Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Optuna on Kubeflow Pipeline 分散ハイパラチューニング
Search
Takashi Suzuki
June 26, 2021
Technology
59
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Optuna on Kubeflow Pipeline 分散ハイパラチューニング
2021/6/26に実施されたOptuna Meetupの登壇資料
Takashi Suzuki
June 26, 2021
More Decks by Takashi Suzuki
See All by Takashi Suzuki
到着予想時間サービスの特徴量のニアリアルタイム化
t24kc
0
210
Kubernetes超入門
t24kc
0
270
AI予約サービスのMLOps事例紹介
t24kc
0
47
MLプロジェクトのリリースフローを考える
t24kc
0
25
GOの機械学習システムを支えるMLOps事例紹介
t24kc
0
160
GOの実験環境について
t24kc
0
46
MOVの機械学習システムを支えるMLOps実践
t24kc
0
48
タクシー×AIを支えるKubernetesとAIデータパイプラインの信頼性の取り組みについて
t24kc
0
59
MOV お客さま探索ナビの GCP ML開発フローについて
t24kc
0
31
Other Decks in Technology
See All in Technology
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
160
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
1.1k
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
530
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
6
720
数値で見る Microsoft MVP 〜Spec Kit と GitHub Copilot Agent で作るデータ可視化ダッシュボード〜
yutakaosada
0
140
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
2
590
セキュリティ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
180
20260720_クラウド女子会×PyLadiesTokyoコラボ Amazon Bedrock ハンズオン用資料
yuuka51
2
120
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
1.2k
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
220
AI工学特論: MLOps・継続的評価
asei
10
2.3k
Featured
See All Featured
Abbi's Birthday
coloredviolet
3
8.8k
A Soul's Torment
seathinner
6
3.1k
Balancing Empowerment & Direction
lara
6
1.2k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Side Projects
sachag
455
43k
The browser strikes back
jonoalderson
0
1.4k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
160
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Designing for Timeless Needs
cassininazir
1
400
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.9k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Transcript
Mobility Technologies Co., Ltd. 開発本部 AI技術開発部 MLエンジニアリンググループ 鈴木 隆史 Optuna
on Kubeflow Pipeline 分散ハイパラチューニング
Mobility Technologies Co., Ltd. 自己紹介 2 鈴木 隆史 | Takashi
Suzuki 開発本部 AI技術開発部 MLエンジニアリンググループ • 2019年DeNA入社 機械学習の実験基盤やパイプラインの設計開発を担当 • 2020年Mobility Technologies転籍
Mobility Technologies Co., Ltd. 3
Mobility Technologies Co., Ltd. 4
Mobility Technologies Co., Ltd. OptunaとKubeflow Pipelineを用いた - 並列ハイパラチューニングのシステムフロー - コードベースの解説
をお話します 今日話すこと 5
Mobility Technologies Co., Ltd. 導入背景 01 6
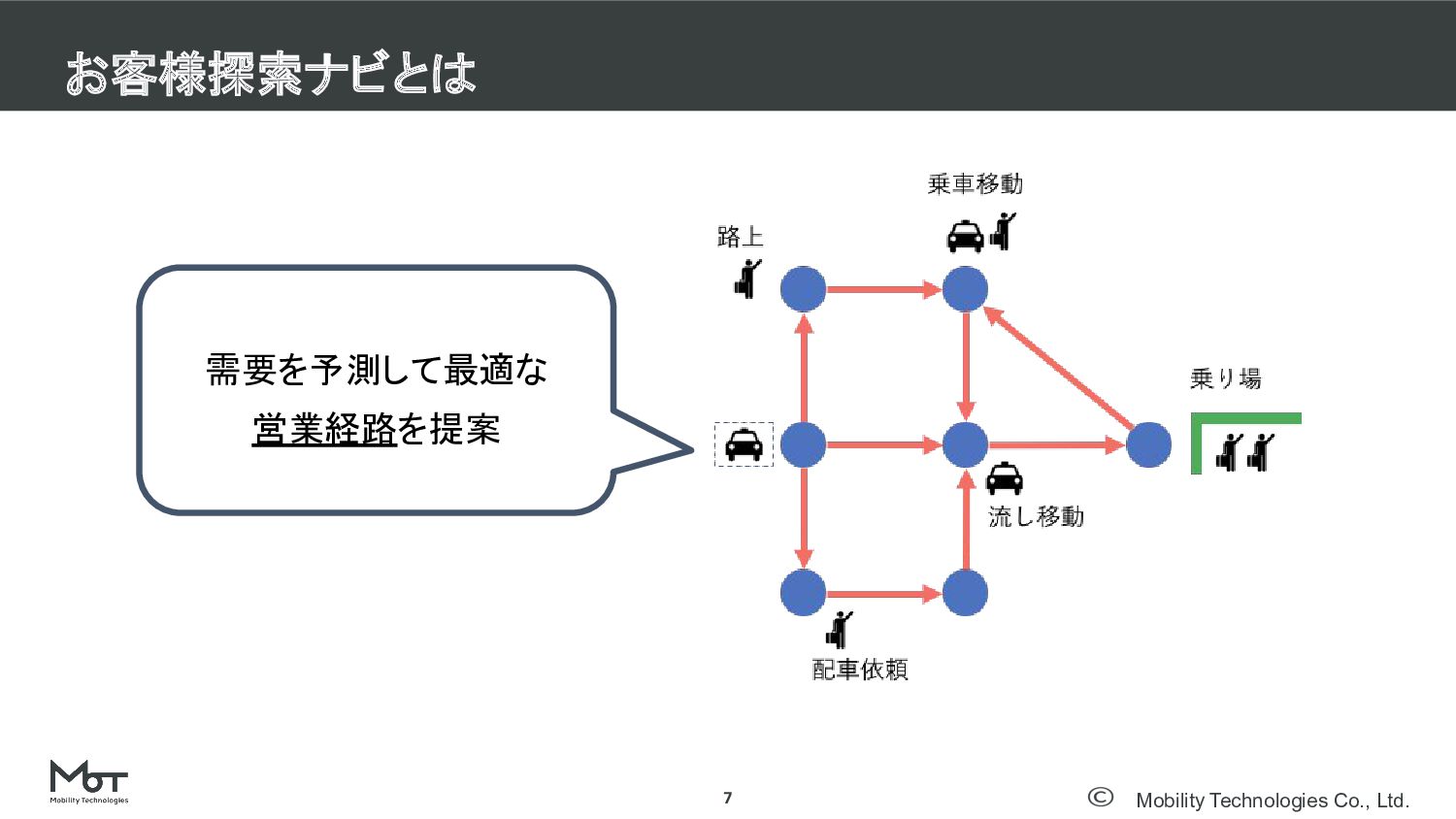
Mobility Technologies Co., Ltd. お客様探索ナビとは 7 需要を予測して最適な 営業経路を提案
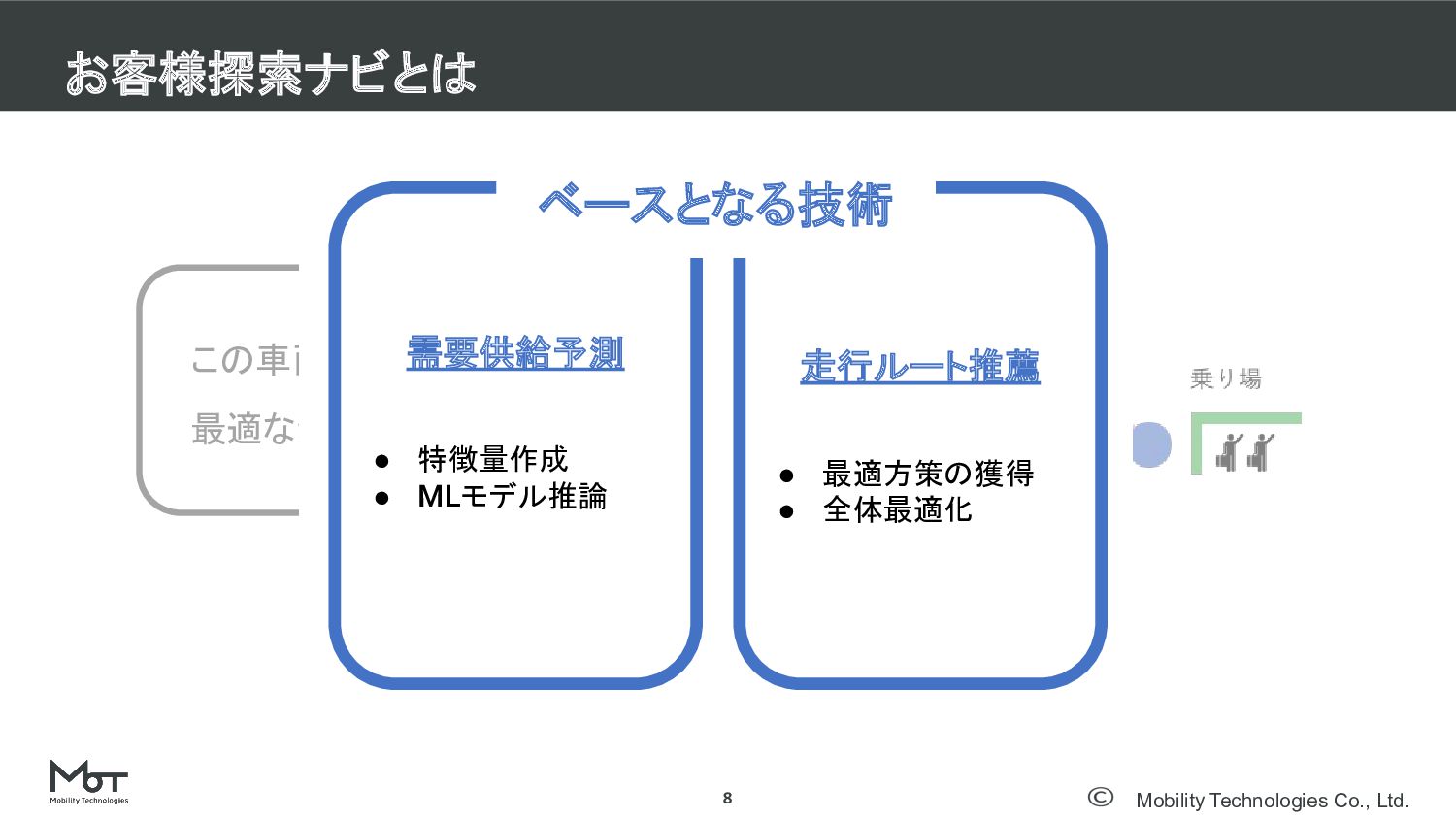
Mobility Technologies Co., Ltd. お客様探索ナビとは 8 この車両にとって 最適な走行経路は何か? 需要供給予測 •
特徴量作成 • MLモデル推論 走行ルート推薦 • 最適方策の獲得 • 全体最適化 ベースとなる技術
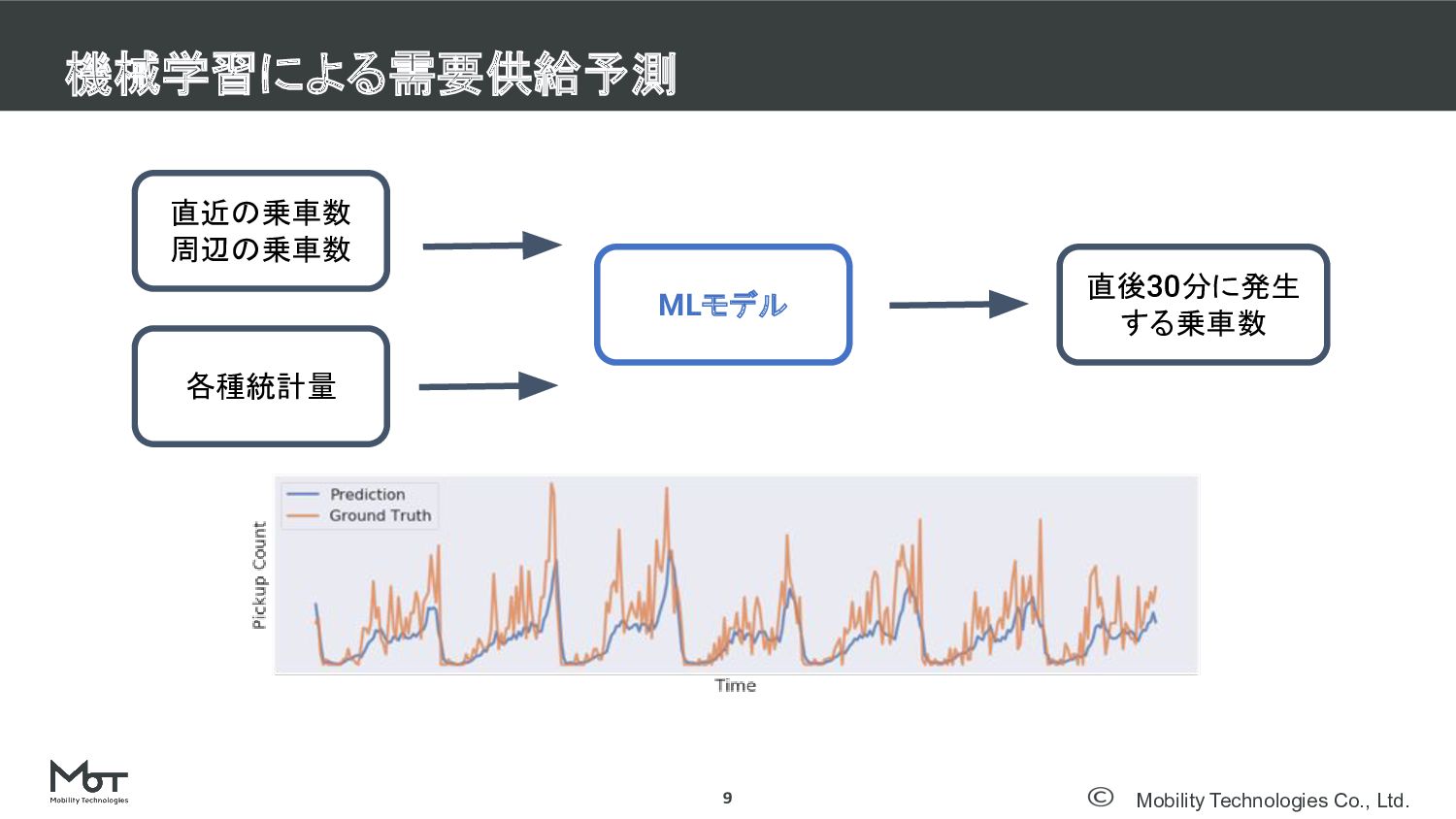
Mobility Technologies Co., Ltd. 機械学習による需要供給予測 9 直近の乗車数 周辺の乗車数 各種統計量 MLモデル
直後30分に発生 する乗車数
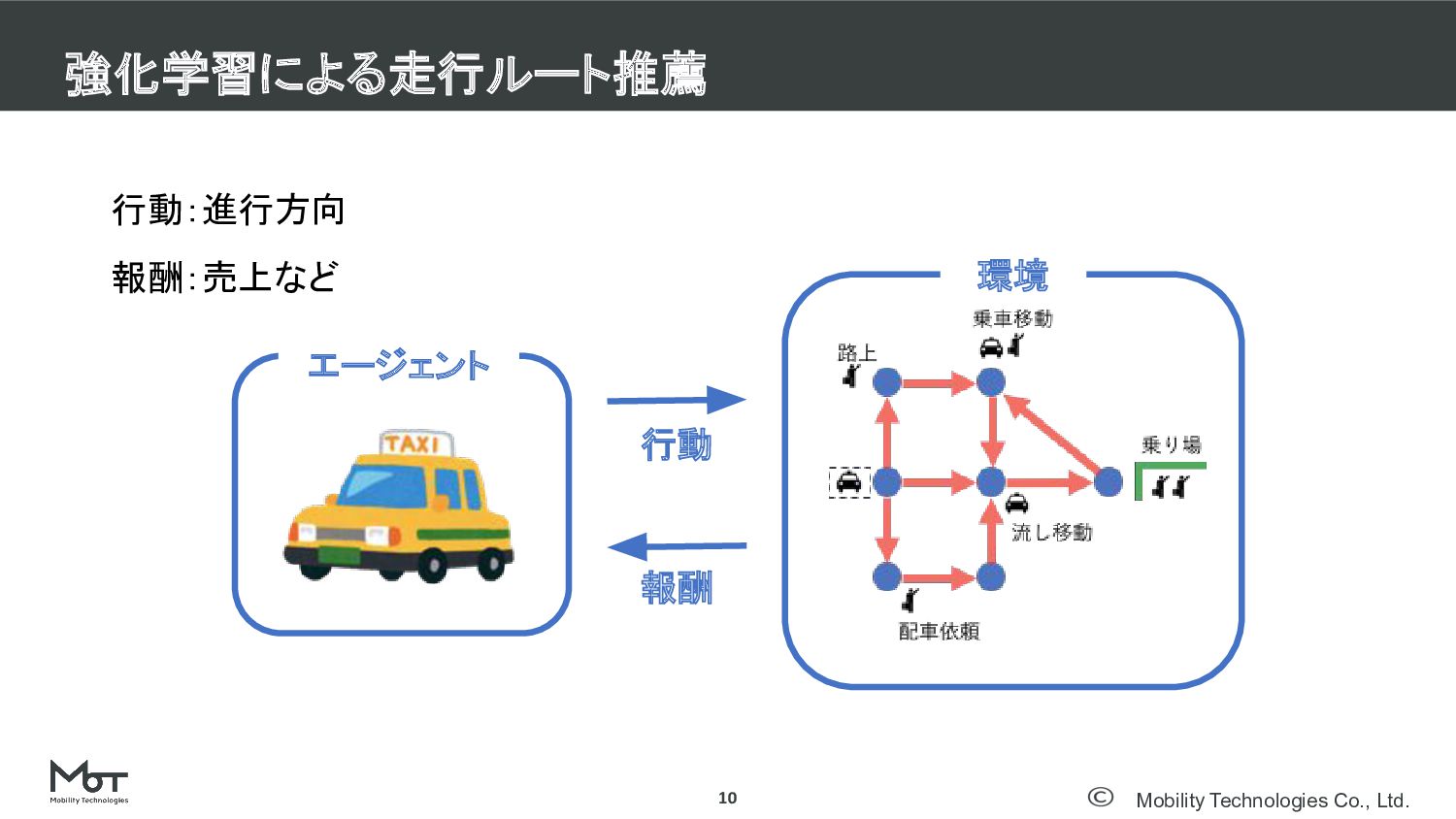
Mobility Technologies Co., Ltd. 強化学習による走行ルート推薦 10 行動:進行方向 報酬:売上など 報酬 行動
環境 エージェント
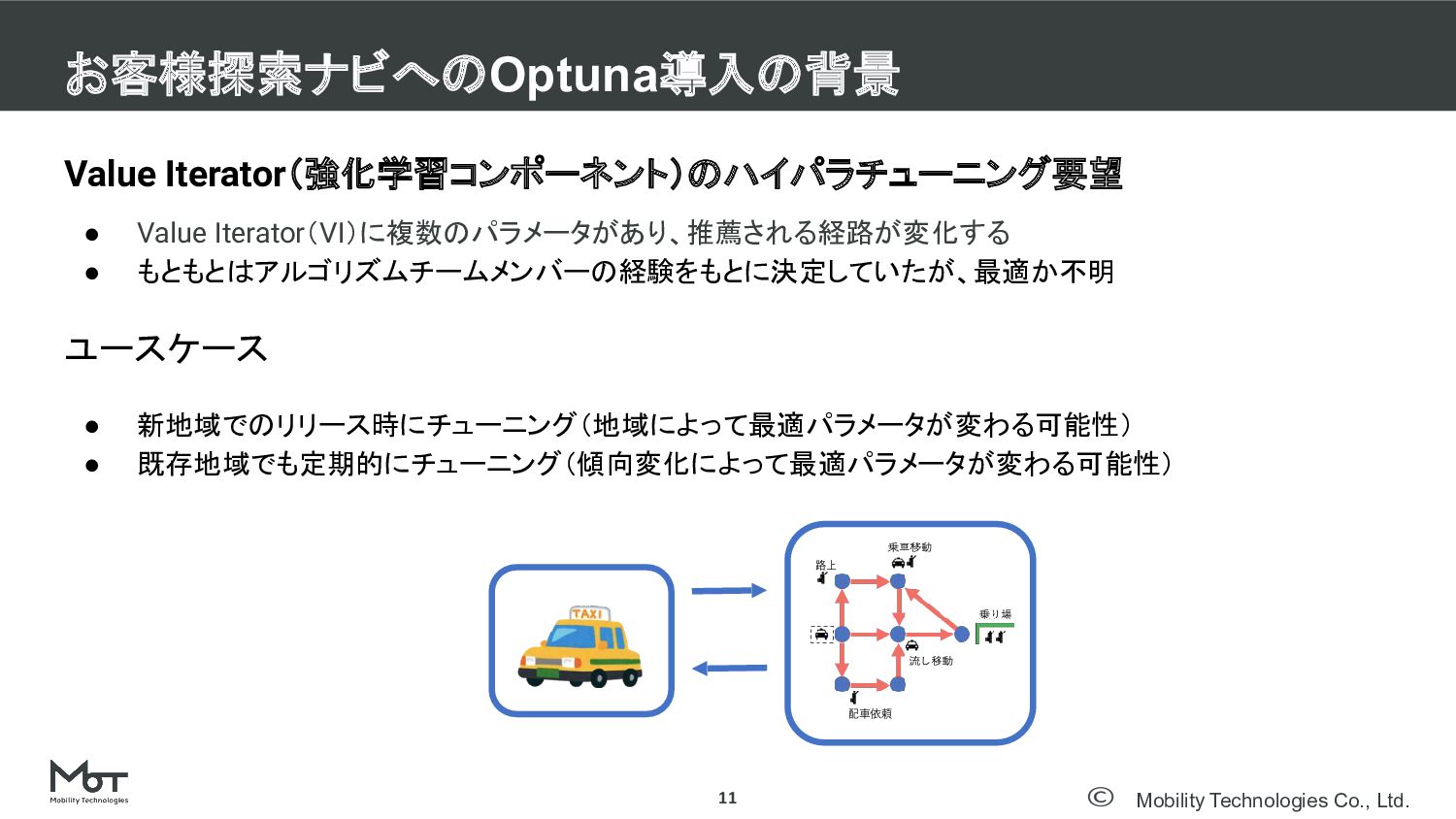
Mobility Technologies Co., Ltd. Value Iterator(強化学習コンポーネント)のハイパラチューニング要望 • Value Iterator(VI)に複数のパラメータがあり、推薦される経路が変化する •
もともとはアルゴリズムチームメンバーの経験をもとに決定していたが、最適か不明 ユースケース • 新地域でのリリース時にチューニング(地域によって最適パラメータが変わる可能性) • 既存地域でも定期的にチューニング(傾向変化によって最適パラメータが変わる可能性) お客様探索ナビへのOptuna導入の背景 11
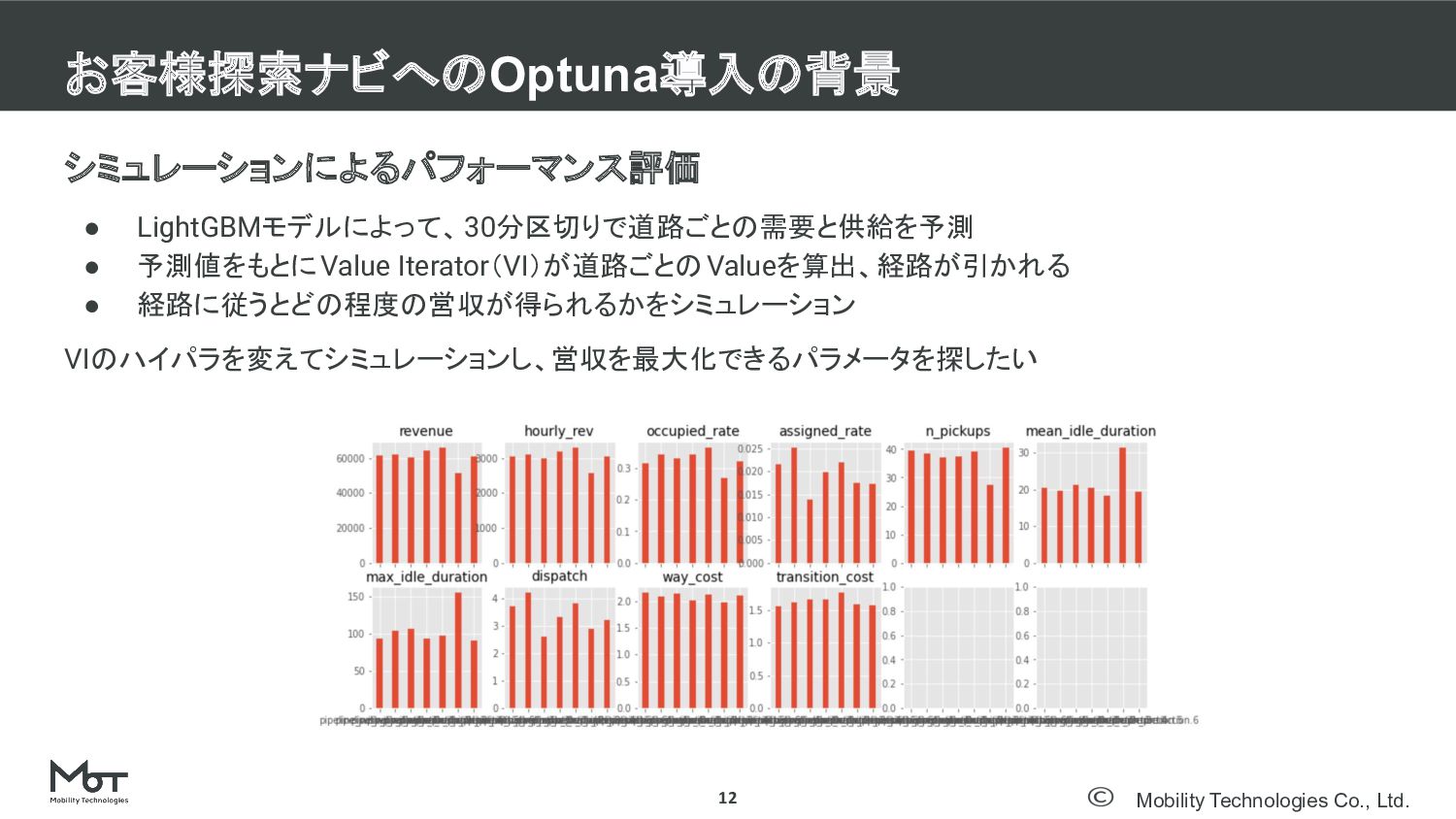
Mobility Technologies Co., Ltd. シミュレーションによるパフォーマンス評価 • LightGBMモデルによって、30分区切りで道路ごとの需要と供給を予測 • 予測値をもとにValue Iterator(VI)が道路ごとのValueを算出、経路が引かれる
• 経路に従うとどの程度の営収が得られるかをシミュレーション VIのハイパラを変えてシミュレーションし、営収を最大化できるパラメータを探したい お客様探索ナビへのOptuna導入の背景 12
Mobility Technologies Co., Ltd. Optuna on Kubeflow Pipeline システムフロー 02
13
Mobility Technologies Co., Ltd. • “The Machine Learning Toolkit for
Kubernetes”(公式サイトより) • 機械学習のサイクルをKubernetes上で実行するためのOSSツール群 Kubeflowについて 14 IUUQT://XXX.LVCFqPX.PSH/EPDT/TUBSUFE/LVCFqPX-PWFSWJFX/
Mobility Technologies Co., Ltd. 機械学習の実験に特化したワークフローエンジン • 可視化:タスクごとのInputやOutputや出力されたJupyter Notebook、Confusion Matrix等も可視化可能 •
パラメータ比較:Experimentsの実験実行ごとの一覧性が高く、使用したパラメータ値の比較がしやすい • Experiments:実験ごとにパイプラインを用意し、入力パラメータを変更して実行までワンタッチで実行 Kubeflow Pipeline(KFP)について 15
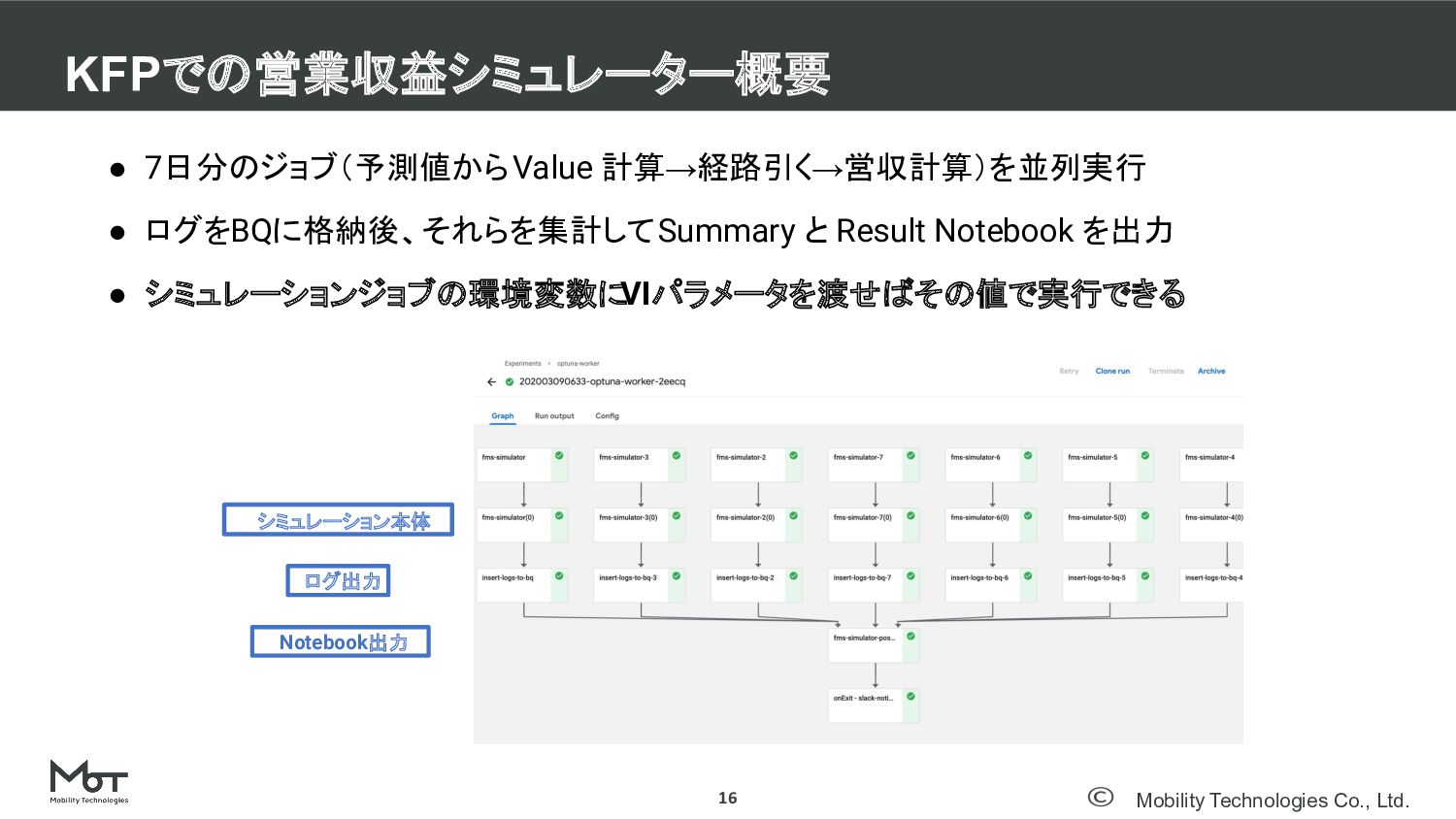
Mobility Technologies Co., Ltd. • 7日分のジョブ(予測値から Value 計算→経路引く→営収計算)を並列実行 • ログをBQに格納後、それらを集計して
Summary と Result Notebook を出力 • シミュレーションジョブの環境変数に VIパラメータを渡せばその値で実行できる KFPでの営業収益シミュレーター概要 16 シミュレーション本体 ログ出力 Notebook出力
Mobility Technologies Co., Ltd. チューニングコード概要 17 import optuna 1試行ごとに行いたい処理 DeNA
TechCon 2020 #denatechcon def objective(trial): # 1. VI parameterをsuggest # 2. そのparameterでsimulation jobをdeploy # 3. 終了後、営収値を集計 return 営業収益値 study = optuna.create_study(direction="maximize") study.optimize(objective, n_trials=100, n_jobs=5) 営収なのでmaximize, 試行数100, 並列実行数5
Mobility Technologies Co., Ltd. Trial, Study情報の格納する場所 • InMemoryStorage ◦ 特に指定しなければこれ
◦ Trial結果の永続化ができないが、ローカルリソースのみでチューニングなら OK • RDBStorage ◦ MySQL, PostgreSQL, SQLite が使える ◦ Study, Trial のログが残る。分散最適化ならこちら ◦ チューニングの中断・再開ができたり、可視化ができたり何かと便利 Optuna ストレージ選択 18
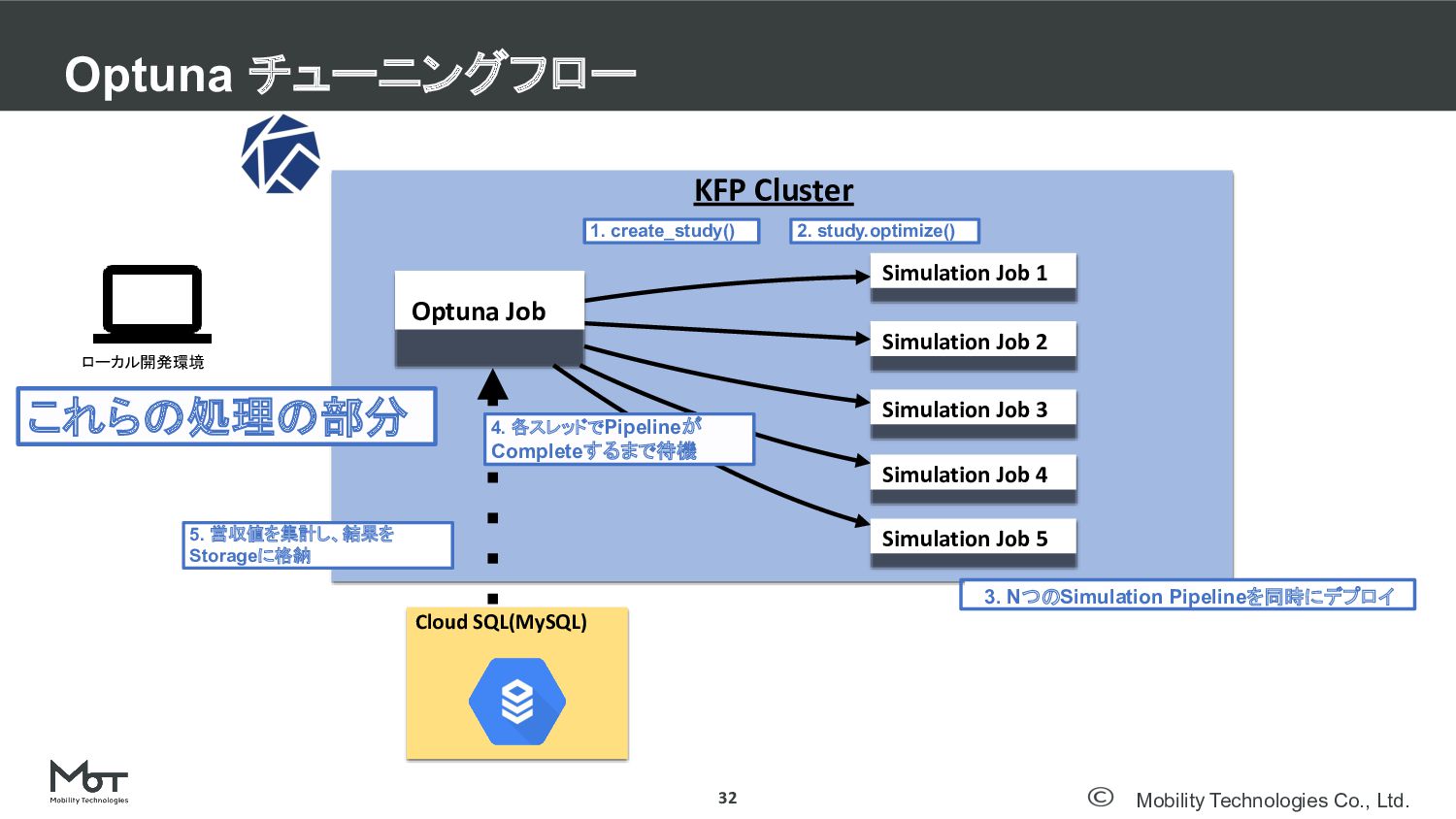
Mobility Technologies Co., Ltd. Optuna チューニングフロー 19 DeNA TechCon 2020
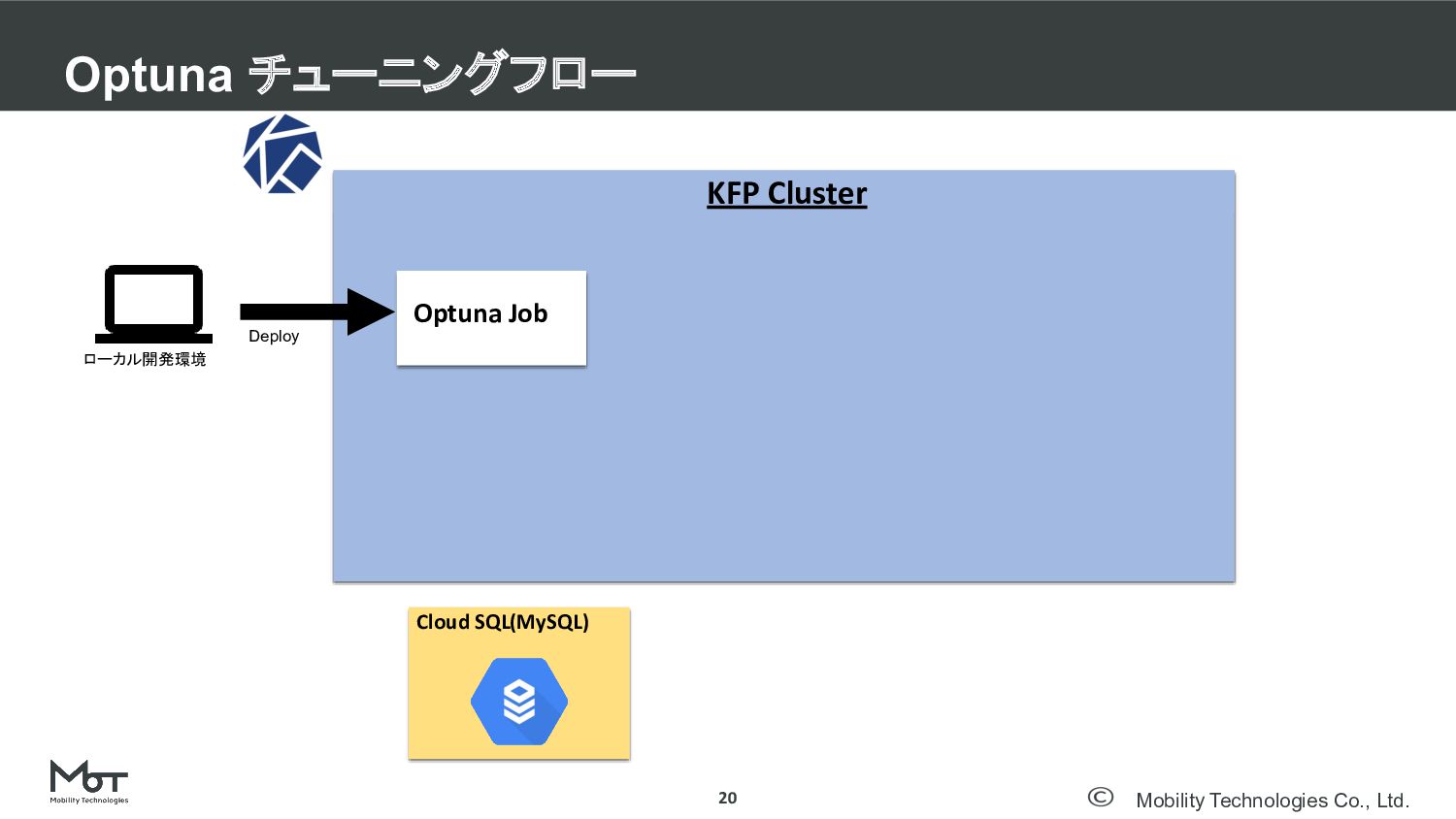
#denatechcon KFP Cluster Cloud SQL(MySQL) ローカル開発環境 Storage永続化のためにCloudSQLを用意
Mobility Technologies Co., Ltd. Optuna チューニングフロー 20 KFP Cluster Optuna
Job Cloud SQL(MySQL) Deploy ローカル開発環境
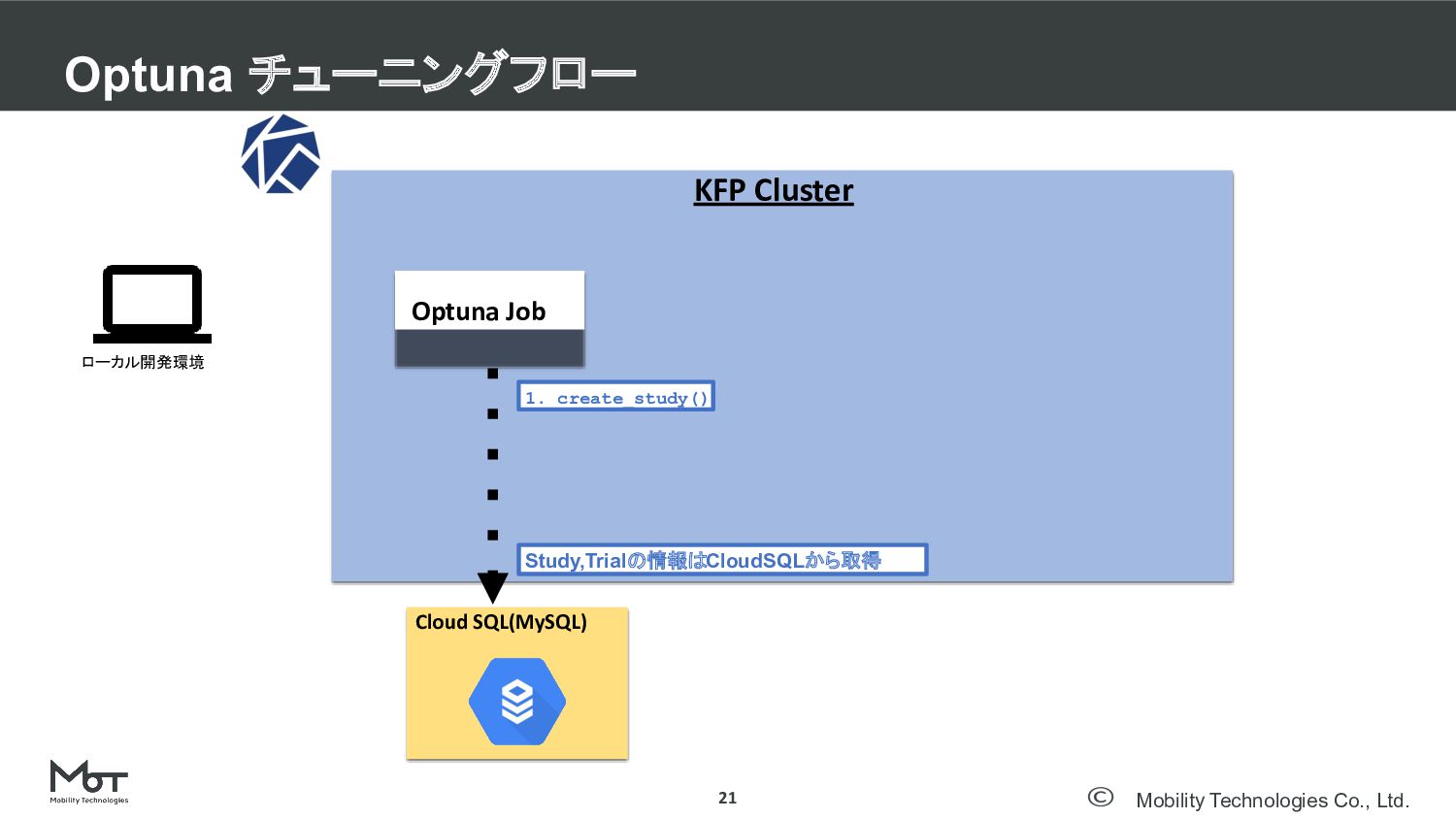
Mobility Technologies Co., Ltd. Optuna チューニングフロー 21 DeNA TechCon 2020
#denatechcon KFP Cluster Optuna Job Cloud SQL(MySQL) ローカル開発環境 1. create_study() Study,Trialの情報はCloudSQLから取得
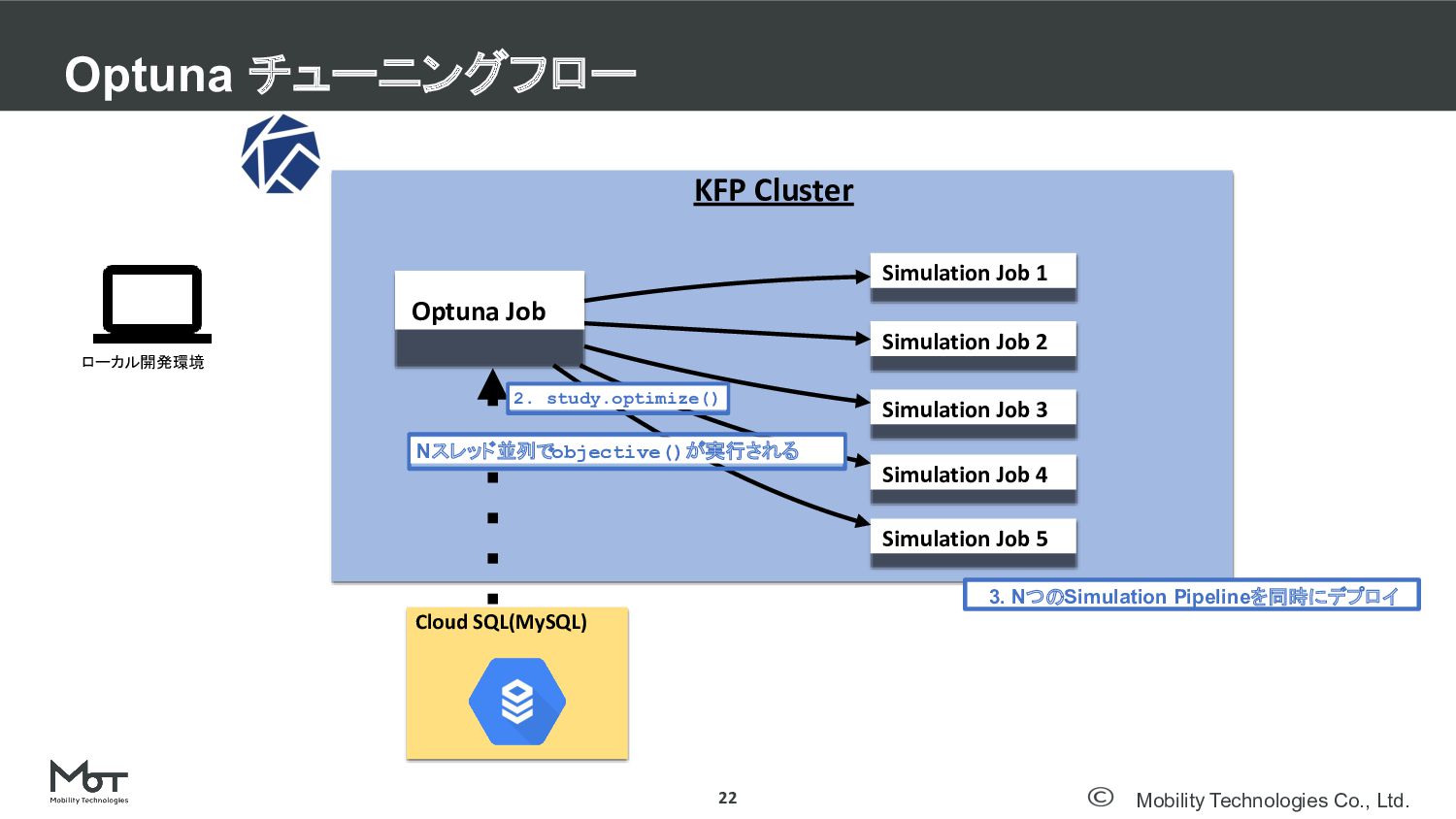
Mobility Technologies Co., Ltd. Optuna チューニングフロー 22 DeNA TechCon 2020
#denatechcon KFP Cluster Optuna Job Cloud SQL(MySQL) ローカル開発環境 Simulation Job 1 Simulation Job 2 Simulation Job 3 Simulation Job 4 Simulation Job 5 2. study.optimize() 3. NつのSimulation Pipelineを同時にデプロイ Nスレッド並列でobjective()が実行される
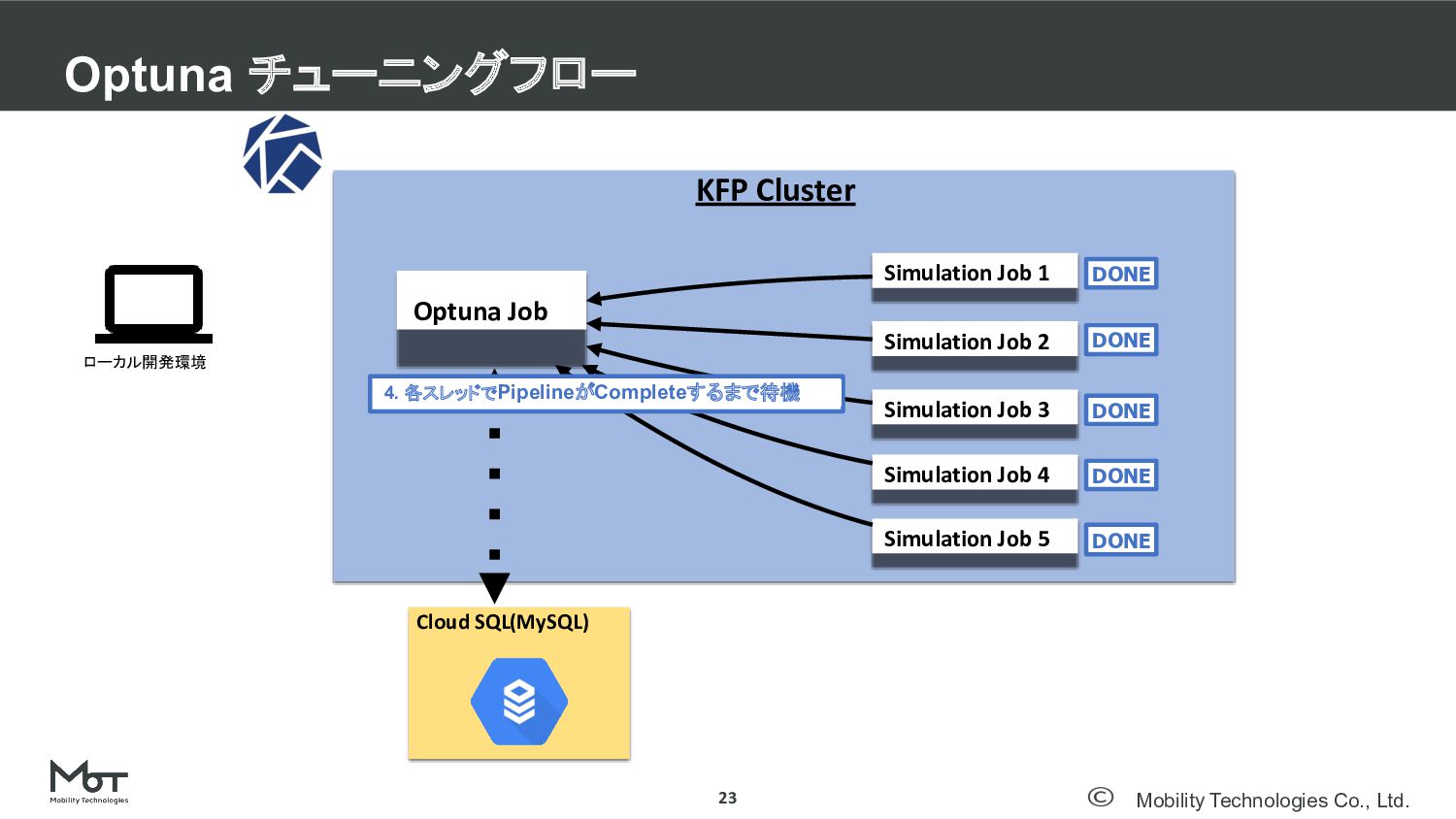
Mobility Technologies Co., Ltd. Optuna チューニングフロー 23 DeNA TechCon 2020
#denatechcon KFP Cluster Optuna Job Cloud SQL(MySQL) ローカル開発環境 Simulation Job 1 Simulation Job 2 Simulation Job 3 Simulation Job 4 Simulation Job 5 DONE DONE DONE DONE DONE 4. 各スレッドでPipelineがCompleteするまで待機
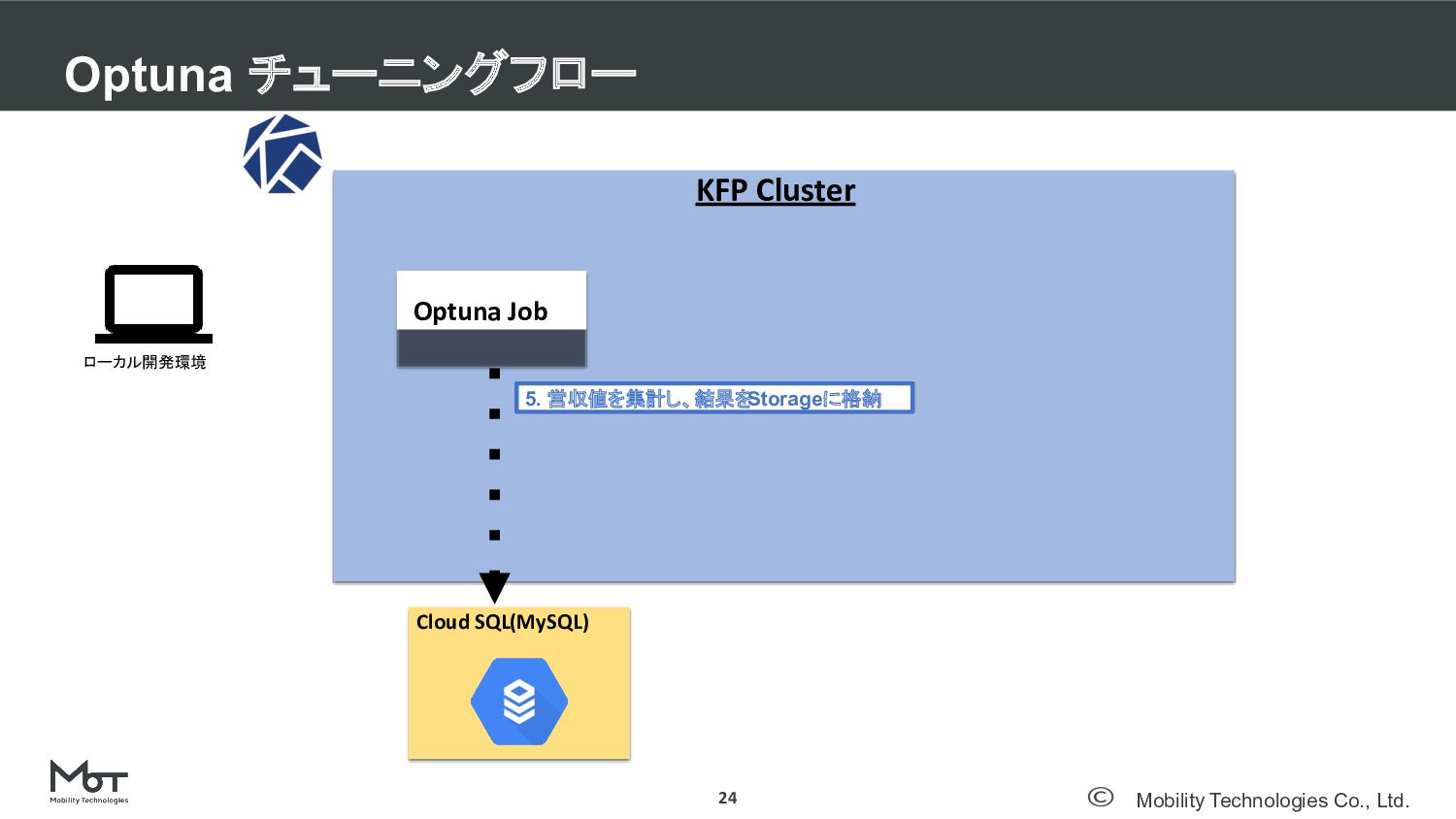
Mobility Technologies Co., Ltd. Optuna チューニングフロー 24 DeNA TechCon 2020
#denatechcon KFP Cluster Optuna Job Cloud SQL(MySQL) ローカル開発環境 5. 営収値を集計し、結果を Storageに格納
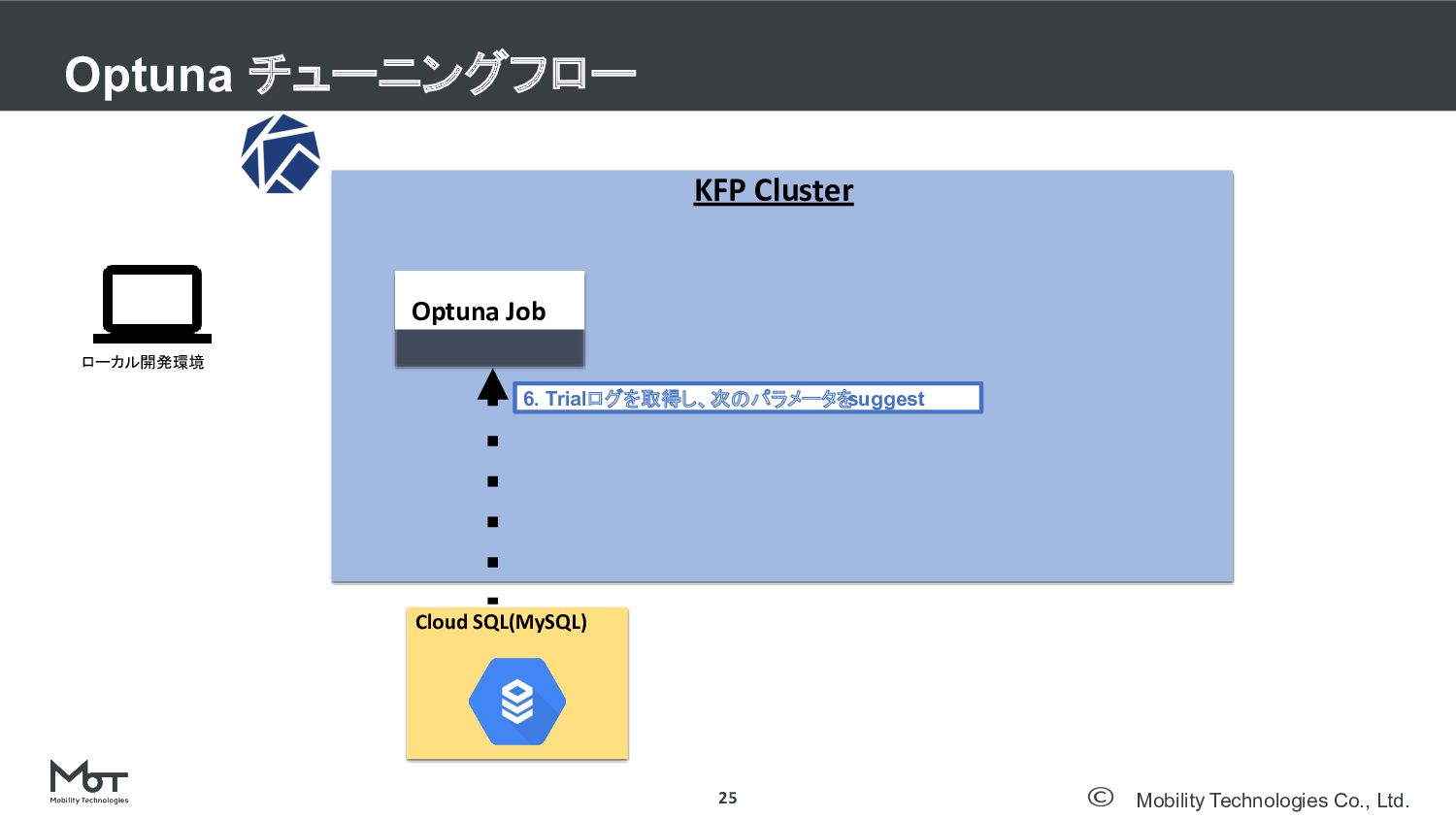
Mobility Technologies Co., Ltd. Optuna チューニングフロー 25 KFP Cluster Optuna
Job Cloud SQL(MySQL) ローカル開発環境 6. Trialログを取得し、次のパラメータを suggest
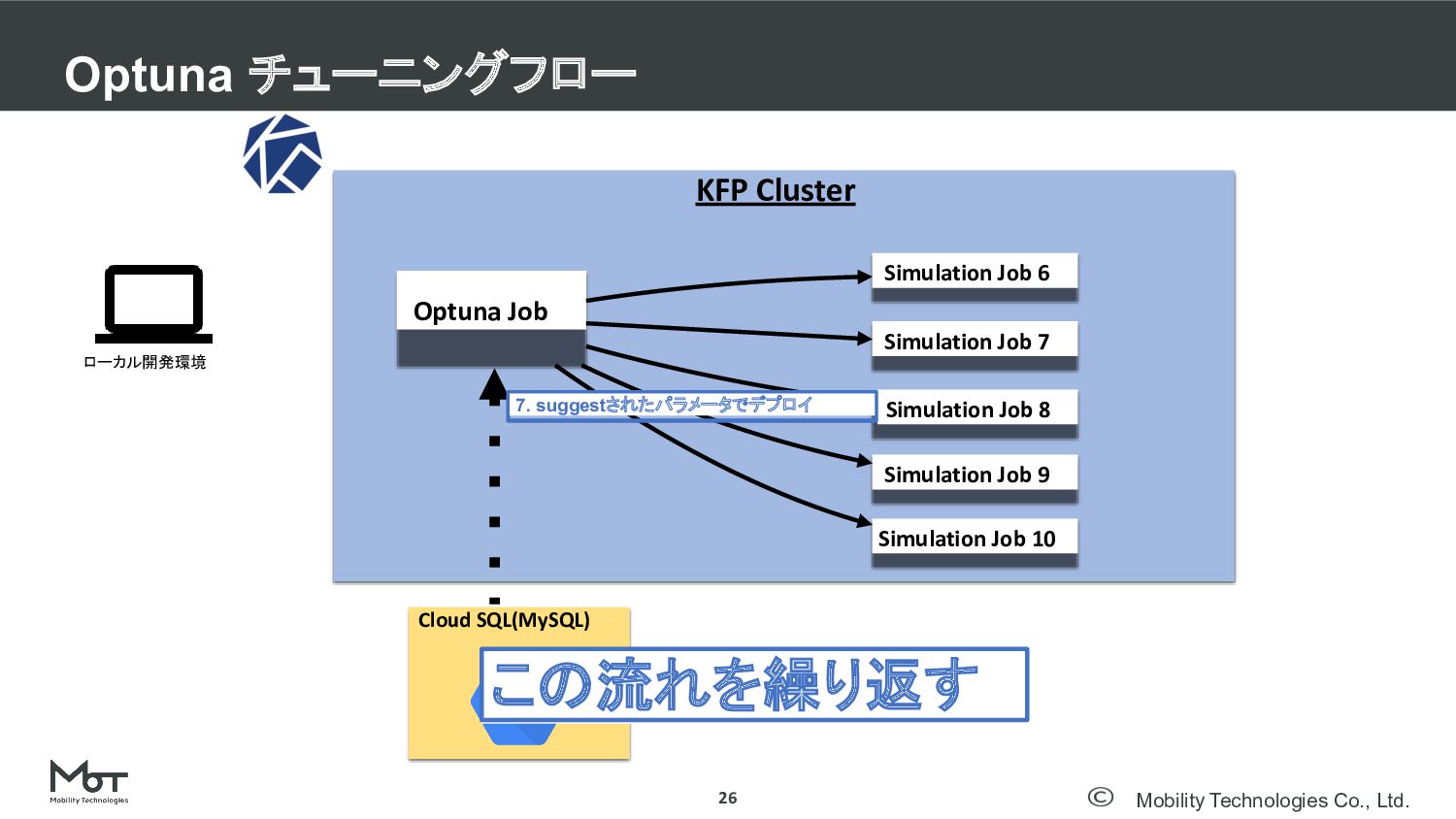
Mobility Technologies Co., Ltd. Optuna チューニングフロー 26 DeNA TechCon 2020
#denatechcon KFP Cluster Optuna Job Cloud SQL(MySQL) ローカル開発環境 Simulation Job 6 Simulation Job 7 Simulation Job 8 Simulation Job 9 Simulation Job 10 7. suggestされたパラメータでデプロイ この流れを繰り返す
Mobility Technologies Co., Ltd. コードベースの解説 03 27
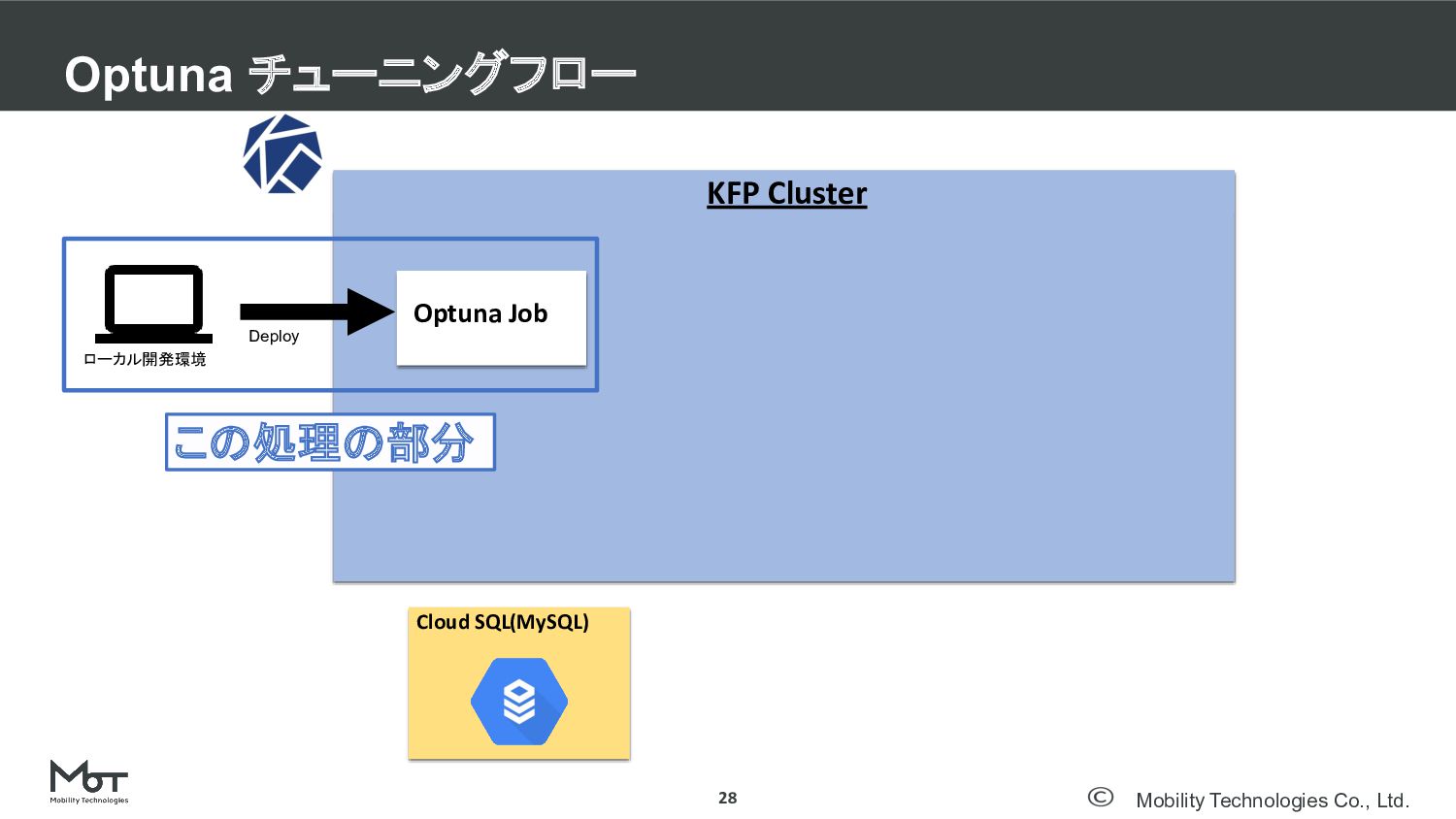
Mobility Technologies Co., Ltd. Optuna チューニングフロー 28 KFP Cluster Optuna
Job Cloud SQL(MySQL) Deploy ローカル開発環境 この処理の部分
Mobility Technologies Co., Ltd. Optuna Job のデプロイ 29 def deploy_optuna(c,
comment=None): code_id = deploy_settings(c, comment=task_name) resource_setting = format_resource_setting( c.resource_setting, settings["master_cpu"], settings["master_memory"], settings["master_node_pool"], ) pipeline = wf.create_optuna_pipeline(code_id, optuna_settings, resource_setting) wf.compile_pipeline(code_id, pipeline, pipeline_filename) return wf.run_pipeline(code_id, user, pipeline_filename) KFP Pipeline functionを生成 (次ページ) リソース指定 Pipelineデプロイ
Mobility Technologies Co., Ltd. Optuna Job のKFP Function 30 def
create_optuna_pipeline (code_id, optuna_settings , resource_setting ): @kfp.dsl.pipeline (name=code_id) def pipeline(config=json.dumps(optuna_settings)): base_url = optuna_settings[ "base_url"] msg = code_id + " is {{workflow.status }} " + base_url + "/{{workflow.uid}}" exit_task = create_slack_notification_op(msg) with dsl.ExitHandler(exit_task): create_optuna_op( code_id, optuna_settings, { "USER": "optuna-worker" }, resource_setting ) return pipeline Pipeline func デコレータ exit_taskでSlack通知 ExitHandlerで 終了時タスク指定(成功・失敗問わず) KFP Operator生成(次ページ)
Mobility Technologies Co., Ltd. Optuna Jobの KFP Operator 31 def
create_optuna_op (sim_id, optuna_settings , env_params , resource_setting ): command = [ "inv", "run-optuna" ] arguments = [ f"--settings= {json.dumps(optuna_settings) }"] op = dsl.ContainerOp( name="optuna" , image=optuna_settings[ "image"], command=command, arguments =arguments, file_outputs ={"mlpipeline-ui-metadata" : "/tmp/mlpipeline-ui-metadata.json" }, ) for k, v in env_params.items(): op.container.add_env_variable(V1EnvVar( name=k, value=v)) op = set_op_resource(op, resource_setting) sidecar = kfp.dsl.Sidecar( name="cloudsqlproxy" , image="gcr.io/cloudsql-docker/gce-proxy:1.14" , command=[ "/cloud_sql_proxy" , f"-instances={gcp_project}:us-central1:optuna=tcp:3306" , ], ) op.add_sidecar(sidecar) return op KFP Operator作成 Operatorリソース定義 SidecarにCloudSQL Proxy Imageを指定 add_sidecar() で設定可
Mobility Technologies Co., Ltd. Optuna チューニングフロー 32 KFP Cluster Optuna
Job Cloud SQL(MySQL) ローカル開発環境 Simulation Job 1 Simulation Job 2 Simulation Job 3 Simulation Job 4 Simulation Job 5 3. NつのSimulation Pipelineを同時にデプロイ 4. 各スレッドでPipelineが Completeするまで待機 2. study.optimize() 5. 営収値を集計し、結果を Storageに格納 これらの処理の部分 1. create_study()
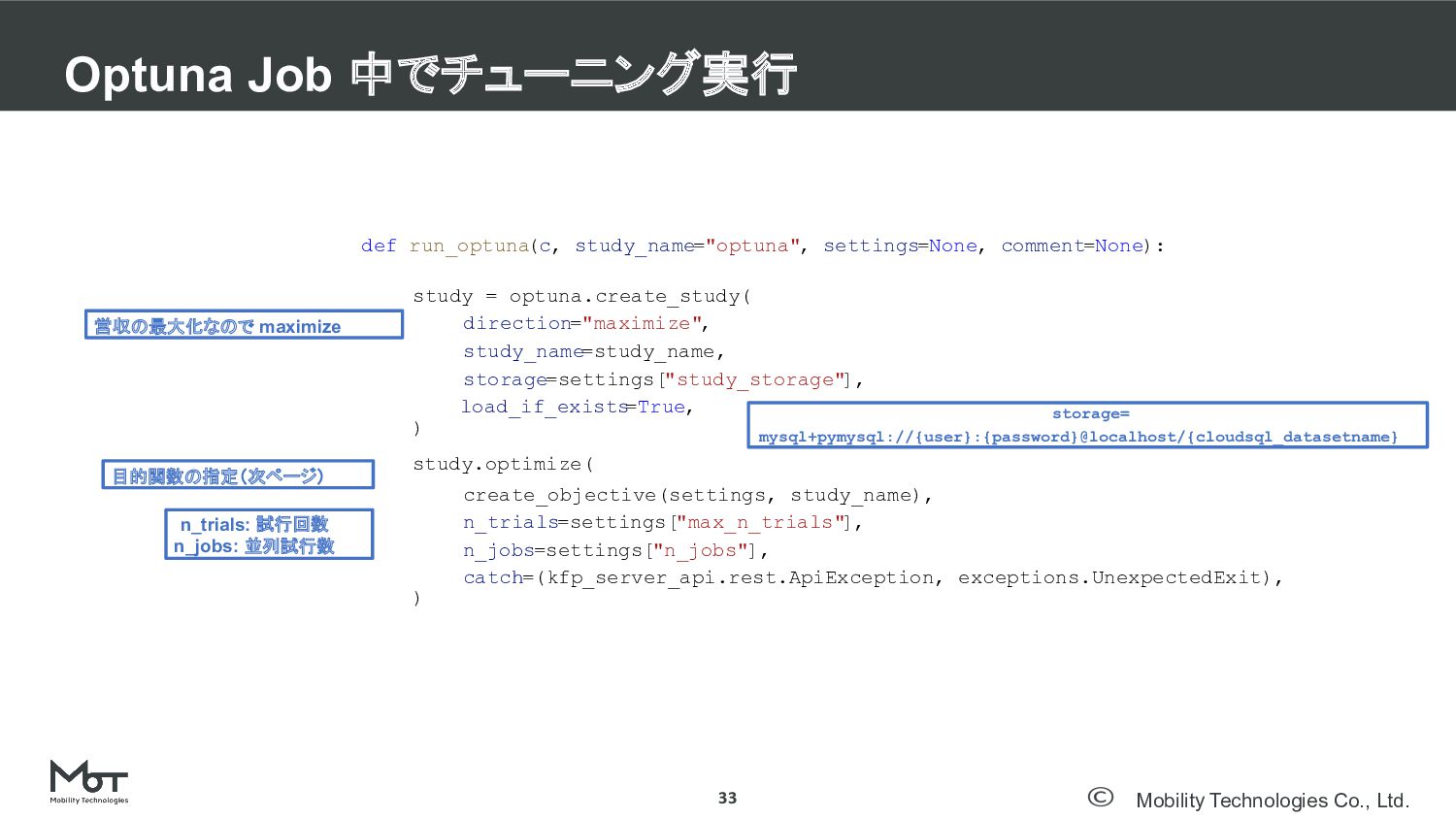
Mobility Technologies Co., Ltd. Optuna Job 中でチューニング実行 33 def run_optuna(c,
study_name="optuna", settings=None, comment=None): study = optuna.create_study( direction="maximize", study_name=study_name, storage=settings["study_storage" ], load_if_exists =True, ) study.optimize( create_objective(settings, study_name), n_trials=settings["max_n_trials" ], n_jobs=settings["n_jobs"], catch=(kfp_server_api.rest.ApiException, exceptions.UnexpectedExit), ) 営収の最大化なので maximize storage= mysql+pymysql://{user}:{password}@localhost/{cloudsql_datasetname} 目的関数の指定(次ページ) n_trials: 試行回数 n_jobs: 並列試行数
Mobility Technologies Co., Ltd. 並列Trialの中身(1) 34 def create_objective (optuna_settings ,
study_name ): def objective (trial): for k, v in optuna_settings[ "parameters" ].items(): csv_args[k] = getattr(trial, v[ "distribution" ])( v["name"], v["min_value" ], v["max_value" ] ) csv_path = f"{study_name }_{trial.trial_id }.csv" make_setting_csv(csv_path, **csv_args) completed_trials = len( [ trial.state for trial in trial.study.trials if trial.state == optuna.structs.TrialState.COMPLETE ] ) if completed_trials >= settings[ "n_trials" ]: logger.info ("Number of completed trials:" , str(completed_trials)) logger.info ("Best trial:" , trial.study.best_trial) return 指定した分布ごとに parameterをsuggest (内部で過去Trialのログを参照) パラメータの探索範囲は configに持っている (LightGBMTuner使えば決めなくていい) シミュレーション用の設定ファイル作成 正常に終了したシミュレーションジョブ数を集計 (シミュレーションジョブが稀に死ぬため)
Mobility Technologies Co., Ltd. 並列Trialの中身(2) 35 code_id, pipeline_filename = run(
c, csv_path =csv_path, days=settings[ "days"], memory=settings[ “worker_memory" ], build_only =True, ) run_result = wf.run_pipeline(code_id, user, pipeline_filename) run_name = wf.wait_for_simulation_completion(run_result) bqla = BigQueryLogAnalyzer(run_name) summary, metrics_cols = bqla.create_summary( cost_table =settings[ "cost_table" ] ) summary_mean = summary.groupby( "config_id" )[metrics_cols].mean() return float(summary_mean.revenue) シミュレーションジョブが完了するまで待機 BQからシミュレーションのログを抽出し営収を集計 (既存機能) 結果の営収値を返す シミュレーションのPipeline Function作成 (既存機能)
Mobility Technologies Co., Ltd. 実験と評価 04 36
Mobility Technologies Co., Ltd. • Trial数: 100(最大Trial数は150, 50回までのfailを許容) • 並列Trial数:
5 • 探索パラメータ ◦ GAMMA(割引率): loguniform, 0.80-0.99 ◦ WAY_COST_WEIGHT(道路コスト重み): loguniform, 0.01-0.20 ◦ MAX_WAITING_TIME(最大許容待ち時間): int, 250-350 実験設定 37
Mobility Technologies Co., Ltd. 実験評価 38 • 特定期間でシミュレーションでハイパラチューニング • 特定期間のみに適応していないか確認のため、以降の期間の営収値を比較
◦ 新旧パラメータ x MLモデル/統計値の4パターン • 評価結果 ◦ MLモデルは平均して営業収益が 1.4%上昇 ◦ 統計値は平均して営業収益が 2.2%上昇 ◦ アルゴリズムの改善施策と同等の上昇幅 • その後QAで実際にひかける経路も問題ないため、本番へリリース済み
Mobility Technologies Co., Ltd. まとめ 05 39
Mobility Technologies Co., Ltd. 必要な情報が揃っている • Study や Trial Object
から、これまで行った試行情報や、最もパフォーマンスが良かった情報が取得できる • 目的関数の細かい処理やチューニング後の分析がしやすい クラウドコンポーネントとの組み合わせで時短可能 • ローカル環境でのチューニングも十分に便利だが、クラウドインフラ環境でワークフローや外部 DBと組み合 わせることにより、並列分散処理が容易 • パラメータや報酬の管理をシンプルにするために、試行部分を疎結合化が重要 Optunaの使いやすさ 40
Mobility Technologies Co., Ltd. 疎結合による弊害 • 7日間の営収シミュレーションを 5並列、100試行でハイパラチューニングを実施している • そのためハイパラチューニング中はワークフローのジョブが大量に生成される
並列実行による弊害 • シミュレーションを実行する GKEのnode poolがオートスケールする前に、他のジョブのリソースを奪ってし まうことがある • 試行時にスケールしないコンポーネントがあると全体の足を引っ張ってしまう 課題点 41
Mobility Technologies Co., Ltd. 精度面 • Trial数や、パラメータ数の増加による報酬影響について • チューニング対象期間のパフォーマンス影響について システム面
• 更に並列実行数を上げた場合のボトルネック調査 • 定期チューニングの実行、評価とデプロイの自動化 今後 42
Mobility Technologies Co., Ltd. Appendix 43 お客様探索ナビのアルゴリズムやMLOps全般については DeNA TechConでの登壇資料をご覧ください https://www.slideshare.net/dena_tech/mov-mlops
https://www.slideshare.net/dena_tech/dena-techcon-2019- 132196217
Mobility Technologies Co., Ltd. 44 技術全般 Twitter @mot_techtalk Thank You!
We Are Hiring! AI関連 Twitter @mot_ai_tech
confidential 文章·画像等の内容の無断転載及び複製等の行為はご遠慮ください。 Mobility Technologies Co., Ltd. 45
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}