cover additional material The material covered here will be relatively simplified, the technical summary of the concepts will still be delivered. A lot of these concepts are theoretical and practical in a mix. I hope you have fun going through this.
II chapter titled “Distributed Systems” of Database Internals “A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable” - Leslie Lamport
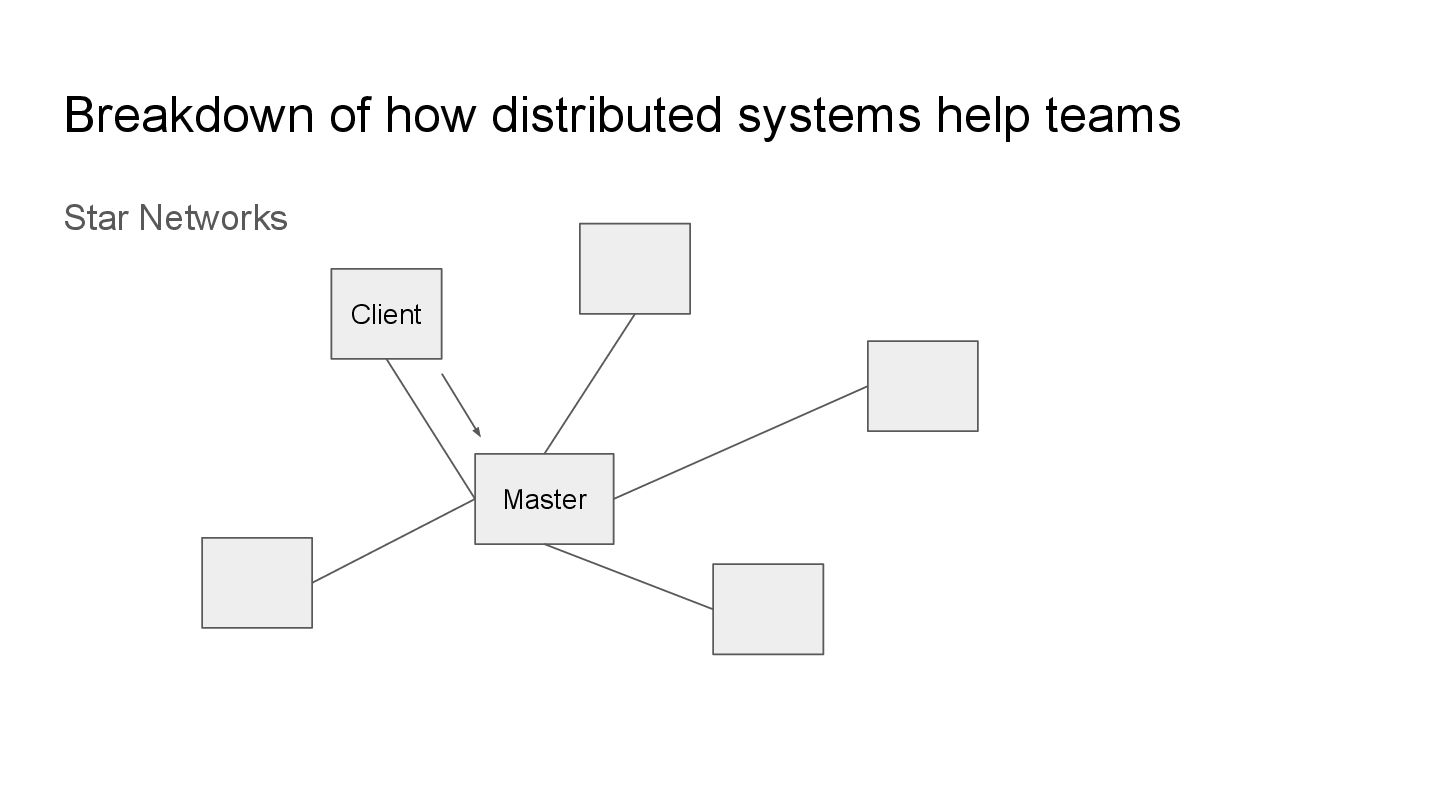
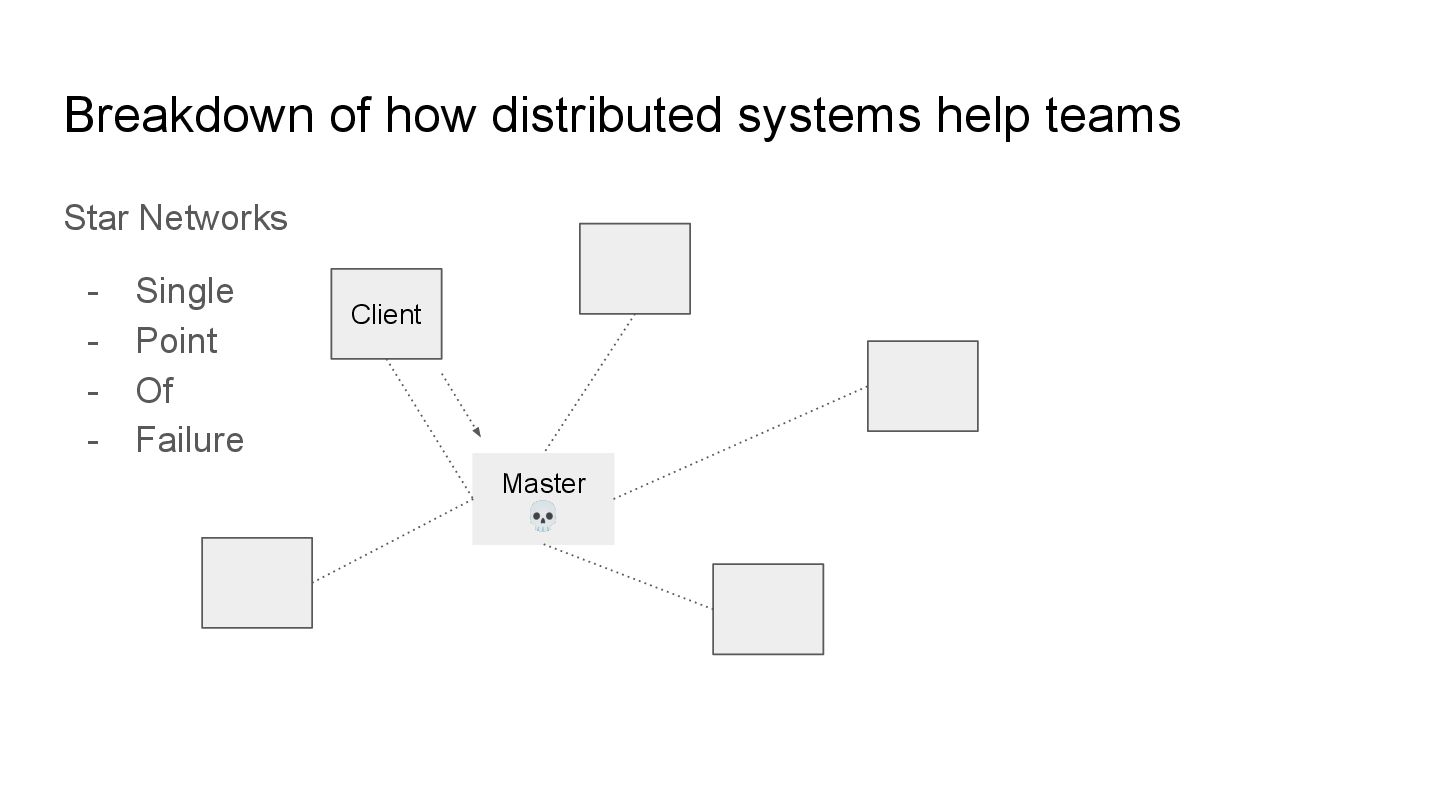
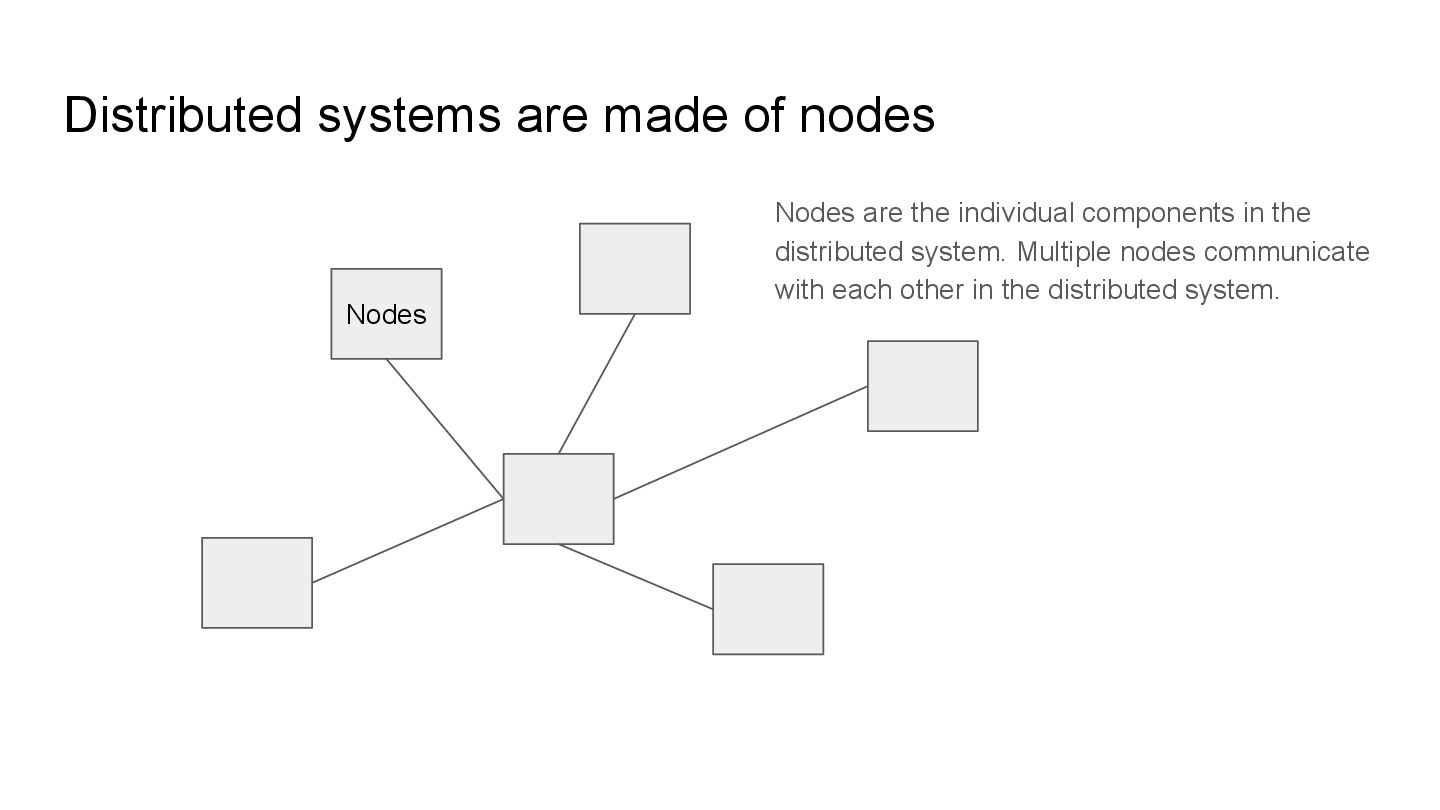
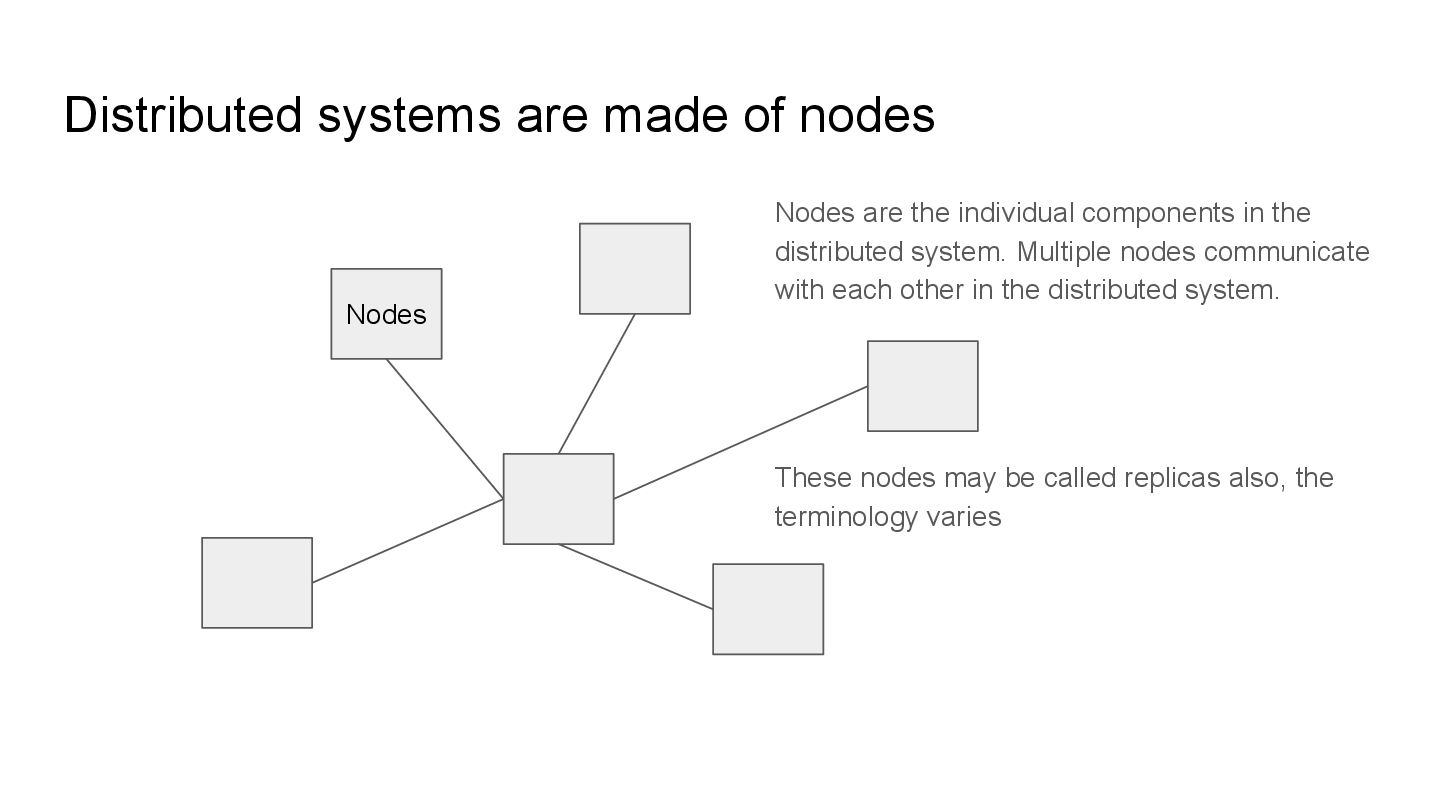
individual components in the distributed system. Multiple nodes communicate with each other in the distributed system. These nodes may be called replicas also, the terminology varies
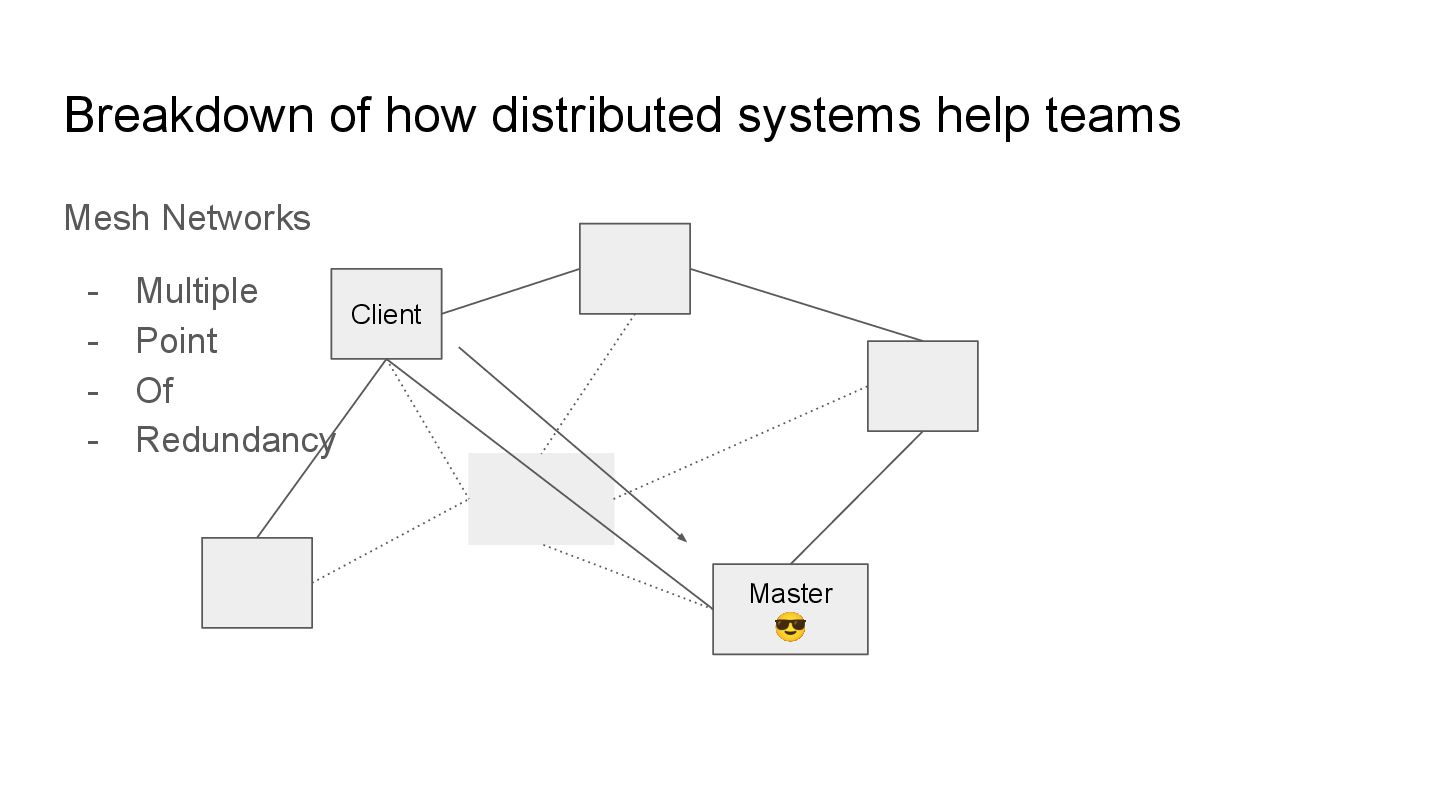
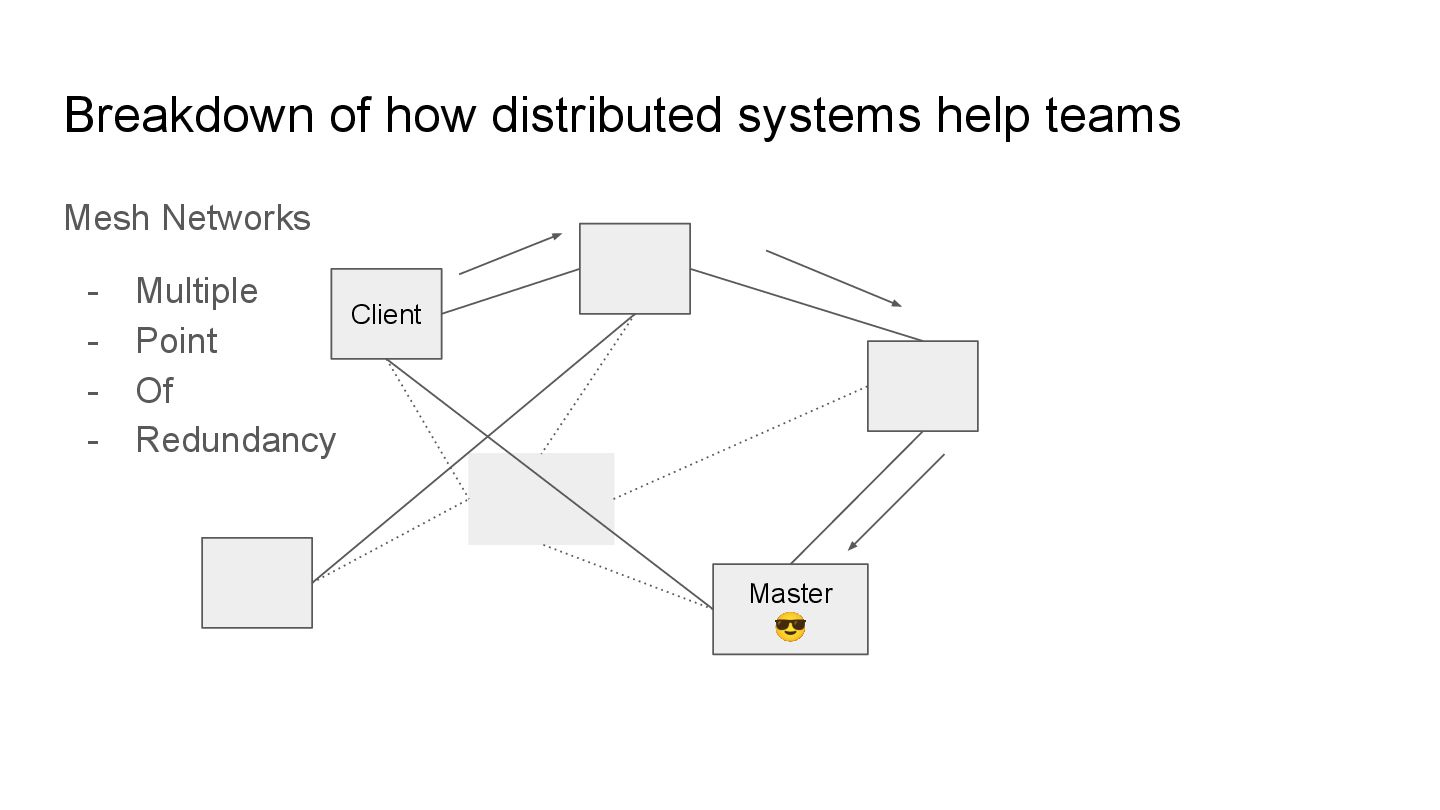
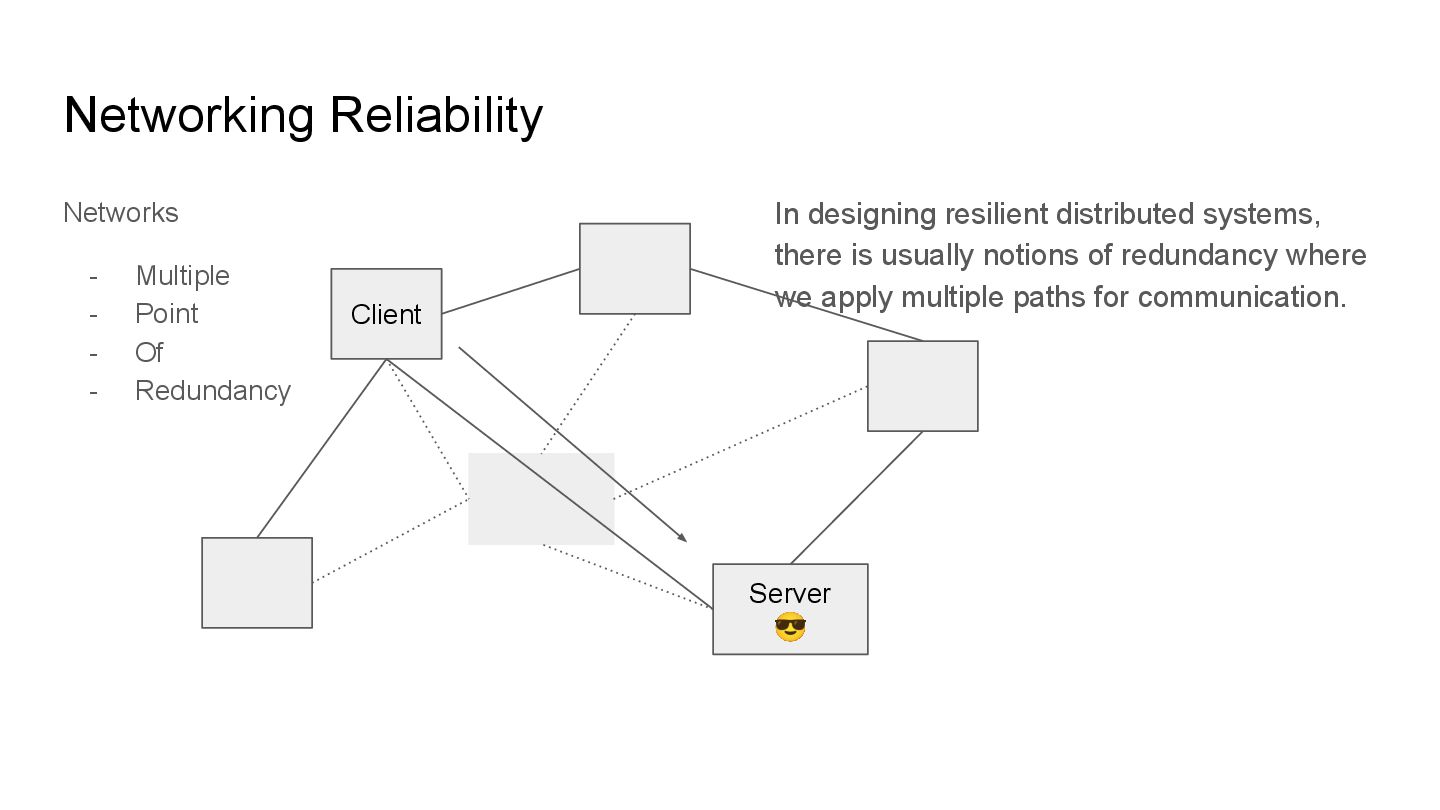
stability by finding smarter ways to have “redundant” paths improving the ease of separating individual systems whilst keeping it working. Despite helping improve stability, they can also increase complexity. Use these concepts sparingly.
to distributed algorithms, this is an overview of the more infrastructure and theoretical related parts of it. Algorithms handle the interactions between these systems in the more lower level, this is very high level, we will not be doing any coding.
to distributed algorithms, this is an overview of the more infrastructure and theoretical related parts of it. Algorithms handle the interactions between these systems in the more lower level, this is very high level, we will not be doing any coding. This discussion is based off the Database Internals book by Alex Petrov.
tasks so they can run faster. It is simply “division of labour” across various workers. The more workers you have does not always imply faster performance And breaking a task into bits does not always make it more efficient
or more independent tasks independently. Concurrency can mean taking a process A and creating a chain of processes to become: B -> C -> D -> A Where B, C and D are running independently to achieve A. Parallelism is the ability to run the same thing at the same time multiple times. Parallelism means taking a process A and making it run in X times where each is distinctly independent but performing the same operation. X -> A X -> A X -> A
multiple tasks and is not limited by hardware Concurrency can be context switched across hardware so there is not a “hard” reliance on the number of cores assigned. Parallelism implies each process is running on a single dedicated resource and will usually just stay active from start to finish Parallelism requires actual physical hardware to run so if you have X cores, you can reasonably run X versions of a task before it becomes slower.
in the physical setup of a core to use a high speed register to emulate context switching with such performance that it can be likened to an actual physical core.
in the physical setup of a core to use a high speed register to emulate context switching with such performance that it can be likened to an actual physical core. Hyperthreaded v Real Core Thread 1 Thread 2 (Register) Core Thread 1
schedule two of the same tasks on a single core, it will really be fighting for resources on the same core. This works for most things because cache access and other resources on a core are efficient so it is appears seamless.
schedule two of the same tasks on a single core, it will really be fighting for resources on the same core. This works for most things because cache access and other resources on a core are efficient so it is appears seamless. The operating system will usually just take threads as cores to simplify scheduling tasks onto them, but there is always a performance hit for such emulation.
schedule two of the same tasks on a single core, it will really be fighting for resources on the same core. This works for most things because cache access and other resources on a core are efficient so it is appears seamless. The operating system will usually just take threads as cores to simplify scheduling tasks onto them, but there is always a performance hit for such emulation. If you have latency specific or contention driven processes like databases that need performance, use physical cores against hyperthreaded ones.
concurrency in parallelism but you cannot have parallelism in concurrent tasks. The reason is parallelism implies that the same process is executed at the same time in independent blobs.
concurrency in parallelism but you cannot have parallelism in concurrent tasks. The reason is parallelism implies that the same process is executed at the same time in independent blobs. Concurrency implies composition of independent single tasks working together so the timelines overlap.
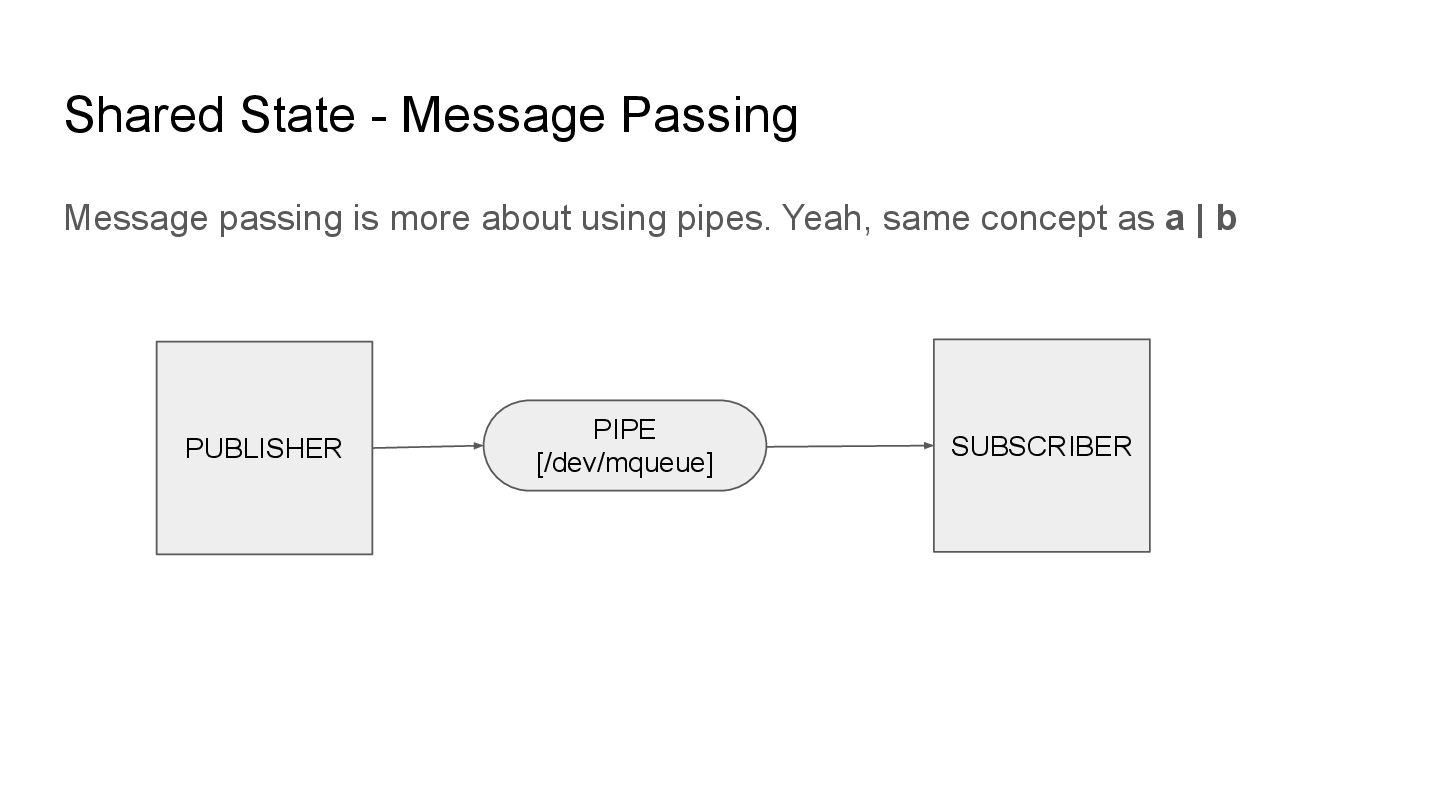
in distributed systems You either have • Message passing (queues, signals) • Shared memory (databases, heaps) Unlike message passing, shared memory requires synchronization to allow for safe(serializable) updates. The concept of serializable consistency will be discussed later on.
you ephemerally take some data from point A and pass it to point B through a pipe. That pipe is usually called a queue but you can do so through io redirection etc.
you ephemerally take some data from point A and pass it to point B through a pipe. That pipe is usually called a queue but you can do so through io redirection etc. In Linux, this can be emulated with the /dev/mqueue filesystem which allows kernel support for message passing primitives. See here: https://man7.org/linux/man-pages/man7/mq_overview.7.html
you ephemerally take some data from point A and pass it to point B through a pipe. That pipe is usually called a queue but you can do so through io redirection etc. In Linux, this can be emulated with code but most queues will use the /dev/mqueue filesystem which allows kernel support for message passing primitives. See here: https://man7.org/linux/man-pages/man7/mq_overview.7.html This can also be done with code using your basic queue data structure from the user space.
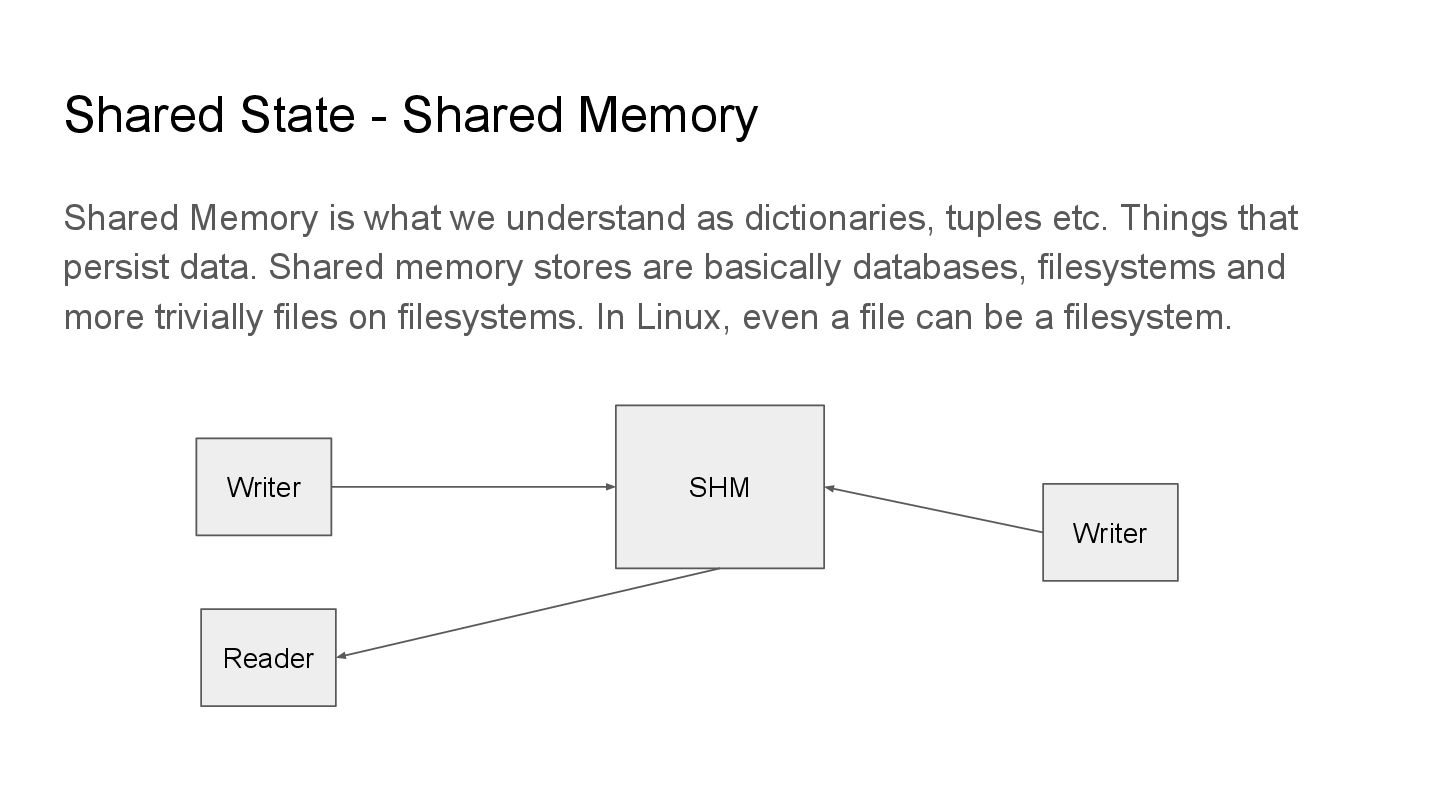
understand as dictionaries, tuples etc. Things that persist data. Shared memory stores are basically databases, filesystems and more trivially files on filesystems. In Linux, even a file can be a filesystem. SHM Writer Reader Writer
you are guaranteed that within the allocated block of memory, data persisted can be retrieved multiple times. In Linux, the /dev/shm filesystem allows you to perform allocations with kernel support for shared memory stores. See https://man7.org/linux/man-pages/man7/shm_overview.7.html
you are guaranteed that within the allocated block of memory, data persisted can be retrieved multiple times. In Linux, the /dev/shm filesystem allows you to perform allocations for shared memory stores. See https://man7.org/linux/man-pages/man7/shm_overview.7.html Memory allocators, arenas and various other primitives allow for allocation of shared memory blocks. Just like the message passing note, this can be implemented without this filesystem.
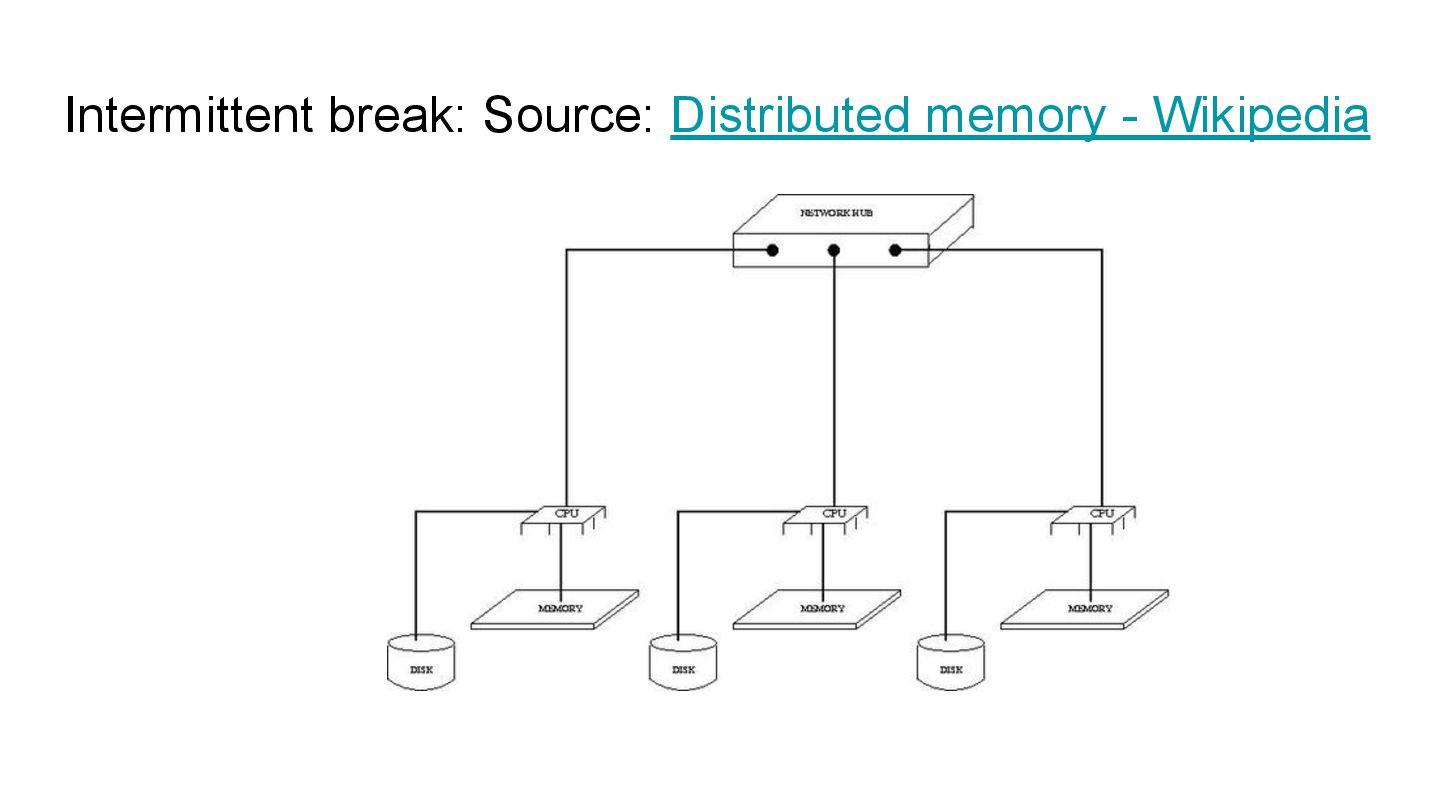
can also have distributed memory which in addition to data locality, moves memory information to a store outside the systems where it is running. The interconnect to allow data transfer is usually over some network (wired or wireless) and pages can be swapped between independent systems as required.
protocols is Remote DMA (RDMA) which allows direct access to memory pages bypassing the CPU. You can find this in Infiniband NICs and GPUs for example. To cover GPUs, they have both local and remote memory regions that can be accessed over interconnects for fast processing and retrieval across many parallel executing cores.
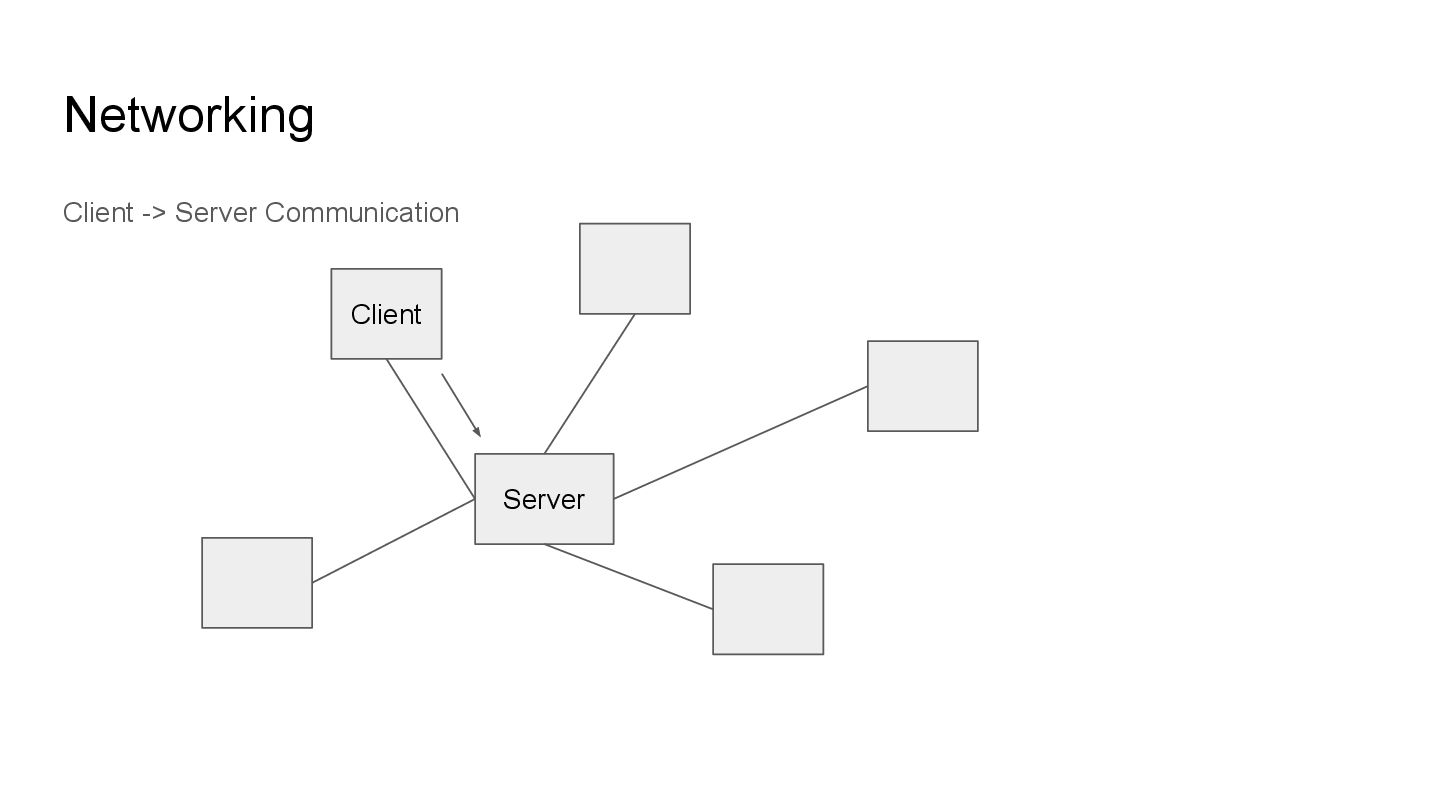
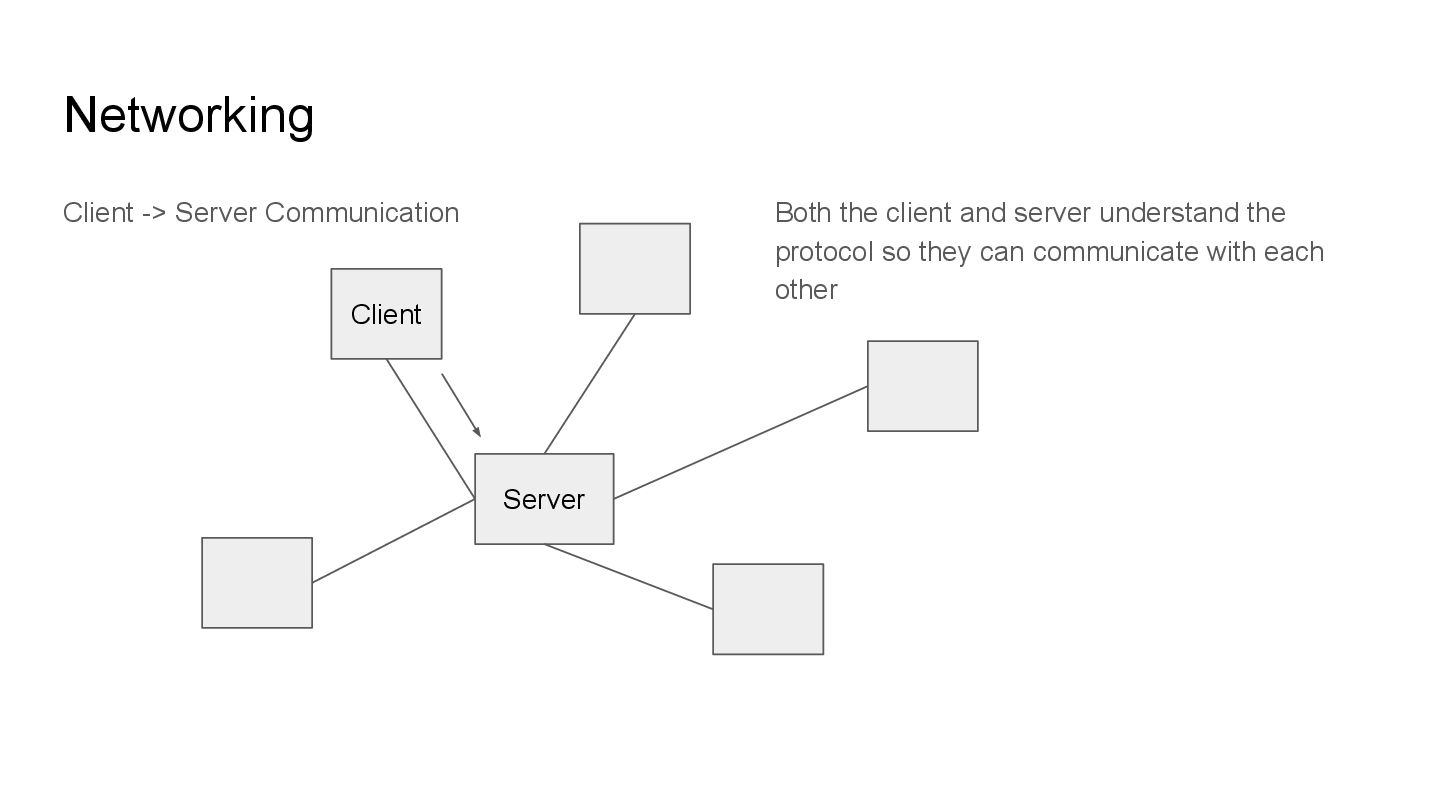
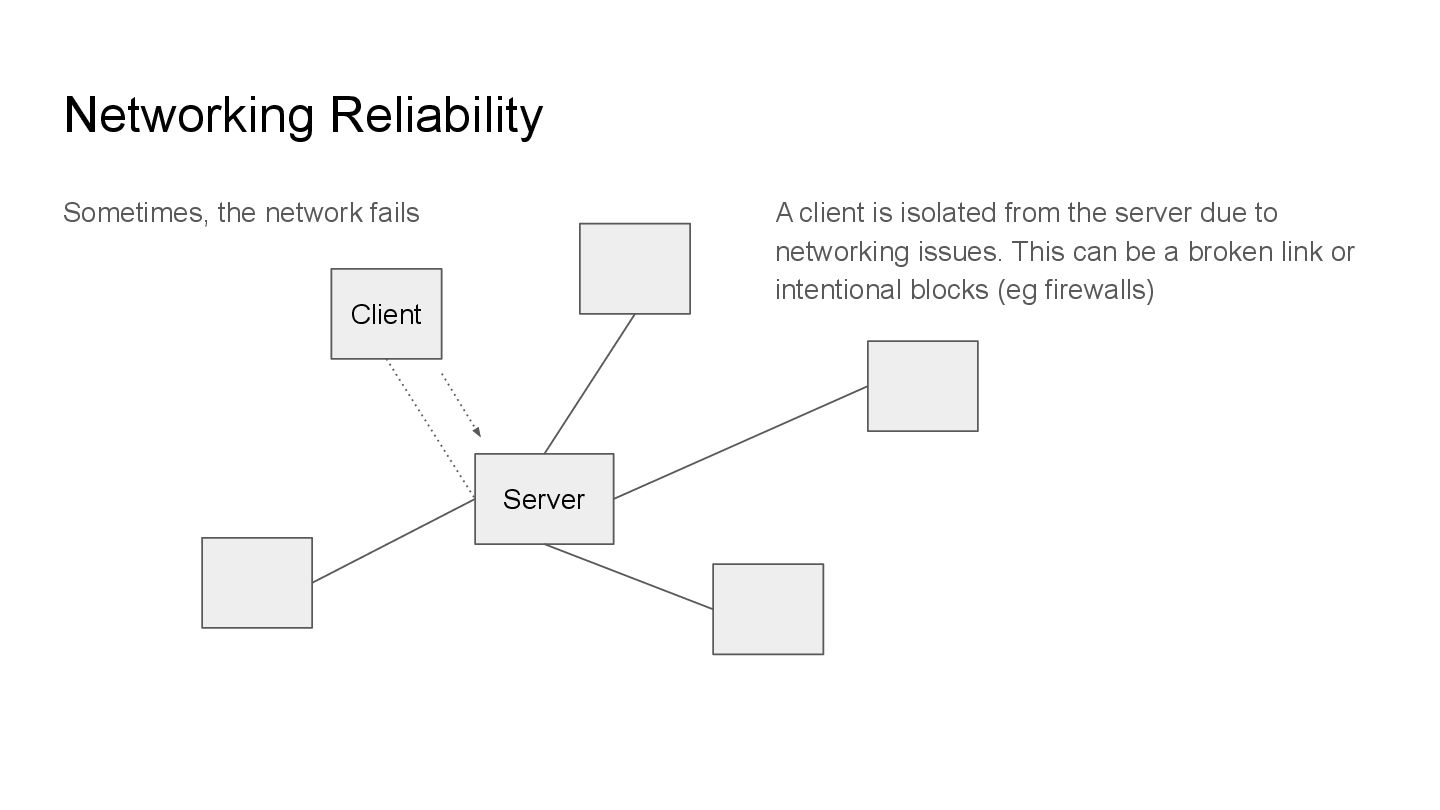
sense. This means we need some way to communicate. Networking allows different systems to pass information over a protocol that defines the standard for how these informations are sent and received.
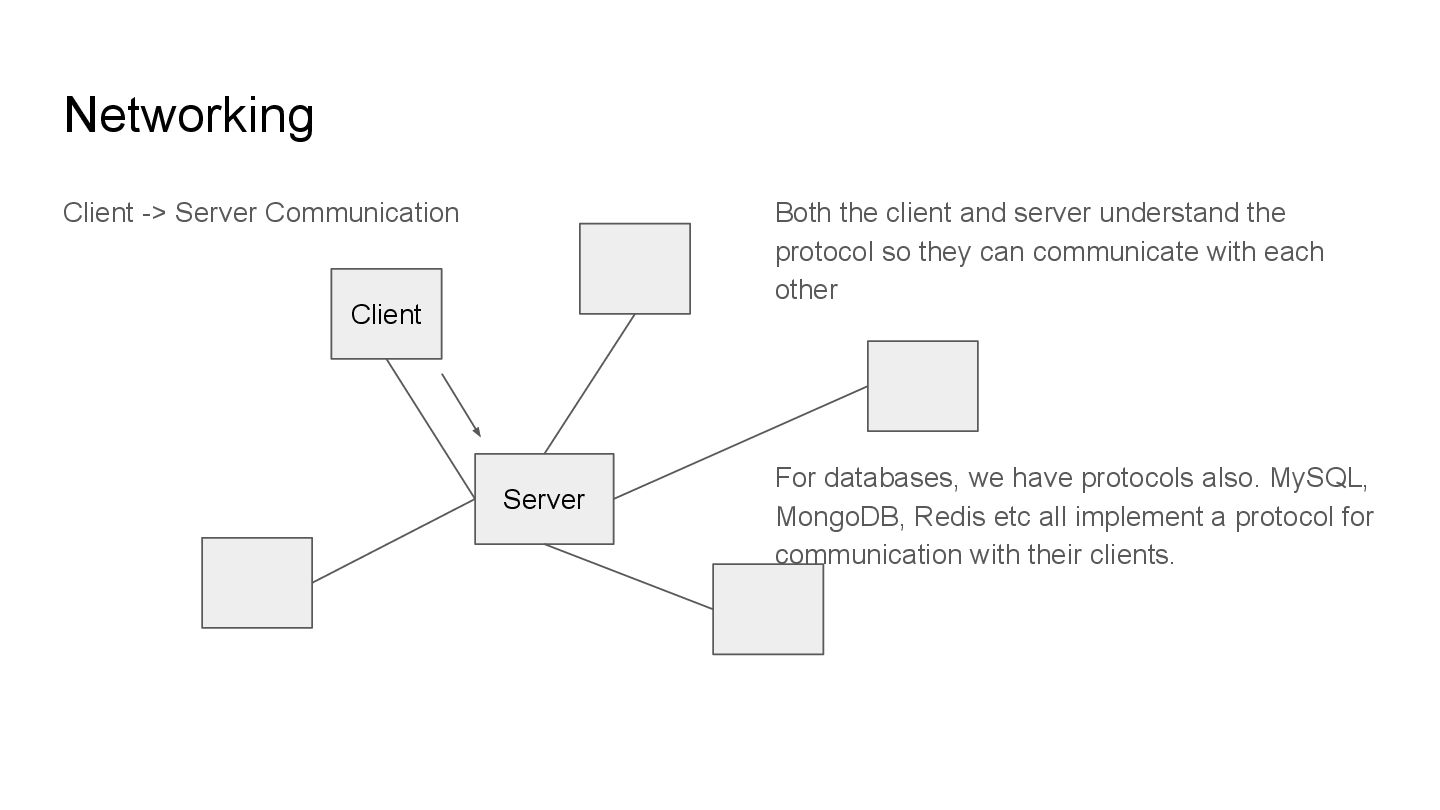
and server understand the protocol so they can communicate with each other For databases, we have protocols also. MySQL, MongoDB, Redis etc all implement a protocol for communication with their clients.
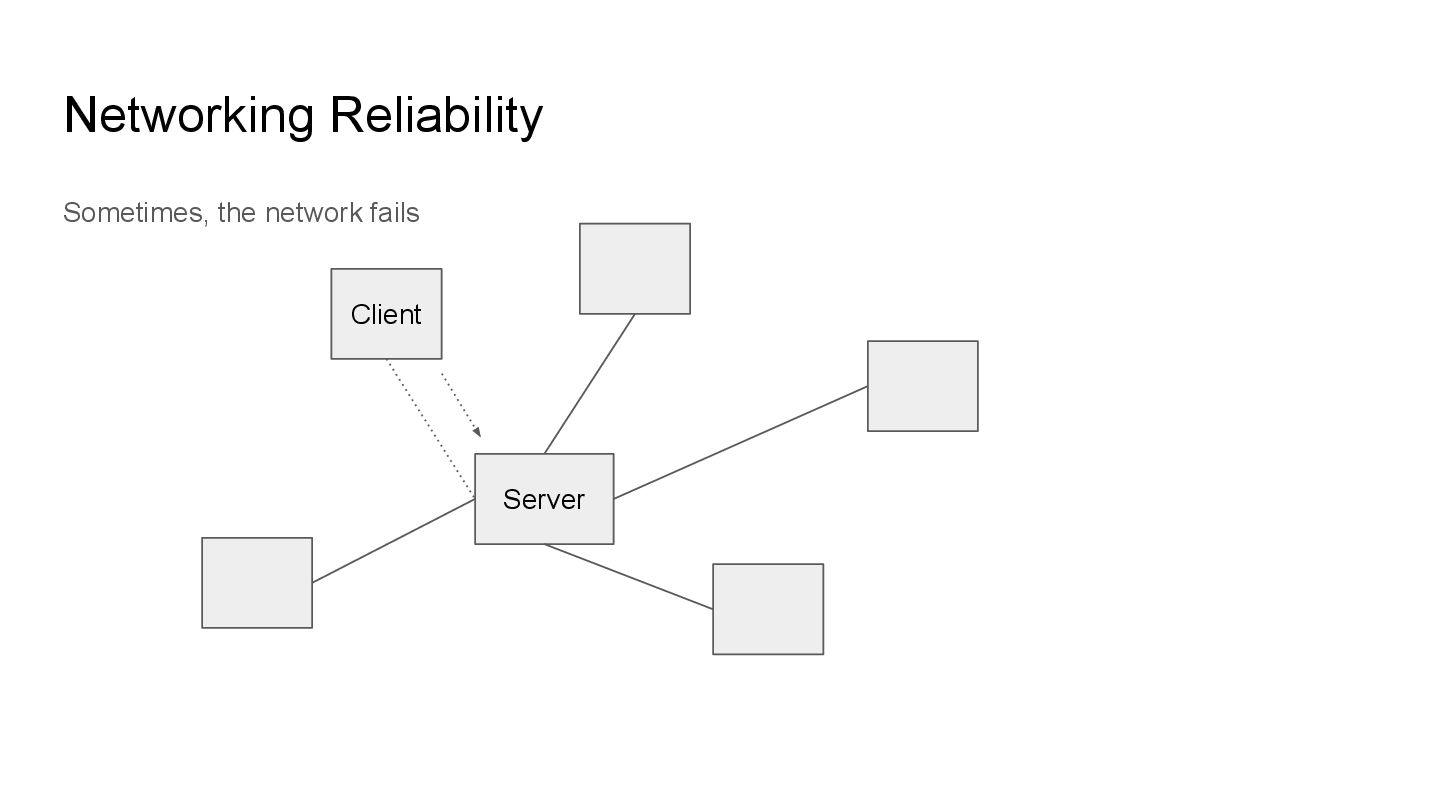
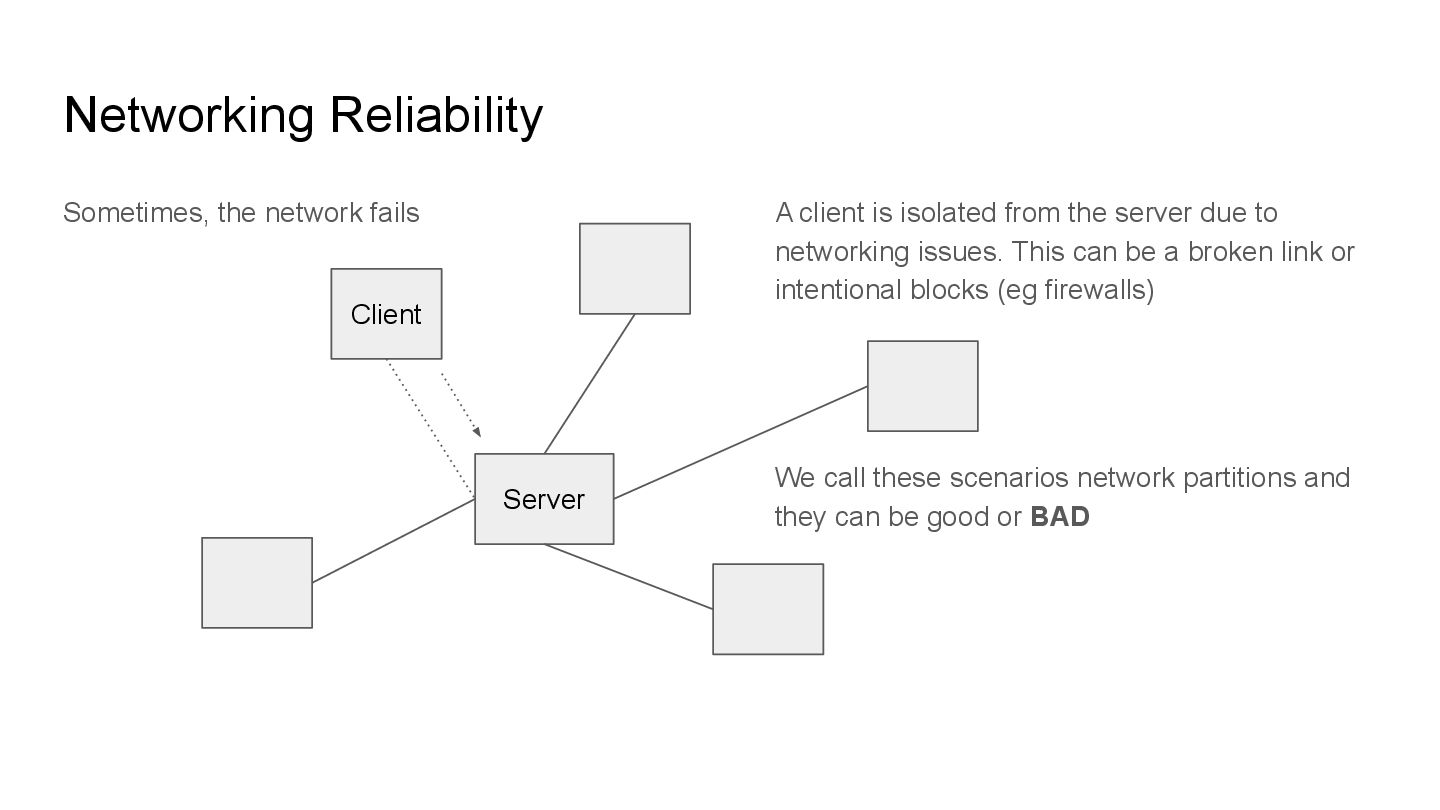
is isolated from the server due to networking issues. This can be a broken link or intentional blocks (eg firewalls) We call these scenarios network partitions and they can be good or BAD
Redundancy Client Server 😎 In designing resilient distributed systems, there is usually notions of redundancy where we apply multiple paths for communication.
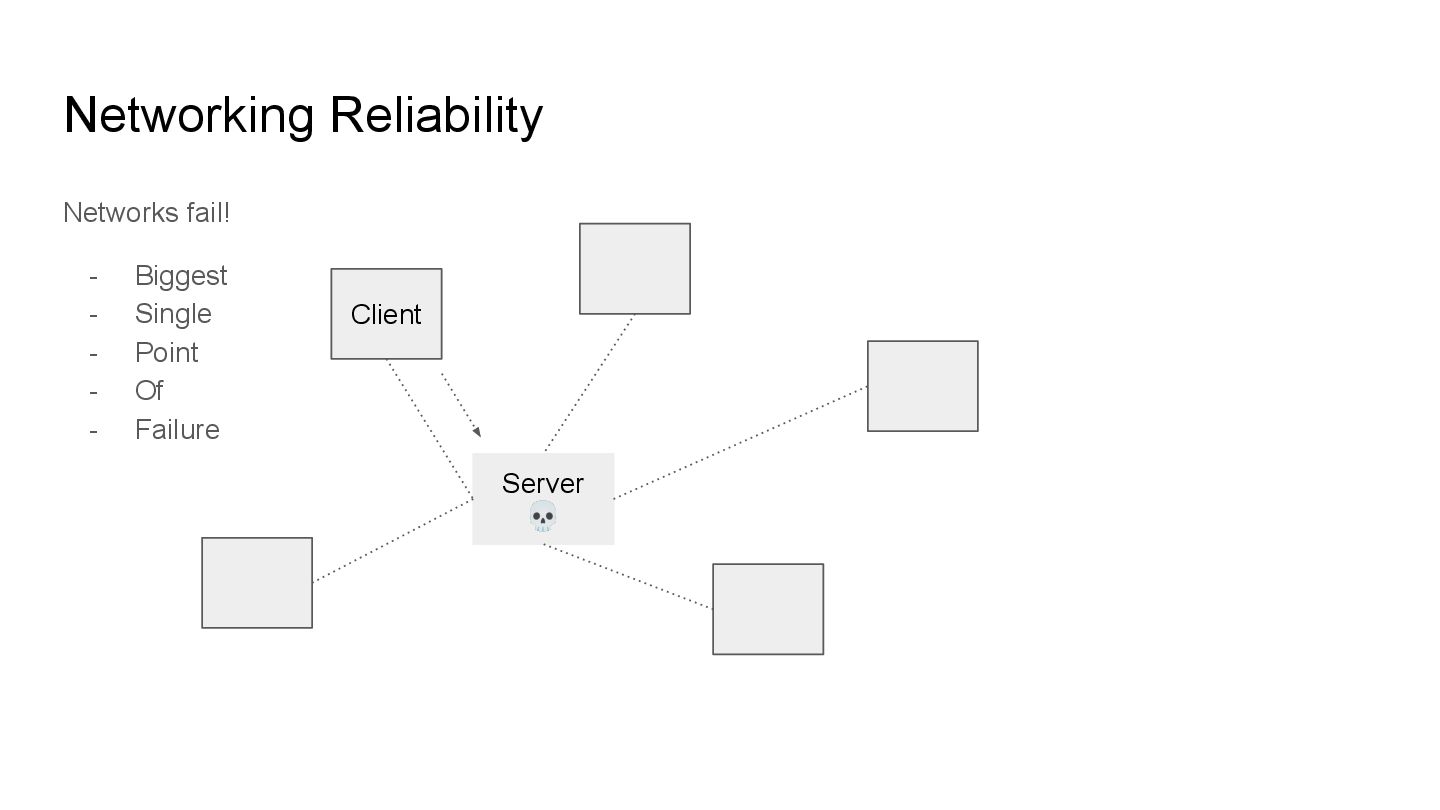
fail, in the delicate balance of distributed systems, this can cause cascading failures. Cascading failures can occur for a number of reasons, for example, replication failures reach a limit due to network partitions and the nodes failover due to WAL build up causing allocated storage to become filled up.
fail, in the delicate balance of distributed systems, this can cause cascading failures. Cascading failures can occur for a number of reasons, for example, replication failures reach a limit due to network partitions and the nodes failover due to WAL build up causing allocated storage to become filled up. that’s a mouthful of things in succession but it happens
of the process and designing to handle them is more difficult than it might appear. The general goal is to try to fix them as they appear cause there’s no universal fix.
of the process and designing to handle them is more difficult than it might appear. The general goal is to try to fix them as they appear cause there’s no universal fix. In the words of Leslie Lamport “A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable”
a numerous amount of techniques to do so. I cover only two for simplicity, you can use retries in the event of short blips and/or use transactions to rollback in the event of such failures so they can retried later on.
machine. Imagine if 1000 nodes retried (multiple) requests to a server during a momentary outage, the requests coming back would leave the entire system under significant load due to the now synchronised barrage of requests that failed.
machine. Imagine if 1000 nodes retried (multiple) requests to a server during a momentary outage, the requests coming back would leave the entire system under significant load due to the now synchronised barrage of requests that failed. To avoid this, apply some random jitter and backoff in some effect on startup, on retry etc to save yourself from the loop of incoming requests that end up causing cascading failures downstream.
prevent actions that partially succeed. In distributed systems, transactions are performed through different means. You can do so through consensus algorithms like Raft, Paxos, 2+ Phase Commits and various others.
star trek reference) Sagas are way to chain transactions across many distributed systems. When you have multiple transactions that occur across multiple isolated data sources, it is impossible to synchronize because each place the transaction goes has a different view of the world.
a transaction failure on one of many services from being achieved. If one system fails in the chain, all the previous changes are rolled back downstream to prevent inconsistency.
a transaction failure on one of many services from being achieved. If one system fails in the chain, all the previous changes are rolled back downstream to prevent inconsistency. As you can imagine, it is quite difficult to achieve this pattern but it is very useful in proper microservice designs for systems with independent transactions eg finance
of an atomic particle at any given instant in time” - Heisenberg’s Uncertainty Principle So, it is also difficult to accurately state the time in distributed systems. Based on the frequency of ticks to count the time, we will always have some miniscule amount of drift due to the nature of particle physics and delay in fetching the time to continue ticking with.
three different clocks These clocks are: • Realtime (based on world time and time zones) • Monotonic (based on the difference of when we started counting)
three different clocks These clocks are: • Realtime (based on world time and time zones) • Monotonic (based on the difference of when we started counting) • Logical (based on an algorithm for timing events)
get from our digital time keepers syncing with NTP servers that provide the time. However, this fails because the time lost in getting the time now is usually off by some miniscule fraction or larger.
get from our digital time keepers syncing with NTP servers that provide the time. However, this fails because the time lost in getting the time now is usually off by some miniscule fraction or larger. This is not an issue unless you have lots of events happening at the same time in different parts of the world, the tiny difference in skew and the fact that time can be globally the same (collision) means this system across multiple transactions can cause issues in consensus and ordering of events.
point, like the big bang (theory?) or the instance the system booted to be more realistic. In Linux, this time can be accessed through syscalls, documentation is available here: https://man7.org/linux/man-pages/man2/clock_getres.2.html
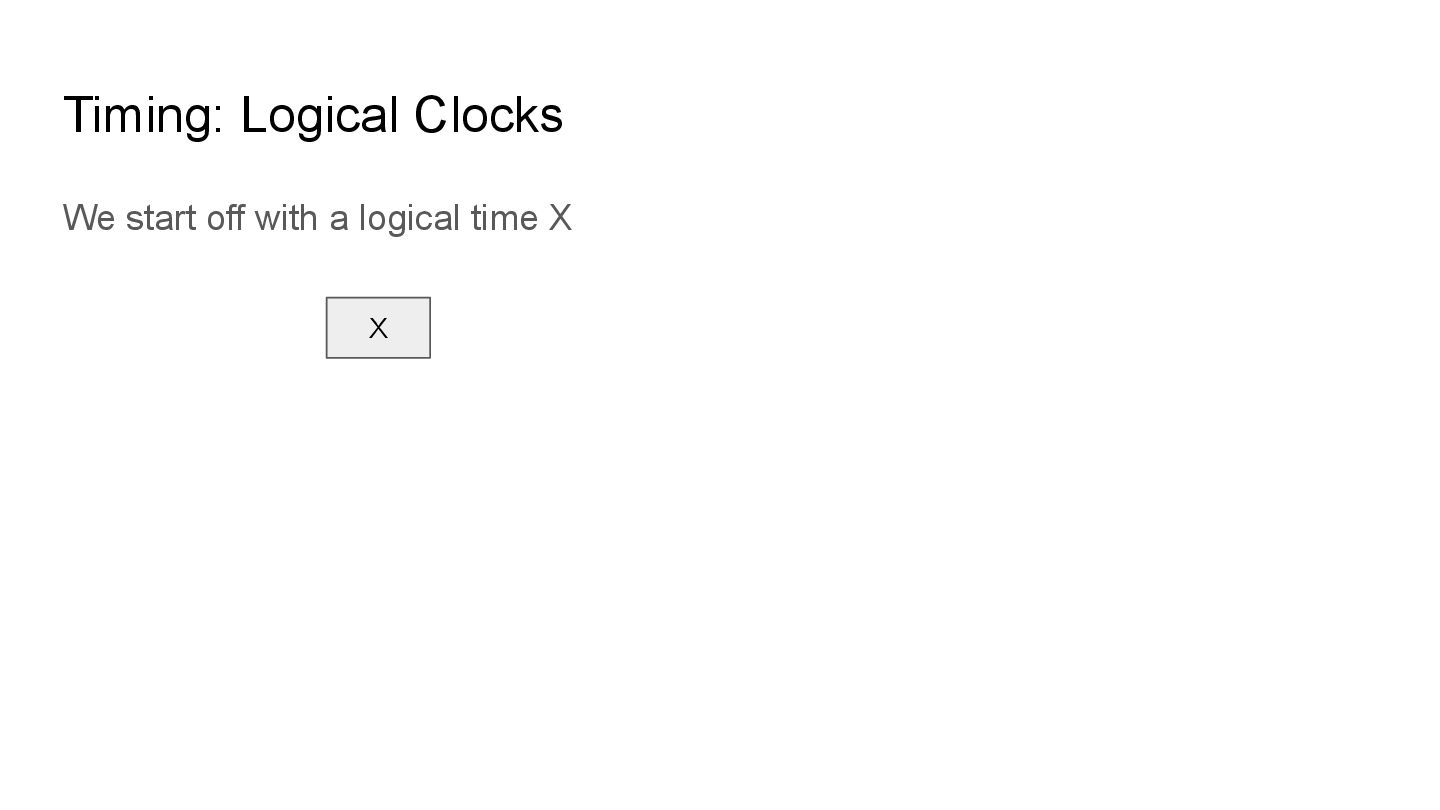
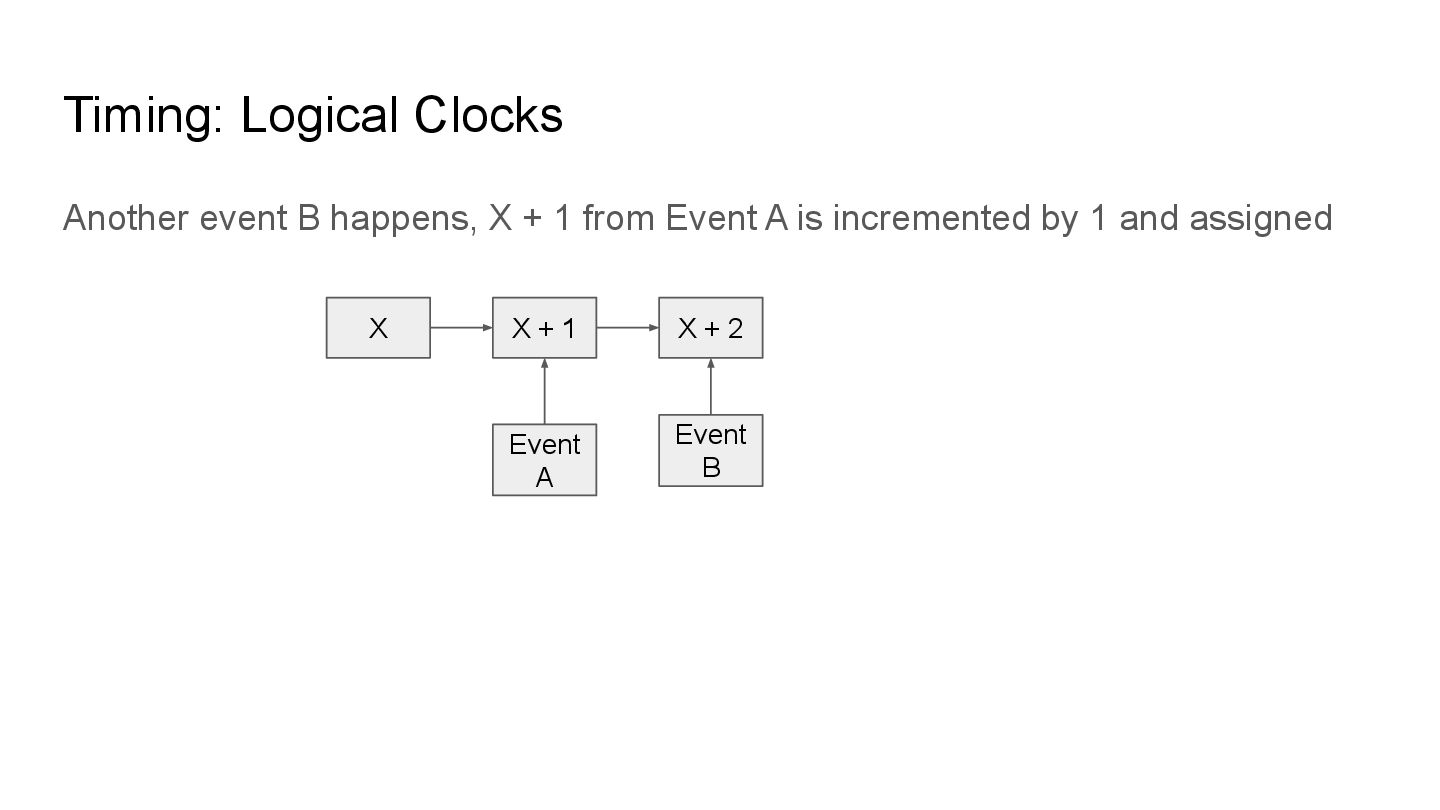
the transactions of events so as to better alleviate the issues with real time clocks. An example of this is Lamport’s Clock where rather than a tick being defined by some frequency pinned to a quartz crystal, we tick based on a monotonically increasing counter for every event that happens.
no skew and we can accurately process the events based on the counter tracking how many “events” have occurred since we started and assigning IDs of time based on that value.
across multiple nodes, the time is very important. The time tells a story of when something was created and what was created after it. This allows for what database enthusiasts called serializable consistency which defines that if event A < event B in time, then event B will take precedence over event A. If we updated a row with event A, it would be overwritten by event B.
across multiple nodes, the time is very important. The time tells a story of when something was created and what was created after it. This allows for what database enthusiasts called serializable consistency which defines that if event A < event B in time, then event B will take precedence over event A. If we updated a row with event A, it would be overwritten by event B. If the timing is off, then serializable consistency fails. Very large databases cannot rely on realtime clocks so they have a mix of logical and realtime clocks.
correct across database replicas, you can find some resources below on how this is accomplished across distributed systems: • Spanner: TrueTime and external consistency | Google Cloud • Consistency without Clocks: The Fauna Distributed Transaction Protocol • Facebook did tons of research just to fix timing: NTP: Building a more accurate time service at Facebook scale
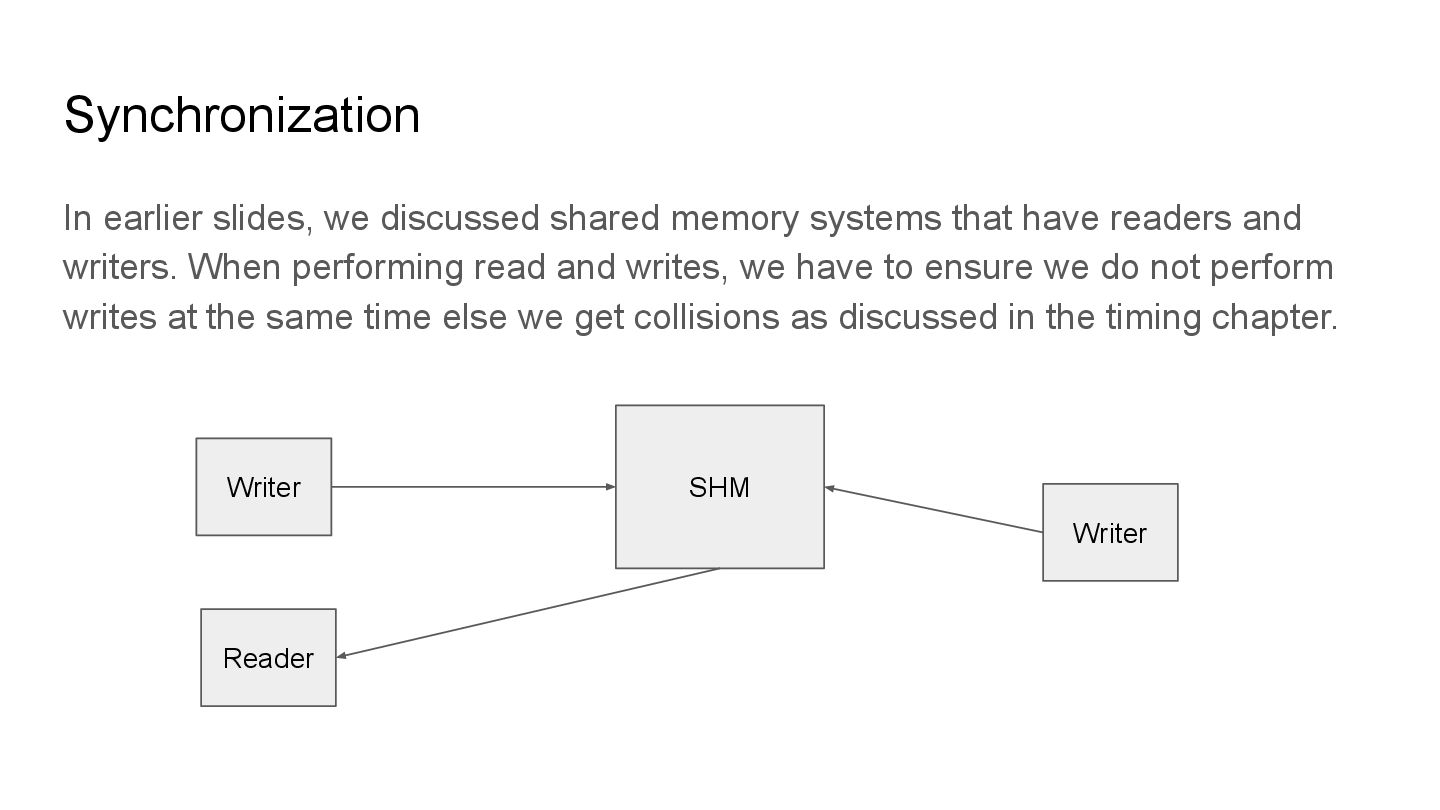
have readers and writers. When performing read and writes, we have to ensure we do not perform writes at the same time else we get collisions as discussed in the timing chapter. SHM Writer Reader Writer
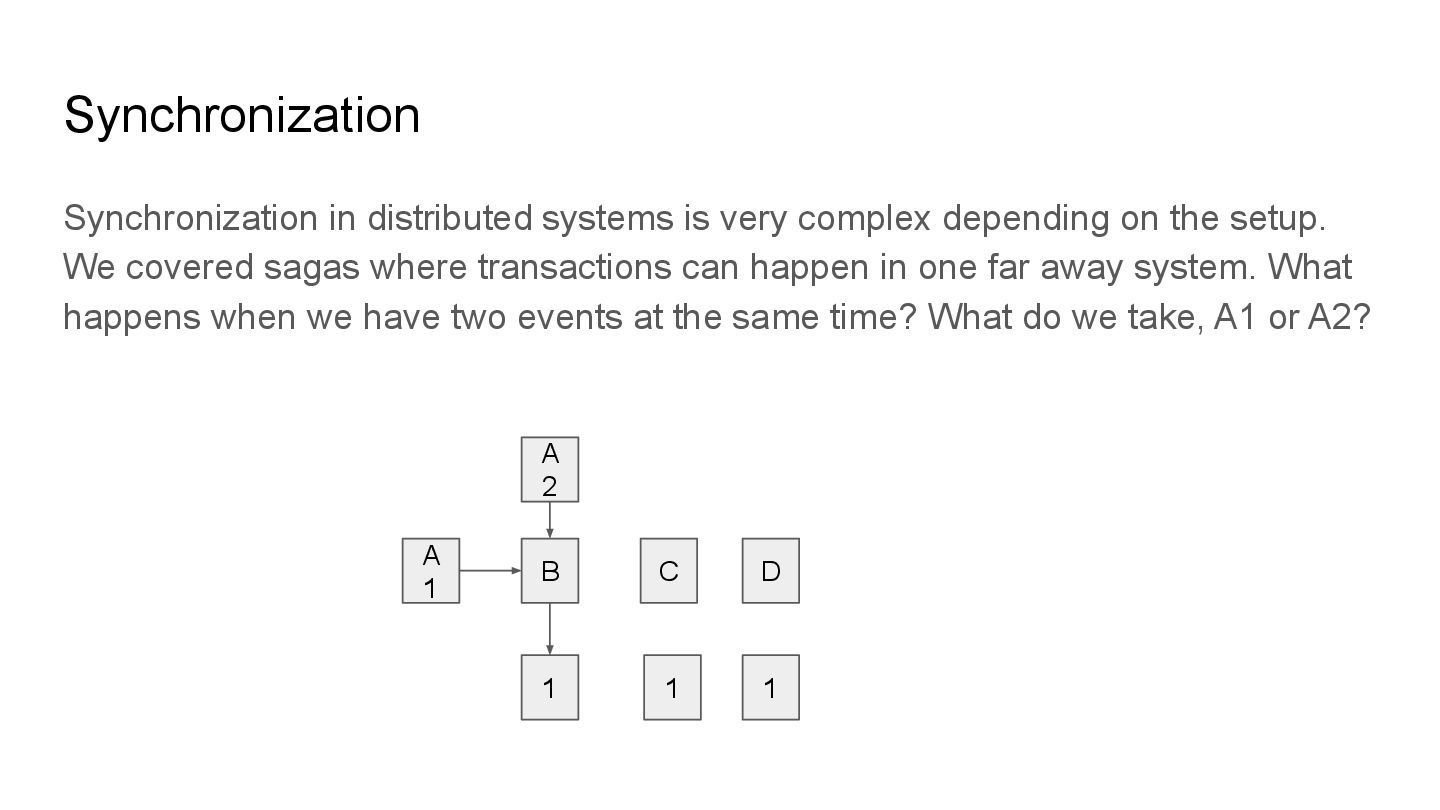
the setup. We covered sagas where transactions can happen in one far away system. What happens when we have two events at the same time? What do we take, A1 or A2? A 1 B C D 1 1 1 A 2
timing and networking is based on who can go first and who’s next. It will usually involve entering a critical section where such updates are only permitted to be done.
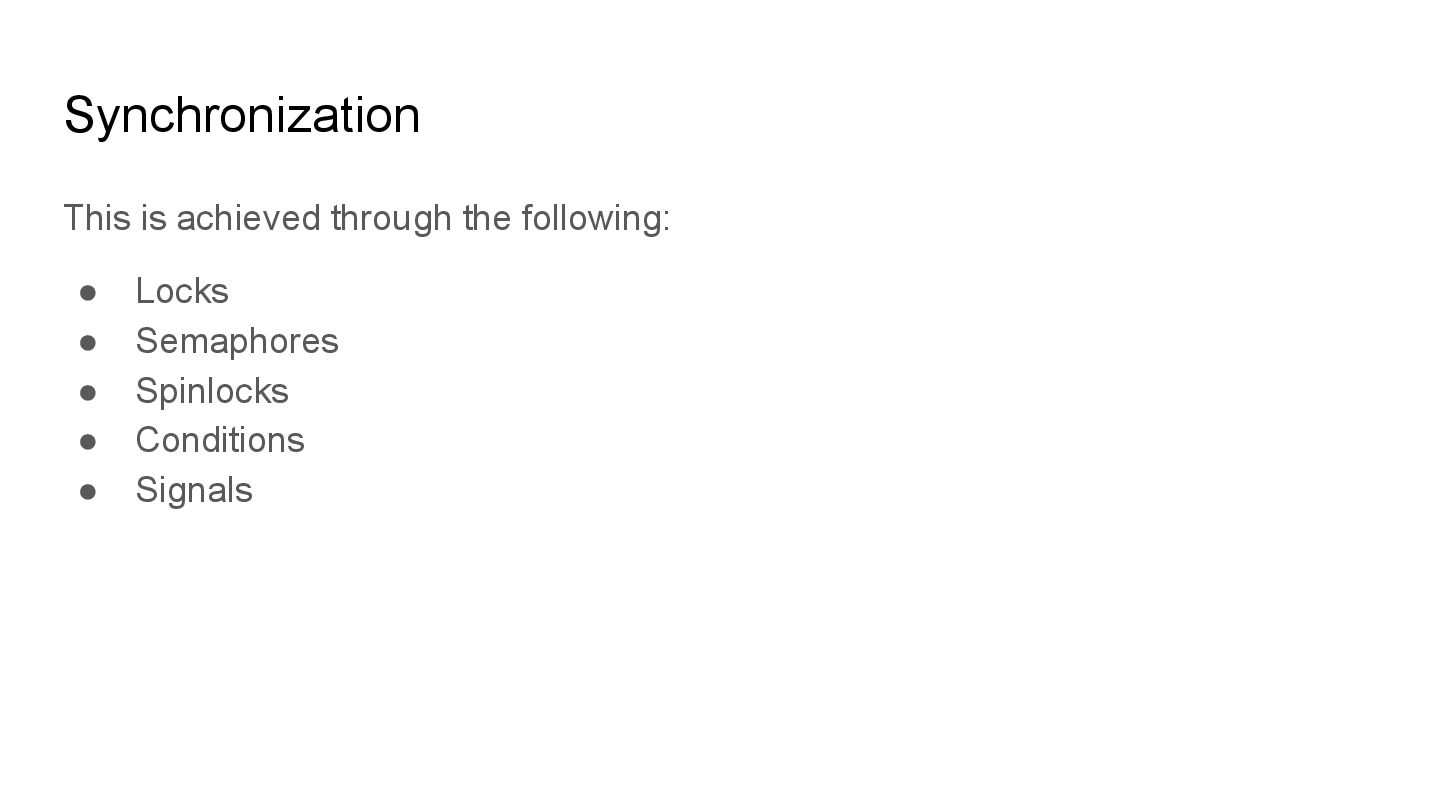
Semaphores • Spinlocks • Conditions • Signals And a lot more primitives depending on the use case. I heavily recommend reading Djikstra’s original paper on this topic: Concurrent Programming, Mutual Exclusion (1965; Dijkstra)
sections that rely on multiple parameters. In replicated storage, the WAL (Write Ahead Log) is a localized transaction log containing sequential entries of transactions. In the wider spectrum of replication, the master replica will apply these replicated updates based on another set of factors, usually this only happens during a master failover. There are tons and tons of consensus requirements in database design which work past mutexes. However, most will resolve as long as the system stays operational.
and delivery requirements. These are specific agreements which are made on messages delivered. Usually, you will find acknowledgements in message passing systems than shared memory stores like databases. However, shared memory systems also enforce deduplication and other forms of acknowledgements in their design.
be retried indefinitely until there is at least one message received on one end and an acknowledgement sent. It does not matter if the requests are duplicated, what matters is that at least one event of it exists.
be retried indefinitely until there is at least one message received on one end and an acknowledgement sent. It does not matter if the requests are duplicated, what matters is that at least one event of it exists. This is useful for things like heartbeats where multiple events are good to signal that things are fine. No events implies some failure with the existing system.
retried indefinitely until one message is received on one end and an acknowledgement sent. This is needed for critical events where duplicates just cannot happen.
retried indefinitely until one message is received on one end and an acknowledgement sent. This is needed for critical events where duplicates just cannot happen. In cases like data transfer, we cannot have the same packet for example sent and acknowledged twice or not acknowledged at all. That would imply data corruption and misordering of TCP sequences.
send a message but there is no issue if it is never received or sent. Systems using UDP packets for data transfer like torrents are a great example. Having at most once delivery implies that acknowledgements are not required for the system to be operational, these can also be looked at as lossy delivery acknowledgements.
exactly once delivery although in practice, it is usually at most once delivery. Databases are high integrity systems requiring strict acknowledgement of packets and data storage and retrieval.
exactly once delivery although in practice, it is usually at most once delivery. Databases are high integrity systems requiring strict acknowledgement of packets and data storage and retrieval. The WAL is implemented to keep data localised until it can be replicated and the acknowledgements are strictly required so database protocols are built on TCP as a result.
that it is possible to process things at the same time speeding up the process. In a similar fashion, we can employ techniques of state sharing to apply those techniques in distributed systems.
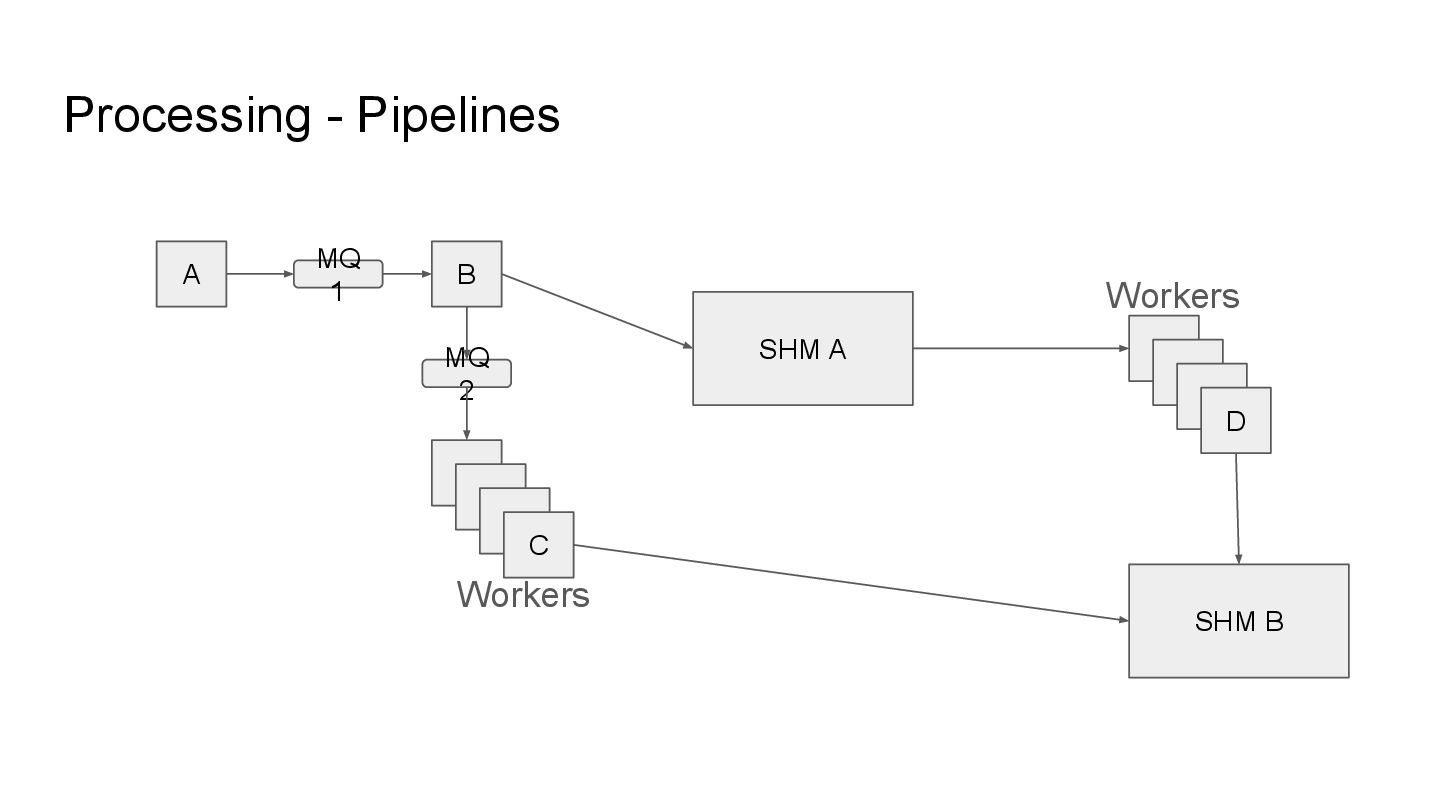
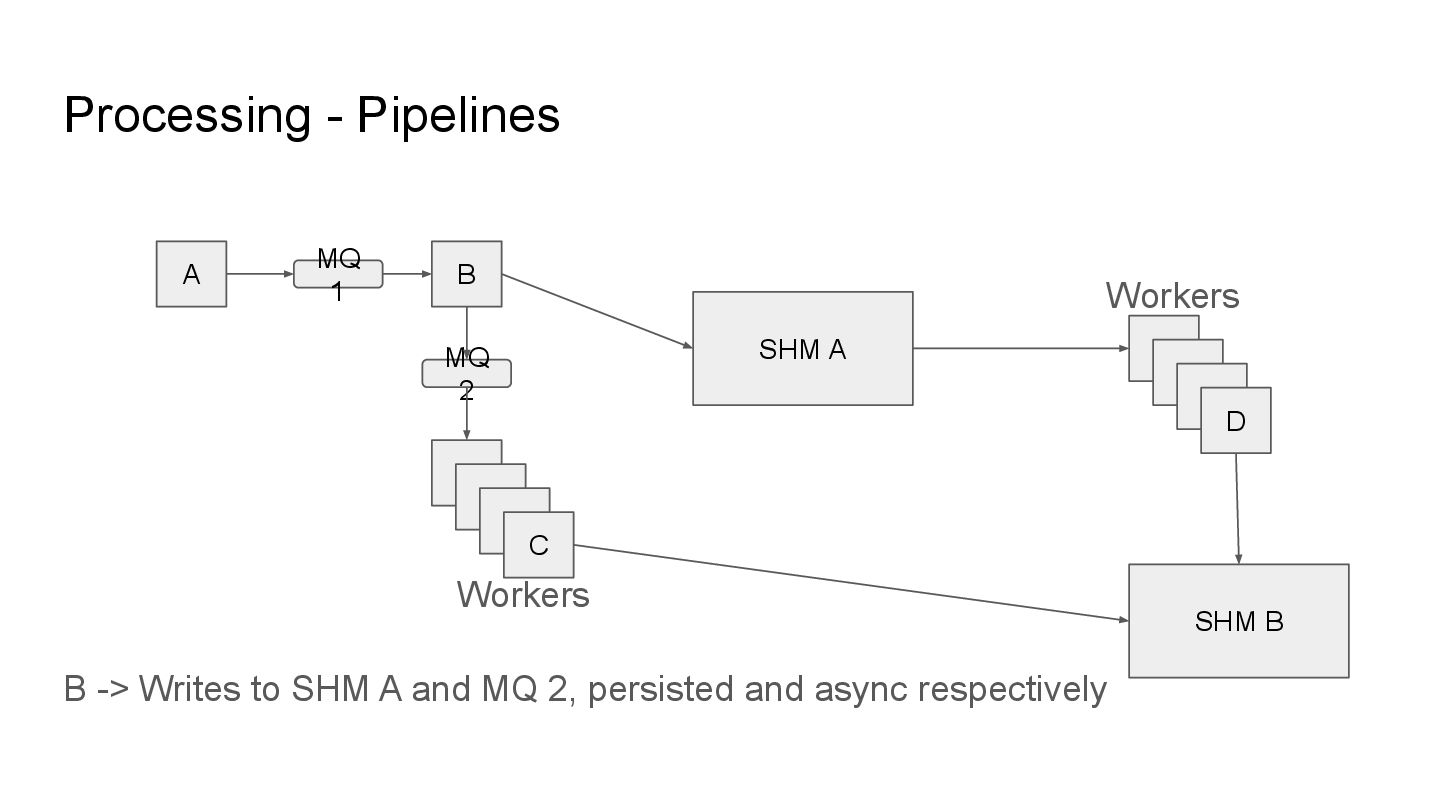
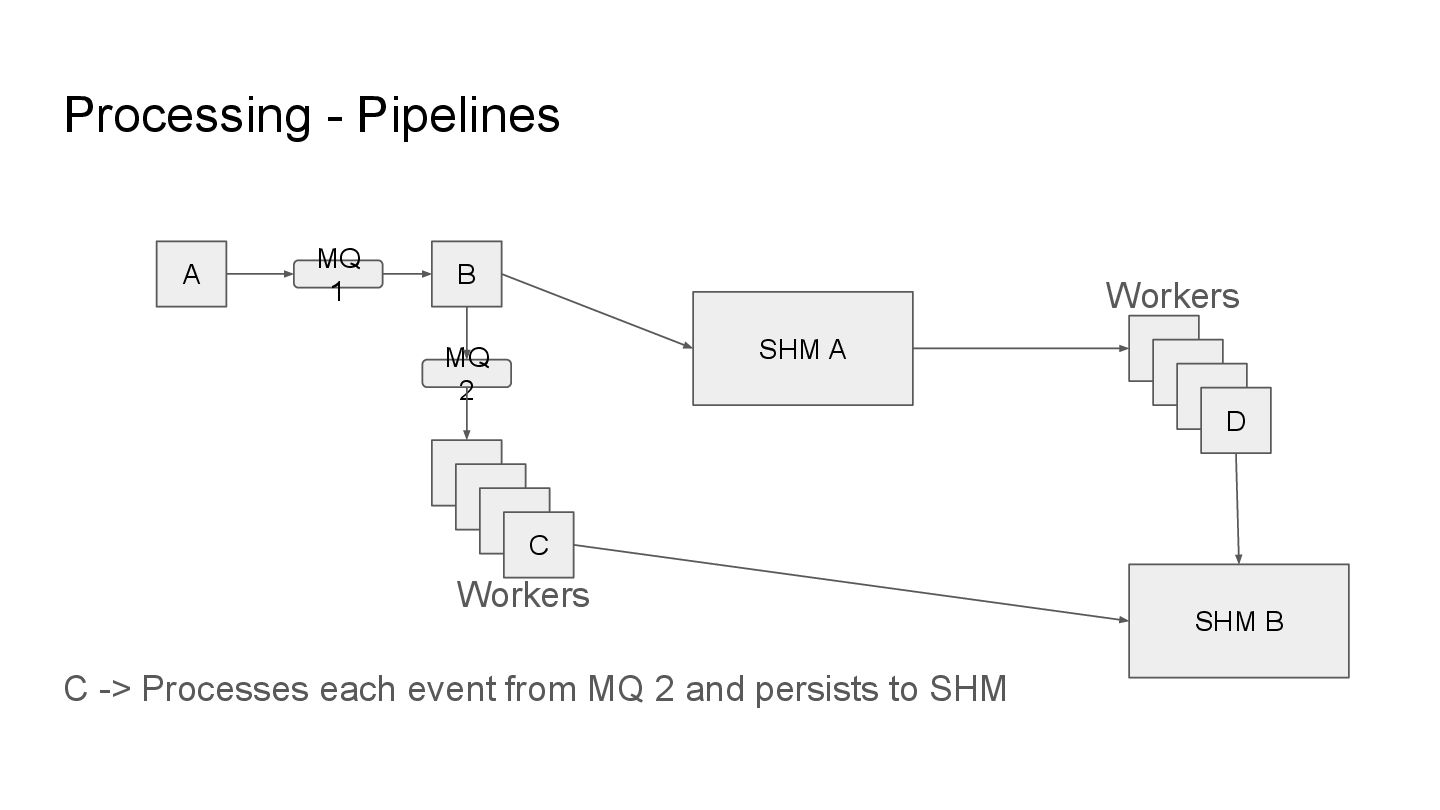
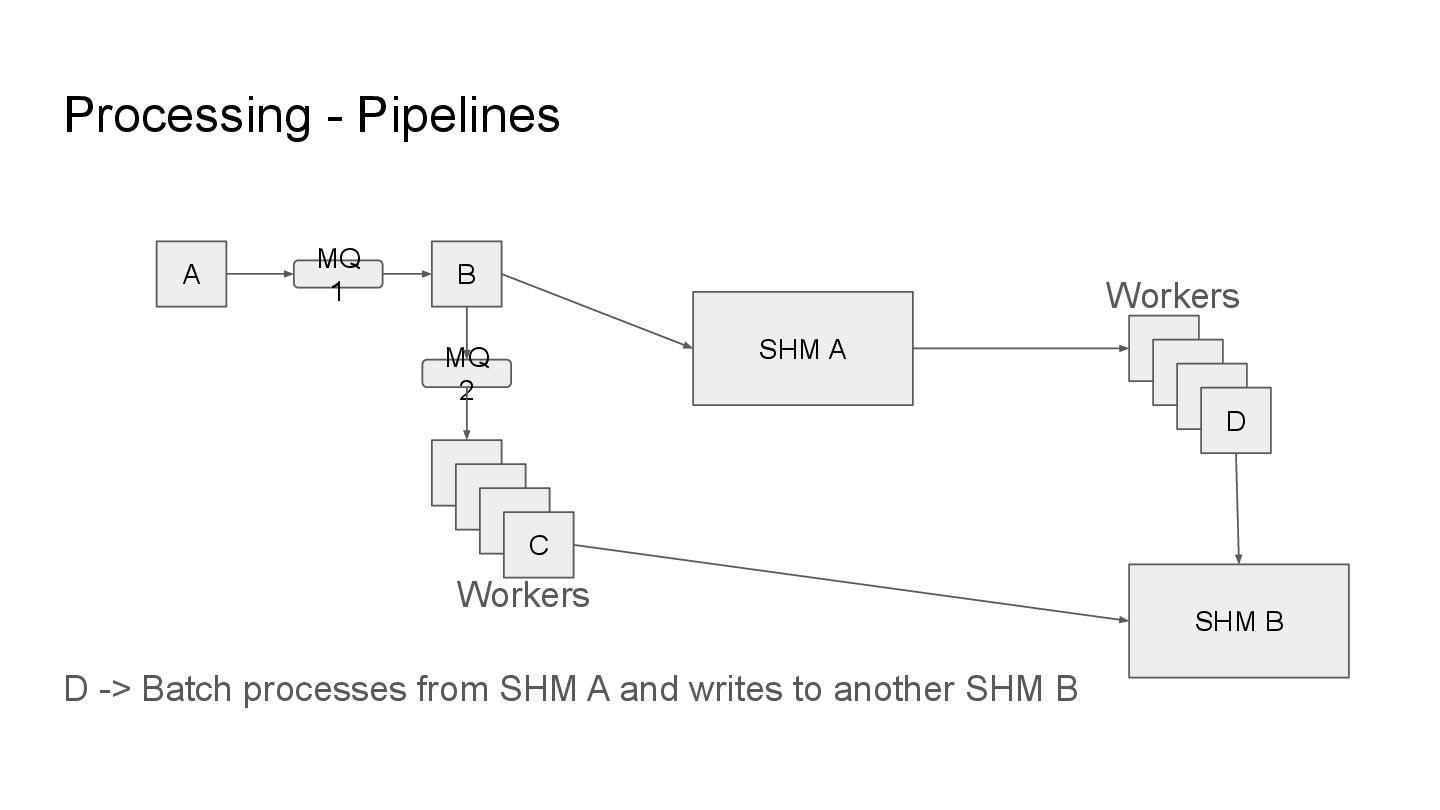
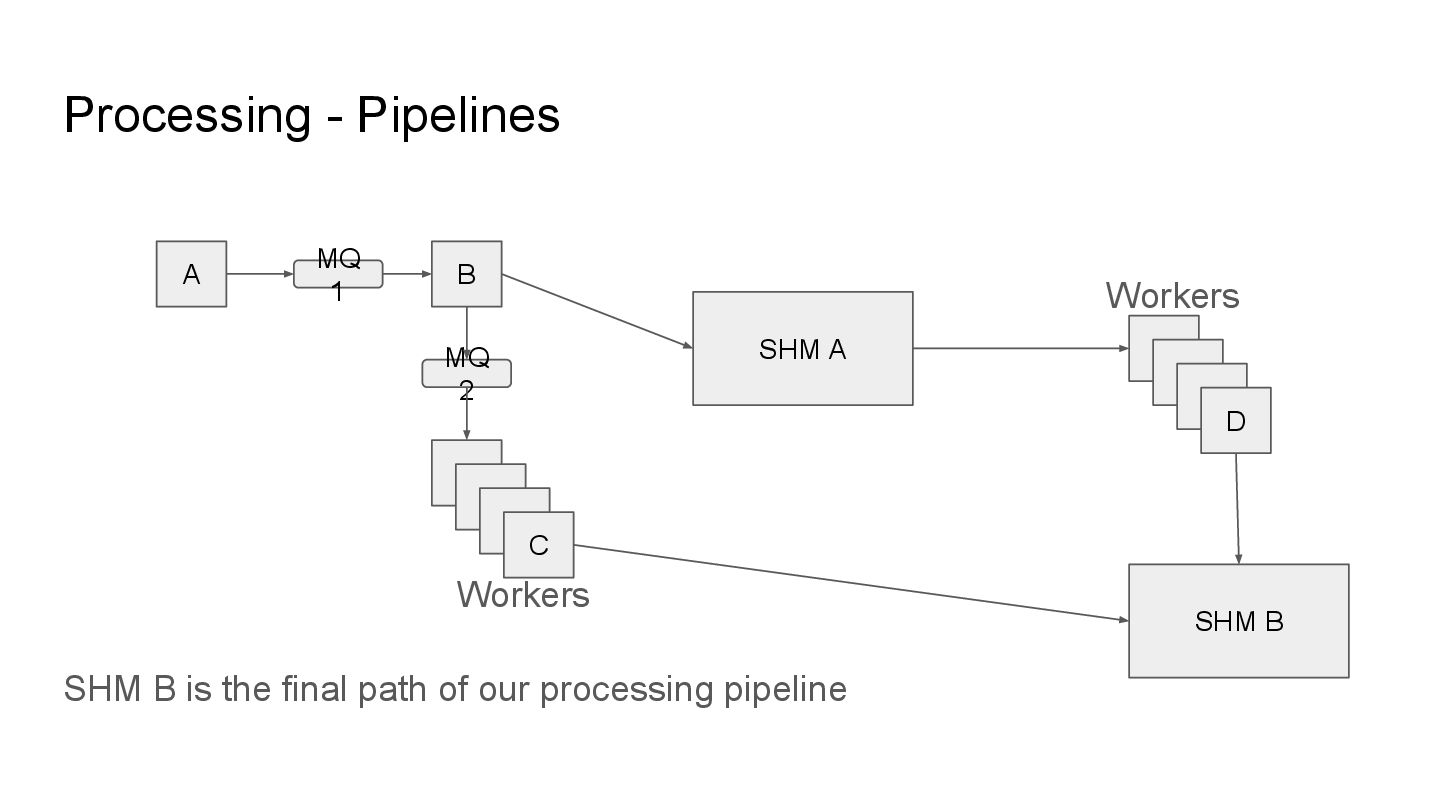
addition to parallel execution, we model the stages of processing in chained workflows. These chained workflows are called pipelines and these pipelines may employ any number of transactions and rollbacks in processing information.
addition to parallel execution, we model the stages of processing in chained workflows. These chained workflows are called pipelines and these pipelines may employ any number of transactions and rollbacks in processing information. As a refresher: MQ - Message Queue (message queue) SHM - Shared Memory (database)
varying names, some might say: • Message Queue • Message Broker • Service Bus • Streams Processor And several others. There are differences but the basic idea is all of them implement message passing.
always have a source (start of the message transfer) and a sink (end of the message transfer) in the process. The source and sink could also be termed:
always have a source (start of the message transfer) and a sink (end of the message transfer) in the process. The source and sink could also be termed: • PUBlisher and SUBscriber (PUBSUB)
always have a source (start of the message transfer) and a sink (end of the message transfer) in the process. The source and sink could also be termed: • PUBlisher and SUBscriber (PUBSUB) • Producer and Consumer
always have a source (start of the message transfer) and a sink (end of the message transfer) in the process. The source and sink could also be termed: • PUBlisher and SUBscriber (PUBSUB) • Producer and Consumer And several others, it’s all still message passing.
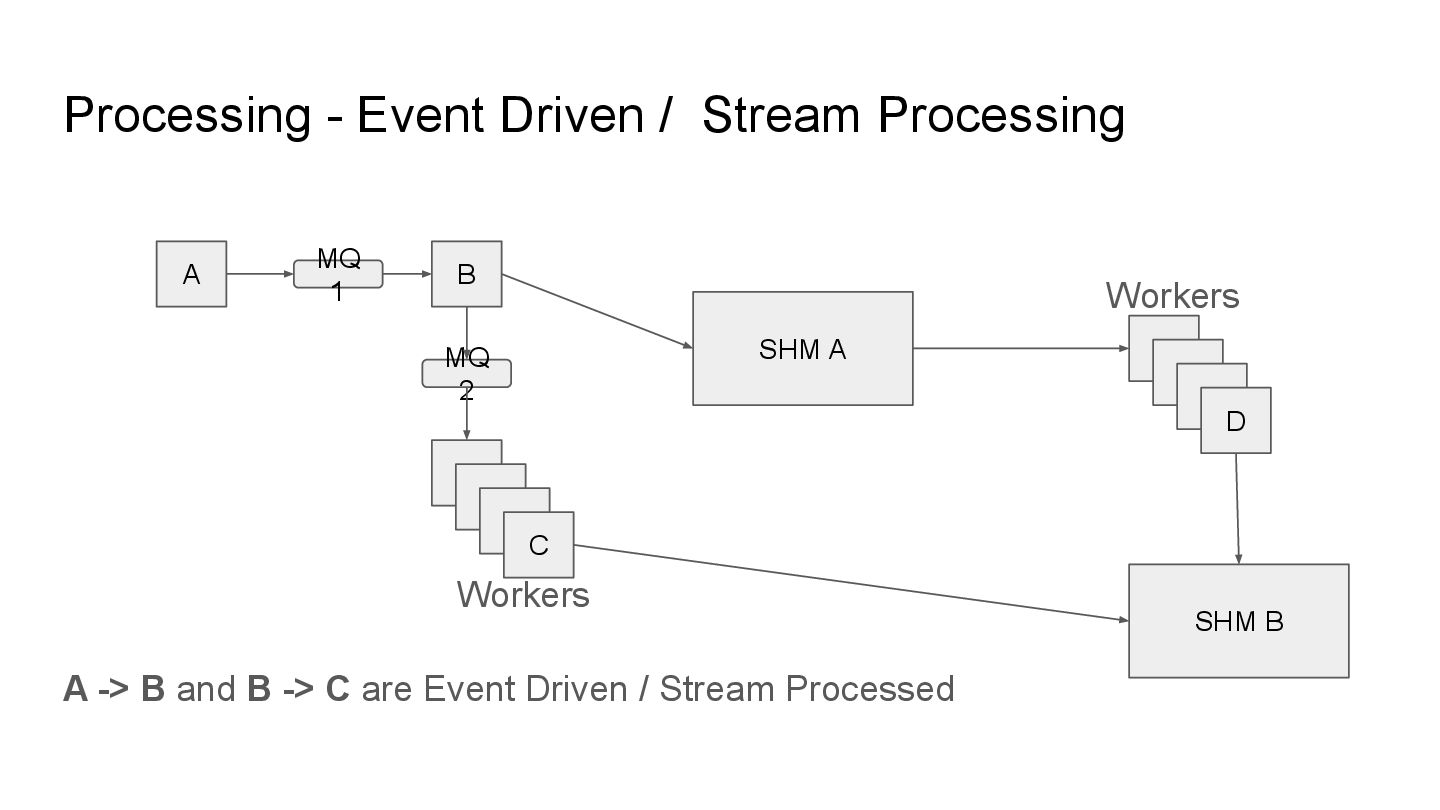
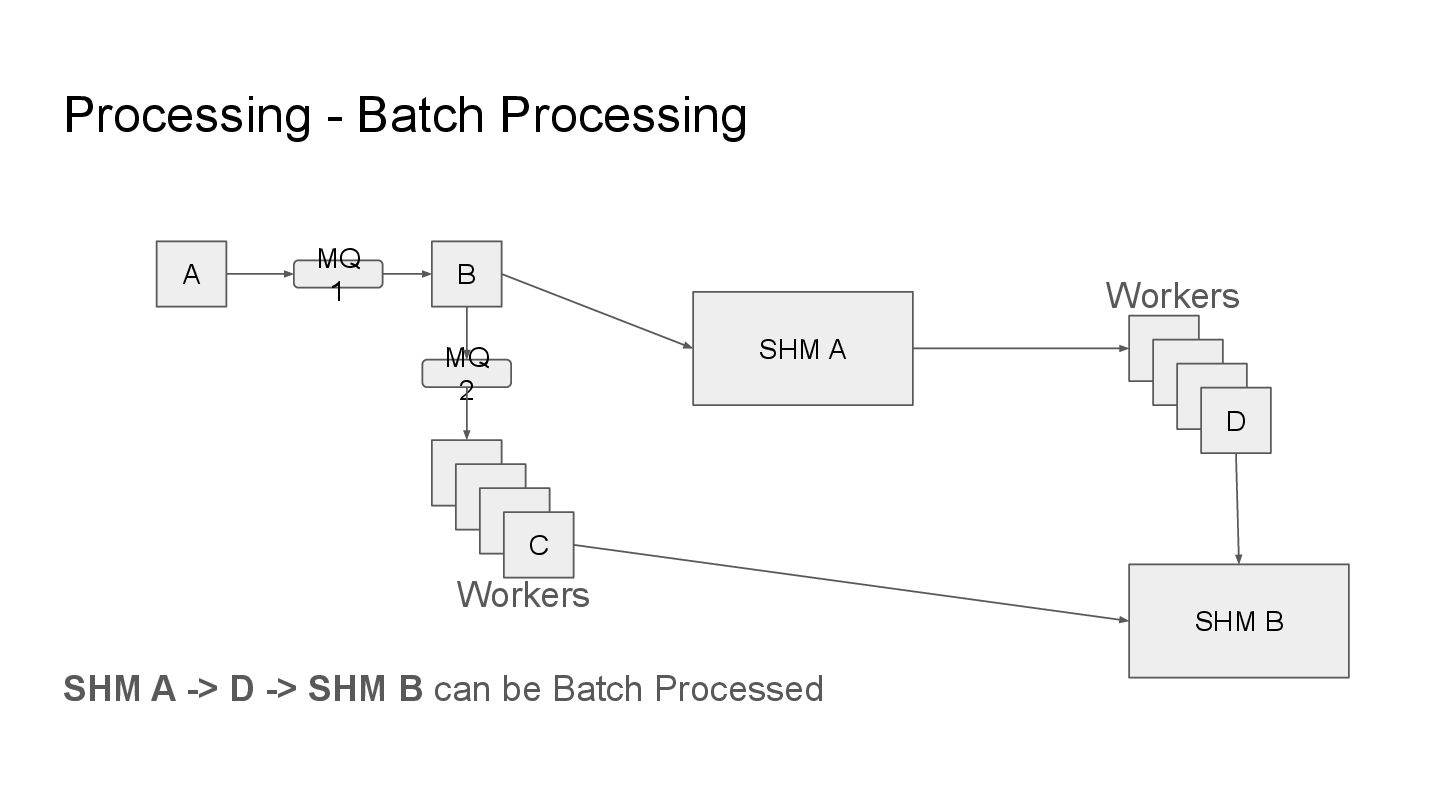
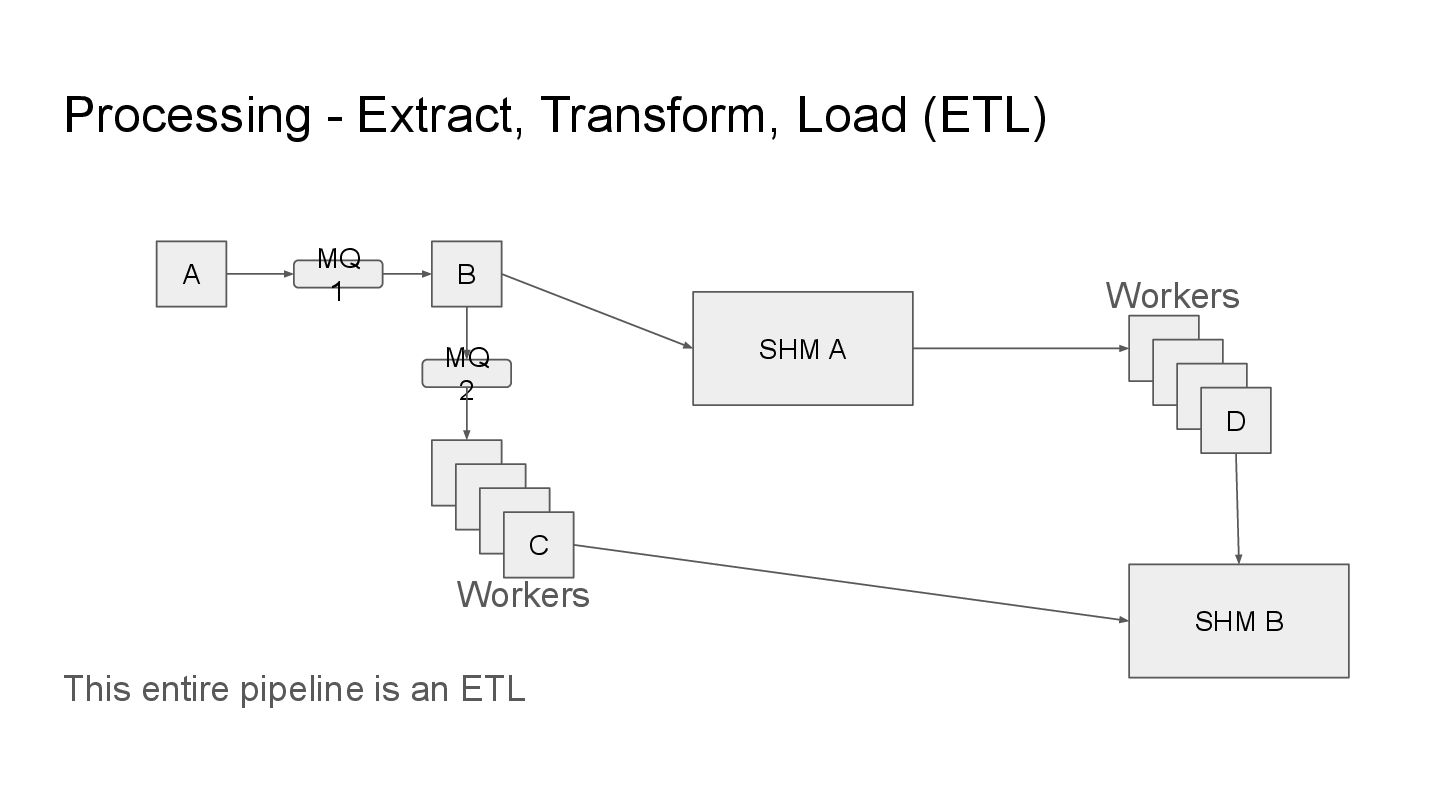
pipelines that employ various forms of techniques, these pipelines can be: • Event Driven / Stream Processing • Batch Process • Extract, Transform, Load (ETL)
we just take events or streams of data as they come and process them to where they need to go. No persistence needed to make this work. Webhooks are a good example of this paradigm.
persistent store of data to aggregate all the information over some interval. Batch processing is useful when you need to gather tons of data and makes sense of it in a single outlook.
persistent store of data to aggregate all the information over some interval. Batch processing is useful when you need to gather tons of data and makes sense of it in a single outlook. An example of this is Payroll where all your expenses over a month need to be added together so you can get a final ledger over that period.
you are usually running a mix of batch and stream processing. You take data aggregated over a period of time (Extract) with various input and output streams performing operations on them in the process (Transform) only to save the final output in a warehouse for consumption (Load)
tons of information for acquiring trends and performing complex data analysis. These processing systems have very long storage requirements and integrate multiple sources of information.They have very strong transaction guarantees and require significant compute to run.
tons of information for acquiring trends and performing complex data analysis. These processing systems have very long storage requirements and integrate multiple sources of information.They have very strong transaction guarantees and require significant compute to run. OLAPs databases are usually the likes of Spanner, Aurora, Snowflake and most other data warehousing solutions you will find.
and short term batch processing outcomes where data needs to be processed in a relatively short time and the data sources to aggregate from are minimal. OLTP databases usually do not have very strong transaction guarantees and this eases performance in the processing aspect.
and short term batch processing outcomes where data needs to be processed in a relatively short time and the data sources to aggregate from are minimal. OLTP databases usually do not have very strong transaction guarantees and this eases performance in the processing aspect. Examples are the classic databases, Redshift, RDS and others.
here are used internally in the database internals design. In building distributed systems with databases, these are similar concepts that can be applied to their design.
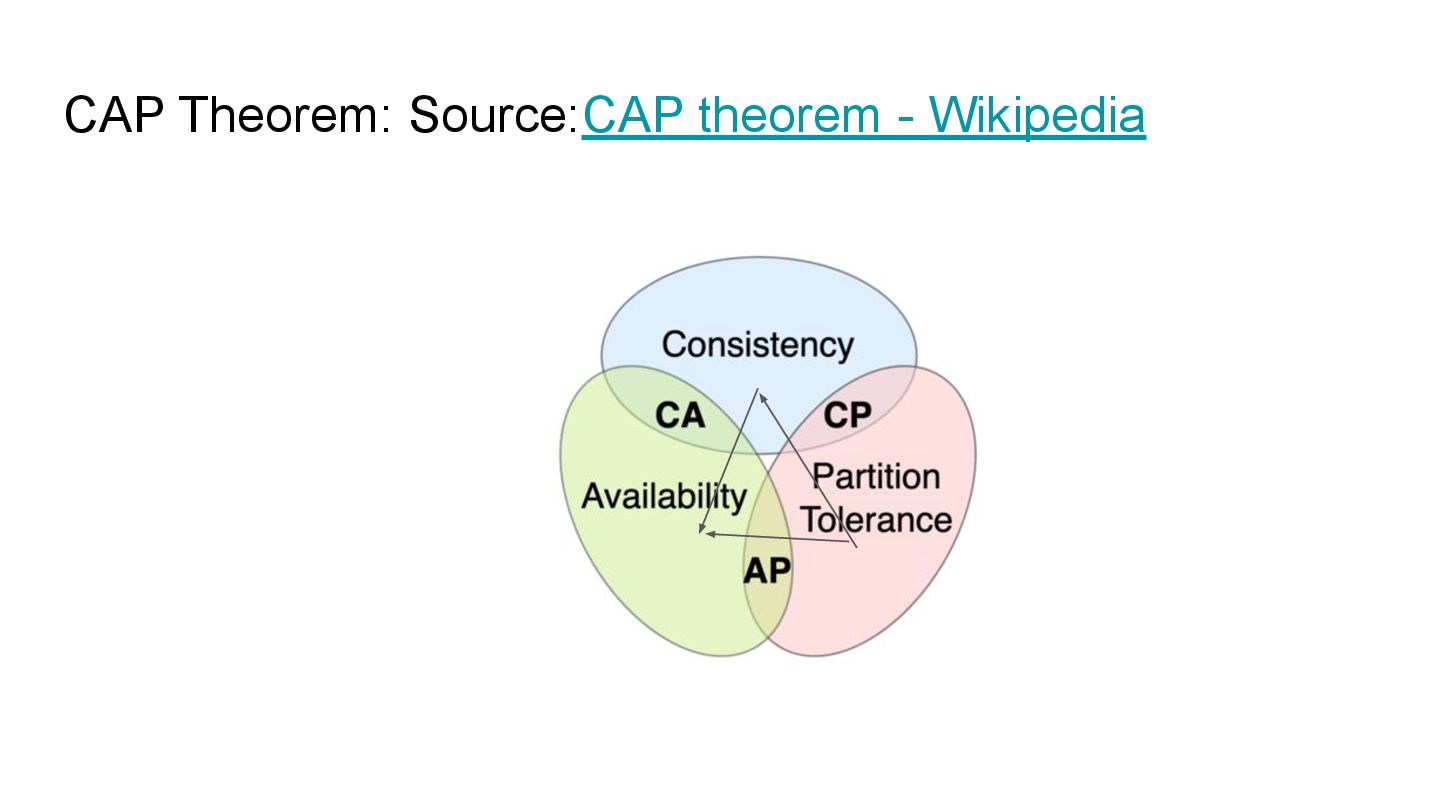
distributed system is always the same at any given time. Availability means that every update to such information will always be received without error.
distributed system is always the same at any given time. Availability means that every update to such information will always be received without error. Partition Tolerance means that no matter the number of nodes, we will always be operating despite the failure of other nodes.
is impossible to have Consistency, Availability and Partition Tolerance in a distributed system. Partition Tolerance is more aligned with the “distributed” aspect of systems as every node can independently perform actions.
is impossible to have Consistency, Availability and Partition Tolerance in a distributed system. Partition Tolerance is more aligned with the “distributed” aspect of systems as every node can independently perform actions, doing so in consensus means that we will either sacrifice availability of the system since the now failed nodes will give errors.
is impossible to have Consistency, Availability and Partition Tolerance in a distributed system. Partition Tolerance is more aligned with the “distributed” aspect of systems as every node can independently perform actions, doing so in consensus means that we will either sacrifice availability of the system since the now failed nodes will give errors or consistency in the results since failed nodes cannot get the most updated information.
and Paterson (hence the name). Source: Impossibility of Distributed Consensus with One Faulty Process It draws on three properties of the consensus process:
and Paterson (hence the name). Source: Impossibility of Distributed Consensus with One Faulty Process It draws on three properties of the consensus process: • Agreement
and Paterson (hence the name). Source: Impossibility of Distributed Consensus with One Faulty Process It draws on three properties of the consensus process: • Agreement • Validity
and Paterson (hence the name). Source: Impossibility of Distributed Consensus with One Faulty Process It draws on three properties of the consensus process: • Agreement • Validity • Termination
ensure decisions are defined and agreed upon by active non-failing members of the network. Validity implies that the value proposed is made by members of the network participating in the voting process, it cannot be externally provided.
ensure decisions are defined and agreed upon by active non-failing members of the network. Validity implies that the value proposed is approved by members of the network participating in the voting process, it cannot be externally provided or defaulted. Termination means a decision is only made when active non-faulty members agree it can be made.
are asynchronous implying there is no upper bound on processing time before a decision is made. The basis of the paper establishes that: 1. it is not possible to have a distributed system that can guarantee its current state is always up to date without failure
are asynchronous implying there is no upper bound on processing time before a decision is made. The basis of the paper establishes that: 1. it is not possible to have a distributed system that can guarantee its current state is always up to date without failure 2. consensus cannot be said to occur within a bounded time, there will always be delays that violate a predefined interval for resolution
of the same problem, that distributed systems are a tradeoff in consensus. FLP Impossibility makes it known that time in distributed systems cannot be bounded and the state of each interacting member is never perfectly known, hence why consensus will always take an unbounded amount of time due to uncooperating members.
of the same problem, that distributed systems are a tradeoff in consensus. FLP Impossibility makes it known that time in distributed systems cannot be bounded and the state of each interacting member is never perfectly known, hence why consensus will always take an unbounded amount of time due to uncooperating members. CAP argues that a distributed system cannot be perfectly designed to have all members achieve consensus without ignoring failing members or the known state of the system.
it impossible to reliably know the state of the network at any given time. Workarounds for failures are best known depending on the problem and there are extensive literatures taking into consideration these failures in considering solutions.
it impossible to reliably know the state of the network at any given time. Workarounds for failures are best known depending on the problem and there are extensive literatures taking into consideration these failures in considering solutions. In summary, there is no perfect distributed system.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}