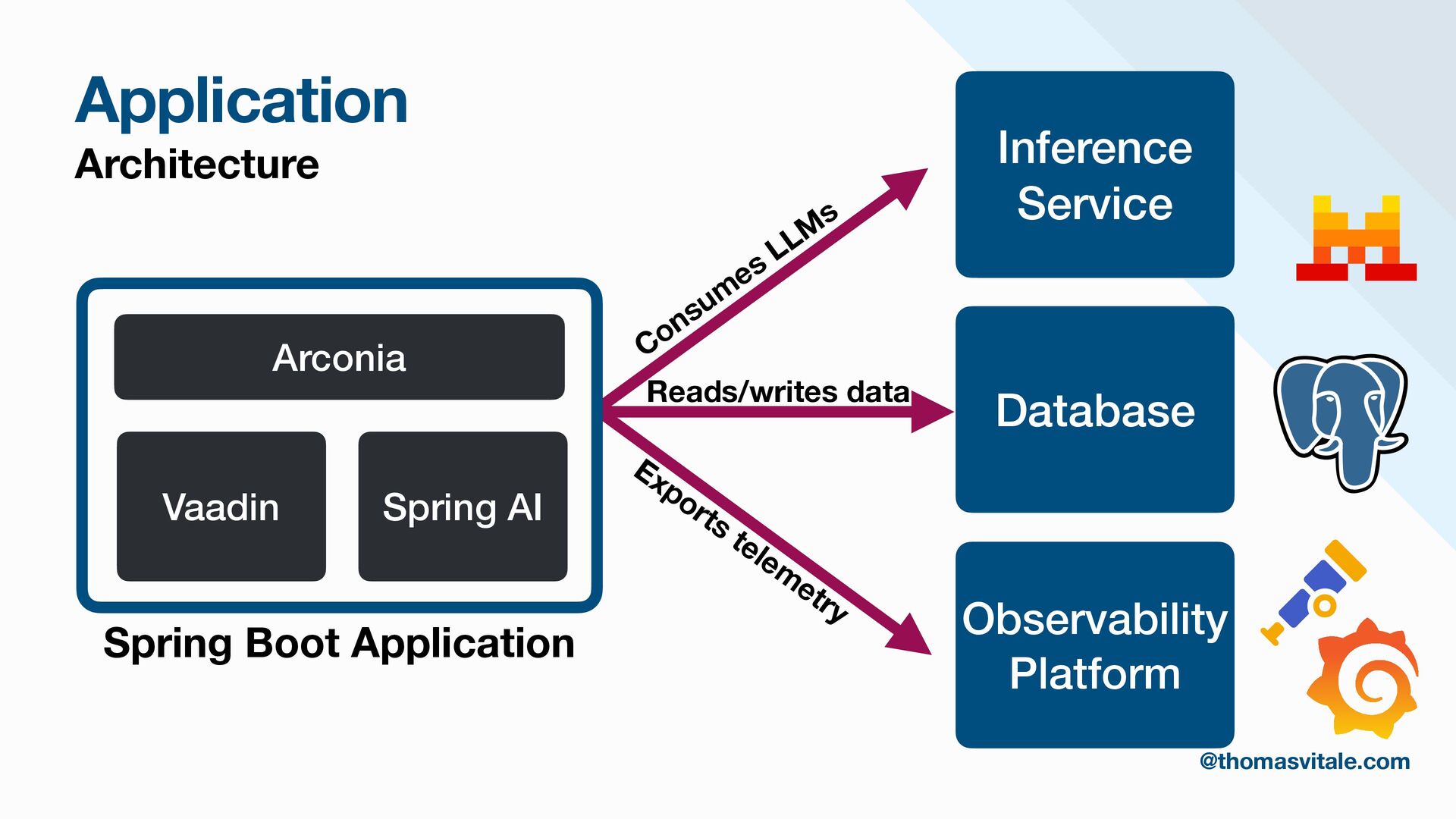
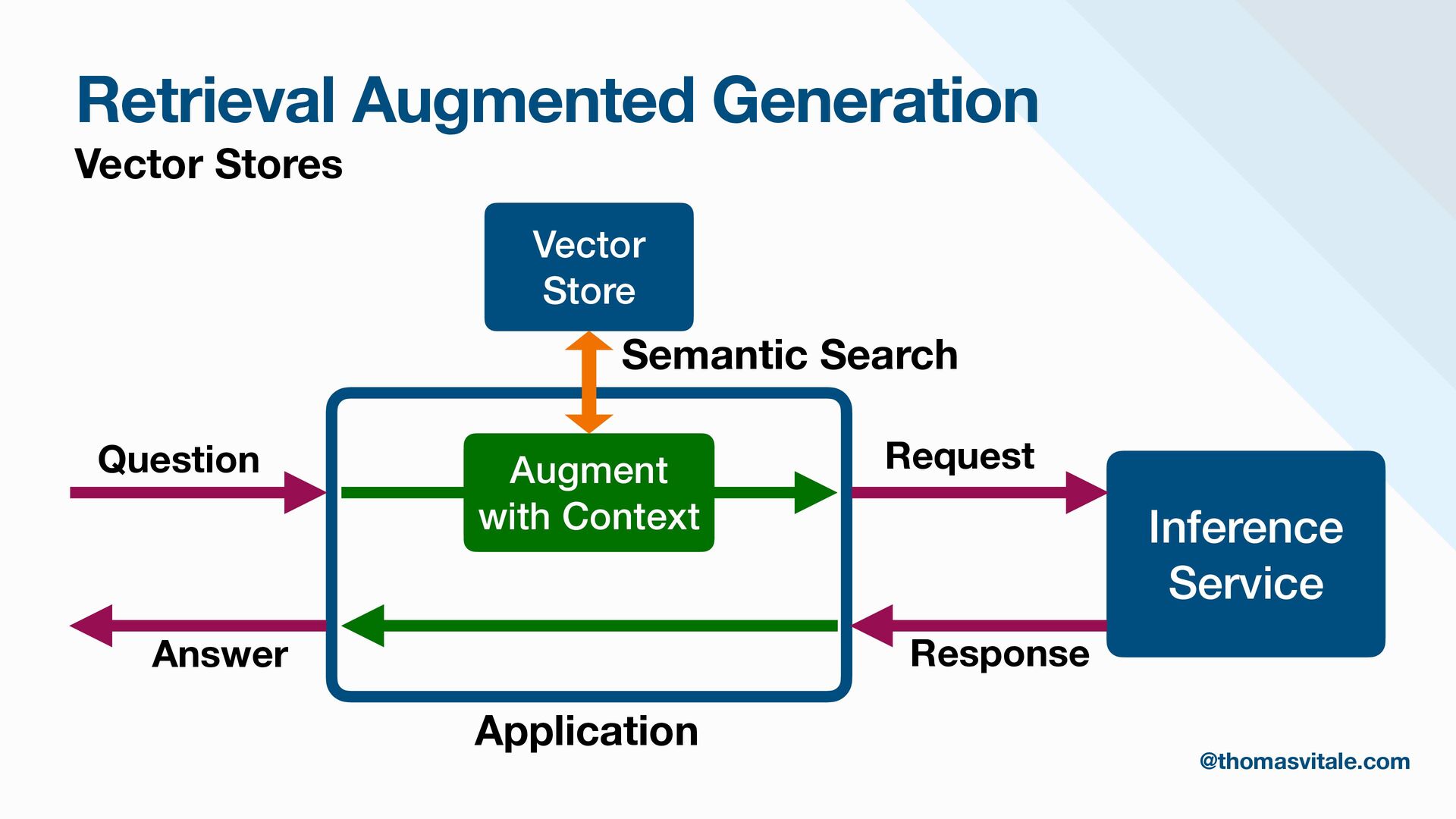
Retrieval-Augmented Generation (RAG) is a foundational approach to enhancing LLMs by integrating them with targeted, domain-specific data. This session will provide a hands-on guide to designing and implementing modular RAG architectures using Java and Spring AI. Through practical examples, you will gain insights into building production-ready RAG workflows that support both current and future use cases.
The session will cover five key stages:
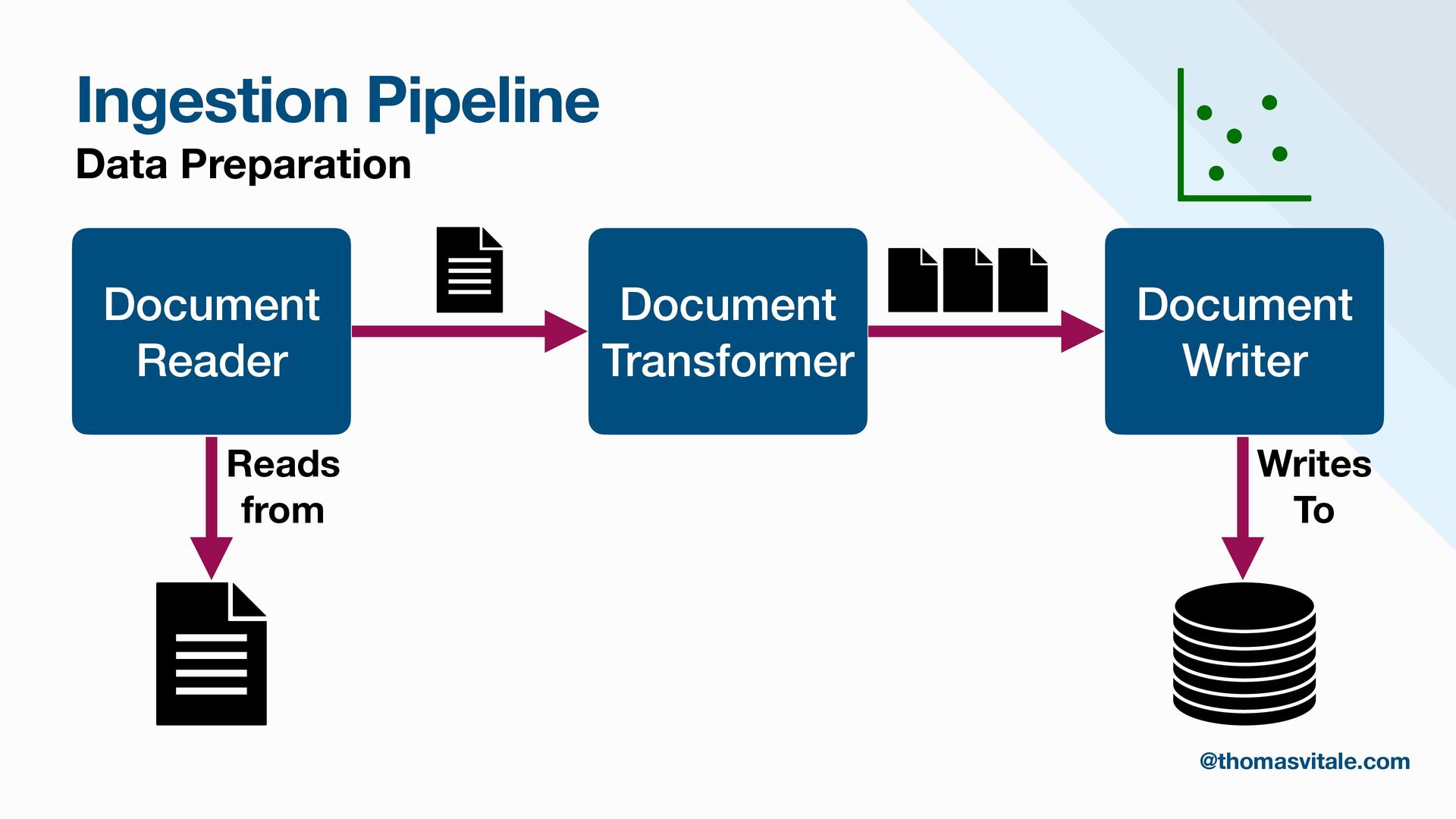
- Data Indexing: Methods for structuring, chunking, and indexing documents, improving the efficiency and accuracy of downstream retrieval tasks.
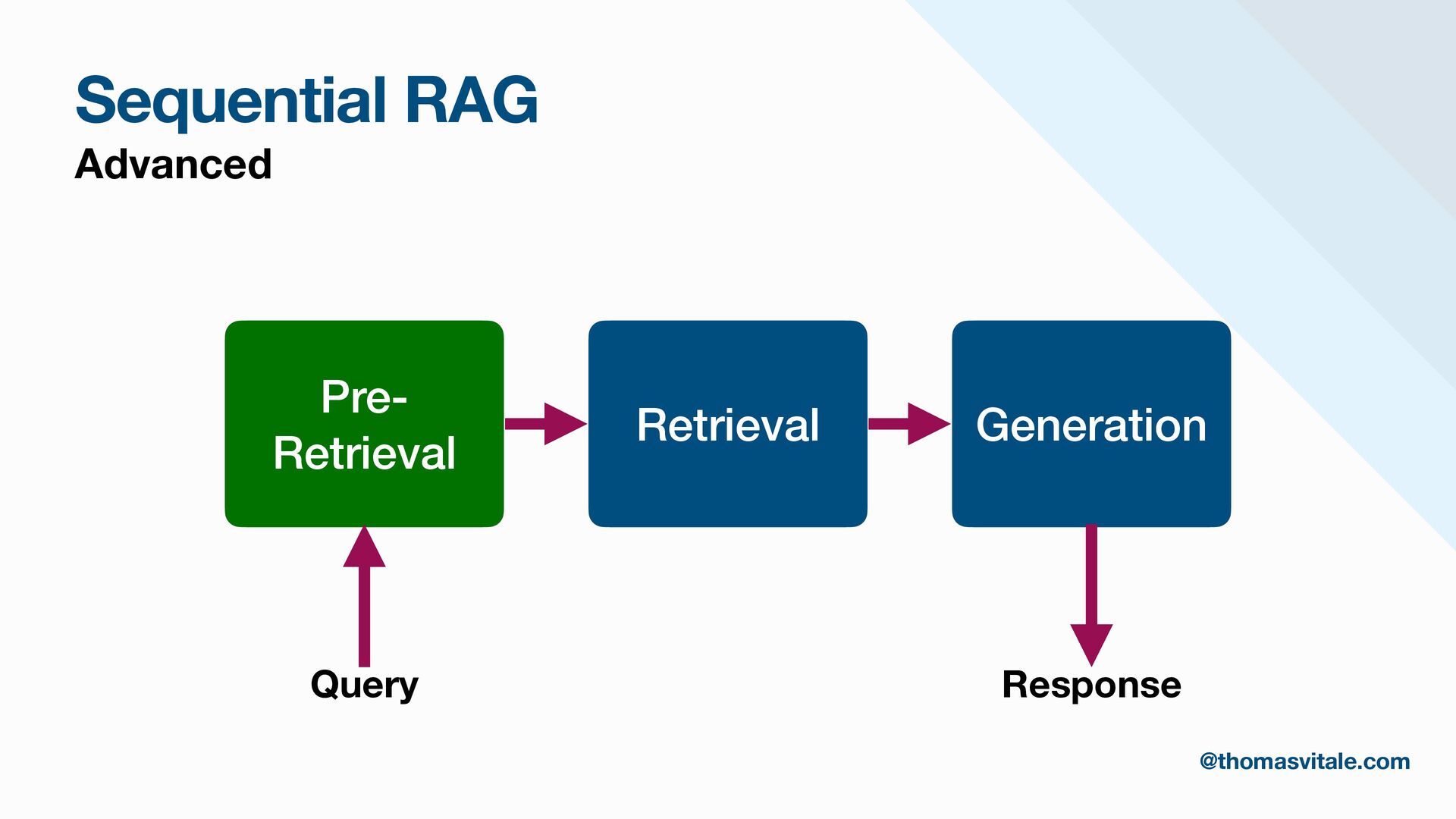
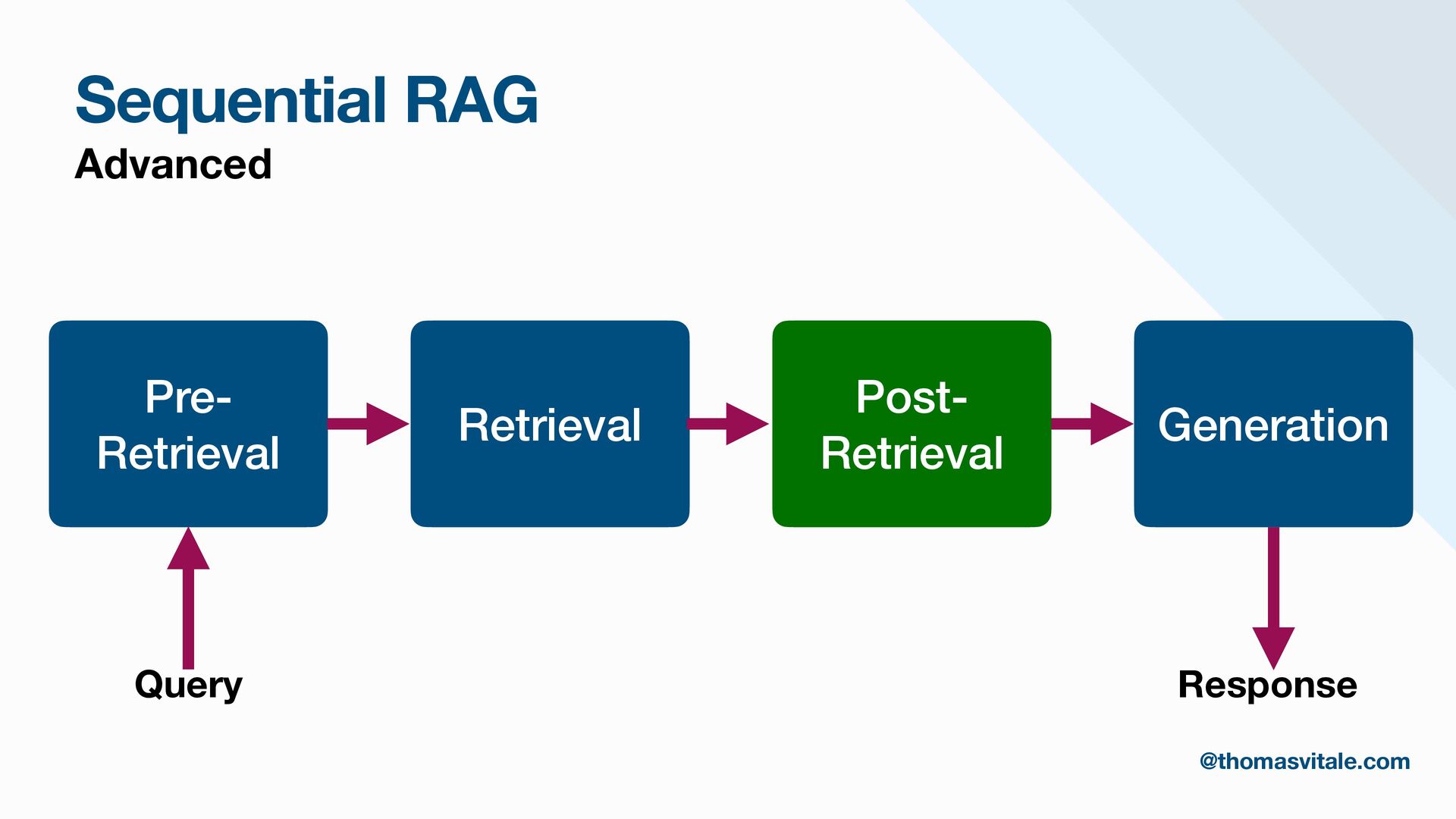
- Query Analysis: Techniques for transforming and enhancing queries in the pre-retrieval phase to improve relevance and precision during retrieval.
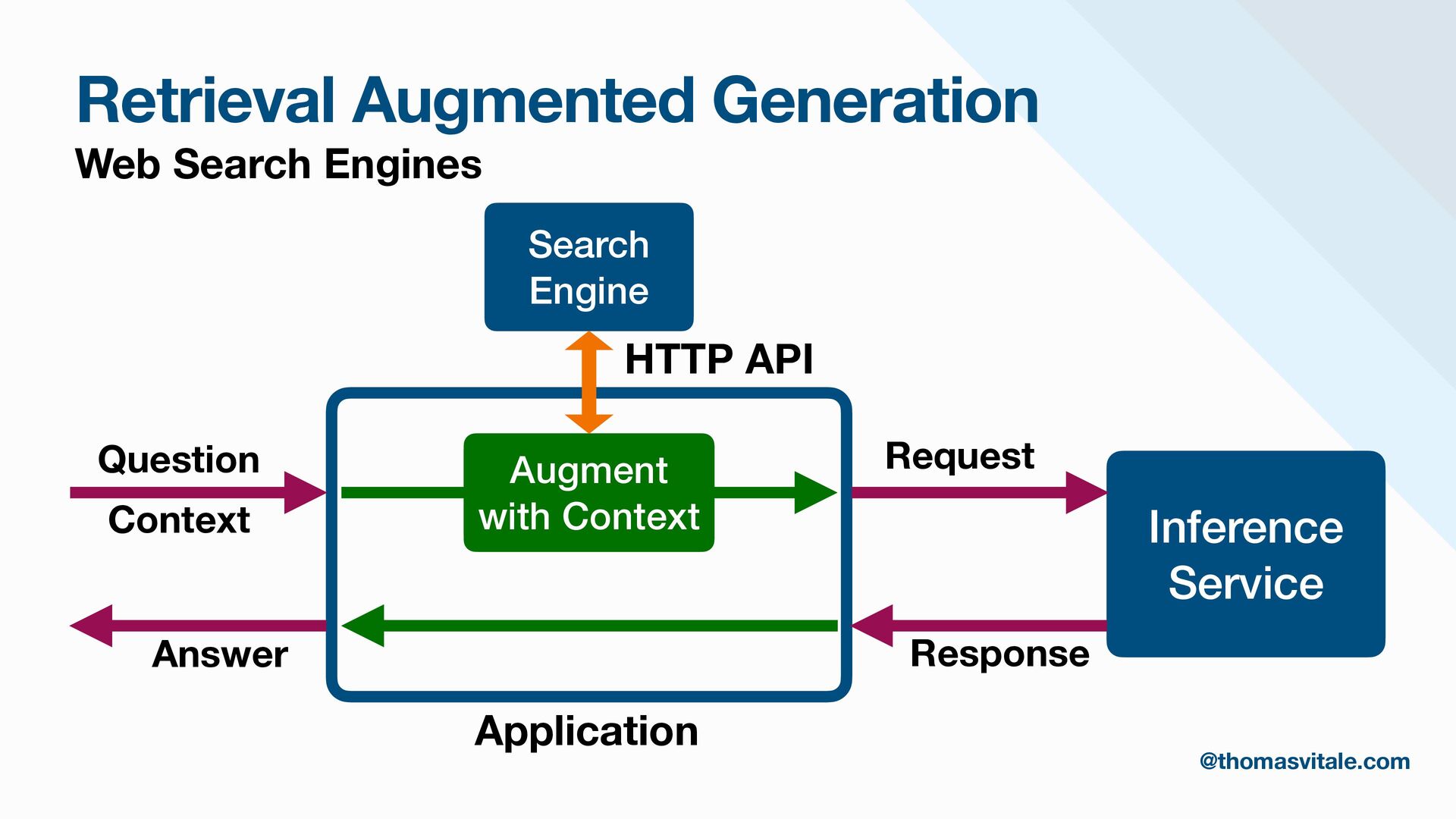
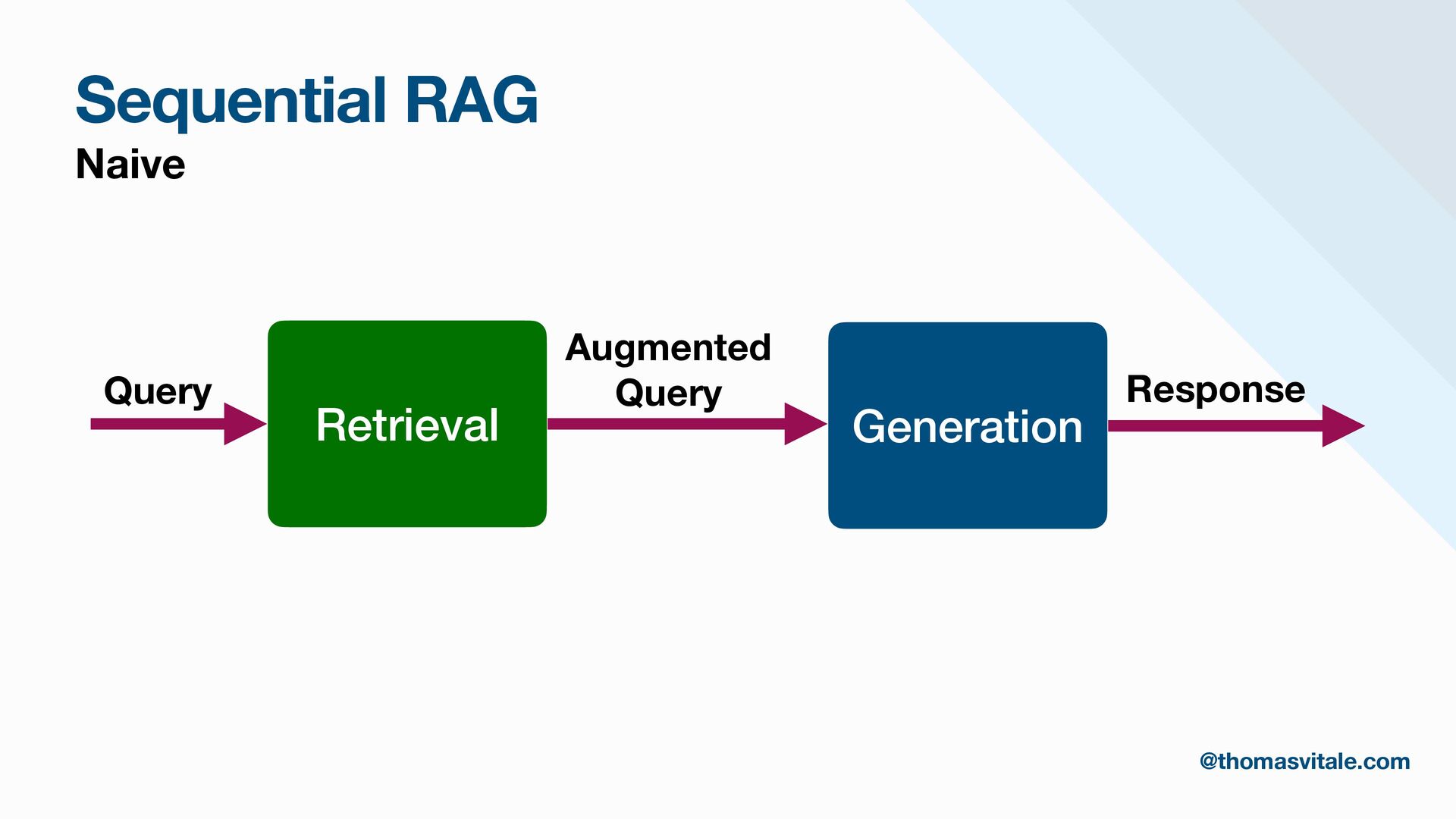
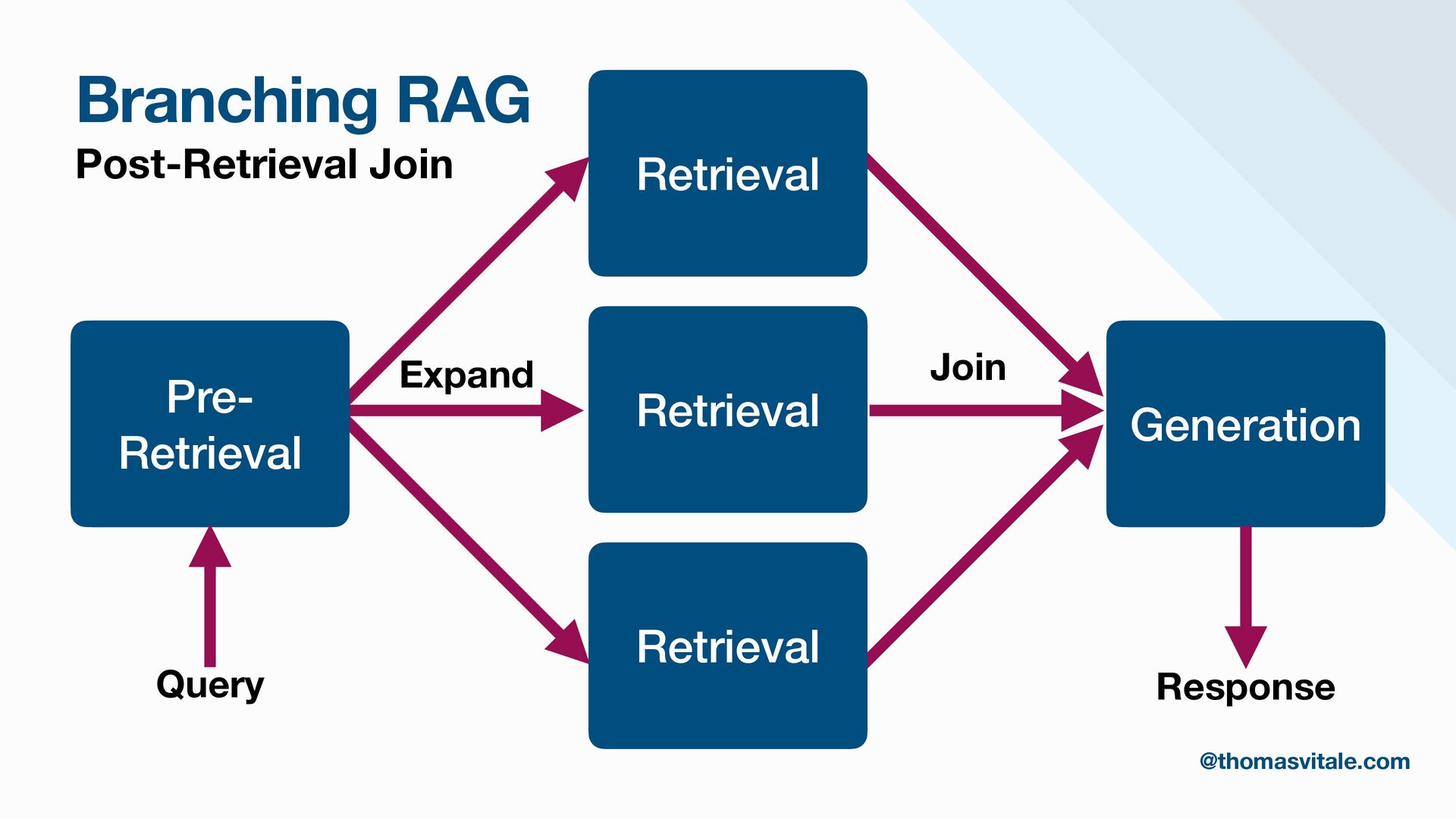
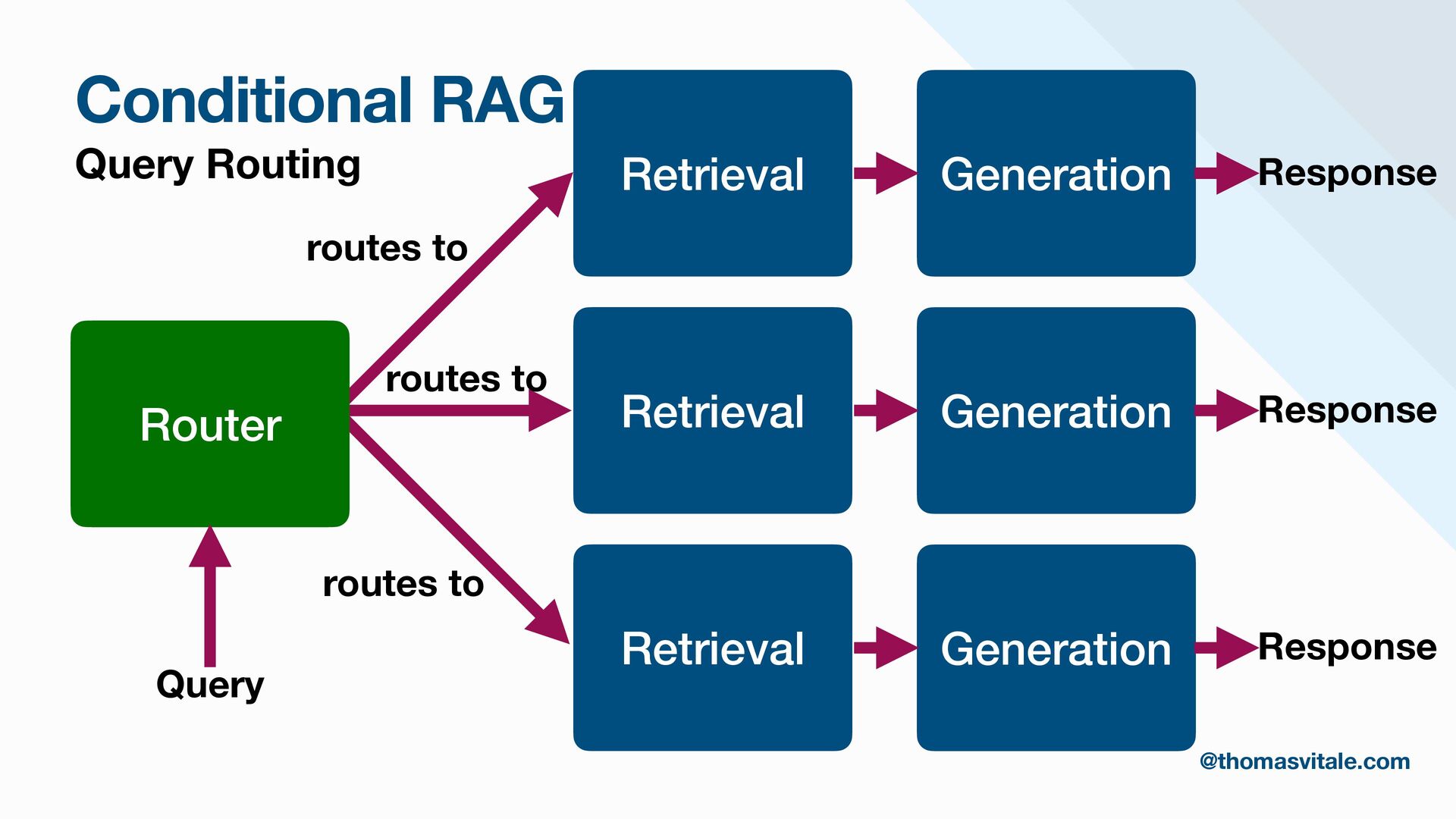
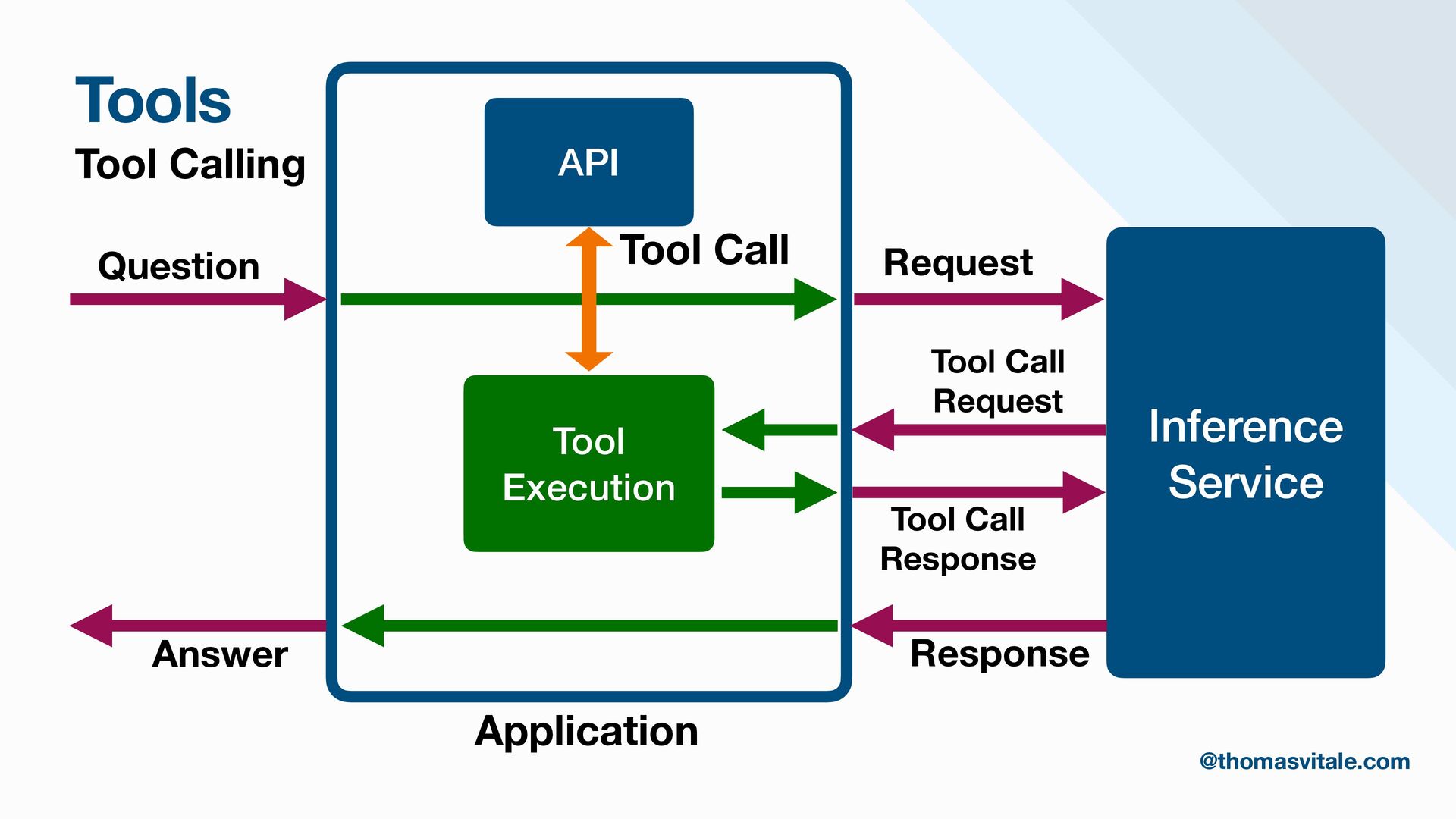
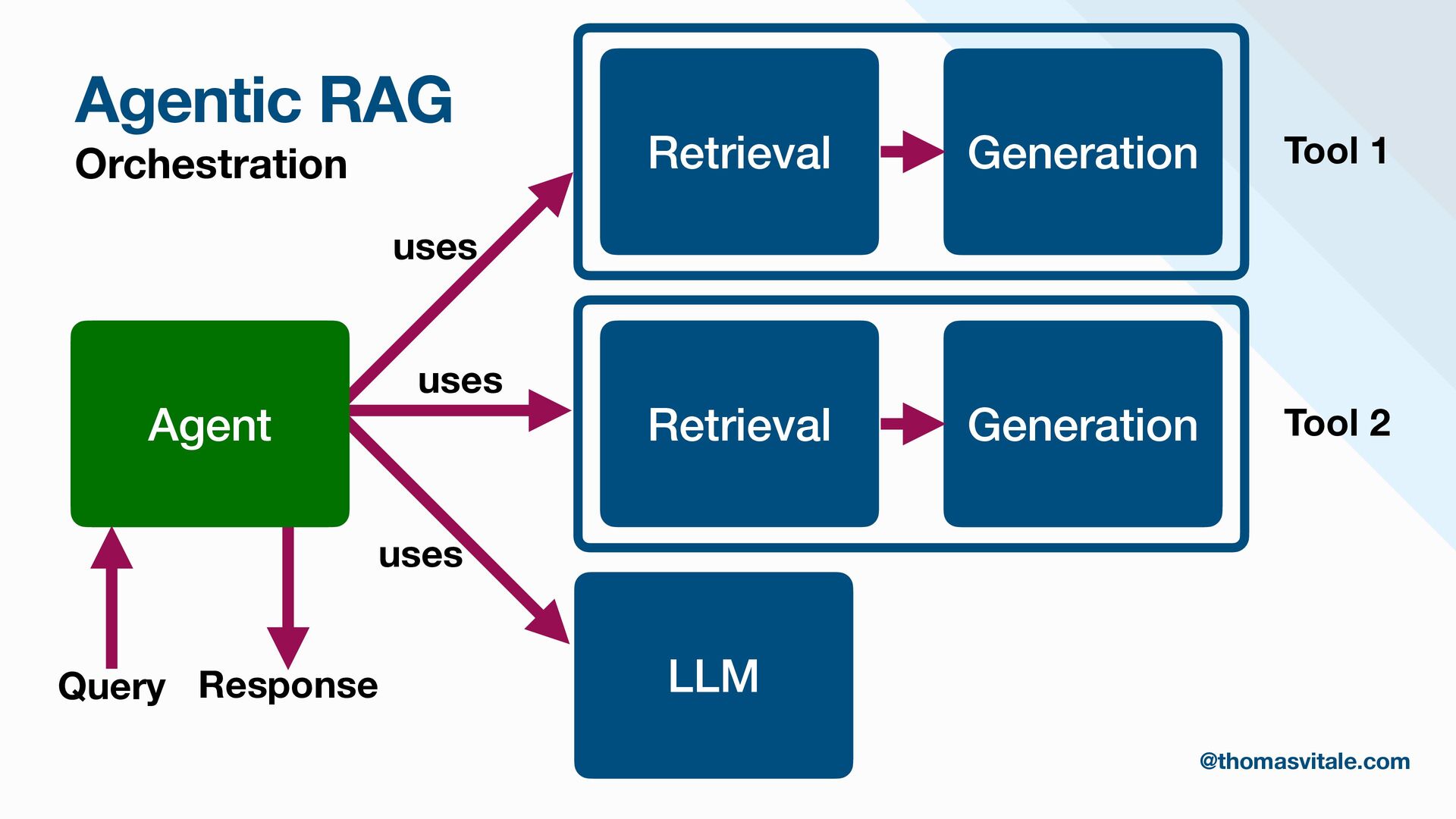
- Retrieval: Strategies for sourcing data from multiple repositories, using agent-based routing to select relevant data sources, and combining, re-ranking, or filtering results to deliver the most contextually relevant information for generation.
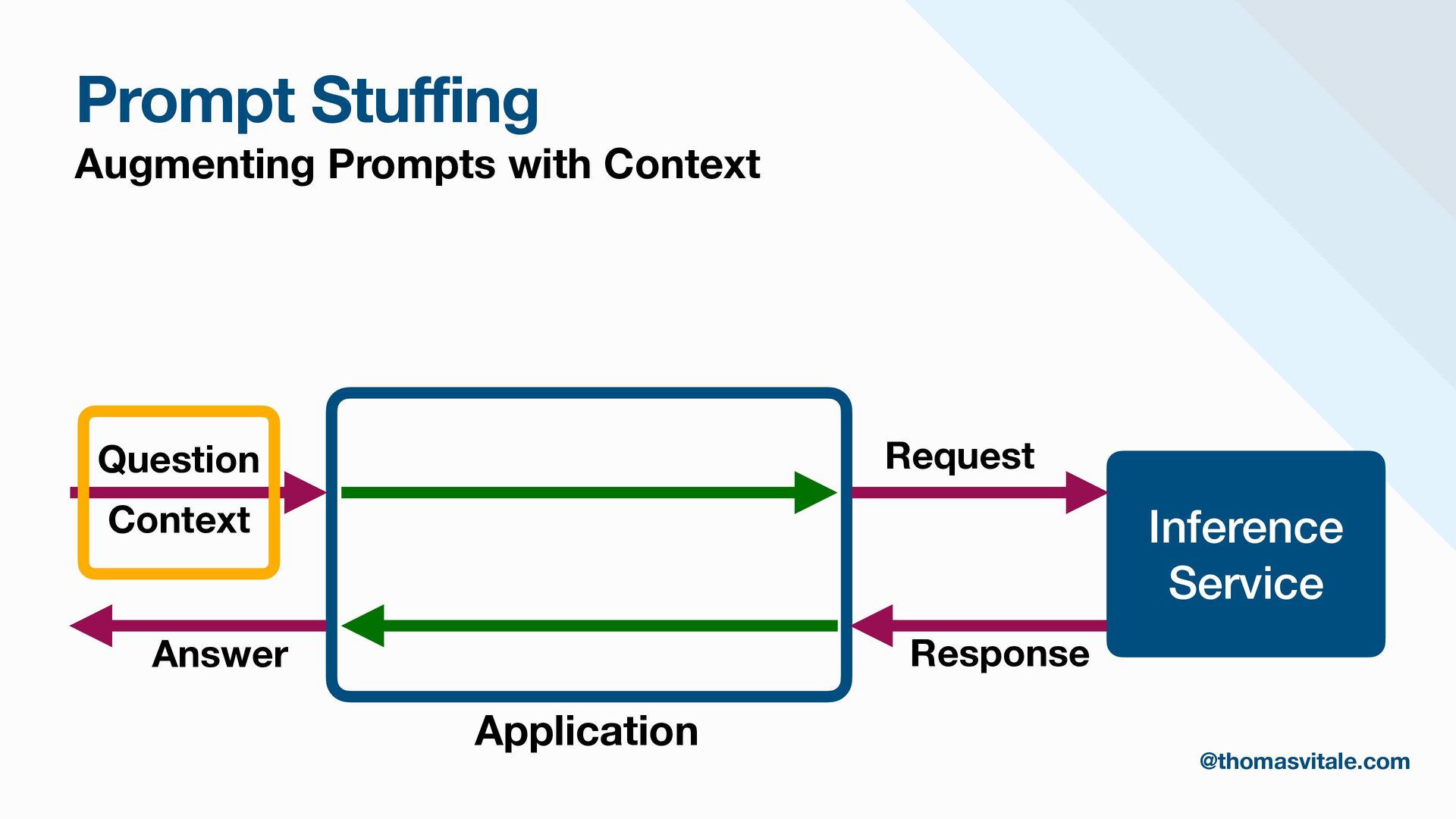
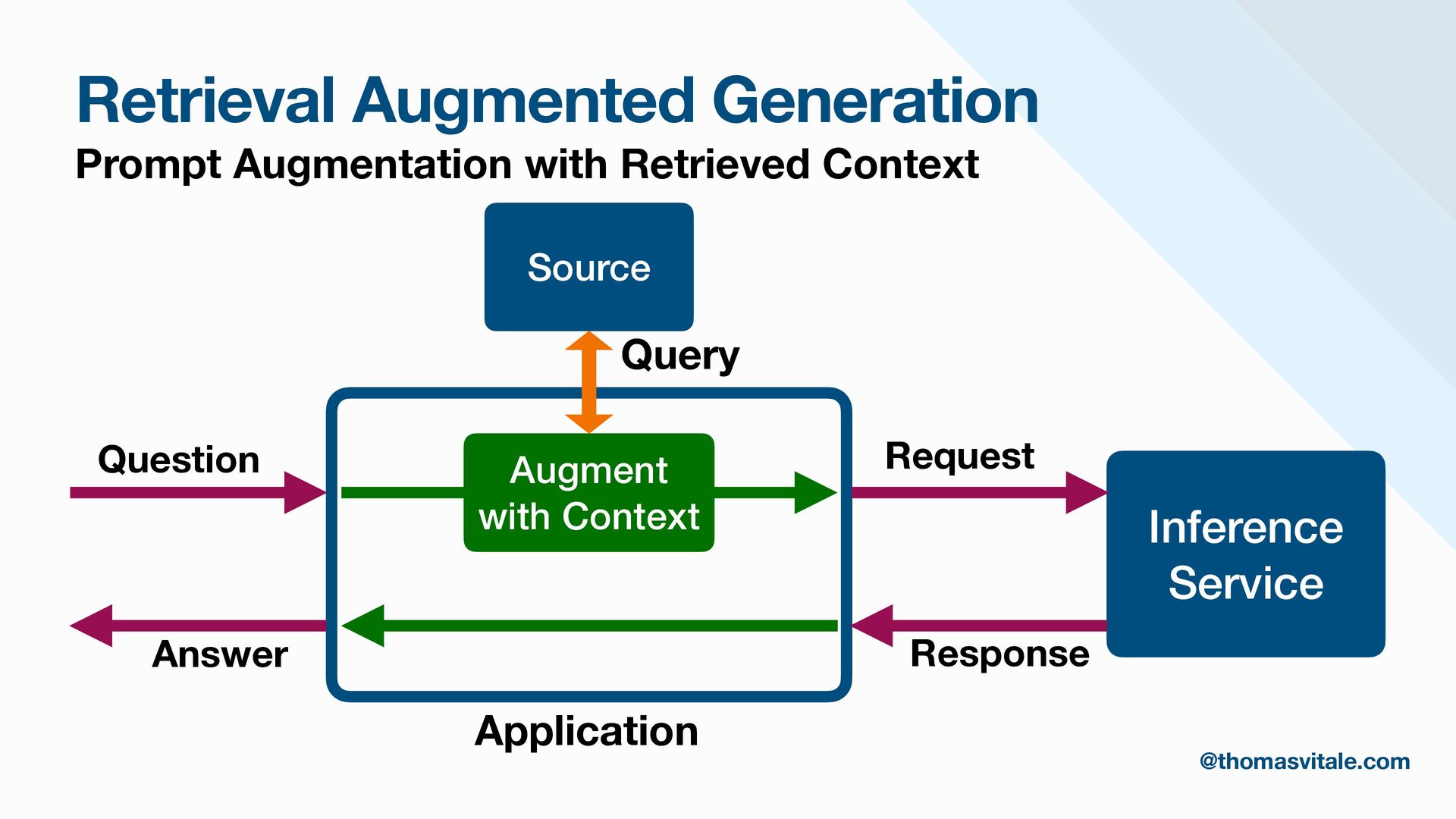
- Augmentation: Methods for augmenting user prompts with retrieved content, including advanced techniques for contextualization, citation, and summarization.
- Evaluation: Metrics and evaluation methods to assess document relevance and model output accuracy, as well as iterative feedback loops for refining RAG workflows to meet quality standards.
Additionally, the session will address important considerations for observability and developer experience in building RAG workflows.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}