など) グラフ中ノー ドの埋め込み表現 (D eep w alk by P er ozz i et al. 2014, line T ang et al. 2015, node2v ec by G r ov er et al.2016) グラフ全体に着目 グラフ間類似度: gr ap h‑ker nel et c. コミュニティ抽出、 サブグラフ分類、 ラベル付与 構文木からの推定、 分子配列から構造、 機能予測 グラフ全体の埋め込み← 本論文 一般のグラフ埋め込み表現でなくグラフとみなせる特定のタス ク用(素性の提案)論文は多数
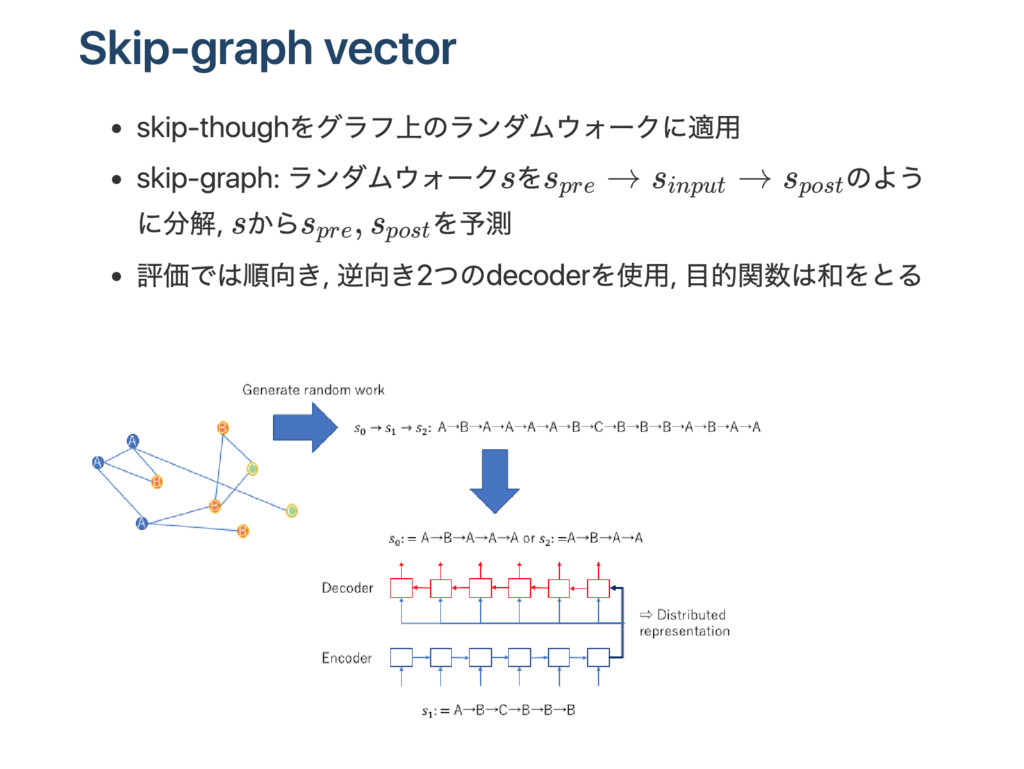
中のs ent enceの埋め込み表現を抽出 s kip‑gr amを同じアイデア: センテンスs = {w }から前のセンテンスs = {w }, 後の センテンスs = {w }を予測 目的関数: L = P(w ∣{w } , h ) + P(w ∣{w } , h ) P(w ∣{w } , h ) ∼ exp(v h ) V = {v }: 単語ごとに決まる重み行列 i i t i+1 i+1 t i−1 i−1 t t ∑ i+1 t i+1 t′ t <t ′ i t ∑ i−1 t i−1 t′ t <t ′ i i+1 t i+1 t′ t <t ′ i wi+1 t i+1 t w
GRU h : encoder の出力ベクトル decoder:h をバイアスに付加した GRU r = σ(W x + U h + C h ) z = σ(W x + U h + C h ) = tanh(W x + U (r z ⊙ h ) + Ch ) h = (1 − z ) ⊙ +z ⊙ i i t r d t−1 r d t−1 r i t z d t−1 z d t−1 r i h ¯t d t−1 d t t−1 i i+1 t t t h ¯t
emant ic r elat edness: 2つのセンテンスが意味的に類似しているか 言い換え検出:2つのセンテンスが言いかえか否か識別 image‑s ent ence r anking: 与えられた画像(キャプション)に適切な キャプション(画像)をランキング 文書識別: レビュー、 意見の極性、 質問の分類など
ベクトル表現抽出: i. 各グラフごとK 個のランダムウォー クを生成 ii. encoder でベクトル表現を出力 iii. K 個のベクトル表現を合算 ベクトル表現の合算方法 S ingle w alk: 十分に長い系列1つのみ生成し使う(K = 1) A v er age:次元ごとに平均 M ax: 次元ごとに M ax C lust er: k‑means → bu g of clust er ′ ′ ′
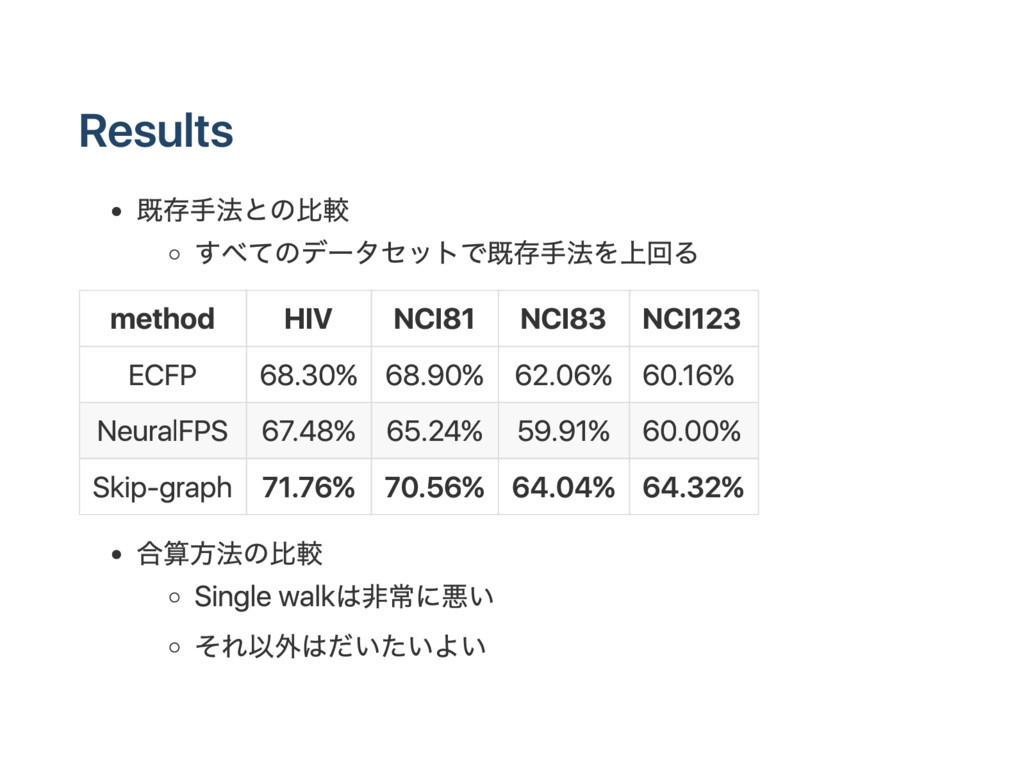
et: NCI 81, NCI 83, NCI 123, HIV 比較手法: ECFP : E xt ended‑connect iv ity cir cu lar fingerpr ints, 各ノー ド からk近傍の分子に着目し、 it er at iv eにノー ドの素性を更新し has h関数で固定長ベクトルに変換 N eur al FPS : ECFP をk近傍をまとめる処理を CNN にしたもの S kip‑gr ap h: 提案手法 素性抽出後sv mで識別機を構築し予測精度を比較
83 NCI 123 ECFP 68.30% 68.90% 62.06% 60.16% N eur al FPS 67.48% 65.24% 59.91% 60.00% S kip‑gr ap h 71.76% 70.56% 64.04% 64.32% 合算方法の比較 S ingle w alkは非常に悪い それ以外はだいたいよい
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}