Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
TTデバイスで大規模計算
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Tenstorrent Japan
May 17, 2026
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
TTデバイスで大規模計算
Tenstorrent Tech Talk #7, Session1
Tenstorrent Japan
May 17, 2026
More Decks by Tenstorrent Japan
See All by Tenstorrent Japan
TTデバイス間通信を支えるTT-Fablic解説 Part1
tenstorrent_japan
0
220
TT Korea OSS Program Overview
tenstorrent_japan
0
170
RISC-V CPU「TT-Ascalon」
tenstorrent_japan
0
410
TT OSS Developer Program in Japan
tenstorrent_japan
0
650
TT-NN 概要 ~内部実装の概説
tenstorrent_japan
0
240
TTNNモデル実装 実践編 ~PytorchモデルのTTNN移植から最適化まで~
tenstorrent_japan
0
230
お外でBlackhole
tenstorrent_japan
1
380
Go Out with Blackhole
tenstorrent_japan
0
380
RVV1.0で遊ぼうと思ったら Blackholeを買っていた話
tenstorrent_japan
0
390
Featured
See All Featured
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
310
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
260
How to Talk to Developers About Accessibility
jct
2
280
Docker and Python
trallard
47
3.9k
Git: the NoSQL Database
bkeepers
PRO
432
67k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
WCS-LA-2024
lcolladotor
0
670
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Embracing the Ebb and Flow
colly
88
5.1k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.4k
Transcript
TTデバイスで大規模計算 YOSHIFUJI Naoki (Tenstorrent, FAE) @Tenstorrent Tech Talk #7 (2026/04/20)
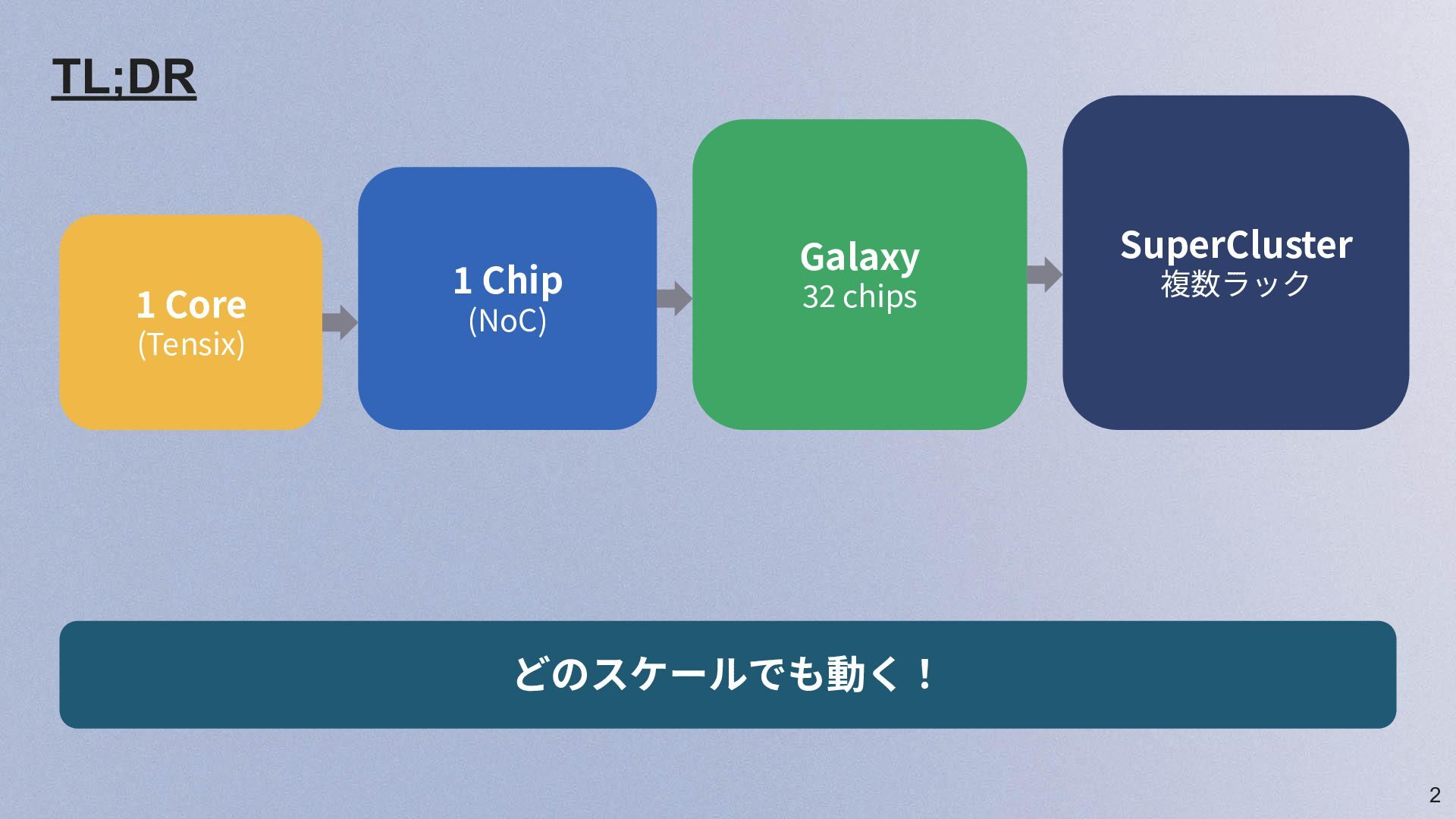
2 1 Core (Tensix) 1 Chip (NoC) Galaxy 32 chips
SuperCluster 複数ラック どのスケールでも動く! TL;DR
自己紹介 吉藤 尚生 YOSHIFUJI Naoki (@LWisteria) (Online avatar) [主な業績] •
『実践的パフォーマンスエンジニアリングによるAI高速化』筆頭編 著者 • LLM/AIの事業立ち上げ・展開 • HWの特性を活かしたSW開発・高速化の支援 • HPC・LLM・計算土木力学分野にて論文投稿・学会発表 • テンストレントジャパン Field Application Engineer (2026-) • フィックスターズ リードエンジニア・ディレクター (2013-2025) ◦ LLM事業推進室 室長 (2023-2024) ◦ パフォーマンスエンジニアリング・ラボ ラボ長 (2025) 3
目次 1. 全体構成 2. ハードウェア 1. Tensixコア 2. NoC 3.
Ethernetコア 4. 外部接続ケーブル 5. Galaxy 6. SuperCluster 3. ソフトウェア 1. tt-nn/vLLM 2. tt-metalium 3. tt-distributed 4. tt-fabric 4. まとめ 4
全体構成 5
6 Tensixコア — FPU/SFPU + L1 SRAM(グリッド状に配置) NoC — オンチップ通信網(チップ内メッシュ接続)
Ethernetコア — チップ間100G/400Gリンク(NoCグリッド上に配置) Galaxy — 32チップ搭載6Uサーバー(1トレイ8チップ×4トレイ) SuperCluster — 複数Galaxy接続(TT-Fabricでメッシュ状に接続) 全体構成 — ハードウェア ※トレイ間‧サーバー間: QSFP-DD + Warp Bridge
7 ttnn / vLLM PyTorchライクAPI · 推論 tt-metalium 処理をプリミティブに実⾏できるプログラミングモデル及びランタイム TT-Fabric
接続を統⼀的に扱えるようにするもの TT-Distributed 実際に分散実⾏するランタイム 全体構成 — ソフトウェア
Tensixコア内 8
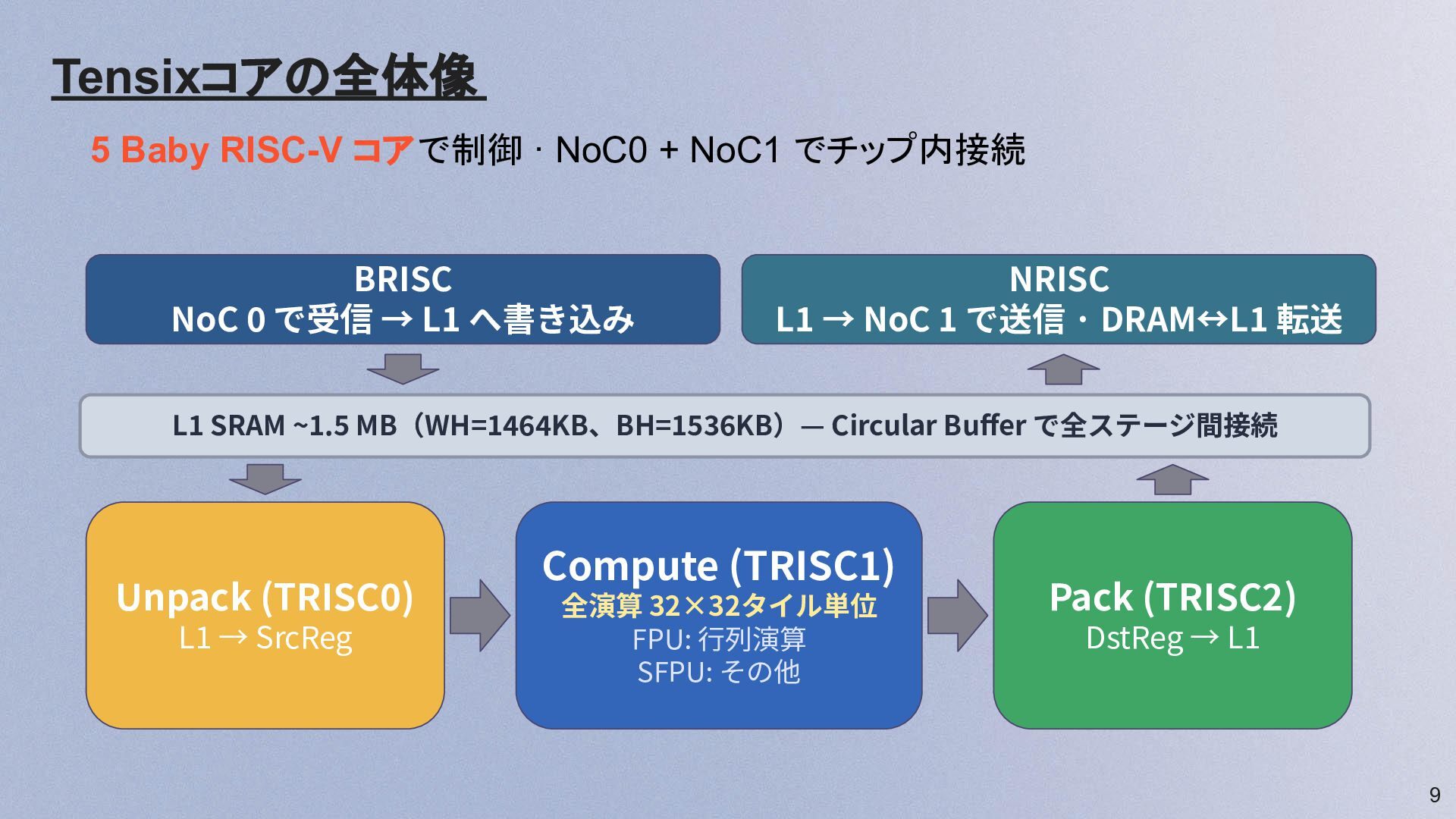
9 Tensixコアの全体像 BRISC NoC 0 で受信 → L1 へ書き込み Unpack
(TRISC0) L1 → SrcReg Compute (TRISC1) 全演算 32×32タイル単位 FPU: ⾏列演算 SFPU: その他 Pack (TRISC2) DstReg → L1 NRISC L1 → NoC 1 で送信 · DRAM↔L1 転送 L1 SRAM ~1.5 MB(WH=1464KB、BH=1536KB)— Circular Buffer で全ステージ間接続 5 Baby RISC-V コアで制御 · NoC0 + NoC1 でチップ内接続
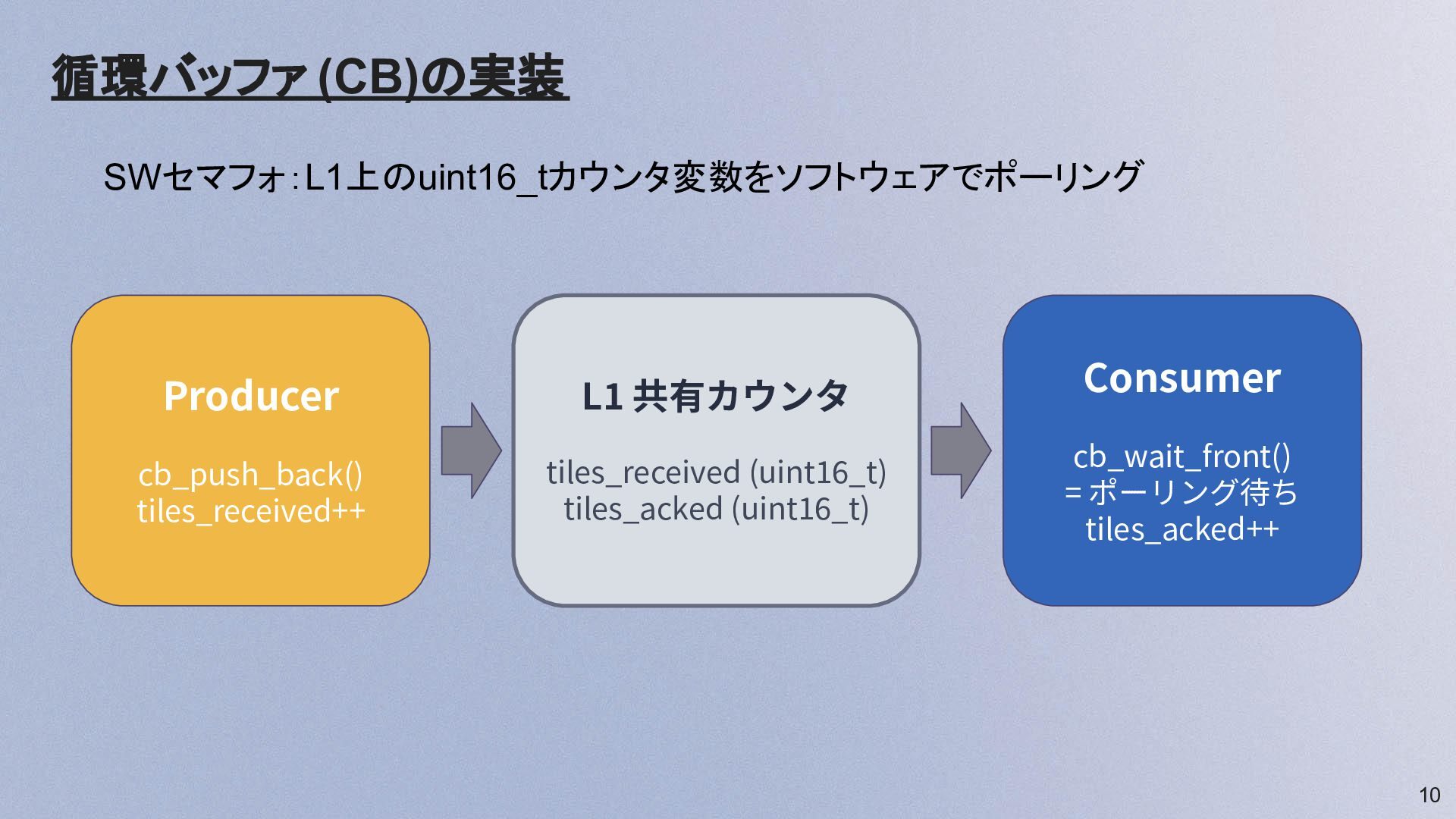
10 循環バッファ (CB)の実装 Producer cb_push_back() tiles_received++ L1 共有カウンタ tiles_received (uint16_t)
tiles_acked (uint16_t) Consumer cb_wait_front() = ポーリング待ち tiles_acked++ SWセマフォ:L1上のuint16_tカウンタ変数をソフトウェアでポーリング
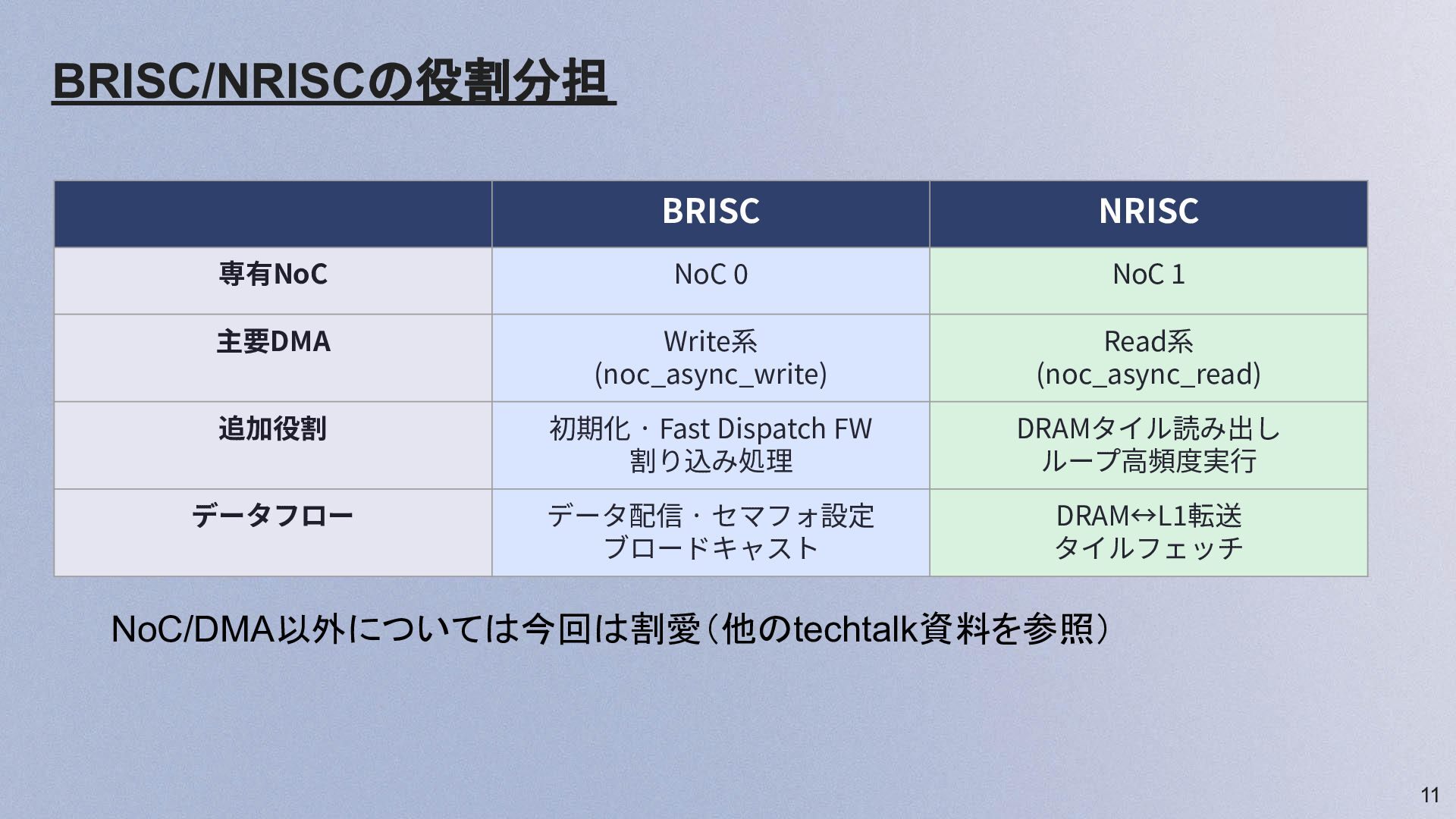
11 BRISC/NRISCの役割分担 BRISC NRISC 専有NoC NoC 0 NoC 1 主要DMA
Write系 (noc_async_write) Read系 (noc_async_read) 追加役割 初期化 · Fast Dispatch FW 割り込み処理 DRAMタイル読み出し ループ⾼頻度実⾏ データフロー データ配信 · セマフォ設定 ブロードキャスト DRAM↔L1転送 タイルフェッチ NoC/DMA以外については今回は割愛(他のtechtalk資料を参照)
12 DRAMアクセスと PCIeホスト通信 Tensixコアにデータを持ってくるには、 1. ホストからPCIe経由で内部DRAM(GDDR6)に送信 2. DRAMからTensixコアのL1 SRAMに転送 が必要
今日は割愛(以前のTechTalk資料などを参照)
NoC(チップ内 Tensixコア間) 13
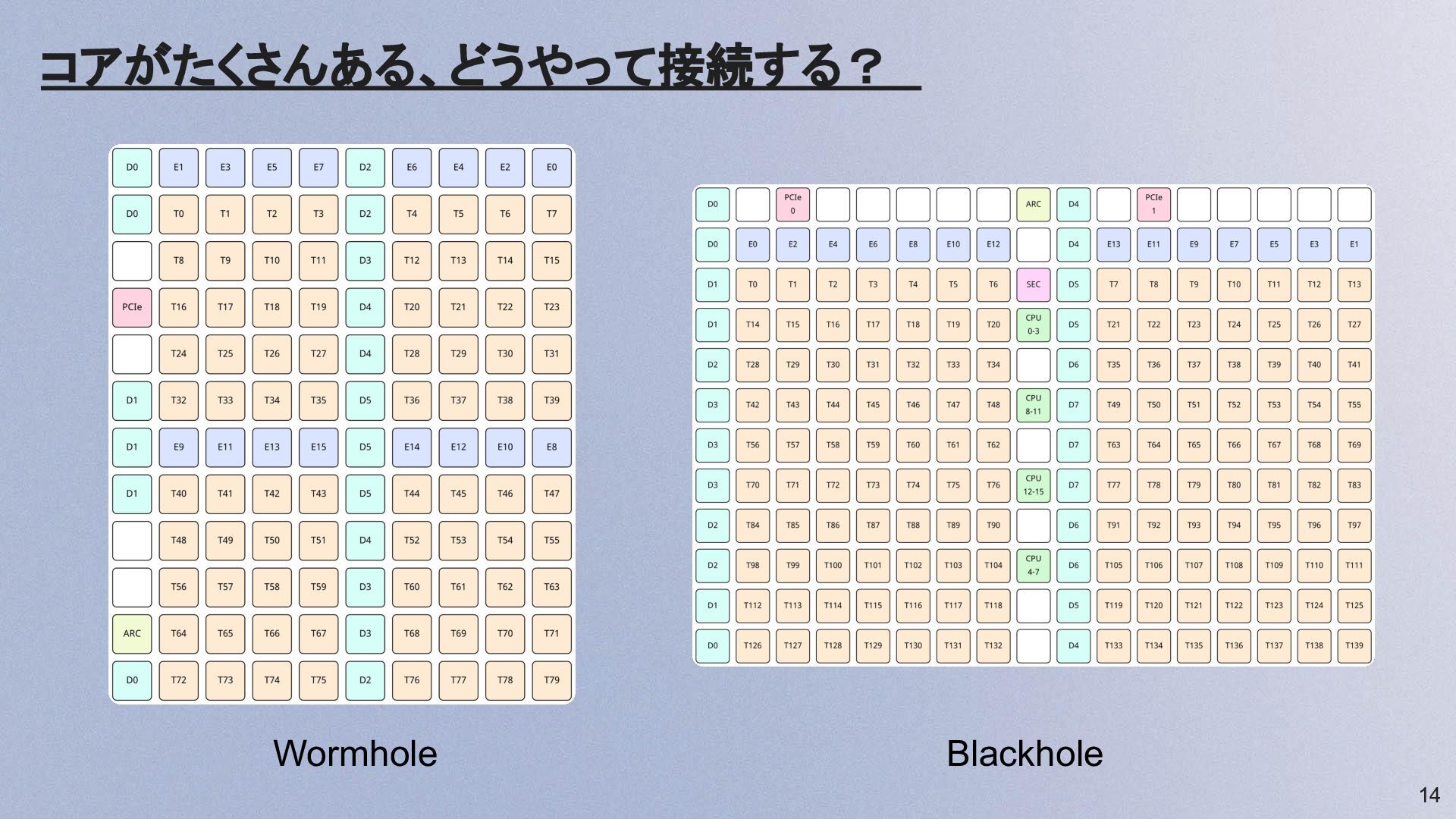
コアがたくさんある、どうやって接続する? 14 Wormhole Blackhole
15 NoC(チップ内ネットワーク) • 各RISC-Vコアは自分のローカルSRAM(L1)のみ • 他コアアクセスを代替するのがNoC (Netwok on Chip) 特徴:
• 非同期DMA • 2つの独立したNetwork on Chip (NoC0, NoC1) ◦ 読み書きを並列処理(後述) • 座標(x, y, localaddr)指定するだけで転送 • 複雑な転送もできる
16 NoC API:非同期DMAコマンド データ転送 noc_async_read noc_async_write 宛先指定: get_noc_addr(x, y, offset)
アドレッシング (x, y, local_address) の3タプル Tensix / DRAM / PCIe / Ethernet 全ノード共通形式 マルチキャスト書き込み対応 バリア: noc_async_read_barrier() / noc_async_write_barrier() HWカウンタをポーリングしてDMA完了を待つ 各RISC-Vは自コアのローカルL1のみ直接load/store可能 → リモートアクセスはすべてNoC経由の非同期DMA チップ外への通信もNoCからEthernetコアを経由 (TT-Fabricがマルチチップに延伸、後述)
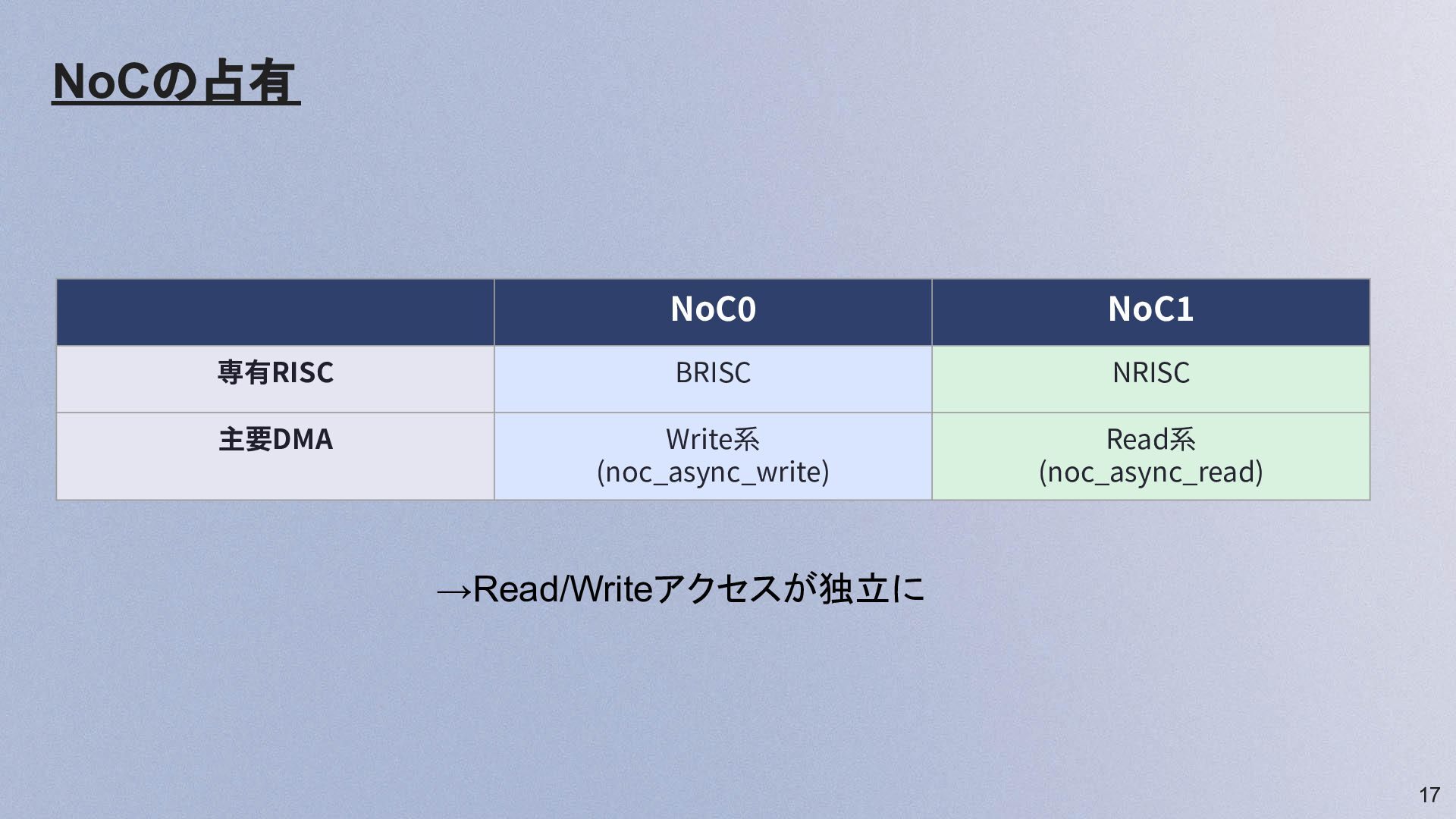
17 NoCの占有 NoC0 NoC1 専有RISC BRISC NRISC 主要DMA Write系 (noc_async_write)
Read系 (noc_async_read) →Read/Writeアクセスが独立に
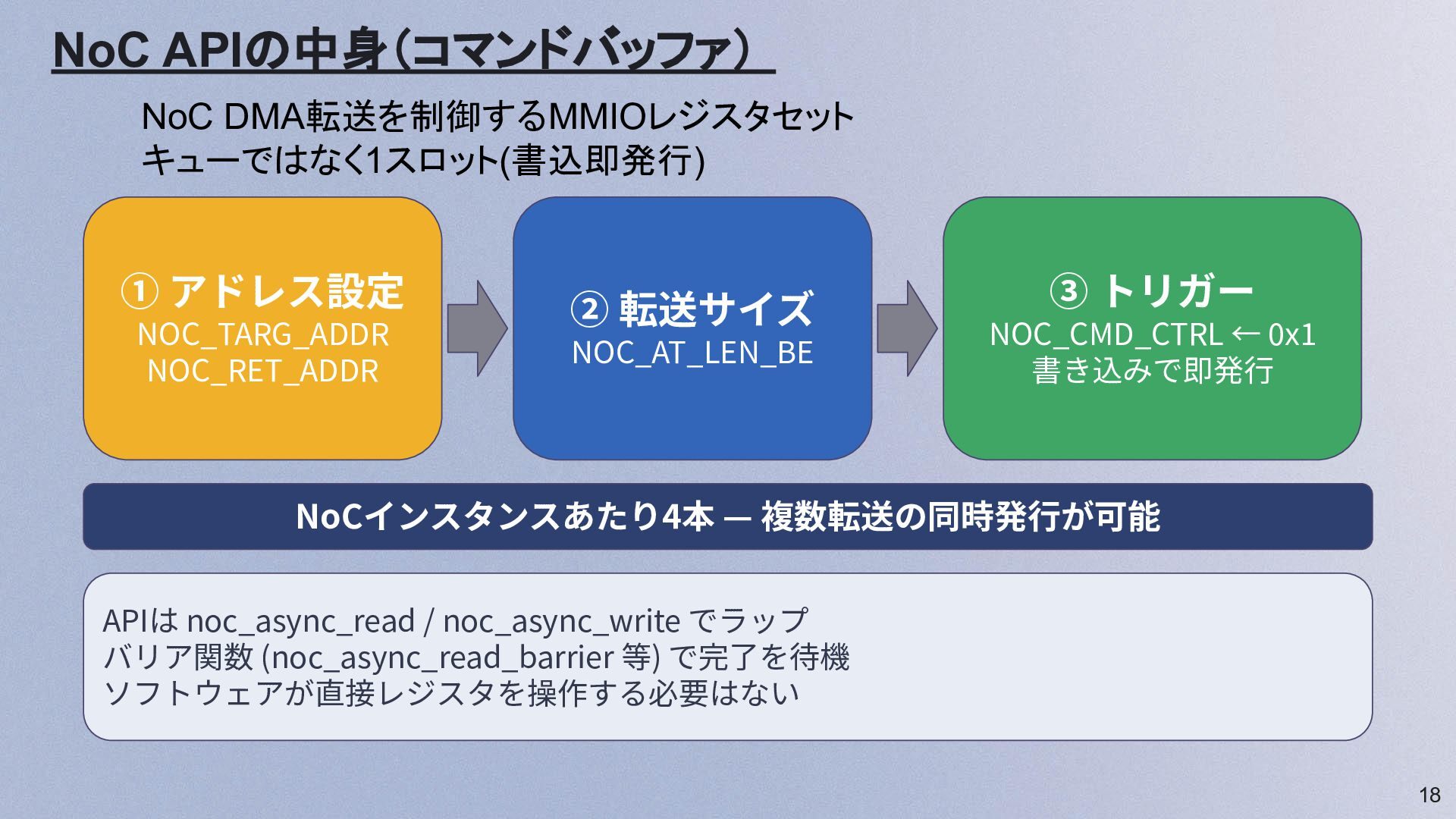
18 NoC APIの中身(コマンドバッファ) ① アドレス設定 NOC_TARG_ADDR NOC_RET_ADDR ② 転送サイズ NOC_AT_LEN_BE
③ トリガー NOC_CMD_CTRL ← 0x1 書き込みで即発⾏ NoCインスタンスあたり4本 — 複数転送の同時発⾏が可能 APIは noc_async_read / noc_async_write でラップ バリア関数 (noc_async_read_barrier 等) で完了を待機 ソフトウェアが直接レジスタを操作する必要はない NoC DMA転送を制御するMMIOレジスタセット キューではなく1スロット(書込即発行)
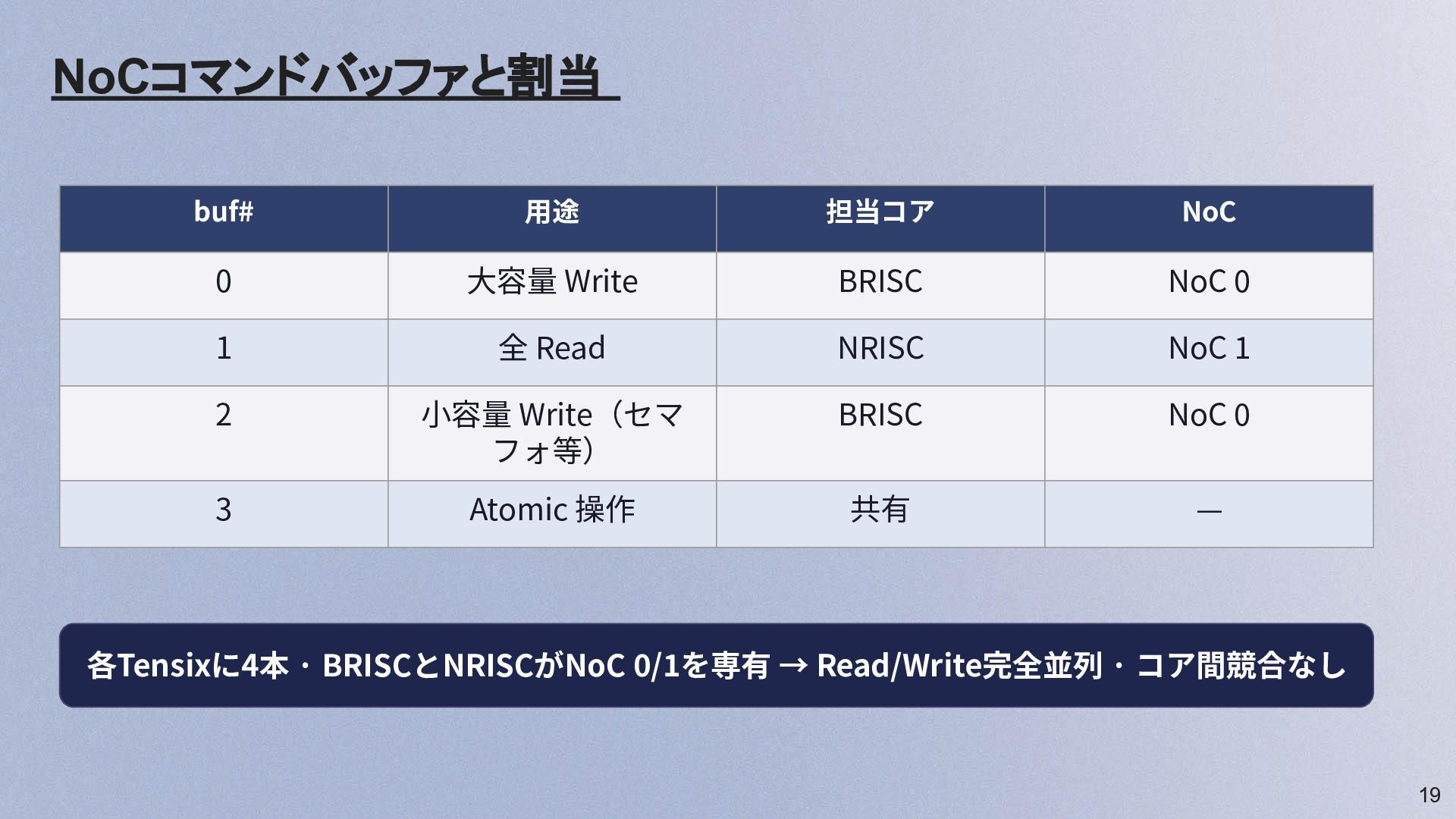
19 NoCコマンドバッファと割当 buf# ⽤途 担当コア NoC 0 ⼤容量 Write BRISC
NoC 0 1 全 Read NRISC NoC 1 2 ⼩容量 Write(セマ フォ等) BRISC NoC 0 3 Atomic 操作 共有 — 各Tensixに4本 · BRISCとNRISCがNoC 0/1を専有 → Read/Write完全並列 · コア間競合なし
20 NoCによる複雑な転送 マルチキャスト 矩形範囲(x_start,y_start→x_end,y_end) の全コアに⼀⻫書き込み CCL集団通信の基盤 Atomic操作 リモートL1上のアドレスにHWレベルで実⾏ INCR_GET: カウンタ+1
SWAP / CAS 分散バリア‧セマフォ実装に使⽤ 大規模化には直接寄与しないので詳細割愛
21 NoCのその他の機能 機能 仕組み 用途 Inline DW Write 32bit値をパケットヘッダに埋め込み、宛先 L1の指定アドレス
に直接書き込み L1共有カウンタのポーリングによる同 期・フラグ通知 ハーベスティング 製造時の不良コアを無効化し、 NoCがアドレスを自動リマップ 歩留まり向上・ソフトから透過的に動作 Watcher TT_METAL_WATCHER=1で有効化、NoCトランザクション をログ収集 デッドロック調査・NoC障害分析
Ethernetコア(チップ間接続) 22
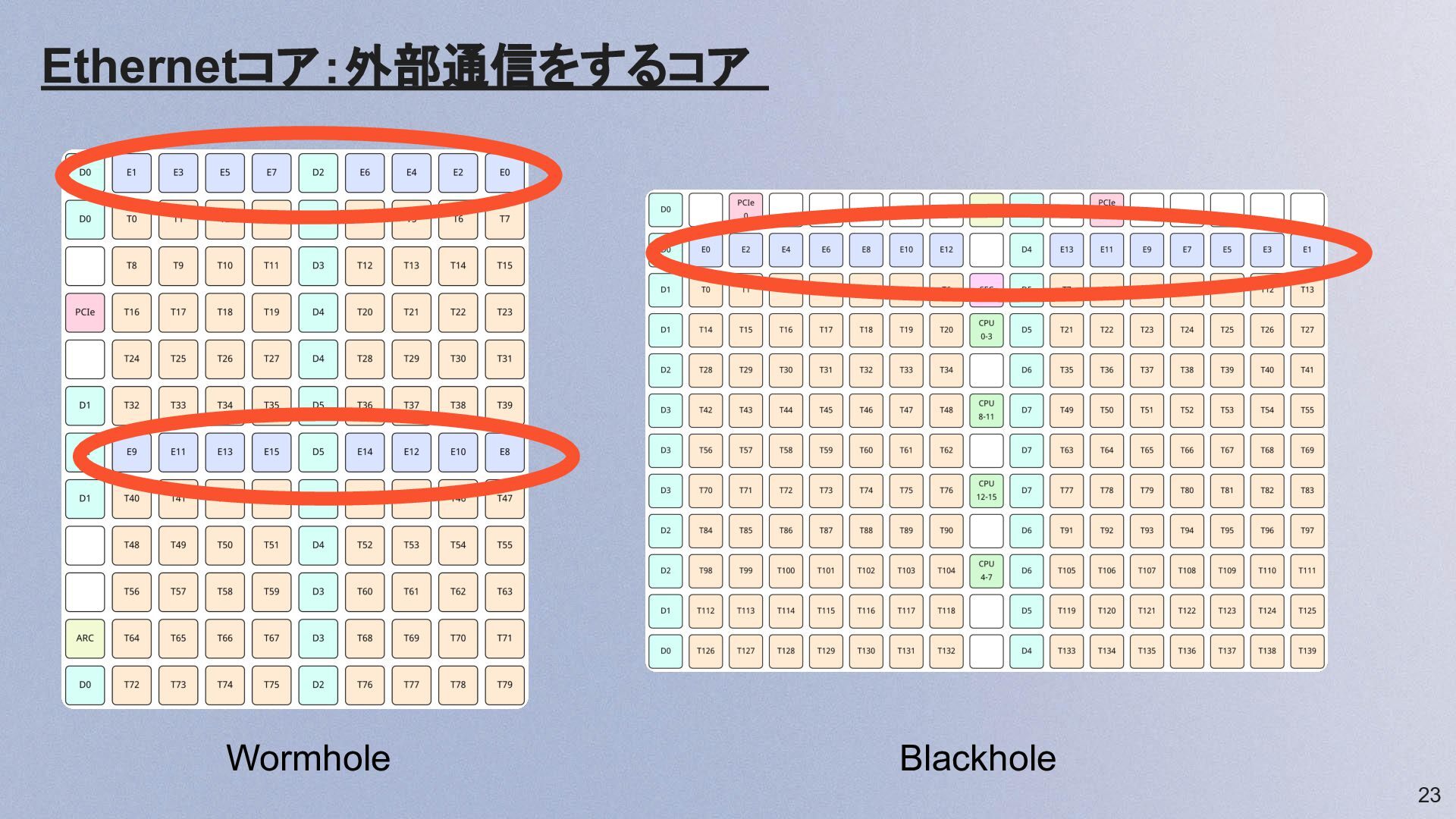
Ethernetコア:外部通信をするコア 23 Blackhole Wormhole Blackhole
24 Ethernetコア概要 項⽬ Wormhole Blackhole Ethernetコア数/チップ 16 14 RISC-Vコア/Eコア 1
2 L1 SRAM/コア 256 KB 512 KB リンク速度/コア 100 Gbps 400 Gbps チップ合計帯域 1,600 Gbps 4 Tbps • プログラマブルなルーター RISC-V上で Fabric Router FW が動作し、パケットのルーティングを ソフトウェア制御 • NoCエンドポイント チップ内NoCに接続されたノードで、Tensixから noc_async_write で 直接データ送信可能
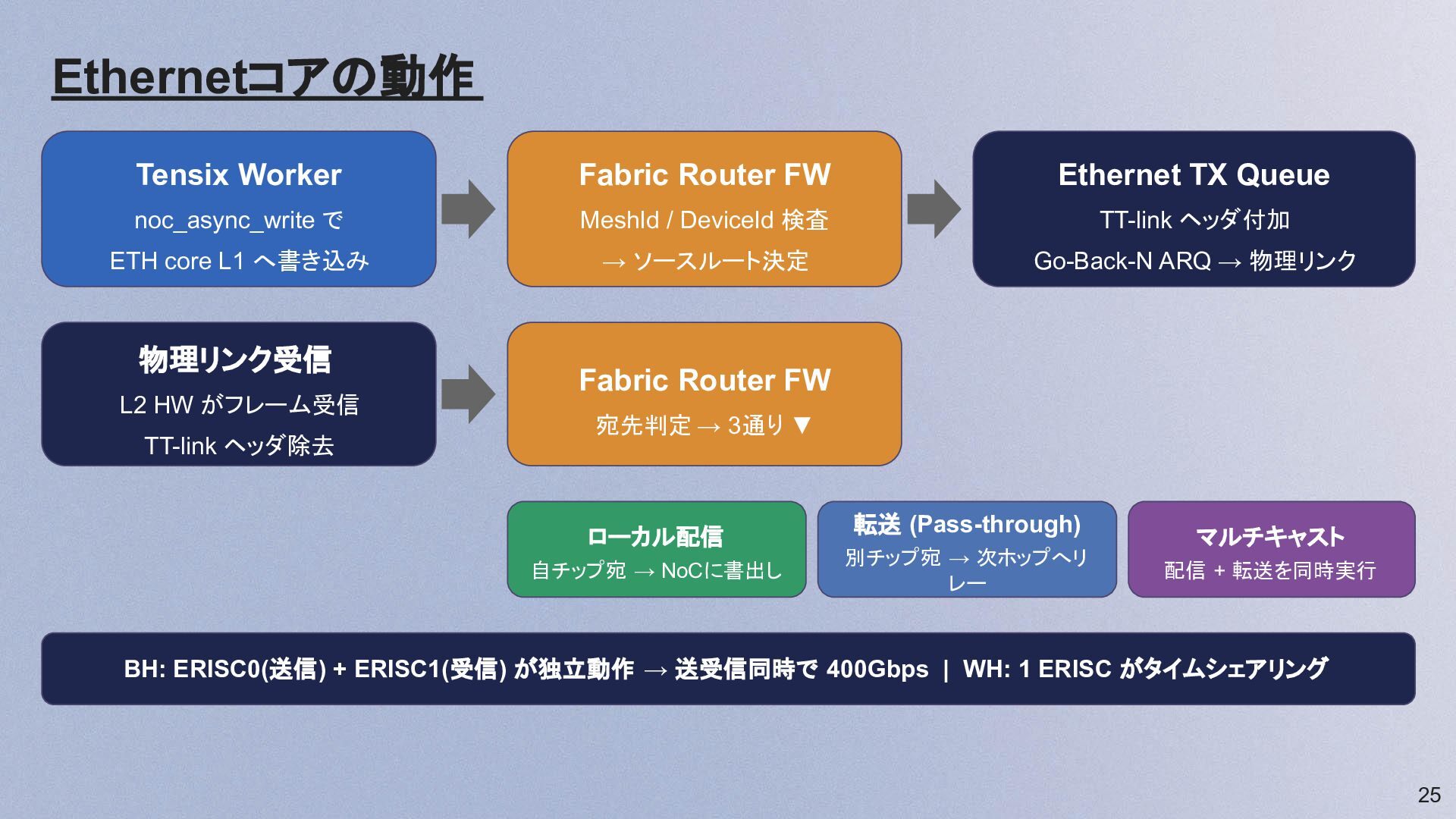
25 Ethernetコアの動作 Tensix Worker noc_async_write で ETH core L1 へ書き込み
Fabric Router FW MeshId / DeviceId 検査 → ソースルート決定 Ethernet TX Queue TT-link ヘッダ付加 Go-Back-N ARQ → 物理リンク 物理リンク受信 L2 HW がフレーム受信 TT-link ヘッダ除去 Fabric Router FW 宛先判定 → 3通り ▼ ローカル配信 自チップ宛 → NoCに書出し 転送 (Pass-through) 別チップ宛 → 次ホップへリ レー マルチキャスト 配信 + 転送を同時実行 BH: ERISC0(送信) + ERISC1(受信) が独立動作 → 送受信同時で 400Gbps | WH: 1 ERISC がタイムシェアリング
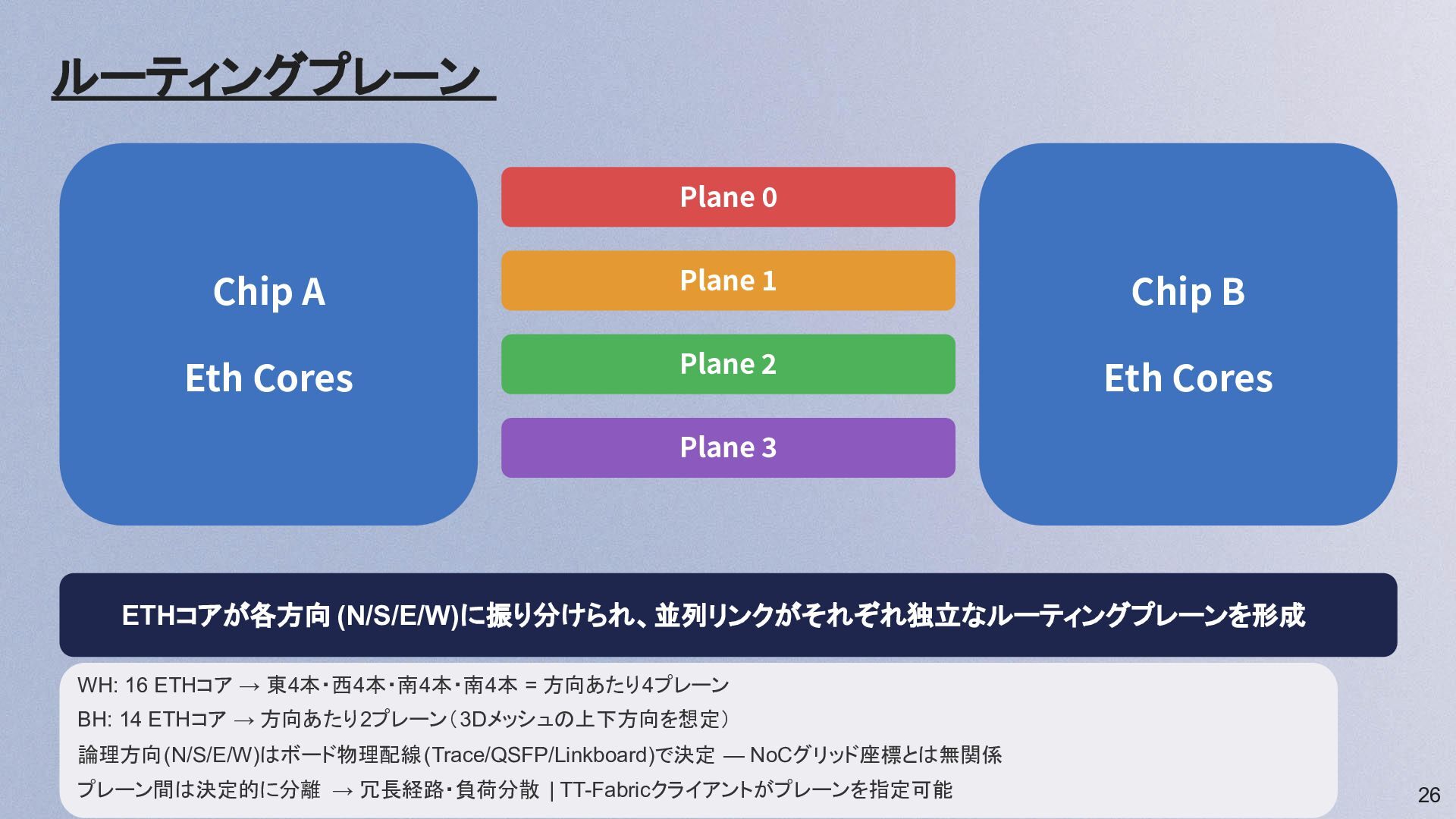
26 Chip A Eth Cores Chip B Eth Cores Plane
0 Plane 1 Plane 2 Plane 3 ETHコアが各方向 (N/S/E/W)に振り分けられ、並列リンクがそれぞれ独立なルーティングプレーンを形成 ルーティングプレーン WH: 16 ETHコア → 東4本・西4本・南4本・南4本 = 方向あたり4プレーン BH: 14 ETHコア → 方向あたり2プレーン(3Dメッシュの上下方向を想定) 論理方向(N/S/E/W)はボード物理配線(Trace/QSFP/Linkboard)で決定 — NoCグリッド座標とは無関係 プレーン間は決定的に分離 → 冗長経路・負荷分散 | TT-Fabricクライアントがプレーンを指定可能
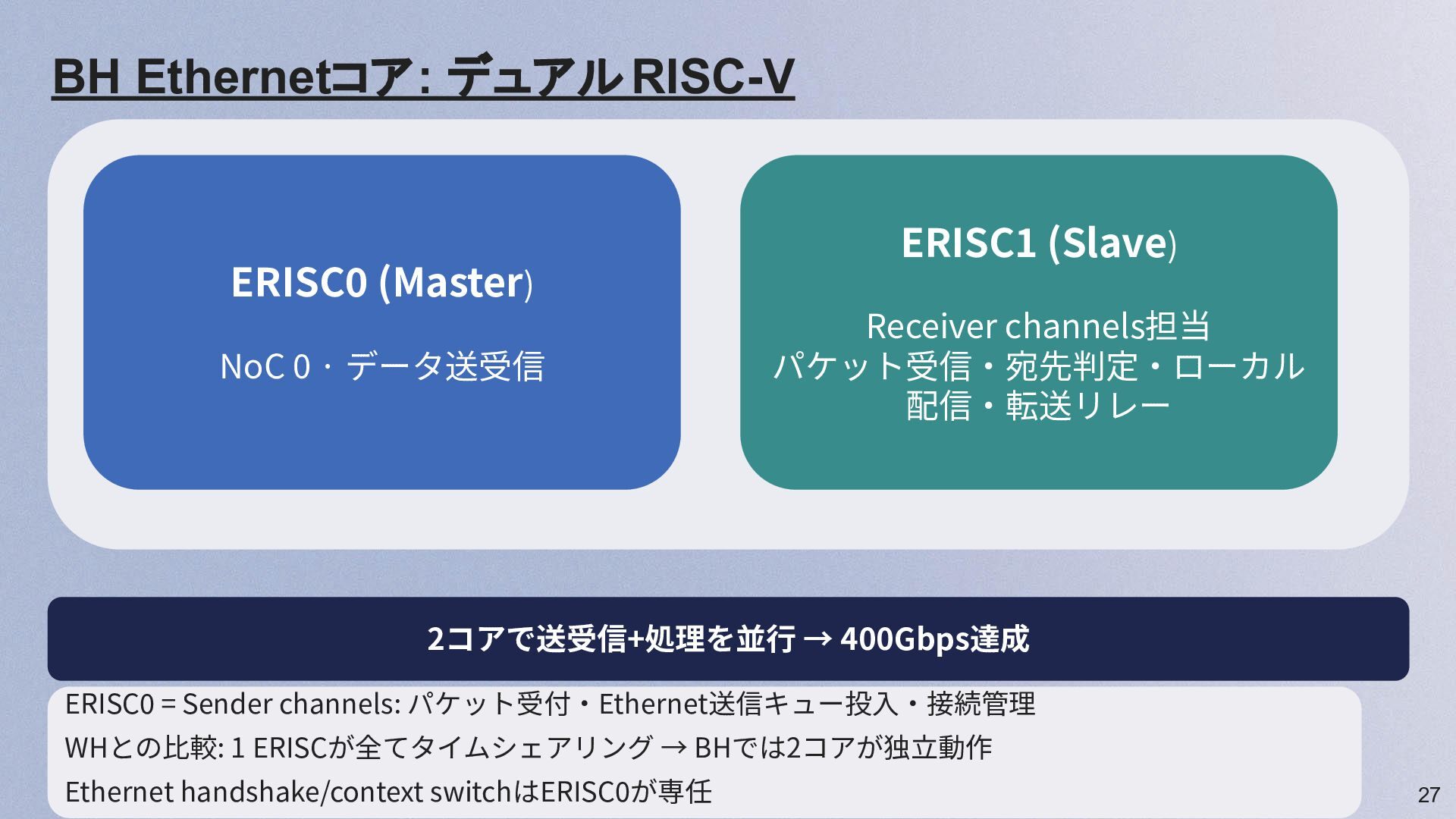
27 ERISC0 (Master) NoC 0 · データ送受信 ERISC1 (Slave) Receiver
channels担当 パケット受信‧宛先判定‧ローカル 配信‧転送リレー 2コアで送受信+処理を並⾏ → 400Gbps達成 BH Ethernetコア: デュアルRISC-V ERISC0 = Sender channels: パケット受付‧Ethernet送信キュー投⼊‧接続管理 WHとの⽐較: 1 ERISCが全てタイムシェアリング → BHでは2コアが独⽴動作 Ethernet handshake/context switchはERISC0が専任
28 外部接続ポート (QSFP・Warp Bridge)
29 QSFP-DD(業界標準) 8レーン · 100G/200G/400G/800G DAC / AEC / AOC
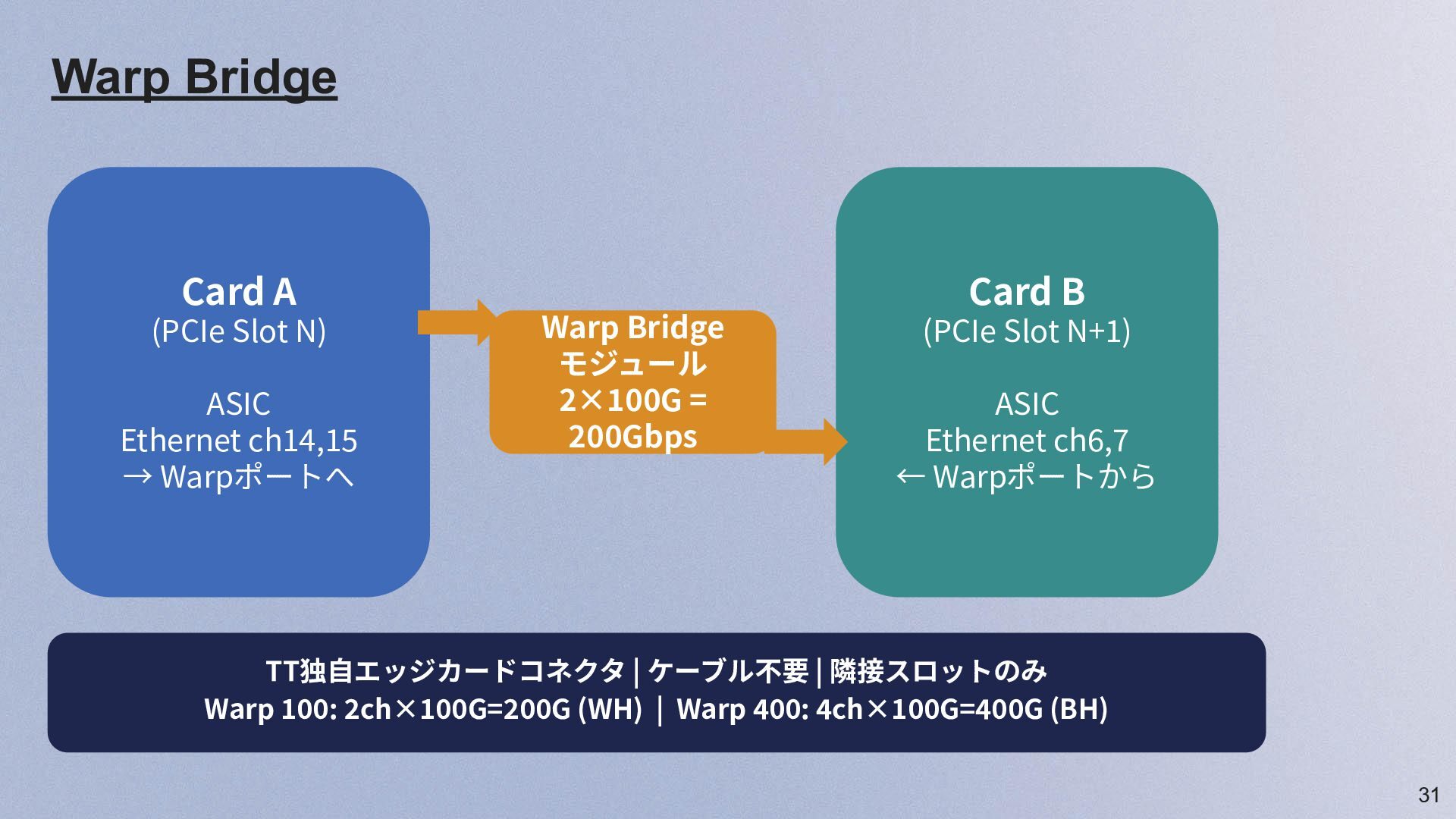
/ 光 Warp 100 Bridge(TT独⾃) 隣接カード間ブリッジ 100Gリンク · 低遅延 外部接続の 2種類
30 QSFP-DD パッシブDAC ~1-2m 最低コスト AEC ~3-5m Galaxy内標準 AOC 30-50m
ラック間 WH: QSFP56 50G/lane → 200Gbps/port BH: QSFP112 100G/lane → 800Gbps/port ← 短距離‧低コスト ⻑距離‧⾼コスト →
31 Warp Bridge Card A (PCIe Slot N) ASIC Ethernet
ch14,15 → Warpポートへ Warp Bridge モジュール 2×100G = 200Gbps Card B (PCIe Slot N+1) ASIC Ethernet ch6,7 ← Warpポートから TT独⾃エッジカードコネクタ | ケーブル不要 | 隣接スロットのみ Warp 100: 2ch×100G=200G (WH) | Warp 400: 4ch×100G=400G (BH)
Galaxy(サーバー内カード間) 32
33 トレイ1: 8チップ トレイ2: 8チップ トレイ3: 8チップ トレイ4: 8チップ 6Uシャーシ
· 32チップ合計 · PCBトレース + Linkboard + QSFP-DD Galaxy:最大構成 補⾜情報 ホスト: 標準x86サーバー(Ubuntu)が PCIeでトレイに接続 (1チップのみx8 PCIe接続、 他7チップはx1で認識のみ) MaaS/Ansible/SLURM/Kubernetesで構成 管理可能
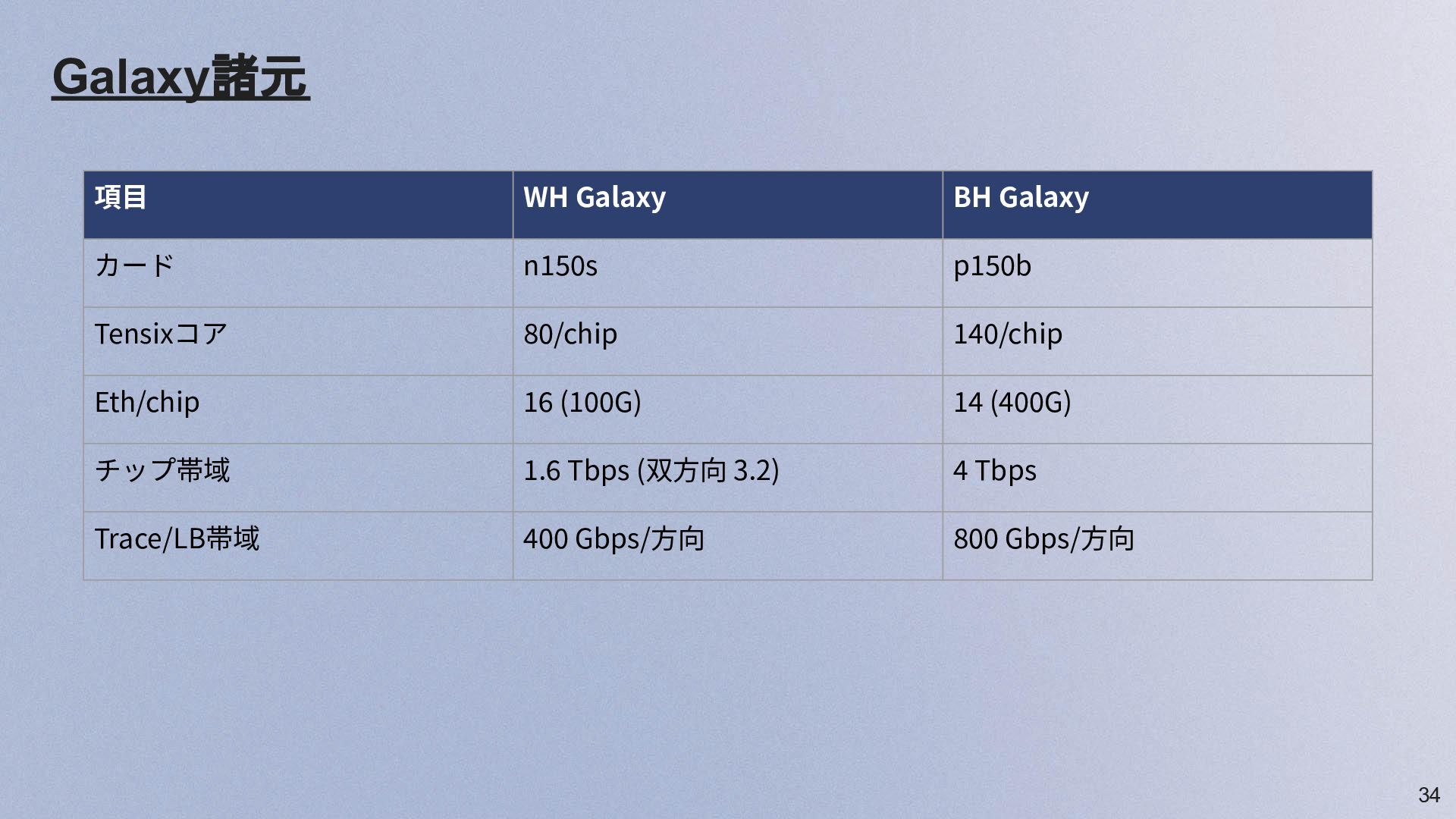
34 Galaxy諸元 項⽬ WH Galaxy BH Galaxy カード n150s p150b
Tensixコア 80/chip 140/chip Eth/chip 16 (100G) 14 (400G) チップ帯域 1.6 Tbps (双⽅向 3.2) 4 Tbps Trace/LB帯域 400 Gbps/⽅向 800 Gbps/⽅向
35 UBBトレイ(Wormholeの例) WH chips (2x4) to Linkboard to QSFP
SuperCluster(サーバー間) 36
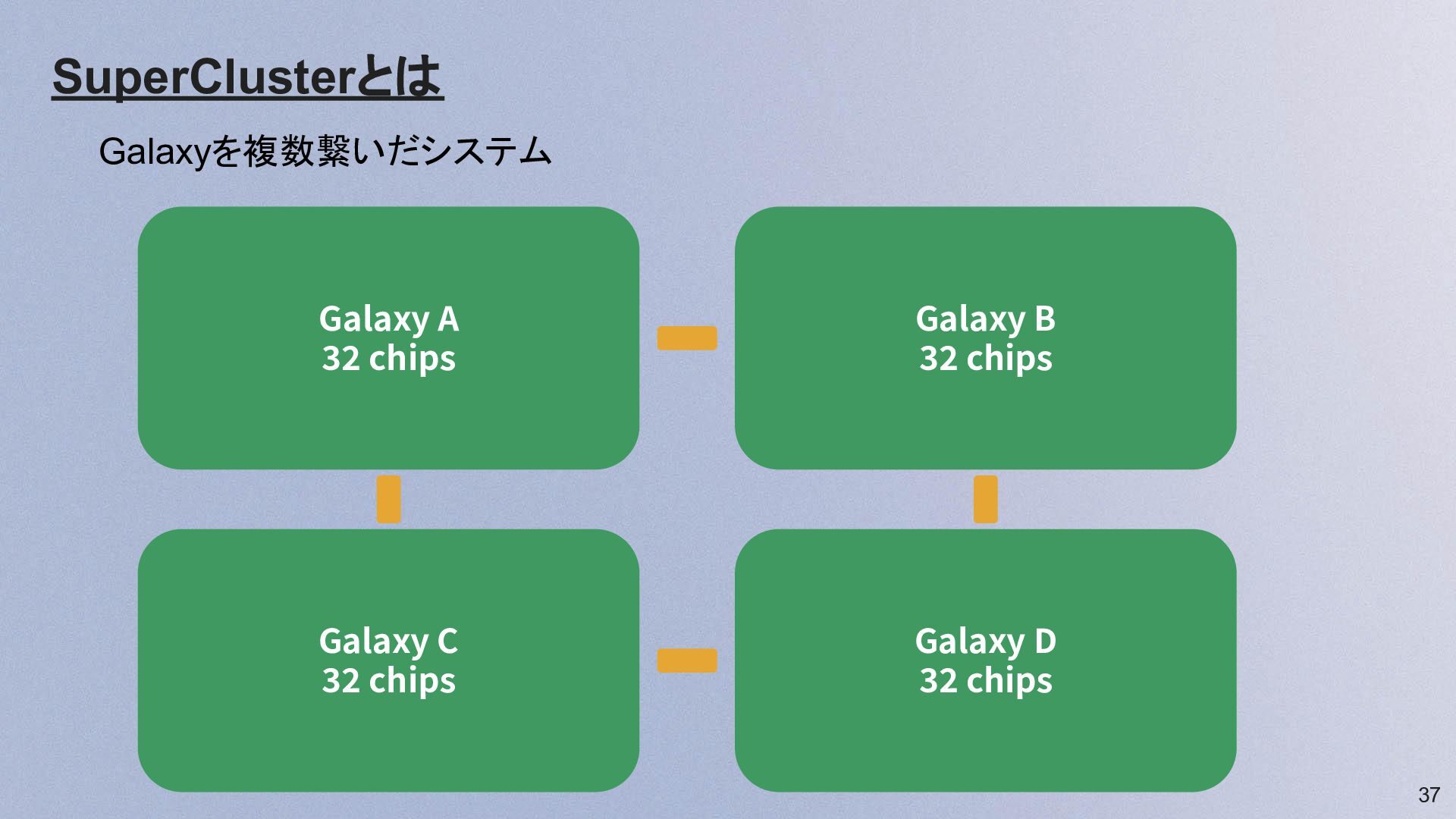
37 Galaxy A 32 chips Galaxy B 32 chips Galaxy
C 32 chips Galaxy D 32 chips SuperClusterとは Galaxyを複数繋いだシステム
38 1 Galaxy — 32 chips SC: 4 Galaxy —
128 chips SC4: 4 SC, 16 Galaxy — 256 chips SC9: 9 SC, 36 Galaxy — 1152 chips スケーリング 中規模推論 ⼤規模推論 超⼤規模推論‧ファインチューン 分散学習
ソフトウェアスタック 39
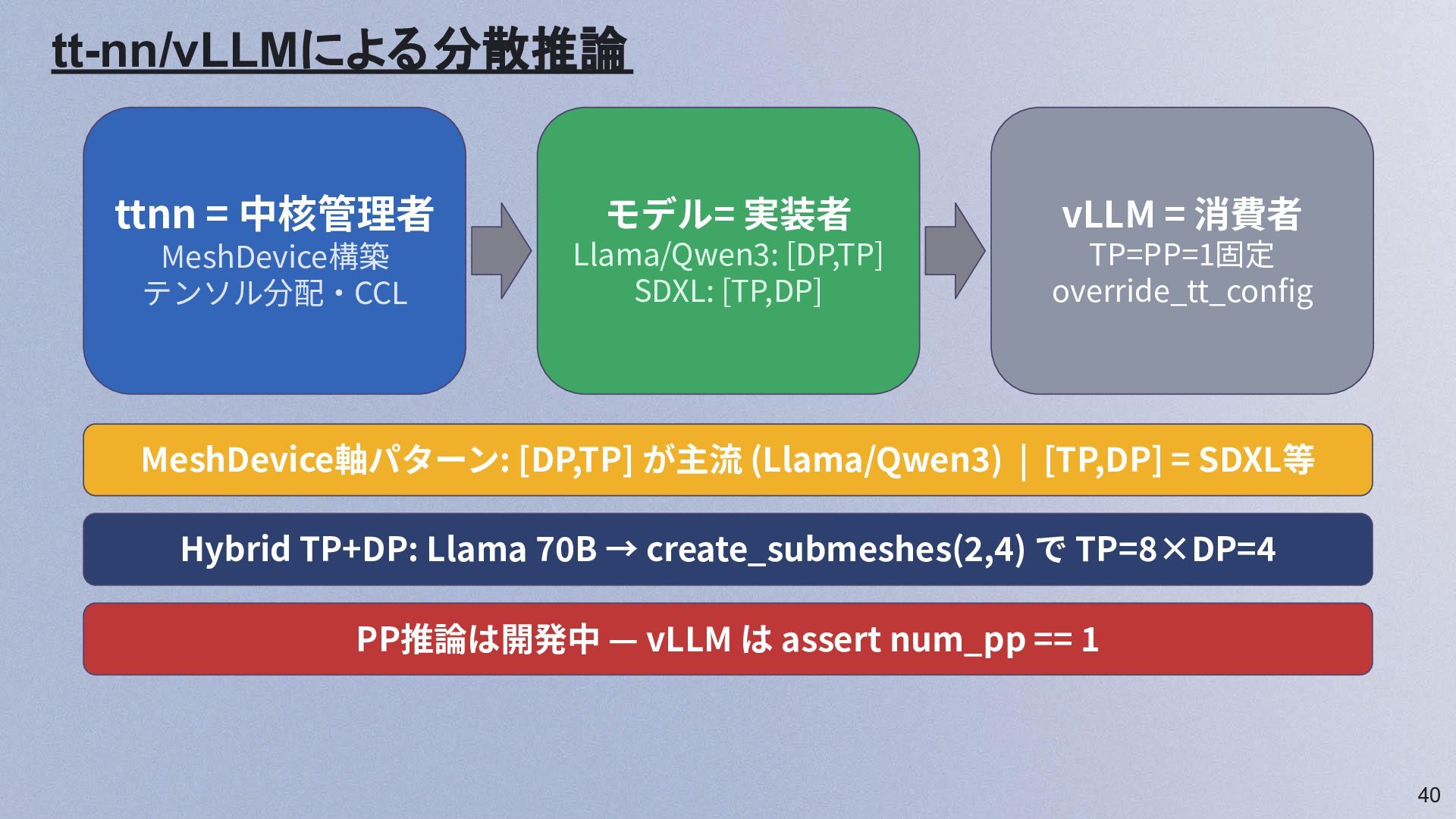
40 tt-nn/vLLMによる分散推論 ttnn = 中核管理者 MeshDevice構築 テンソル分配‧CCL モデル= 実装者 Llama/Qwen3:
[DP,TP] SDXL: [TP,DP] vLLM = 消費者 TP=PP=1固定 override_tt_config MeshDevice軸パターン: [DP,TP] が主流 (Llama/Qwen3) | [TP,DP] = SDXL等 Hybrid TP+DP: Llama 70B → create_submeshes(2,4) で TP=8×DP=4 PP推論は開発中 — vLLM は assert num_pp == 1
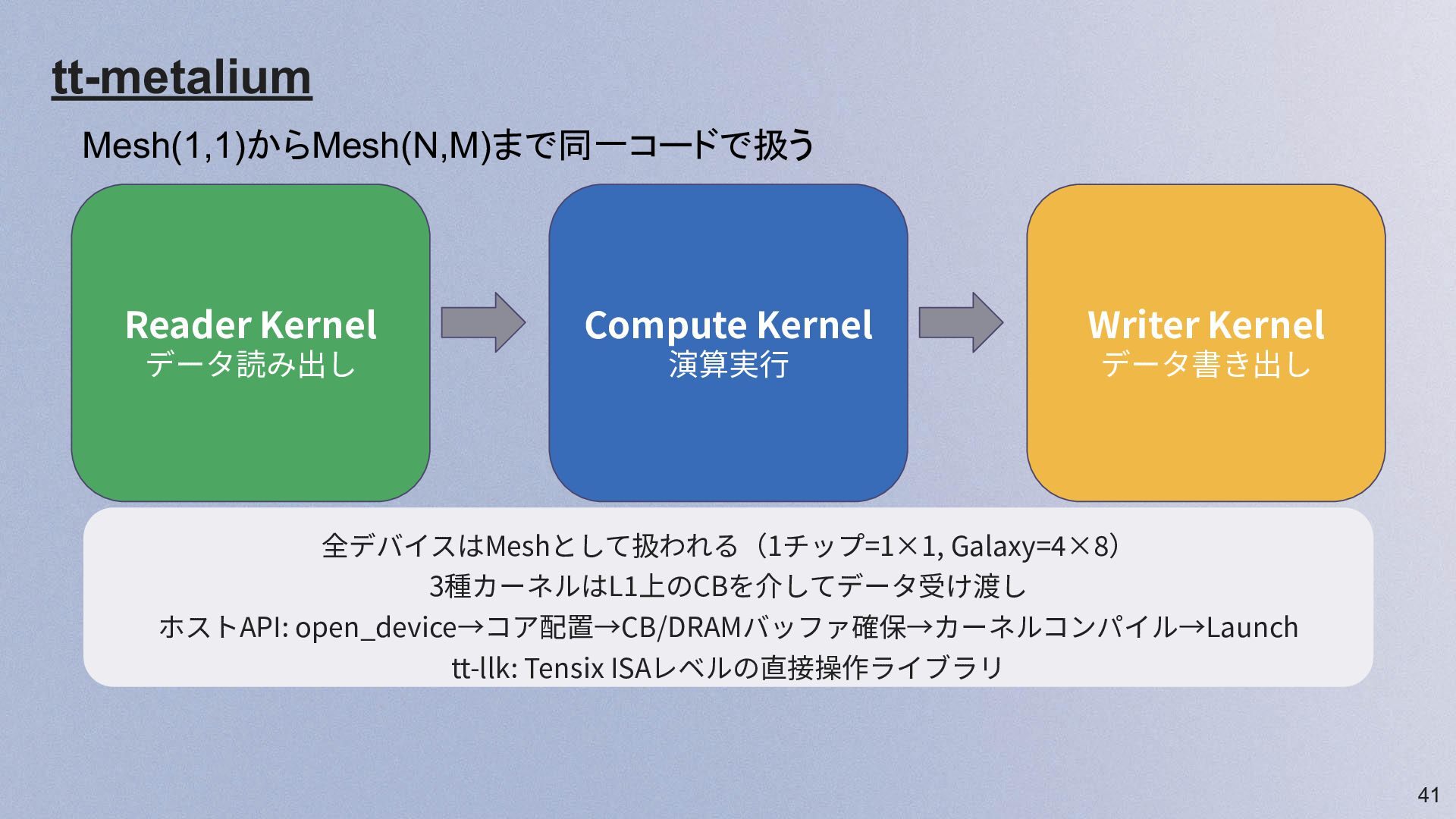
41 Reader Kernel データ読み出し Compute Kernel 演算実⾏ Writer Kernel データ書き出し
tt-metalium 全デバイスはMeshとして扱われる(1チップ=1×1, Galaxy=4×8) 3種カーネルはL1上のCBを介してデータ受け渡し ホストAPI: open_device→コア配置→CB/DRAMバッファ確保→カーネルコンパイル→Launch tt-llk: Tensix ISAレベルの直接操作ライブラリ Mesh(1,1)からMesh(N,M)まで同一コードで扱う
42 TT-Distributed 複数デバイス・サーバーをまたぐ分散実行のマルチホスト SPMDランタイム MeshDevice 複数の物理デバイスを 仮想的に1メッシュとして抽象化 open_mesh_device( MeshShape(4, 8))
MeshWorkload 単一プログラムを メッシュ全体に並列ディスパッチ SPMDモデル: デバイスごと逐次実行を排除 CCL(集団通信) All-Gather: テンソル集約 Reduce-Scatter: 縮約分散 All-Reduce: 全同期 → TP/DPの基本ブロック tt-metalium(カーネル管理) + TT-Fabric(チップ間通信)の上に構築 | TP/DPロジック自体は ttnn側が担当 詳細はまた次回以降にて(今日は割愛)
43 L5: Socket API L4: Fabric API L3: Routing(L0静的 +
L1動的) L2: Packet / Link L1: Physical (Ethernet) Data Plane TT-Fabric Control Plane: PCIe経由管理レイヤ (トポロジ認識‧ルーティングテーブル配布‧障害検知→リルーティング) サポートトポロジ: 1Dライン, 1Dリング, 2Dメッシュ, 2Dトーラス 信頼性: 次元順ルーティング, Bubble Flow Control, TTL, ⾃動リルーティング 詳細はこのあとのセッションにて
まとめ 44
45 Tensixコア — FPU/SFPU + RISC-V + L1 NoC —
メッシュ接続 · 座標アドレッシング Ethernet — WH: 100G×16 · BH: 400G×14 Galaxy — 32チップ · Linkboard + QSFP SuperCluster — QSFP-DD 全てを統⼀的にメッシュとして扱えるソフトウェアスタック(fabric, distributed) まとめ:大規模推論の全体像
{kind=link}
{kind=link}
![自己紹介 吉藤 尚生 YOSHIFUJI Naoki (@LWisteria) (Online avatar) [主な業績] •](https://files.speakerdeck.com/presentations/e3f37478044e4034859f922797b3165d/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}