Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL. • (Conneau+ ACL 2020) Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, Veselin Stoyanov. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of ACL 2020. • (Wu and Dredze 2019) Shijie Wu, Mark Dredze. Beto, Bentz, Becas: The Surprising Cross- Lingual Effectiveness of BERT. In Proceedings of EMNLP. 2019. • (Pires+ 2019) Telmo Pires, Eva Schlinger and Dan Garrette. How multilingual is Multilingual BERT? In Proceedings of NAACKL 2019. • (Fabio DMKD 2017) Fabio Gasparetti. Modeling user interests from web browsing activities. Data Mining and Knowledge Discovery. 2017.
{kind=link}
{kind=link}
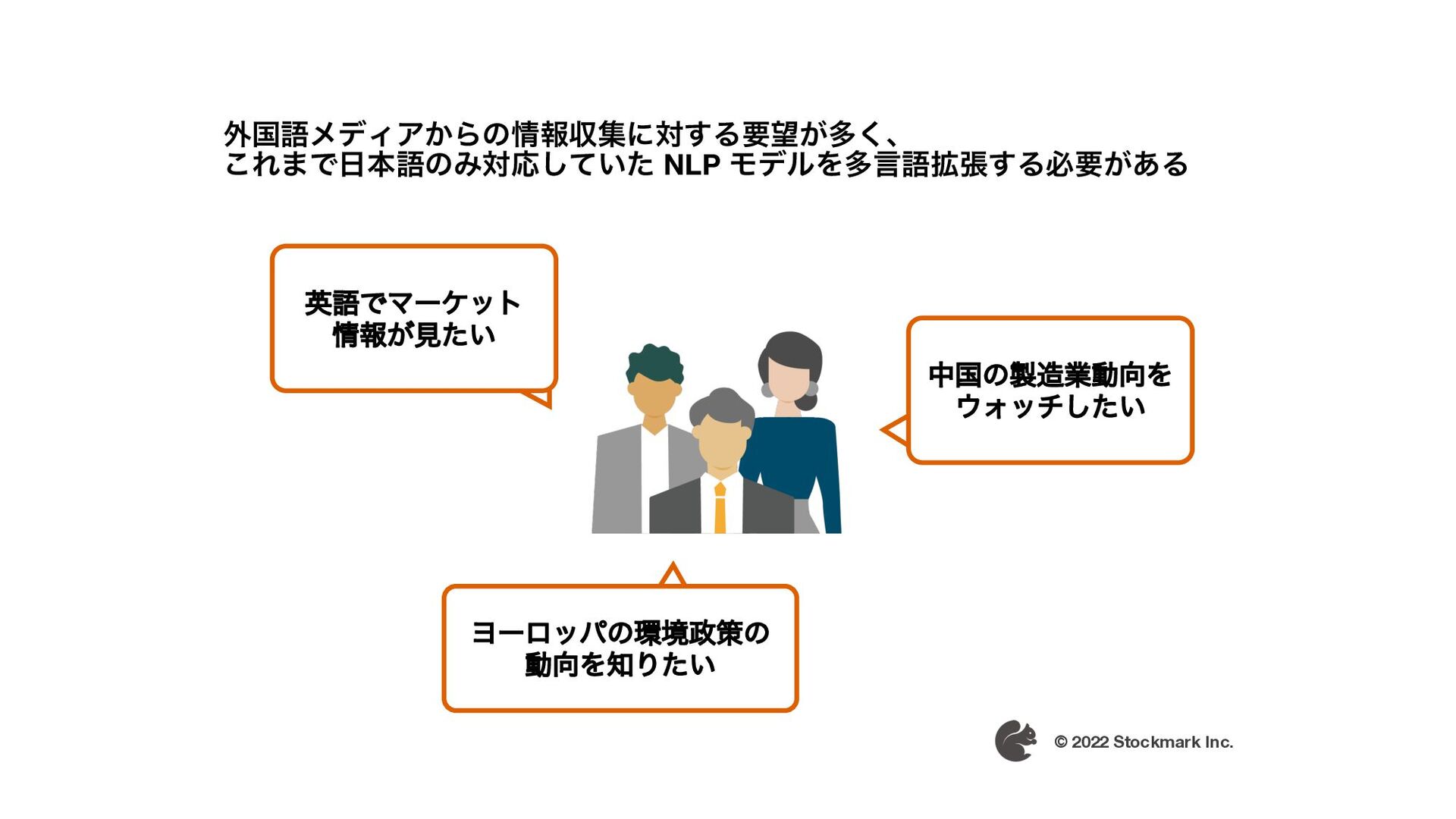{kind=link}
{kind=link}
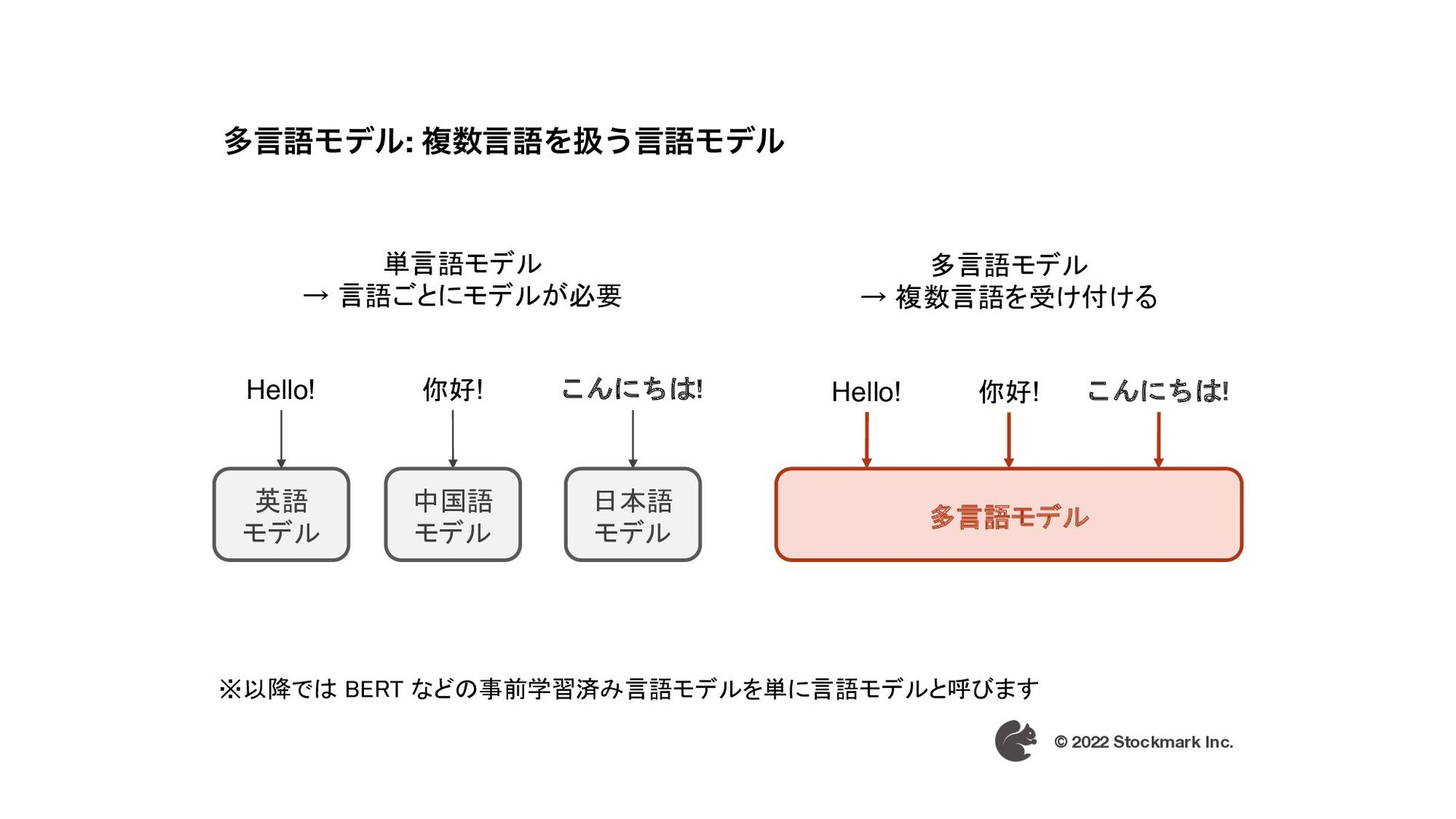{kind=link}
{kind=link}
{kind=link}
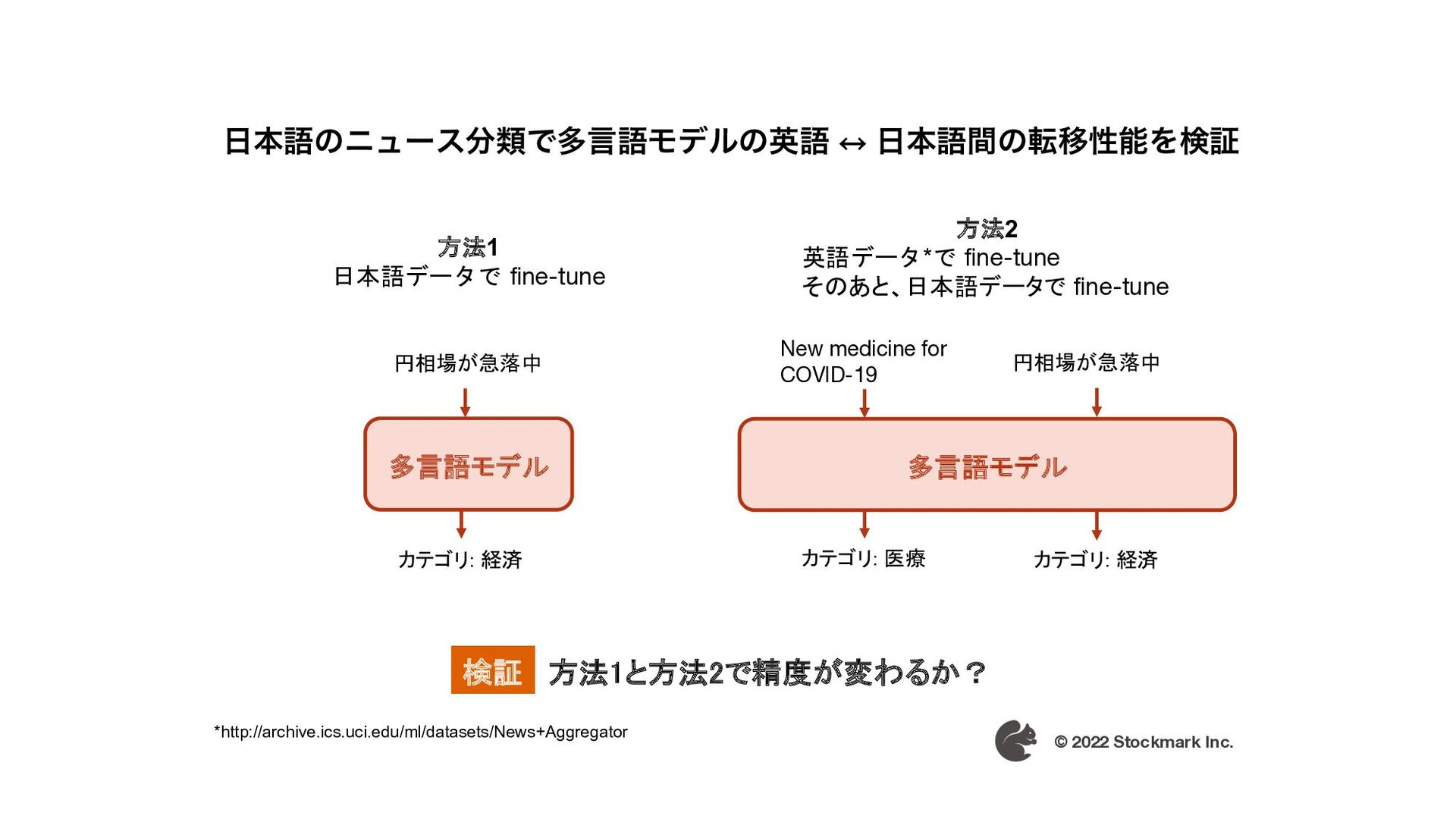{kind=link}
{kind=link}
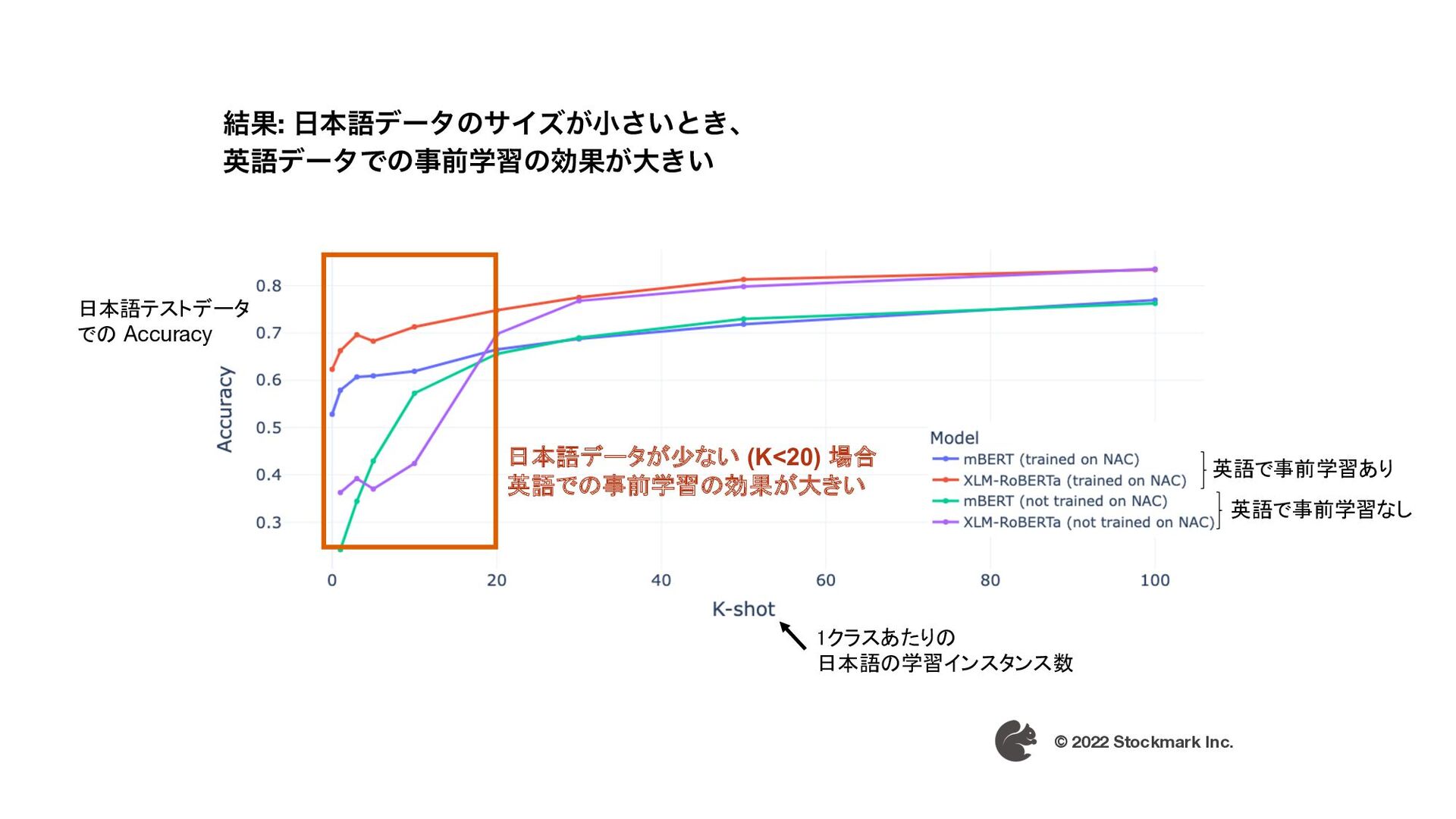{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}