Presented by: Marius Bogoevici
Video recording: https://youtu.be/CXy_T_rWcLE
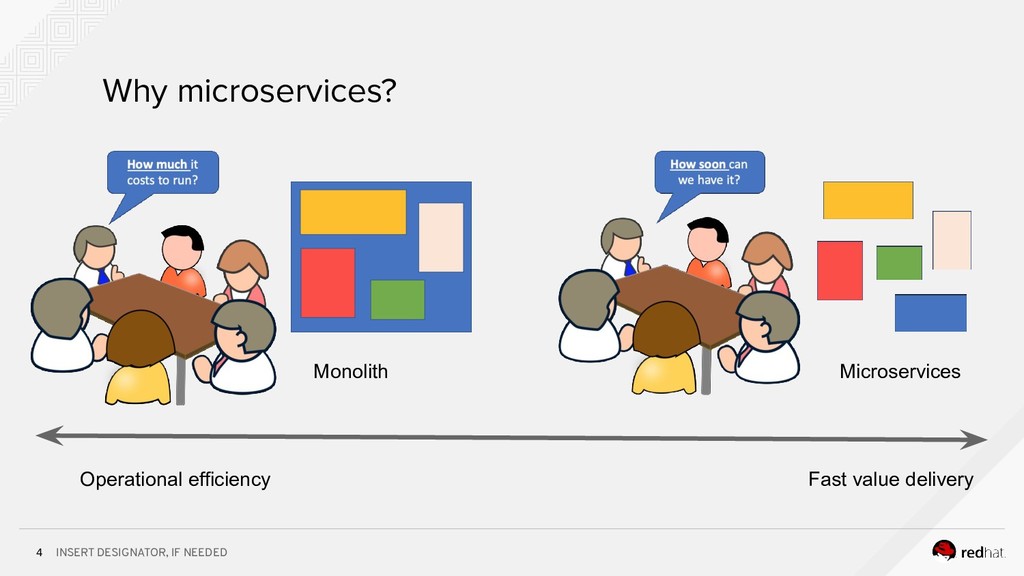
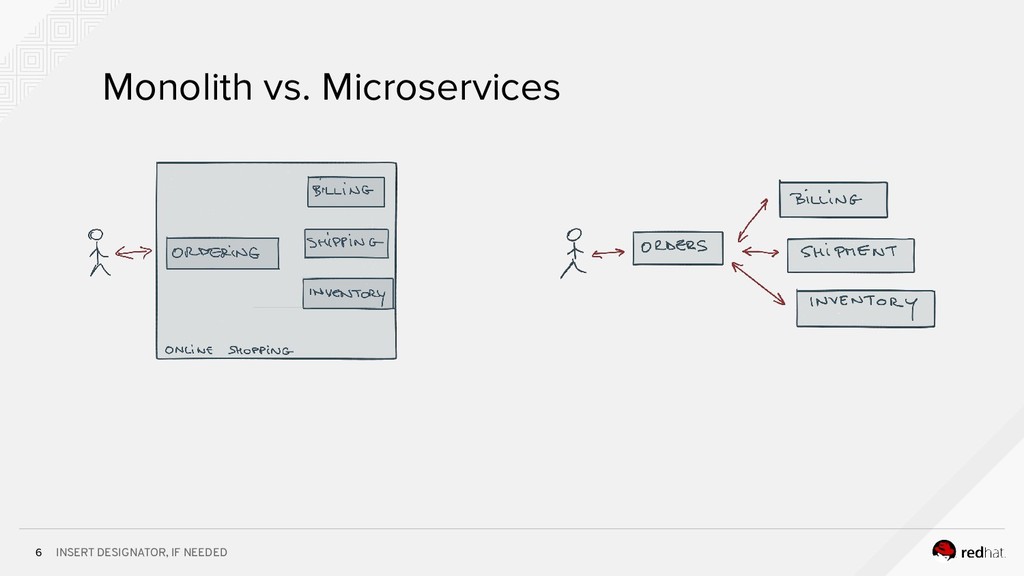
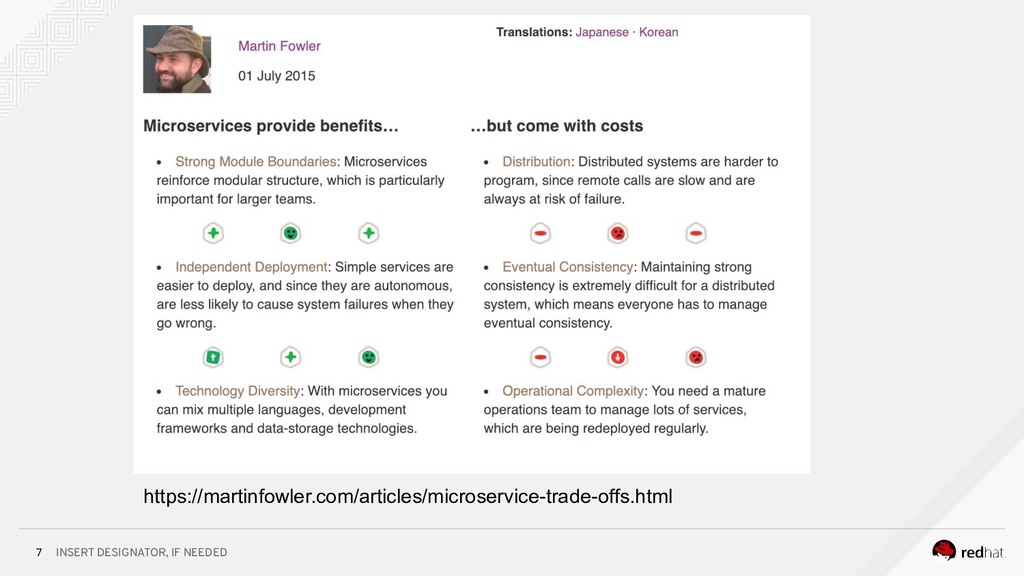
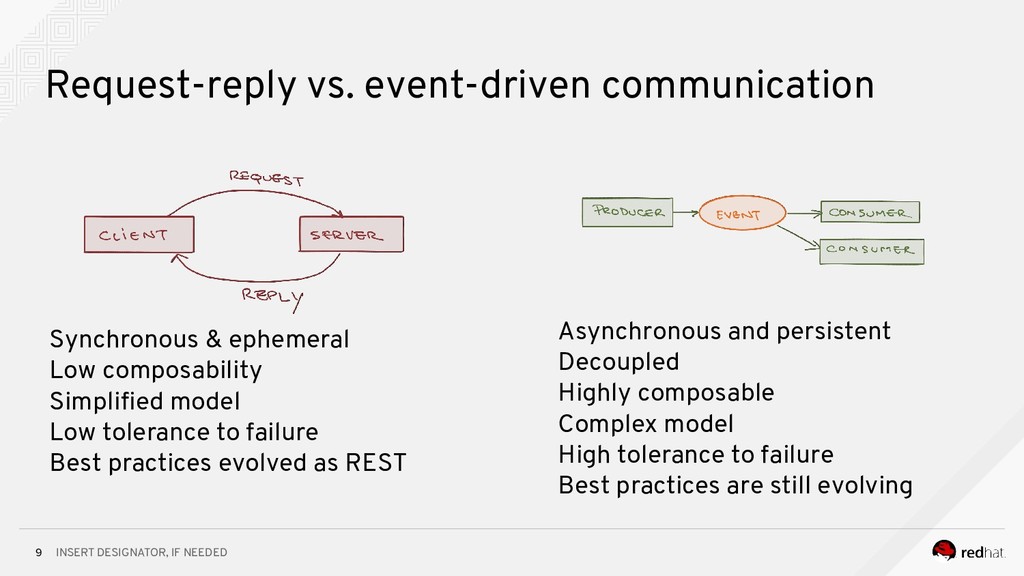
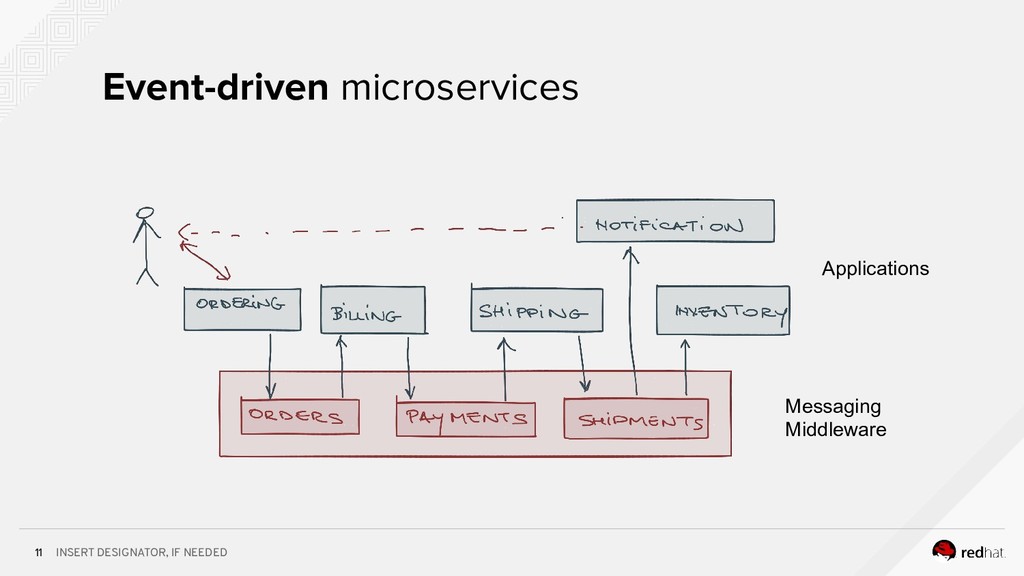
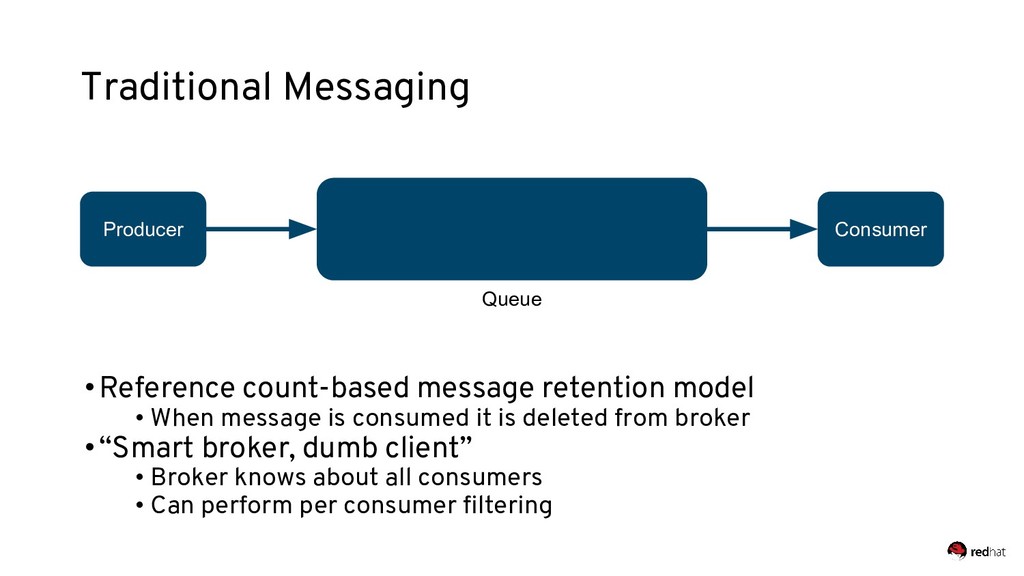
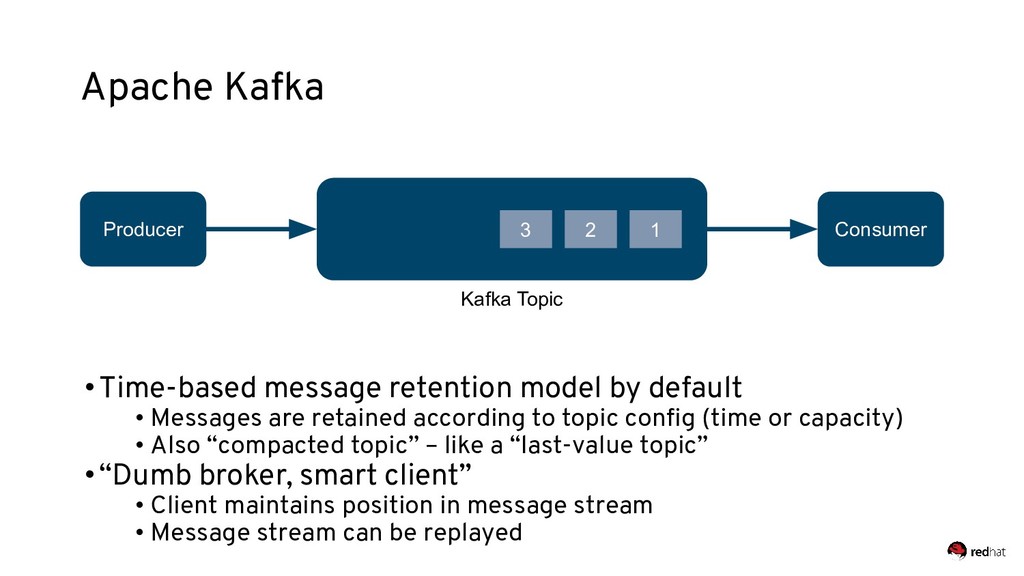
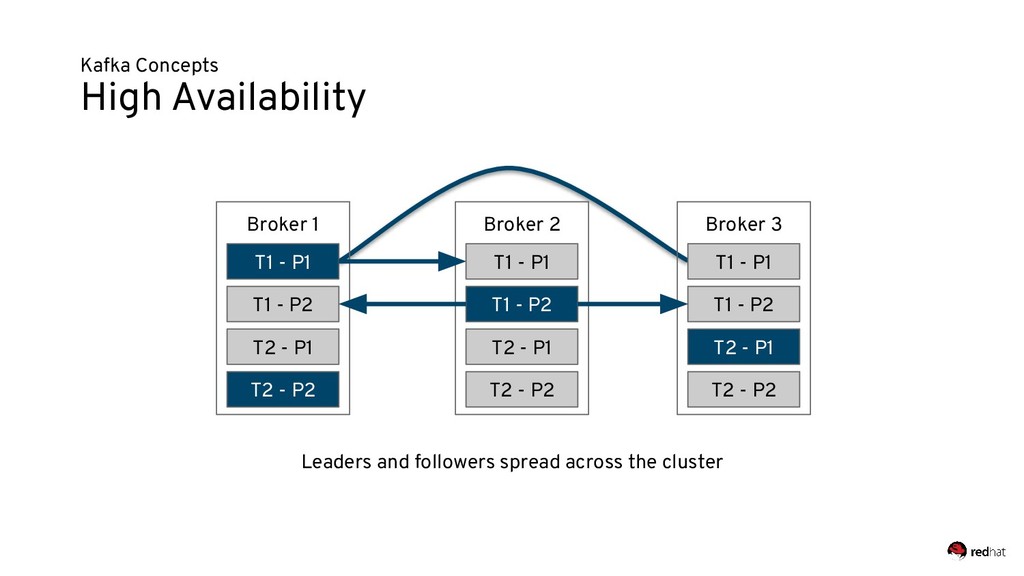
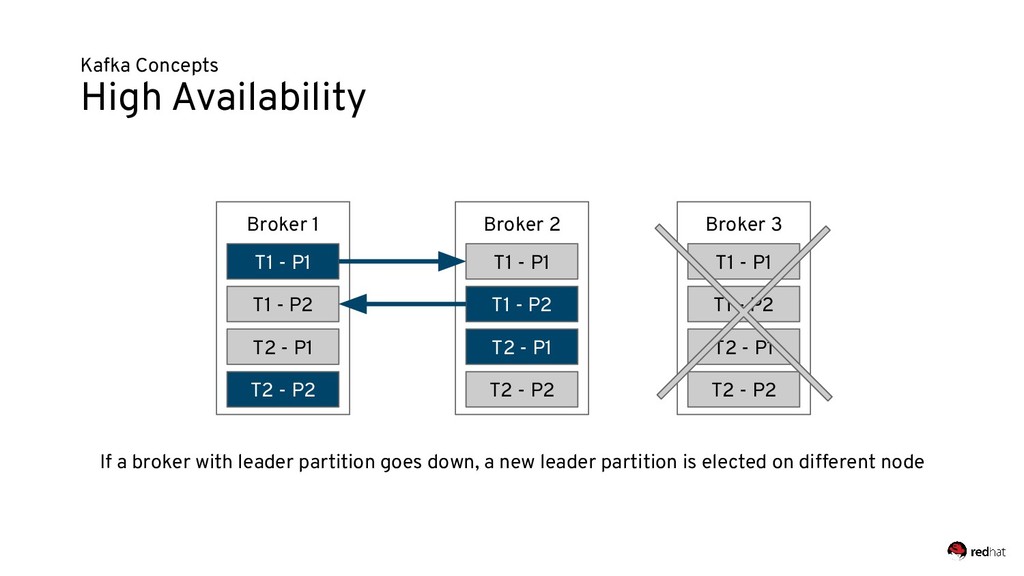
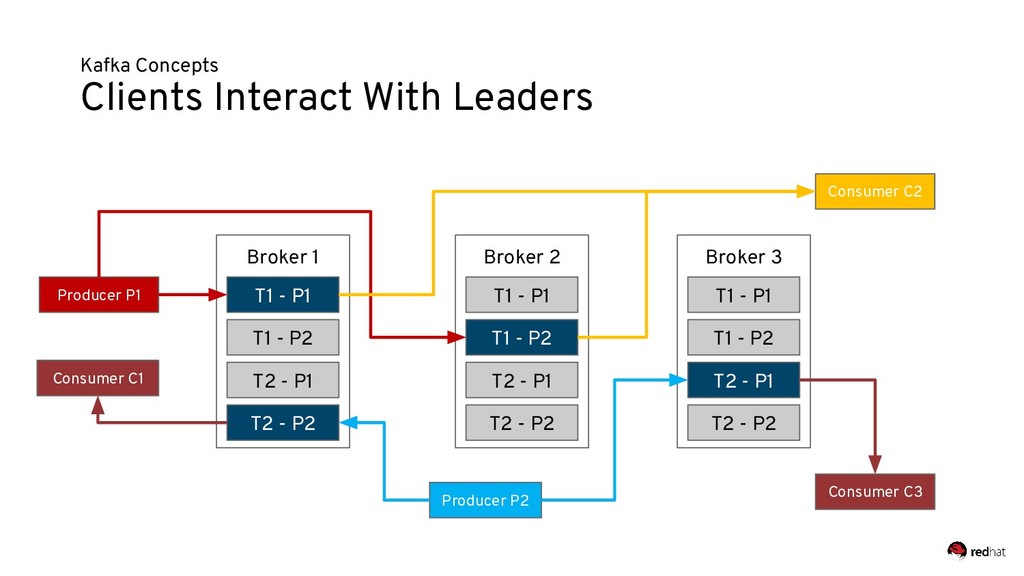
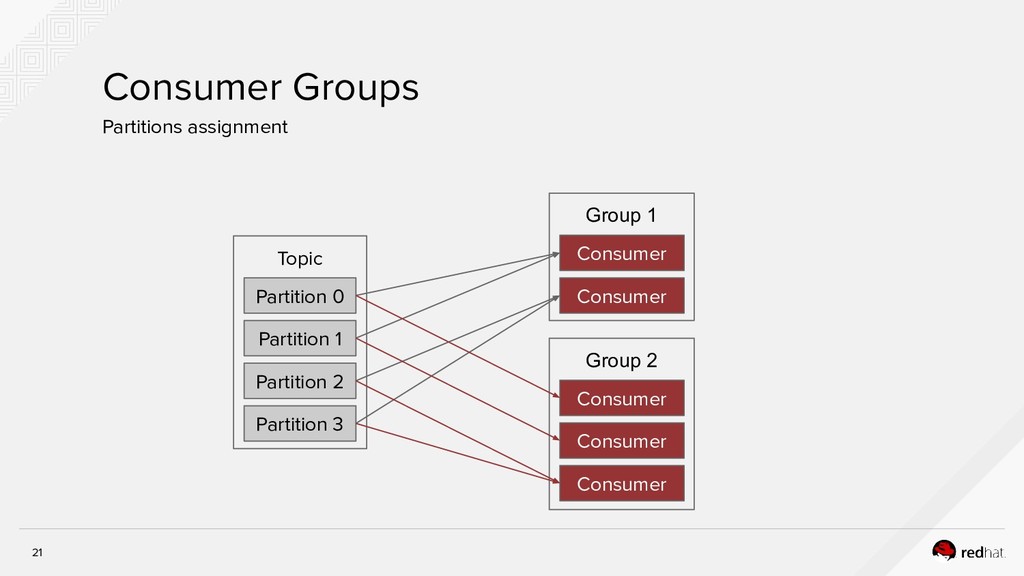
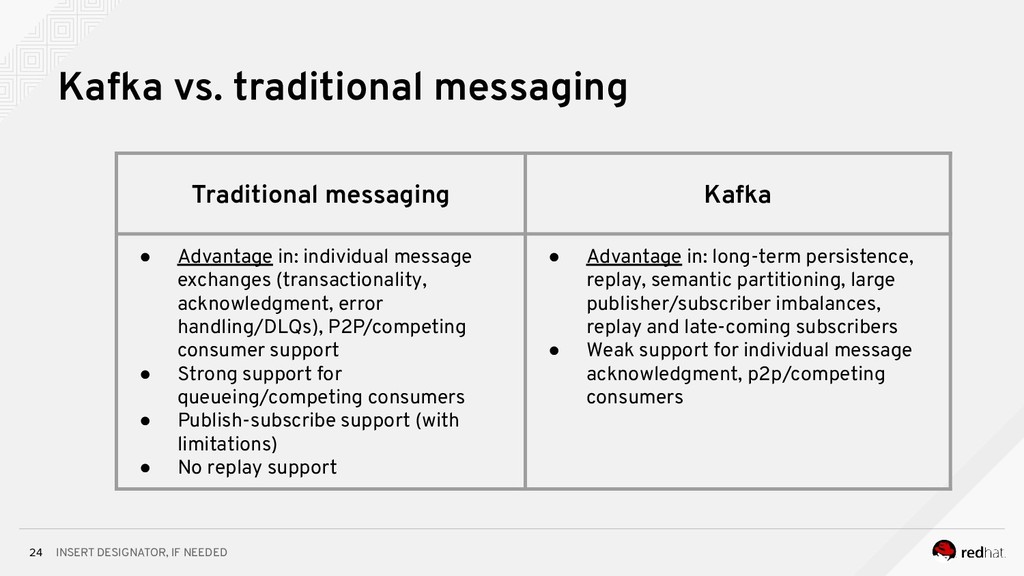
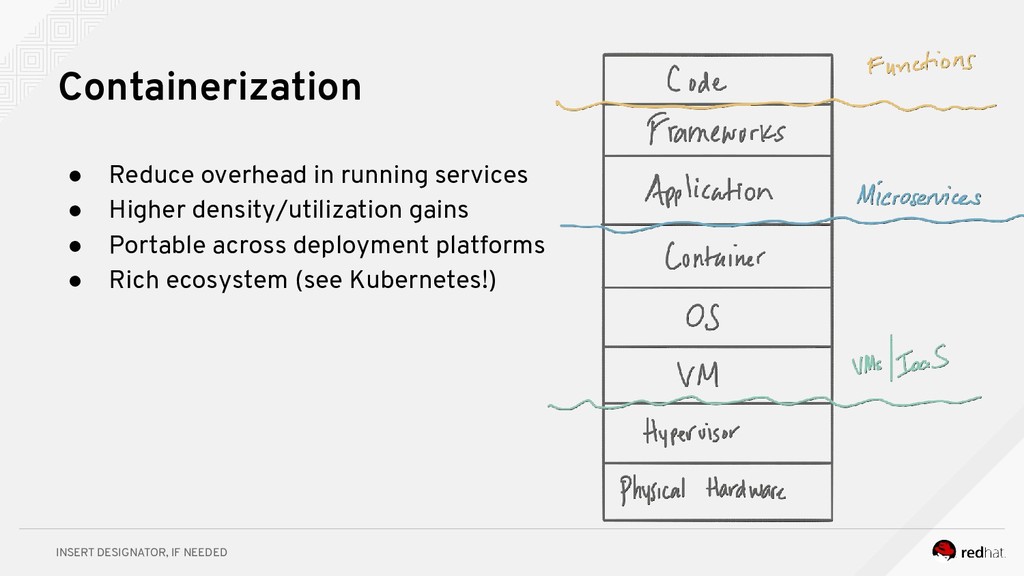
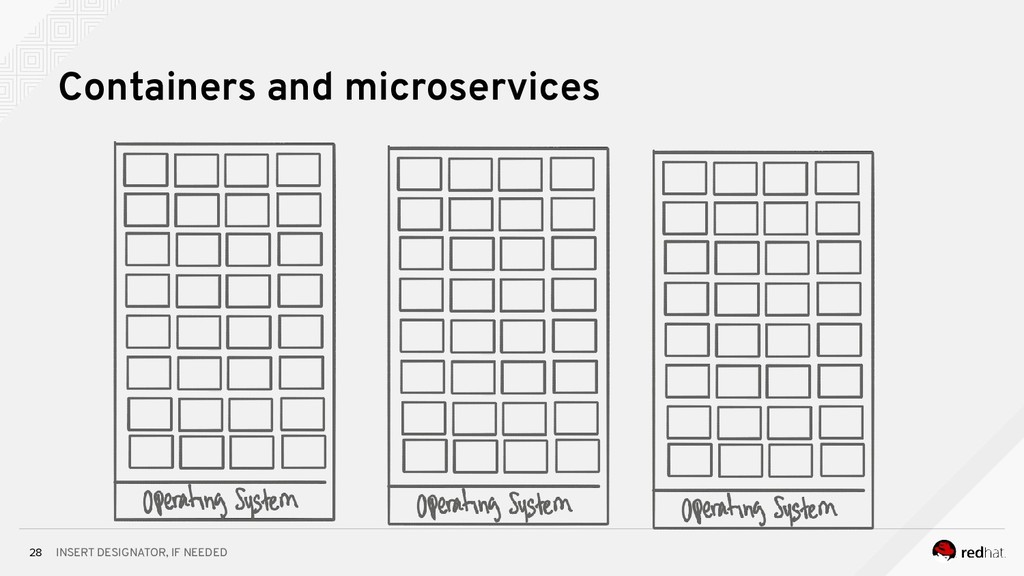
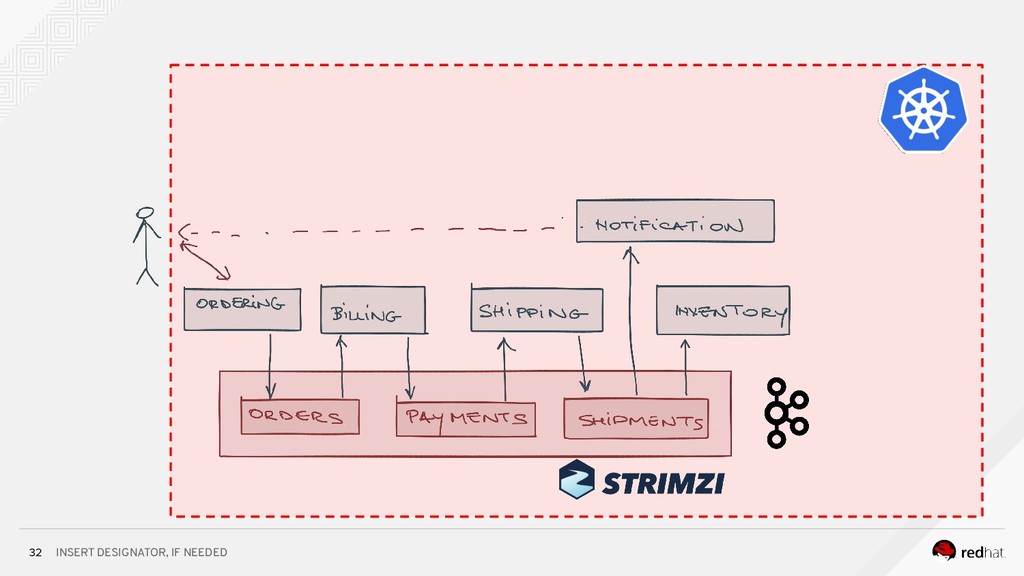
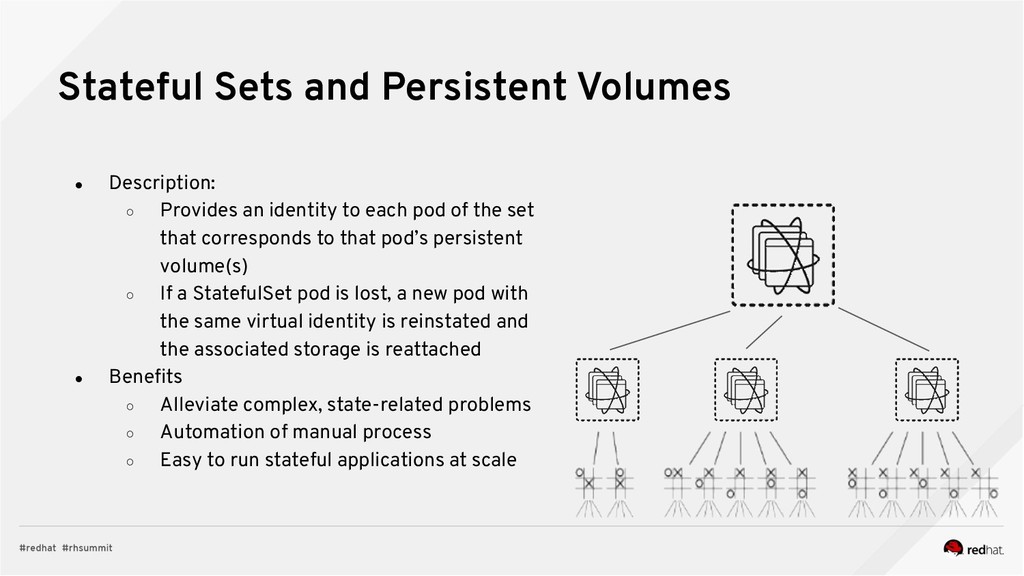
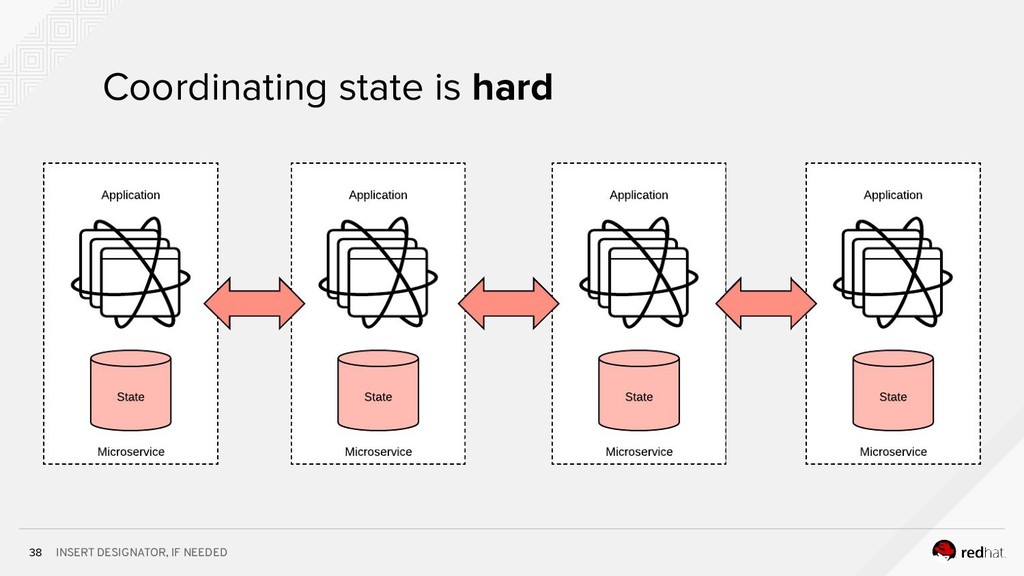
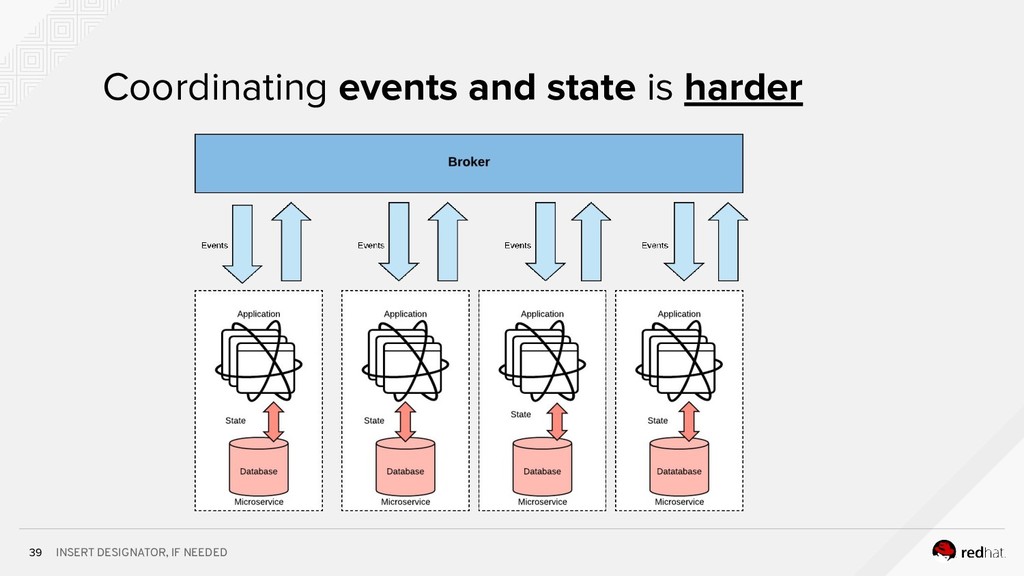
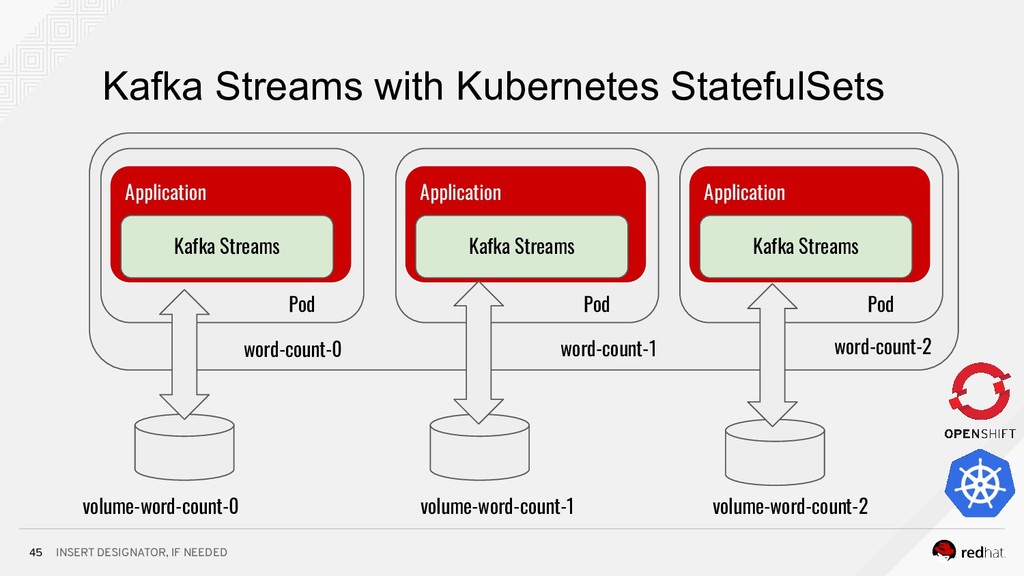
Event-centric design and event-driven architecture are powerful tools for designing scalable distributed systems, capable of taking advantage of the agility and organizational efficiencies promised by microservices. In this presentation we will show you how to build such an architecture using Kafka and Kubernetes. To build such an architecture, you need a reliable and scalable messaging system (Kafka), a powerful programming model (Spring/Kafka Streams), and a platform where they all can run reliably and resiliently (Kubernetes.)
In this presentation, you will see a demo-centric introduction to how these technologies complement each other and deliver a cohesive solution:
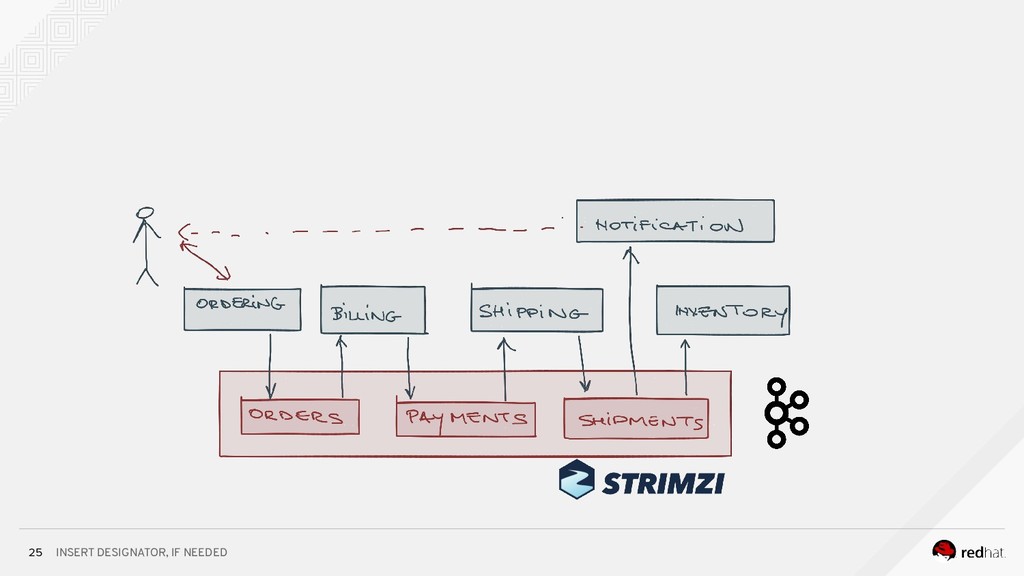
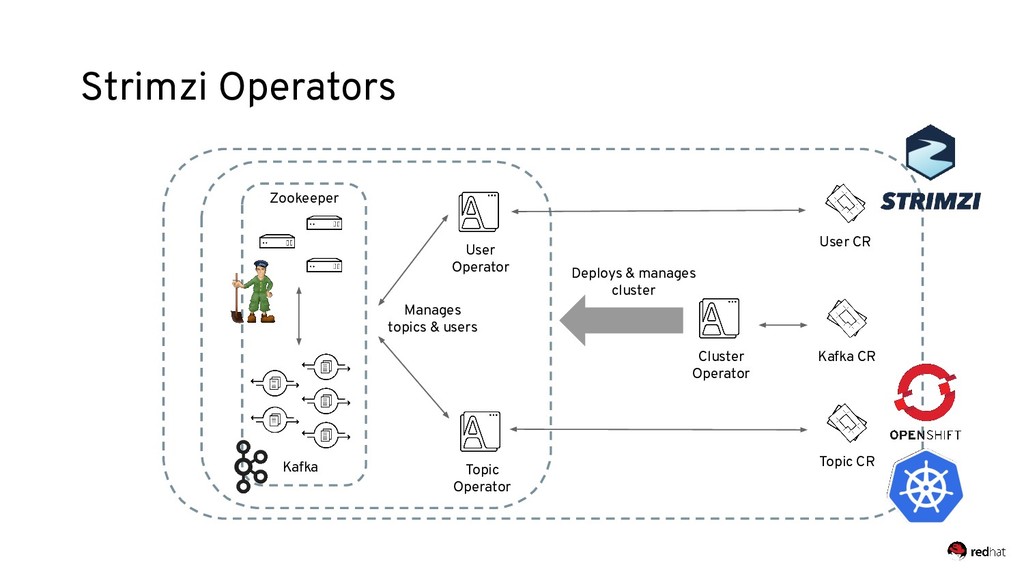
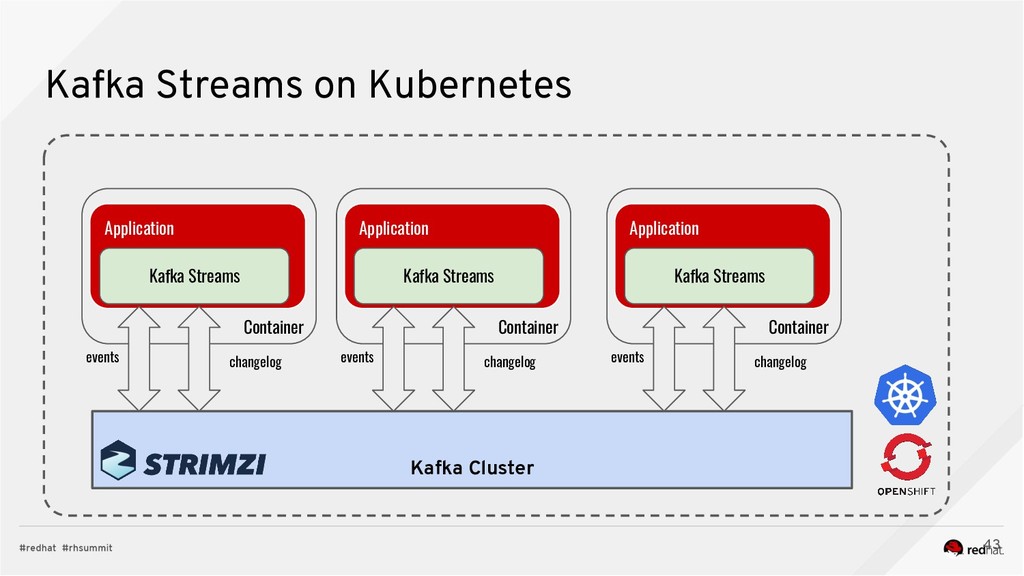
* how to run Kafka on Kubernetes using the Strimzi operator for Kafka;
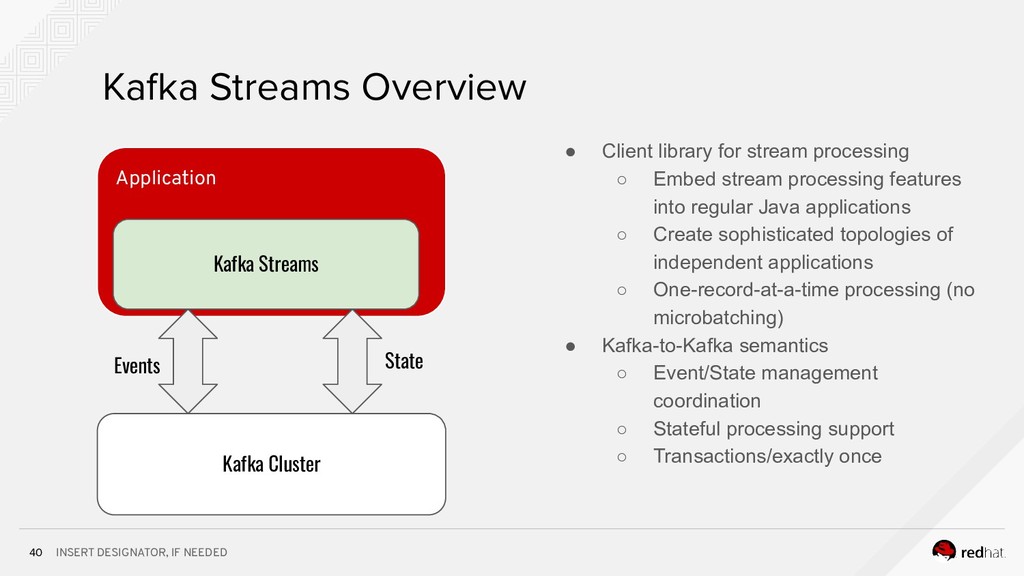
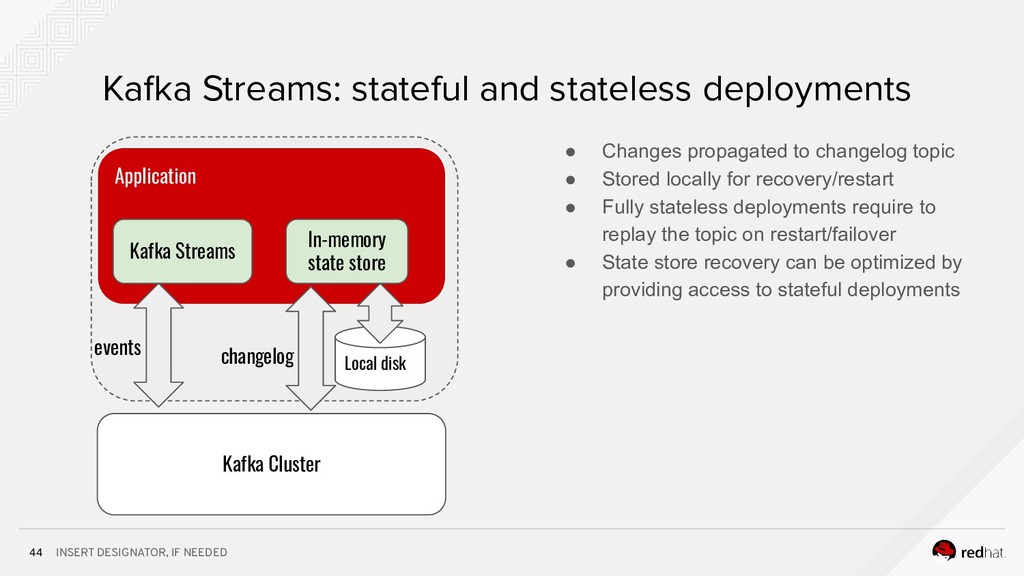
* how to build microservices using Spring and Kafka Streams;
* how to run bring them all together in complex data processing topologies on Kubernetes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}