Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
到着予想時間サービスの特徴量のニアリアルタイム化
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Takashi Suzuki
May 31, 2023
Technology
200
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
到着予想時間サービスの特徴量のニアリアルタイム化
2023/5/31に実施されたGO TechTalkの登壇資料
Takashi Suzuki
May 31, 2023
More Decks by Takashi Suzuki
See All by Takashi Suzuki
Kubernetes超入門
t24kc
0
240
AI予約サービスのMLOps事例紹介
t24kc
0
44
MLプロジェクトのリリースフローを考える
t24kc
0
24
GOの機械学習システムを支えるMLOps事例紹介
t24kc
0
160
Optuna on Kubeflow Pipeline 分散ハイパラチューニング
t24kc
0
56
GOの実験環境について
t24kc
0
43
MOVの機械学習システムを支えるMLOps実践
t24kc
0
48
タクシー×AIを支えるKubernetesとAIデータパイプラインの信頼性の取り組みについて
t24kc
0
57
MOV お客さま探索ナビの GCP ML開発フローについて
t24kc
0
29
Other Decks in Technology
See All in Technology
20260619 私の日常業務での生成 AI 活用
masaruogura
1
200
やさしいA2A入門
minorun365
PRO
12
1.8k
機械学習を「社会実装」するということ 2026年夏版 / Social Implementation of Machine Learning June 2026 Version
moepy_stats
5
2.4k
社内 AI エージェント Synapse と セマンティックレイヤーの育て方
hiroakis
3
1.9k
スキルと MCP ツール、責務をどう分けるか? AI が迷わないインターフェース設計の戦略
cdataj
1
1k
現地で盛り上がった WWDC26 Keynote
zozotech
PRO
1
240
AIネイティブな開発のサプライチェーンリスク対策 〜激動の開発現場でリスクに立ち向かう〜【ZennFes】
cscengineer
PRO
2
120
200個のGitHubリポジトリを横断調査したかった
icck
0
130
AIはどのように 組織のアジリティを変えるのか?
junki
3
770
EventBridge Connection
_kensh
5
710
【Cyber-sec+】経営層を"動かす"ための考え方
hssh2_bin
0
180
FDE という解 ― 暗黙知と明示知をつなぐ、伴走型エンジニアリング ―
otanet
0
150
Featured
See All Featured
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
330
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Building Adaptive Systems
keathley
44
3.1k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
430
Navigating Weather and Climate Data
rabernat
0
220
A better future with KSS
kneath
240
18k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
210
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4k
First, design no harm
axbom
PRO
2
1.2k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
420
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Transcript
© GO Inc. タクシーアプリ『GO』 データ基盤 全体像 1 2023.05.31 GO株式会社
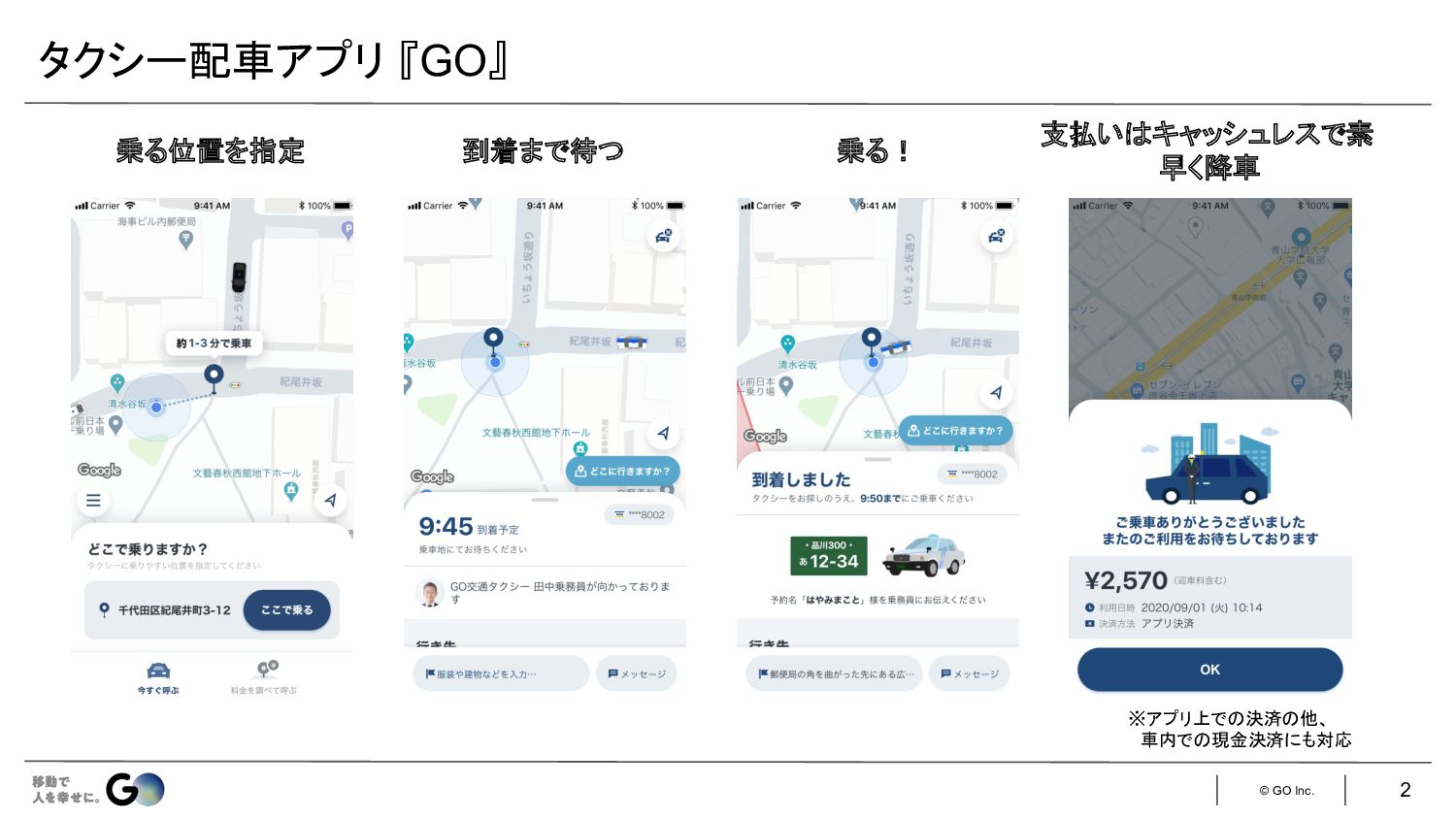
© GO Inc. 2 タクシー配車アプリ 『GO』 乗る位置を指定 到着まで待つ 乗る! 支払い
キャッシュレスで素 早く降車 ※アプリ上で 決済 他、 車内で 現金決済にも対応
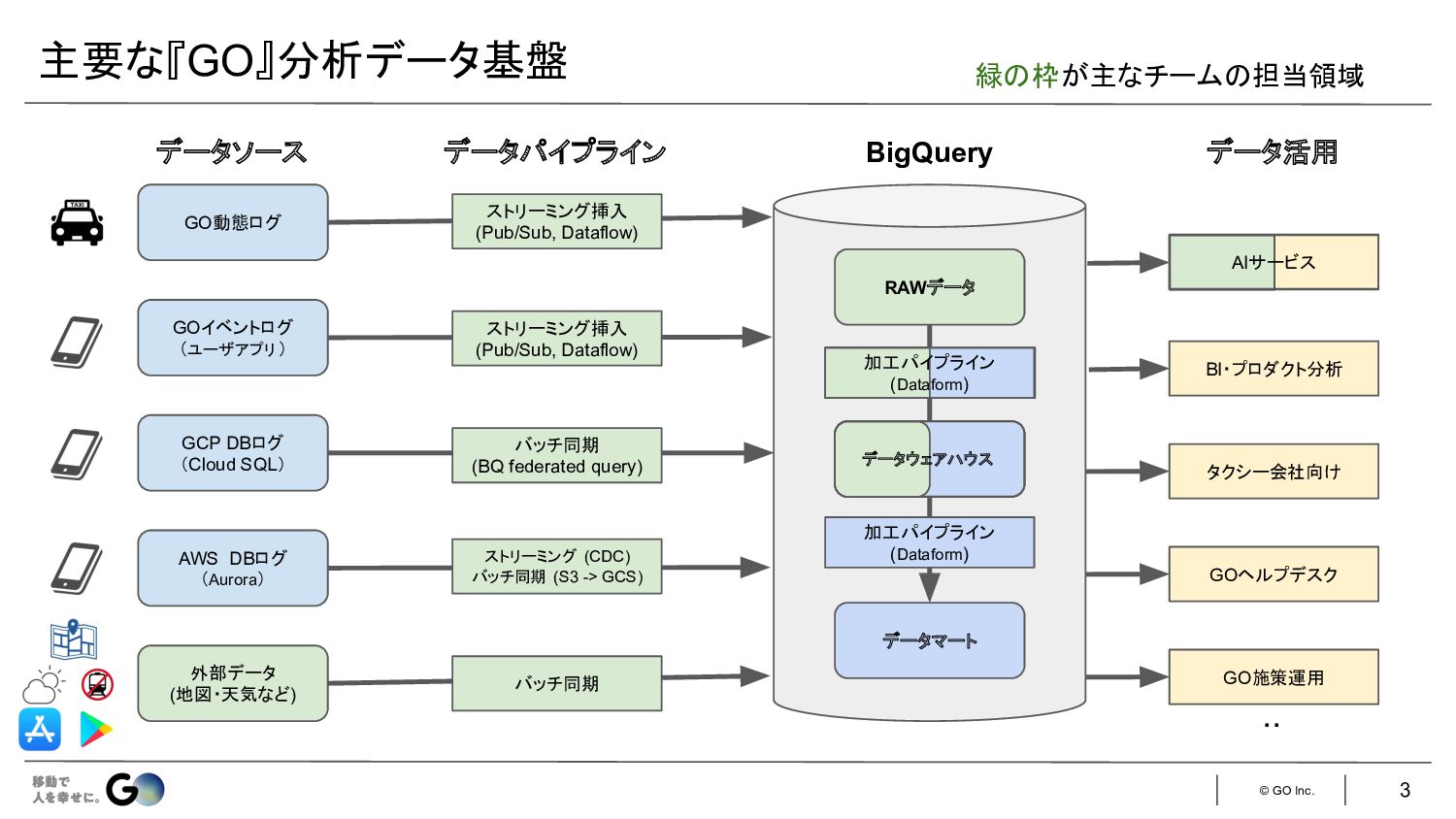
© GO Inc. 主要な『GO』分析データ基盤 3 GO動態ログ GOイベントログ (ユーザアプリ ) GCP
DBログ (Cloud SQL) AWS DBログ (Aurora) 外部データ (地図・天気など) データソース データパイプライン BigQuery RAWデータ データマート データ活用 BI・プロダクト分析 バッチ同期 ストリーミング (CDC) バッチ同期 (S3 -> GCS) バッチ同期 (BQ federated query) ストリーミング挿入 (Pub/Sub, Dataflow) ストリーミング挿入 (Pub/Sub, Dataflow) 加工パイプライン (Dataform) タクシー会社向け GOヘルプデスク GO施策運用 ・・ 緑 枠が主なチーム 担当領域 加工パイプライン (Dataform) データウェアハウス AIサービス
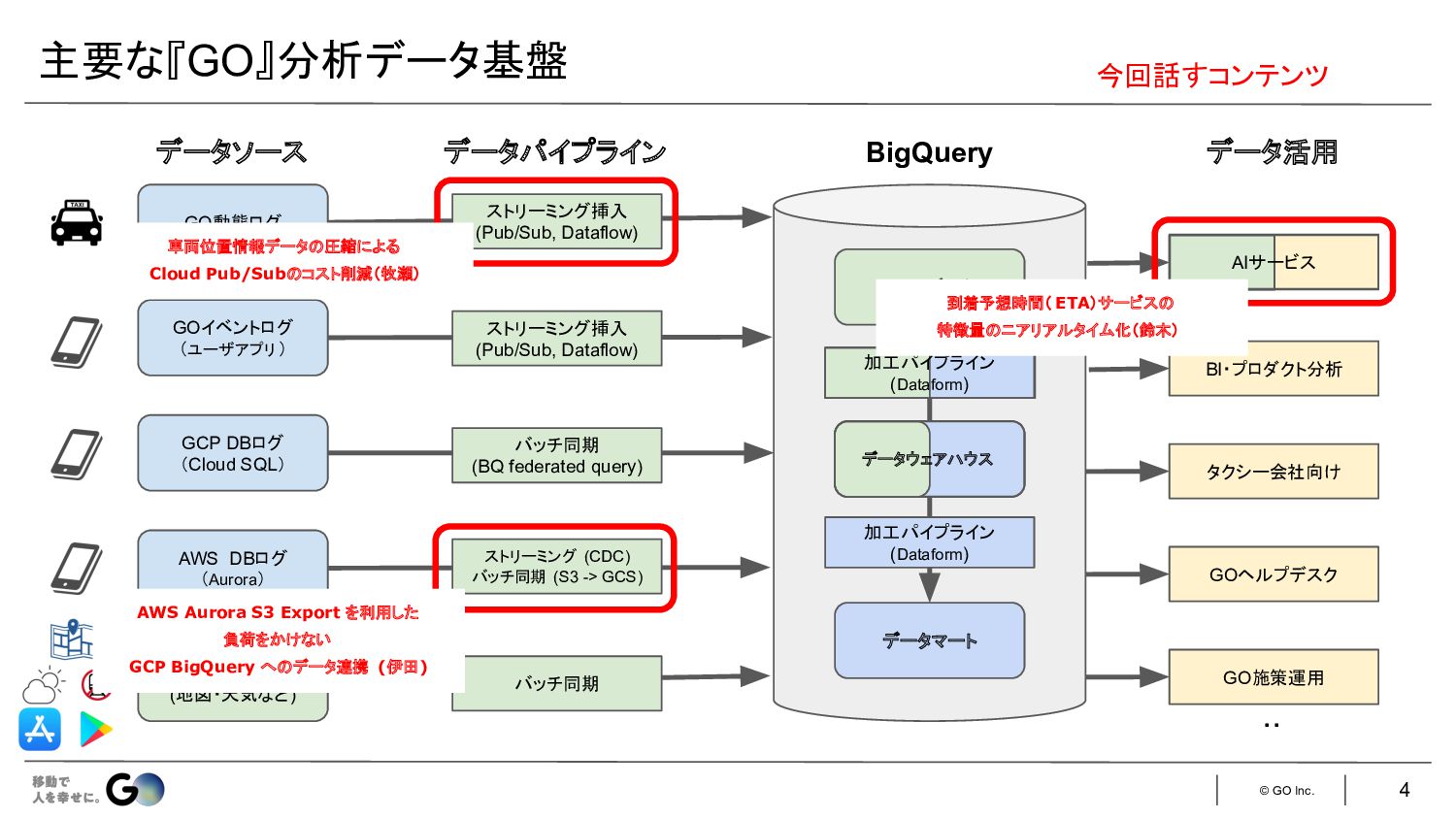
© GO Inc. 主要な『GO』分析データ基盤 4 今回話すコンテンツ GO動態ログ GOイベントログ (ユーザアプリ )
GCP DBログ (Cloud SQL) AWS DBログ (Aurora) 外部データ (地図・天気など) データソース データパイプライン BigQuery RAWデータ データマート データ活用 BI・プロダクト分析 バッチ同期 ストリーミング (CDC) バッチ同期 (S3 -> GCS) バッチ同期 (BQ federated query) ストリーミング挿入 (Pub/Sub, Dataflow) ストリーミング挿入 (Pub/Sub, Dataflow) 加工パイプライン (Dataform) タクシー会社向け GOヘルプデスク GO施策運用 加工パイプライン (Dataform) データウェアハウス AIサービス ・・ 車両位置情報データ 圧縮による Cloud Pub/Sub コスト削減(牧瀬) AWS Aurora S3 Export を利用した 負荷をかけない GCP BigQuery へ データ連携 (伊田) 到着予想時間( ETA)サービス 特徴量 ニアリアルタイム化(鈴木)
© GO Inc. 到着予想時間(ETA)サービス 特徴量 ニアリアルタイム化 5 2023.05.31 鈴木 隆史
GO株式会社
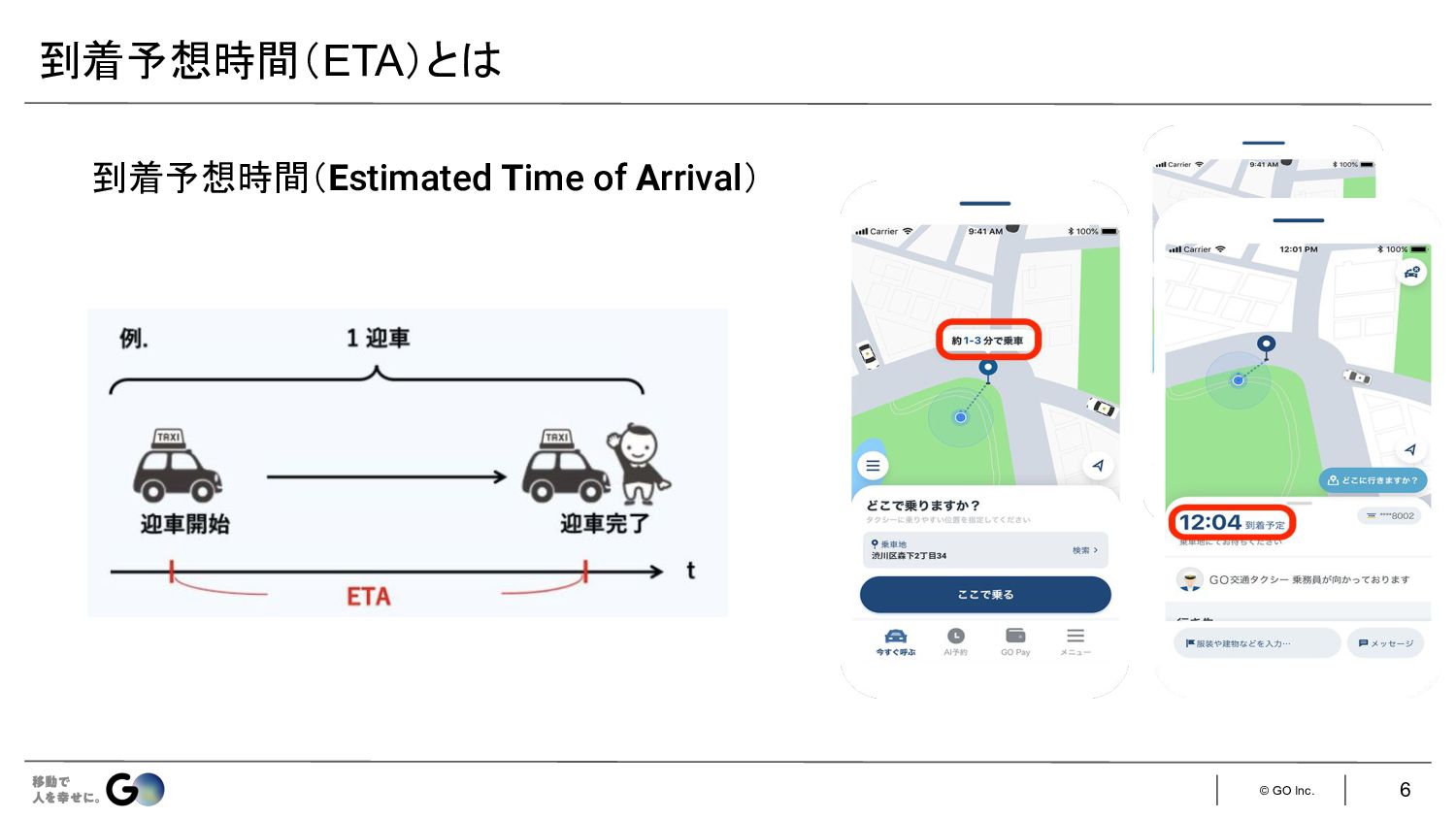
© GO Inc. 到着予想時間(Estimated Time of Arrival) 到着予想時間(ETA)と 6
© GO Inc. 7 ETA精度 事業影響度が大きい • 『GO』アプリ コア機能(配車依頼、予約機能など)として利用している •
アプリで表示している到着時間よりも遅着・早着 場合 ◦ UX 悪化、キャンセル率 増加 ◦ 特に大幅な遅着時 ネガティブ体験 • 遠方 車両を向かわせてしまった場合 ◦ 迎車時間が長くなることによる機会損失 到着予想時間(ETA) 精度 重要性
© GO Inc. 8 現状と課題
© GO Inc. アルゴリズム側 改善 • 経路探索 + MLモデル ハイブリッド構成へ変更(参考:
DeNA TechCon 2022 - あと何分?タク シーアプリ『GO』到着予測AI 社会実装まで -) • 通り過ぎ問題へ 対策(参考:GO Tech Blog - ETA(到着予想時間) 重要性と「通り過ぎ問題」へ 対策 -) システム側 改善 • リアルタイムな需要供給・道路状況 反映 ◦ 降雪など 突発的なイベントで 精度低下 改善 9 到着予想時間(ETA) 精度向上に向けた取り組み 本日話すテーマ 課題 ニアリアルタイム(30分ごと)に更新されるデータを用いて 機械学習モデルを更新する仕組みがない
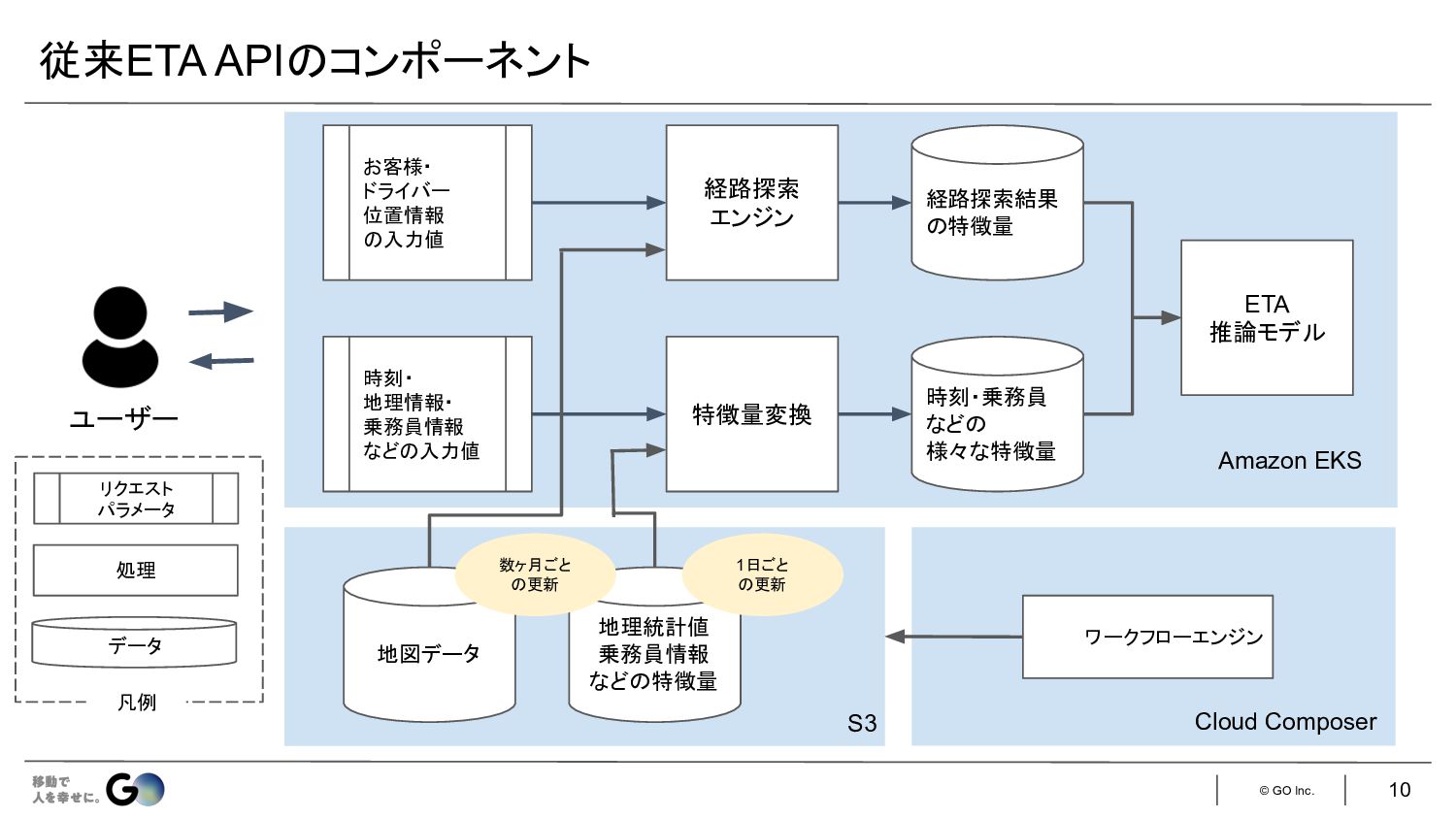
© GO Inc. 従来ETA API コンポーネント 10 ユーザー 時刻・ 地理情報・
乗務員情報 など 入力値 お客様・ ドライバー 位置情報 入力値 経路探索 エンジン 経路探索結果 特徴量 ETA 推論モデル Amazon EKS 特徴量変換 時刻・乗務員 など 様々な特徴量 地図データ S3 地理統計値 乗務員情報 など 特徴量 数ヶ月ごと 更新 ワークフローエンジン Cloud Composer 1日ごと 更新 処理 リクエスト パラメータ データ 凡例
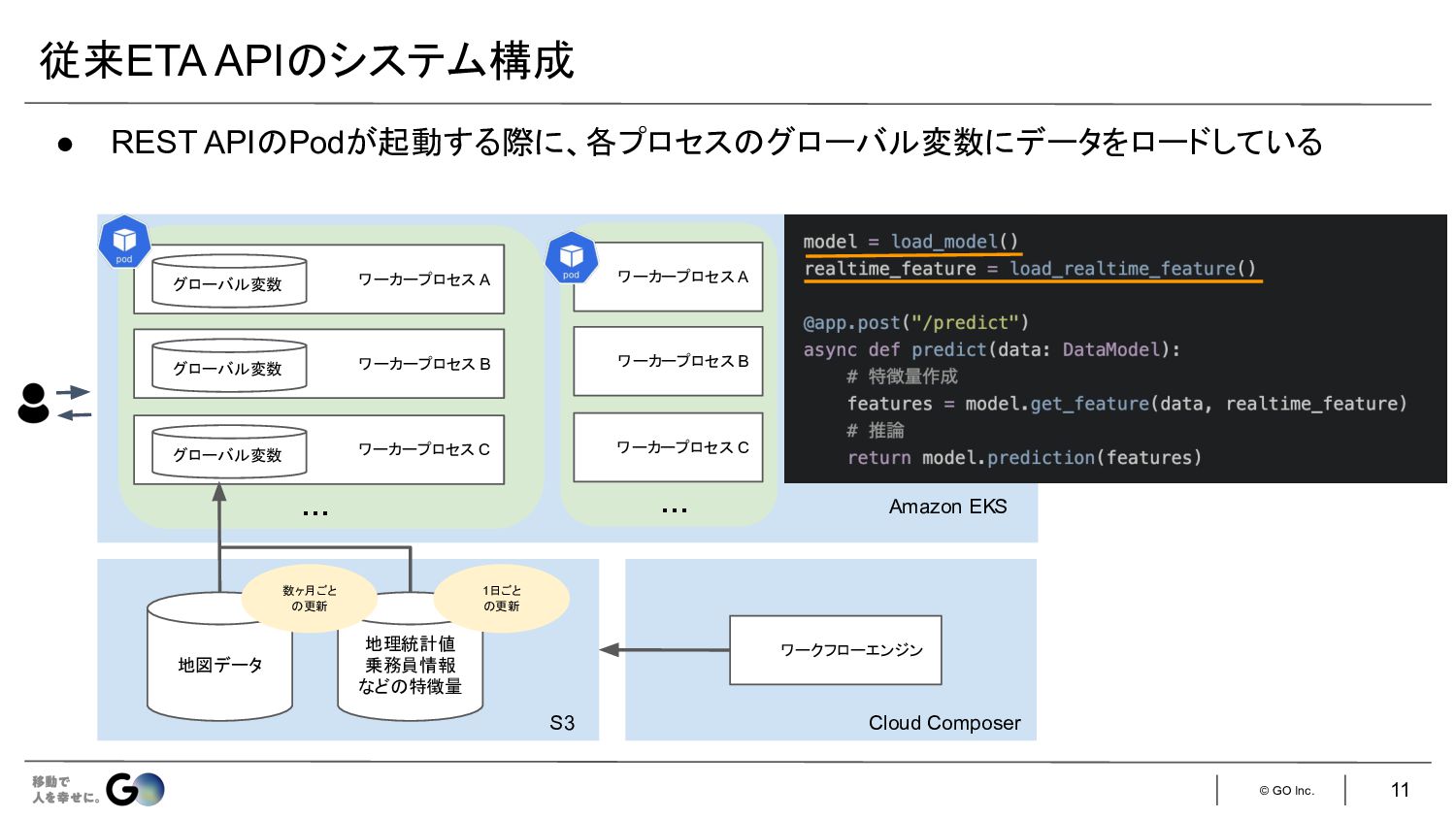
© GO Inc. 従来ETA API システム構成 11 地図データ 地理統計値 乗務員情報
など 特徴量 数ヶ月ごと 更新 1日ごと 更新 ワーカープロセス A グローバル変数 ワーカープロセス B グローバル変数 ワーカープロセス C グローバル変数 … … ワークフローエンジン Cloud Composer Amazon EKS S3 • REST API Podが起動する際に、各プロセス グローバル変数にデータをロードしている ワーカープロセス A ワーカープロセス B ワーカープロセス C …
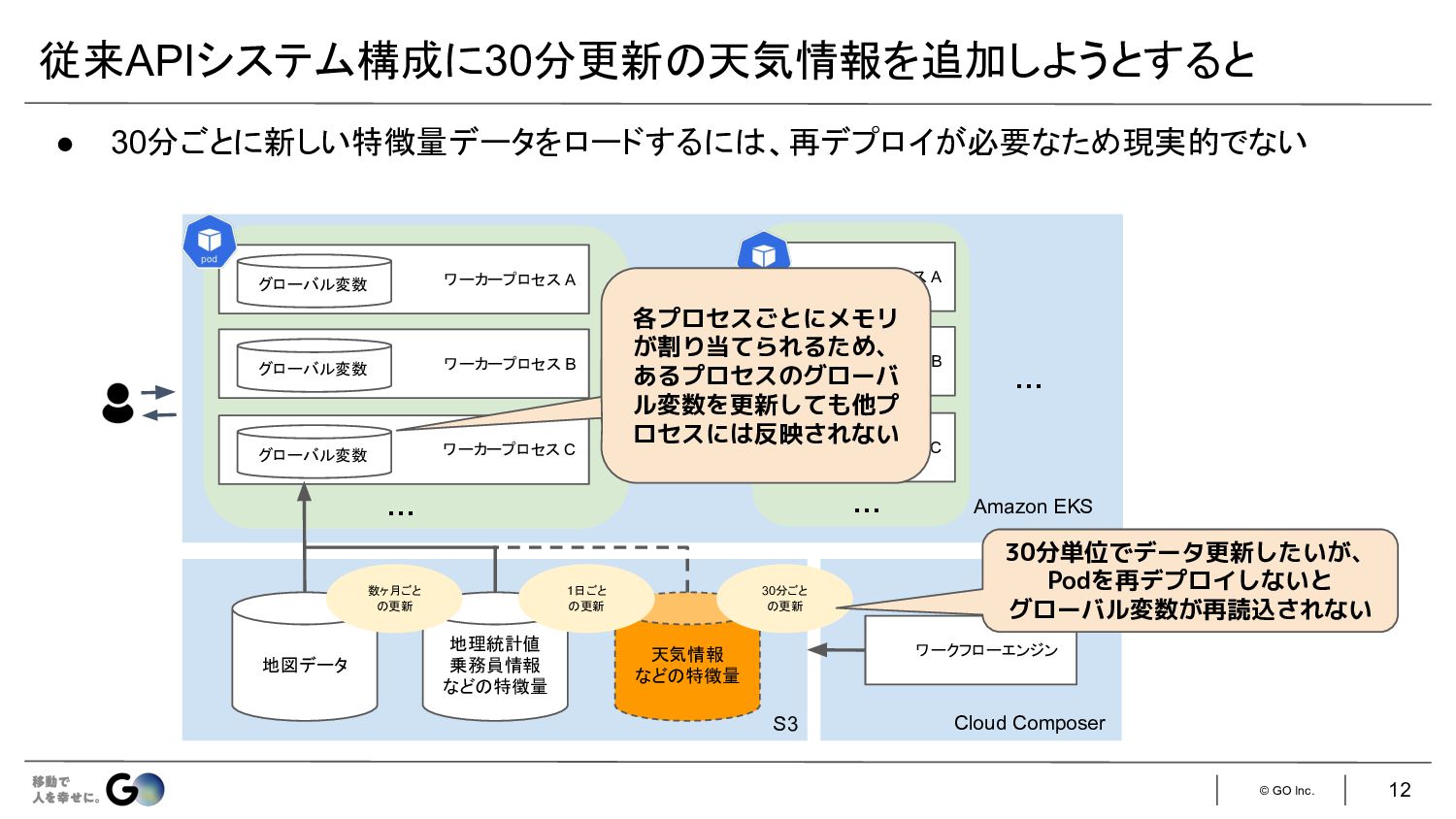
© GO Inc. 従来APIシステム構成に30分更新 天気情報を追加しようとすると 12 地図データ 地理統計値 乗務員情報 など
特徴量 天気情報 など 特徴量 数ヶ月ごと 更新 1日ごと 更新 ワーカープロセス A グローバル変数 ワーカープロセス B グローバル変数 ワーカープロセス C グローバル変数 … 30分ごと 更新 ワークフローエンジン Cloud Composer S3 • 30分ごとに新しい特徴量データをロードするに 、再デプロイが必要なため現実的でない 30分単位でデータ更新したいが、 Podを再デプロイしないと グローバル変数が再読込されない ワーカープロセス A ワーカープロセス B ワーカープロセス C … 各プロセスごとにメモリ が割り当てられるため、 あるプロセスのグローバ ル変数を更新しても他プ ロセスには反映されない … Amazon EKS
© GO Inc. 13 解決策 検討
© GO Inc. 14 解決案 候補 実装方式 サービング方式 メリット デメリット
Vertex AI Feature Store 利用 オンラインサービング (少量 最新データを取得 ) * 低レイテンシ/低メモリ * 複数データソース (BigQuery/GCS)に対して統一 したI/Fで取得可能 * コンピュートコスト大 * バッチ処理と比較して高い バッチサービング (大量 定期更新データを取得 ) * 統一I/F * サーバーキャッシュに乗せるこ とで低レイテンシ * 高メモリ * リアルタイムデータ 参照 ができない 独自実装 オンラインサービング (少量 最新データを取得 ) (Redis開発想定) * 低レイテンシ/低メモリ * コンピュートコスト大 バッチサービング (大量 定期更新データを取得 ) (データ取得プロセス開発想定 ) * サーバーキャッシュに乗せること で低レイテンシ * 使用メモリ次第で低コスト * 現状 実装ベース * リアルタイムデータ 参照 ができない * 高メモリ
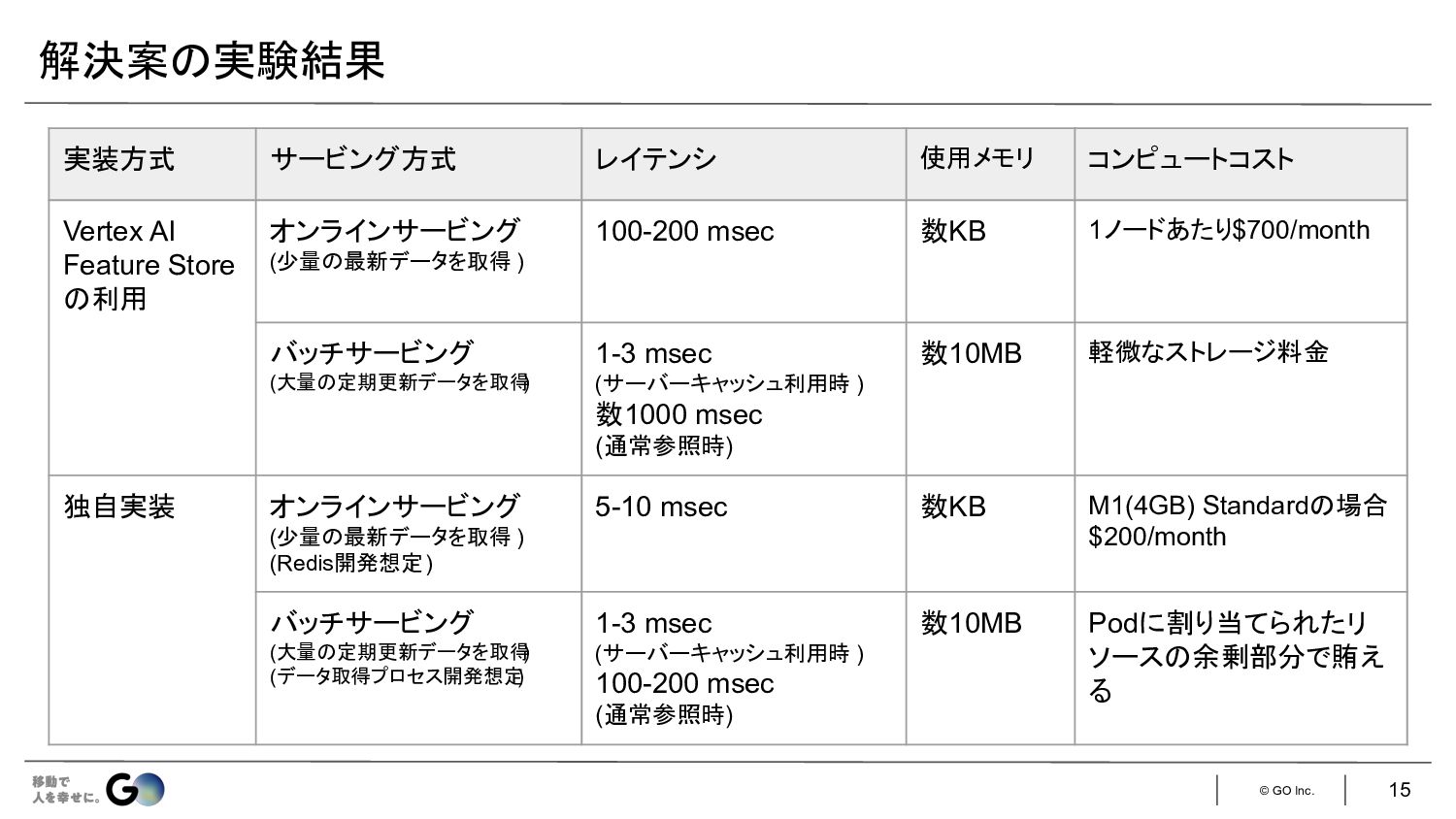
© GO Inc. 15 解決案 実験結果 実装方式 サービング方式 レイテンシ 使用メモリ
コンピュートコスト Vertex AI Feature Store 利用 オンラインサービング (少量 最新データを取得 ) 100-200 msec 数KB 1ノードあたり$700/month バッチサービング (大量 定期更新データを取得 ) 1-3 msec (サーバーキャッシュ利用時 ) 数1000 msec (通常参照時) 数10MB 軽微なストレージ料金 独自実装 オンラインサービング (少量 最新データを取得 ) (Redis開発想定) 5-10 msec 数KB M1(4GB) Standard 場合 $200/month バッチサービング (大量 定期更新データを取得 ) (データ取得プロセス開発想定 ) 1-3 msec (サーバーキャッシュ利用時 ) 100-200 msec (通常参照時) 数10MB Podに割り当てられたリ ソース 余剰部分で賄え る
© GO Inc. 今回 下記 理由でバッチサービング 独自実装を採用した • 既に特徴量 BigQueryで集約管理しているため、I/F共通化
恩恵が小さいこと • 特徴量データサイズが小さく、サーバーキャッシュに乗り切ること ◦ サーバーキャッシュに乗れ 、通信オーバーヘッドがない分オンラインサービング よりも高 に動作すること • 利用する特徴量 30分単位で更新できれ よく、バッチサービングで要件を満たせる こと • 現在 実装ベース まま開発できること 16 バッチサービング独自実装 選定理由
© GO Inc. 17 解決策 実現
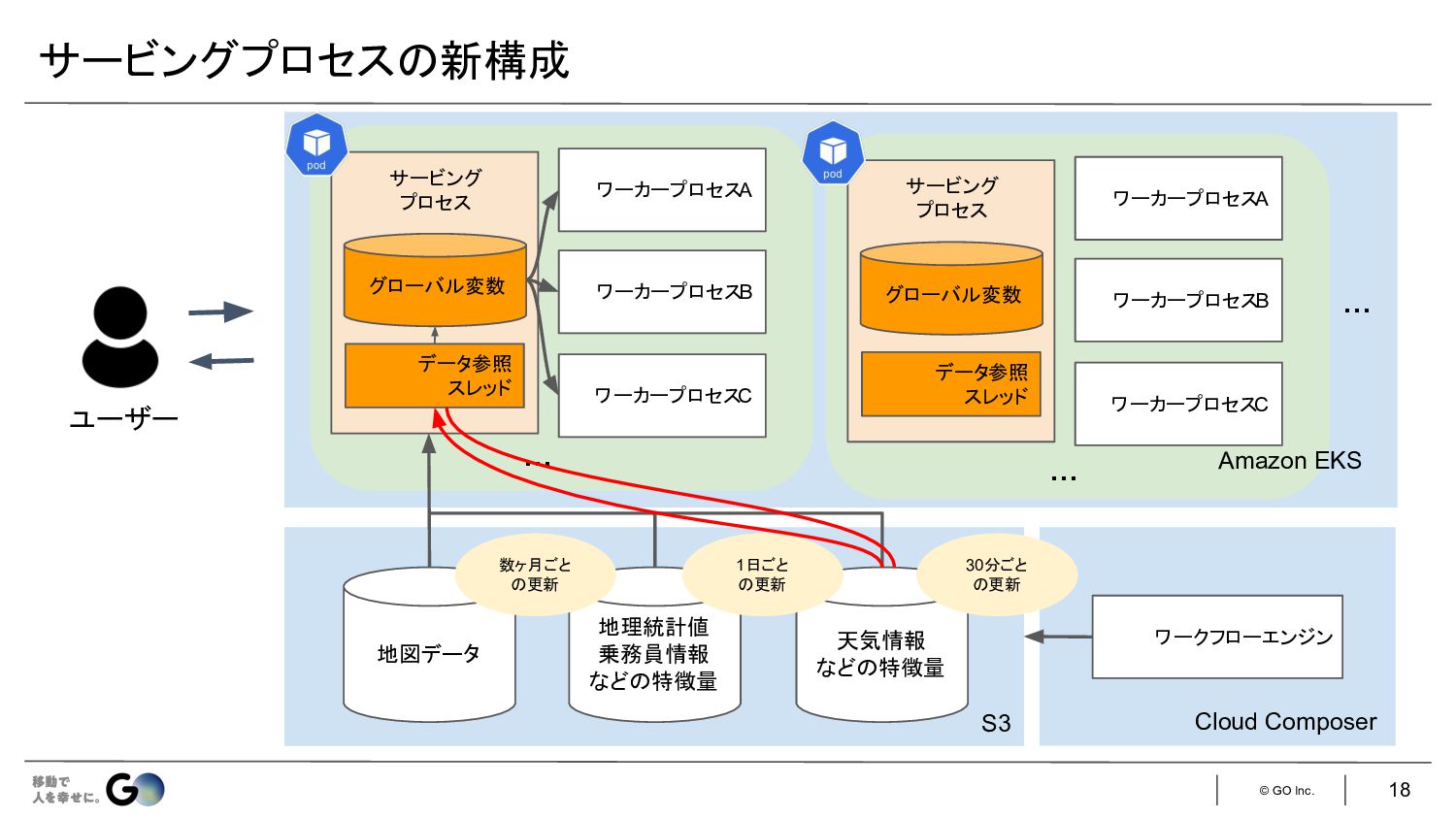
© GO Inc. サービングプロセス 新構成 18 地図データ 地理統計値 乗務員情報 など
特徴量 天気情報 など 特徴量 数ヶ月ごと 更新 1日ごと 更新 ワーカープロセスA ワーカープロセスB ワーカープロセスC … … … 30分ごと 更新 ワークフローエンジン Cloud Composer サービング プロセス グローバル変数 データ参照 スレッド ユーザー S3 ワーカープロセスA ワーカープロセスB ワーカープロセスC サービング プロセス グローバル変数 データ参照 スレッド Amazon EKS …
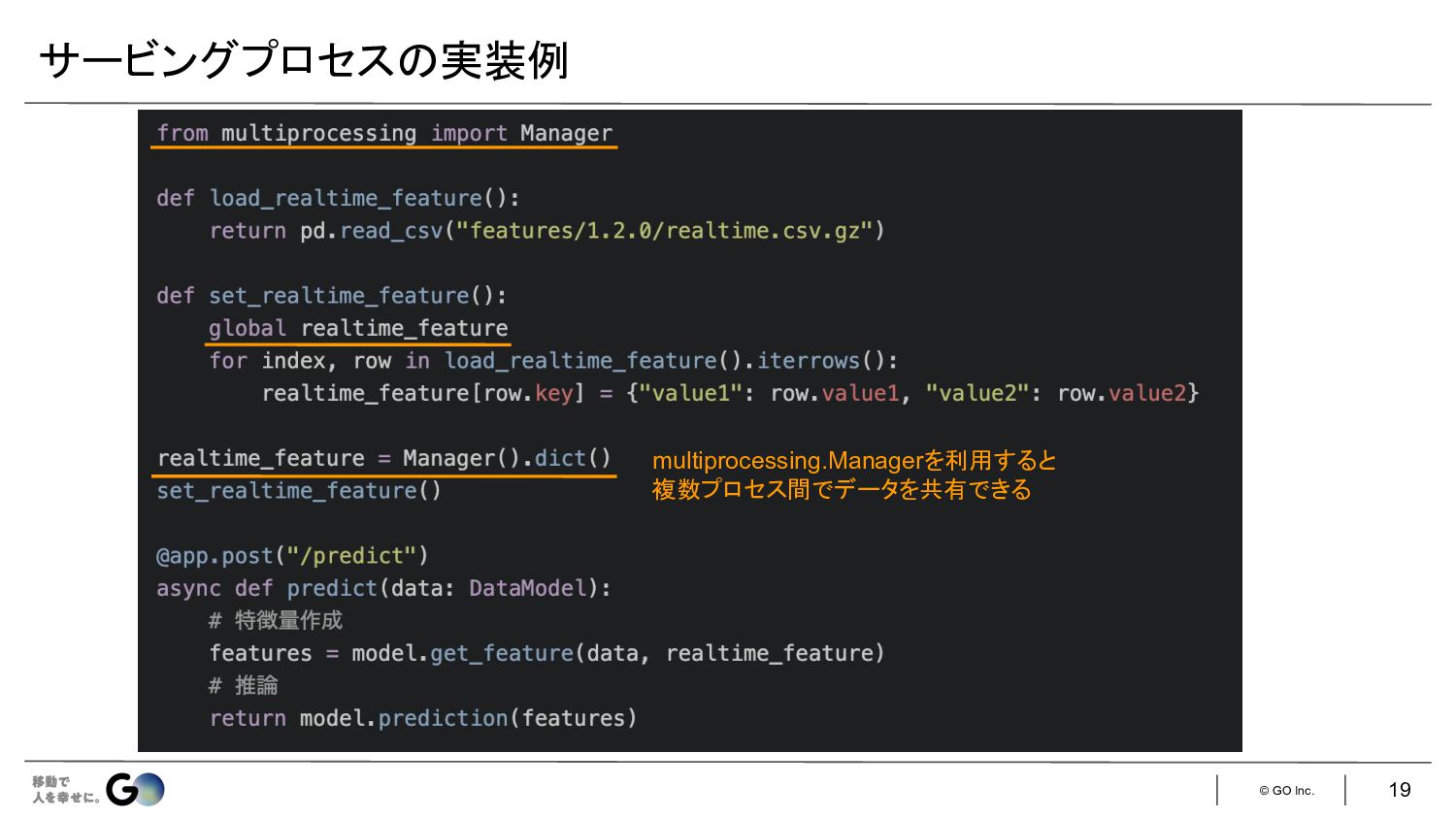
© GO Inc. 19 サービングプロセス 実装例 multiprocessing.Managerを利用すると 複数プロセス間でデータを共有できる
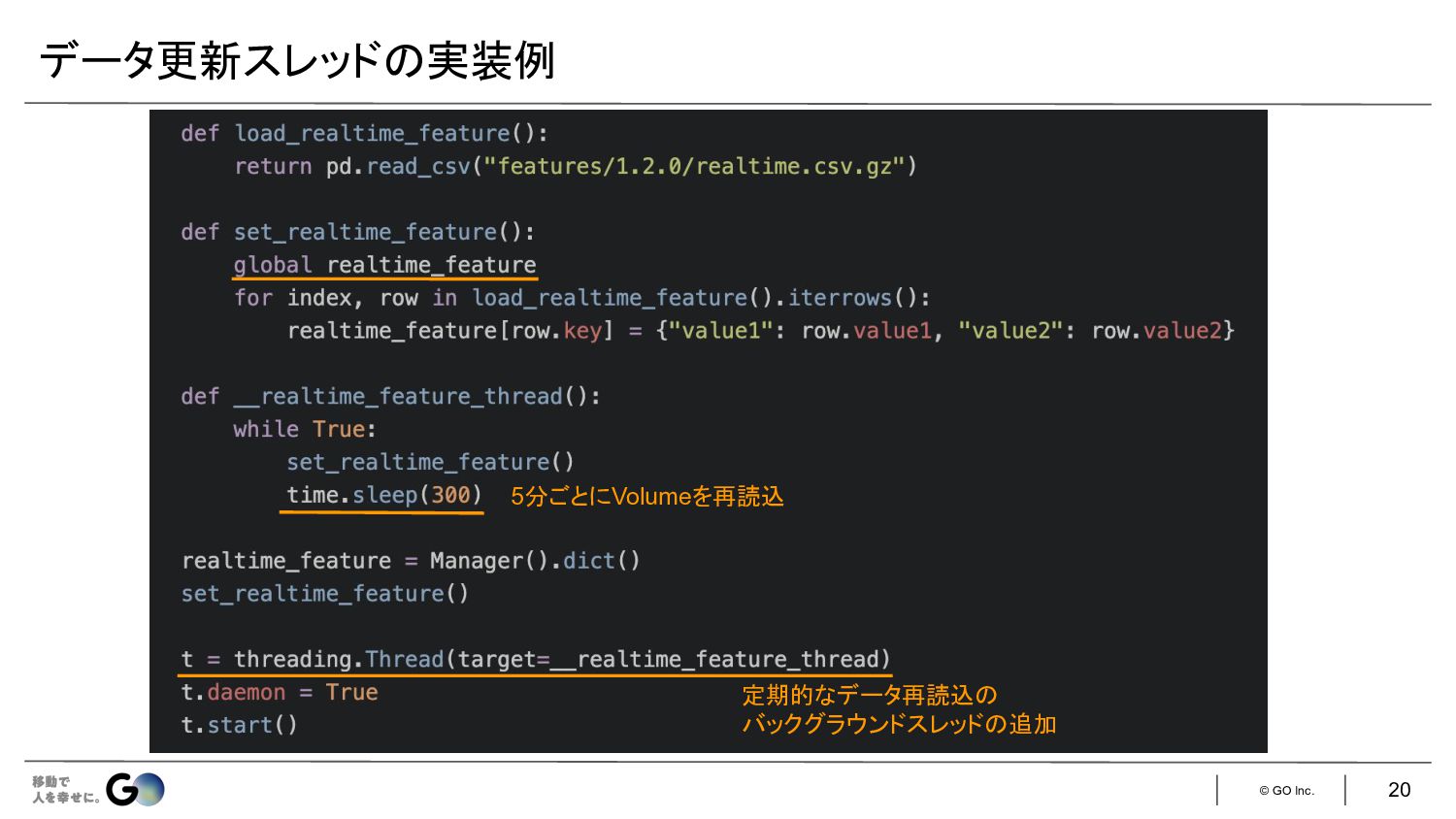
© GO Inc. 20 データ更新スレッド 実装例 定期的なデータ再読込 バックグラウンドスレッド 追加 5分ごとにVolumeを再読込
© GO Inc. 特徴量 バージョン管理 • データ 後方互換性がなくなるタイミングでデータファイル バージョンを変更し、モデルで デー
タバージョンを指定して処理することで、新旧両方 データを扱える ◦ 例)features/1.1.0/realtime.csv.gz -> features/1.2.0/realtime.csv.gz ◦ モデルによって違うバージョン 特徴量を利用することが可能 ◦ 後方互換性がない更新が入っても、既存 パイプライン エラーにならない • バージョン更新時 デプロイ順番に 注意 ◦ 1. Cloud Composerで新しい特徴量データ デプロイ ◦ 2. APIで利用する特徴量バージョン 更新 ◦ こ 手順を踏むことで データフォーマット変更時 エラーを回避 21 運用上 考慮点
© GO Inc. 今回 ニアリアルタイム特徴量 提供に 、バッチサービング独自実装を採用 • オンラインサービングやFeature Storeを利用するメリットが小さかったため見送り
• オンラインサービングと比較して低レイテンシで特徴量を提供可能 • 複数プロセスを起動するAPIで 、サービングプロセスを利用して各プロセスでデータを共有 • 定期的なデータ更新スレッドを利用して、データ 再読み込み 特徴量管理 工夫 • バージョン管理を導入することで、モデルごとに違うバージョン 特徴量を利用可能 22 まとめ
文章・画像等 内容 無断転載及び複製等 行為 ご遠慮ください。 © GO Inc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}