各言語のカーネル(ipython, iruby)のリッチなインタフェース • ちなみにgithubでもプレビューが動く 13 Open source, interactive data science and scientific computing across over 40 programming languages.
for data mining and data analysis •Accessible to everybody, and reusable in various contexts •Built on NumPy, SciPy, and matplotlib •Open source, commercially usable - BSD license 14 • Pythonで手軽に機械学習するならデファクト。 • 沢山のアルゴリズム。C++レイヤーで計算するので演算が早い。 • 共通のインタフェース ◦ fit(x,y): 与えられた訓練データとハイパーパラメータを元に訓練する。 ◦ predict(x): 新規の入力データを与えて予測を行う。 ◦ score(x,y): データへの当てはめの良さを評価。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
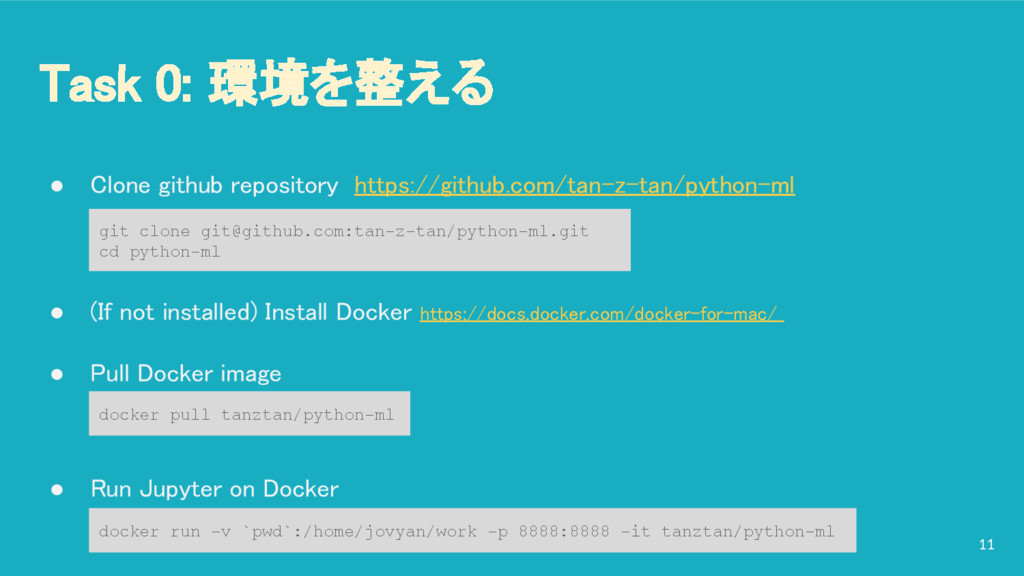{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
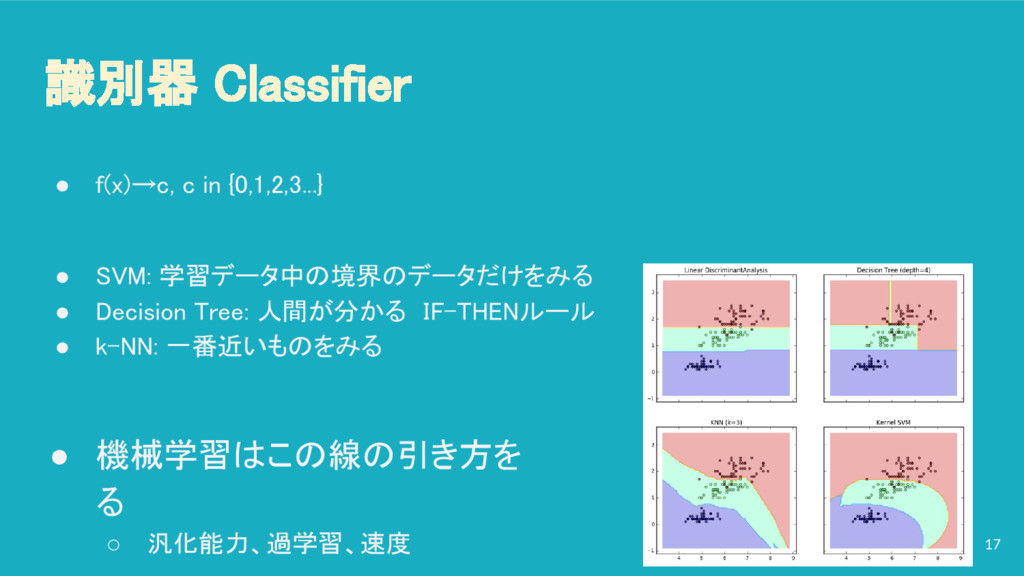{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}