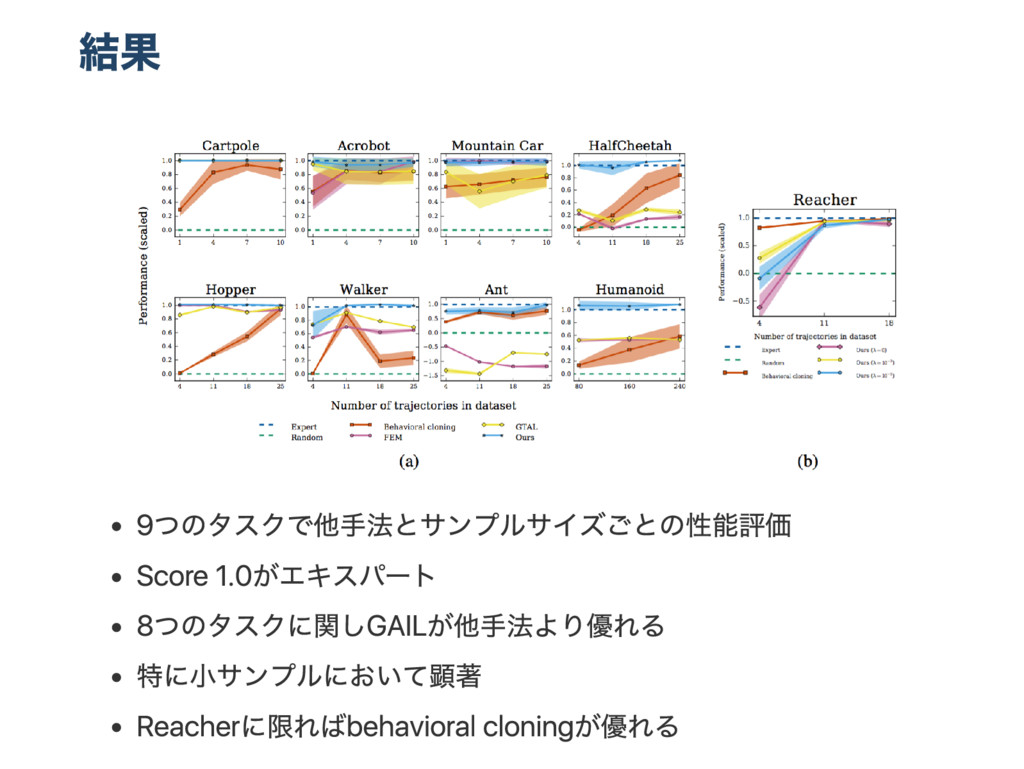
H o(O pen AI ) and S tefano E rmon(S tanford U niversity) エキスパー トの行動デー タからコスト関数を推定せずに直接ポリシ ー を学習する一般的な徒弟学習のフレー ムワー クを提案 既存の徒弟学習も含まれる このフレー ムワー クの1つのアルゴリズムとして G ener at iv e adv ers ar ial netw or k(GAN )的な最適化関数をもつ模倣学習の手法を 提案 大規模系に適用可で複雑なポリシー を表現可能 既存の模倣学習手法より少ないデー タでポリシー を獲得 紹介者: 大浦 健志@_takoika
at ion lear ing): エキスパー トの行動デー タから学習 B ehav iour cloning: 教師あり学習で状態から行動を学習 逆強化学習(I nv ers e r einfr ocement lear ning): 報酬関数を推定 徒弟学習(A ppr ent ices hip lear ning): 最適ポリシー を直接学習 するアルゴリズム
+ ψ (ρ − ρ ) ψ(c) = const.: ρ = ρ となり有限のサンプルから確率分布全 体は学習できない ψ(c) = {f (s, a)}: (s, a)によって決定される素性 学習によって決定されるのは{w } 素性に対して線形なコスト関数 既存の徒弟学習 (A beel2004, S y ed 2007, S y ed 2008) ψ E π∈Π ∗ π πE π πE { 0 ∞ if c ∈ { w f (s, a)} ∑ i i else i i
しか表現できない → より記述力のあるモデルで学習したい 提案する正則化関数 ψ = 至る所負の任意のコスト関数を表現可能 対応する双対問題(実際に最適化する関数) ψ (ρ − ρ ) = max E [log(D(s, a))] +E [log(1 − D(d, a))] GA { E [g(c(s, a))] πE +∞ if c < 0 otherwise { −x − log(1 − e ) x +∞ if x < 0 otherwise GA ∗ π πE D π πE
a))] + E[log(1 − D(s, a))] − λH(π) GAN のアナロジー、 収束性など GAN の議論が使える D(s, a) ∈ (0, 1): (s, a)‑p air がエキスパー トから生成された確率 でDはエキスパー トのサンプルか否かを学習する ポリシーπは軌道がエキスパー トに似るように学習 GAN における G ener at or はoccup ancy measur e lρに対応 ポリシーπはパラメー タθをもつニュー ラルネットワー クπ (s, a) で表現 ポリシー の更新は TRPO (s chu lman 2015)で勾配を計算しθを更新 D is cr iminat orDはパラメー タwをもつニュー ラルネットワー クD ψ の勾配からwを更新 π, Dを交互に更新する(GAN とおなじ) π D π θ w ∗
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}