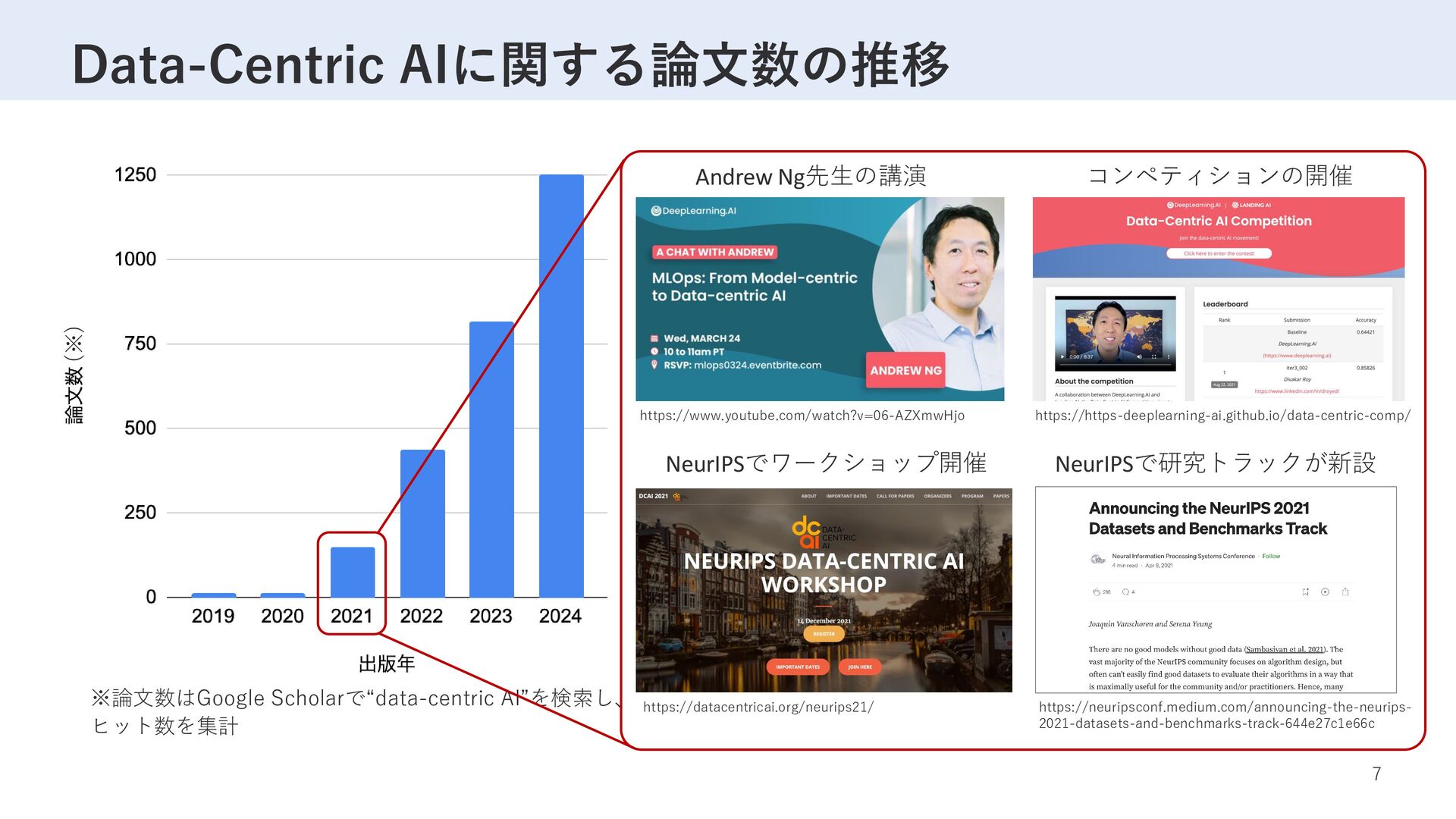
CHI 2021] “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI データカスケード:データの問題から生じる 負の影響が連鎖的に下流に波及していく事象 • データ作業の軽視:データ収集やアノテー ションなどの作業はモデル開発と比較して、 成果が適切に評価されづらく、インセン ティブ(報酬や学術的成果など)が不足し ているため、軽視される傾向にある。 • データカスケードの原因:現実世界との乖離、 応用ドメイン領域の知識不足、相反する報酬 システム、組織間におけるドキュメント不足 により発生
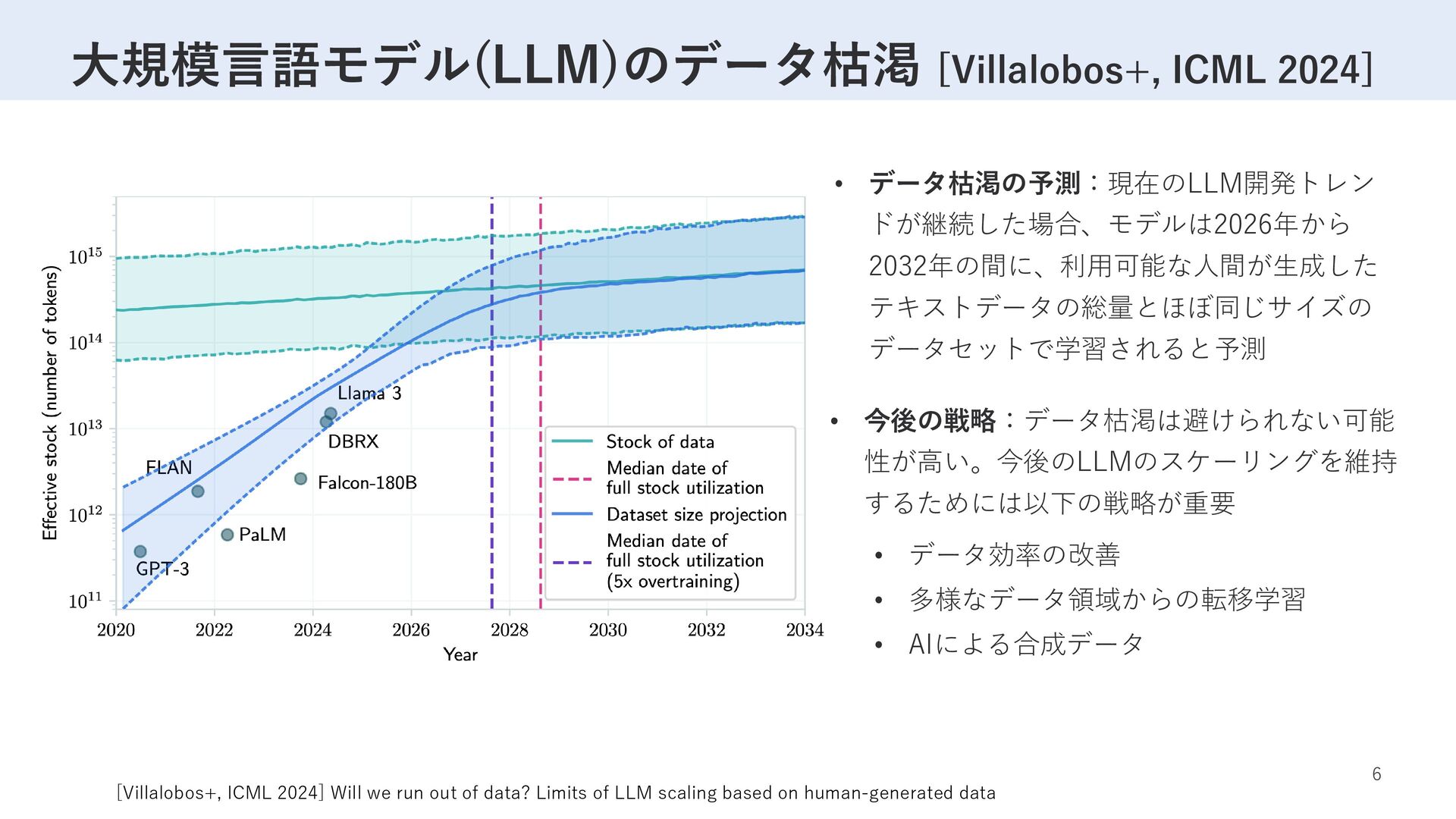
するためには以下の戦略が重要 [Villalobos+, ICML 2024] Will we run out of data? Limits of LLM scaling based on human-generated data 大規模言語モデル(LLM)のデータ枯渇 [Villalobos+, ICML 2024] • データ効率の改善 • 多様なデータ領域からの転移学習 • AIによる合成データ
models collapse when trained on recursively generated data • 研究の目的:将来、インターネット上のコンテンツの多くがAIによって生成されるようになると、新 しいモデルはAI生成データを再び学習することになる。本研究では、AIが自ら生成した情報を再学習 し続けたときに、モデルの性能や分布特性にどのような影響が生じるのかを明らかにする。 • モデル崩壊:学習済みのモデルが生成したデータが次世代モデルの学習データセットを汚染し、後続 モデルが現実を誤って認識するようになる退化的なプロセスのこと。
A Systematic Study of Scaling Laws, Benefits, and Pitfalls 合成データのタイプ • 教科書スタイルの合成データ (TXBK)を学習に用いた場合、Validation loss が明確に高く、 性能が劣化する。 • 再言語化合成データ(HQやQA)では、自然データ (CC)と同等、あるいはわずかに良好な結果 が得られた。 合成データのスケーリング則と混合戦略 [Kang+, arXiv 2025] (2/3)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![5 データカスケード [Sambasivan+, CHI 2021] • データカスケードの蔓延:インタビュー参加 者53名のAI実務者の92%が1回以上、45.3%が 2回以上のデータカスケードを経験 [Sambasivan+,](https://files.speakerdeck.com/presentations/f10dbcff10744179b21c4dfafc986d29/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
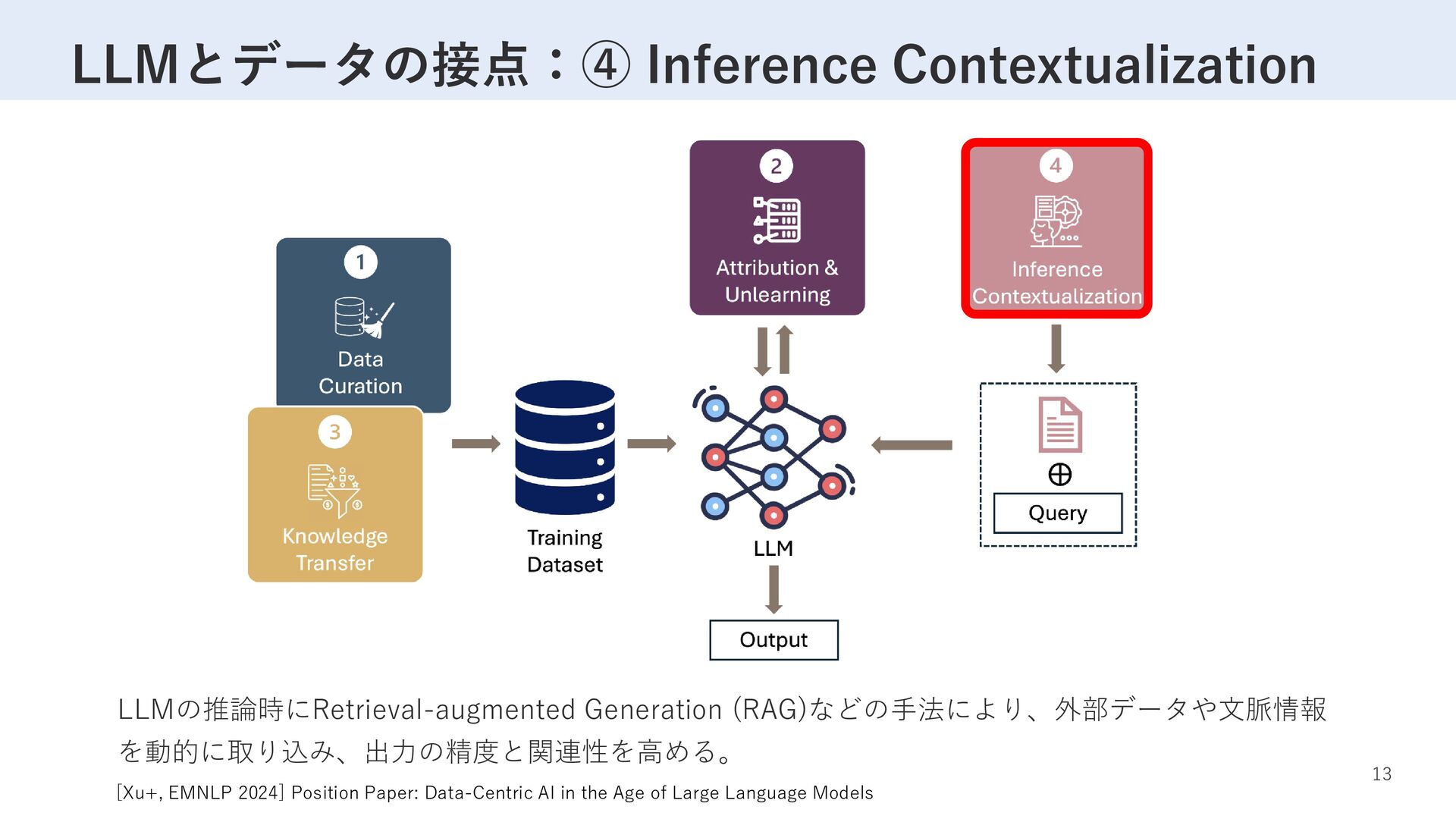
![9 LLMとデータの接点 [Xu+, EMNLP 2024] Position Paper: Data-Centric AI in](https://files.speakerdeck.com/presentations/f10dbcff10744179b21c4dfafc986d29/slide_8.jpg){kind=link}
![10 LLMとデータの接点:① Data Curation LLMを学習するための膨大なデータを収集・選別・整形し、高品質で信頼性の高い学習データとして 体系的に整備する。 [Xu+, EMNLP 2024] Position](https://files.speakerdeck.com/presentations/f10dbcff10744179b21c4dfafc986d29/slide_9.jpg){kind=link}
![11 LLMとデータの接点:② Attribution & Unlearning 著作権侵害や有害なメッセージなどの問題があるLLMの出力のソースを追跡(Attribution)し、 その影響を除去(Unlearning)する。 [Xu+, EMNLP 2024]](https://files.speakerdeck.com/presentations/f10dbcff10744179b21c4dfafc986d29/slide_10.jpg){kind=link}
![12 LLMとデータの接点:③ Knowledge Transfer 大規模な汎用モデルが持つ知識を抽出し、特定のタスクに最適化された小規模モデルへ効率的に 転移する。 [Xu+, EMNLP 2024] Position](https://files.speakerdeck.com/presentations/f10dbcff10744179b21c4dfafc986d29/slide_11.jpg){kind=link}
{kind=link}
![14 LLMとデータの接点:注目論文の紹介 今回は、Data CurationとKnowledge Transferに関連する「LLMによる合成データの活用」について、 二つの注目論文を紹介する。 [Xu+, EMNLP 2024] Position](https://files.speakerdeck.com/presentations/f10dbcff10744179b21c4dfafc986d29/slide_13.jpg){kind=link}
{kind=link}
![16 合成データによるモデル崩壊 [Shumailov+, Nature 2024] (1/3) [Shumailov+, Nature 2024] AI](https://files.speakerdeck.com/presentations/f10dbcff10744179b21c4dfafc986d29/slide_15.jpg){kind=link}
![17 合成データによるモデル崩壊 [Shumailov+, Nature 2024] (2/3) [Shumailov+, Nature 2024] AI](https://files.speakerdeck.com/presentations/f10dbcff10744179b21c4dfafc986d29/slide_16.jpg){kind=link}
![18 合成データによるモデル崩壊 [Shumailov+, Nature 2024] (3/3) [Shumailov+, Nature 2024] AI](https://files.speakerdeck.com/presentations/f10dbcff10744179b21c4dfafc986d29/slide_17.jpg){kind=link}
![19 [Kang+, arXiv 2025] Demystifying Synthetic Data in LLM Pre-training:](https://files.speakerdeck.com/presentations/f10dbcff10744179b21c4dfafc986d29/slide_18.jpg){kind=link}
![20 [Kang+, arXiv 2025] Demystifying Synthetic Data in LLM Pre-training:](https://files.speakerdeck.com/presentations/f10dbcff10744179b21c4dfafc986d29/slide_19.jpg){kind=link}
![21 [Kang+, arXiv 2025] Demystifying Synthetic Data in LLM Pre-training:](https://files.speakerdeck.com/presentations/f10dbcff10744179b21c4dfafc986d29/slide_20.jpg){kind=link}
{kind=link}