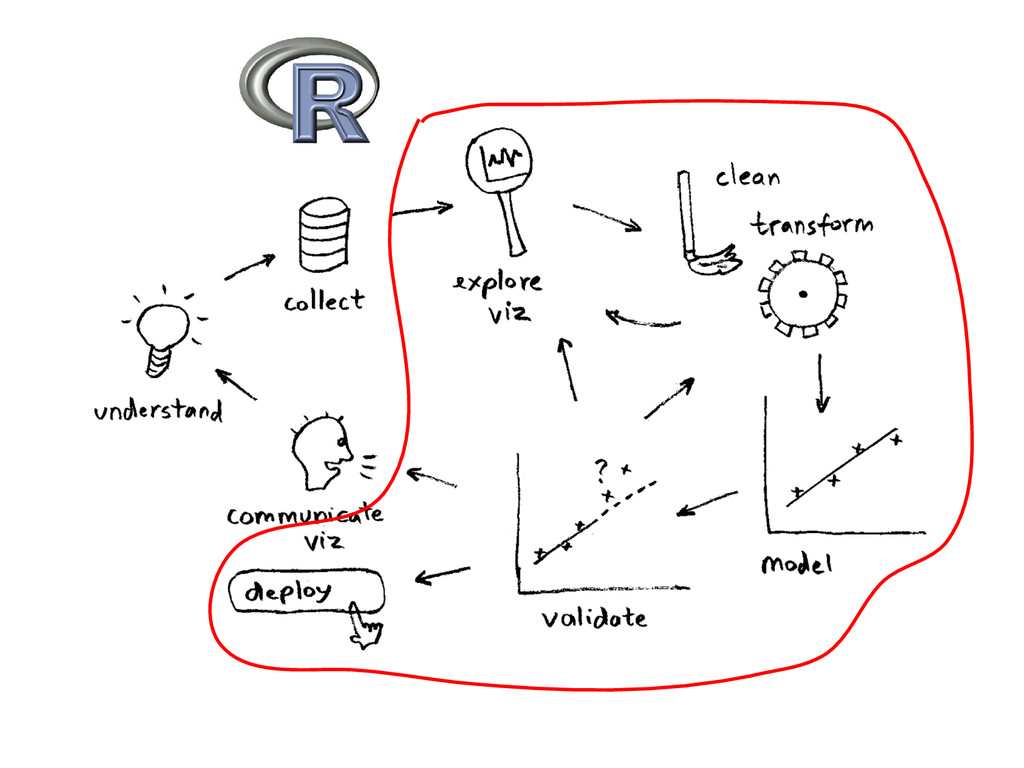
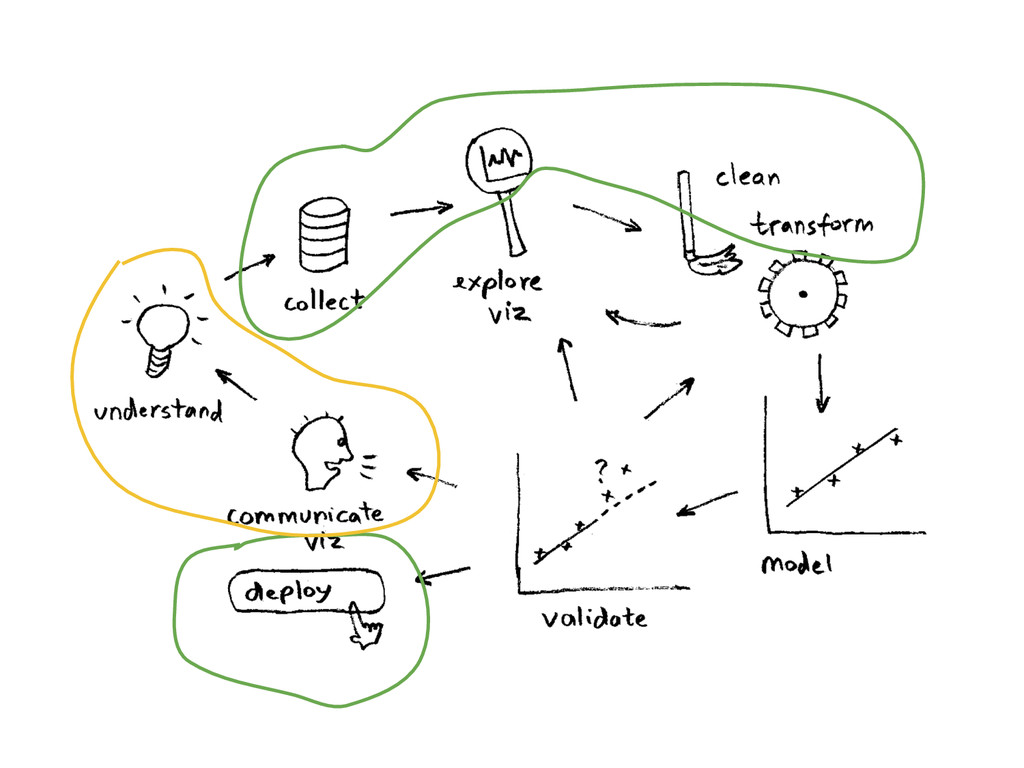
and R. So the most obvious thing to was to investigate about SparkR I came across a piece of code that reads lines from a file and count how many lines have a "a" and how many lines have a "b". I prepared a file with 5 columns and 1 million records.
and R. So the most obvious thing to was to investigate about SparkR I came across a piece of code that reads lines from a file and count how many lines have a "a" and how many lines have a "b". I prepared a file with 5 columns and 1 million records. Spark: 26.45734 seconds for a million records? Nice job -:) R: 48.31641 seconds? Look like Spark was almost twice as fast this time...and this is a pretty simple example...I'm sure that when complexity arises...the gap is even bigger…
and R. So the most obvious thing to was to investigate about SparkR I came across a piece of code that reads lines from a file and count how many lines have a "a" and how many lines have a "b". I prepared a file with 5 columns and 1 million records. Spark: 26.45734 seconds for a million records? Nice job -:) R: 48.31641 seconds? Look like Spark was almost twice as fast this time...and this is a pretty simple example...I'm sure that when complexity arises...the gap is even bigger… HOLLY CRAP UPDATE! Markus gave me this code on the comments... [R: 0.1791632 seconds]. I just added a couple of things to make complaint...but...damn...I wish I could code like that in R
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}