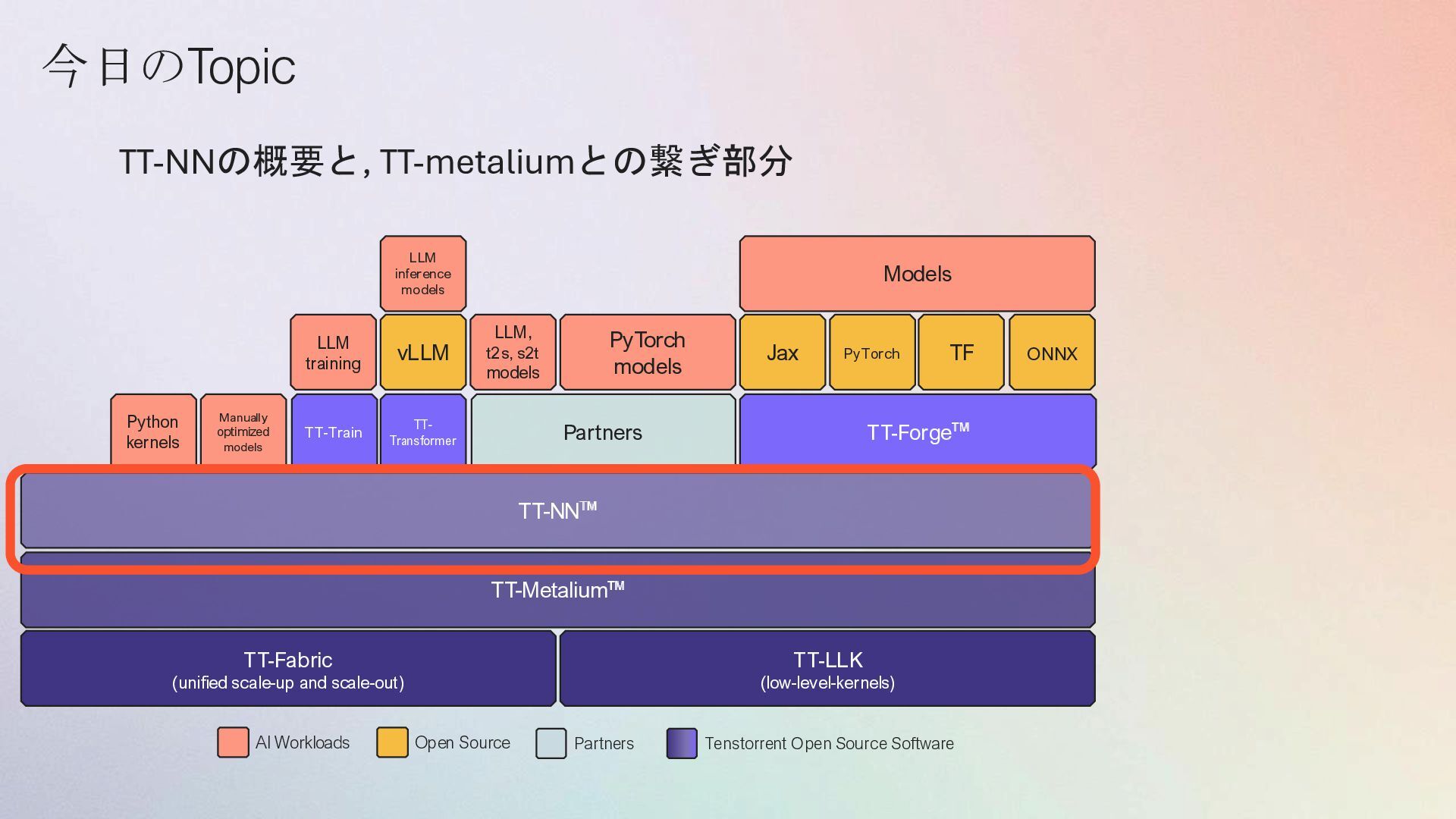
RISC-V 1 Router 1 Router 0 L1 Memory • 3 user C kernels program a single Tensix core • 1 compute kernel • 2 data movement kernels data movement kernel data movement kernel compute kernel おさらい TT-Metalium
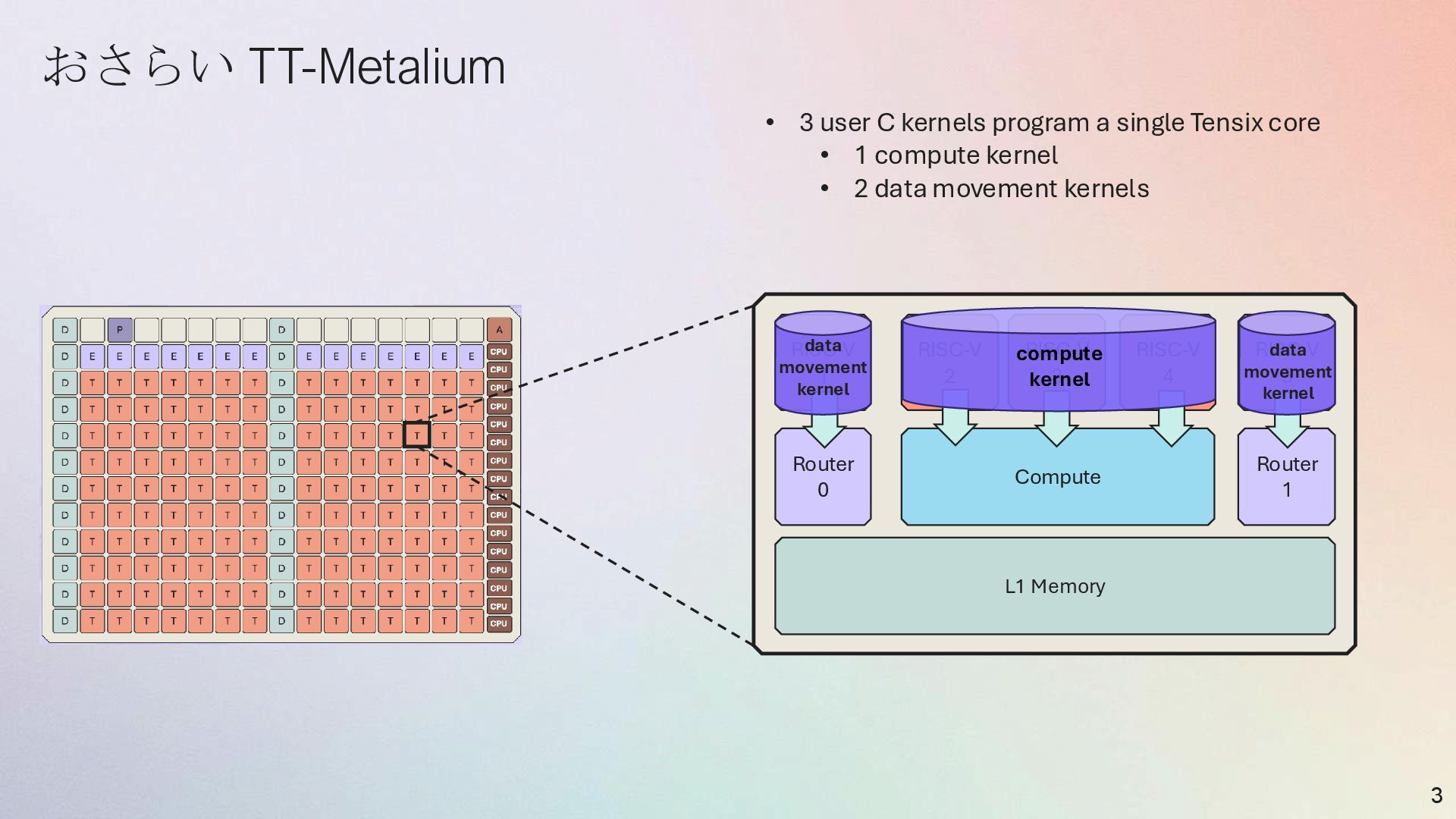
RISC-V 5 RISC-V 1 Router 1 Router 0 L1 Memory CBs CBs NoC 0 NoC 1 data movement kernel data movement kernel compute kernel • Circular Buffer (CB) • SRAM memory object with hardware- enabled flow control
• Pytorch • Doesn’t handle block-floats, tiles, layouts or sharding • Doesn’t natively handle multi-device • Custom libraries currently developed for multi-device • Doesn’t support performance OP configurations • Model developer can’t configure Ops for performance • Not really native multi-device • Additional layers on top 5 TT-NN • Native layouts and sharding • Native Distributed Shared Memory • SRAM and DRAM • Developer can configure OPs for performance • OPs are designed to be a great target for compilers compilers / MLIR • Native multi-device / multi-host
5], fill_value=1.0, dtype=ttnn.bfloat16, layout=ttnn.TILE_LAYOUT, device=device) b = ttnn.full([1], fill_value=2.0, dtype=ttnn.bfloat16, layout=ttnn.TILE_LAYOUT, device=device) c = a * b print(c) 7
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
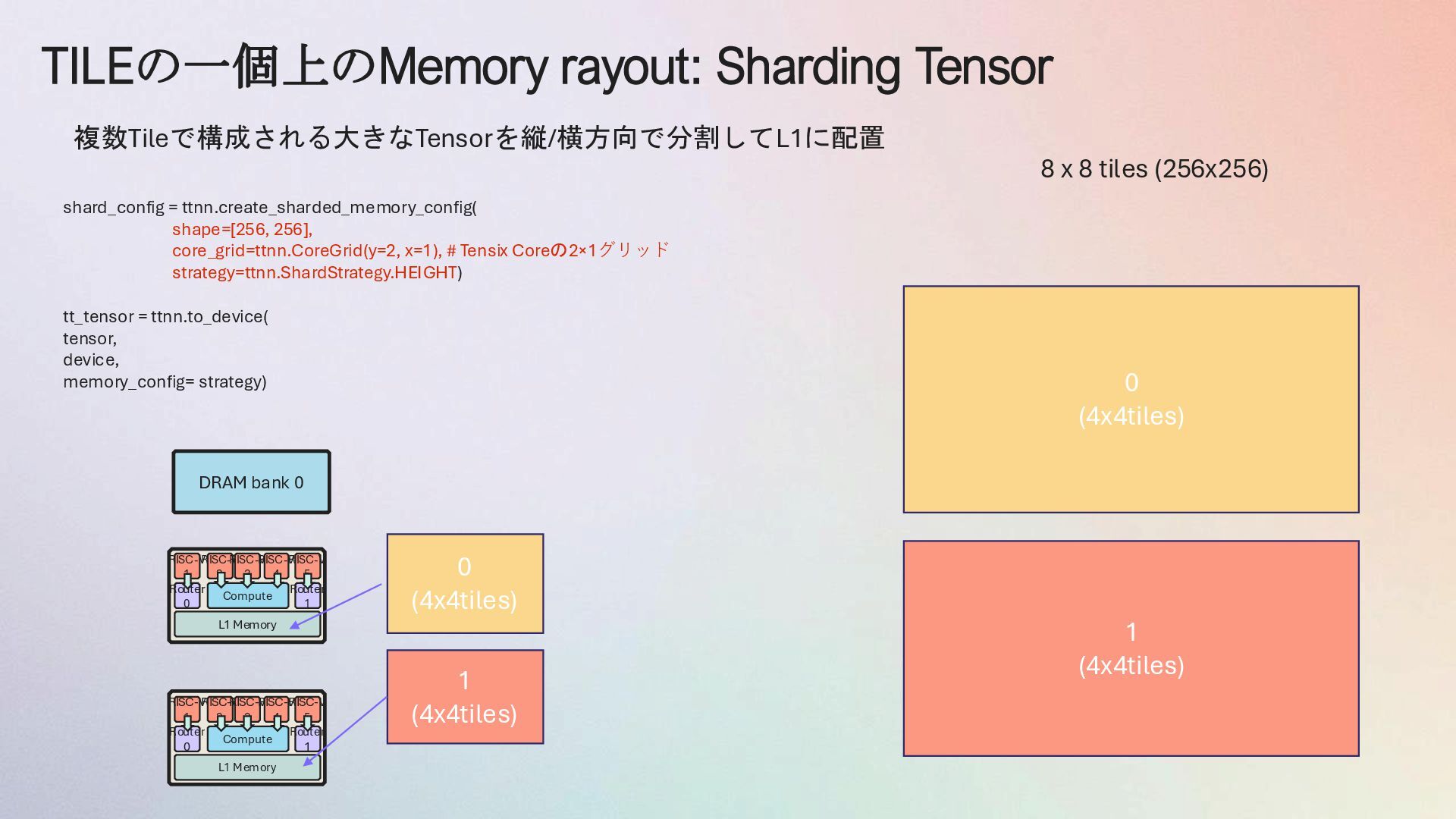{kind=link}
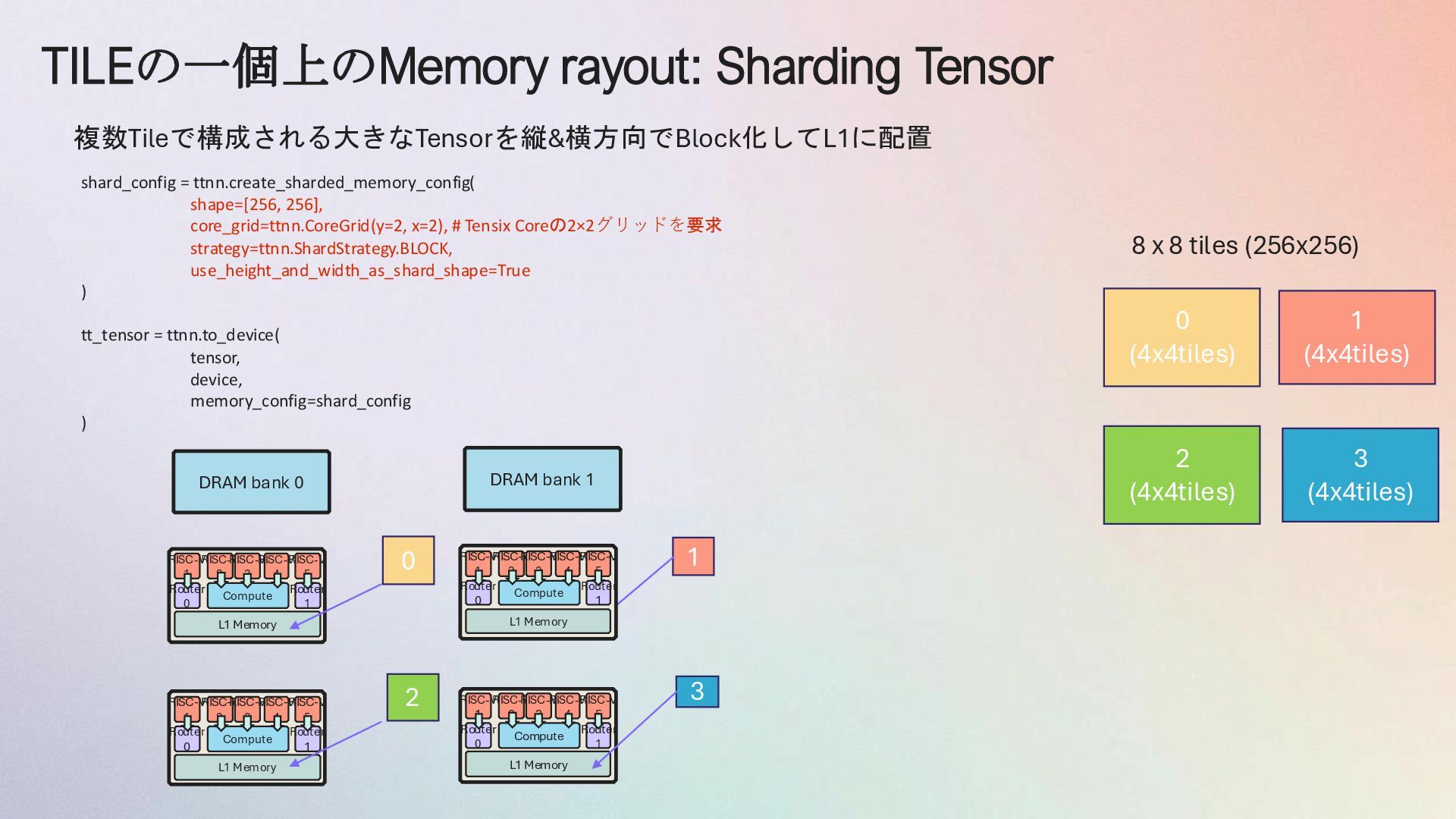{kind=link}
{kind=link}
![実応用(Conv2d)でのSharding 14 input_tensor = torch.randn([32, 224, 224, 64]) # Height](https://files.speakerdeck.com/presentations/4a64129c39ed4472b606eb97d5c0f553/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}