https://www.youtube.com/live/j1KGQHlHJ5E
競技プログラミングにおいて,定数倍高速化は TLE を回避するための重要な技術である.定数倍高速化により,想定より遅いオーダーの解法を通したり,作問時にそれを防ぐことができたりする.もちろん,競技プログラミング以外の一般のプログラミングにおいても,定数倍高速化はプログラムの質に関わる重要な技術である.
本講義では,
- 計算の仕組み
- 命令の速さ
- コンパイラによる最適化
- アセンブラ
- メモリアクセスの仕組み
- ベクトル化
などのトピックを定数倍高速化の観点から扱い,C++ での様々な定数倍高速化のテクニックを教える.プログラムの定数倍を予想・改善できるようになることが,本講義の目標である.
#### 前提知識 (なくても得るものはあると思います)
- C++ のプログラミング経験
- 競技プログラミングの経験
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[高度なテク] 定数倍でボトルネックを知る 四則演算,ビット演算など色々な演算の速度 コンパイラによる最適化 メモリアクセスの速度 体感のデータ構造の速度 メモリ確保の速度 入出力の速度 などからプログラムの定数倍を知る 31](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
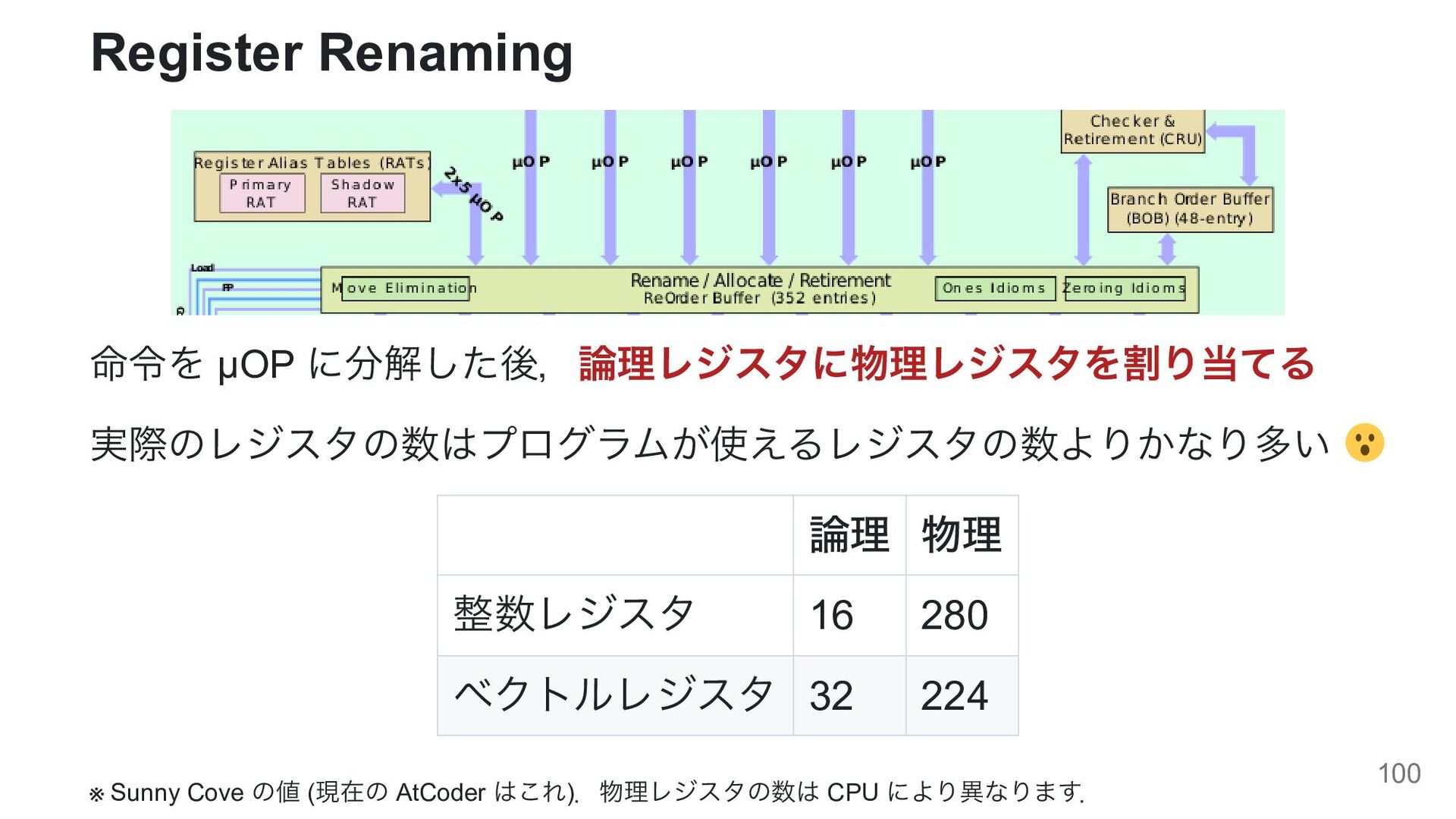{kind=link}
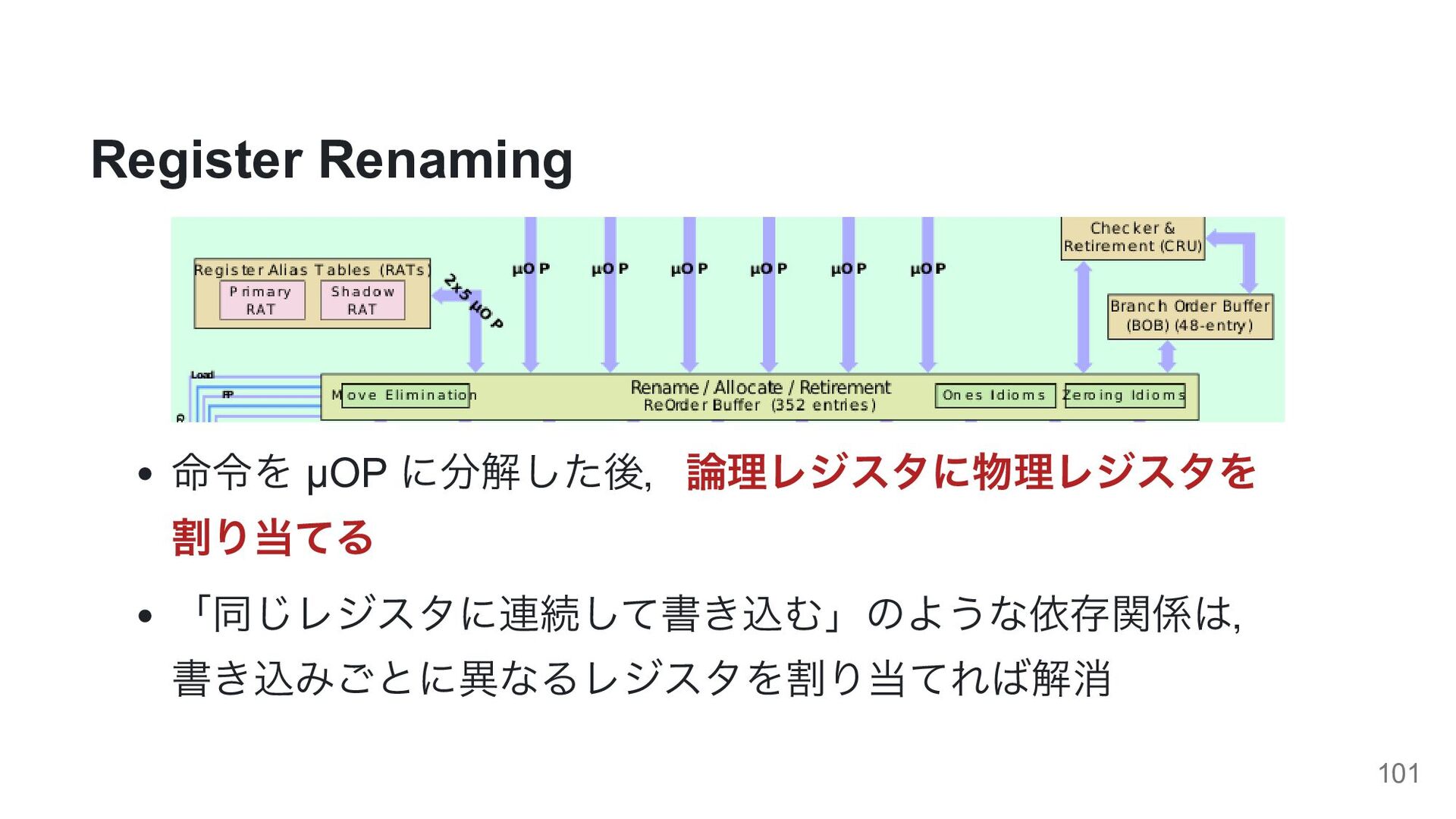{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ヒント のワーシャルフロイド法 の入力生成部分は無視できる A はシーケンシャルアクセス B は配列が転置されていて, A[j][i] , A[j][k]](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_145.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実は,簡単にもっと遅くすることができる 配列の大きさを 2 冪に揃えるだけ u64 A[1000][1000]; → u64 A[1024][1024]; が左シフトに変わって高速化するのでは](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_151.jpg){kind=link}
![u64 A[1000][1000]; のとき, rep(j, 1000) A[j][k] は ライン間隔のメモリアクセスを 回 →](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_152.jpg){kind=link}
![実測 u64 A[1024][1024]; にするだけでさらに 倍 の差がついた! = 1678 ms](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_153.jpg){kind=link}
{kind=link}
![どうしてもシーケンシャルアクセスにできないとき 行列の転置 u64 A[3000][3000]; rep(i, 3000) rep(j, i) { swap(A[i][j],](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_155.jpg){kind=link}
![A[0][0] A[0][7] A[7][0] A[7][7] これは シーケンシャルアクセス 157](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_156.jpg){kind=link}
![A[0][0] A[0][7] A[7][0] A[7][7] これは シーケンシャルアクセス ではない 158](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_157.jpg){kind=link}
![A[0][0] A[0][7] A[7][0] A[7][7] じゃあこれは…? 159](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_158.jpg){kind=link}
![A[0][0] A[0][7] A[7][0] A[7][7] 縦方向のアクセス → シーケンシャルアクセスでは ない…? 短い期間内に横方向に 連続してアクセス](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_159.jpg){kind=link}
![A[0][0] A[0][7] A[7][0] A[7][7] ブロック化 A[i][j] の の範囲と の範囲を いくつかのブロックに分け,](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_160.jpg){kind=link}
![A[0][0] A[0][7] A[7][0] A[7][7] ブロック化 キャッシュに乗るくらいの 大きさのブロックに 切り分け,ブロックごとに 転置するだけで転置が 高速化される!](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_161.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![例 u32 A[8]; rep(i, 8) A[i] = 1; ↓ コンパイル](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_179.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![コンパイラに任せよう 1. 並列化しやすいようにプログラムを書く A[i] += B[i]; のように, シーケンシャルアクセスで同じ操作をするコードを書く AVX-512 の命令一覧を見て,それにコンパイルできそうな](https://files.speakerdeck.com/presentations/1bf812bcbcf644aeaac4872e2f761f98/slide_191.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}