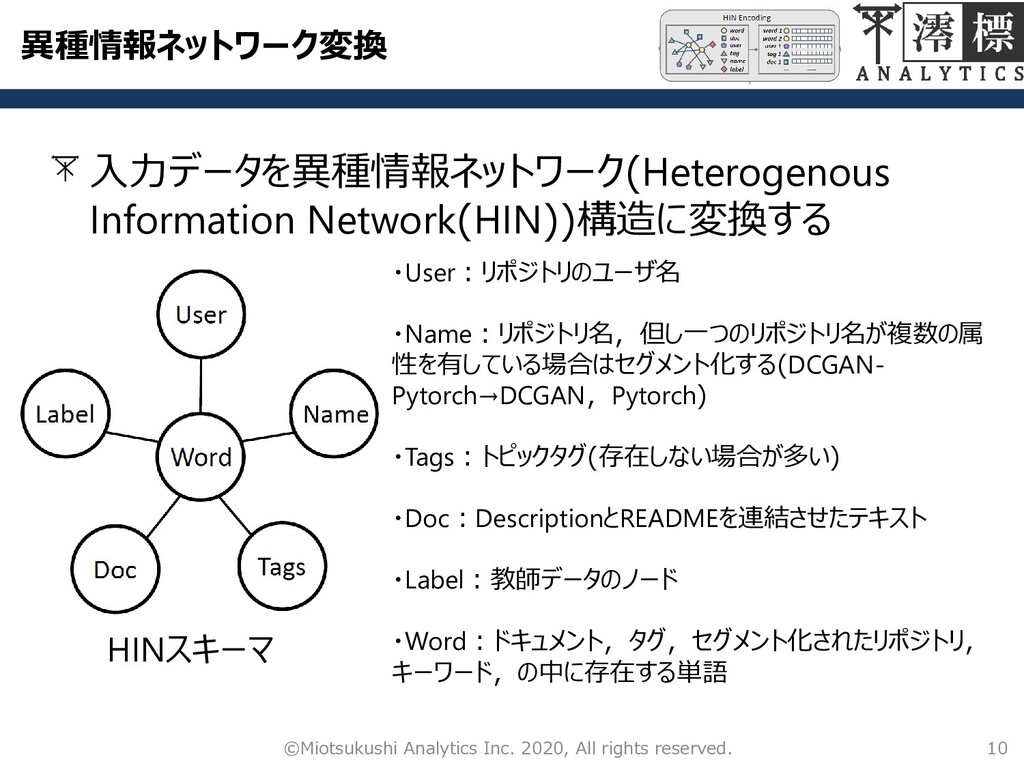
異種情報ネットワーク変換 入力データを異種情報ネットワーク(Heterogenous Information Network(HIN))構造に変換する 10 ©Miotsukushi Analytics Inc. 2020, All
rights reserved. HINスキーマ ・User:リポジトリのユーザ名 ・Name:リポジトリ名,但し一つのリポジトリ名が複数の属 性を有している場合はセグメント化する(DCGAN- Pytorch→DCGAN,Pytorch) ・Tags:トピックタグ(存在しない場合が多い) ・Doc:DescriptionとREADMEを連結させたテキスト ・Label:教師データのノード ・Word:ドキュメント,タグ,セグメント化されたリポジトリ, キーワード,の中に存在する単語
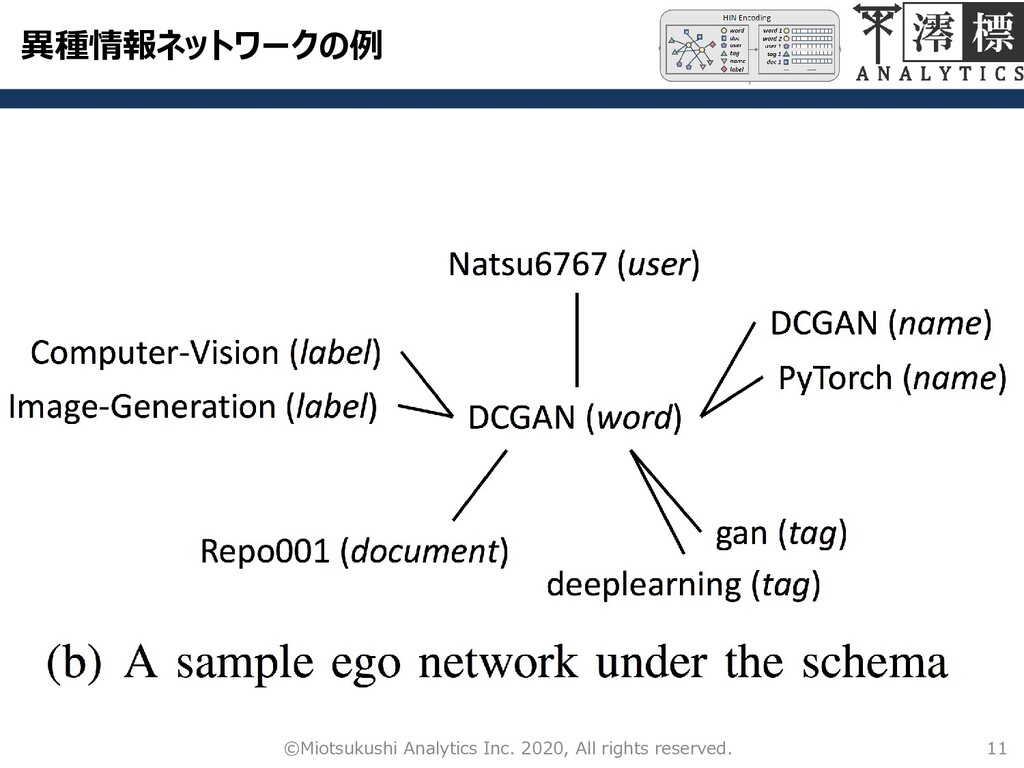
異種情報ネットワークの例 11 ©Miotsukushi Analytics Inc. 2020, All rights reserved.
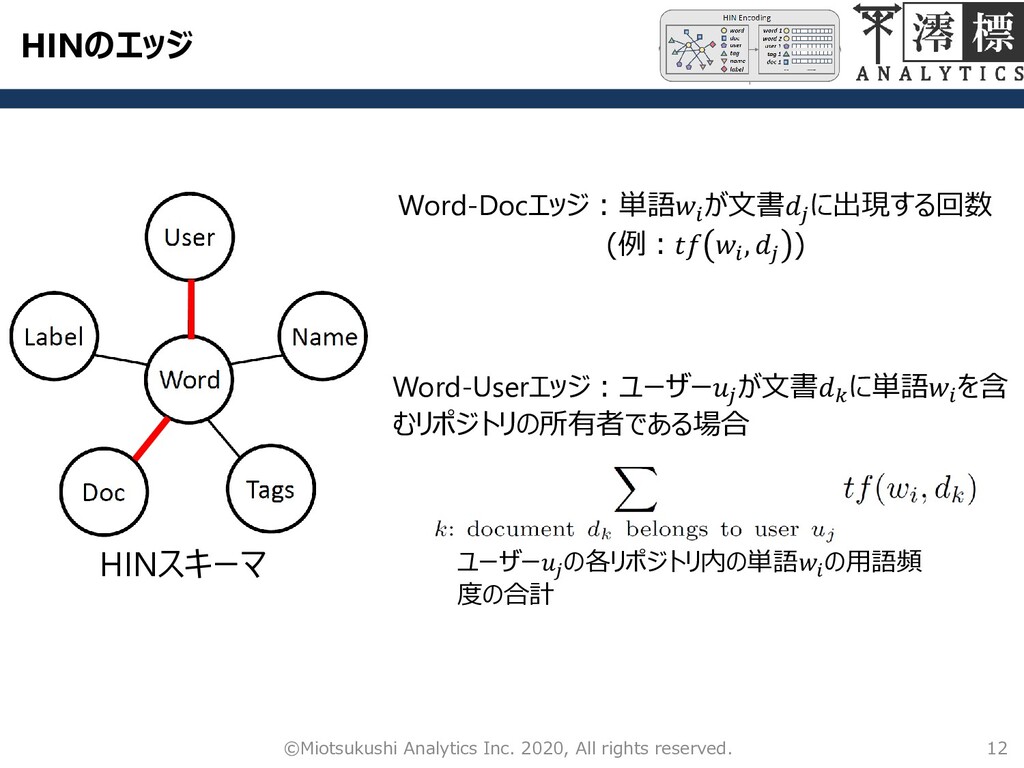
HINのエッジ 12 ©Miotsukushi Analytics Inc. 2020, All rights reserved. HINスキーマ
Word-Docエッジ:単語 が文書 に出現する回数 (例: , ) Word-Userエッジ:ユーザー が文書 に単語 を含 むリポジトリの所有者である場合 ユーザー の各リポジトリ内の単語 の用語頻 度の合計
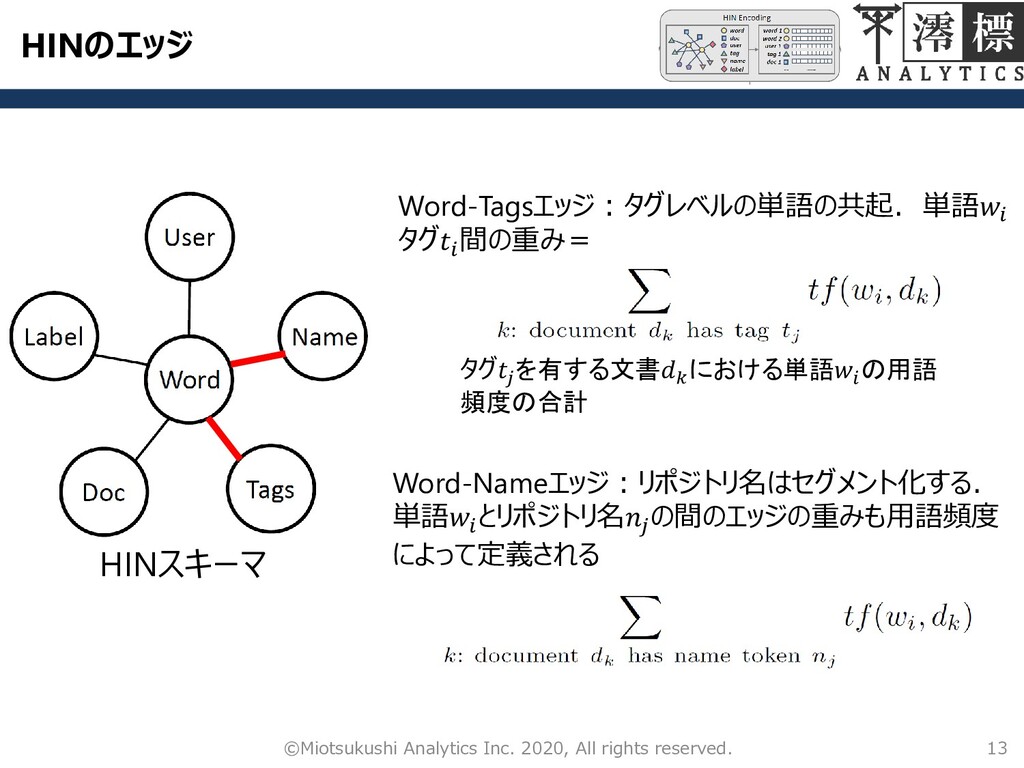
HINのエッジ 13 ©Miotsukushi Analytics Inc. 2020, All rights reserved. HINスキーマ
Word-Tagsエッジ:タグレベルの単語の共起.単語 タグ 間の重み= Word-Nameエッジ:リポジトリ名はセグメント化する. 単語 とリポジトリ名 の間のエッジの重みも用語頻度 によって定義される タグ を有する文書 における単語 の用語 頻度の合計
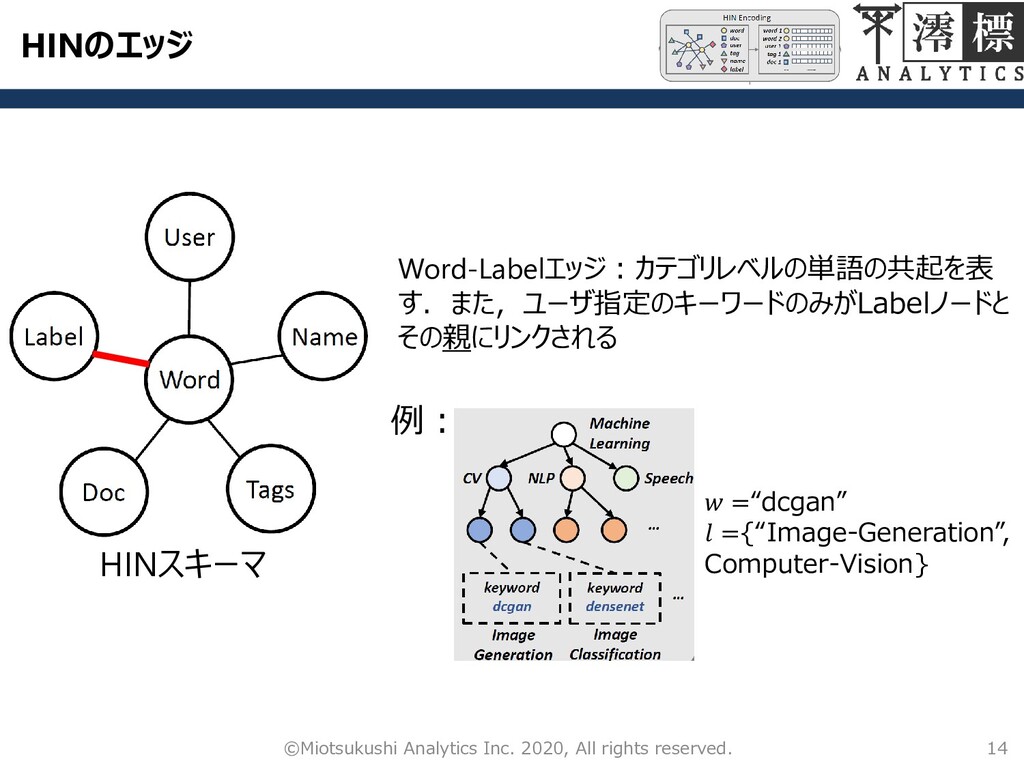
HINのエッジ 14 ©Miotsukushi Analytics Inc. 2020, All rights reserved. HINスキーマ
Word-Labelエッジ:カテゴリレベルの単語の共起を表 す.また,ユーザ指定のキーワードのみがLabelノードと その親にリンクされる 例: =“dcgan” ={“Image-Generation”, Computer-Vision}
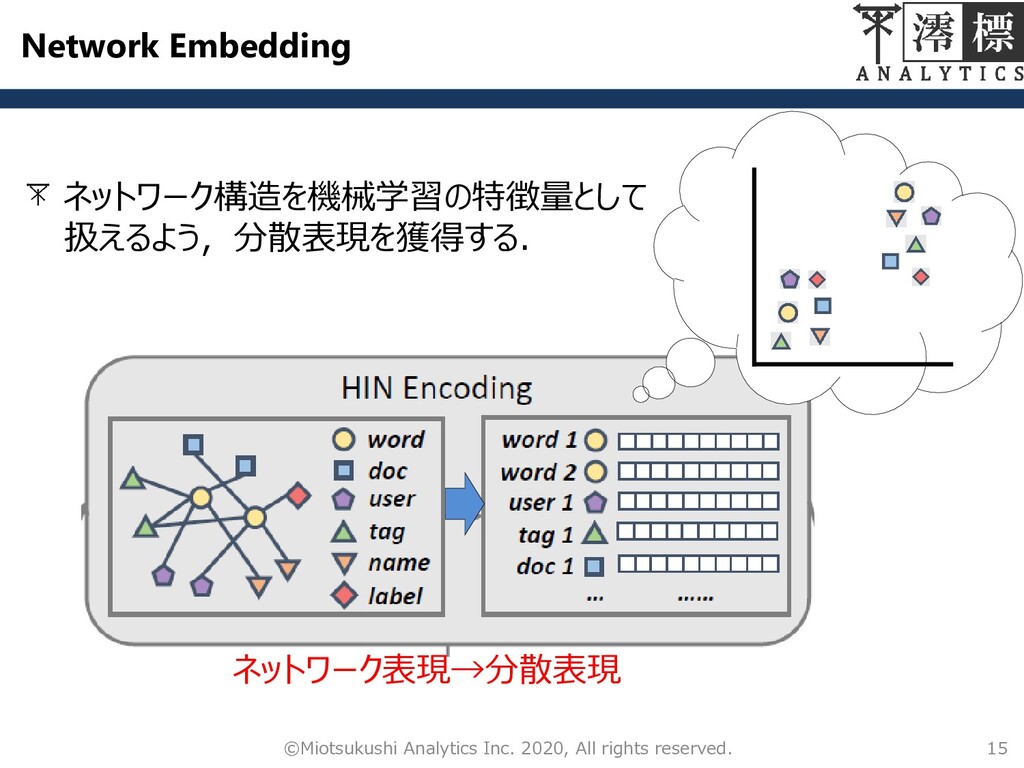
Network Embedding ネットワーク構造を機械学習の特徴量として 扱えるよう,分散表現を獲得する. 15 ©Miotsukushi Analytics Inc. 2020, All
rights reserved. ネットワーク表現→分散表現
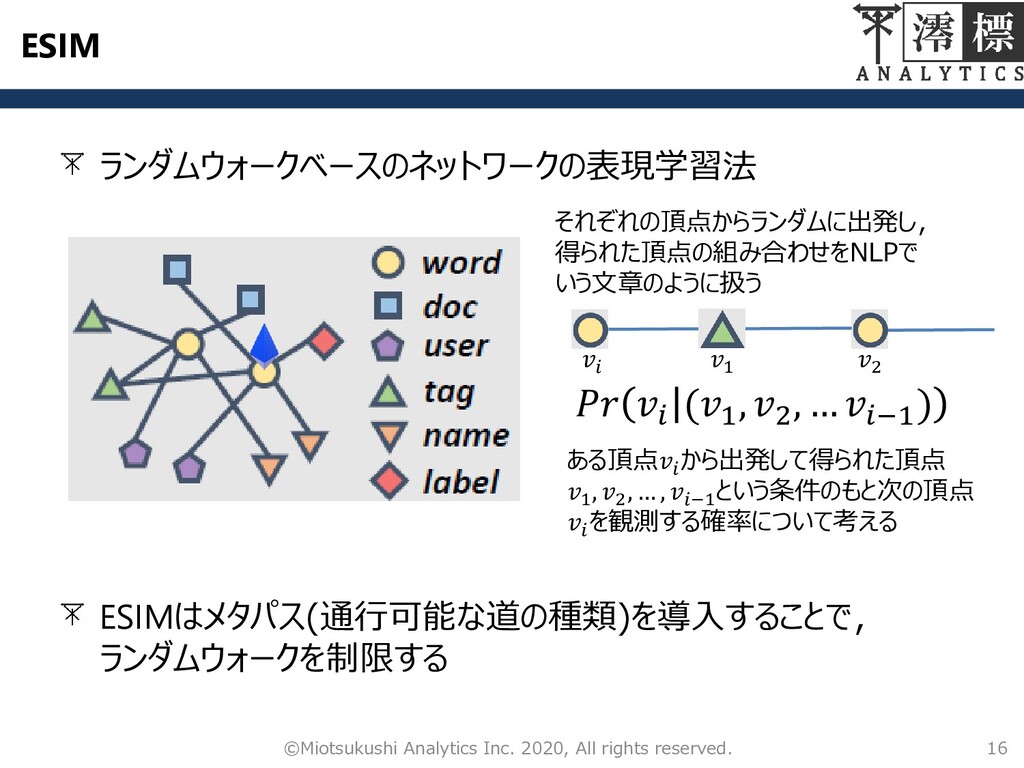
ESIM ランダムウォークベースのネットワークの表現学習法 16 ©Miotsukushi Analytics Inc. 2020, All rights reserved.
それぞれの頂点からランダムに出発し, 得られた頂点の組み合わせをNLPで いう文章のように扱う 1 2 (1 , 2 , … −1 ) ある頂点 から出発して得られた頂点 1 , 2 , … , −1 という条件のもと次の頂点 を観測する確率について考える ESIMはメタパス(通行可能な道の種類)を導入することで, ランダムウォークを制限する
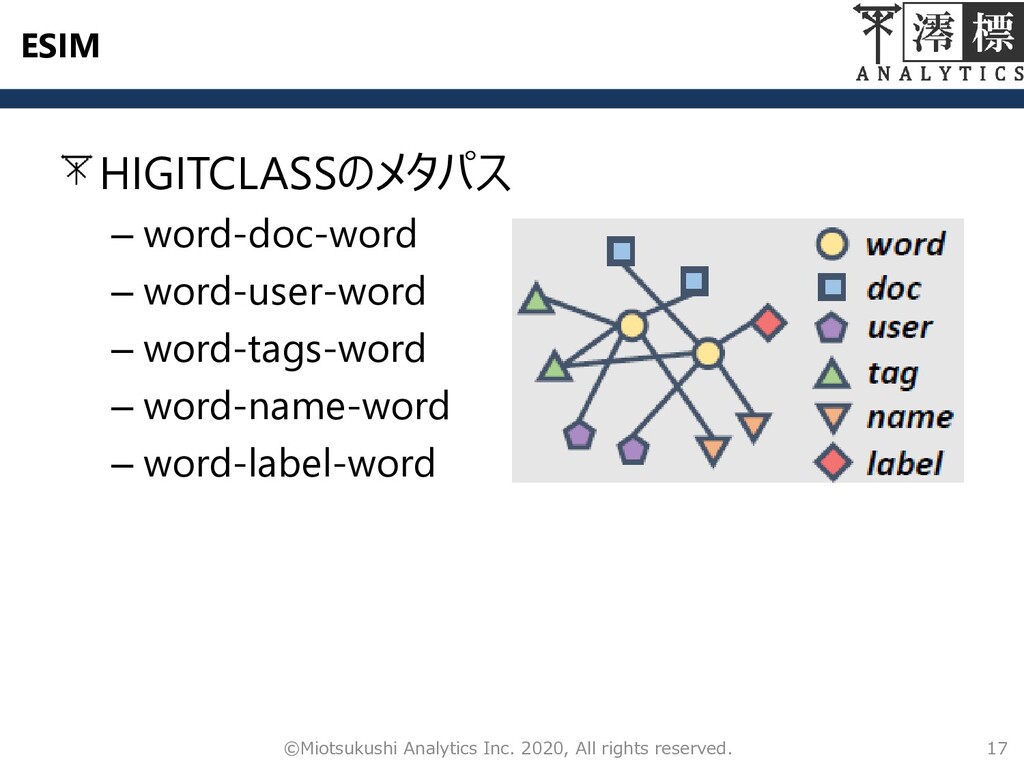
ESIM HIGITCLASSのメタパス – word-doc-word – word-user-word – word-tags-word – word-name-word
– word-label-word 17 ©Miotsukushi Analytics Inc. 2020, All rights reserved.
ESIMによる分散表現の獲得 18 ©Miotsukushi Analytics Inc. 2020, All rights reserved. 先ほど定義したメタパスℳとその対応するノードシーケンス
= 1 − 2 − ⋯ − が与えられた場合 1次マルコフ連鎖の確率 バイアス 埋込ベクトル(分散表現) ℳ , ℳ , ℳ , , について尤度を最大化することで学習,分散表現を獲得する Skip-Gram Modelに類似
19 ©Miotsukushi Analytics Inc. 2020, All rights reserved. 異種情報を扱えるよう ネットワーク構造に変換
→エンベディング 教師データ不足とバイアスを 解決するために,キーワード を拡張する 教師データ形式の不一致を 解決するために,擬似文書 生成を行う HIGITCLASS
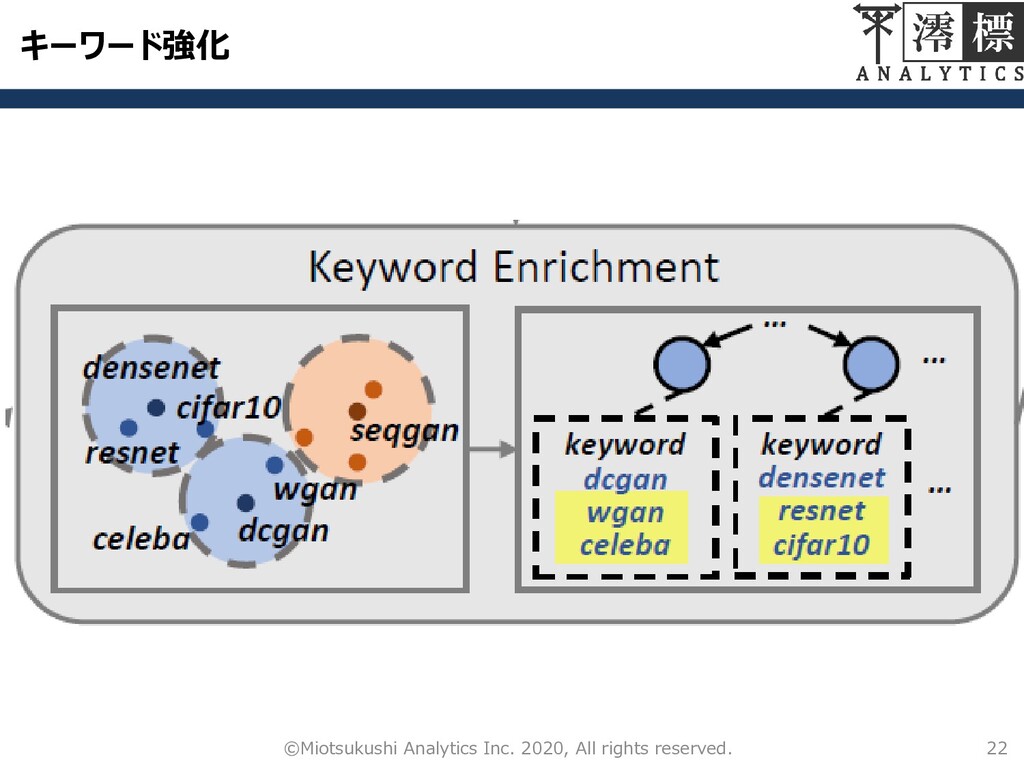
キーワード強化 ユーザーはキーワードを1つしか与えない このキーワードセットを増やしたい 20 ©Miotsukushi Analytics Inc. 2020, All rights
reserved. 前ステップにおいて,単語の埋め込みベクトル を獲得 – これを用いて以下の手順で,キーワードセットの強化を行っていく
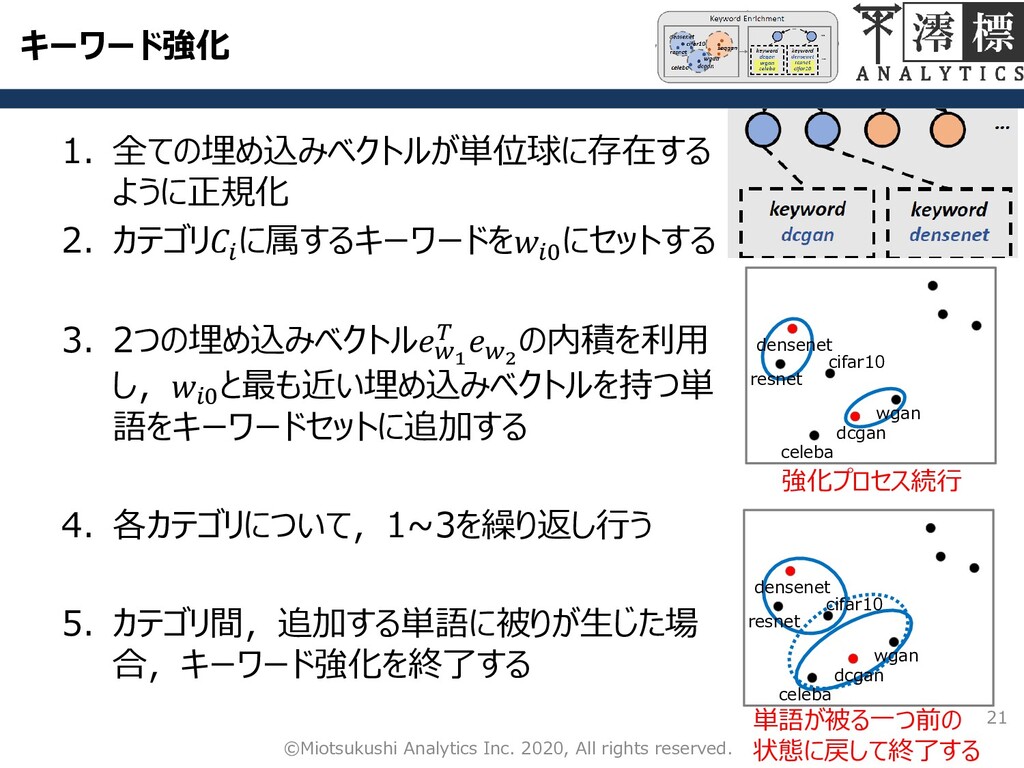
キーワード強化 21 ©Miotsukushi Analytics Inc. 2020, All rights reserved. 1.
全ての埋め込みベクトルが単位球に存在する ように正規化 2. カテゴリ に属するキーワードを0 にセットする 3. 2つの埋め込みベクトル1 2 の内積を利用 し,0 と最も近い埋め込みベクトルを持つ単 語をキーワードセットに追加する 4. 各カテゴリについて,1~3を繰り返し行う 5. カテゴリ間,追加する単語に被りが生じた場 合,キーワード強化を終了する densenet resnet cifar10 dcgan celeba wgan 強化プロセス続行 densenet resnet dcgan celeba wgan cifar10 単語が被る一つ前の 状態に戻して終了する
キーワード強化 22 ©Miotsukushi Analytics Inc. 2020, All rights reserved.
23 ©Miotsukushi Analytics Inc. 2020, All rights reserved. 異種情報を扱えるよう ネットワーク構造に変換
→エンベディング 教師データ不足とバイアスを 解決するために,キーワード を拡張する 教師データ形式の不一致を 解決するために,擬似文書 生成を行う HIGITCLASS
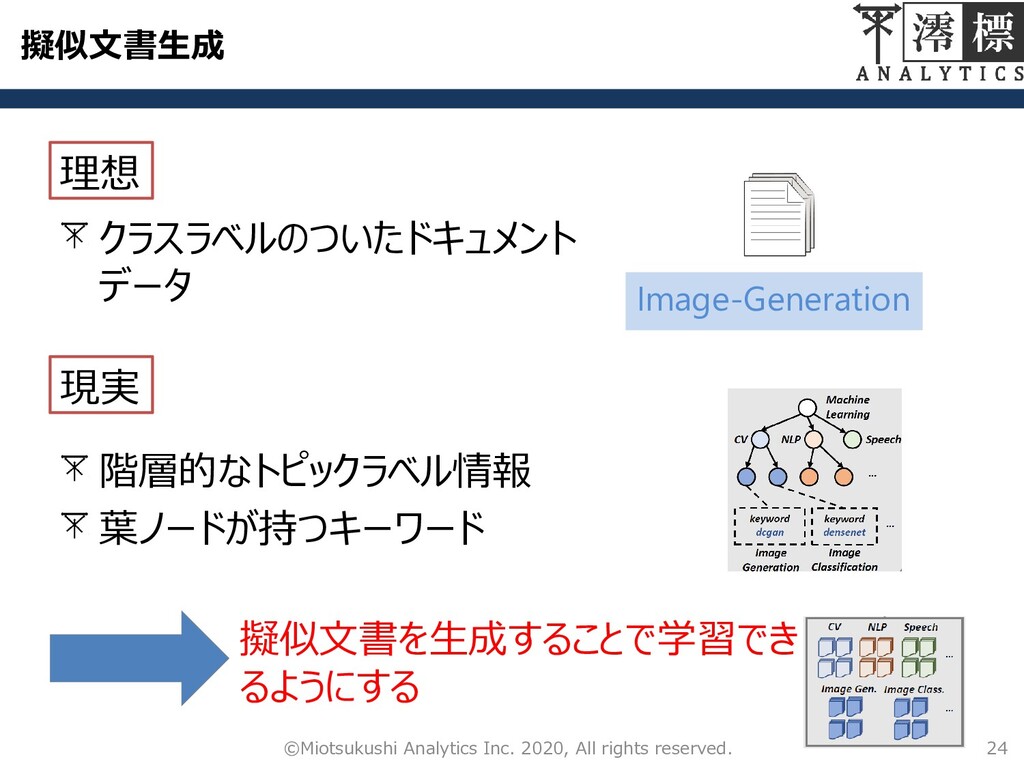
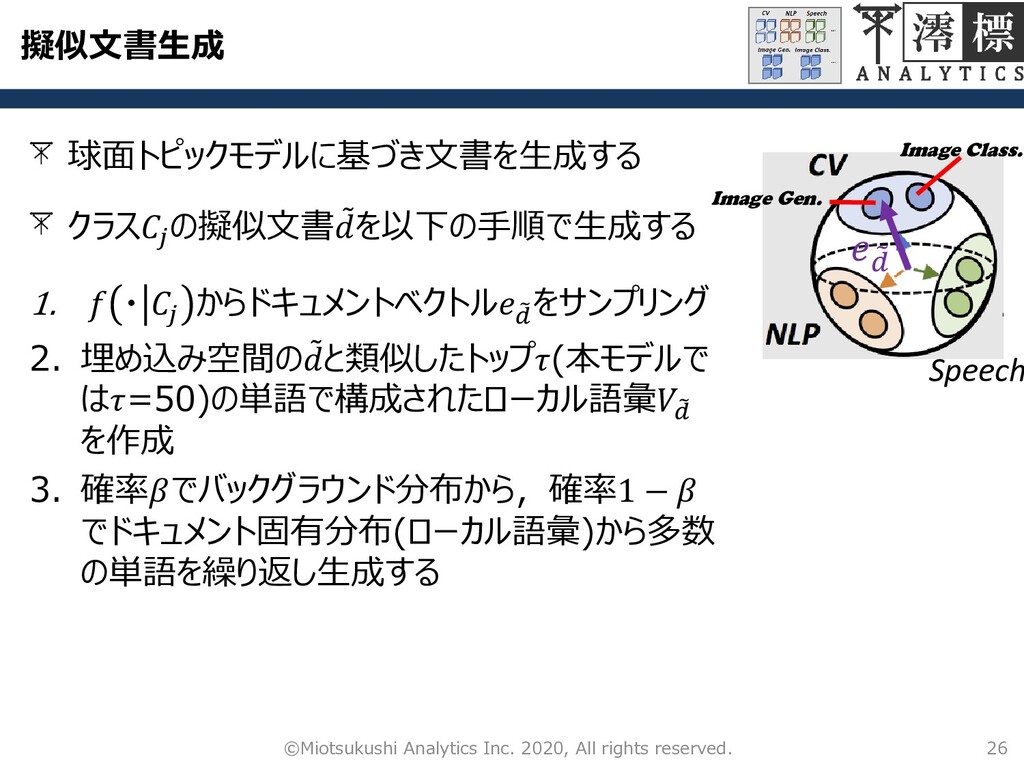
擬似文書生成 クラスラベルのついたドキュメント データ 24 ©Miotsukushi Analytics Inc. 2020, All rights
reserved. 理想 現実 Image-Generation 擬似文書を生成することで学習でき るようにする 階層的なトピックラベル情報 葉ノードが持つキーワード
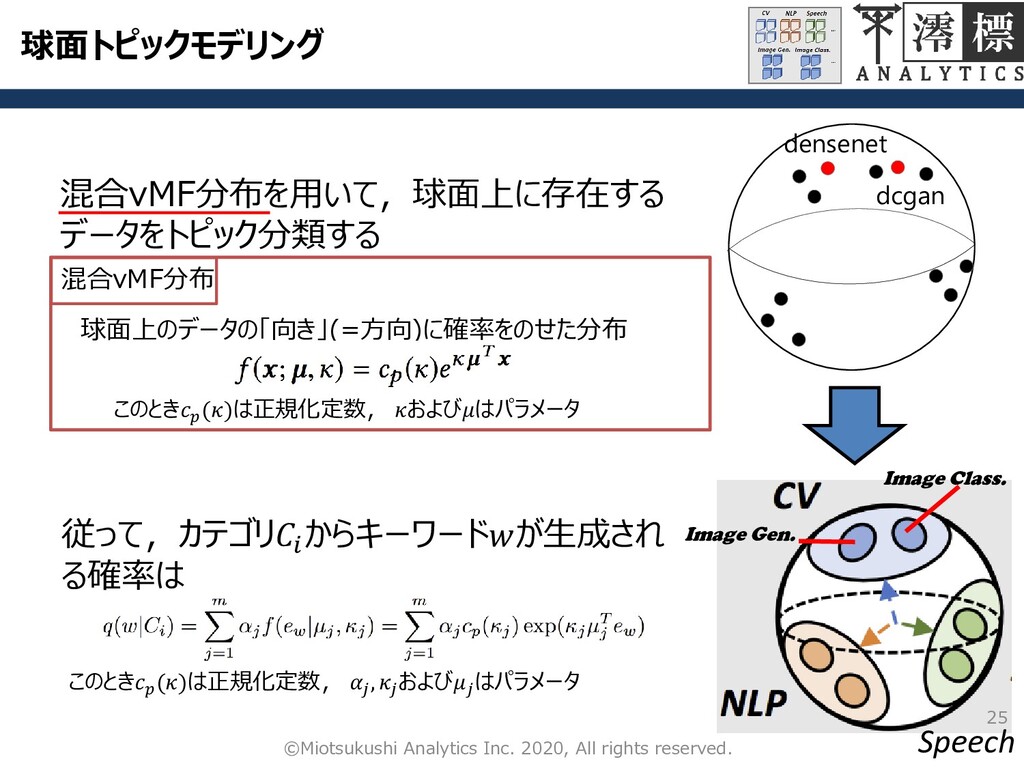
Speech Image Gen. Image Class. 球面トピックモデリング 25 ©Miotsukushi Analytics Inc.
2020, All rights reserved. densenet dcgan 混合vMF分布を用いて,球面上に存在する データをトピック分類する 球面上のデータの「向き」(=方向)に確率をのせた分布 混合vMF分布 このとき ()は正規化定数, およびはパラメータ 従って,カテゴリ からキーワードが生成され る確率は このとき ()は正規化定数, , および はパラメータ
擬似文書生成 26 ©Miotsukushi Analytics Inc. 2020, All rights reserved. Speech
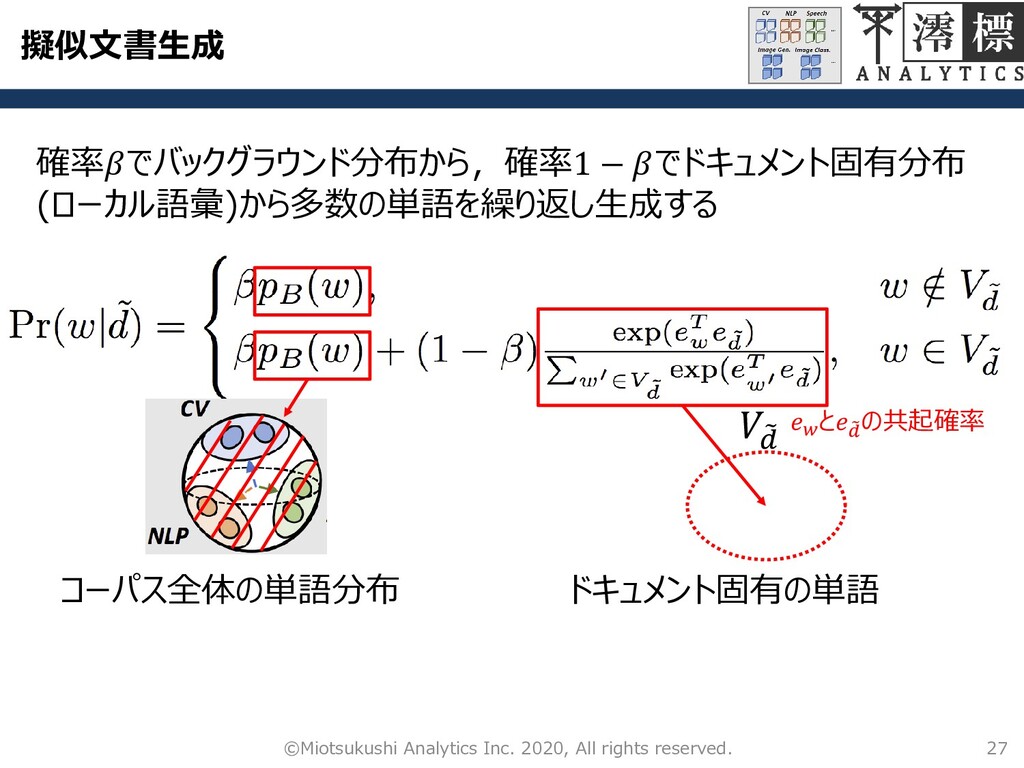
Image Gen. Image Class. 球面トピックモデルに基づき文書を生成する 1. ・ からドキュメントベクトル ෨ をサンプリング 2. 埋め込み空間の ሚ と類似したトップ(本モデルで は=50)の単語で構成されたローカル語彙෨ を作成 3. 確率でバックグラウンド分布から,確率1 − でドキュメント固有分布(ローカル語彙)から多数 の単語を繰り返し生成する クラス の擬似文書 ሚ を以下の手順で生成する ෨
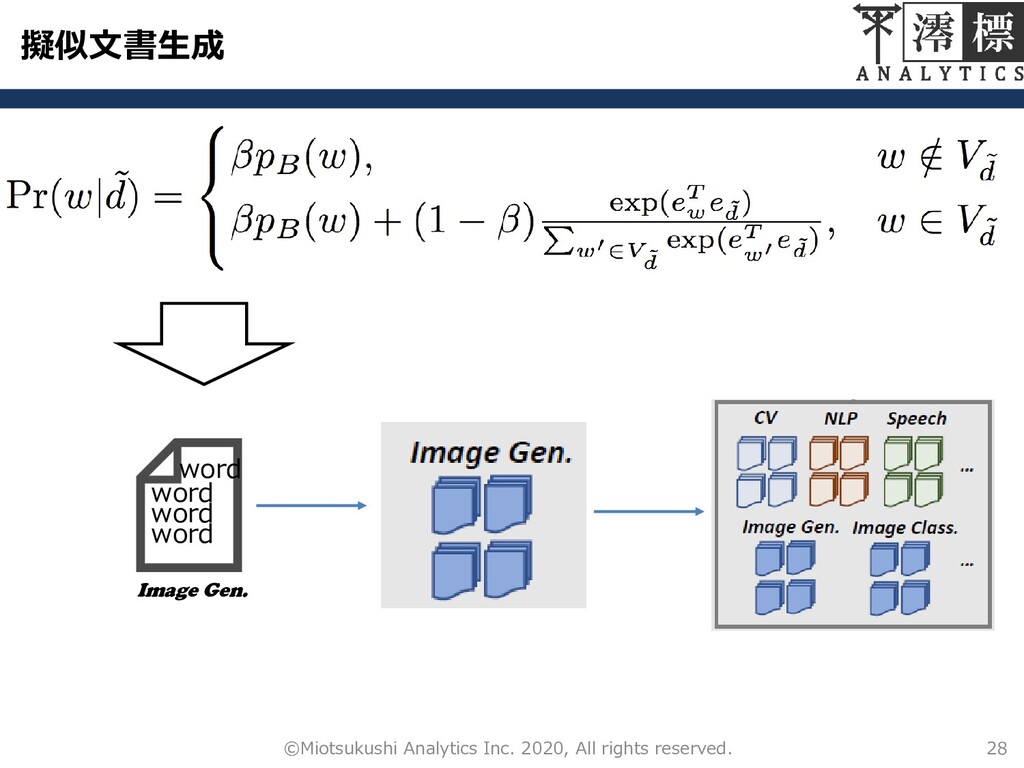
擬似文書生成 27 ©Miotsukushi Analytics Inc. 2020, All rights reserved. 確率でバックグラウンド分布から,確率1
− でドキュメント固有分布 (ローカル語彙)から多数の単語を繰り返し生成する ෨ コーパス全体の単語分布 ドキュメント固有の単語 と ෨ の共起確率
擬似文書生成 28 ©Miotsukushi Analytics Inc. 2020, All rights reserved. word
word word word Image Gen.
29 ©Miotsukushi Analytics Inc. 2020, All rights reserved. 異種情報を扱えるよう ネットワーク構造に変換
→エンベディング 教師データ不足とバイアスを 解決するために,キーワード を拡張する 教師データ形式の不一致を 解決するために,擬似文書 生成を行う HIGITCLASS
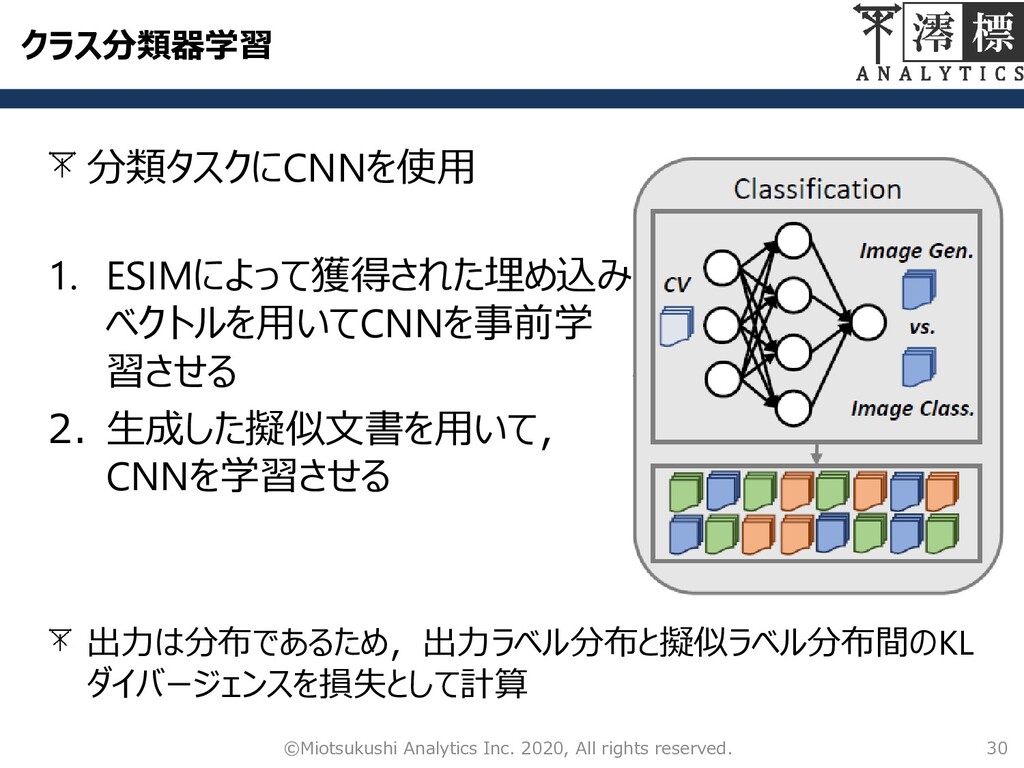
クラス分類器学習 30 ©Miotsukushi Analytics Inc. 2020, All rights reserved. 分類タスクにCNNを使用
1. ESIMによって獲得された埋め込み ベクトルを用いてCNNを事前学 習させる 2. 生成した擬似文書を用いて, CNNを学習させる 出力は分布であるため,出力ラベル分布と擬似ラベル分布間のKL ダイバージェンスを損失として計算
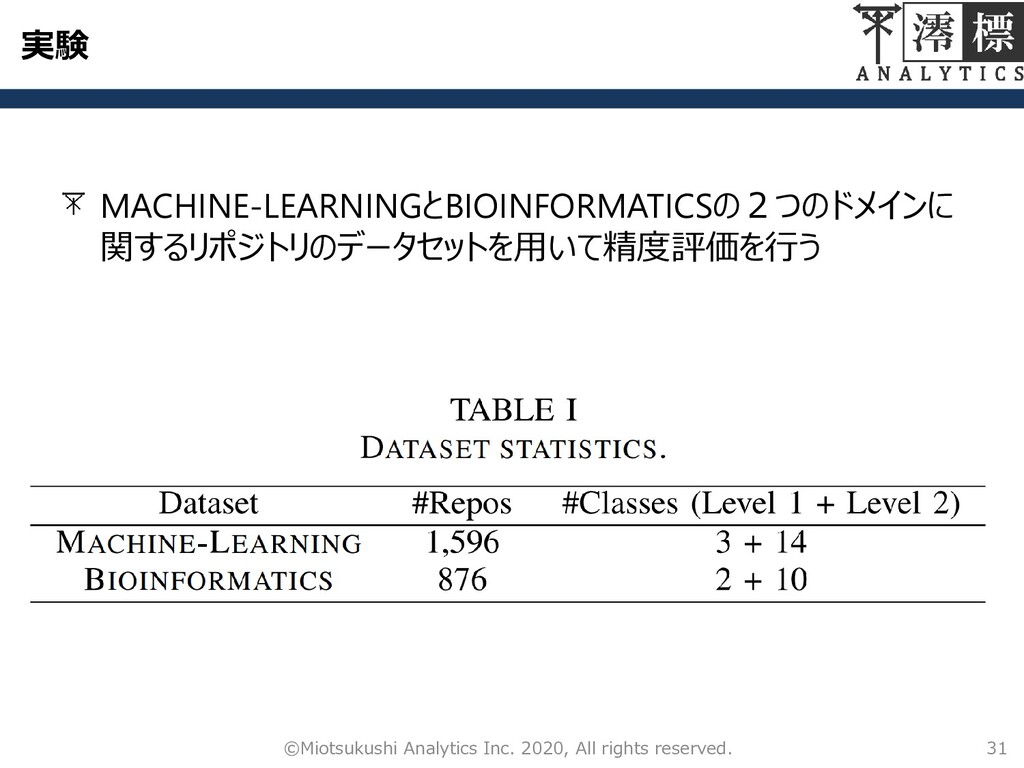
実験 MACHINE-LEARNINGとBIOINFORMATICSの2つのドメインに 関するリポジトリのデータセットを用いて精度評価を行う 31 ©Miotsukushi Analytics Inc. 2020, All rights
reserved.
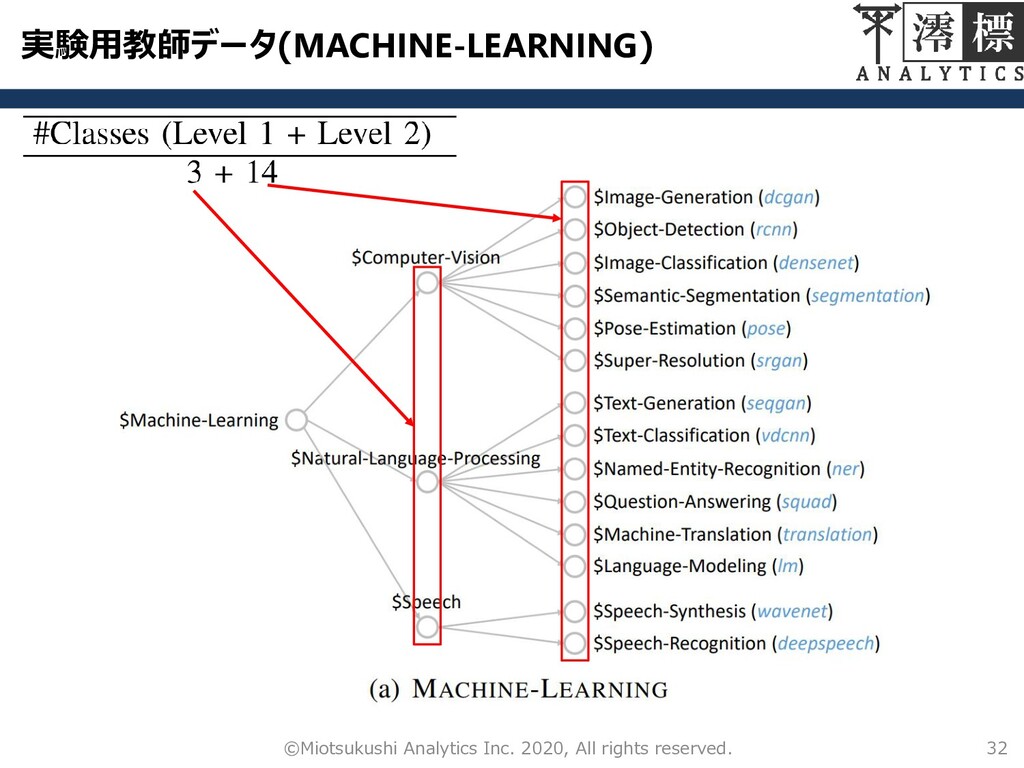
実験用教師データ(MACHINE-LEARNING) 32 ©Miotsukushi Analytics Inc. 2020, All rights reserved.
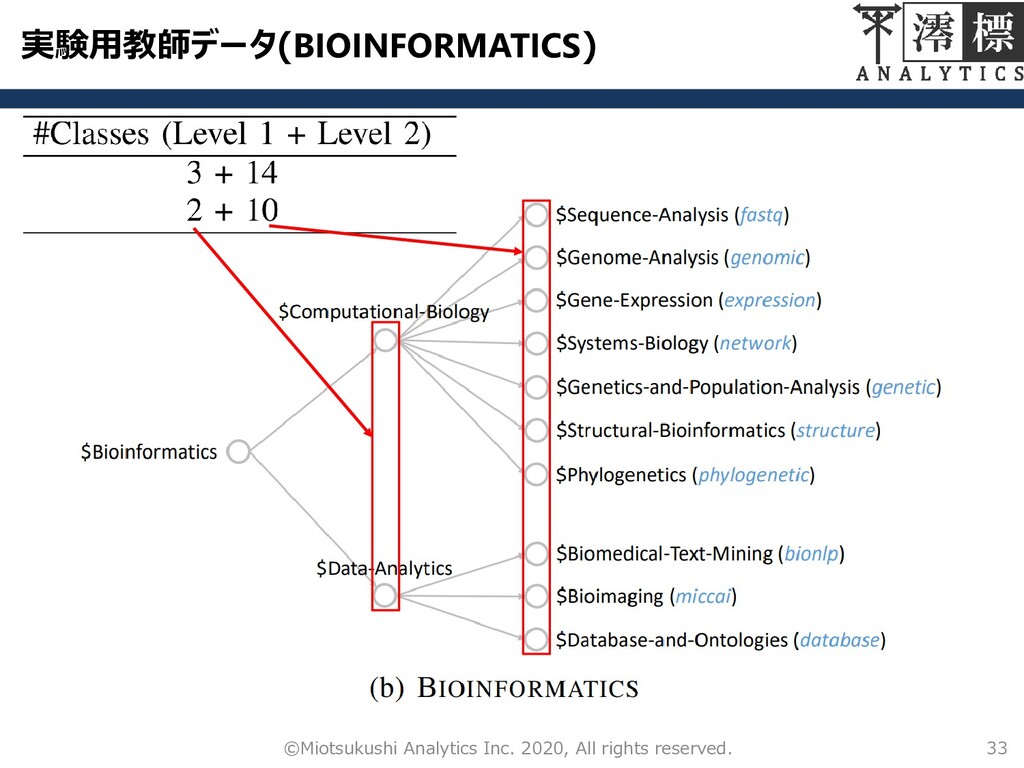
実験用教師データ(BIOINFORMATICS) 33 ©Miotsukushi Analytics Inc. 2020, All rights reserved.
評価指標 レベル別でF1スコアを使用する 34 ©Miotsukushi Analytics Inc. 2020, All rights reserved.
カテゴリを ,1 (2 )を全てのLevel1(Level2)カテゴリのセットと定義する Micro-F1= Macro-F1= LEVEL-2のMicro-F1/Macro-F1の式は1 のところを2 に変更 全体のMicro-F1/Macro-F1の式は1 のところを1 ∪ 2 に変更 (LEVEL-1カテゴリセットの場合)
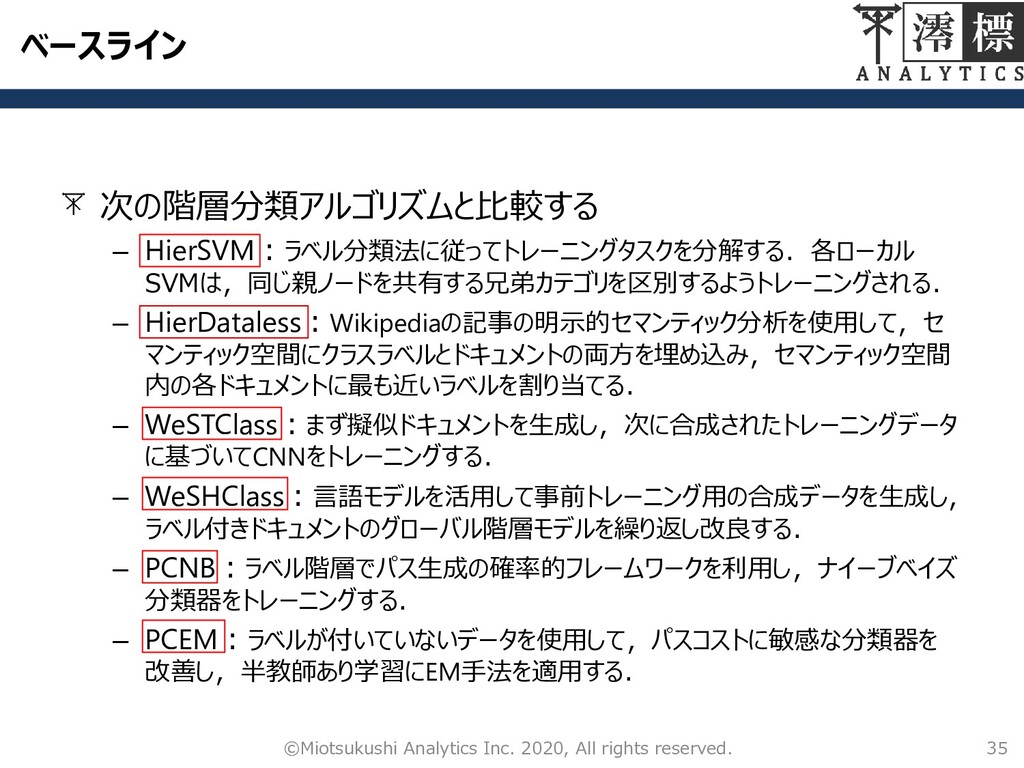
ベースライン 次の階層分類アルゴリズムと比較する – HierSVM:ラベル分類法に従ってトレーニングタスクを分解する.各ローカル SVMは,同じ親ノードを共有する兄弟カテゴリを区別するようトレーニングされる. – HierDataless:Wikipediaの記事の明示的セマンティック分析を使用して,セ マンティック空間にクラスラベルとドキュメントの両方を埋め込み,セマンティック空間 内の各ドキュメントに最も近いラベルを割り当てる. –
WeSTClass:まず擬似ドキュメントを生成し,次に合成されたトレーニングデータ に基づいてCNNをトレーニングする. – WeSHClass:言語モデルを活用して事前トレーニング用の合成データを生成し, ラベル付きドキュメントのグローバル階層モデルを繰り返し改良する. – PCNB:ラベル階層でパス生成の確率的フレームワークを利用し,ナイーブベイズ 分類器をトレーニングする. – PCEM:ラベルが付いていないデータを使用して,パスコストに敏感な分類器を 改善し,半教師あり学習にEM手法を適用する. 35 ©Miotsukushi Analytics Inc. 2020, All rights reserved.
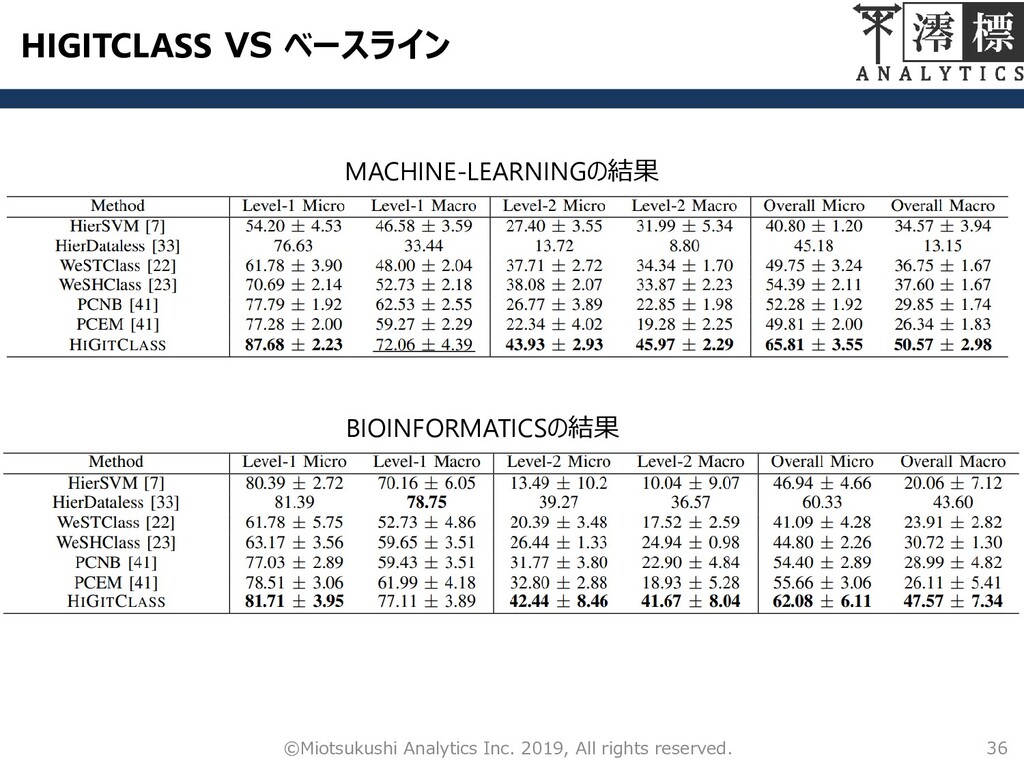
HIGITCLASS VS ベースライン 36 ©Miotsukushi Analytics Inc. 2019, All rights
reserved. MACHINE-LEARNINGの結果 BIOINFORMATICSの結果
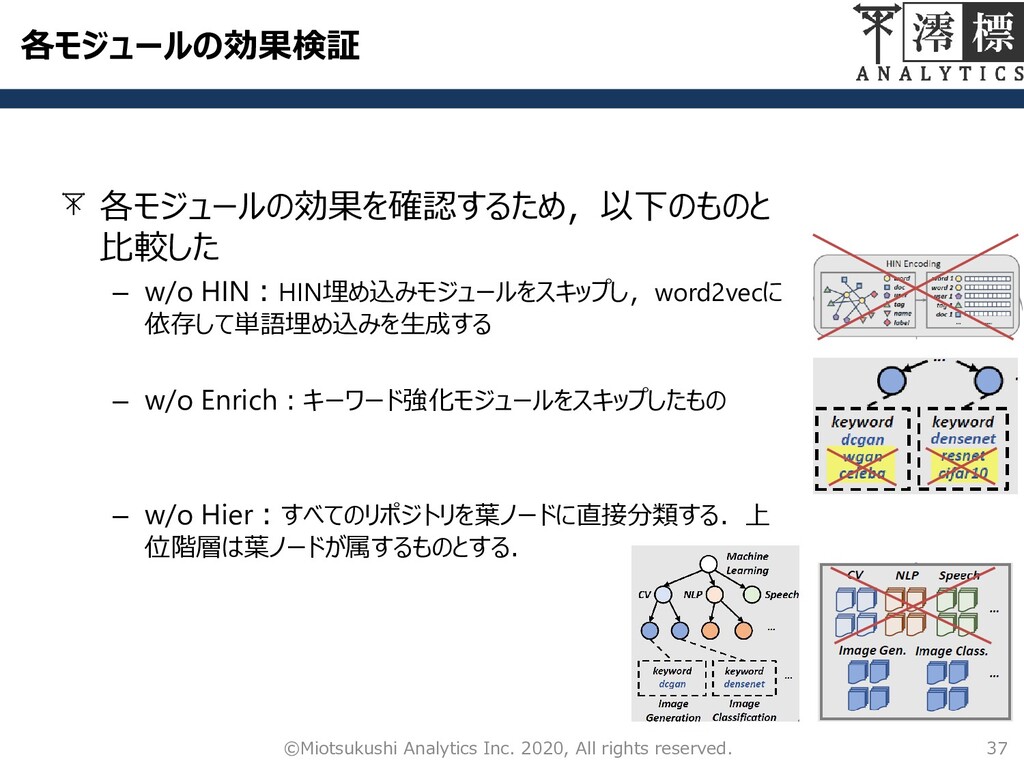
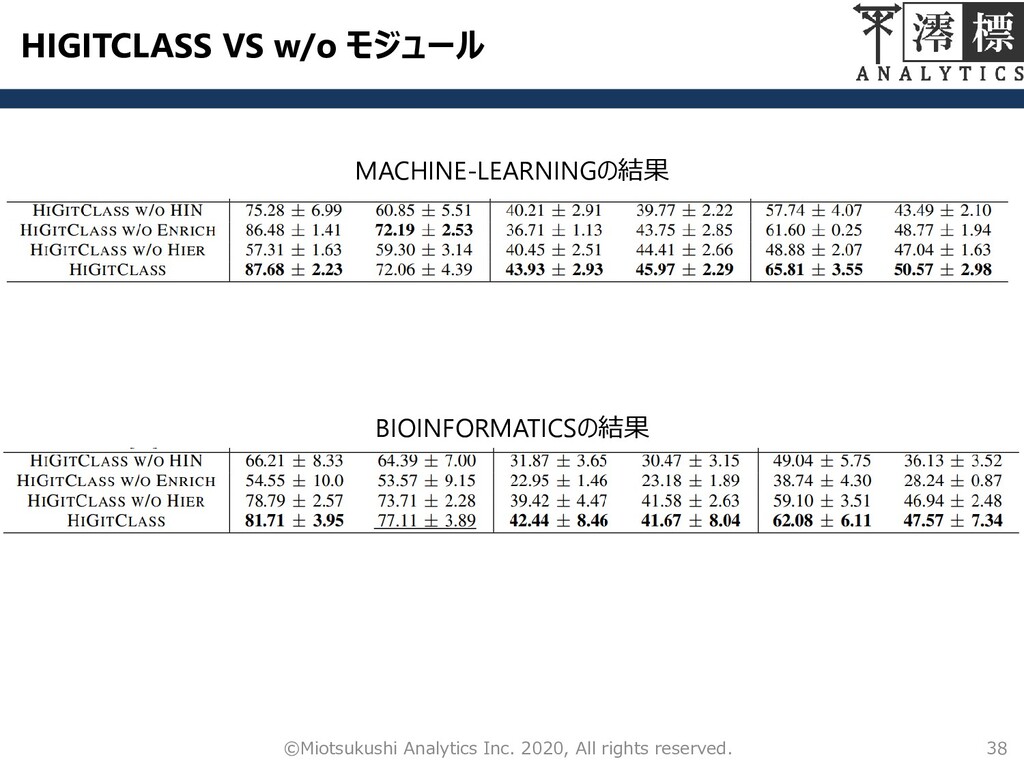
各モジュールの効果検証 各モジュールの効果を確認するため,以下のものと 比較した – w/o HIN:HIN埋め込みモジュールをスキップし,word2vecに 依存して単語埋め込みを生成する – w/o Enrich:キーワード強化モジュールをスキップしたもの
– w/o Hier:すべてのリポジトリを葉ノードに直接分類する.上 位階層は葉ノードが属するものとする. 37 ©Miotsukushi Analytics Inc. 2020, All rights reserved.
HIGITCLASS VS w/o モジュール 38 ©Miotsukushi Analytics Inc. 2020, All
rights reserved. MACHINE-LEARNINGの結果 BIOINFORMATICSの結果
HIN構築と埋め込みの効果 HIN構築と埋め込みの効果の詳細を調査する HIGITCLASSでは以下のメタパスが与えられていた – word-doc-word – word-user-word – word-tags-word –
word-name-word – word-label-word どのメタパスが効果的かを調査するため,各メタパス一つだけを 除いたバージョンで比較を行う. 39 ©Miotsukushi Analytics Inc. 2020, All rights reserved. HIN埋め込み手法として他の埋め込み手法と比較することESIM の妥当性を調査する – metapath2vec – HIN2vec
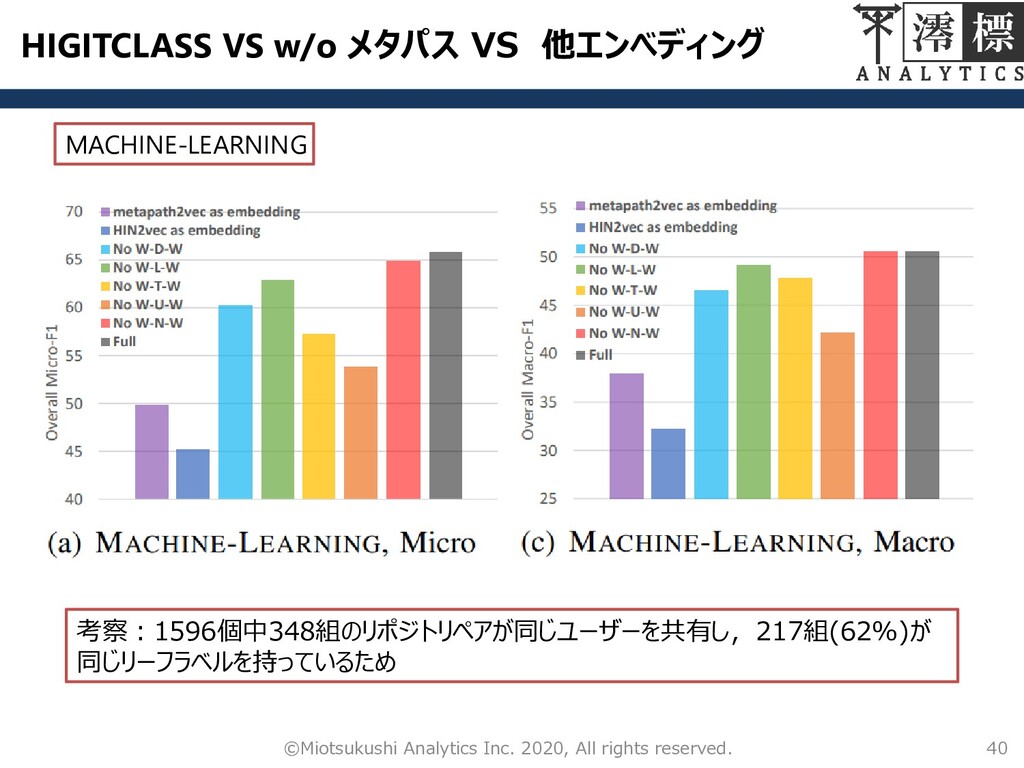
HIGITCLASS VS w/o メタパス VS 他エンべディング 40 ©Miotsukushi Analytics Inc.
2020, All rights reserved. MACHINE-LEARNING 考察:1596個中348組のリポジトリペアが同じユーザーを共有し,217組(62%)が 同じリーフラベルを持っているため
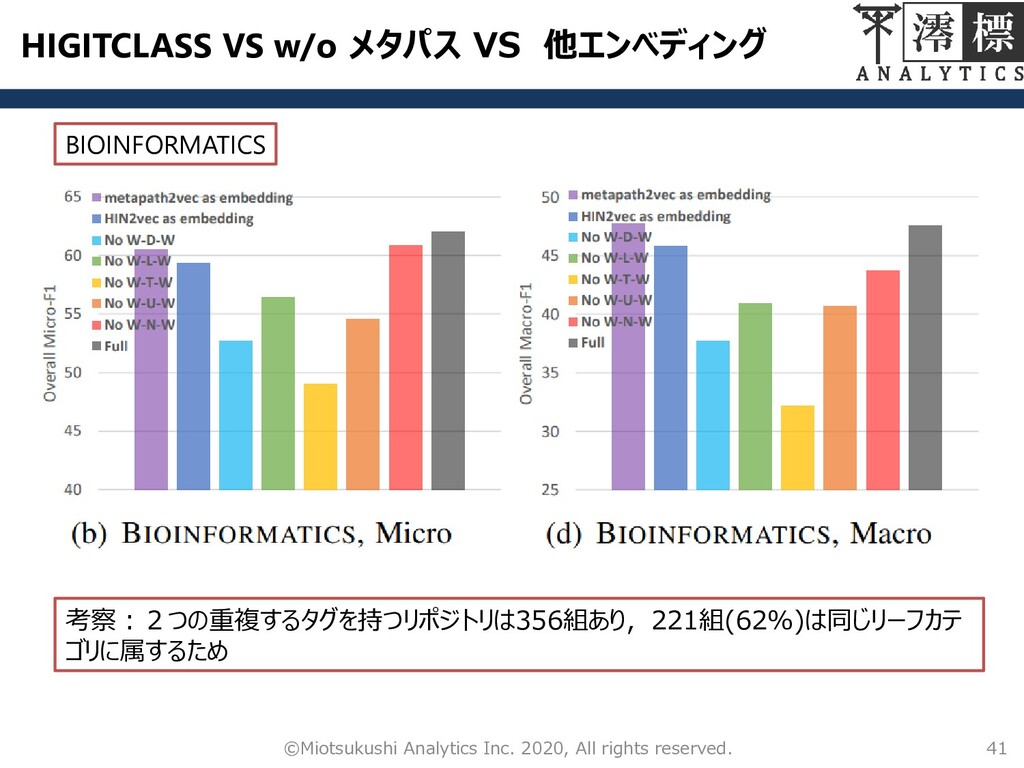
HIGITCLASS VS w/o メタパス VS 他エンべディング 41 ©Miotsukushi Analytics Inc.
2020, All rights reserved. BIOINFORMATICS 考察:2つの重複するタグを持つリポジトリは356組あり,221組(62%)は同じリーフカテ ゴリに属するため
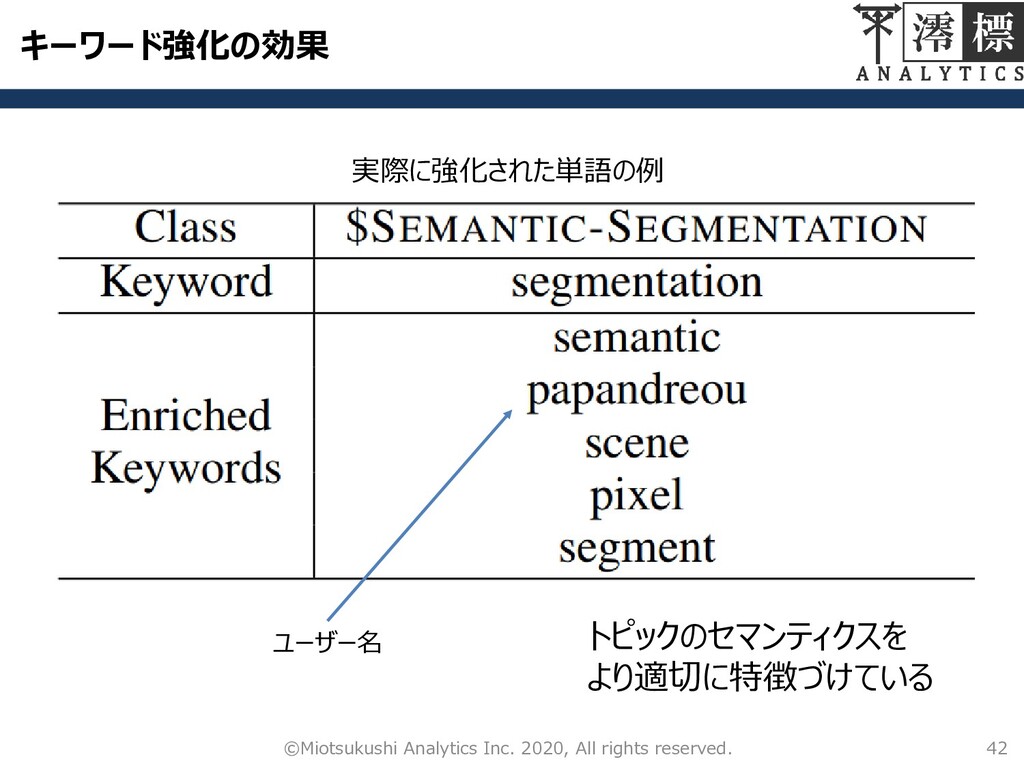
キーワード強化の効果 42 ©Miotsukushi Analytics Inc. 2020, All rights reserved. 実際に強化された単語の例
ユーザー名 トピックのセマンティクスを より適切に特徴づけている
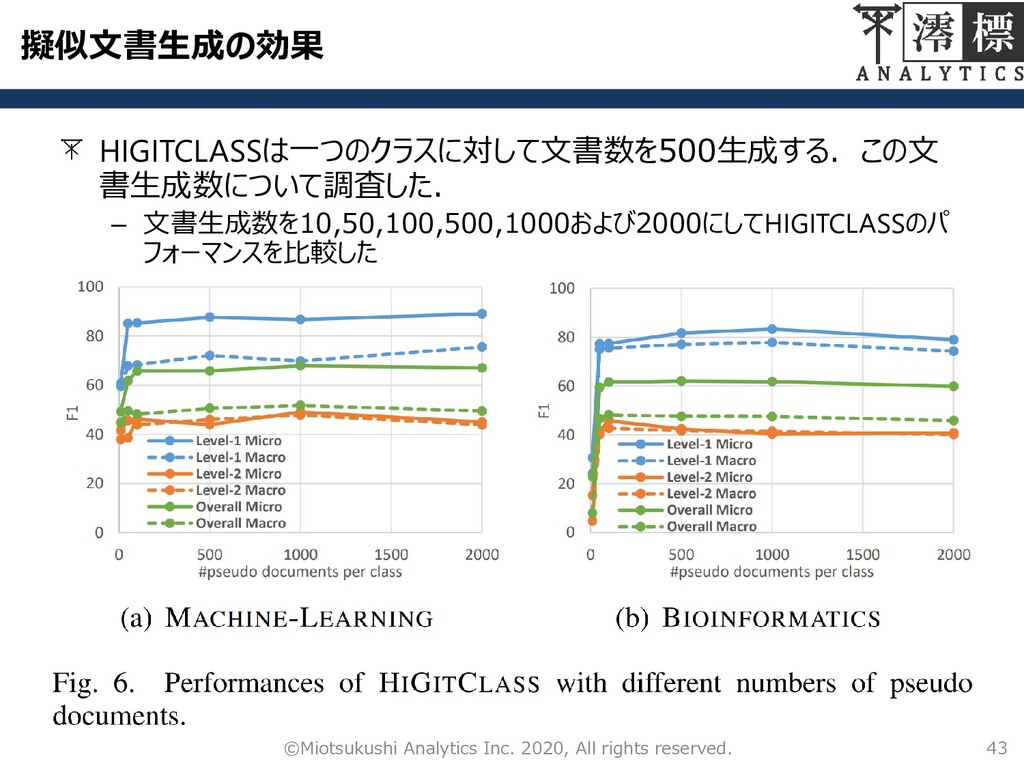
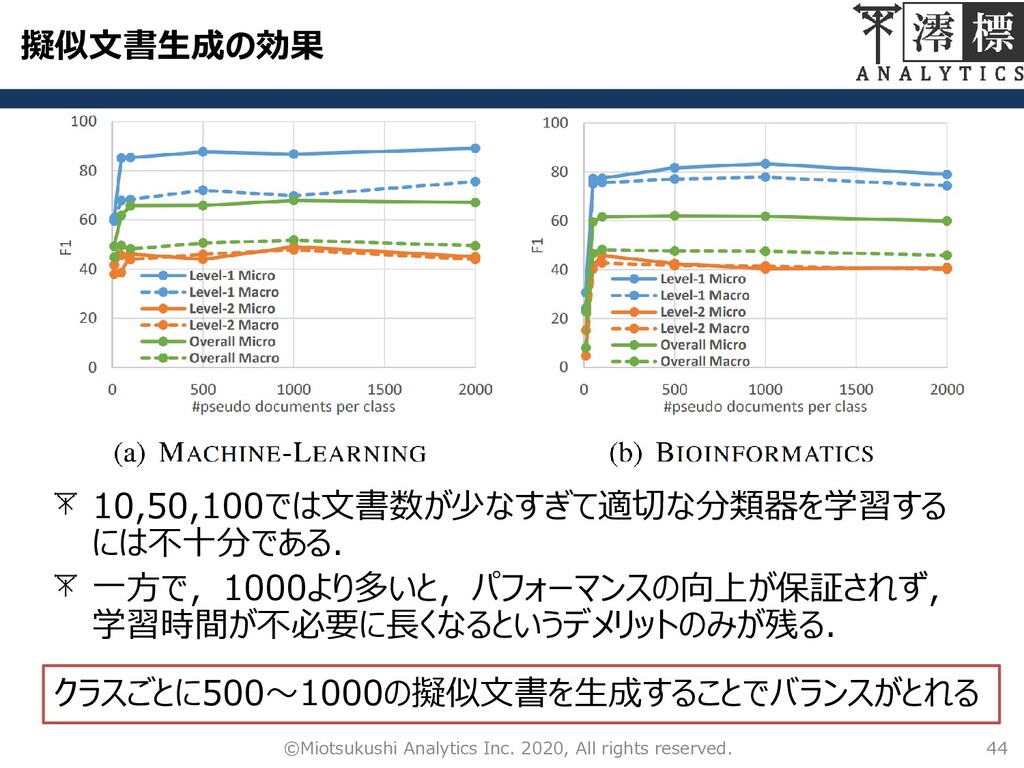
擬似文書生成の効果 43 ©Miotsukushi Analytics Inc. 2020, All rights reserved. HIGITCLASSは一つのクラスに対して文書数を500生成する.この文
書生成数について調査した. – 文書生成数を10,50,100,500,1000および2000にしてHIGITCLASSのパ フォーマンスを比較した
擬似文書生成の効果 44 ©Miotsukushi Analytics Inc. 2020, All rights reserved. 10,50,100では文書数が少なすぎて適切な分類器を学習する
には不十分である. 一方で,1000より多いと,パフォーマンスの向上が保証されず, 学習時間が不必要に長くなるというデメリットのみが残る. クラスごとに500~1000の擬似文書を生成することでバランスがとれる
まとめ GitHubリポジトリのタグ付けタスクを通して様々な課題に取り組 んだ 45 ©Miotsukushi Analytics Inc. 2020, All rights
reserved. 課題 マルチモーダ ル情報の扱 い 教師データ不 足 異なる教師 データフォー マット アプローチ HINネットワー クの活用と埋 め込み キーワード強 化モジュール 擬似ドキュメ ント生成 各アプローチを行うことで,既存手法より優れたパフォーマンスを 示すことが出来た
YOU can count on US. ©Miotsukushi Analytics Inc. 2020, All
rights reserved. 46
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}