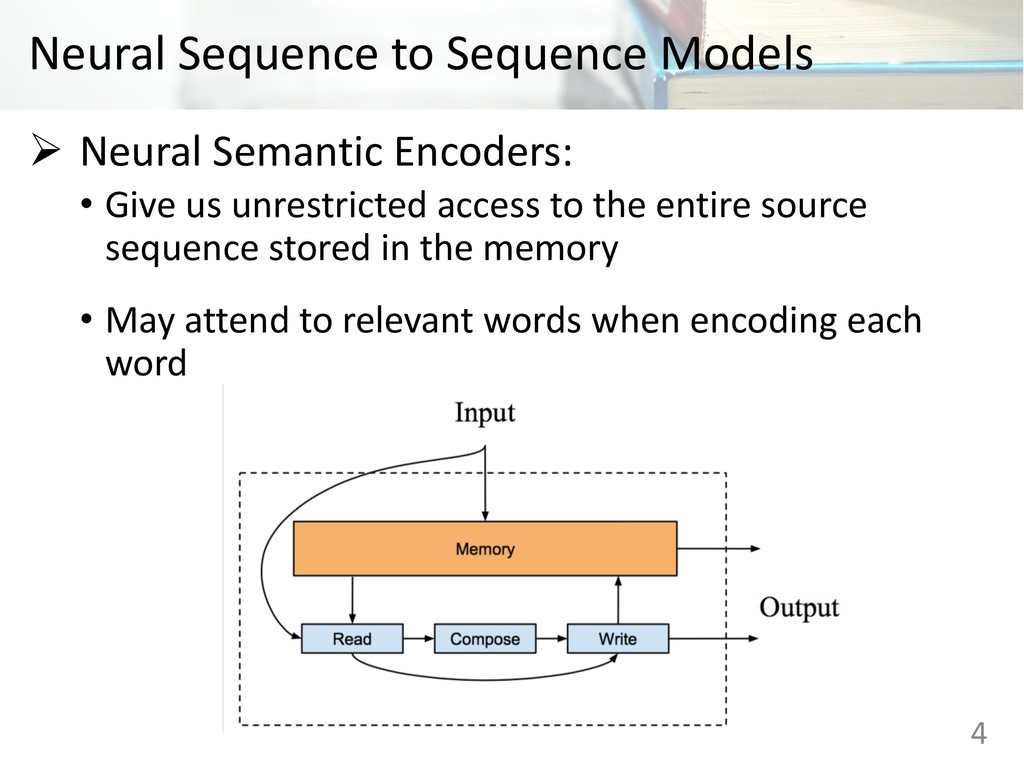
structure of complex sentences Ø This paper adapts an architecture with Neural Semantic Encoders for sentence simplification Ø Experiments demonstrate the effectiveness of proposed approach on different simplification datasets 2
by Newsela editor Ø Wikismall: Aligned complex-simple sentence pairs from English Wikipedia (EW) and Simple English Wikipedia Ø Wikilarge: A mixture of three Wikipedia datasets 5
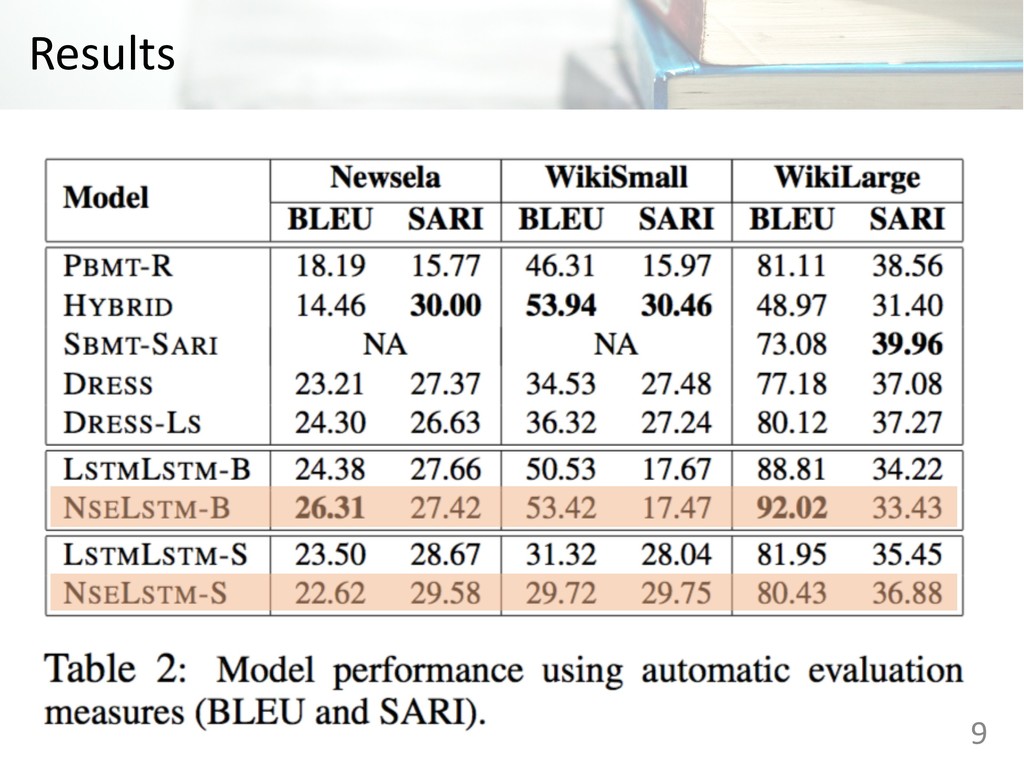
sequence models • LSTMLSTM: The encoder is implemented by LSTM • NSELSTM: The encoder is implemented by NSE Ø Models were tuned on the development sets, either with BLEU (-B) or SARI (-S) Dataset Train Dev. Test Newsela 94,208 1,129 1,077 Wikismall 88,837 205 100 Wikilarge 296,402 2,000 359 6
Ø HYBRID: A hybrid semantic-based model that combines a simplification model and a monolingual MT model Ø SBMT-SARI: A SBMT model with simplification-specific components Ø DRESS: A deep reinforcement learning model Ø DRESS-LS: A combination of DRESS and a lexical simplification 7
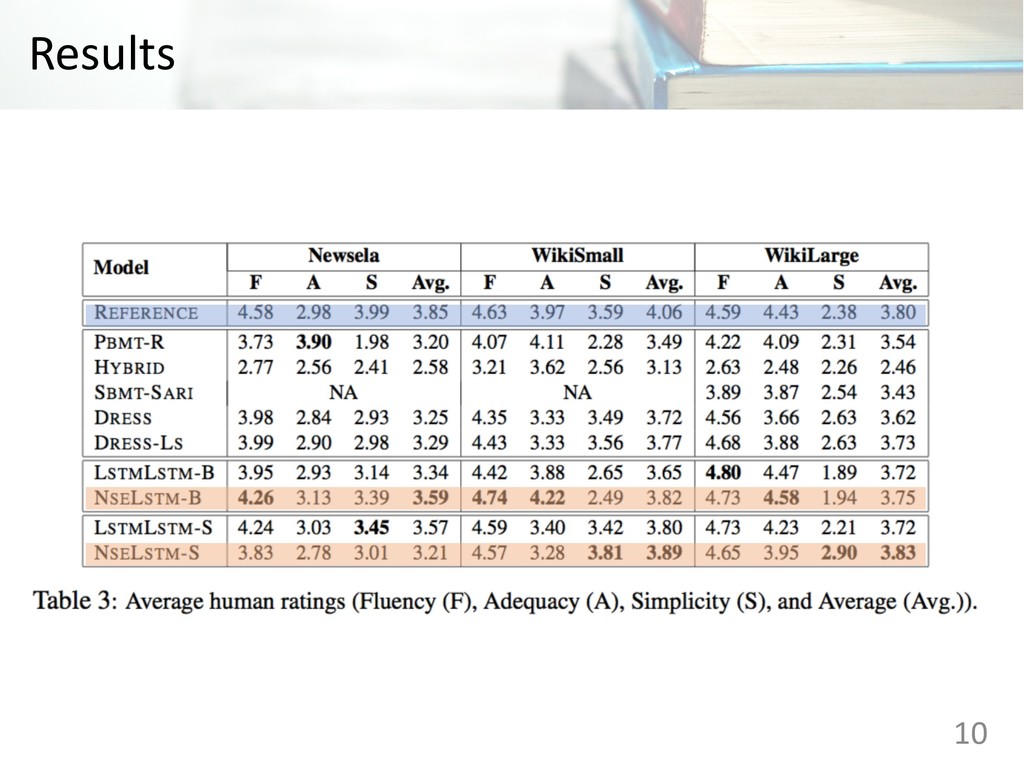
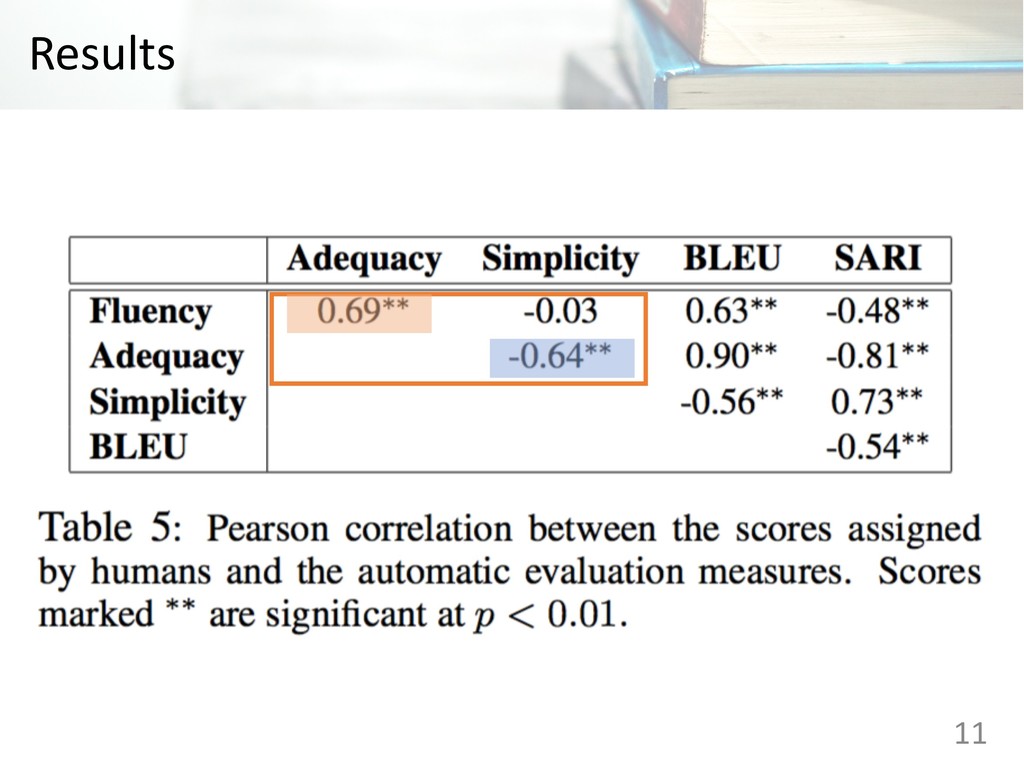
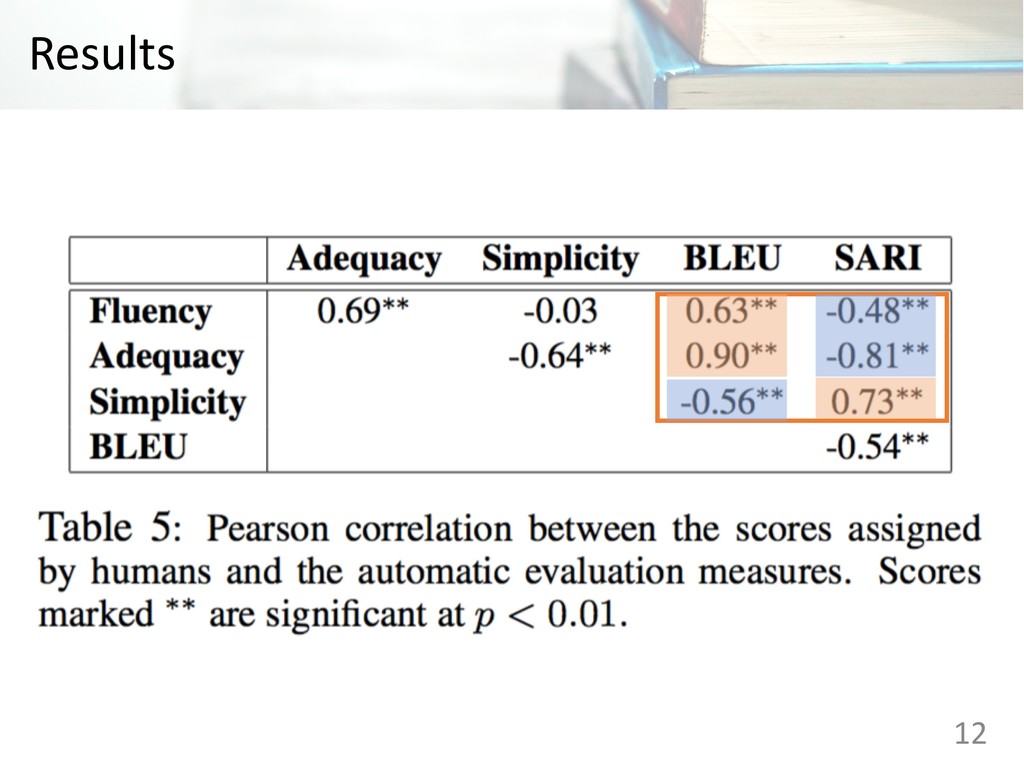
Judgments (five point Likert scale) • Fluency: The extent to which the output is grammatical English • Adequacy: The extent to which the output has the same meaning as the input sentence • Simplicity: The extent to which the output is simpler than the input sentence 8
Encoders for sentence simplification Ø The proposed model is capable of reducing the reading difficulty of the input, while performing well in terms of grammaticality and meaning preservation 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}