etworks from D ecentralized D ata H . B r endan M c M ahan E ider M oor e D aniel R amage S et h H amps on B lais e A gu er a y A r cas, G oogle, I nc.
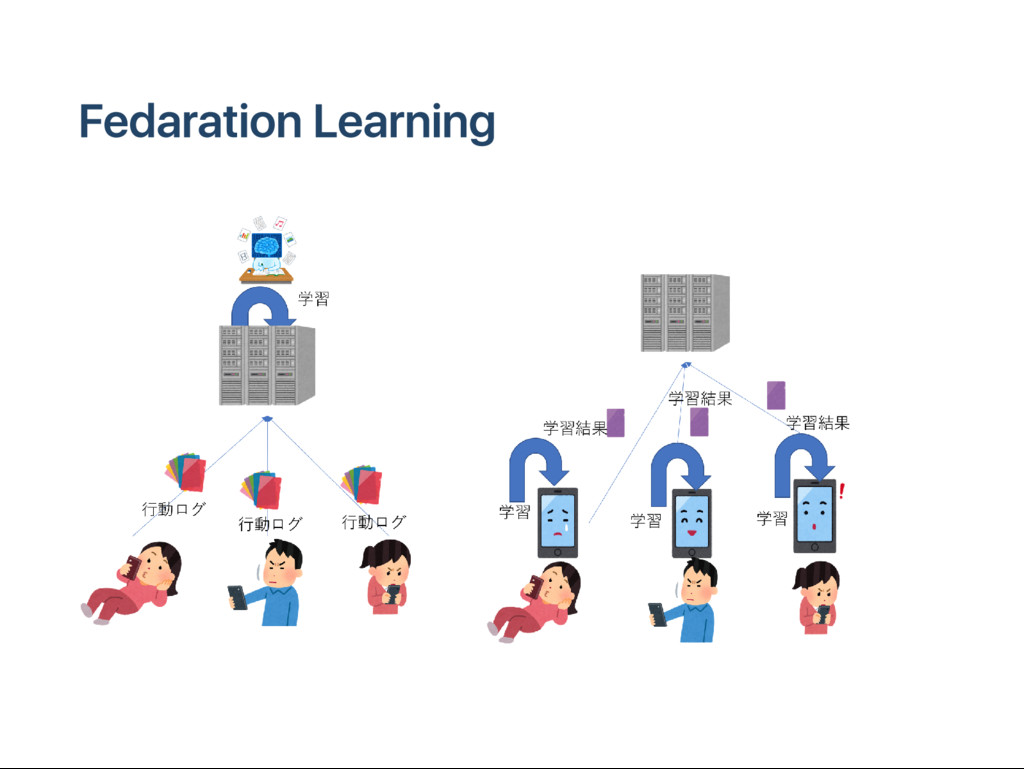
バにあげたくない solution localで学習を行う 並列度を高める: 同時に学習するクライアント数 it er at ionを増やす: localで学習する回数 A ndr oid版 G boar d(キー ボー ド入力と検索結果の提示int er face): サジェ スチョンの精度向上でテストされている
balanced dat a、 同期的学習: P er cptr on(M acdonald),DNN (P ov ey) 非同期学習: s oft av er agingによる DNN (Zhang) 凸の場合w orst ケー スで1クライアントより悪くなるという証明あり 凸最適化: 複数の研究がある IID にデー タ分配する必要あり クライアント間のデー タ数を同じにする必要あり 非同期 SGD : DNN がター ゲット(D ean)、 更新回数多い
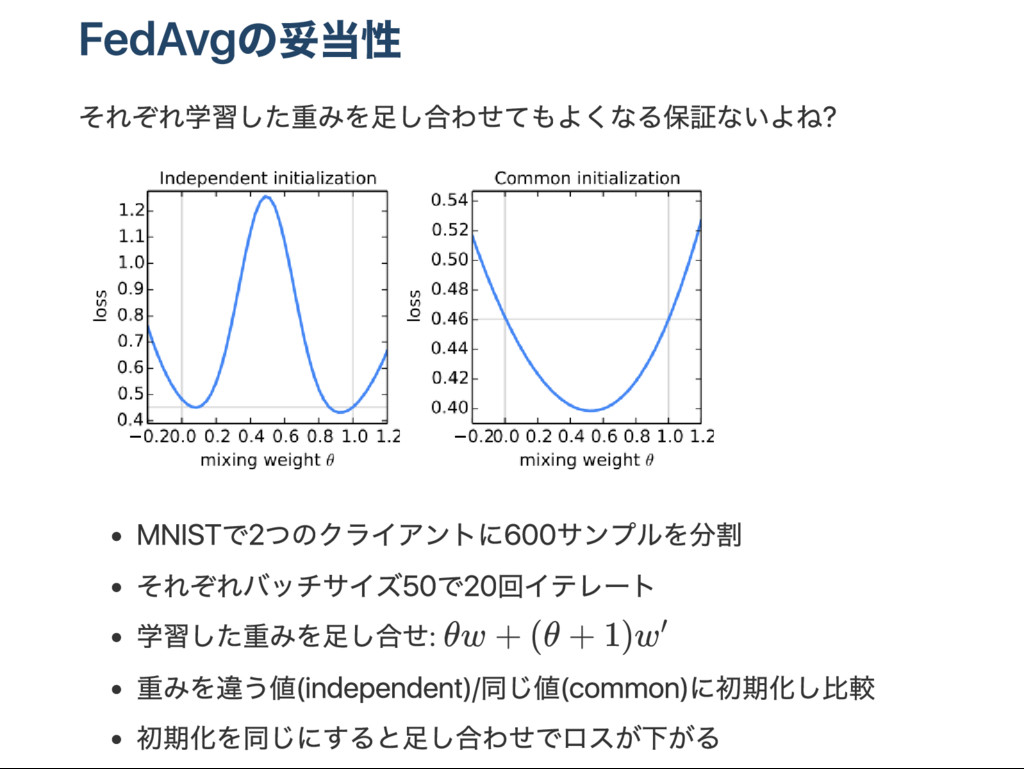
onous SGD をベー スラインとして評価 各クライアントが学習サンプルを保持してる状態で 1. すべてのクライアントのうち割合 C を選ぶ 2. クライアント毎に勾配評価 g : クライアントkの勾配 3. (@サー バー) w ← w − η g n = n , n : クライントkの学習サンプル数 C : 各r ou ndで学習を行うクライアントの割合 各クライアントの勾配の平均で更新 k ∑ k n nk k ∑ k k k
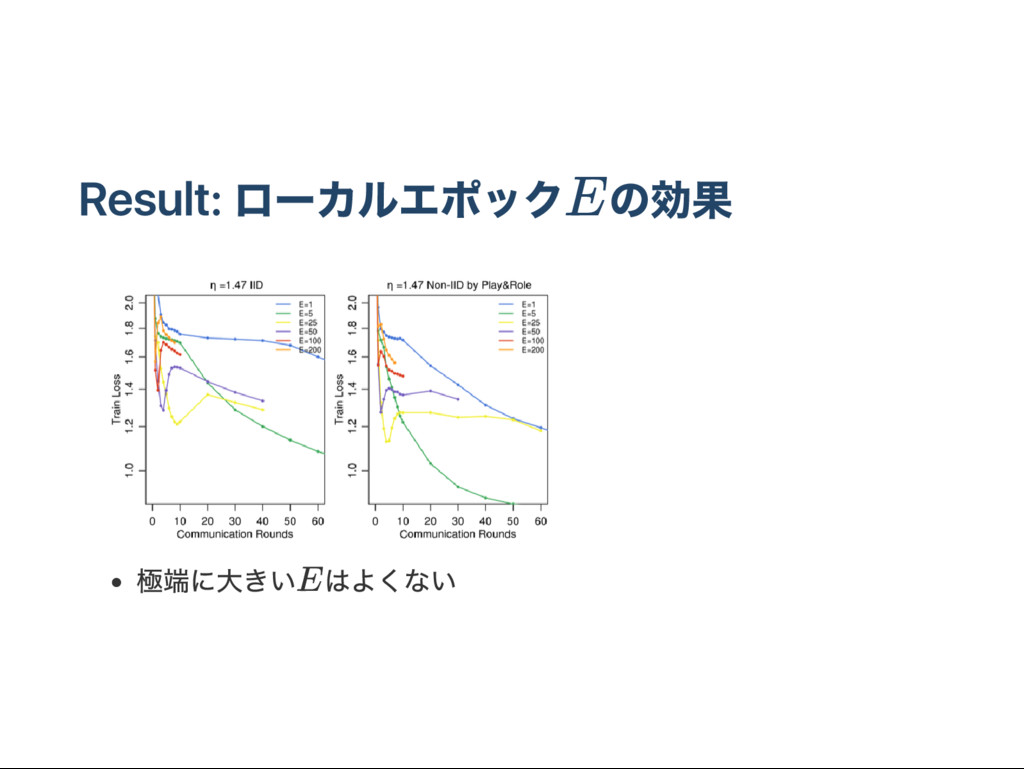
すべてのクライアントのうち割合 C を選ぶ 以下クライアント毎に 2. w ← w 3. サイズBのバッチにわける 4. for e in 1..E: iii. for b in B at ches: 重み更新 w ← w − ηg (w ) 5. (@サー バー) w ← w C : 各r ou ndで学習を行うクライアントの割合 E : 各r ou ndで学習を行う更新回数 B : 各r ou ndで学習を行うバッチ数 u = E : 1r ou ndおこる更新の回数( はサイズBのバッチの数) 各クライアントの学習済み重みで更新 k t k k k k t ∑ k n nk k k B nk B nk
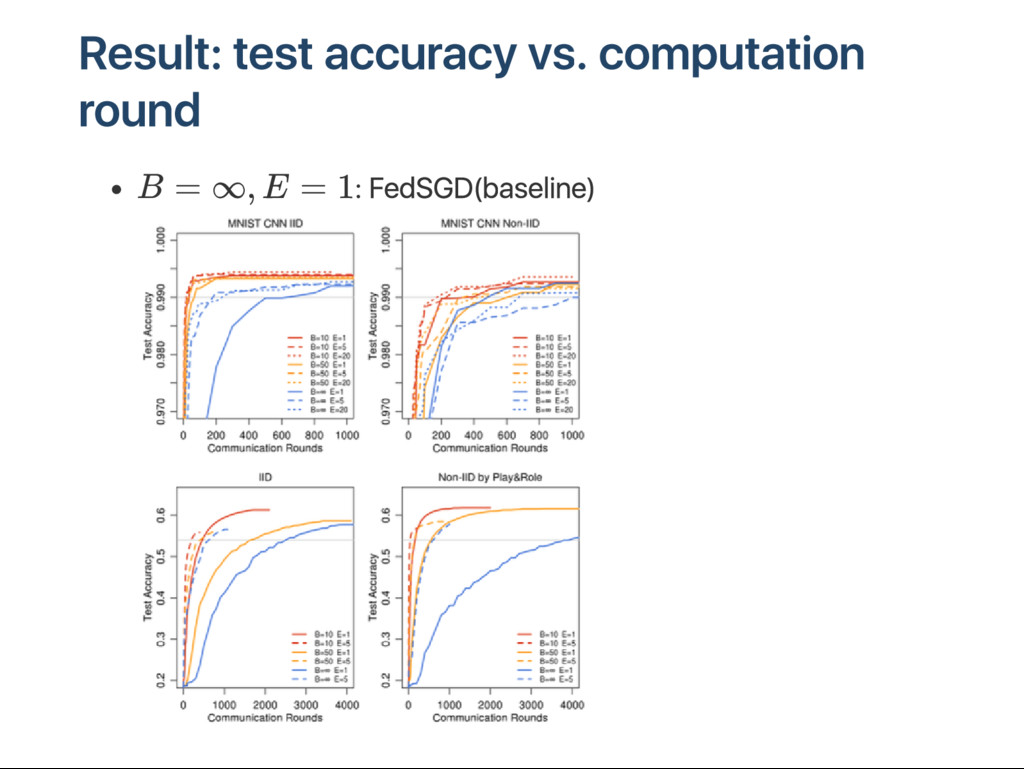
v g w it h E =1, B =∞) CIFAR ‑10: 2‑MLP , CNN IID : s hu ffled N on‑IID : s ort してユー ザ数*2に分割し2つのユニットをユー ザ ごとに分配 S hakesp ear e 次の単語を予測するタスク: st acked char act er‑lev el LSTM u nbalanced: r ou nd: クライアントが学習してサー バに集約する処理単位 通信回数の少なくしたいのでr ou nd数で評価
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}