Read Database in Sync • Database Logs: The Source's Own Truth • MongoDB Change Streams • Building a Read Database with Change Streams • Lessons from Production • Conclusion
writes often perform poorly under complex read queries. • Joins, aggregations, and filters on relational data become expensive as data grows. • Independent scalability. Read and write sides can be scaled separately based on their own loads. • Custom data shape. A dedicated read model can be denormalized to exactly match query requirements. • Right tool for the right job. Different read use cases may call for different databases. (full-text search, caching, analytics etc.) • The read DB keeps serving queries even when the source DB is down or under maintenance.
application writes to both source and read DB in the same operation. • Event-driven sync. The app publishes events, a consumer updates the read DB. • Scheduled batch refresh. A periodic job polls the source and applies recent changes to the read DB. • Log-based replication . Changes are captured directly from the database logs. Trade-offs at a Glance Each approach differs in latency, consistency guarantees, and operational cost. • Dual writes and event sync tie read DB updates to application code. Outbox pattern helps, but adds complexity. • Log-based replication wins on ordering, durability, and decoupling from the application.
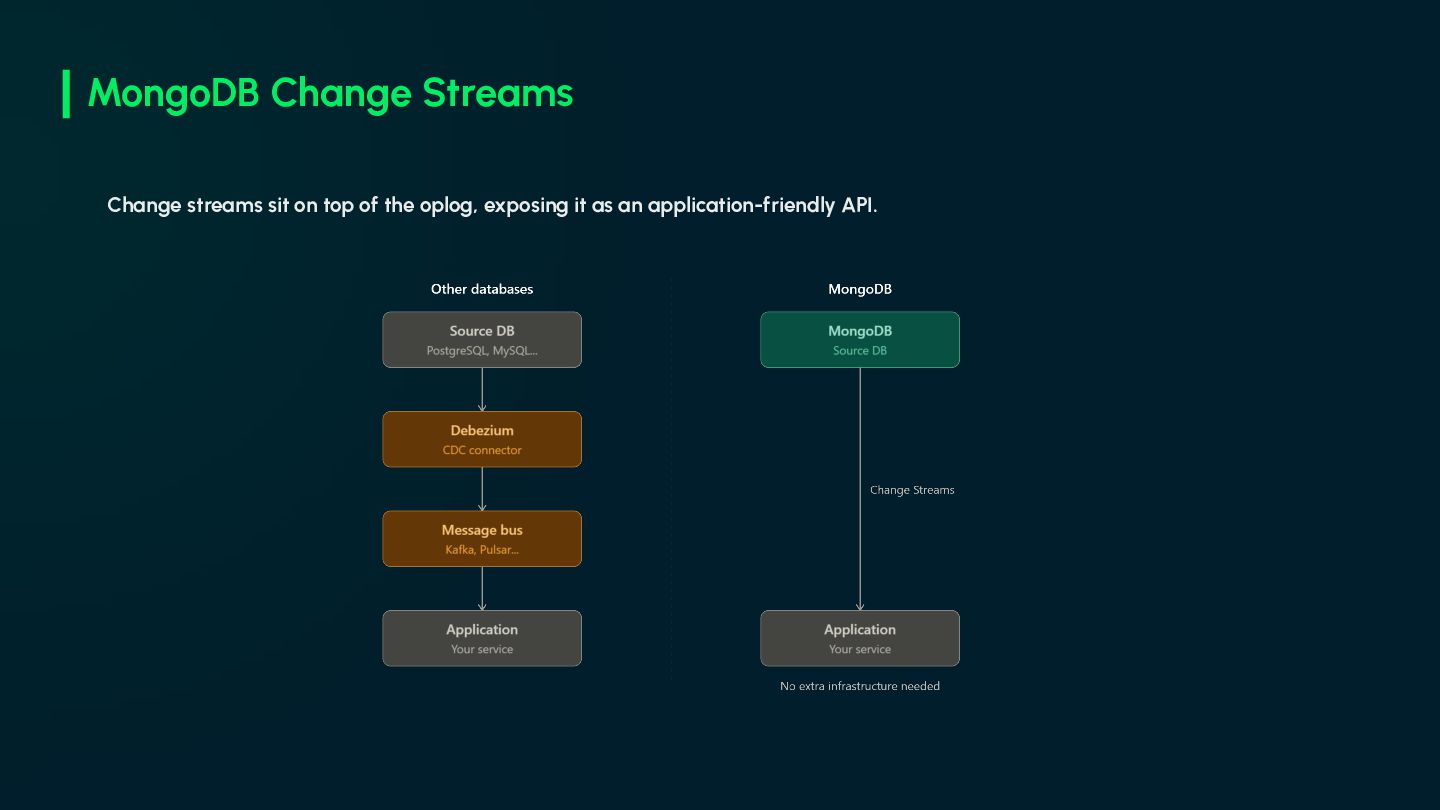
maintains a log for recovery and replication. • Postgres has the WAL, MySQL has the binlog, MongoDB has the oplog. • The log is append-only and ordered: inserts, updates, and deletes, nothing missed. • Applications can read this log to react to changes without touching the source service. • This is the core idea behind Change Data Capture (CDC).
instances are not supported. • A change stream is a cursor that streams ordered change events in real time. • Can be opened at collection, database, or cluster level. • Event types: insert, update, replace, delete, drop, and invalidate. • Server-side filtering allows subscribing only to the changes you care about. • Change streams guarantee at-least-once delivery, backed by a resume token.
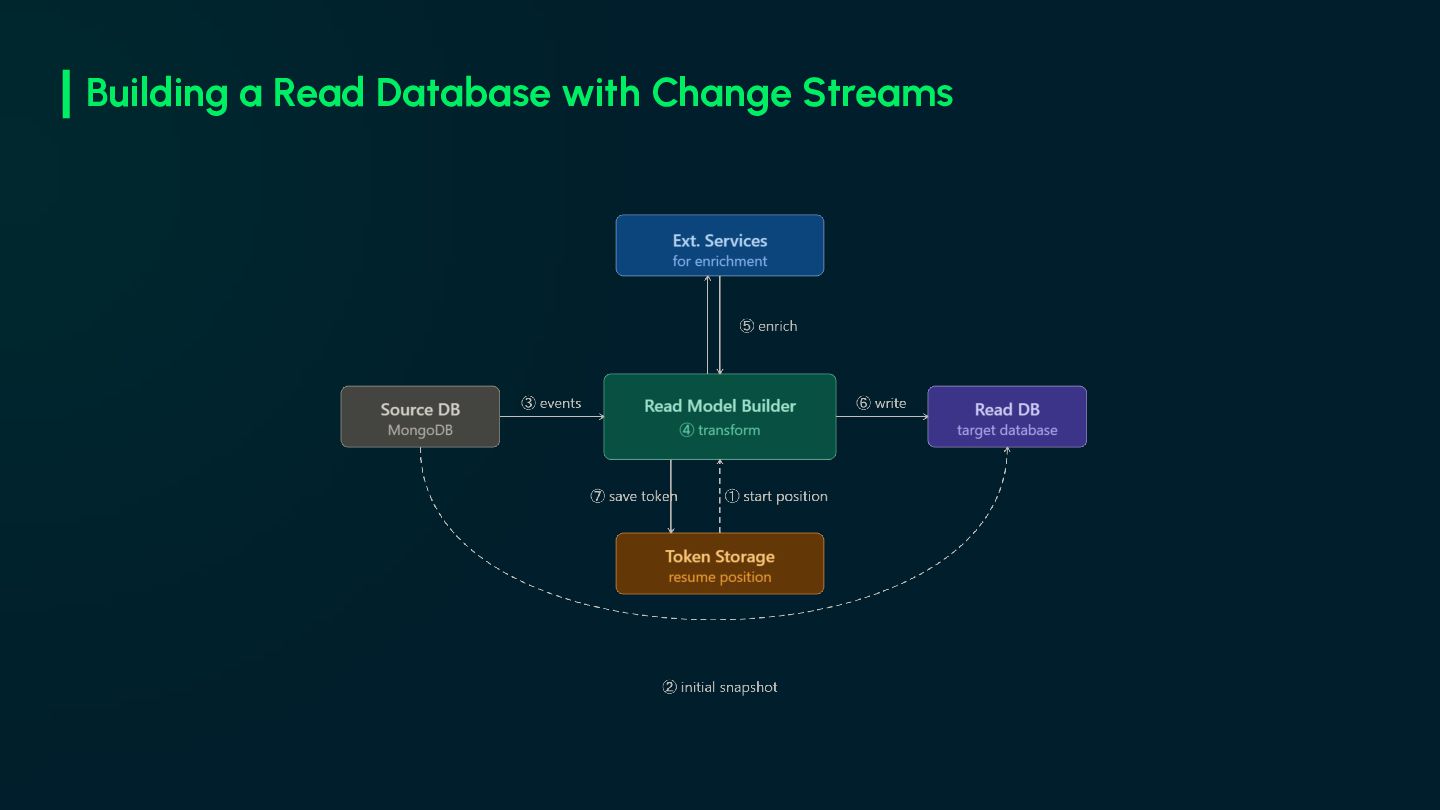
start position. Save the resume token before the snapshot begins to avoid missing events. • Initial snapshot. Existing data must be loaded into the read DB before the change stream starts. • Start the change stream. Start listening from the saved token once the snapshot is complete. • Process and transform. Each event is consumed, mapped, and shaped to match the read model. • Enrich with external data. Events may need data from other services to build a complete read model. • Write enriched data to the read DB. • Save the resume token after successfully processed event.
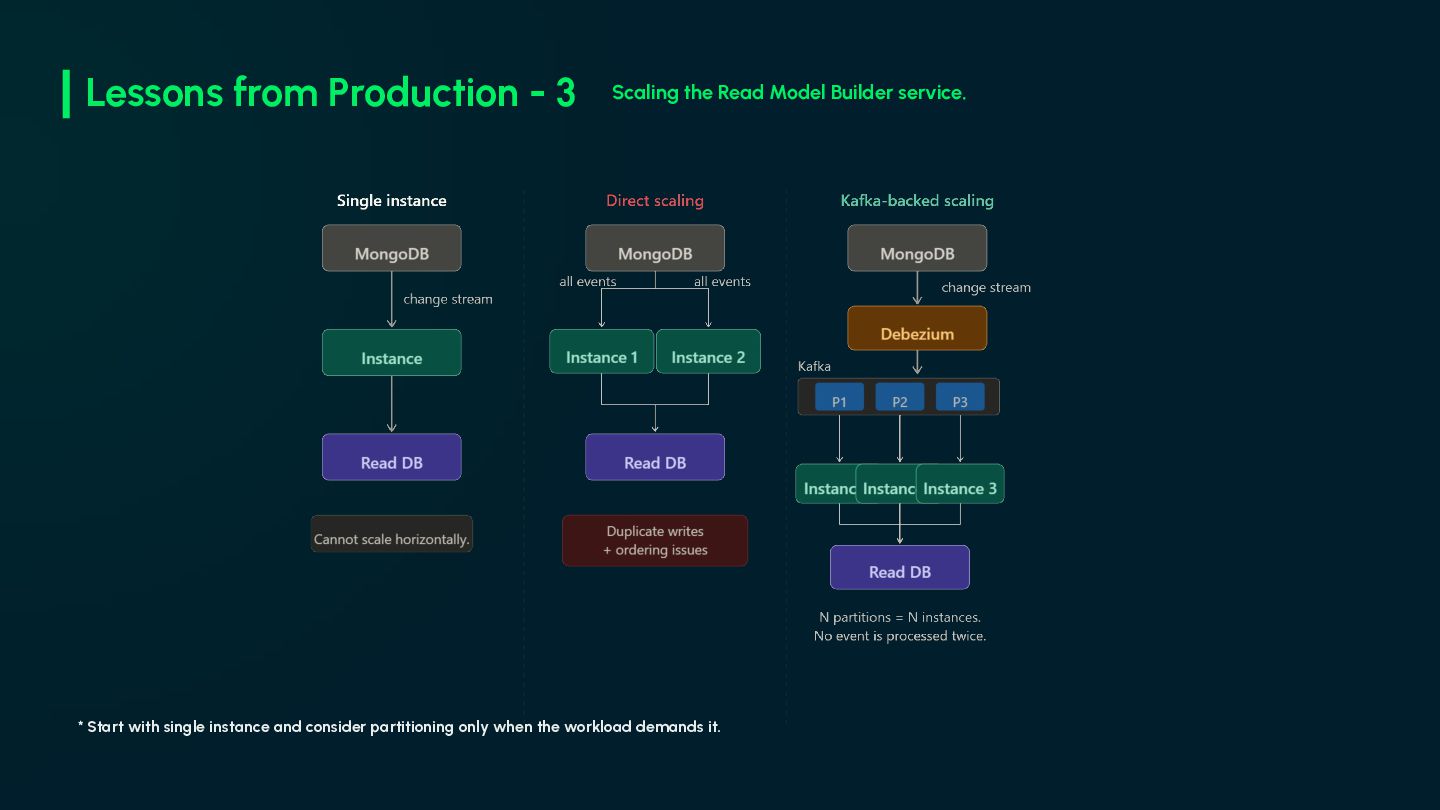
N failures on the same event, skip it and log critically. Never let a poison message block the stream. • Handle Read DB unavailability and backpressure. (pay attention to oplog window) • Never commit the resume token until the event is fully processed. • Make sure your streamer automatically restarts after any crash. • Always restart from the persisted token. Starting from current time on restart, silently loses every event that arrived during downtime. • Consider batch processing if read model builder falls behind. • Don't forget the replace event. replaceOne() won't produce an update event. Resiliency of the Read Model Builder service.
day one. It is not a deployment script, it is your catch-all recovery mechanism. (event loss, schema changes, data corruption) • The stream and snapshot, both must be designed to run concurrently without corrupting the read DB. • Snapshot batches create a processing gap. An update processed in this gap can be overwritten. Versioned writes prevent it. • Offset-based pagination fails during the snapshot. Inserts and deletes shift the window. Use cursor-based pagination instead. • Cursor-based pagination requires an ordered field. UUIDs may not be sequential, a timestamp like CreatedAt is a safer choice. • Use the source document ID as the read document ID. Idempotency is enforced at the storage level. Duplicate inserts will be rejected. • Unless urgent, run snapshots during off-peak hours. Build the snapshot like a feature, not a script.
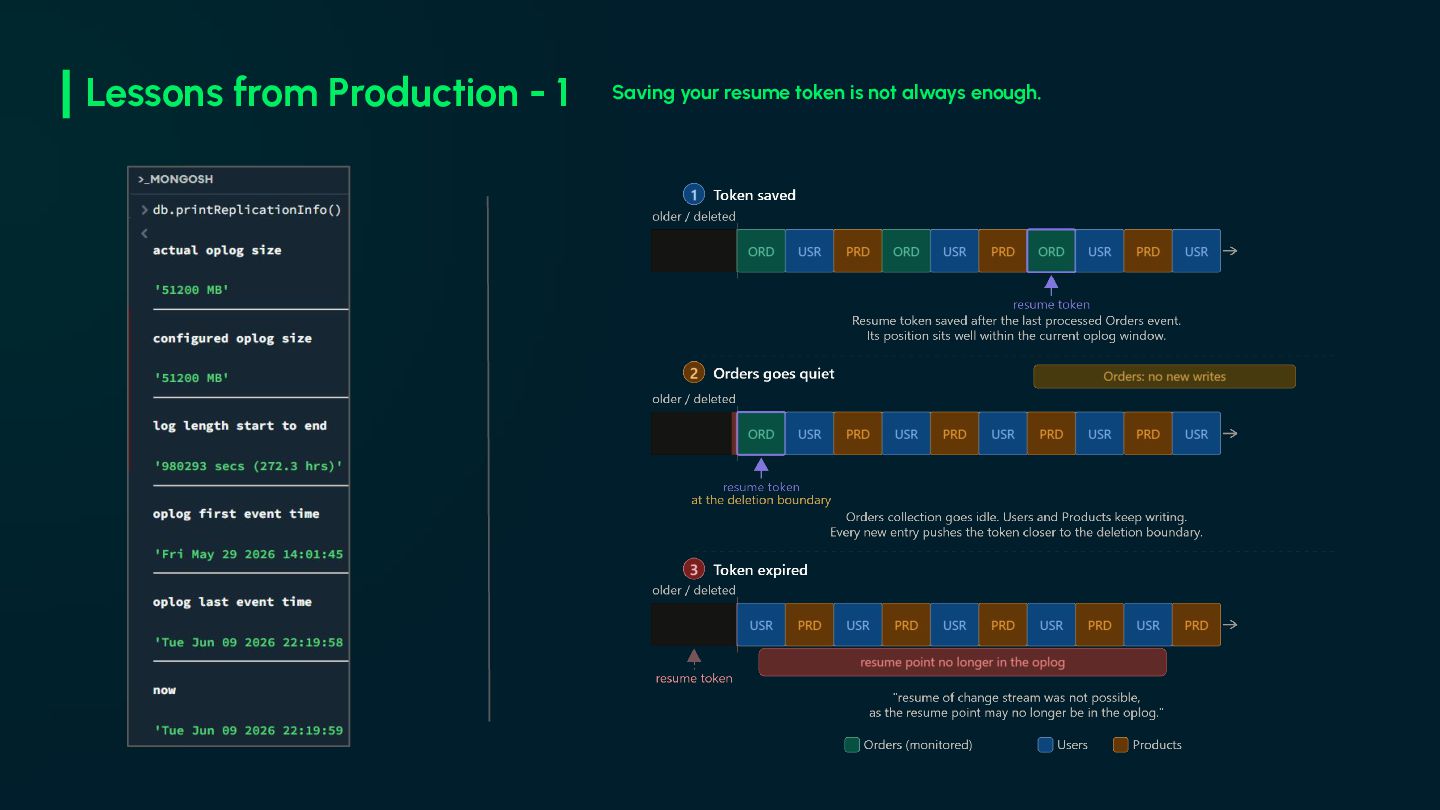
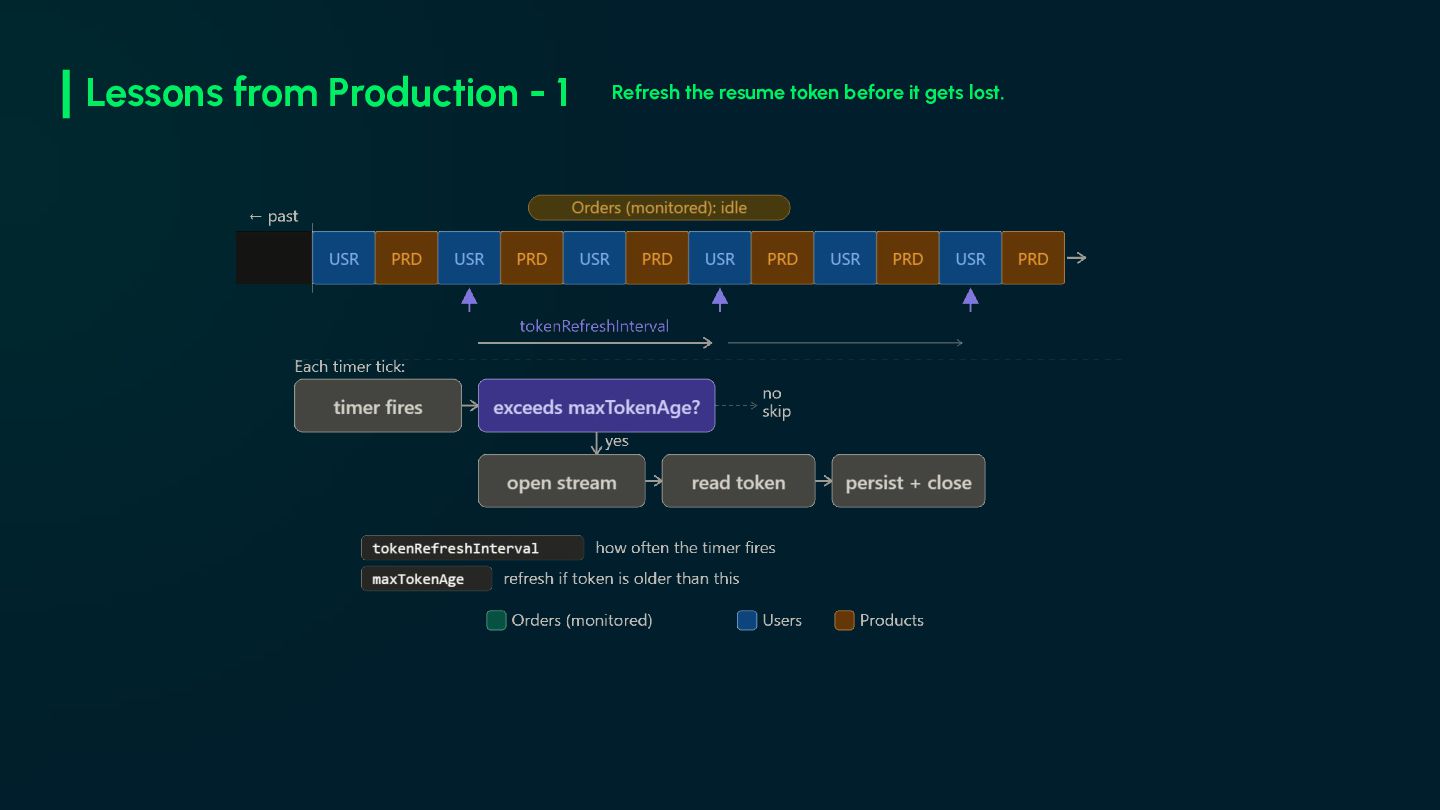
infrastructure. No CDC tool, no message bus. • The resume token is the most important piece in your system. Treat its loss as an incident. • Monitor oplog window size. A shrinking window means your resume token can expire, causing event loss. • Design for idempotency from day one. • The snapshot is not a deployment script. You will need it again. • Everything will fail eventually. Design accordingly.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}