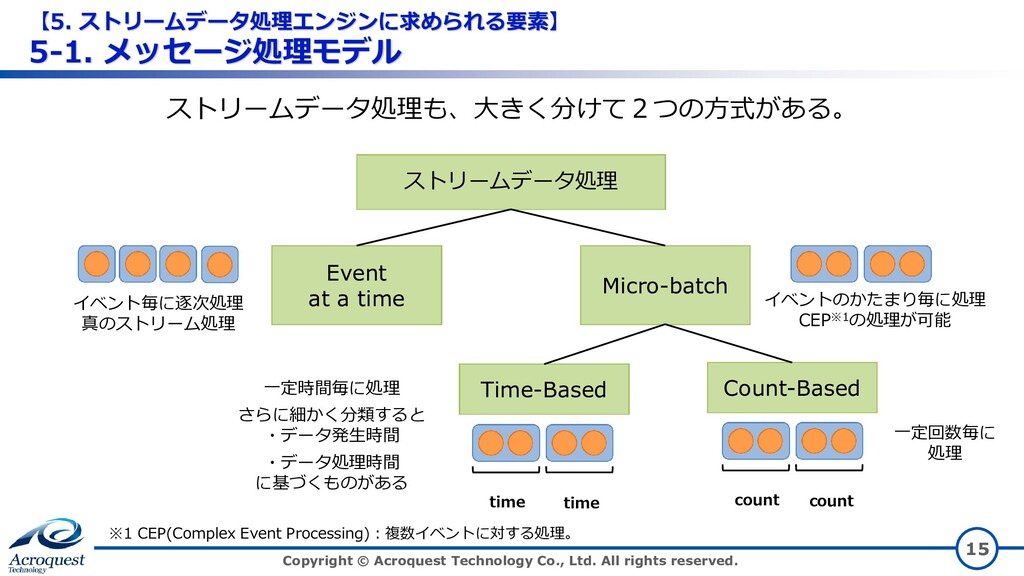
All rights reserved. 15 ストリームデータ処理 Event at a time Micro-batch Time-Based Count-Based ストリームデータ処理も、大きく分けて2つの方式がある。 イベント毎に逐次処理 真のストリーム処理 イベントのかたまり毎に処理 CEP※1の処理が可能 time time count count 一定時間毎に処理 さらに細かく分類すると ・データ発生時間 ・データ処理時間 に基づくものがある 一定回数毎に 処理 ※1 CEP(Complex Event Processing):複数イベントに対する処理。
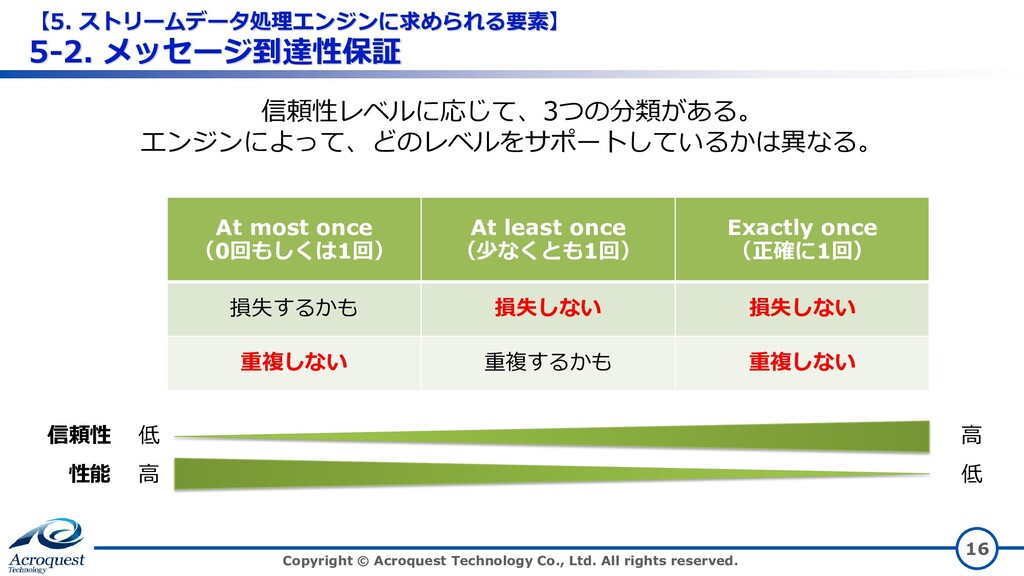
All rights reserved. 16 At most once (0回もしくは1回) At least once (少なくとも1回) Exactly once (正確に1回) 損失するかも 損失しない 損失しない 重複しない 重複するかも 重複しない 信頼性 性能 低 高 高 低 信頼性レベルに応じて、3つの分類がある。 エンジンによって、どのレベルをサポートしているかは異なる。
Co., Ltd. All rights reserved. 26 TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", new RandomSentenceSpout(), 5); builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout"); builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word")); Config conf = new Config(); conf.setNumWorkers(3); StormSubmitter.submitTopology(args[0], conf, builder.createTopology()); ※一部
本日のまとめ 1. ストリームデータ処理エンジンに求められる内容も高機能になってきている。 ① スケーラブル、耐障害性は必須になっている。 ② Backpressureによるフロー制御、ウィンドウ処理なども必要性が高い。 2. ストリーム処理エンジンは、戦国時代になっている。 ① Storm、Spark Streaming、Flinkが代表格。 ② Spark、Flink は、バッチとストリームの両方をサポートし、かつ、 クエリ処理や機械学習などのエコシステムを統合して提供しているのは有用。 ③ どれを利用するかは、そのエンジンの特性や強みを理解して選ぶしかない。 3. エンジンだけでなくシステム全体のアーキテクチャを考慮しよう。 ① データ収集やキュー処理、データの永続化など、一連の流れを検討する必要がある。 ② 運用のツールも揃ってきているので、うまく活用しよう。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}