model graph Extract model summary • Operations • Parameters • Shape/Size Convert Torch to TTNN Ops Per Op PCC Impl Module Per Module PCC End-to-End End-to-End PCC Optimization Step by Step Implementation Mapping Torch to TTNN Ops Request to TT-Metal Develop Ops/Features in TT-Metal If no If yes
{kind=link}
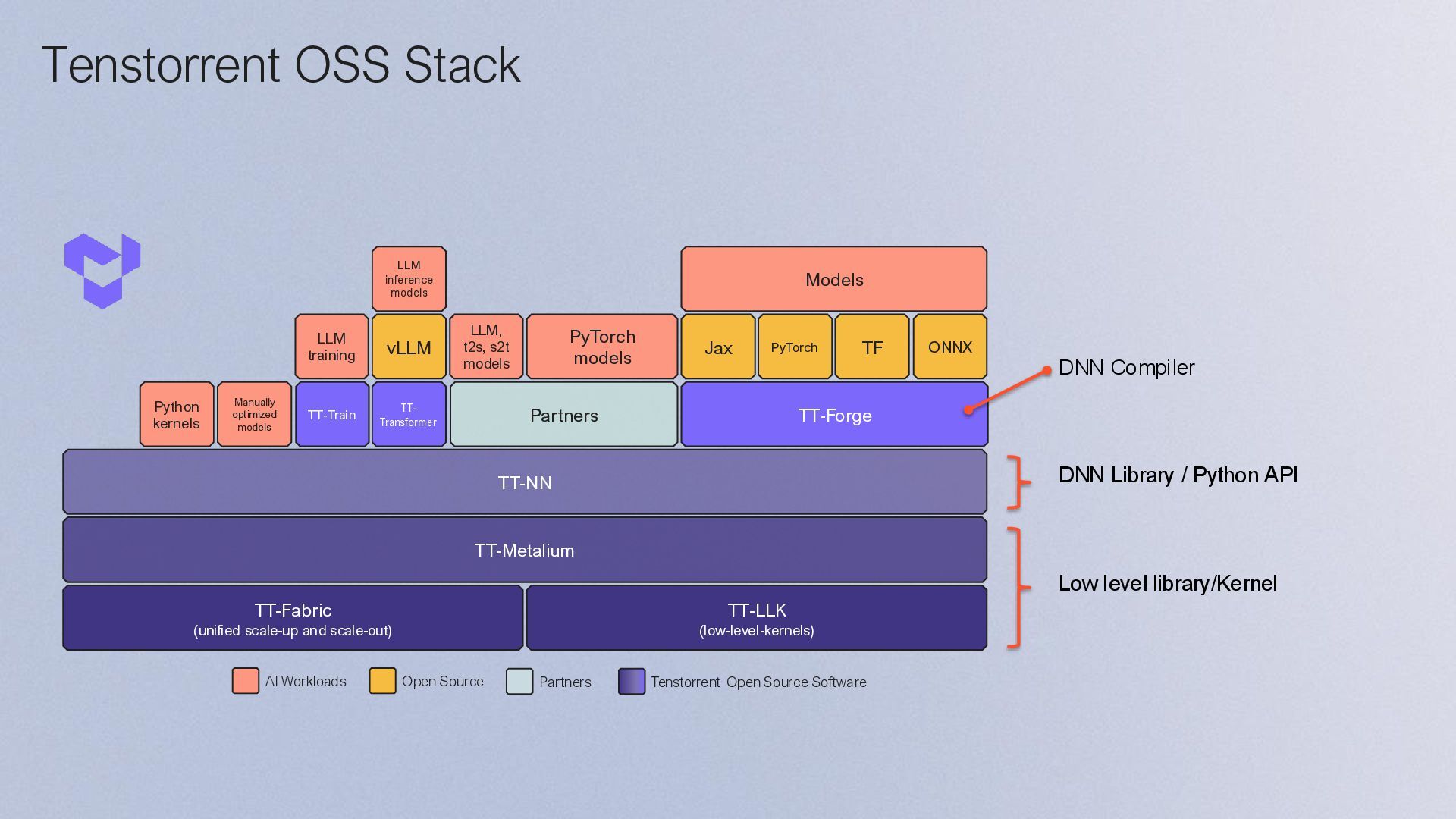{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
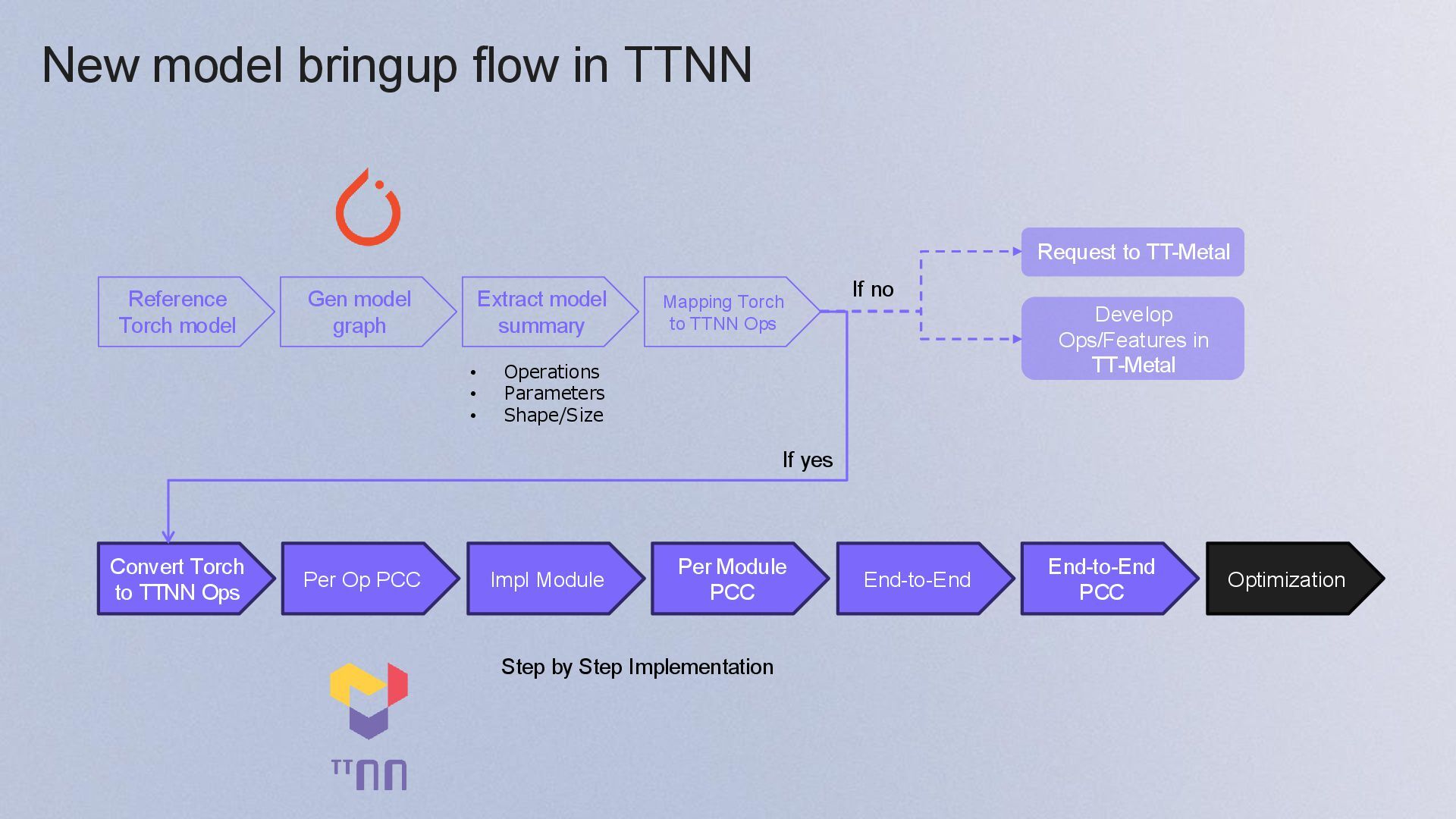{kind=link}
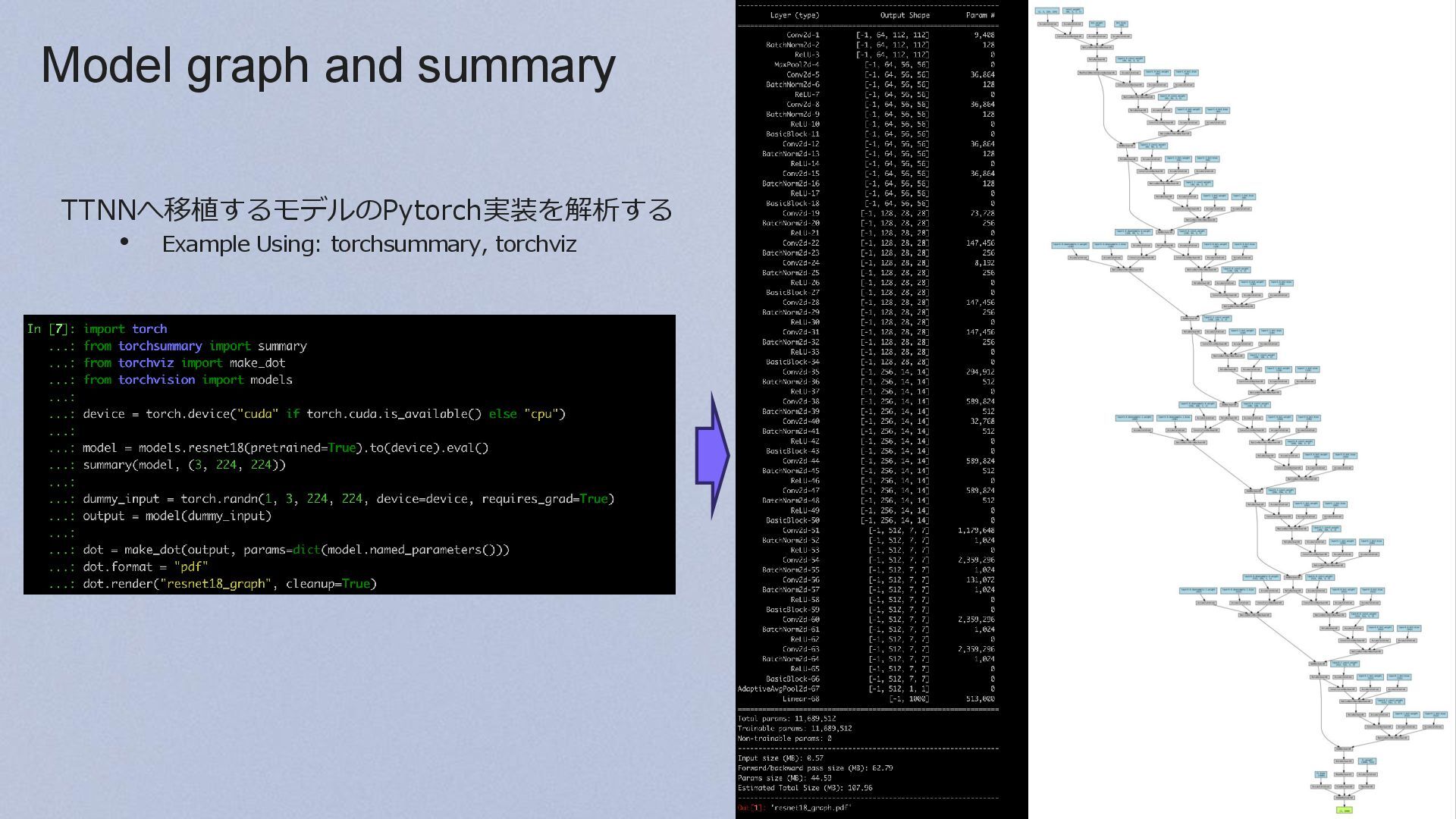{kind=link}
{kind=link}
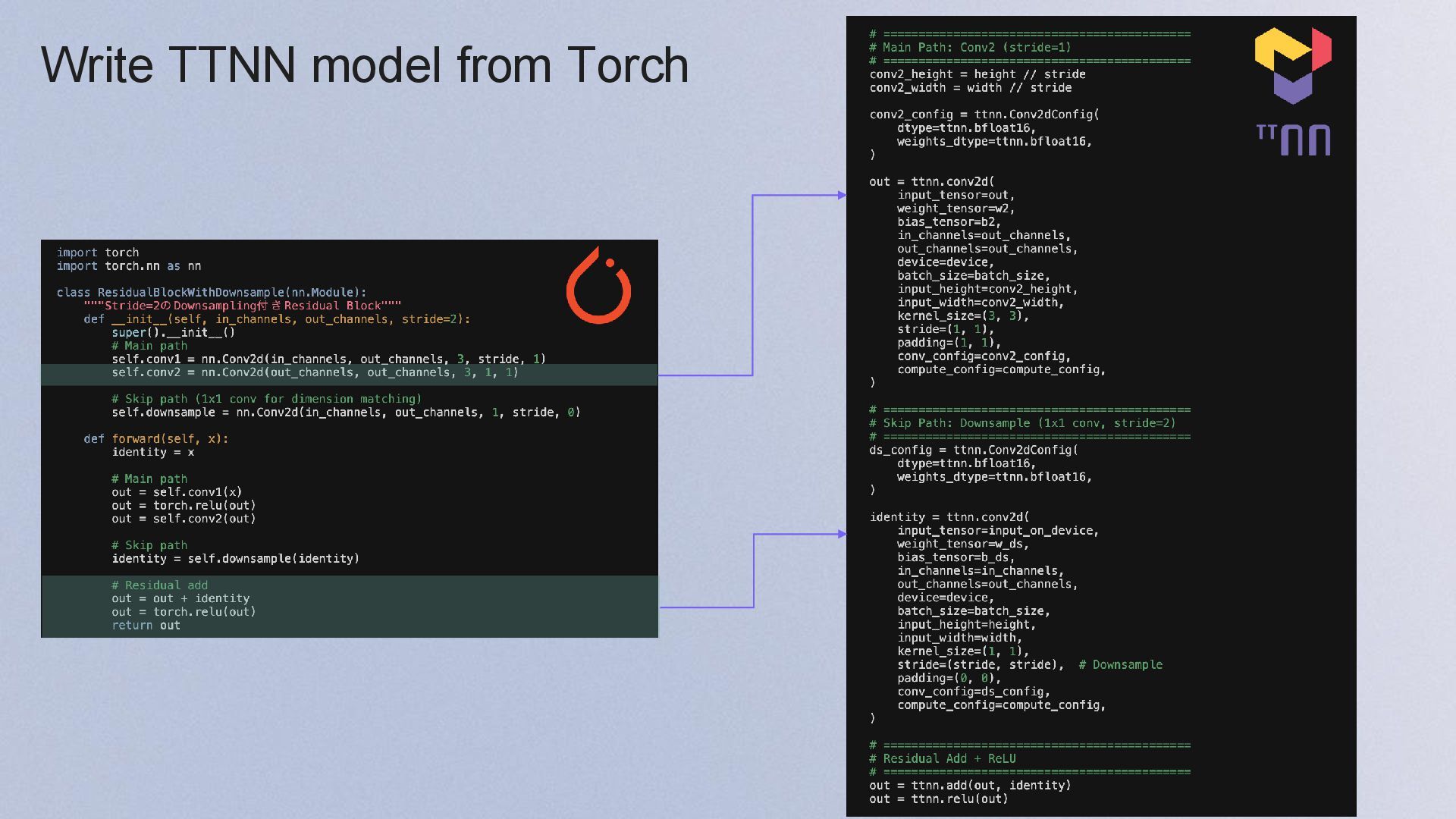{kind=link}
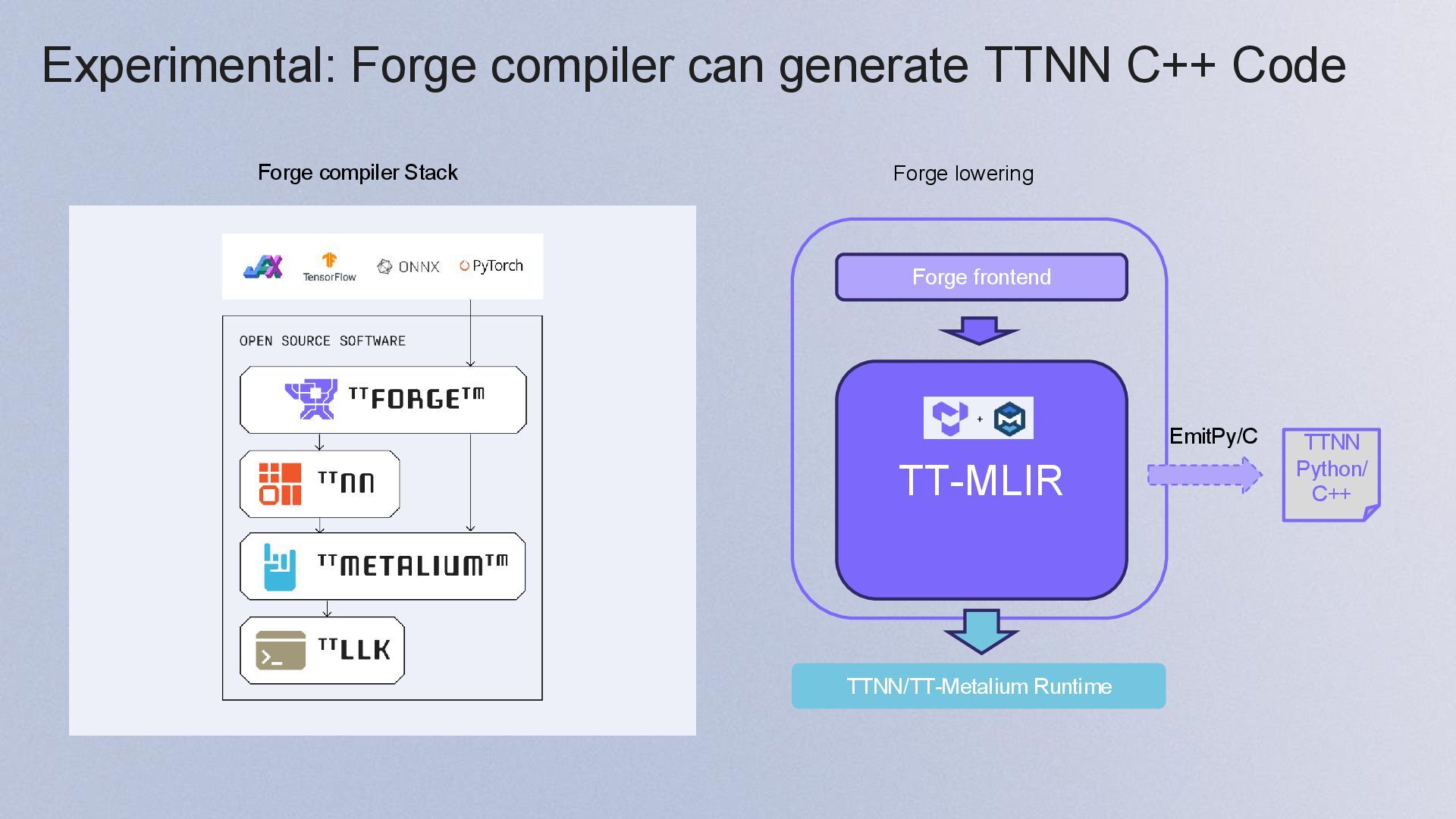{kind=link}
{kind=link}
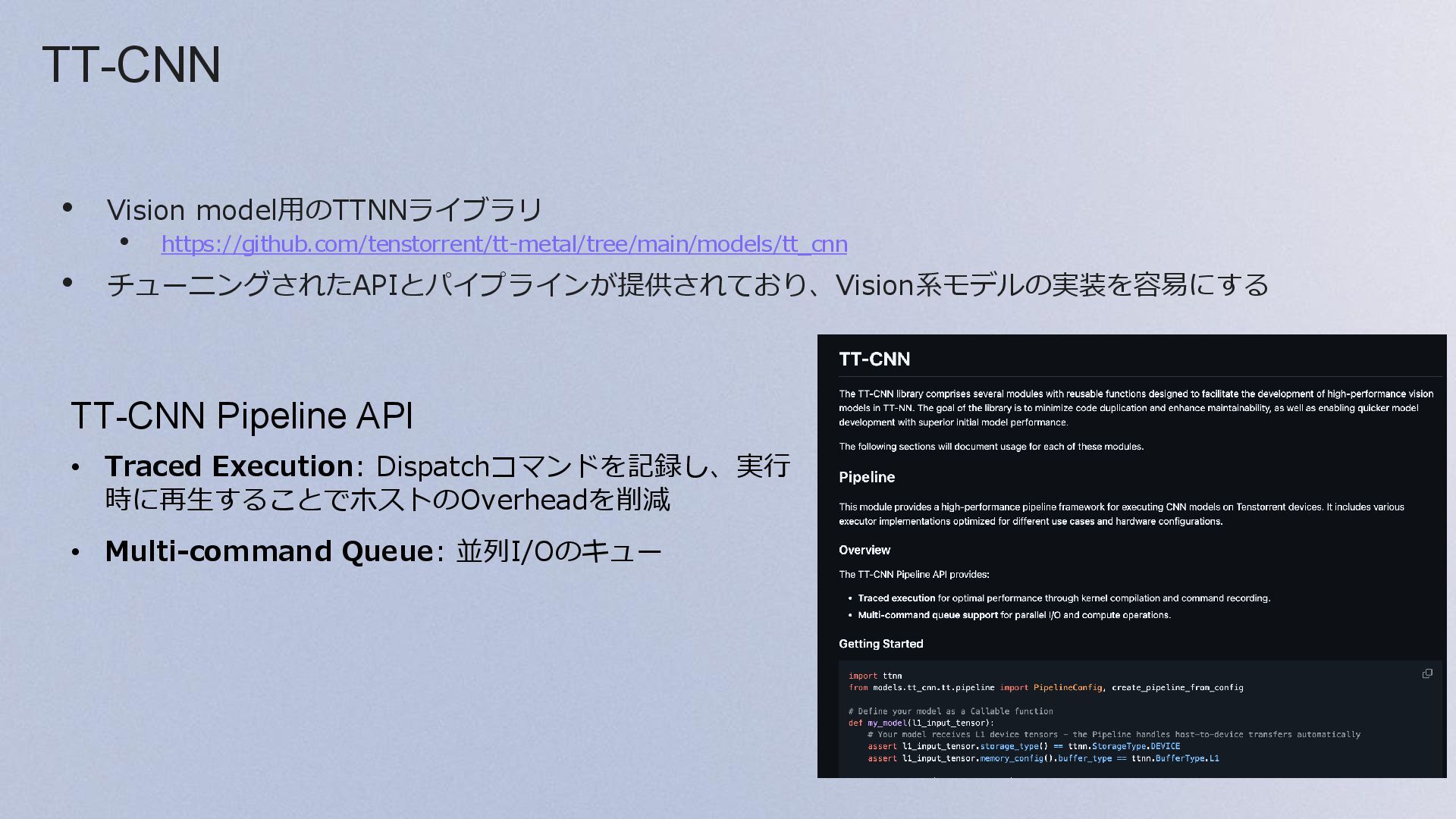{kind=link}
{kind=link}
{kind=link}
{kind=link}
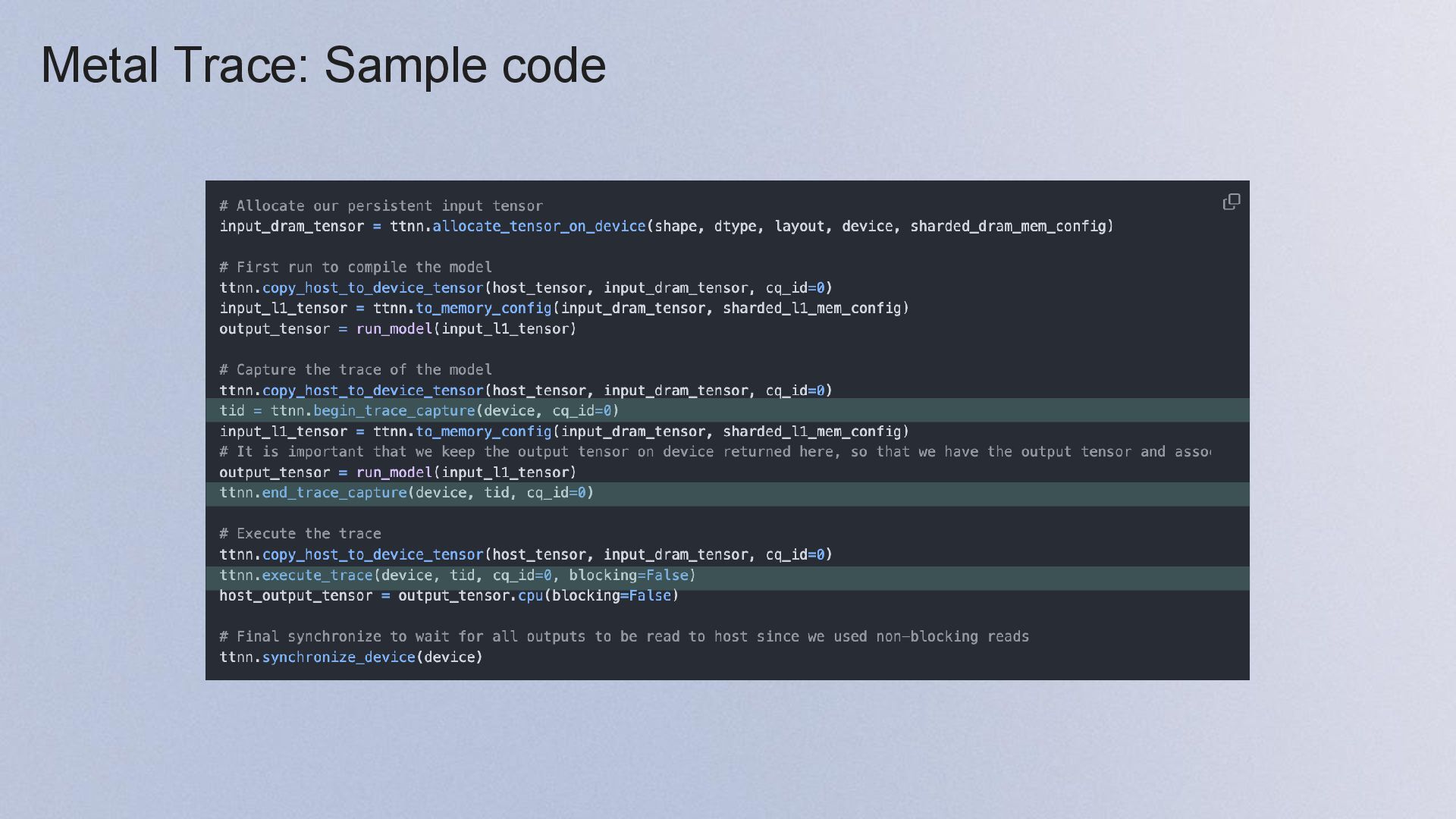{kind=link}
{kind=link}
{kind=link}
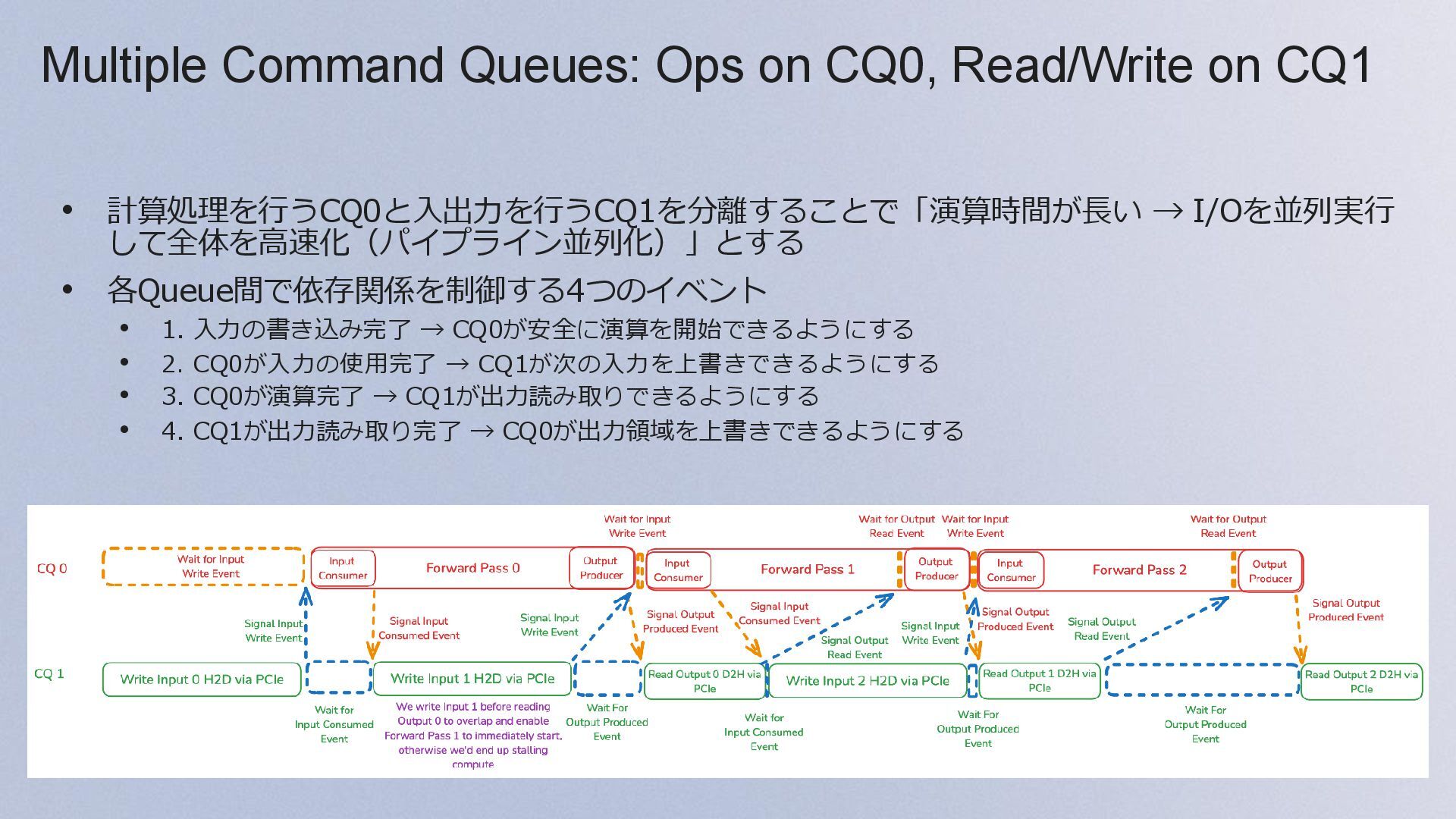{kind=link}
{kind=link}
![TT-CNN Level 4: Full Pipeline Full Pipelineのメモリフロー Input: [CQ1] Host](https://files.speakerdeck.com/presentations/2ae84035d0dd425a9e428104bae04382/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
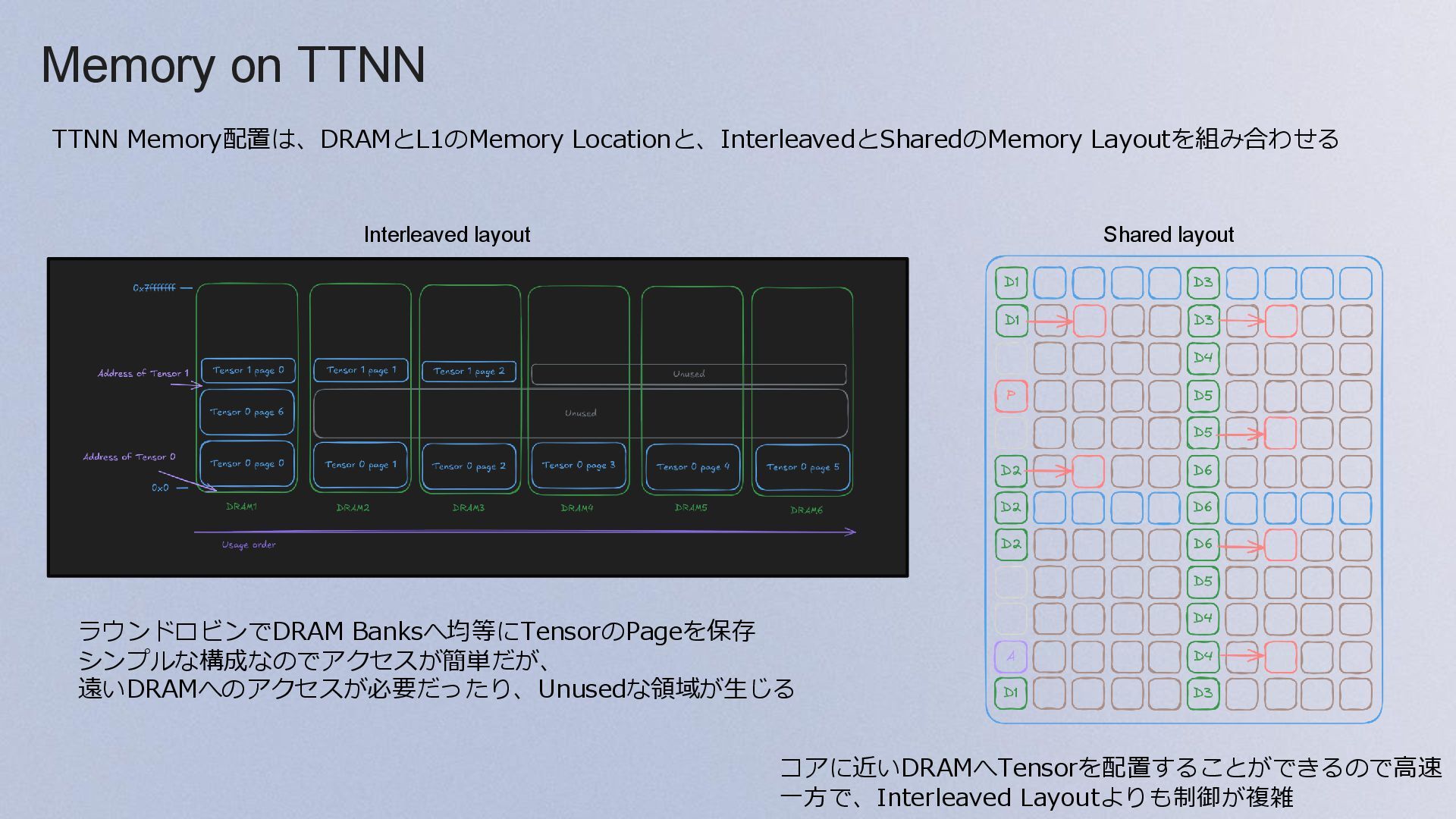{kind=link}
{kind=link}
{kind=link}
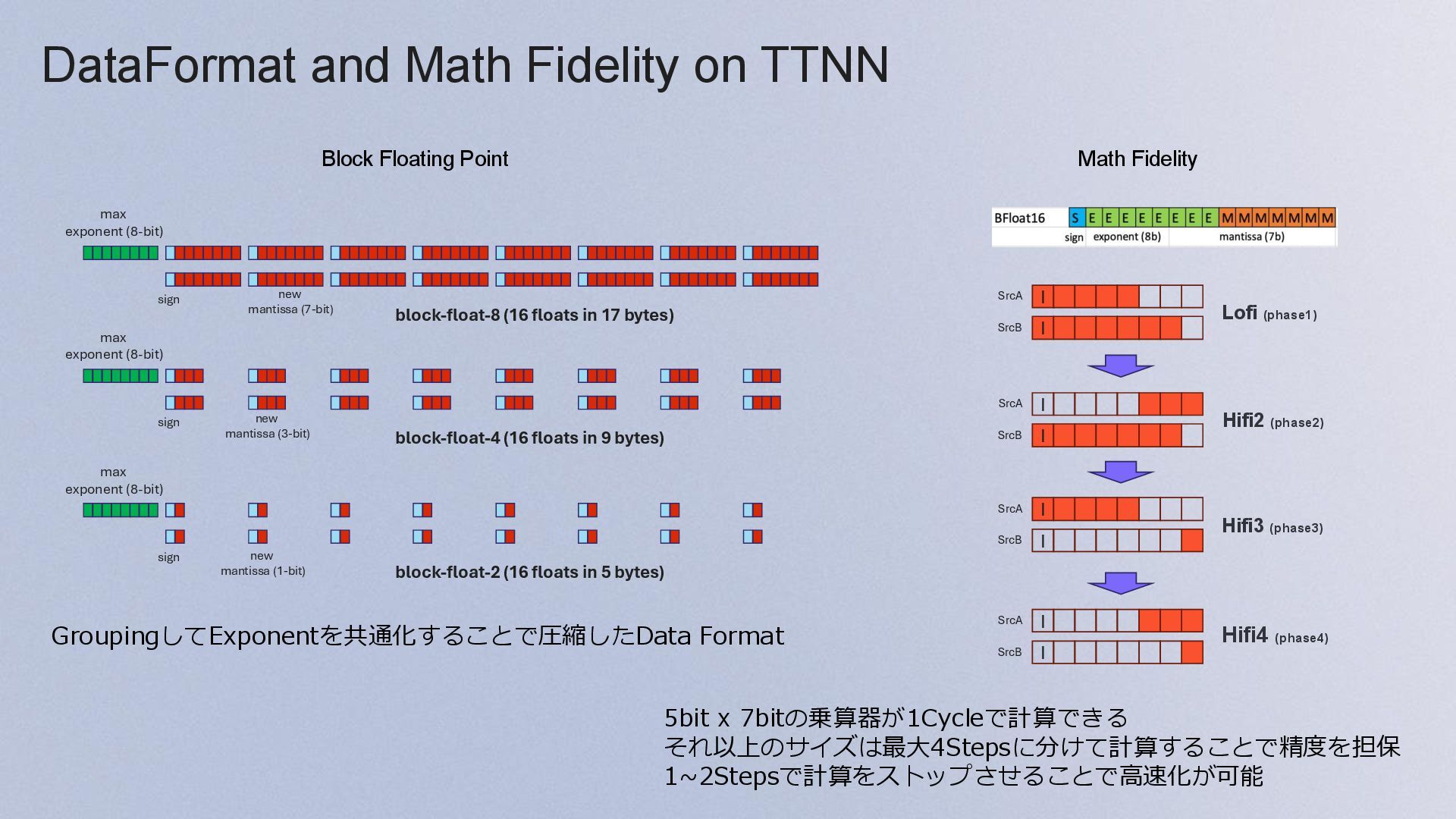{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
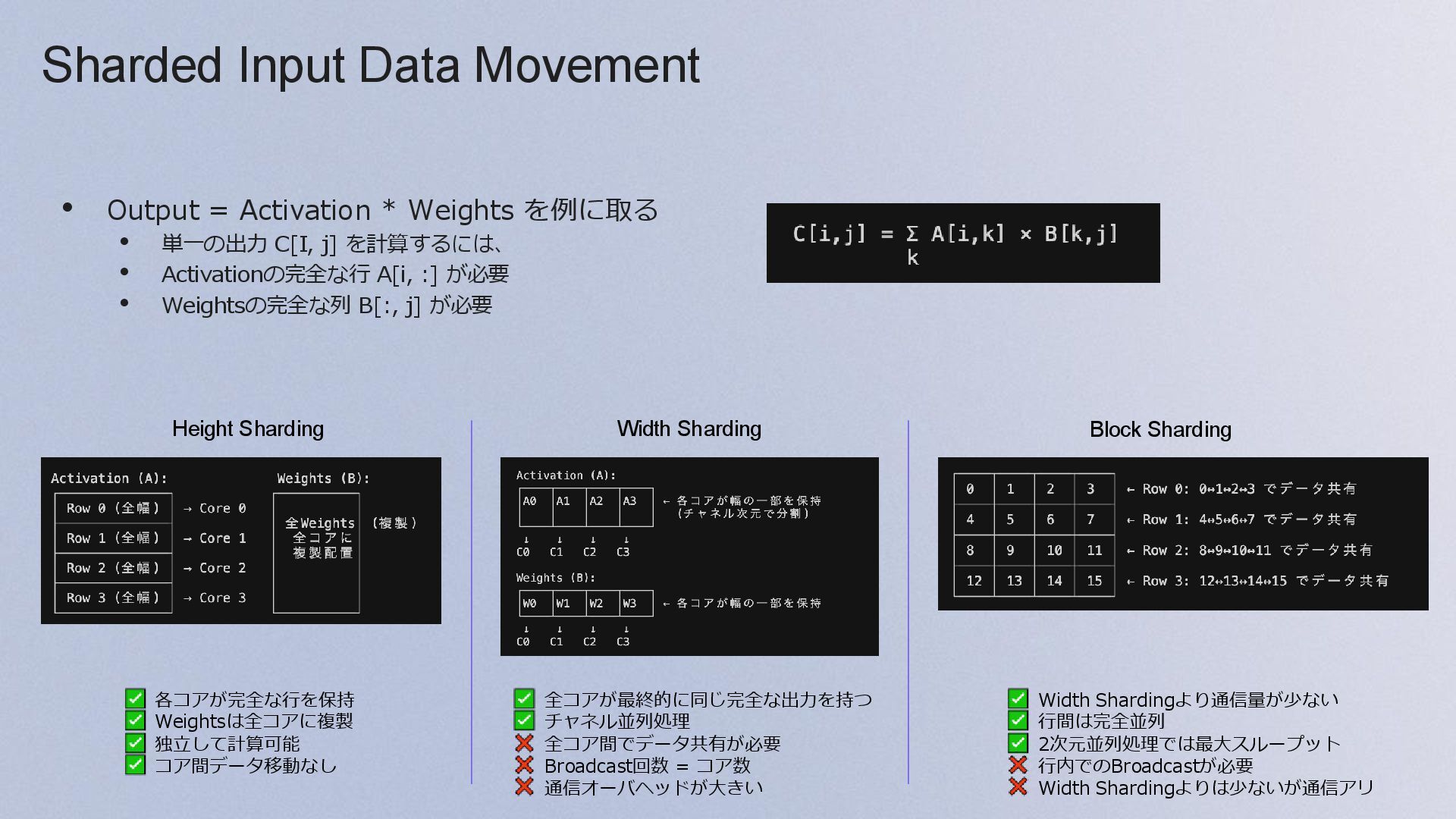{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
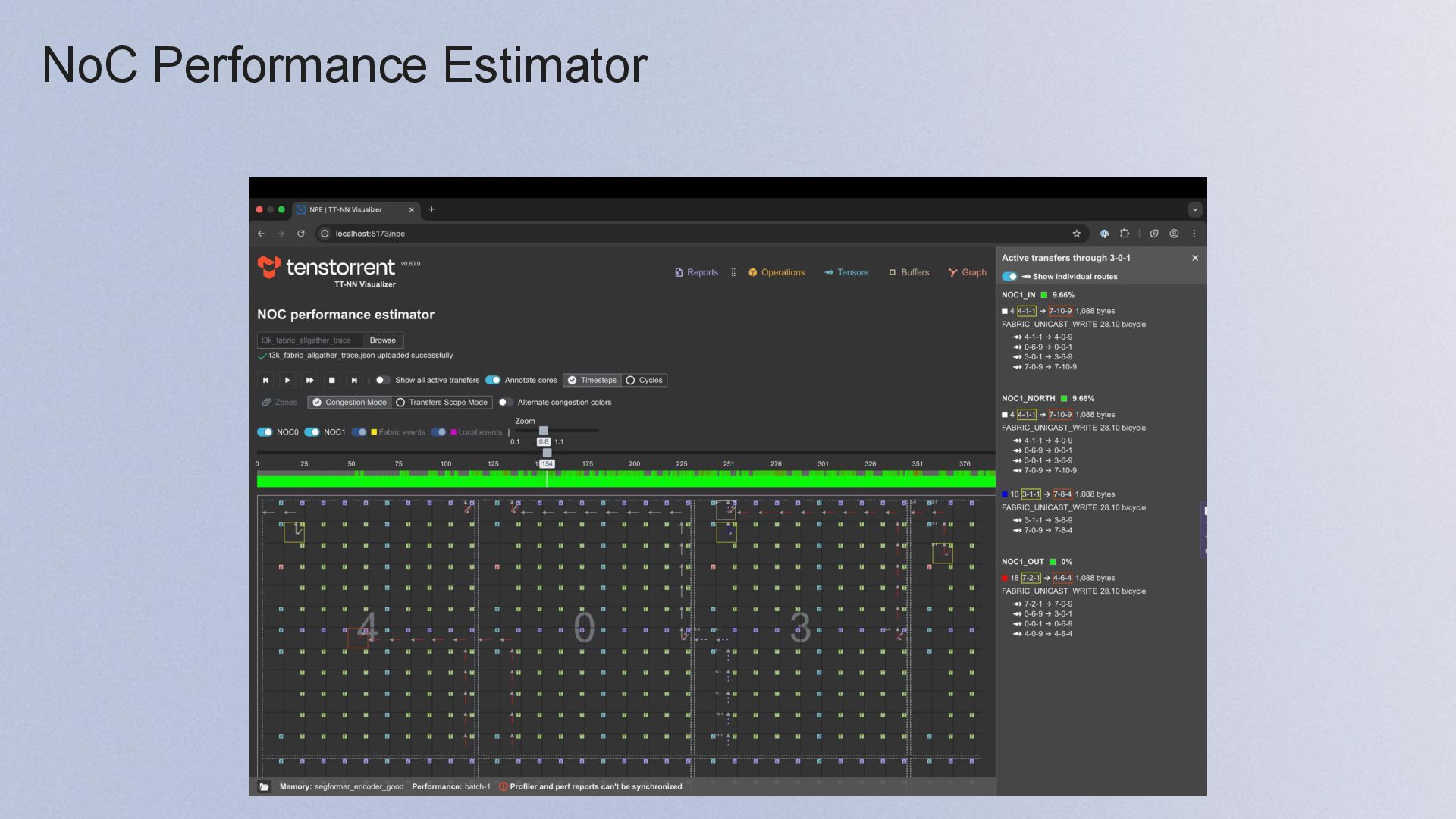{kind=link}
{kind=link}
{kind=link}