просто Но не всегда… Зависит от языка текста 13 «Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz» « Закон о передаче обязанностей контроля маркировки говядины»
«?!.» В связи с этим первый интервал пробегов был принят равным 350...700 тыс. км. (середина интервала - 525 тыс. км.), второй интервал - 700...1050 тыс. км. (середина интервала - 875 тыс. км.) и третий интервал 1050...1400 тыс. км. (середина интервала -- 1225 тыс. км.).
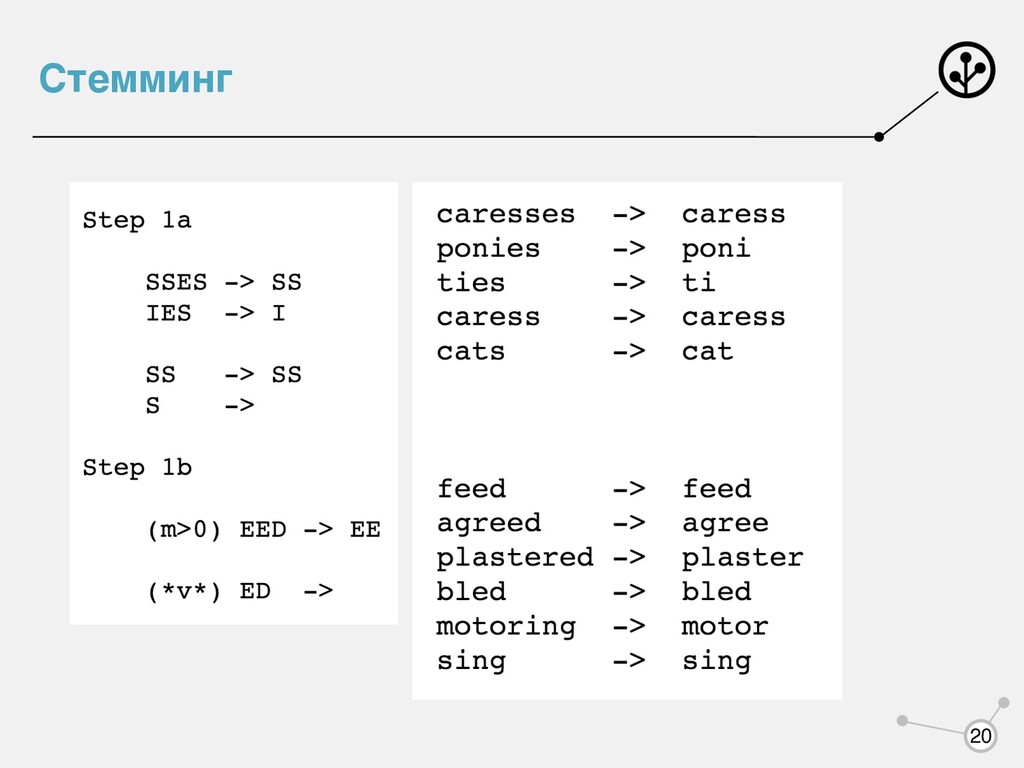
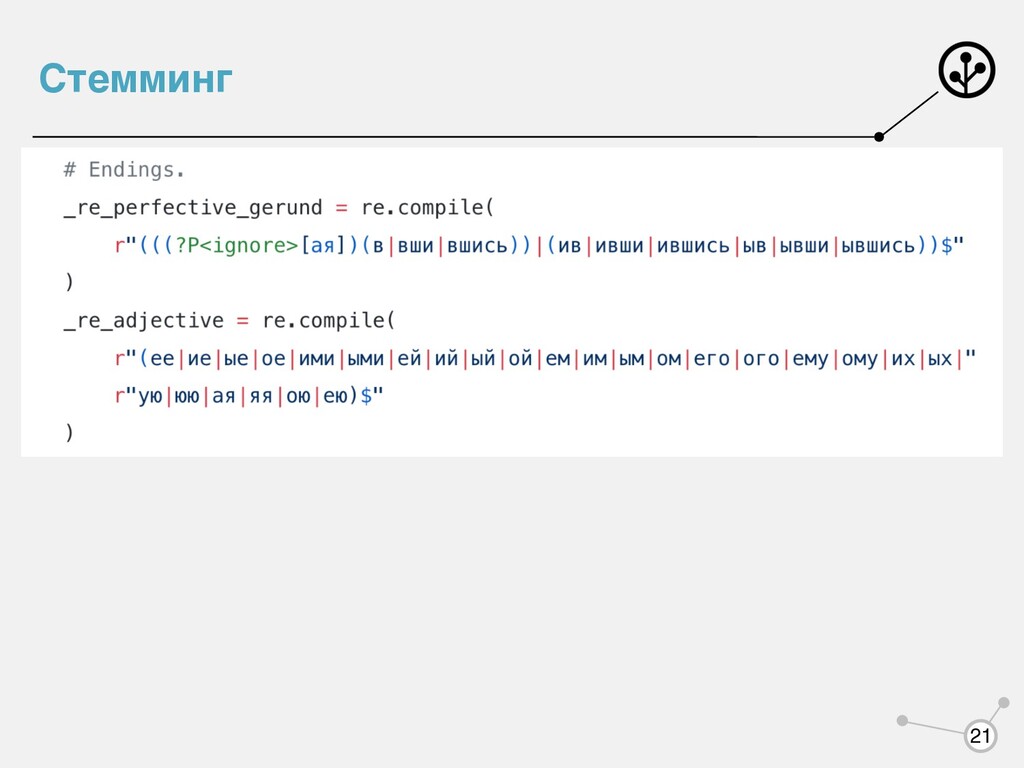
• Предложение должно начинаться с заглавной буквы • Сокращения требуют «особого внимания»: г., тыс., млн., ул., км., • Отдельные большие буквы тоже: А.Б. Иванов • … Но можно учить токенизатор на предложения с помощью ML с учетом специфики корпуса
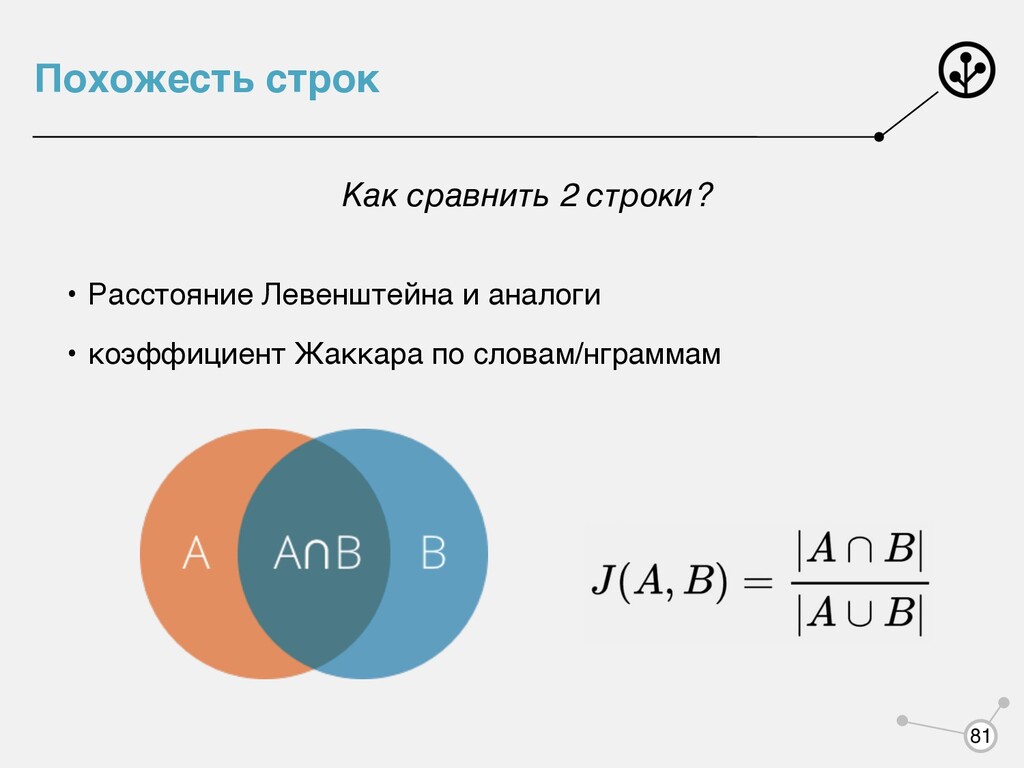
и полнотой поиска, если применить стемминг? - полнота возрастет (схлопнем разные словоформы в одну) - точность может пострадать (если приведем разные слова к одному стему: лев, левый -> лев)
слова в документе (one-hot-encoding) Предположим, что мы обрабатываем коллекцию документов Q: Как будет выглядеть представление документа? A: Вектор с размерностью, равной количеству уникальных слов в коллекции 27
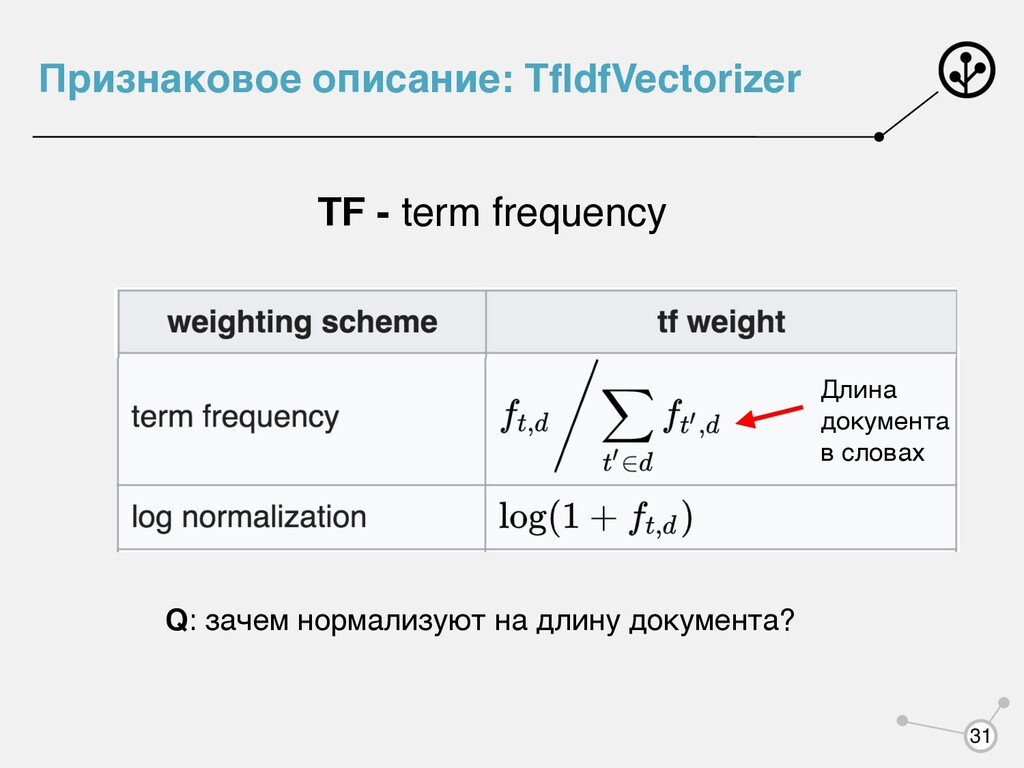
тем оно важнее Давайте хранить не бинарный признак, а счетчик (сколько раз слово встретилось в документе). Q: Как будет выглядеть представление документа в этом случае? A: Так же, как и ранее
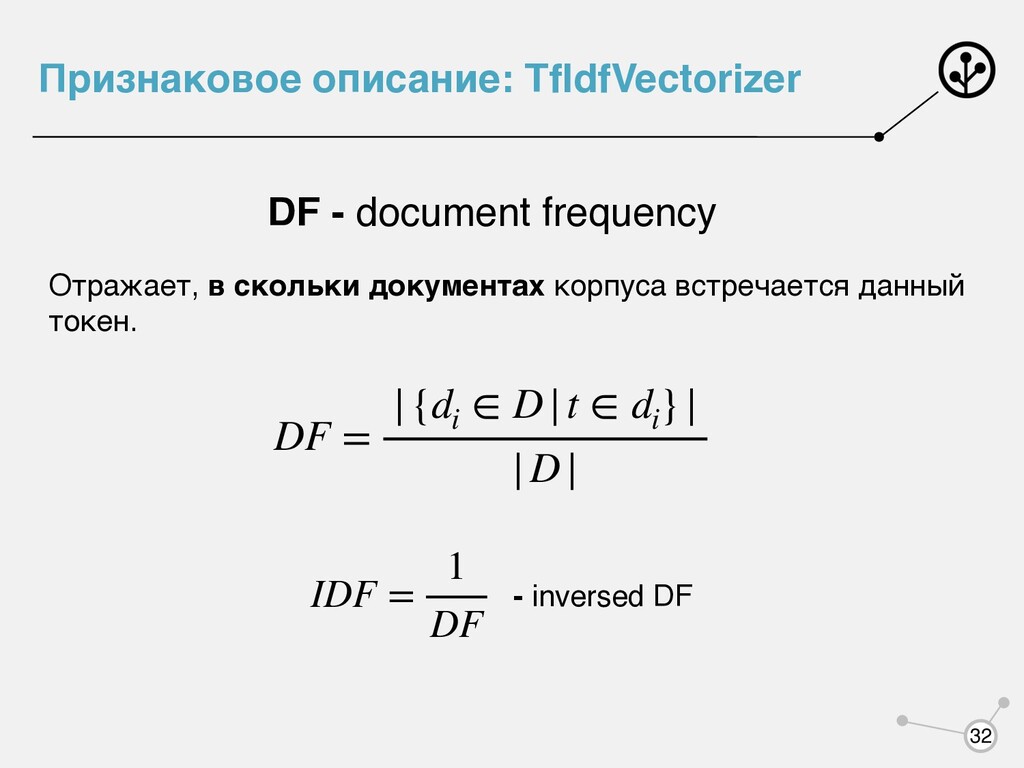
корпуса, но не тему документа. Слишком редкие слова - можно рассматривать как шум. Наиболее информативные слова - встречающиеся довольно часто в относительно небольшом количестве документов.
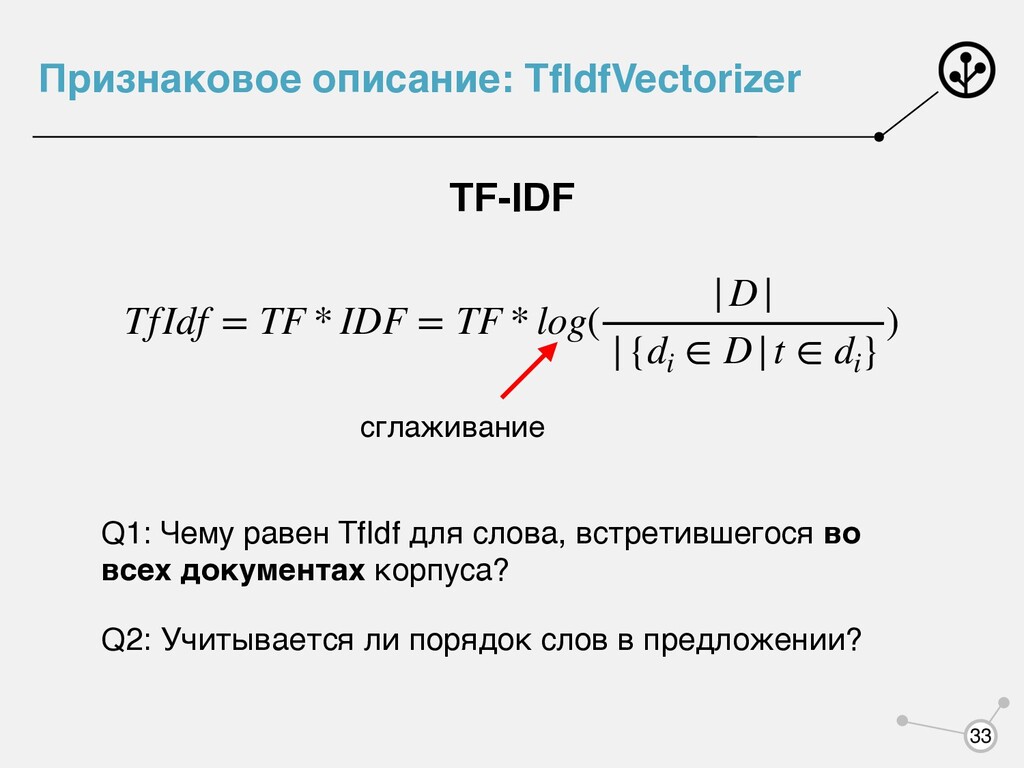
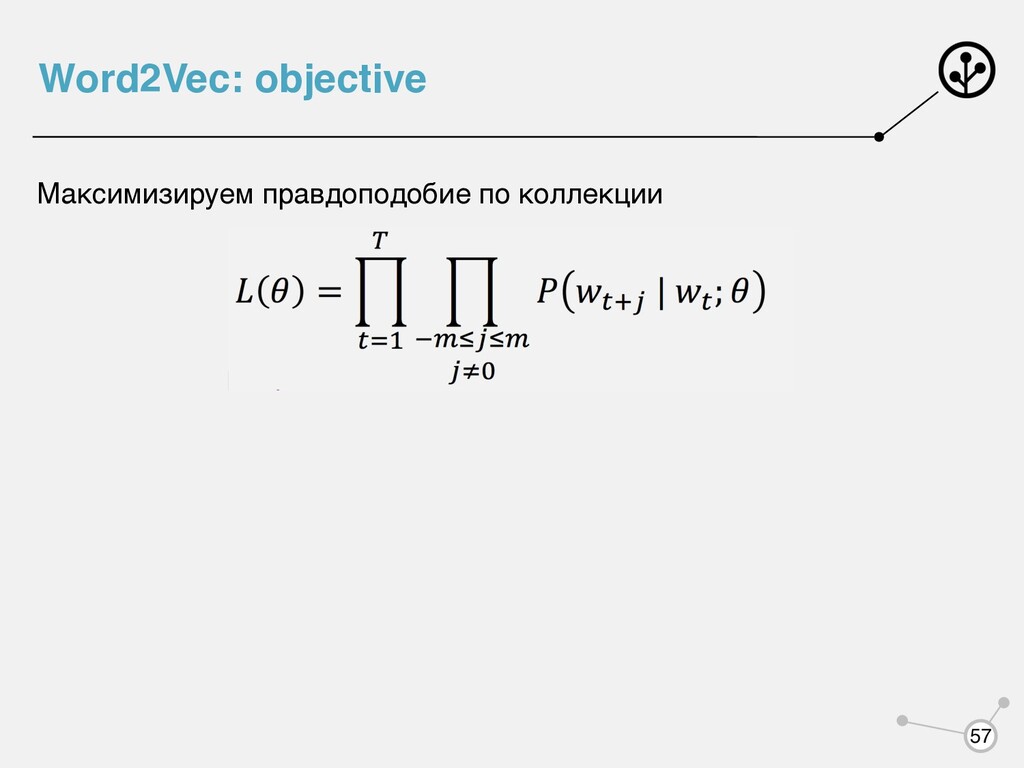
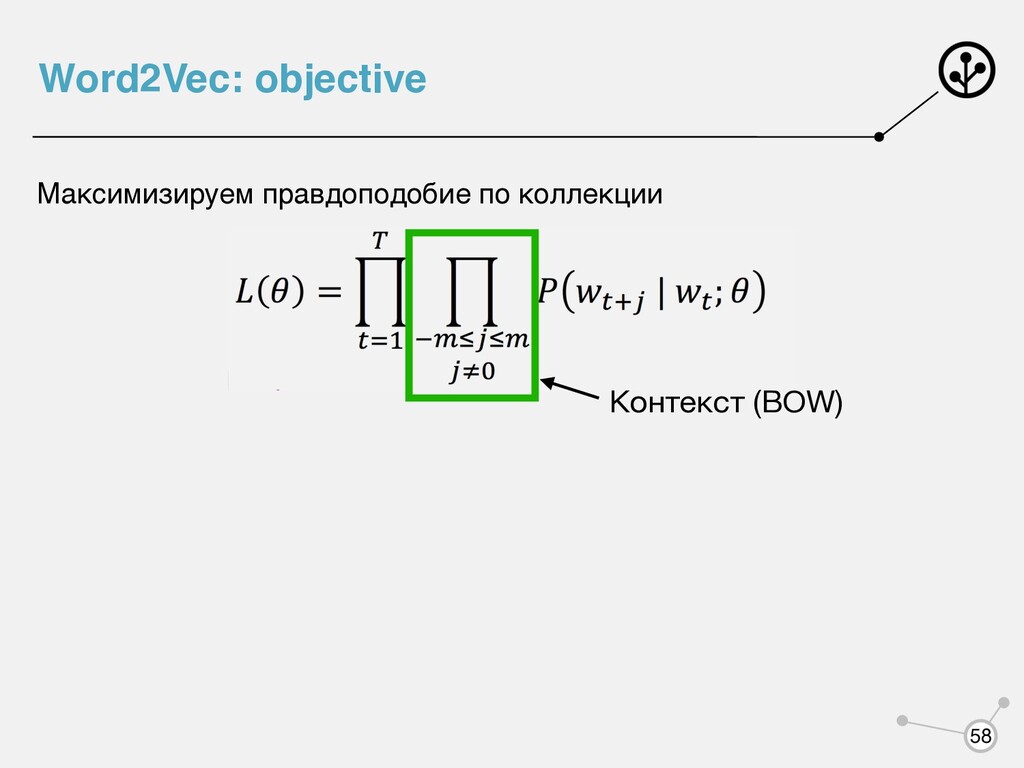
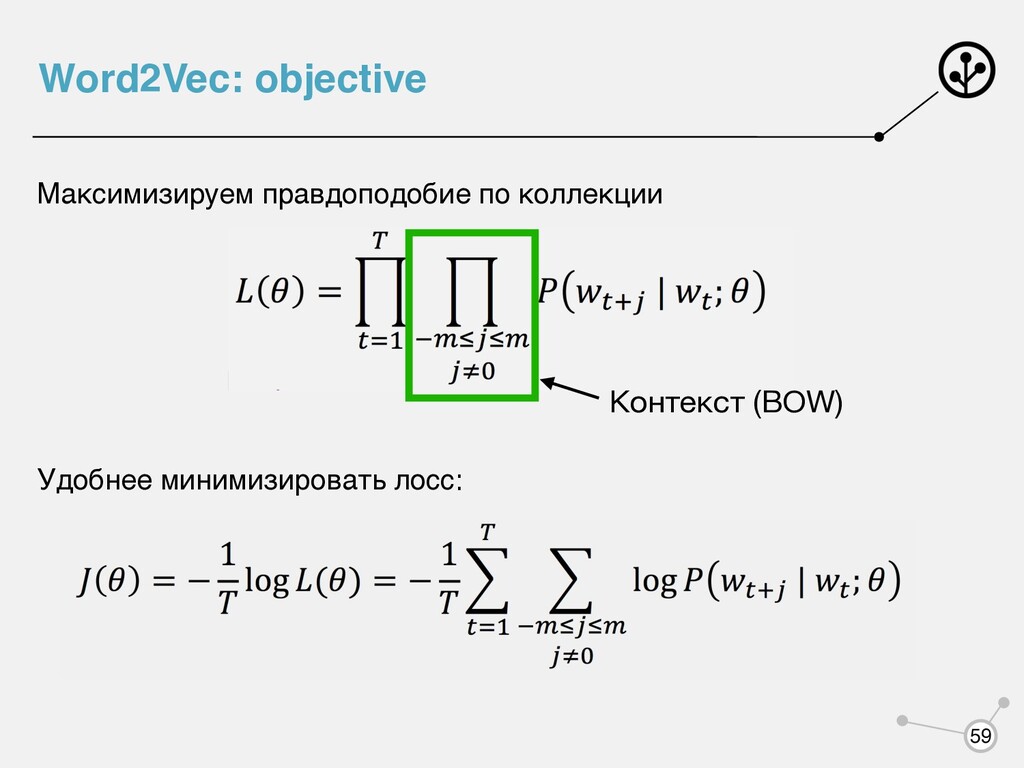
= TF * log( |D| |{di ∈ D|t ∈ di } ) Q1: Чему равен TfIdf для слова, встретившегося во всех документах корпуса? сглаживание Q2: Учитывается ли порядок слов в предложении?
(BOW) 1) «Мне нравится, что вы больны не мной» 2) «Мне не нравится, что вы больны мной» Один и тот же вектор для обоих предложений Q: Как можно подкостылить, чтобы учитывать порядок слов?
Мешок слов + n-грамм 1) «Мне нравится, что вы больны не мной» 2) «Мне не нравится, что вы больны мной» Q: Чем плох такой подход? A: Размерность вектора возрастает на порядки
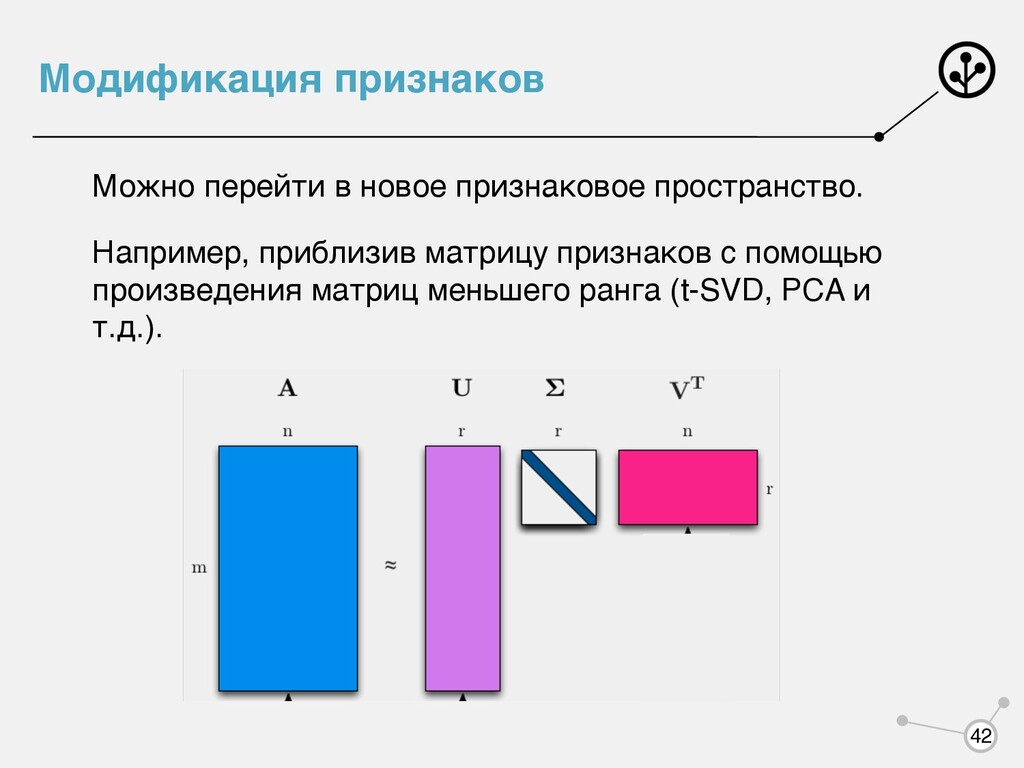
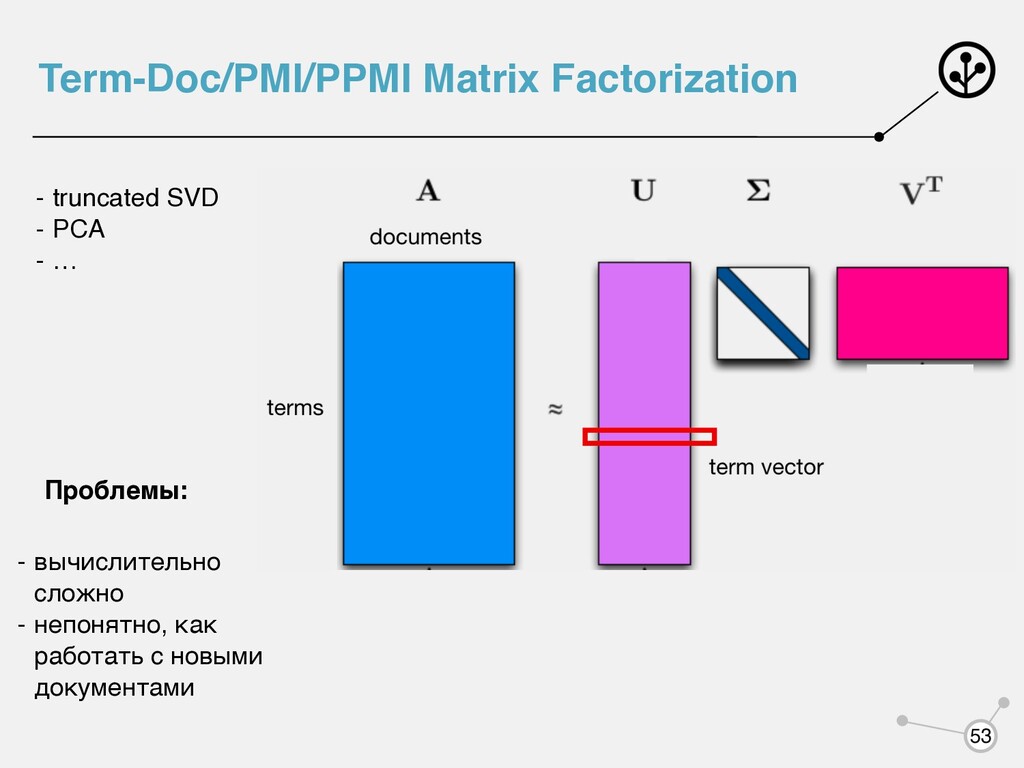
n-граммами Однако это не решает проблему в полной мере. Признаков все равно может быть очень много Пути решения: - отобрать максимально информативные признаки - перейти в новое признаковое пространство
А: Например, l1-регуляризацию. Регулируя величину коэффициента, можно регулировать количество признаков, которые нужно оставить Есть также методы жадного добавления/удаления признаков, основанные на взаимной информации, статистике и т.п.
пространство за счет хеширования признаков исходного пространства • Выбираем количество новых признаков (К bucket’ов для хеш-функции) • Выбираем хеш-функцию, отображающую признак на число [0..K] • Хешируем каждый признак исходного пространства • … • Profit!
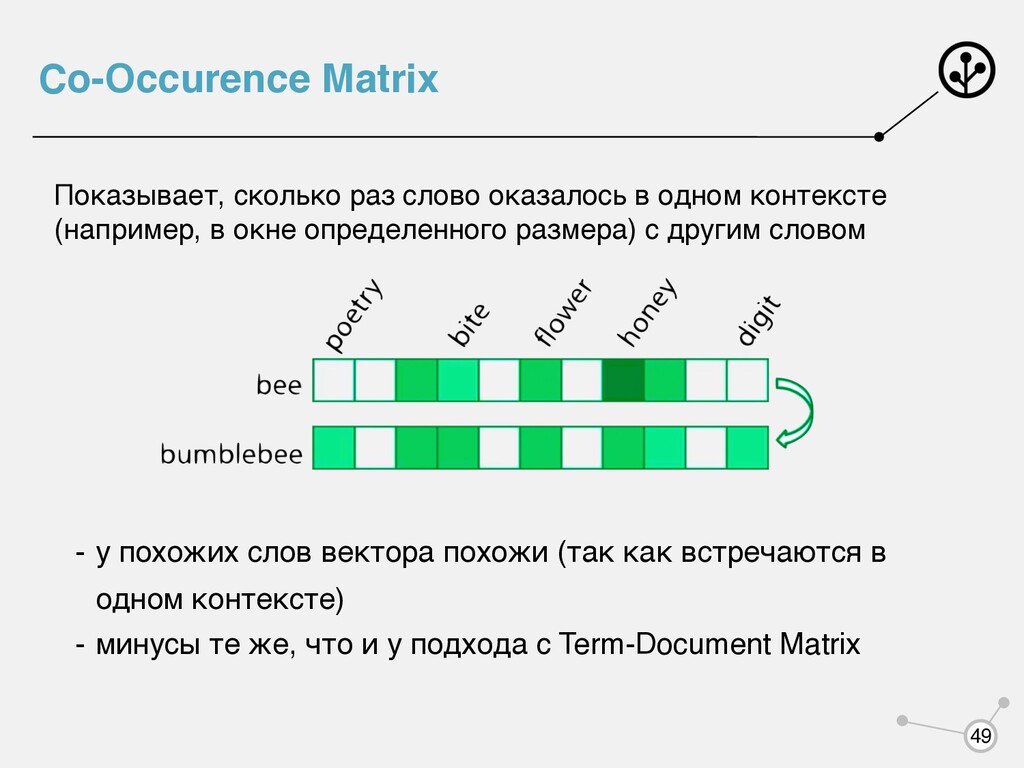
контексте (например, в окне определенного размера) с другим словом - у похожих слов вектора похожи (так как встречаются в одном контексте) - минусы те же, что и у подхода с Term-Document Matrix
случае, если слова встречаются независимо друг от друга? PMI - pointwise mutual information PMI(w, c) = p(w, c) p(w) ⋅ p(c) PMI(w, c) = log( p(w, c) p(w) ⋅ p(c) )
его контекстами Слова похожи по смыслу, если встречаются в похожих контекстах - Я люблю тяжелую и ритмичную Х. - Какую Х вы предпочитаете слушать во время бега ? - Группа «Bullet For My Valentine» играет Х в стиле extreme-metal. Никаких затруднений восстановить пропуск - контекст определяет слово
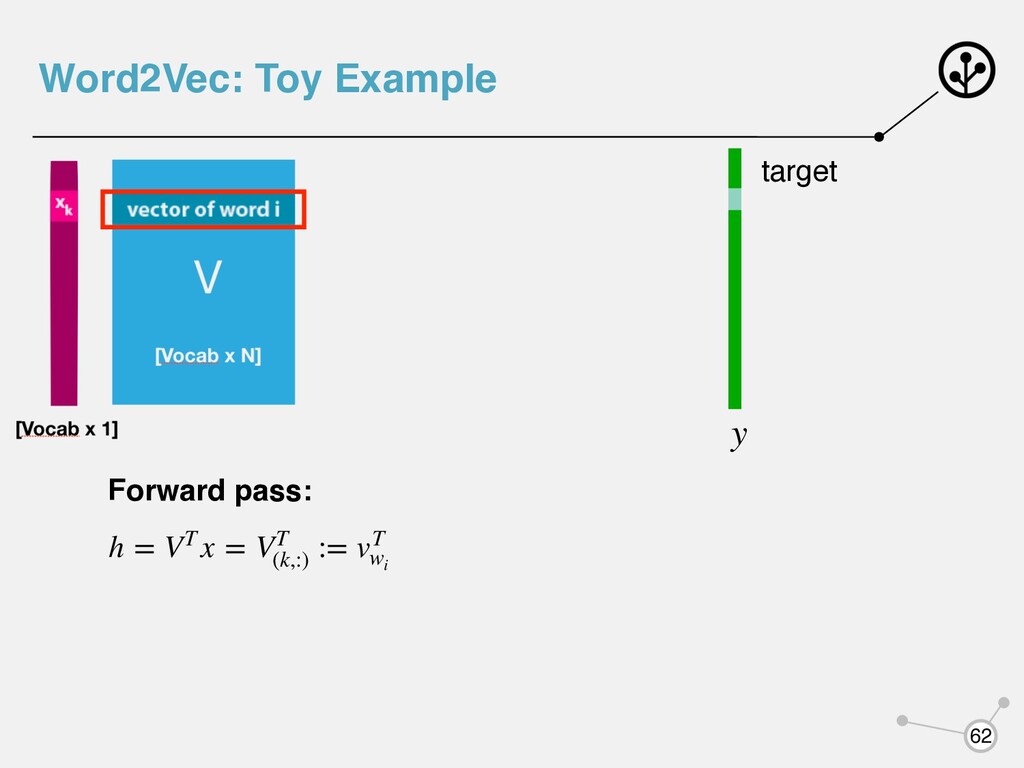
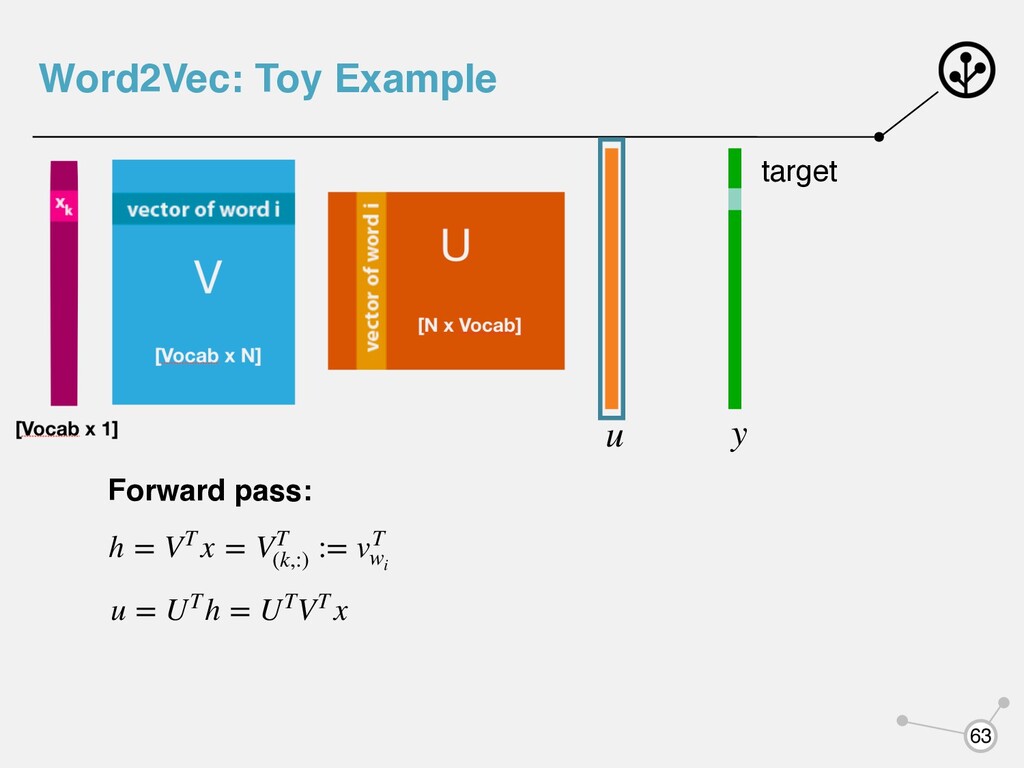
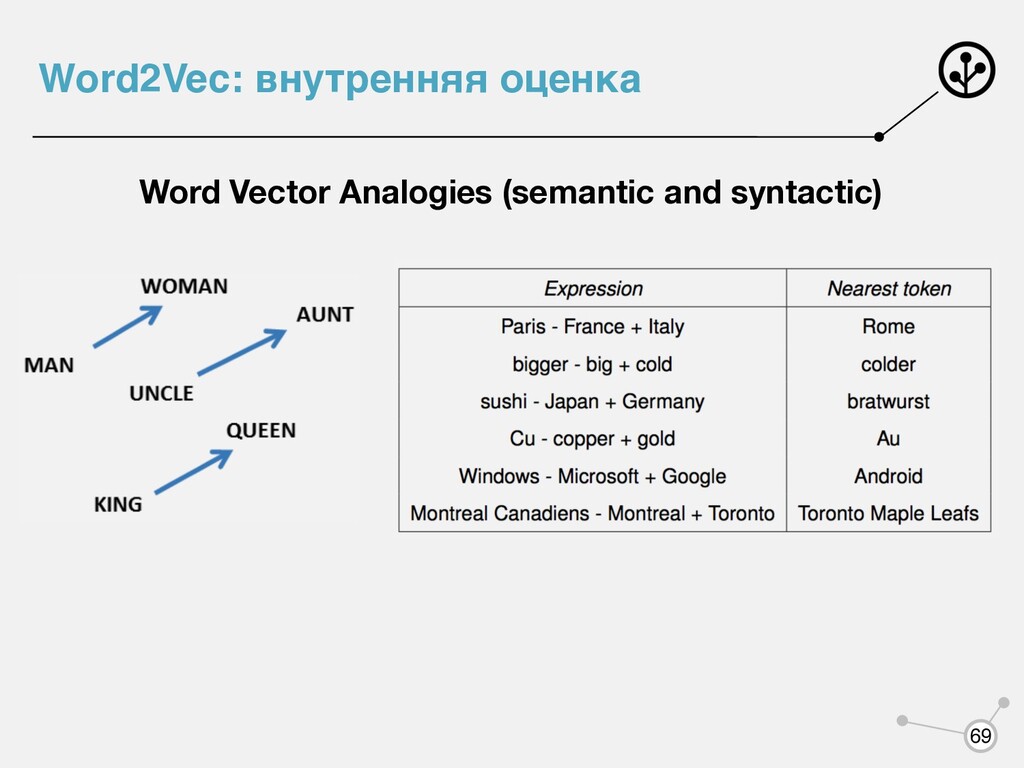
- каждому слову соответствует векторное представление - каждое слово выступает в двух ипостасях: как центральное и контекстное - будем использовать для каждого слова два вектора: vw uw - когда слово w - центральное - когда слово w - контекстное uT c ⋅ vt - чем больше, тем выше вероятность встретить в контексте wt wc
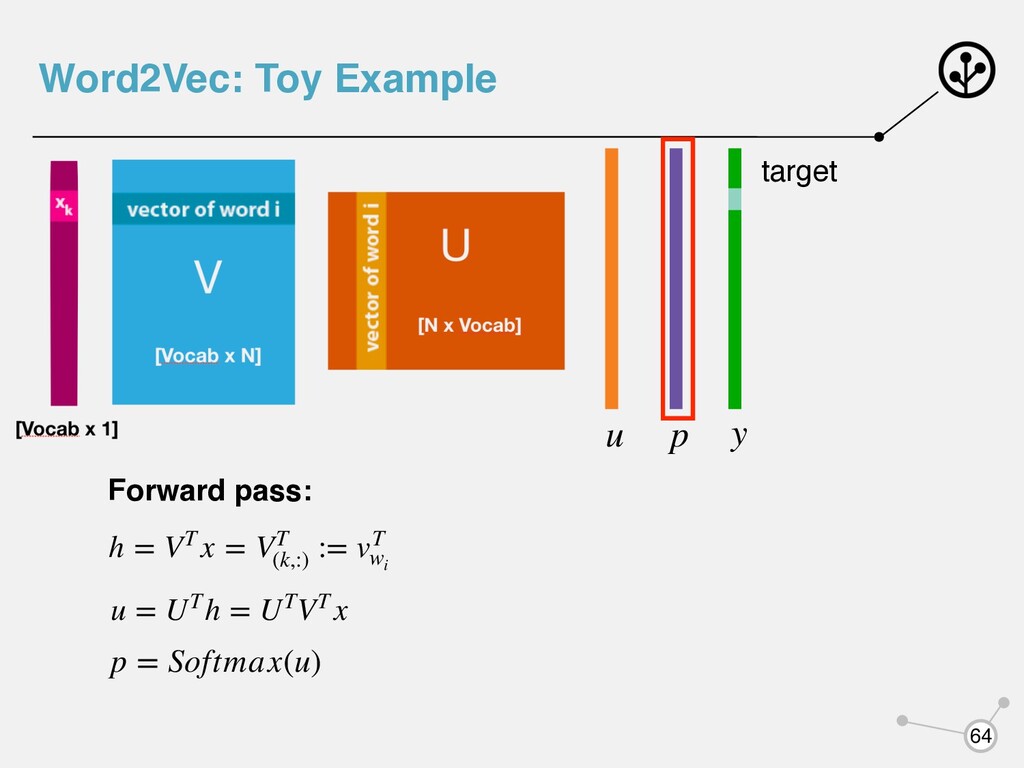
- каждому слову соответствует векторное представление - каждое слово выступает в двух ипостасях: как центральное и контекстное - будем использовать для каждого слова два вектора: vw uw - когда слово w - центральное - когда слово w - контекстное uT c ⋅ vt - чем больше, тем выше вероятность встретить в контексте wt wc Нормализуют с помощью Softmax P(wc |wt ) = exp(uT c ⋅ vt ) ∑ w∈V exp(uT w ⋅ vt )
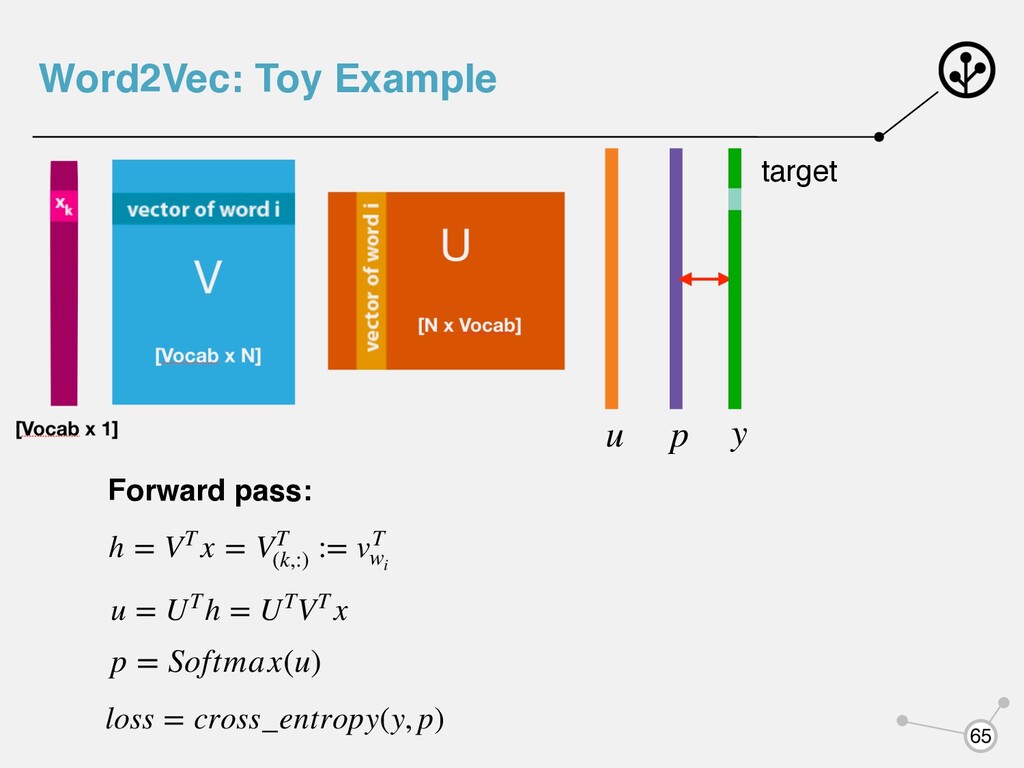
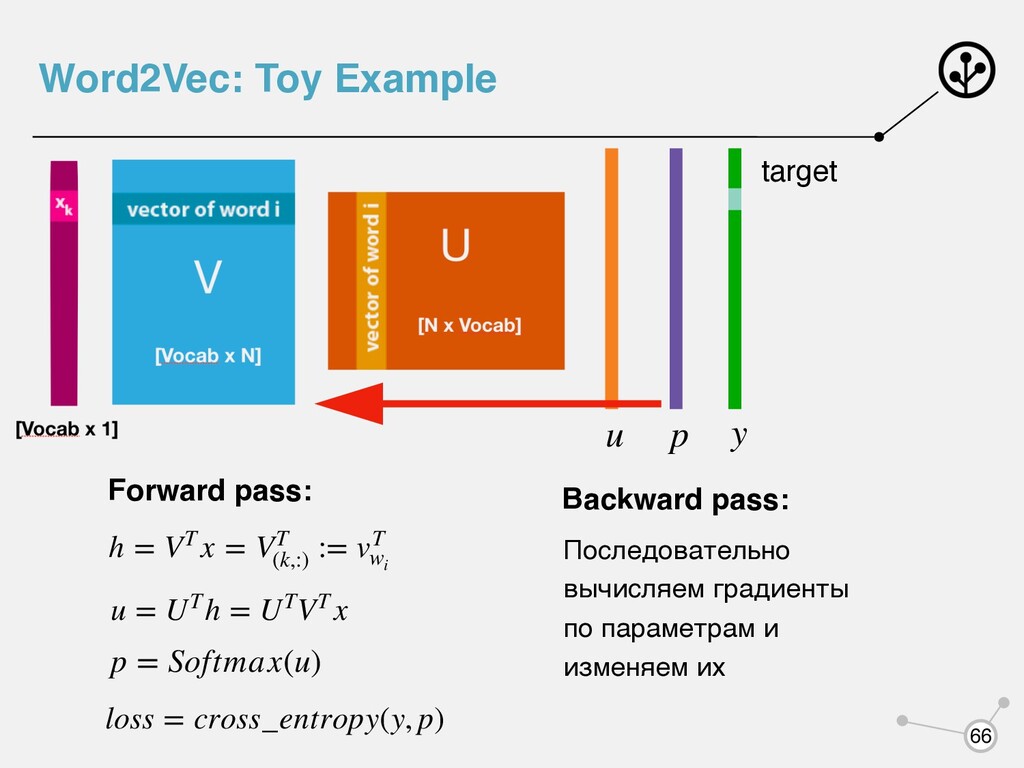
VT (k,:) := vT wi u = UTh = UTVT x p = Softmax(u) loss = cross_entropy(y, p) target y Backward pass: Последовательно вычисляем градиенты по параметрам и изменяем их Word2Vec: Toy Example
vt ) ∑ w∈V exp(uT w ⋅ vt ) суммирование по всему словарю Считать честный софтмакс дорого - Или применяют SkipGram Negative Sampling (SGNS): учим модель отличать слова из контекста от рандомно взятых из словаря. Можно использовать различные аппроксимации софтмакса, например, Hierarchical Softmax
«в вакууме» на вспомогательной подзадаче - не коррелирует с продуктовыми метриками - быстро Extrinsic evaluation («внешняя» оценка): - на реальной задаче - долго - если работает плохо, то непонятно, что именно
сессиях просмотров пользователей, завершившихся бронированием • негативные примеры из того же географического района • эмбеддинги для новых объектов - усреднение 3х ближайших на карте (с тем же типом недвижимости и диапазоном цен) • +21% CTR в карусели «Похожие»; +4.9% к сессиям, завершившихся бронированиями
в почте • user2product и product2product модели • +9% CTR относительно других форматов; сравнимые конверсии в покупки https://arxiv.org/pdf/1606.07154.pdf
мешка символьных n-грамм разного порядка • Учим эмбеддинги для каждой n-граммы вместе со словами • Суммируем эмбеддинги для всех n-грамм слова и выученного вектора слова и получаем результирующий эмбеддинг слова
словесные нграммы тоже хеширует (причем, в те же бакеты) • Слова не хешируются • soft-sliding window - рандомно сэмплируется размер окна из равномерного распределения • Учится с SGNS аналогично Word2Vec • Можно учить вектора supervised • Можно получить сжатую версию модели (весит меньше на порядок с минимальной деградацией качества)
на другой, необходимых для превращения одной строки в другую (веса операций могут отличаться). Q: За какое количество операций вы превратите воду в вино? Расстояние Левенштейна
на другой, необходимых для превращения одной строки в другую (веса операций могут отличаться). Q: За какое количество операций вы превратите воду в вино? Добавляется операция транспозиции (перестановки) соседних символов Расстояние Дамерау-Левенштейна Расстояние Левенштейна
определяем дубликаты по порогу - … - Profit! - надо сравнить все пары между собой - число пар растет квадратично с увеличением размера корпуса Недостатки Было бы хорошо отделить потенциальных дубликатов и проверить их более тщательно
хешей от шинглов. • Уменьшим количество шинглов • Нет необходимости хранить словарь • Можем вычислять «на лету» • Можем корректно работать с новыми последовательностями
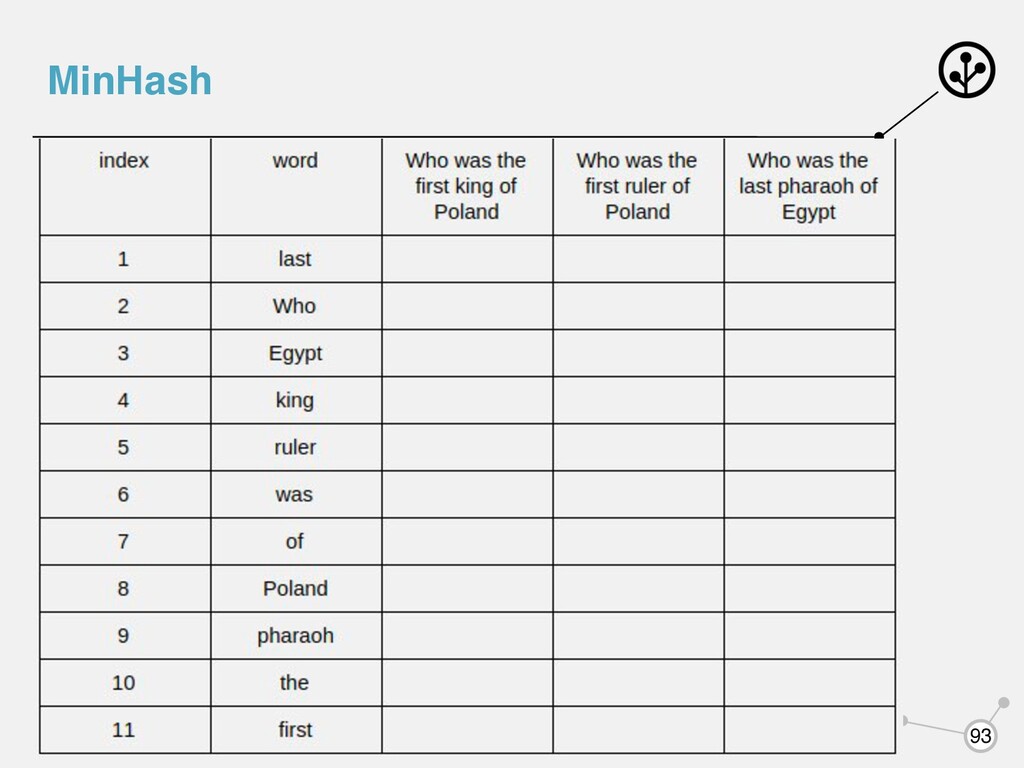
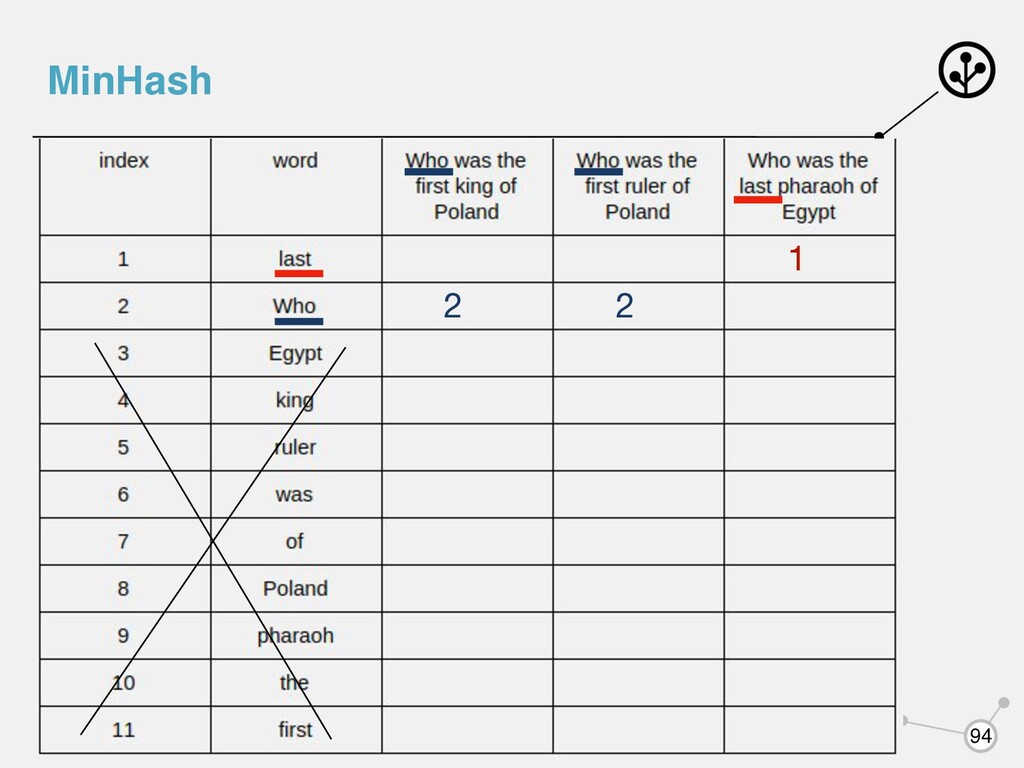
документов получившиеся последовательности (сигнатуры) Signature(“Who was the first king of Poland”) = [2, 1, 1, 3, 1, 1] Signature(“Who was the first ruler of Poland”) = [2, 1, 1, 1, 1, 1] Signature(“Who was the last pharaoh of Egypt”) = [1, 1, 3, 4, 4, 1]
для документов получившиеся последовательности (сигнатуры) Signature(“Who was the first king of Poland”) = [2, 1, 1, 3, 1, 1] Signature(“Who was the first ruler of Poland”) = [2, 1, 1, 1, 1, 1] Signature(“Who was the last pharaoh of Egypt”) = [1, 1, 3, 4, 4, 1] Можем посчитать коэффициент Жаккара между сигнатурами:
Жаккара между шинглированными документами Чем больше операций переиндексации словаря мы делаем - тем точнее оценка Перемешивание словаря не очень эффективно: - надо хранить словарь - надо хранить перестановки Идейно - слову надо сопоставить рандомную чиселку
хеш-функцию (каждый раз разную) - применять ее ко всем шинглам документов - характеризовать документ минимальным хешем (MinHash) из получившихся Работает так же концептуально, но лучше: • не надо хранить словарь • можно работать с элементами вне словаря • запоминаем только набор хеш-функций
документов - выяснили, что коэффициент Жаккара для минхэш- сигнатур - аппроксимация честного коэффициента Жаккара по шинглам Но пар документов все так же много…
= [211, 311] Doc2 = [2, 1, 1, 1, 1, 1] = [211, 111] Doc3 = [1, 1, 3, 4, 4, 1] = [113, 441] Давайте разобьем полученные сигнатуры на группы по 3 элемента Заметим, что околодубликаты имеют общую группу Оценим вероятность того, что для похожих документов (Doc1 и Doc2) будет хотя бы одна общая группа
Жаккара между документами: P1 = J12 = 0.75 2) Вероятность совпадения всех минхэшей в группе из 3х элементов: P2 = P3 1 = J3 12 = 0.753 ≈ 0.42 3) Вероятность несовпадения хотя бы 1 пары минхэшей в группе из 3х элементов: P3 = 1 − P2 = 1 − J3 12 ≈ 0.58
по n элементов в каждой. Вероятность того, что документы имеют хотя бы одну общую группу из n элементов: Psim = 1 − (1 − Jn)b Чем больше размер группы - тем точнее склеиваем дубликаты, но теряем в покрытии b ↑ ⇒ fp ↓ ; fn ↑ b ↓ ⇒ fp ↑ ; fn ↓
которого считают документы дубликатами. Затем подбирают количество групп разбиения n и размер группы b, исходя из следующего правила. b ⋅ n = const t ≈ 1 b 1 n
лучше - хеши от них) в качестве ключей для хэш-таблицы. В качестве значений, например, id документа Doc1 = [211, 311] Doc2 = [211, 111] Doc3 = [113, 441]
лучше - хеши от них) в качестве ключей для хэш-таблицы. В качестве значений, например, id документа Doc1 = [211, 311] Doc2 = [211, 111] Doc3 = [113, 441] 211 111 113 311 441 Doc2 Doc3 [Doc1, Doc2 ] Doc1 Doc3 Потенциальные дубликаты попадают в один бакет
документов заранее, составляем таблицу - обрабатываем запрос тем же самым образом, что и корпус - шинглирование, - формирование минхэш-сигнатуры теми же хэш- функциями - разбивка сигнатуры запроса на супершинглы - используем хэши от супершинглов в качестве ключей - ищем в таблице элементы по таким ключам - если нашли - с большой вероятностью это околодубликаты
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![LSH 105 Doc1 = [2, 1, 1, 2, 1, 1]](https://files.speakerdeck.com/presentations/027a416e525142d0963825102f83f631/slide_104.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}