and Linux Fan Boy • You can follow me on twitter @TiemmaBakare • General Weird Guy with some humour • People call me Bakman, so there’s also that! @ T i e m m a B a k a r e 3
Manifesto - Automation - Security What To Expect In This Talk 3. Continuous Integration and Deployment - Version Control Hooks - Tests and Coverage - Sandboxing and Containers
Config Management 1. Vaults 2. Environment variables 3. Submodules - Release Cycles What To Expect In This Talk 6. GitOps - What is GitOps - Understanding Pull Releases - Operator Concept In Deployments
to react to changes in code and perform certain actions based on that. In CI, we do things like Builds which are automated steps to take the code and run certain tasks on it. What is CI / CD CD - Continuous Deployment / Delivery Here, we take the finished result from the CI parts and push it to some service that would allow us use it without any additional work.
comprehensive documentation Customer collaboration over contract negotiation Responding to change over following a plan source:https://agilemanifesto.org/ Agile Manifesto
the need for user intervention. Automation makes it easy to run through thousands of manual steps. Automation As stated by the Agile Manfesto, one cannot follow the principle of “Responding to change over following a plan“, if the actions are placed over user defined processes, they have to be automated. This is why CI is important.
who can access the server. Consider having a VM and having to deploy code manually or a cPanel account that every developer has access to. Security That introduces a lot of entry points for malicious activity, not just from potential users but the developers themselves. Some person might delete the wrong file or stop the ssh service and various other problems like that. This is why CD is important.
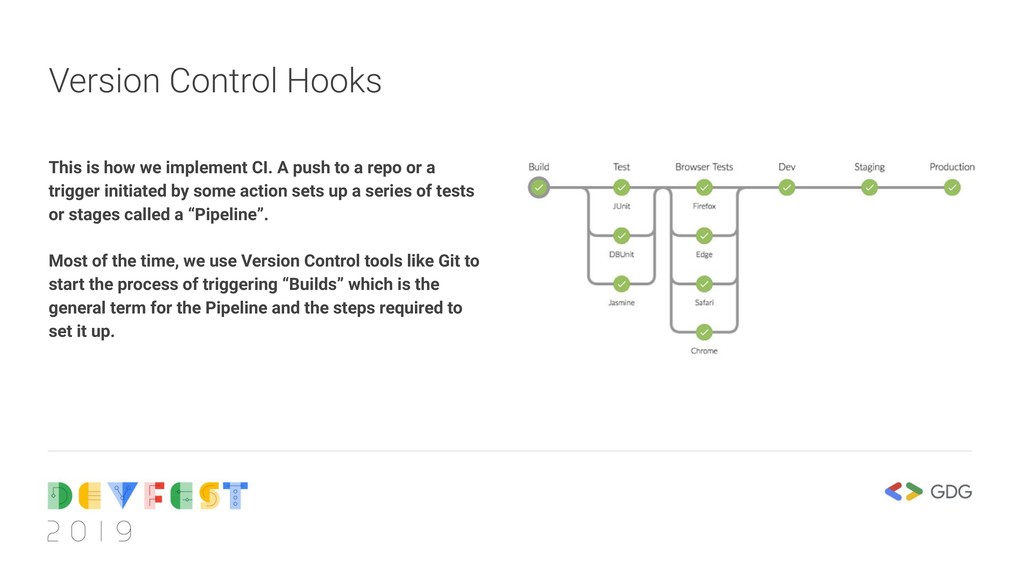
push to a repo or a trigger initiated by some action sets up a series of tests or stages called a “Pipeline”. Most of the time, we use Version Control tools like Git to start the process of triggering “Builds” which is the general term for the Pipeline and the steps required to set it up.
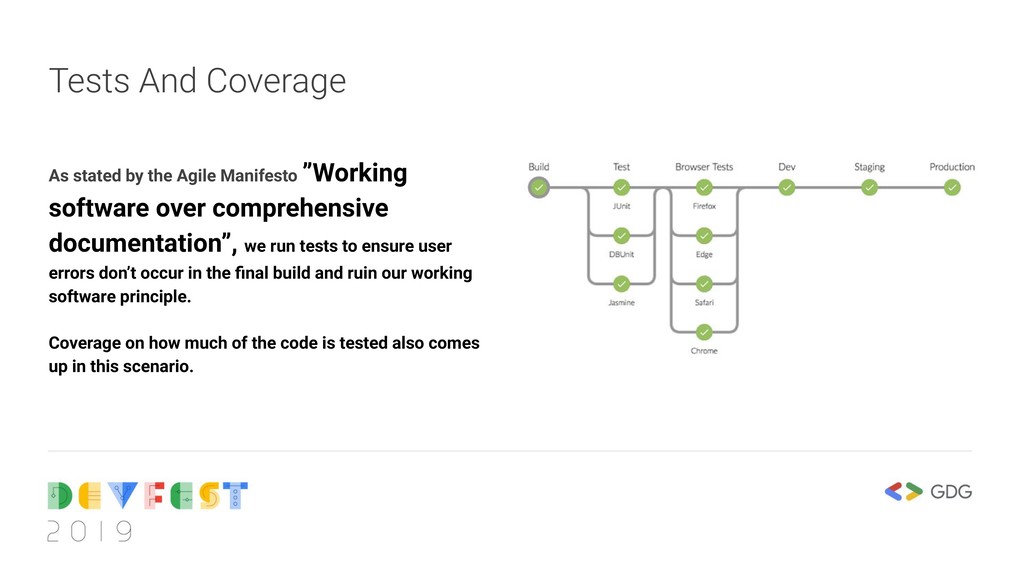
software over comprehensive documentation”, we run tests to ensure user errors don’t occur in the final build and ruin our working software principle. Coverage on how much of the code is tested also comes up in this scenario.
over comprehensive documentation” we need to isolate the pipeline environment so that errors from development don’t show up in production. Some times, various user systems might have hard coded values in their environment or the tools they employ might work for only that version.
don’t pop up in our final production environment, it is always advised to run your pipelines in reproducible sandboxed environment and configure it before running tests. Luckily, this can be automated with containers. Certain environments like Jenkins use VMs to deploy software but it’s best to use the container options to avoid further issues in production.
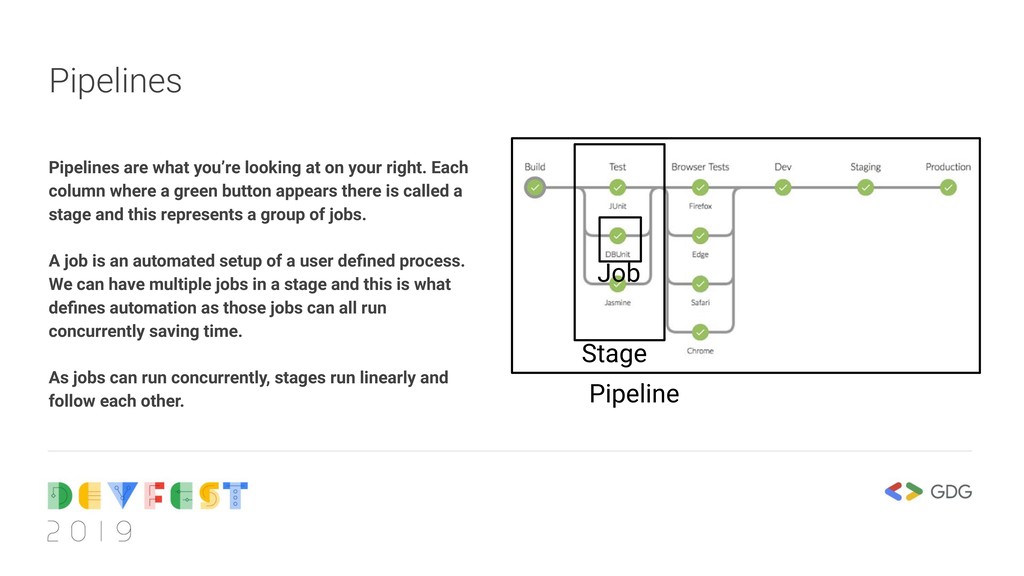
Each column where a green button appears there is called a stage and this represents a group of jobs. A job is an automated setup of a user defined process. We can have multiple jobs in a stage and this is what defines automation as those jobs can all run concurrently saving time. As jobs can run concurrently, stages run linearly and follow each other. Stage Job Pipeline
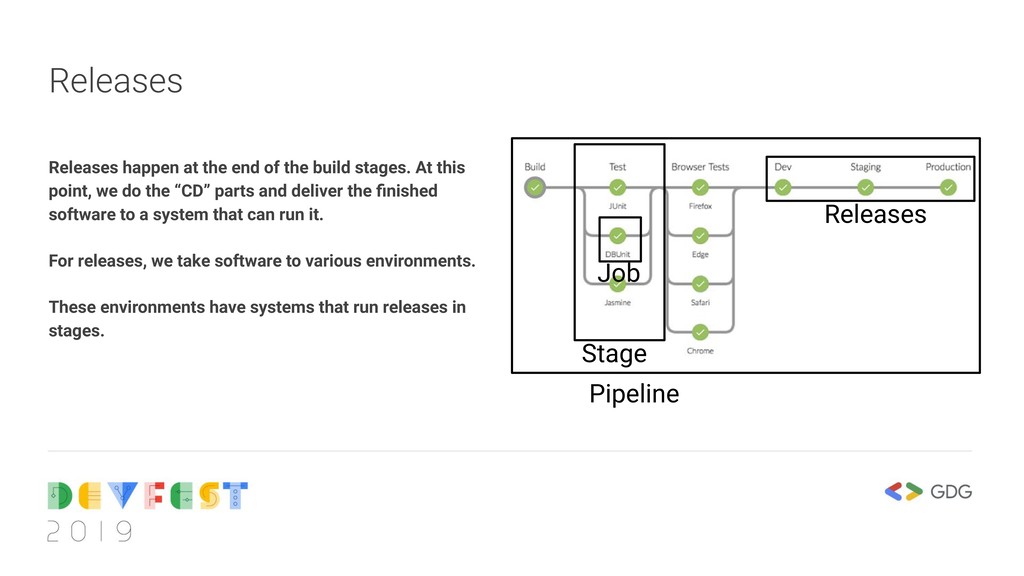
At this point, we do the “CD” parts and deliver the finished software to a system that can run it. For releases, we take software to various environments. These environments have systems that run releases in stages. Stage Job Releases Pipeline
things like passwords, confidential info that we want to keep private at all costs. Configs are just variables that we need to have for our code to work fine. It’s never wise to embed configs in code or the CI environment, always sandbox configs. Secrets and Configuration Management
configurations. Things like passwords, ip addresses, files etc. All of them can be securely stored in a vault and accessed with the use of a token for authentication. An example is the Hashicorp Vault. Vaults
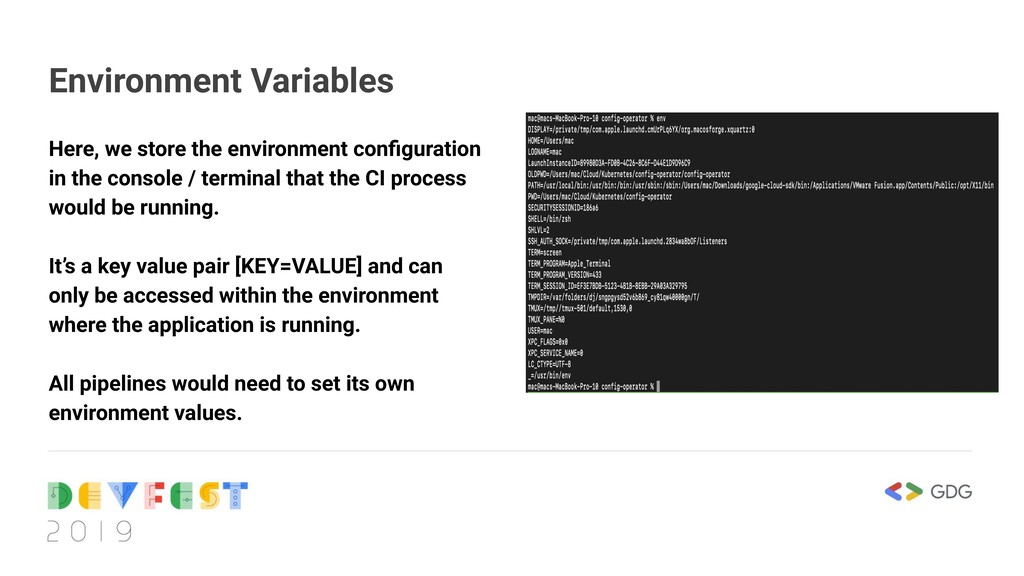
terminal that the CI process would be running. It’s a key value pair [KEY=VALUE] and can only be accessed within the environment where the application is running. All pipelines would need to set its own environment values. Environment Variables
in a GIT repo. This enables us have distributed config across multiple projects using GIT to manage shared configs across projects. GIT Submodules This architecture for config sharing is not recommended for secrets, consider using the other options for those configurations.
track of the last working code sample before deploying a new release. With GIT, it becomes easier as we can always roll out releases with tags. Always have software tags for releases to finished software as opposed to commits as they show what version of the software was deployed there. Release Cycles
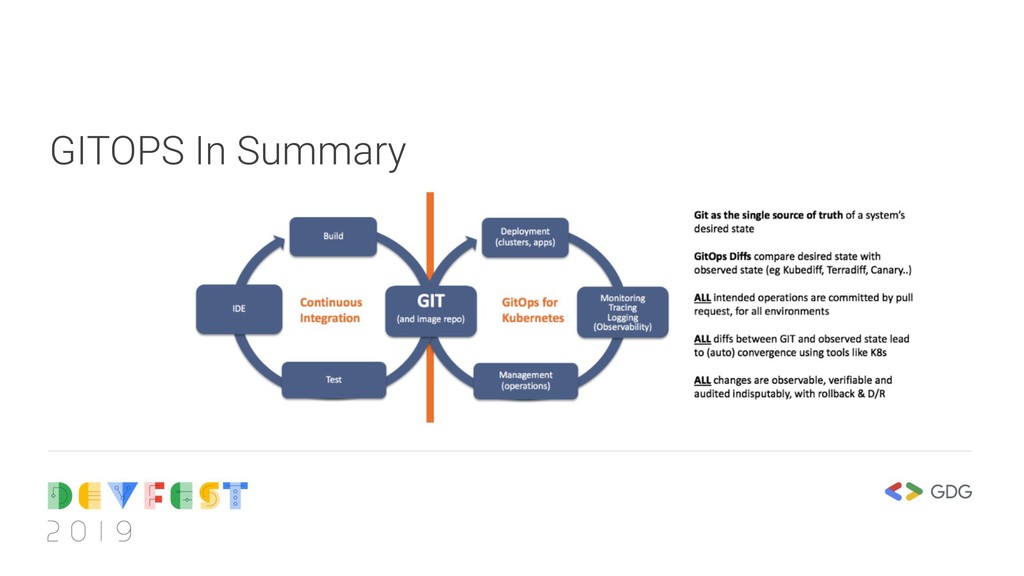
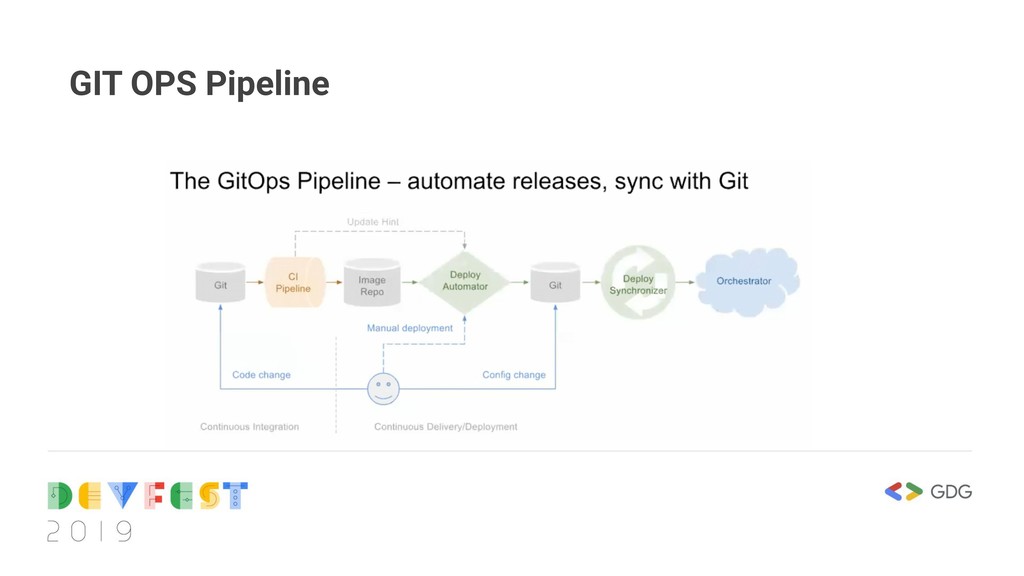
better way to manage configuration changes for deployments. As opposed to the push release cycle employed with traditional CD, we do git pushes to a config repo, then the software deployer in question tracks those changes as they happen and deploys a new release. So instead of pushing configs to the machine as with CD, the deployer application pulls the new release in reverse order.
architecture. The Deploy synchronizer coordinates pulling new configuration for the changes in the deployment code and updates the current running instance.
always push the new release after CI to the system that needs to use it. . In GITOps, the deploy synchronizer pulls the new code and restarts the service. This means that we can have thousands of machines and they all get updated with the code without defining what machines we want to update.
employed in Kubernetes connecting to the master API and watching for events, typically on a limited number of resource types. GITOPS works very well with Kubernetes due to its feature to employ webhooks and watch triggers to changes in state. You can employ GITOPS as a deployment strategy not on K8S but you’d need to define a watch system that triggers on a push webhook
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}