Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ゼロから作るアンサンブル学習(第1回)
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
tatamiya
March 28, 2019
Technology
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ゼロから作るアンサンブル学習(第1回)
tatamiya
March 28, 2019
More Decks by tatamiya
See All by tatamiya
サイコロで理解する統計的仮説検定の考え方
tatamiya
5
3.3k
状態空間時系列モデルで見た R と Python の比較 〜 KFAS と statsmodels 〜
tatamiya
1
1.9k
第1回沖本計量時系列分析輪読
tatamiya
1
730
ゼロから作るアンサンブル学習 第2回資料
tatamiya
0
370
20190409_FasterPythonMeetUp_TAMIYA
tatamiya
0
300
Other Decks in Technology
See All in Technology
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
700
AI x 開発生産性を取り巻く予算戦略と投資対効果
i35_267
7
2.8k
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.5k
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
600
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
510
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
200
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
3
390
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
200
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
880
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
160
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
320
Featured
See All Featured
Designing for humans not robots
tammielis
254
26k
Exploring anti-patterns in Rails
aemeredith
3
450
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Odyssey Design
rkendrick25
PRO
2
730
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
410
It's Worth the Effort
3n
188
29k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1.1k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
370
Transcript
ゼロから作るアンサンブル学習 ~OSSに学ぶ機械学習の実装~ 第1回 決定⽊・ランダムフォレストの理解と実装 たみや@tatatatatamiya
このセミナーについて u ⽬的 u アルゴリズムの理解 u OSSから良い実装を学ぶ u スケジュール u
第1回(3/28 本⽇) : 決定⽊・ランダムフォレストの理解と実装 u 第2回(4⽉下旬) : scikit-learnの読解 u 第3回(5⽉下旬) : 勾配ブースティング〜XGBoost, LightGBM
アルゴリズムの概要 - 決定⽊ - ランダムフォレスト
決定⽊
決定⽊とは︖ プロフィール 年齢 33歳 ⾝⻑ 168cm 体重 65kg 収⼊ 700万円
!? ⾝⻑ > 170cm? 体重 > 70kg? 体重 > 100kg? 年齢 >30? 収⼊ >1000万円? No No Yes Yes No Yes No Yes No Yes モ テ ⾮ モ テ モ テ ⾮ モ テ モ テ ⾮ モ テ 閾値を設けてYes/Noで振り分けていく モテる︖モテない︖ 課題 - どの特徴量で切る︖ - 閾値はいくつにする︖
分類⽅法の決め⽅ 年齢 33歳 32歳 54歳 45歳 24歳 27歳 35歳 48歳
38歳 ⾝⻑ 168cm 165cm 173cm 155cm 175cm 160cm 165cm 180cm 160cm 体重 70kg 50kg 70kg 55kg 65kg 130kg 80kg 75kg 60kg 収⼊ 400万円 600万円 550万円 800万円 300万円 500万円 250万円 700万円 1500万円 モ テ モ テ モ テ ⾮ モ テ ⾮ モ テ モ テ モ テ ⾮ モ テ ⾮ モ テ <理想的なデータの分割> データをある特徴量のある閾値で⼆分割した時, それぞれの断⽚が1種類のクラスのみから構成されている あらかじめラベルづけされたデータを⼊れて学習をおこなう
分割の判断指標 u 「どれだけ単⼀クラス構成に近いか」を不純度として定量化する u データ中に占めるクラスの構成⽐率を# としたとき,全クラス数をとして, u Gini係数 :∑#&' (
1 − # # = 1 − ∑#&' ( # , u Entropy : − ∑#&' ( # log # u いずれの指標も, u ある⼀つのクラスだけに偏っている時,最⼩値0をとる u #∗ = 1, # = 0 ( ≠ ∗) u 全クラスの構成⽐が等しい時,最⼤値log をとる u # = 1/ u 不純度が最⼩になる分割特徴量・閾値を探索する
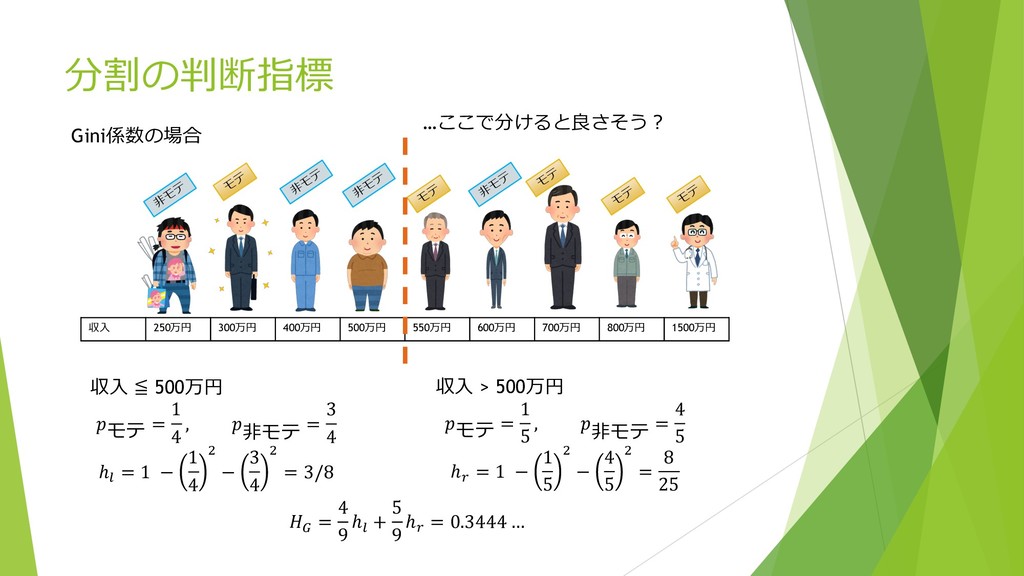
分割の判断指標 モ テ モ テ モ テ ⾮ モ テ
⾮ モ テ モ テ モ テ ⾮ モ テ ⾮ モ テ 収⼊ 250万円 300万円 400万円 500万円 550万円 600万円 700万円 800万円 1500万円 収⼊ ≦ 500万円 モテ = 1 4 , ⾮モテ = 3 4 ℎ; = 1 − 1 4 , − 3 4 , = 3/8 収⼊ > 500万円 モテ = 1 5 , ⾮モテ = 4 5 ℎ> = 1 − 1 5 , − 4 5 , = 8 25 A = 4 9 ℎ; + 5 9 ℎ> = 0.3444 … Gini係数の場合 …ここで分けると良さそう︖
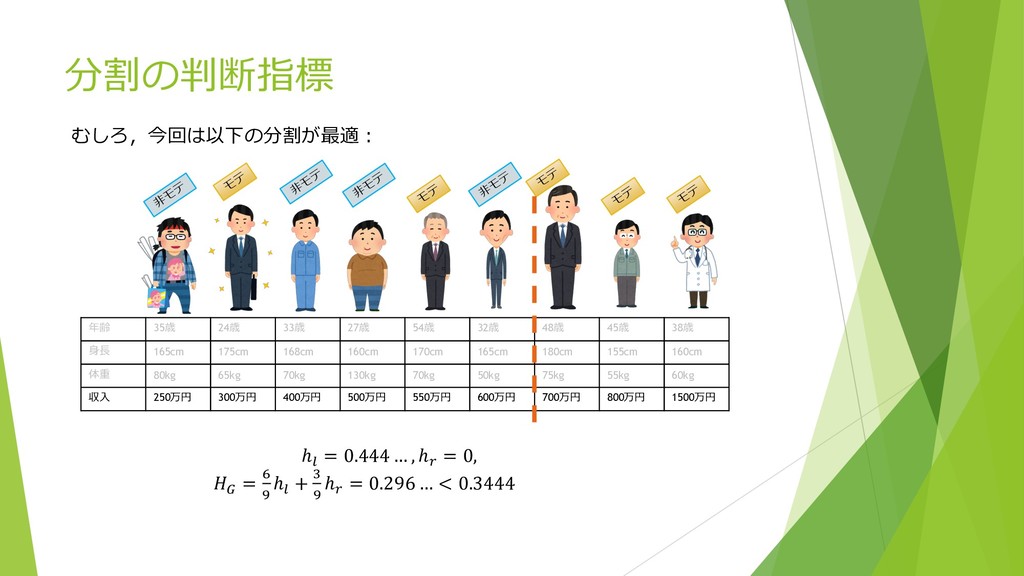
分割の判断指標 モ テ モ テ モ テ ⾮ モ テ
⾮ モ テ モ テ モ テ ⾮ モ テ ⾮ モ テ 年齢 35歳 24歳 33歳 27歳 54歳 32歳 48歳 45歳 38歳 ⾝⻑ 165cm 175cm 168cm 160cm 170cm 165cm 180cm 155cm 160cm 体重 80kg 65kg 70kg 130kg 70kg 50kg 75kg 55kg 60kg 収⼊ 250万円 300万円 400万円 500万円 550万円 600万円 700万円 800万円 1500万円 ℎ; = 0.444 … , ℎ> = 0, A = F G ℎ; + H G ℎ> = 0.296 … < 0.3444 むしろ,今回は以下の分割が最適︓
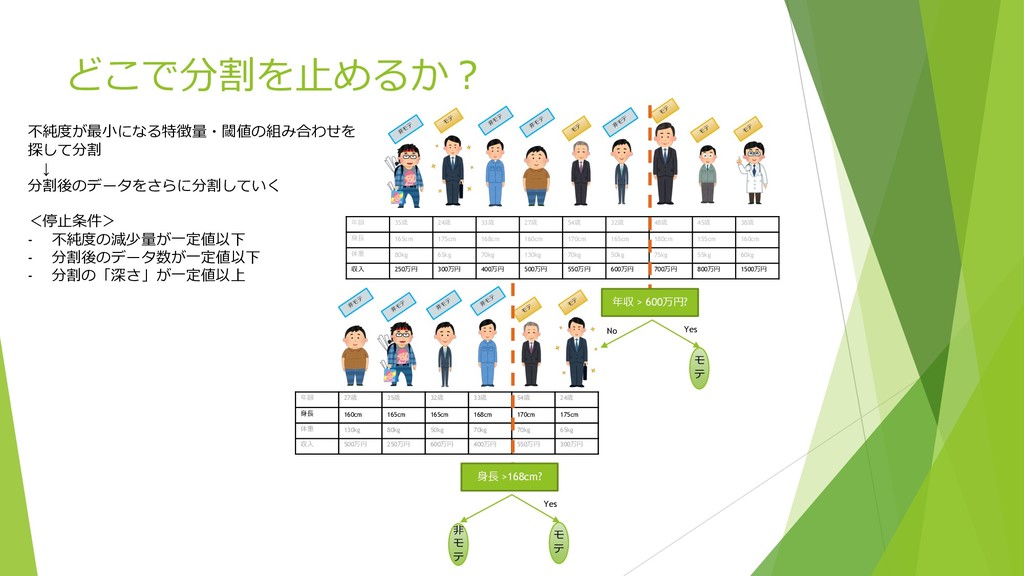
どこで分割を⽌めるか︖ モ テ モ テ モ テ ⾮ モ テ
⾮ モ テ モ テ モ テ ⾮ モ テ ⾮ モ テ 年齢 35歳 24歳 33歳 27歳 54歳 32歳 48歳 45歳 38歳 ⾝⻑ 165cm 175cm 168cm 160cm 170cm 165cm 180cm 155cm 160cm 体重 80kg 65kg 70kg 130kg 70kg 50kg 75kg 55kg 60kg 収⼊ 250万円 300万円 400万円 500万円 550万円 600万円 700万円 800万円 1500万円 年収 > 600万円? No Yes モ テ 年齢 27歳 35歳 32歳 33歳 54歳 24歳 ⾝⻑ 160cm 165cm 165cm 168cm 170cm 175cm 体重 130kg 80kg 50kg 70kg 70kg 65kg 収⼊ 500万円 250万円 600万円 400万円 550万円 300万円 ⾮ モ テ モ テ モ テ ⾮ モ テ ⾮ モ テ ⾮ モ テ ⾝⻑ >168cm? Yes モ テ ⾮ モ テ 不純度が最⼩になる特徴量・閾値の組み合わせを 探して分割 ↓ 分割後のデータをさらに分割していく <停⽌条件> - 不純度の減少量が⼀定値以下 - 分割後のデータ数が⼀定値以下 - 分割の「深さ」が⼀定値以上
ランダムフォレスト
ランダムフォレスト概要 u 決定⽊の⽋点 u 学習データに強く依存する u ⽊を⼤量に集めて多数決を⾏う u 決定⽊よりは性能の劣る「弱学習器」を⼤量に作る u
弱学習器の構築指針 u 学習に使うデータを変える u ブートストラップサンプリング u 分割につかう特徴量を変える u 全特徴量は使わず,⼀部のみ使⽤する u 分割ごとにランダムに選択する
ブートストラップサンプリング u データをランダムに選択して新しいデータセットを量産する u 重複を許す(復元抽出) モ テ ⾮ モ テ
⾮ モ テ モ テ モ テ ⾮ モ テ ⾮ モ テ ⾮ モ テ ⾮ モ テ モ テ モ テ モ テ ⾮ モ テ モ テ モ テ モ テ ⾮ モ テ ⾮ モ テ ・・・
特徴量のランダム選択 u 分割の際に,⼀部のランダムに選んだ特徴量のみを⾒る モ テ ⾮ モ テ ⾮ モ
テ モ テ モ テ ⾮ モ テ ⾮ モ テ ⾮ モ テ ⾮ モ テ 年齢 24歳 27歳 33歳 45歳 54歳 35歳 32歳 35歳 27歳 ⾝⻑ 175cm 160cm 168cm 155cm 170cm 165cm 165cm 165cm 160cm 体重 65kg 130kg 70kg 55kg 70kg 80kg 50kg 80kg 130kg 収⼊ 300万円 500万円 400万円 800万円 550万円 250万円 600万円 250万円 500万円
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}