Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介: soft-DTW
Search
takoika
October 18, 2017
Science
4.7k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介: soft-DTW
takoika
October 18, 2017
More Decks by takoika
See All by takoika
論文紹介: Communication-Efficient Learning of Deep Networks from Decentralized Data
takoika
0
2.6k
SKIP-GRAPH: LEARNING GRAPH EMBEDDINGS WITH AN ENCODER-DECODER MODEL
takoika
1
3.8k
論文紹介 Generative Adversarial Imitation Learning
takoika
5
3.4k
Other Decks in Science
See All in Science
データベース01: データベースを使わない世界
trycycle
PRO
1
1.4k
データベース14: B+木 & ハッシュ索引
trycycle
PRO
0
790
AIPシンポジウム 2025年度 成果報告会 「因果推論チーム」
sshimizu2006
3
570
コーヒー豆様核 (Coffee-bean nuclei) における形態学的サブタイピングと精選・焙煎特性の同定
jagupath
PRO
0
130
水耕栽培:古代の知恵から宇宙農業まで
grow_design_lab
0
170
Sstニューロンによる睡眠不足と回復の制御:データ駆動型トランスクリプトーム解析
tagtag
PRO
0
110
TypeScript で WebAssembly を用いた 型安全なプラグイン設計
nagano
2
580
1. CPC理論の展開と集合的知能モデル(JSAI2026 KS-27 集合的予測符号化と新たな知性の時代)
hayashiyus884
1
310
(2025) Balade en cyclotomie
mansuy
0
660
先端因果推論特別研究チームの研究構想と 人間とAIが協働する自律因果探索の展望
sshimizu2006
3
970
AlgorithAlgorihms for Decision Making
mickey_kubo
0
110
チュートリアル:世界モデル
hf149
0
2k
Featured
See All Featured
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
230
Building Applications with DynamoDB
mza
96
7.1k
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
Automating Front-end Workflow
addyosmani
1370
210k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
41k
Technical Leadership for Architectural Decision Making
baasie
3
450
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
300
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
190
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
The Curious Case for Waylosing
cassininazir
1
440
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
Transcript
Soft-DTW: a Differentiable Loss Function for Time-Series Marco Cuturi and
Mathieu Blondel presenter: Takeshi Oura
アジェンダ • Soft-DTW: a Differentiable Loss Function for Time-Series Marco
Cuturi and Mathieu Blondel • DTW(dynamic time warping)とは • 2つの時系列を⽐較する指標(時系列間の差、違い) • 時系列の⻑さの違い、伸び、縮みを吸収する • 時系列予測のロス関数として使⽤できる • soft-DTW • 微分可能なDTW • 勾配計算アルゴリズムの提案 • 評価 • 複数時系列の平均 • k-means • 時系列識別問題 • 時系列予測
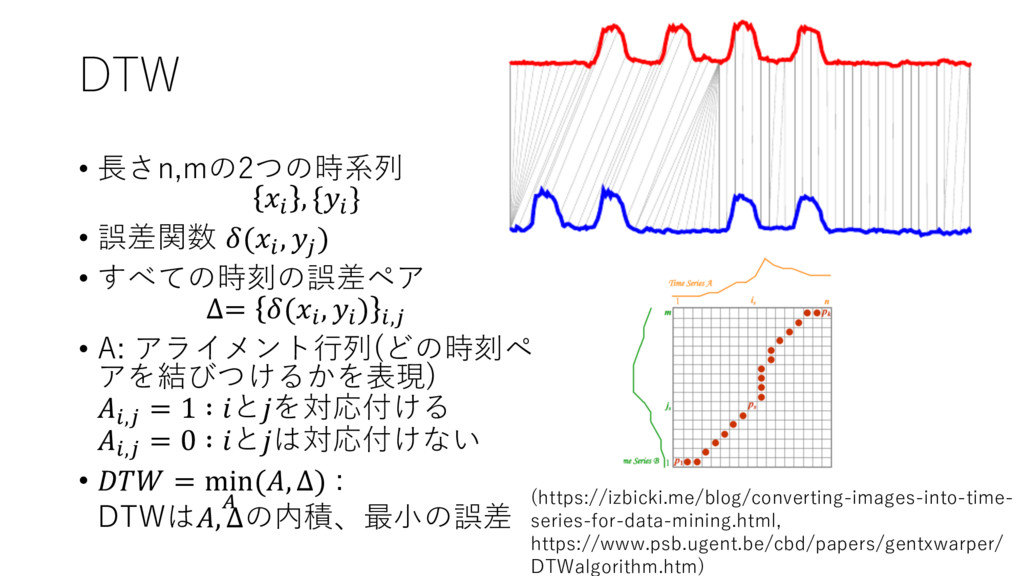
DTW • ⻑さn,mの2つの時系列 " , {" } • 誤差関数 ("
, ) ) • すべての時刻の誤差ペア ∆= (" , " ) ",) • A: アライメント⾏列(どの時刻ペ アを結びつけるかを表現) ",) = 1 ∶ とを対応付ける ",) = 0 ∶ とは対応付けない • = min 9 (, ∆) : DTWは, ∆の内積、最⼩の誤差 https://www.psb.ugent.be/cbd/papers/gentxwarper/ DTWalgorithm.htm) (https://izbicki.me/blog/converting-images-into-time- series-for-data-mining.html,
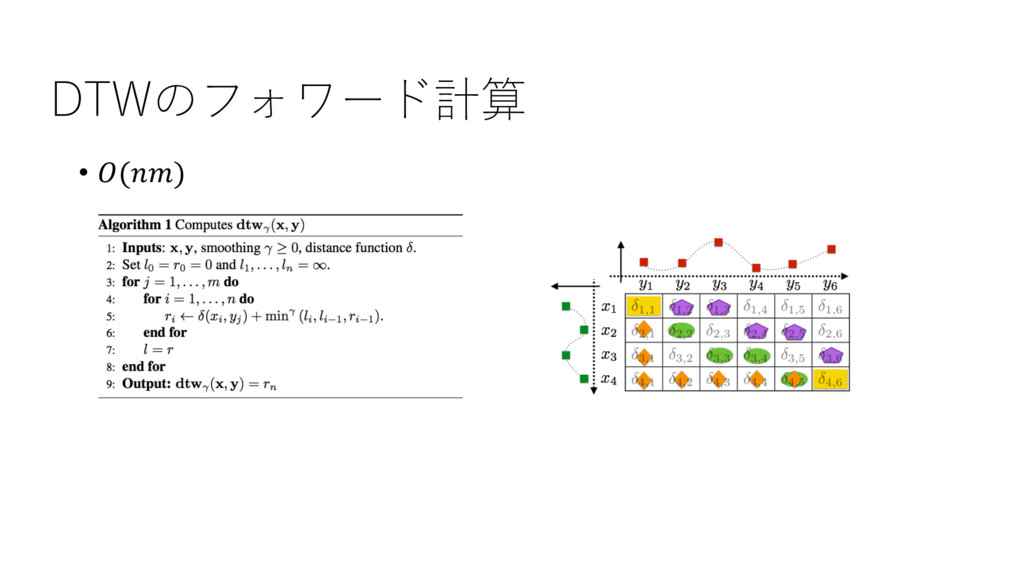
DTWのフォワード計算 • ()
soft-DTW • DTW: = min 9 (, ∆) • soft-DTW:
= = > @(9,A)/= 9 • ⟶ 0:DTWに対応(最適Aのみの寄与) • DTWと同様に計算可能(()) min ("@H,) , ",)@H , "@H,)@H )を−log (@MNOP,Q/= + @MN,QOP/= + @MNOP,QOP/=)にす ればよい
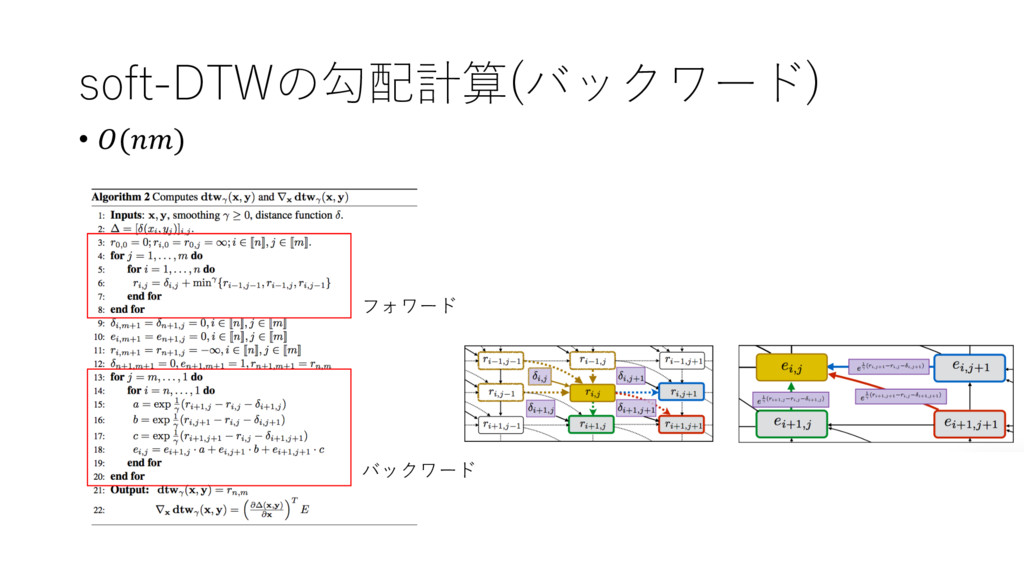
soft-DTWの勾配計算(バックワード) • T = U∆ UT V • ",) =
UMX,Y UMN,Q • いかにUMX,Y UMN,Q を計算するか? アイデア: Z,[ (DTWの値)の偏微分は(i-1,j),(i,j-1),(i-1,j-1)のみに依存 • ",) は上式で再帰的に計算 • ",) = " , " + min = {"@H,) , ",)@H , "@H,)@H } から上式右辺の微分は計算可能
soft-DTWの勾配計算(バックワード) • () フォワード バックワード
soft-DTWの評価 • 仮説: 直接DTWを最⼩化するよりsoft-DTWを最⼩化するほうが (DTWを)最⼩化するうえで優れている • soft-DTWの性質 • = 0:
⾮凸関数(最適化の際ローカルミニマムにつかまる) • ⟶ ∞: 凸関数に近付く • による凸緩和でより最適化されるか? • ⽐較⼿法 • DBA: GAと局所最適化を交互に使⽤しDTWを直接最適化(Patitjean et. al. 2011) • 劣勾配法: 劣勾配でDTWを最適化 • データセット • UCR(University of California, Riverside) time series
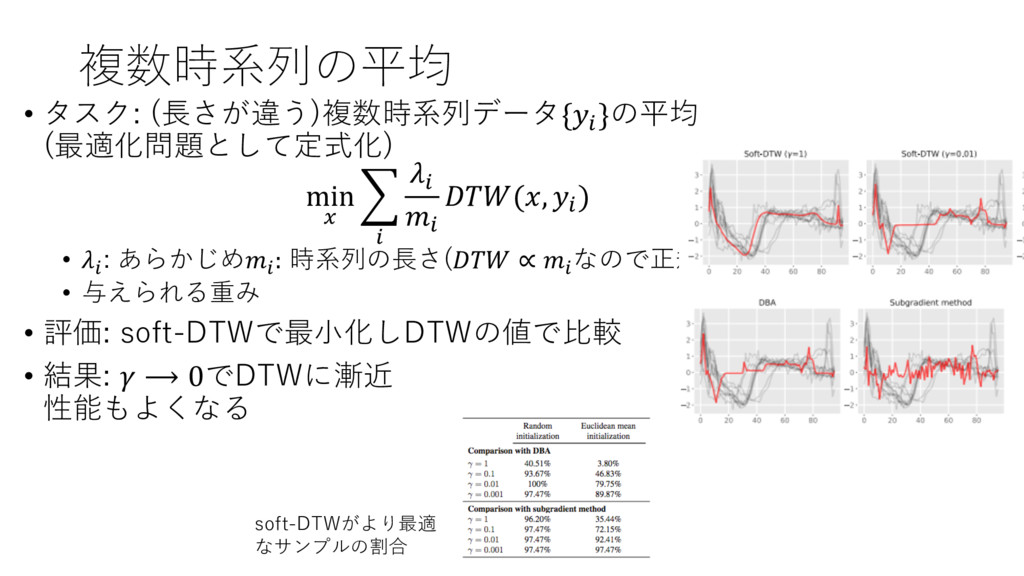
複数時系列の平均 • タスク: (⻑さが違う)複数時系列データ{" }の平均 (最適化問題として定式化) min T > "
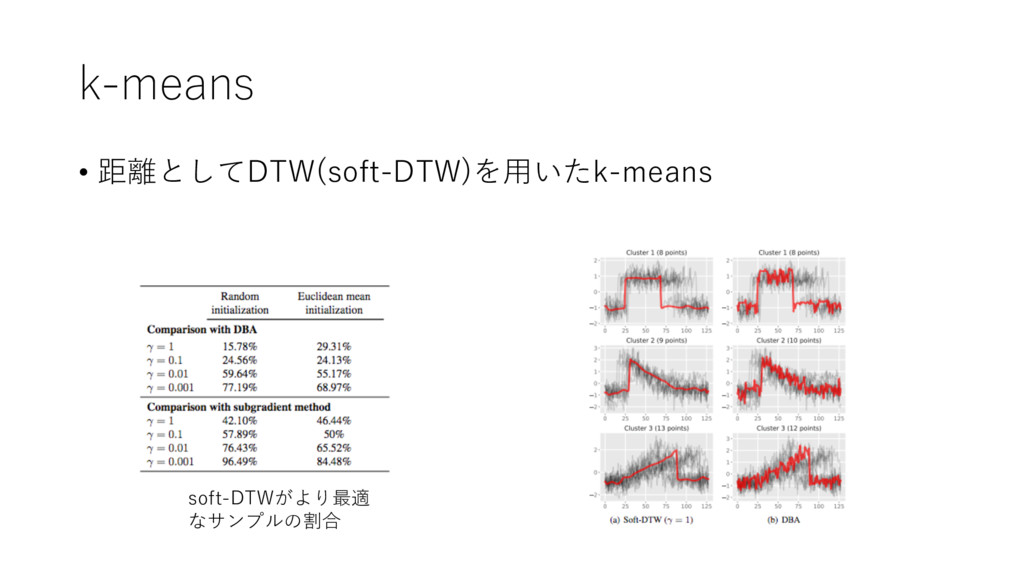
" (, " ) " • " : あらかじめ" : 時系列の⻑さ( ∝ " なので正規化として) • 与えられる重み • 評価: soft-DTWで最⼩化しDTWの値で⽐較 • 結果: ⟶ 0でDTWに漸近 性能もよくなる soft-DTWがより最適 なサンプルの割合
k-means • 距離としてDTW(soft-DTW)を⽤いたk-means soft-DTWがより最適 なサンプルの割合
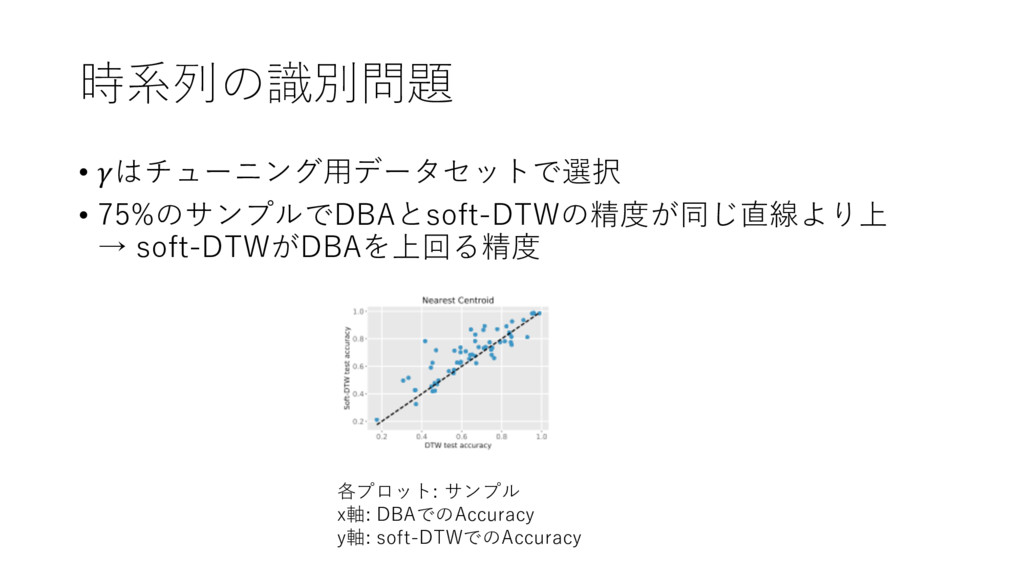
時系列の識別問題 • はチューニング⽤データセットで選択 • 75%のサンプルでDBAとsoft-DTWの精度が同じ直線より上 → soft-DTWがDBAを上回る精度 各プロット: サンプル x軸:
DBAでのAccuracy y軸: soft-DTWでのAccuracy
時系列予測 • インプット: = 1, . . , まで •
アウトプット(予測): = + 1, . . , + • c : パラメータで指定される関数 • ロス関数: min c ∑ (c " H,..,V , " VfH,..,VfZ) " • : サンプルインデックス • 実験: • 時系列の60%,40%: インプット、アウトプット • MLPで評価 (RNNも実験したがMLPより向上しなかった)
まとめ • 微分可能なDTWとその計算アルゴリズムの提案 • フォワード、バックワード: () • 凸緩和することで、解きやすい最適化関数のクラスにできる • DTWを最適化する複数のベンチマーク:
• soft-DTWを⽤い勾配法での評価 • DTWを直接最適化する他アルゴリズムに対する優位性を⽰した
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}