Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
intro_paper_2.pdf
Search
MARUYAMA
March 29, 2017
87
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
intro_paper_2.pdf
MARUYAMA
March 29, 2017
More Decks by MARUYAMA
See All by MARUYAMA
vampire.pdf
tmaru0204
0
200
Misspelling_Oblivious_Word_Embedding.pdf
tmaru0204
0
210
Simple_Unsupervised_Summarization_by_Contextual_Matching.pdf
tmaru0204
0
200
Controlling_Text_Complexity_in_Neural_Machine_Translation.pdf
tmaru0204
0
180
20191028_literature-review.pdf
tmaru0204
0
160
Hint-Based_Training_for_Non-Autoregressive_Machine_Translation.pdf
tmaru0204
0
150
Soft_Contextual_Data_Augmentation_for_Neural_Machine_Translation_.pdf
tmaru0204
0
180
An_Embarrassingly_Simple_Approach_for_Transfer_Learning_from_Pretrained_Language_Models_.pdf
tmaru0204
0
170
Addressing_Trobulesome_Words_in_Neural_Machine_Translation.pdf
tmaru0204
0
180
Featured
See All Featured
My Coaching Mixtape
mlcsv
0
170
So, you think you're a good person
axbom
PRO
2
2.1k
It's Worth the Effort
3n
188
29k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
380
Chasing Engaging Ingredients in Design
codingconduct
0
240
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
420
Leo the Paperboy
mayatellez
8
1.9k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Technical Leadership for Architectural Decision Making
baasie
3
440
Transcript
Simple English Wikipedia: A New Text Simplification Task 丸山 拓海
William Coster and David Kauchak. In Proceedings of ACL 2011, pp. 665 – 669
1 Abstract ・English WikipediaとSimple English Wikipediaから 平易化のためのデータセットを構築 ・コーパスの分析 ・フレーズベース機械翻訳(Moses)による平易化 ・Moses-Oracle:
ベースラインよりBLEUが0.034改善可能 ・137,000文のデータセットを構築 ・Moses: ベースラインよりBLEUが0.005向上 (結果) 2
2 Introduction ・テキストの平易化 幅広い読者がテキストリソースを利用可能に テキストの内容を保持しつつ、文の難しさを軽減する 機械翻訳や構文解析、要約の前処理に用いることで性能の向上 文を与えれば、語彙と文の構造がより単純な同等の文を生成する ・平易化の課題 データ数が少ない 3
2 Introduction ・English wikipediaとSimple English Wikipediaから データセットを生成 ・Simple English Wikipedia
子供や英語学習者を対象とし、平易な語彙と文法が用いられる 4
3 Simplification Corpus Generation ・段落のアライメントをとる ・タイトル ・ペアリング ・10,588記事(もとのEnglish Wikipedia 110K記事からの90%の減少)
・フィルタリング ・1行しか含まれていない記事のペアを削除 (スタブ、曖昧性回避のページ、Wikipediaに関するメタページ) (simpleが複数のnormalに割り当てられる場合もある) ・記事で利用可能な書式設定情報に基づいて段落を識別 ・simpleにおいてTF-IDF, コサイン類似度が閾値または 0.5を超えたnormalに対応付け 5
3 Simplification Corpus Generation ・段落ペアから文のペアを生成 (Barzilay and Elhadad, 2003) 動的計画法を用いて文アライメントを取る
(, ): 番目のnormal文と番目のsimple文との類似度 (TF-IDF、コサイン類似度) _ = 0.0001 6
4 Corpus Analysis ・137,000文から無作為に100文選び、 2人に正しく対応付けされているかを評価 91/100が正しいと判定(残り9文も部分的に一致) ・27%はsimpleとnormalの間で同じ文 ・類似度が0.75を超える文のみを使用して再び評価 98/100が正しいと判定 137,000文から90,000文に減少
・10,588記事のペアから137,000文のペアを抽出 全ての文を平易化する必要はない 7
4 Corpus Analysis ・ simpleの段落の65%は対応付けされていない ・アライメントが取れていない文が多い Table1 データセット生成時の文レベルのアライメント操作 ※データセットにおいて2対2のアライメントは存在しない 8
4 Corpus Analysis ・ normal文がどのようにsimple文に変換されるか GIZA++ を使って解析 Table2 文ペアにおける単語レベルの操作 rewordings
: normal単語が別のsimple単語に変換 deletions : normal単語を削除 reorders : 並び替え merges : 複数のnormal単語が一つのsimple単語に結合 splits : normal単語が複数のsimple単語に分割 9
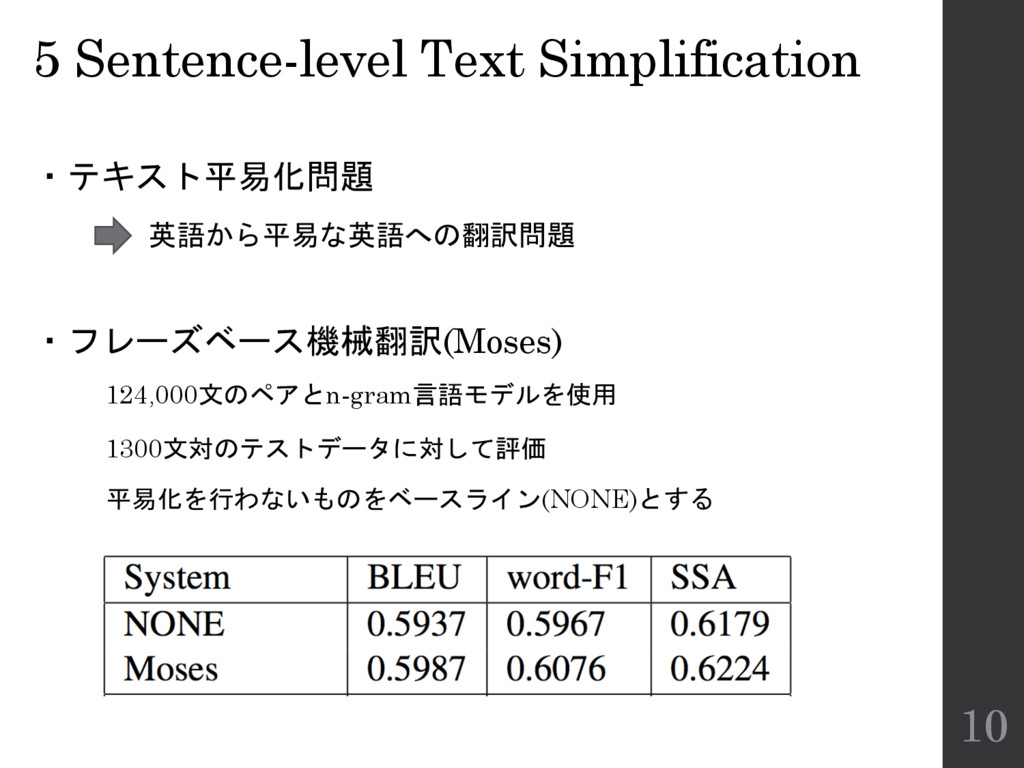
5 Sentence-level Text Simplification ・テキスト平易化問題 英語から平易な英語への翻訳問題 ・フレーズベース機械翻訳(Moses) 124,000文のペアとn-gram言語モデルを使用 1300文対のテストデータに対して評価 平易化を行わないものをベースライン(NONE)とする
10
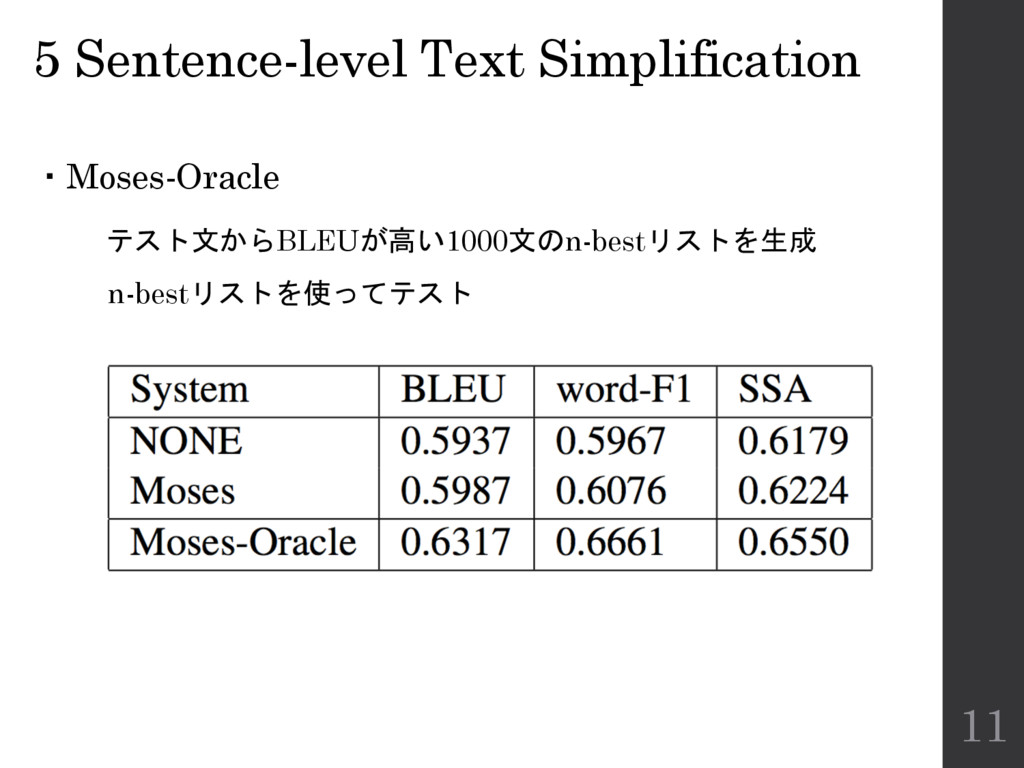
5 Sentence-level Text Simplification ・Moses-Oracle テスト文からBLEUが高い1000文のn-bestリストを生成 n-bestリストを使ってテスト 11
6 Conclusion ・Moses-Oracle: ベースラインよりBLEUが0.034改善可能 ・Moses: ベースラインよりBLEUが0.005向上 ・English WikipediaとSimple English Wikipediaから
137,000文のデータセットを構築 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}