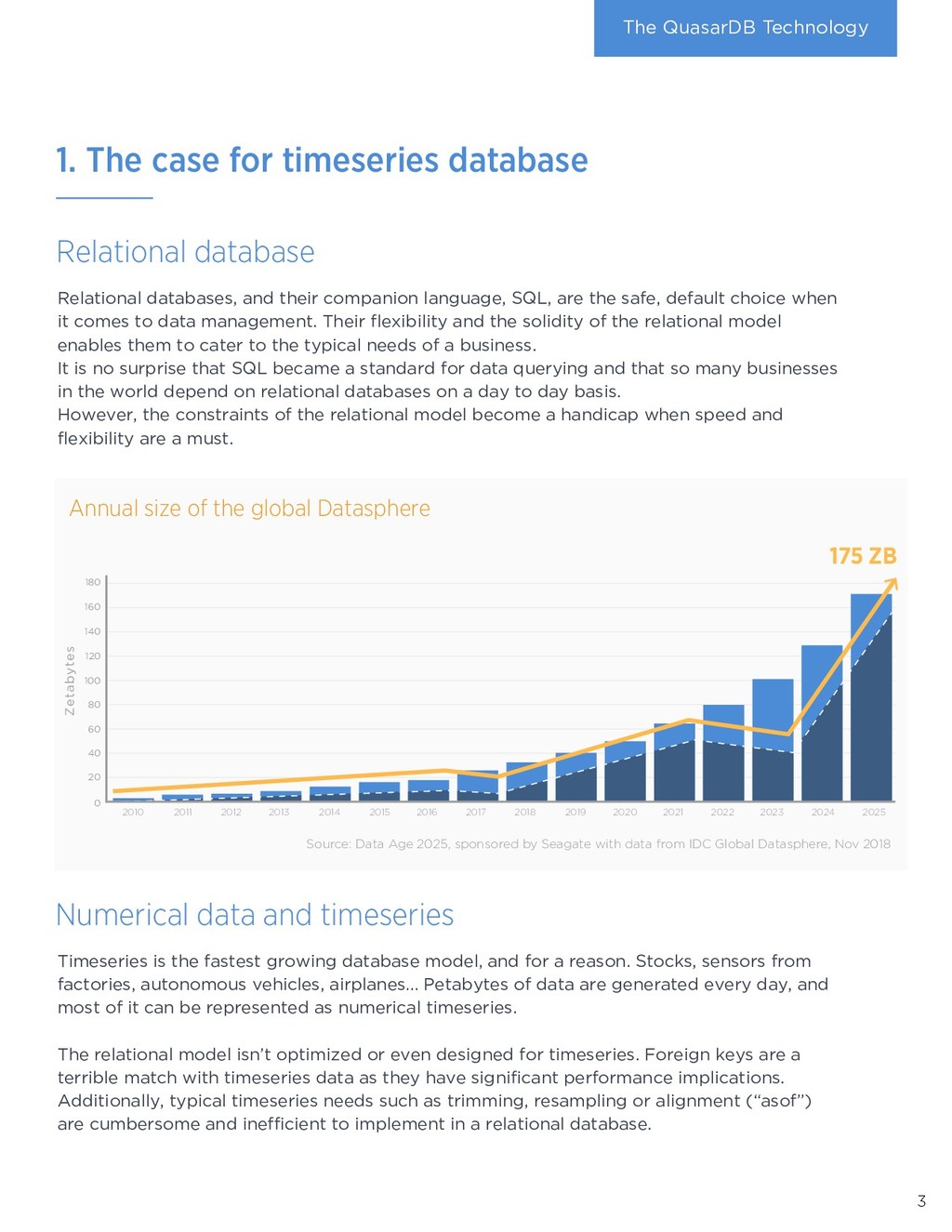
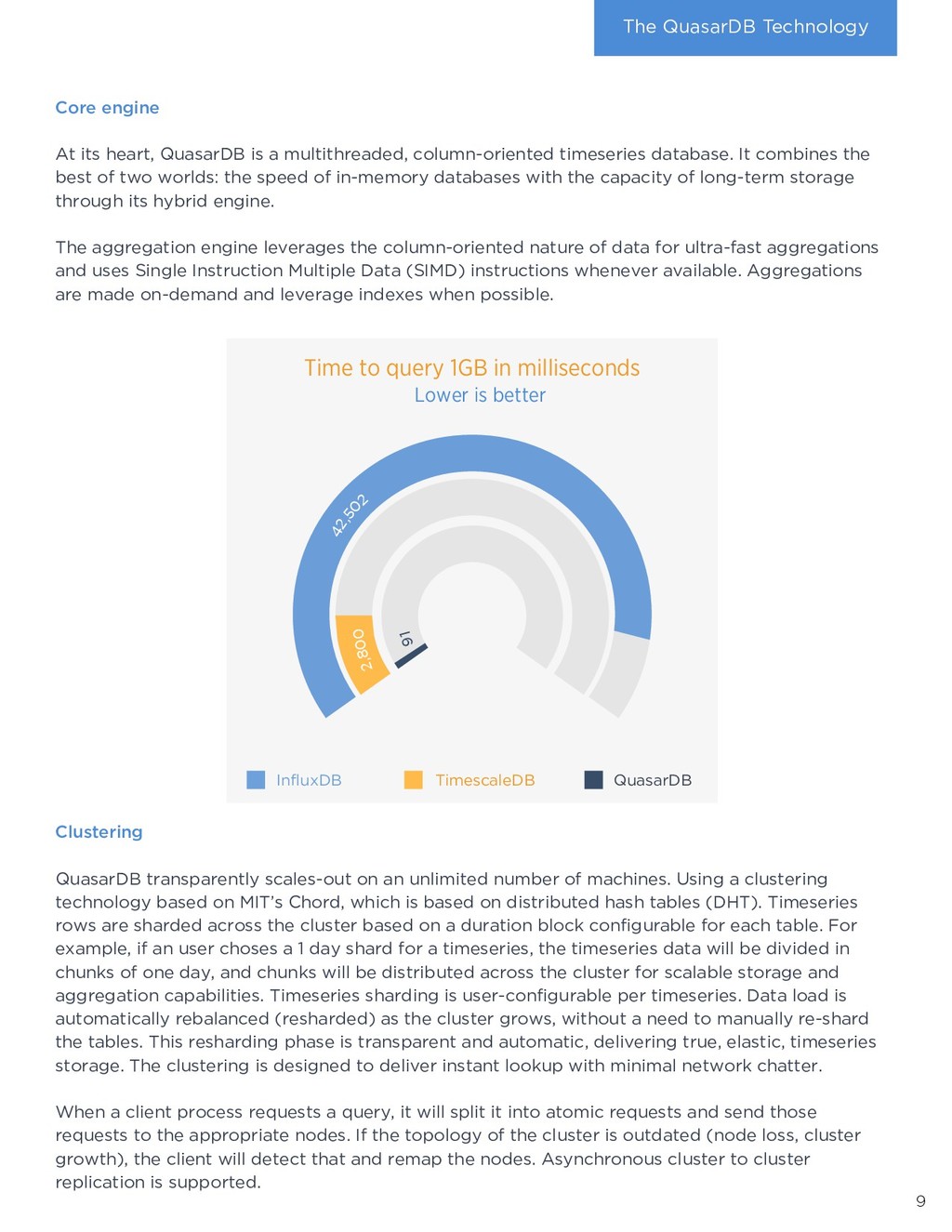
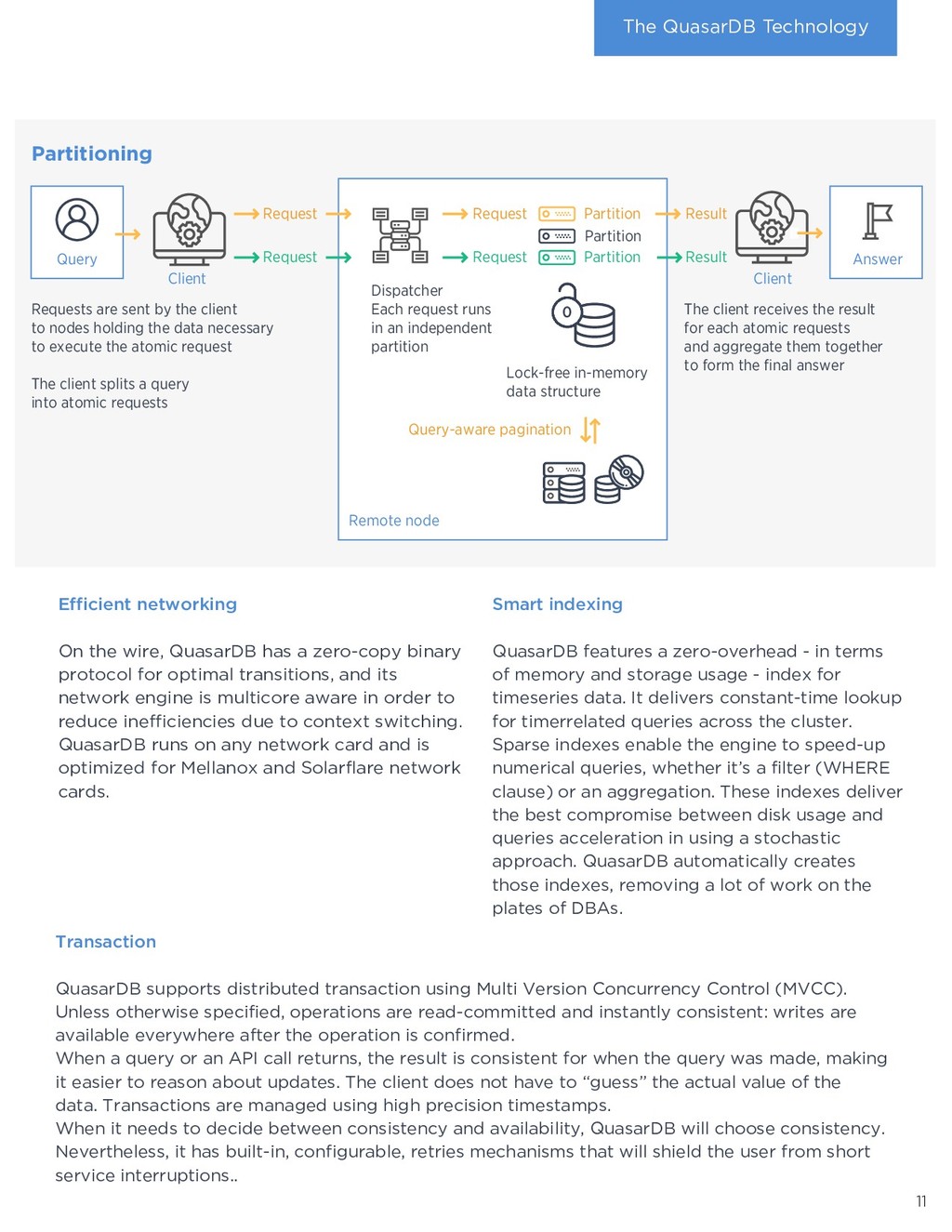
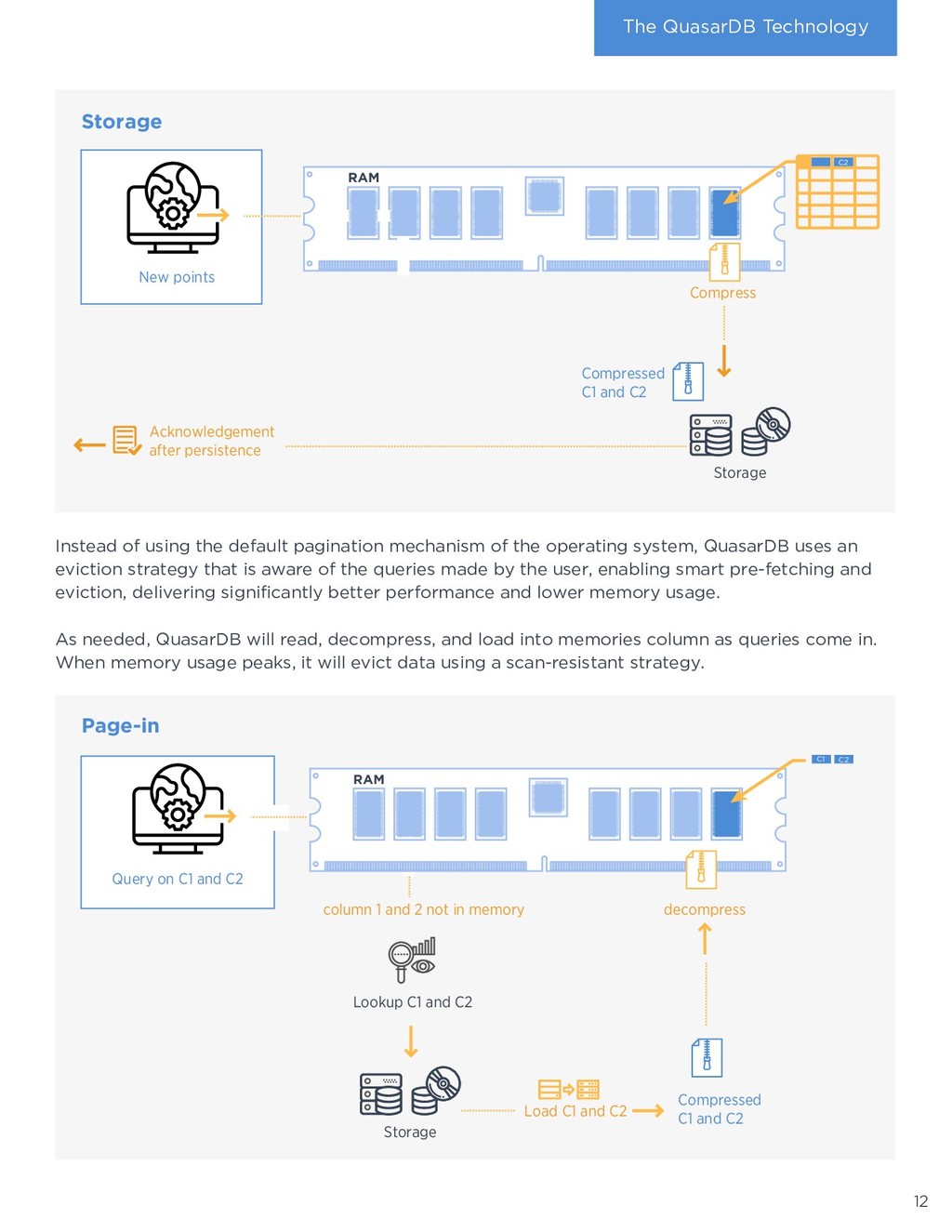
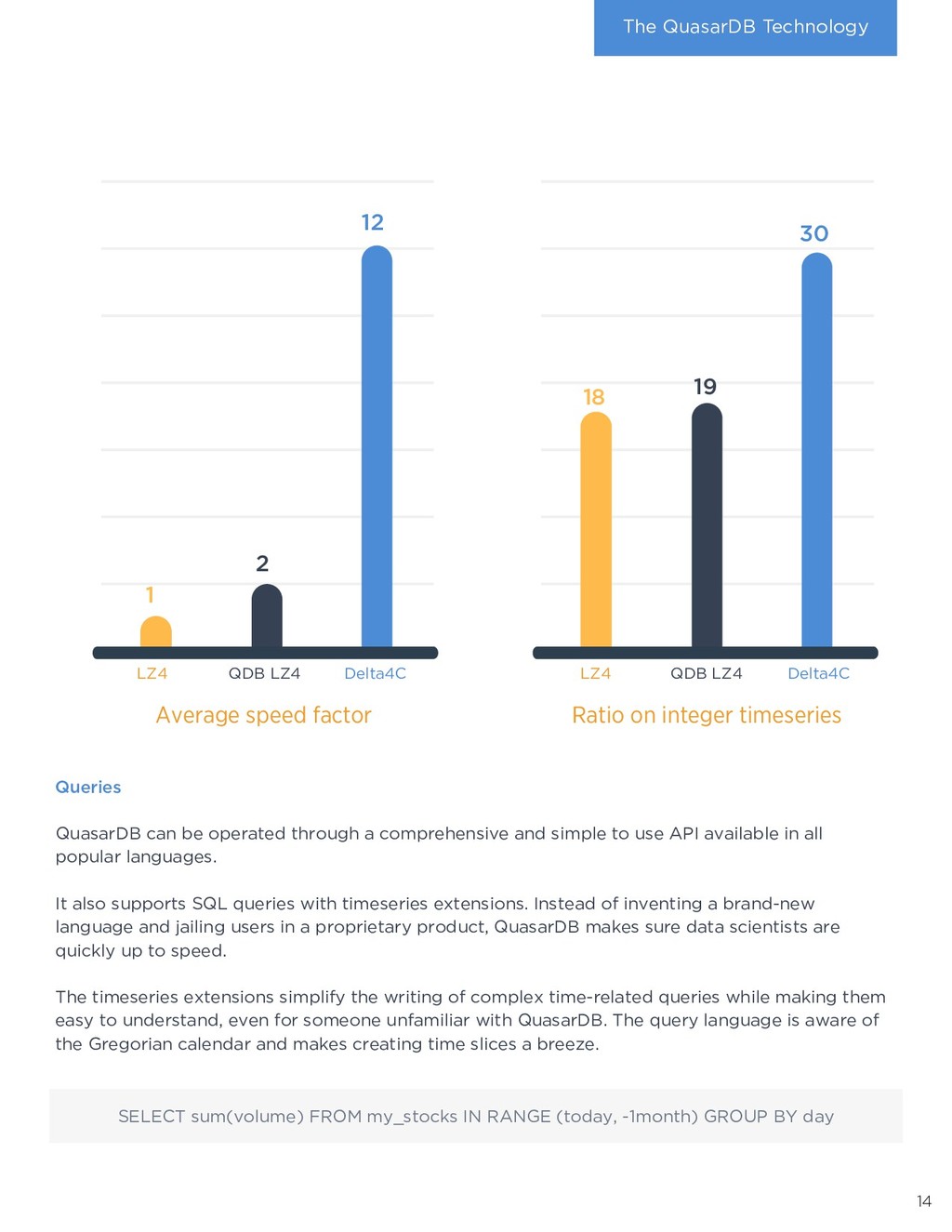
of efficient storage, low CPU usage, integration, and ease of use results in tremendous savings for businesses. Deploying QuasarDB is cheaper and faster than typical Big Data solutions: › Data analysts use known tools such as Python and SQL to interface with their data: no arcane, proprietary language to learn and skills are transferable. › QuasarDB integrates ETL, distribution, storage, analytics, orchestration, and connectivity in a single package radically simplifying deployment and administration, shortening projects time. › Efficient storage means significantly reduced storage costs. › Speed means lower CPU usage, which directly translates to lower hosting costs. Max Min Timestamp 14:00 100 110 15:00 110 120 16:00 105 120 QuasarDB is column oriented in memory and in disk. When storing tables there are two ways or storing the data: per row or per column. When reading data in memory, processors prefetch the data adjacent to it. Thus, reading continuous data is faster than reading scattered data. Row oriented organization favors operations that work on rows, whereas column-oriented favors operations that work on columns. Let us consider a table with min and max values per hour. Computing the minimum value for all hours is a column oriented, whereas computing the spread for a given hour is row oriented. Timeseries columns are significantly larger than the rows, and, most operations are column oriented, making timeseries benefit greatly from column oriented storage. Finally, organizing data as columns enables compression to be more efficient as patterns are more likely to appear within the same column than within the same row. 8 4. Technology deep dive How does QuasarDB deliver these benefits? What sets it apart from the competition? The answer is found in the overwhelming amount innovation packaged into the software. Implementation QuasarDB is written in modern C++ 17 with the most critical parts handwritten in assembly. This delivers a portable binary unconstrainted by a virtual machine or complex dependencies. QuasarDB is available for Intel-compatible and ARM architectures, both 32-bit and 64-bit. Zero-overhead architecture As QuasarDB combines in a single binary the orchestrator, the query engine, the aggregation engine, and the persistence. Thus, it can use a zero-copy architecture that prevents the efficiency loss typically found in big data systems that combines different software products. Data isn’t moved around: it’s processed in place. For example, the memory buffer from the network card can be written directly to disk after sanity checks, removing overheads caused by allocations and copies. What does column- oriented mean ?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}