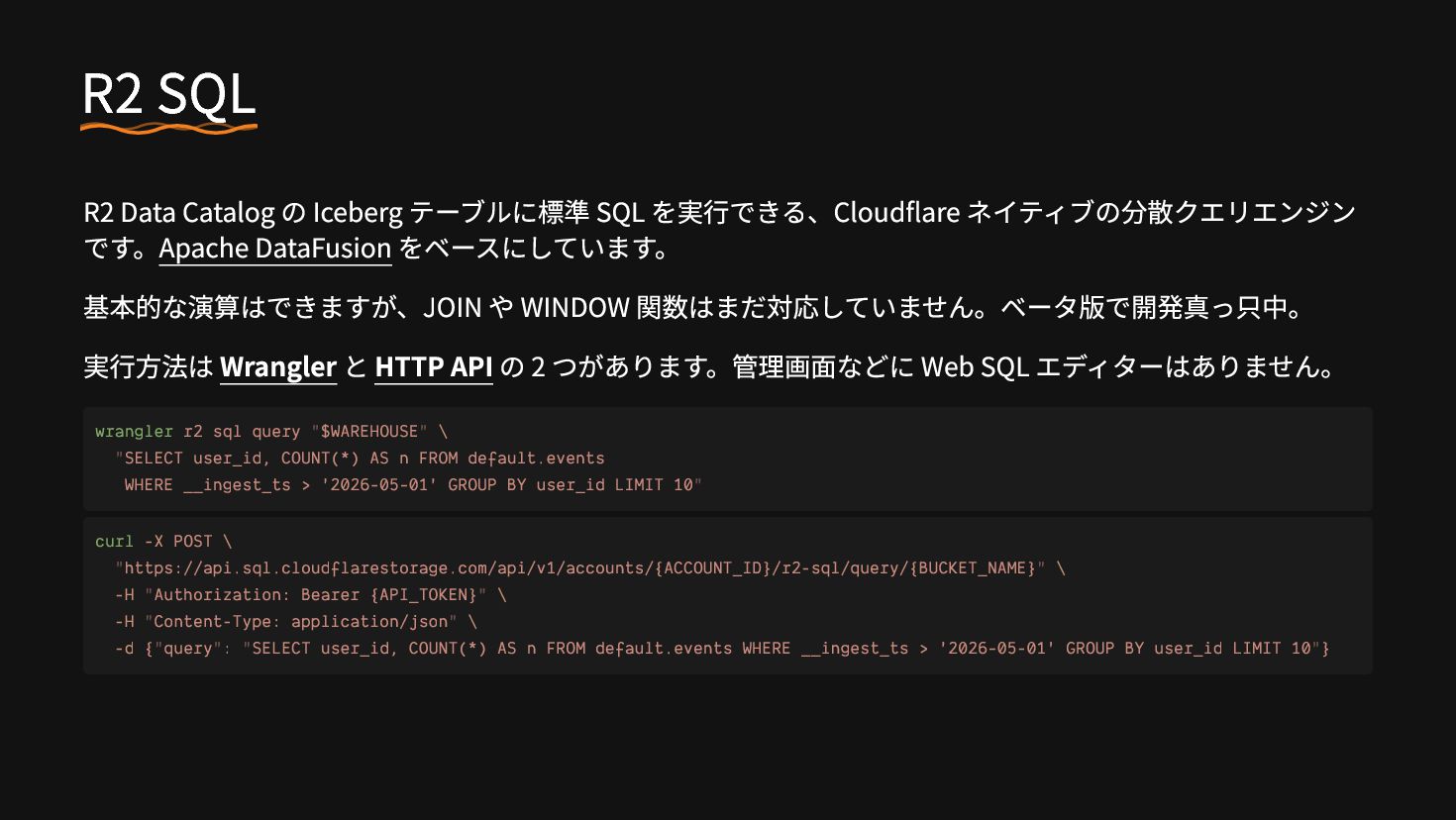
ネイティブの分散クエリエンジン です。Apache DataFusion をベースにしています。 基本的な演算はできますが、JOIN や WINDOW 関数はまだ対応していません。ベータ版で開発真っ只中。 実行方法は Wrangler と HTTP API の 2 つがあります。管理画面などに Web SQL エディターはありません。 wrangler r2 sql query "$WAREHOUSE" \ "SELECT user_id, COUNT(*) AS n FROM default.events WHERE __ingest_ts > '2026-05-01' GROUP BY user_id LIMIT 10" curl -X POST \ "https://api.sql.cloudflarestorage.com/api/v1/accounts/{ACCOUNT_ID}/r2-sql/query/{BUCKET_NAME}" \ -H "Authorization: Bearer {API_TOKEN}" \ -H "Content-Type: application/json" \ -d {"query": "SELECT user_id, COUNT(*) AS n FROM default.events WHERE __ingest_ts > '2026-05-01' GROUP BY user_id LIMIT 10"}
{kind=link}
{kind=link}
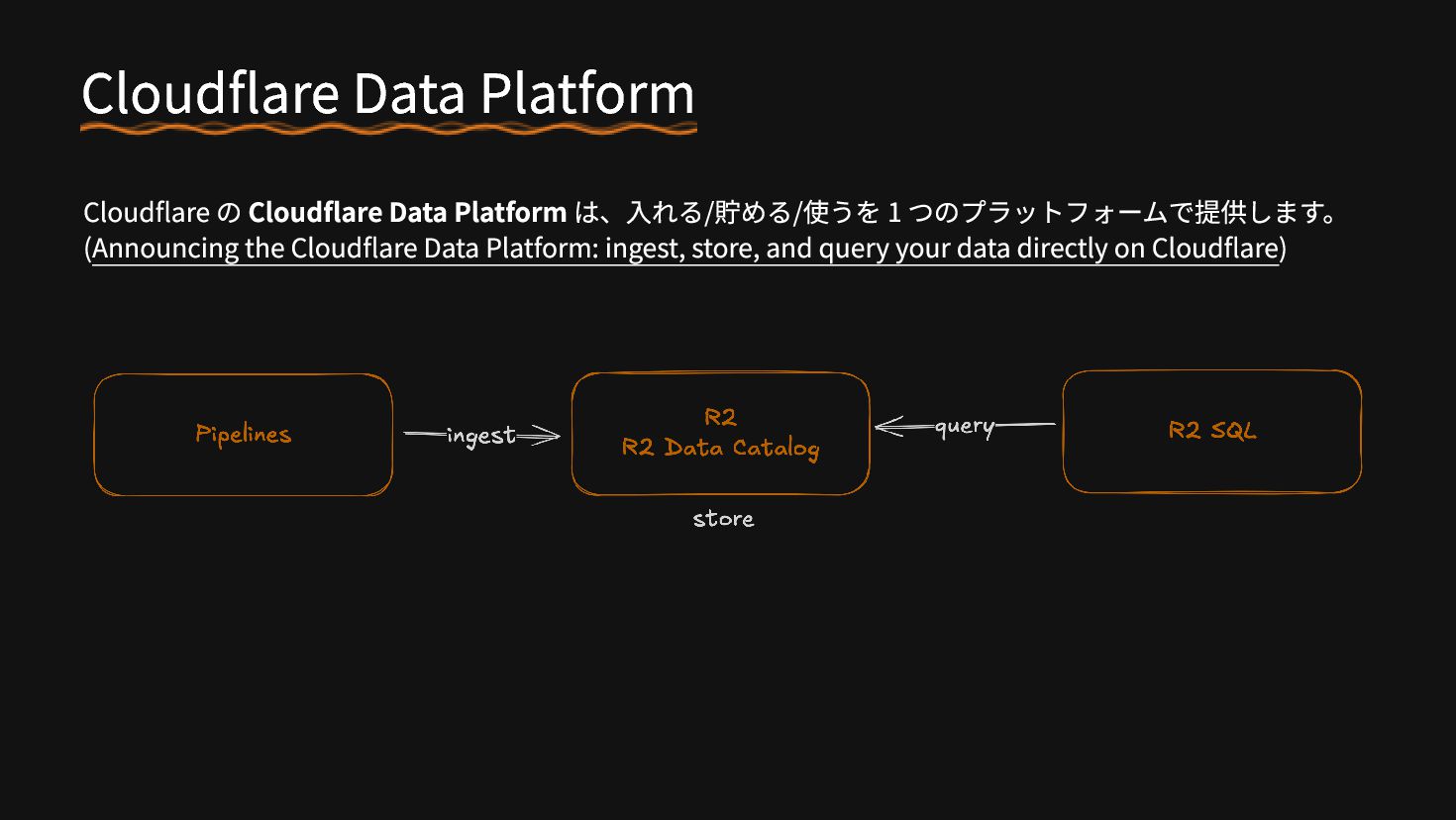{kind=link}
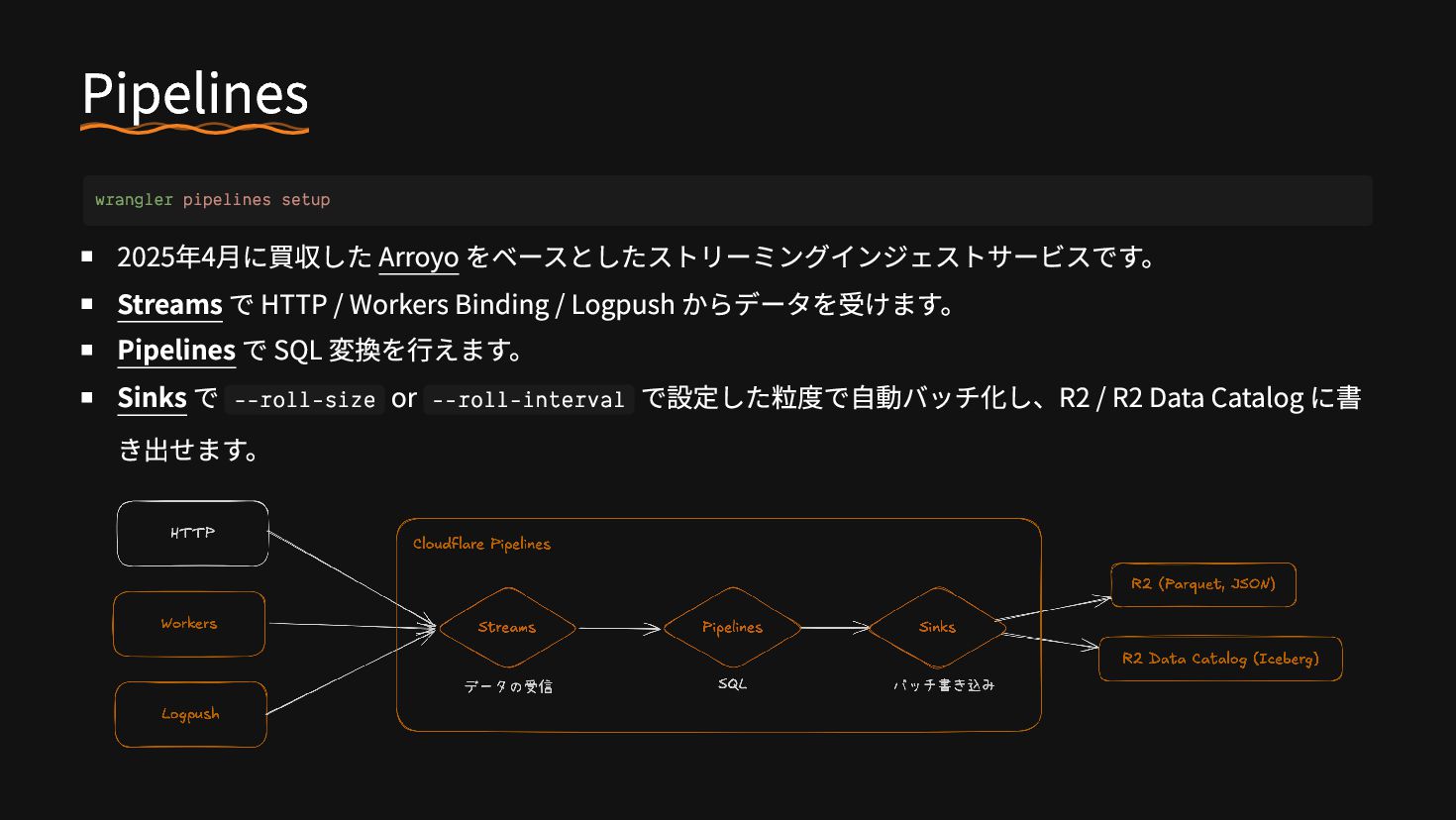{kind=link}
{kind=link}
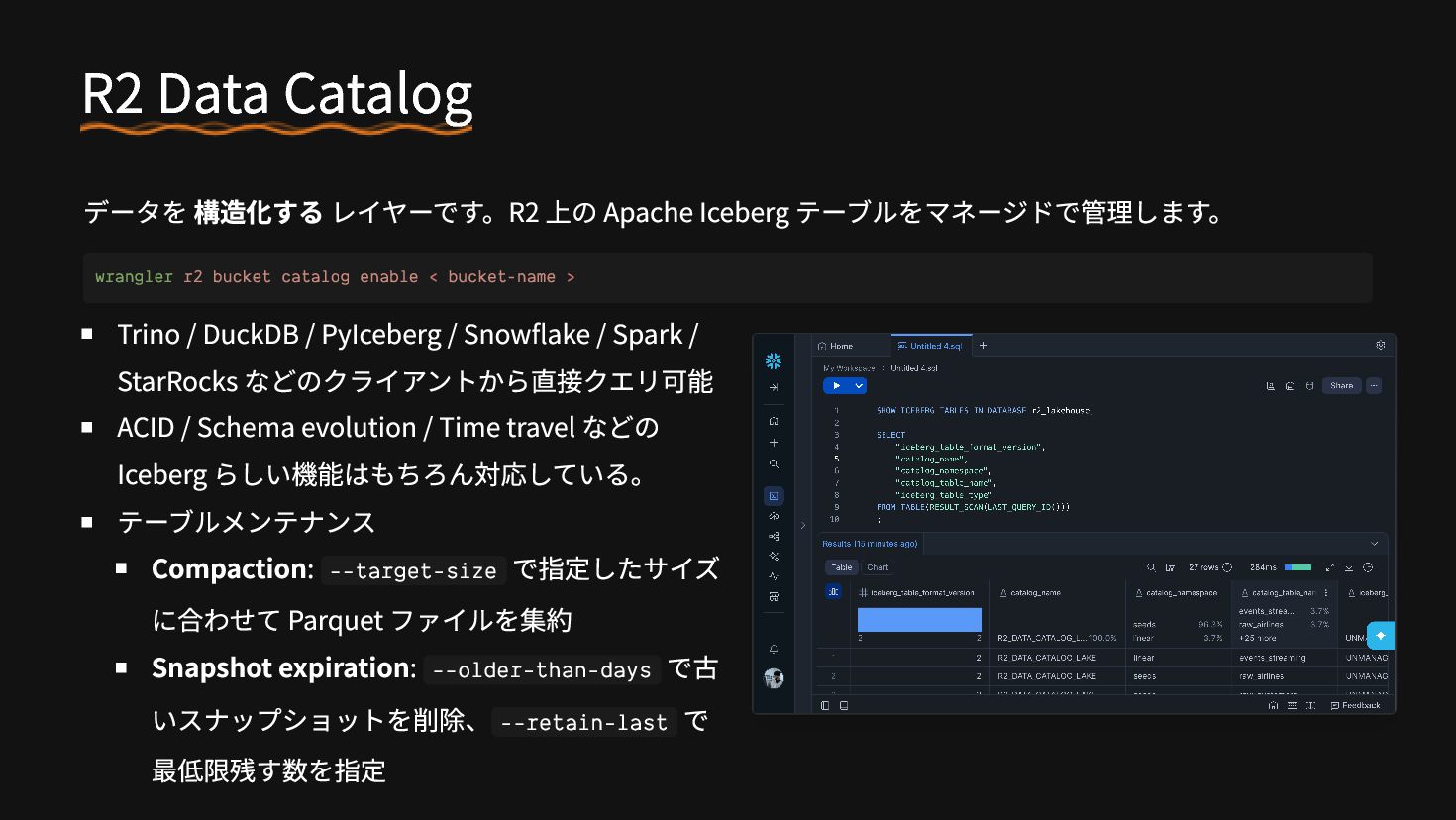{kind=link}
{kind=link}
{kind=link}
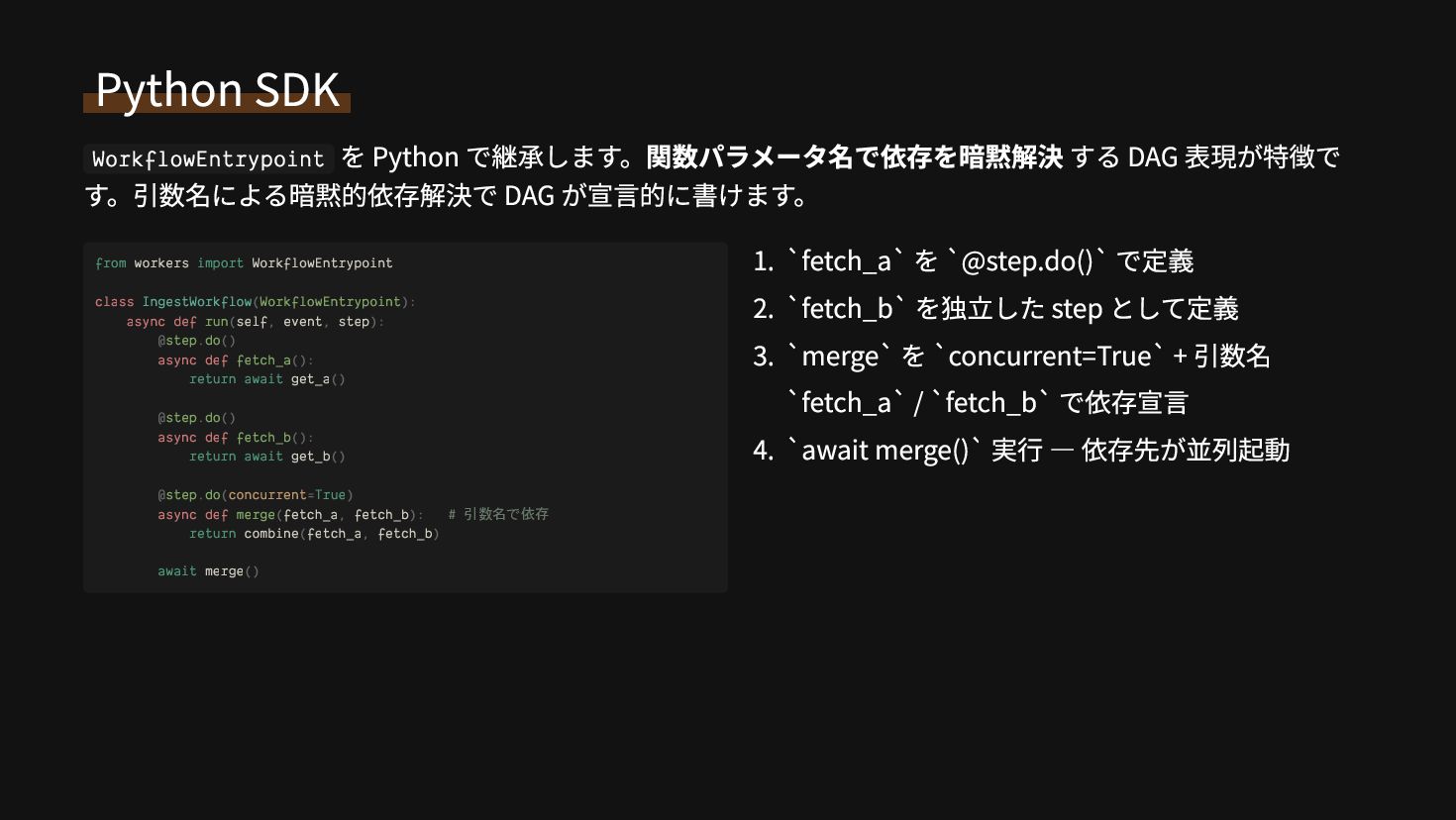{kind=link}
{kind=link}
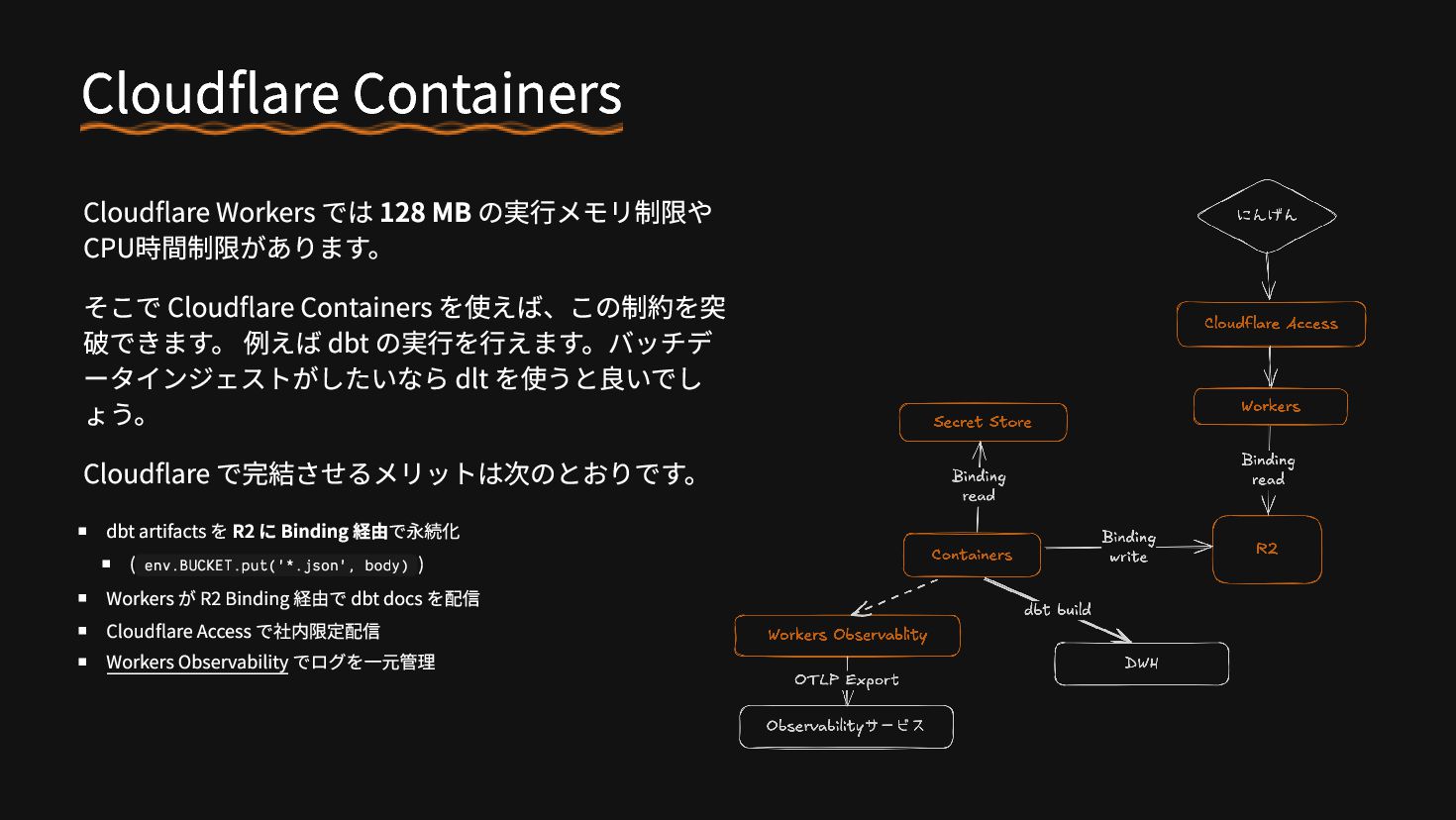{kind=link}
{kind=link}