these external companies, we may have a roughly accurate view of what companies have invested in Pandora, and the amount they have invested compared to others.
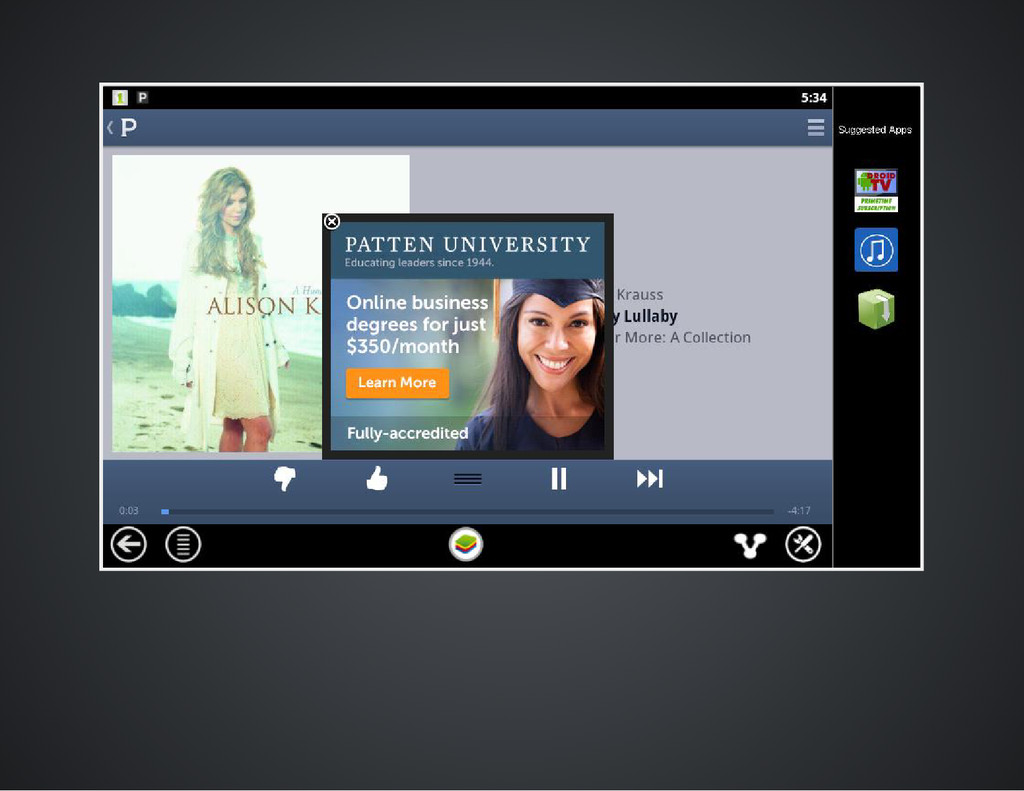
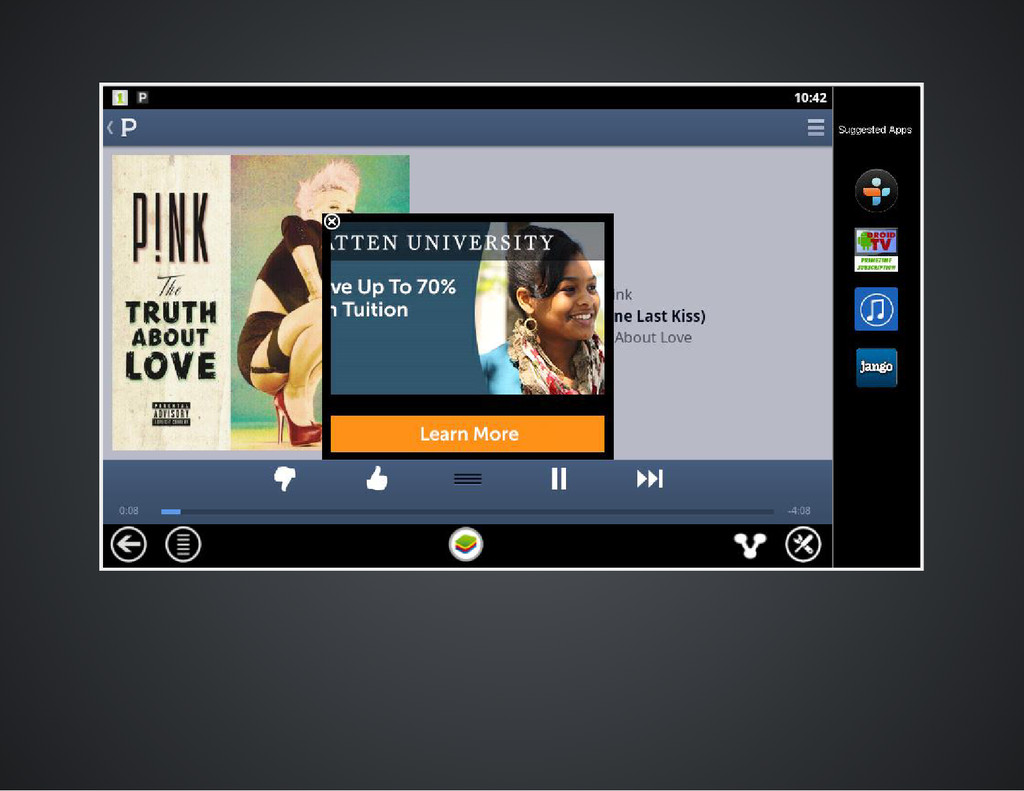
do not want to alter traffic to these sites. We are classifying across hundreds of stations and geographically distributed IP's Why not just look at the link's url? The ads are embedded in the audio player (making the links hard to find) and are often shortened and made unrecognizable
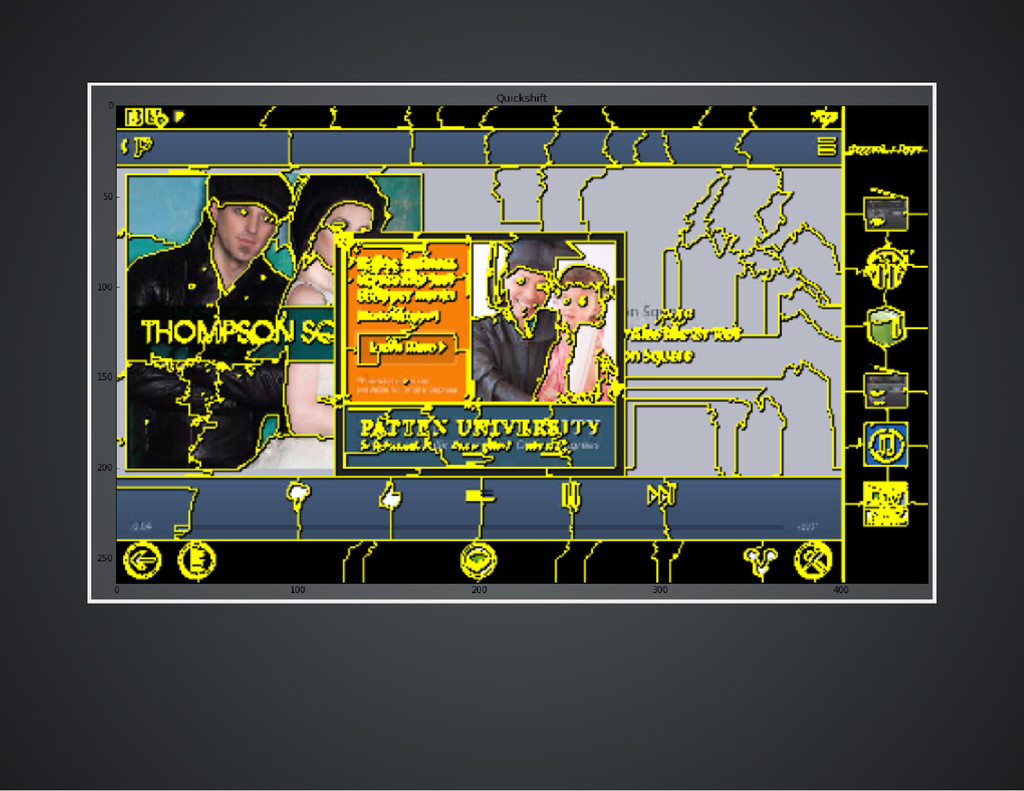
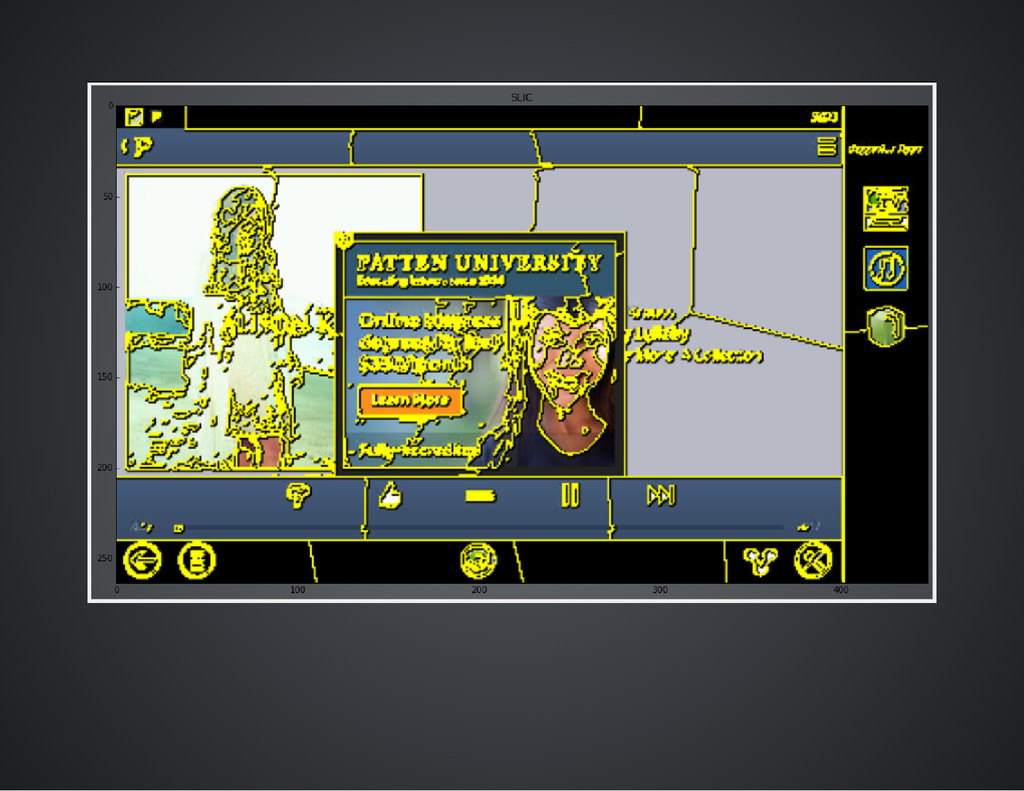
objects with texture, orientation, and depth. It is very likely more complicated features, including Gabor wavelets, would be needed to classify such an image.
correctly. We're confident the algorithm will perform at least as well as the SVM since Gary's implementation has been used and resulted in 99% accuracy on a similar data set.
labeled instance. Another possibly was to provide a feature of the time the ad was found, weighting more recent ads as more important while still keeping a reasonable training set size.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
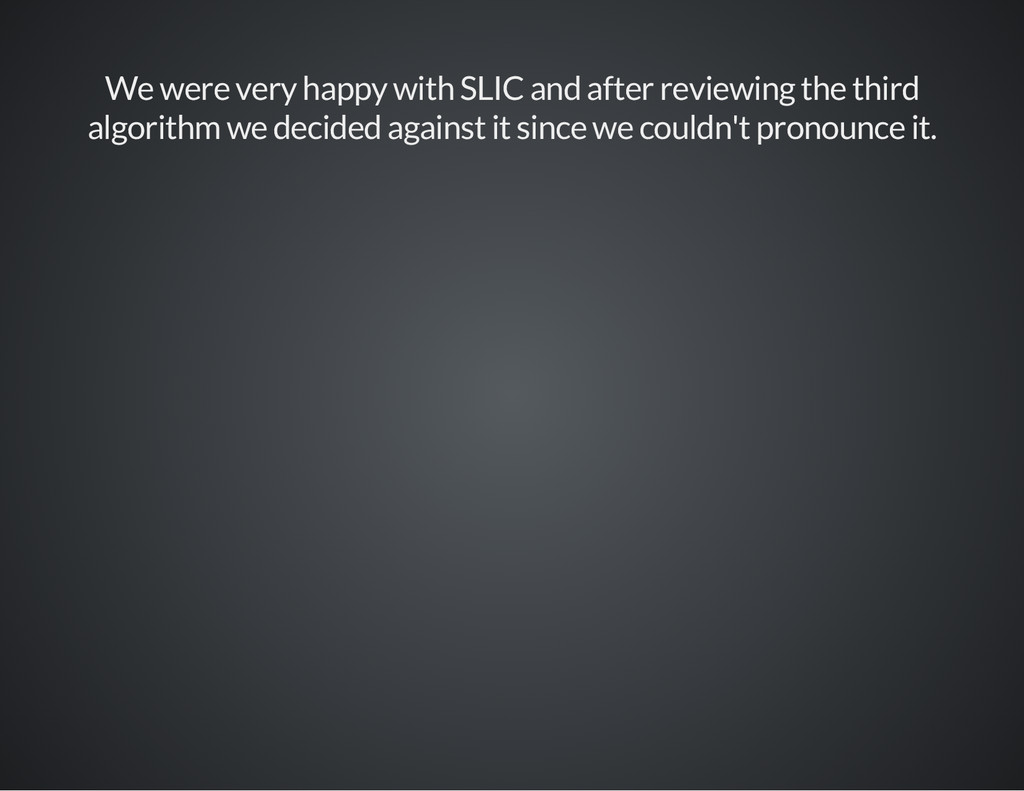{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
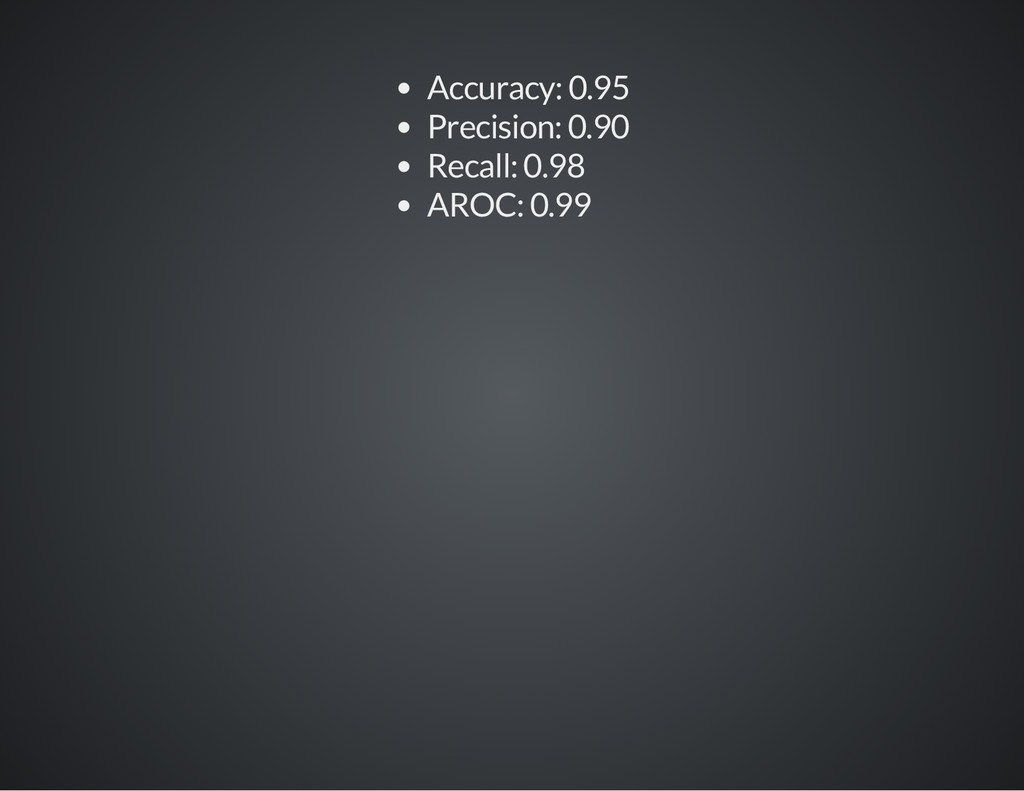{kind=link}
{kind=link}
{kind=link}
{kind=link}
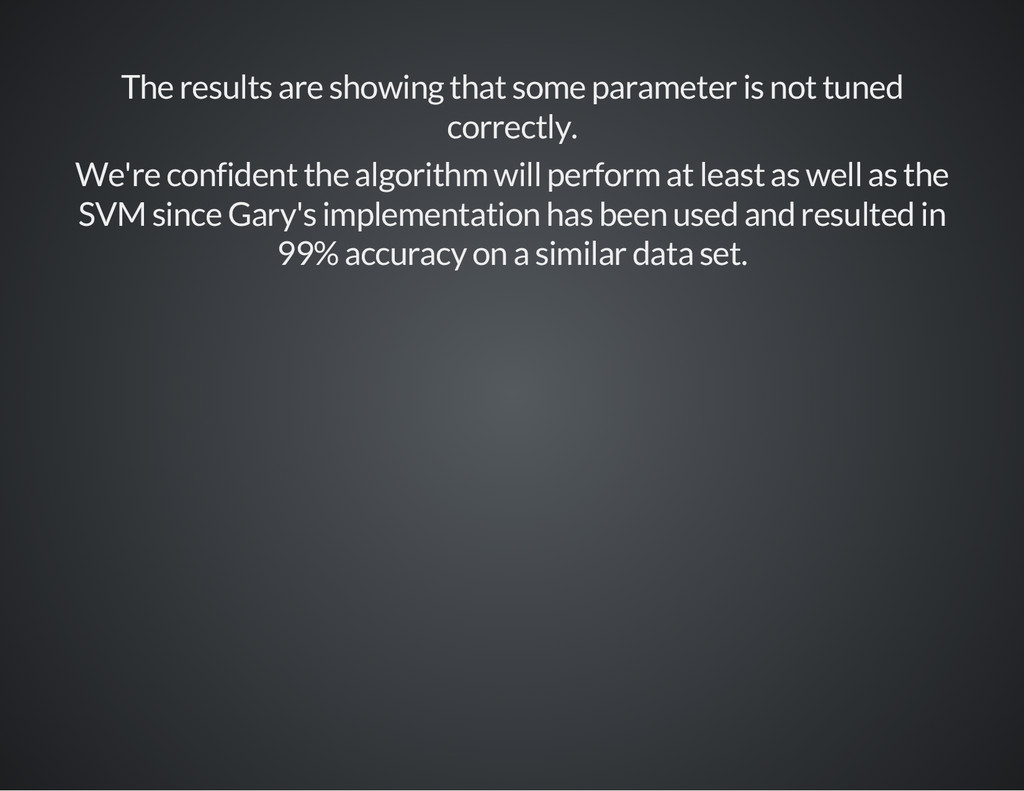{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}