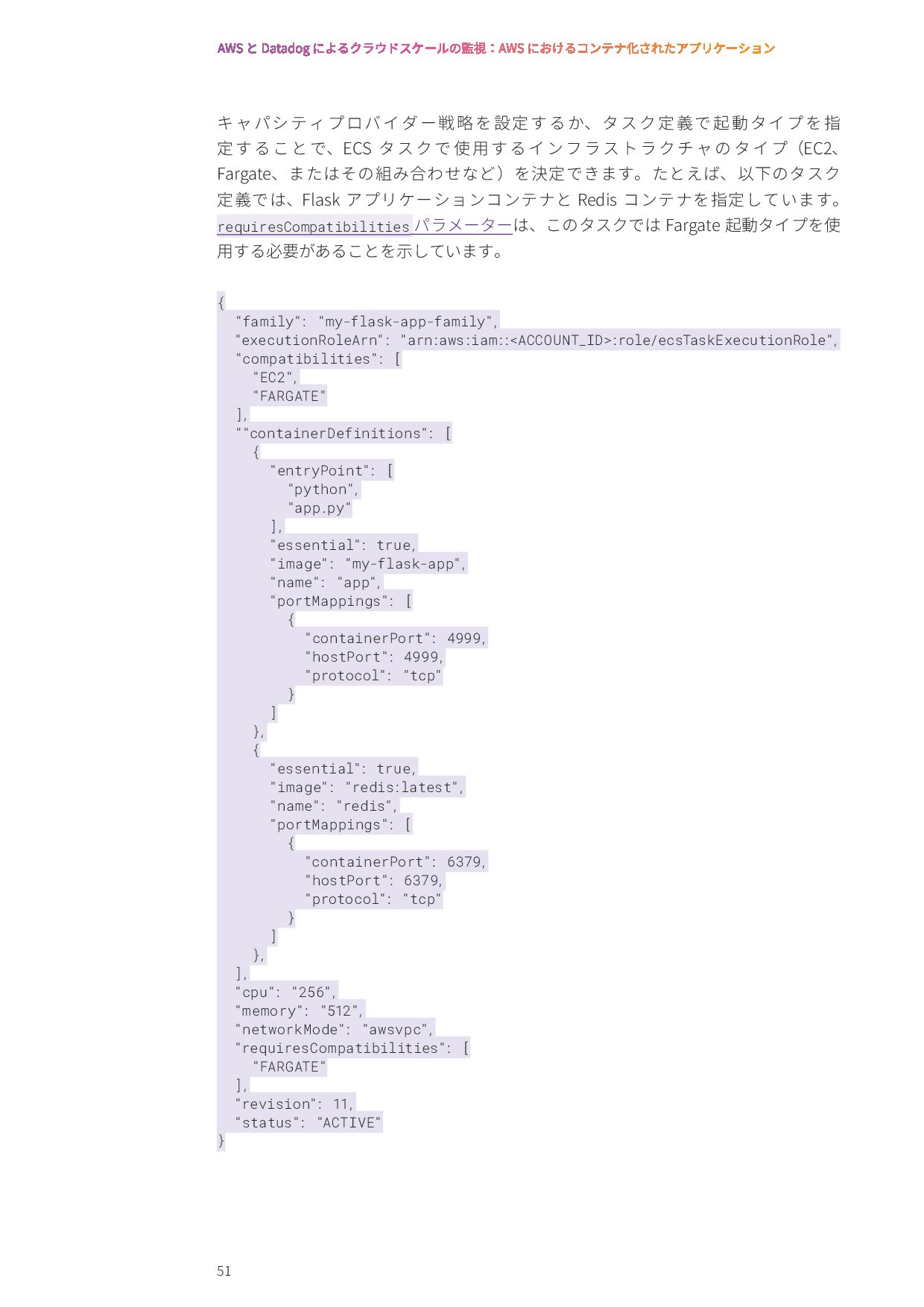
パラメーターは、このタスクでは Fargate 起動タイプを使 用する必要があることを示しています。 { ″family″: ″my-flask-app-family″, ″executionRoleArn″: ″arn:aws:iam::<ACCOUNT_ID>:role/ecsTaskExecutionRole″, ″compatibilities″: [ ″EC2″, ″FARGATE″ ], ″″containerDefinitions″: [ { ″entryPoint″: [ ″python″, ″app.py″ ], ″essential″: true, ″image″: ″my-flask-app″, ″name″: ″app″, ″portMappings″: [ { ″containerPort″: 4999, ″hostPort″: 4999, ″protocol″: ″tcp″ } ] }, { ″essential″: true, ″image″: ″redis:latest″, ″name″: ″redis″, ″portMappings″: [ { ″containerPort″: 6379, ″hostPort″: 6379, ″protocol″: ″tcp″ } ] }, ], ″cpu″: ″256″, ″memory″: ″512″, ″networkMode″: ″awsvpc″, ″requiresCompatibilities″: [ ″FARGATE″ ], ″revision″: 11, ″status″: ″ACTIVE″ }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
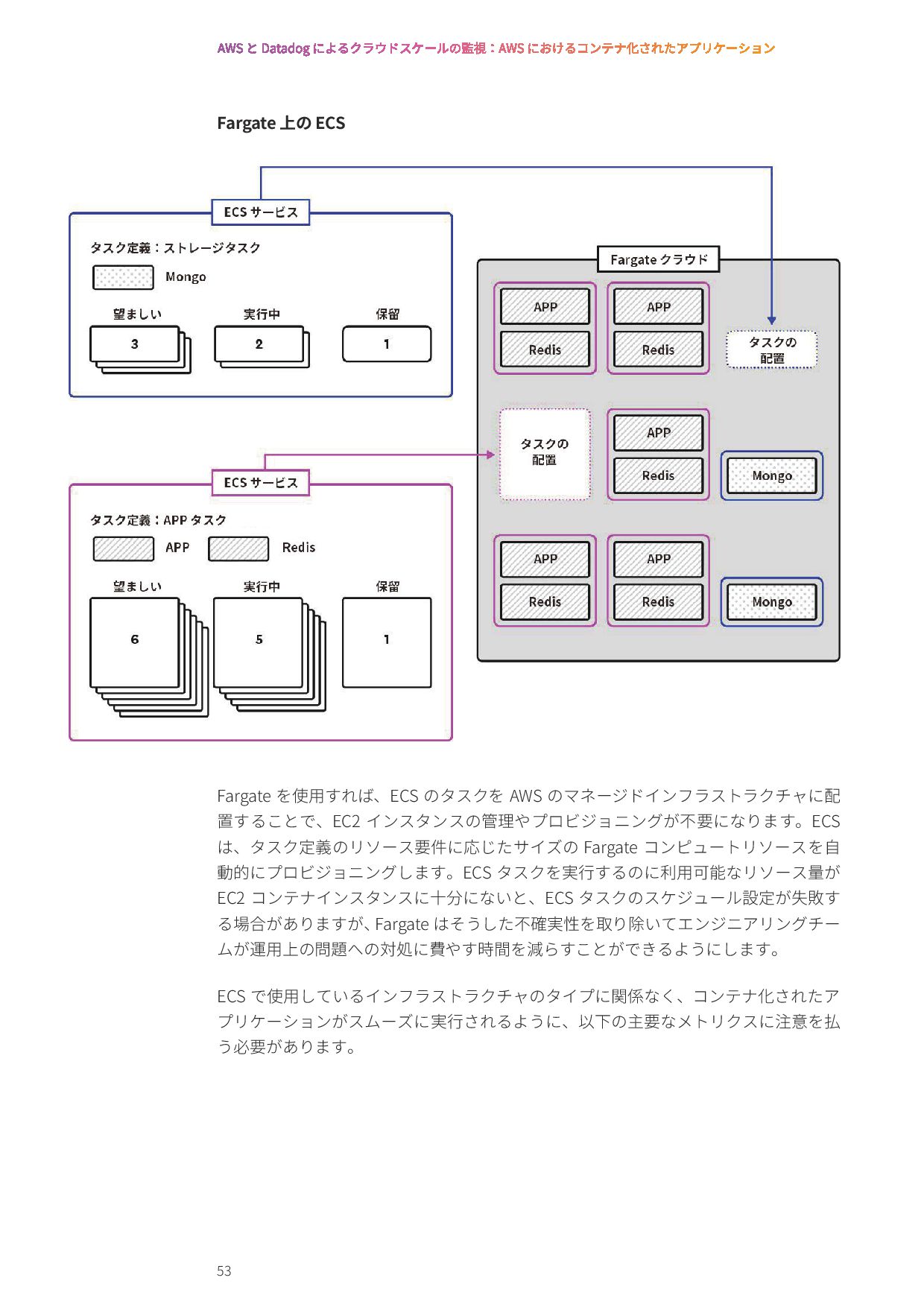{kind=link}
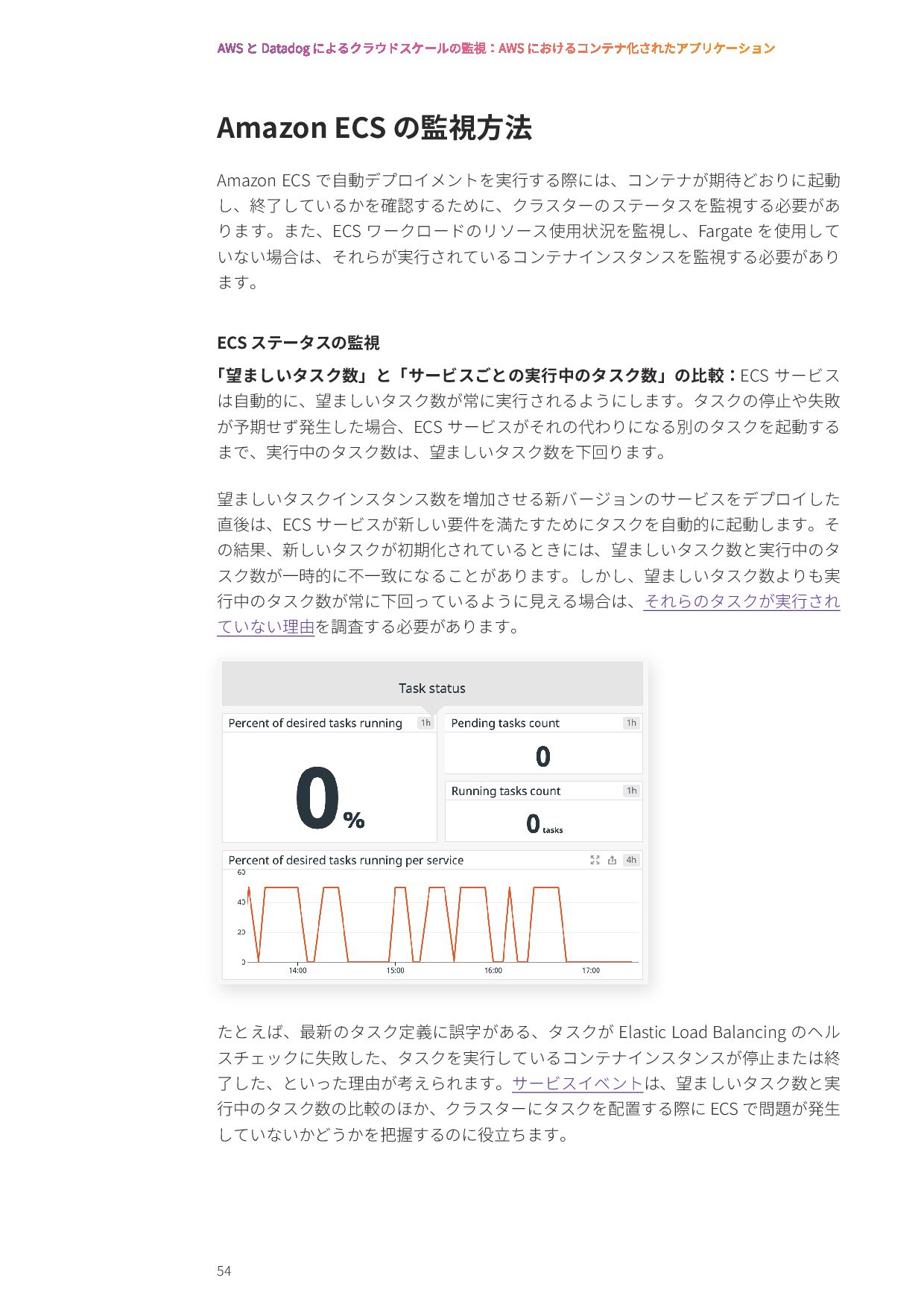{kind=link}
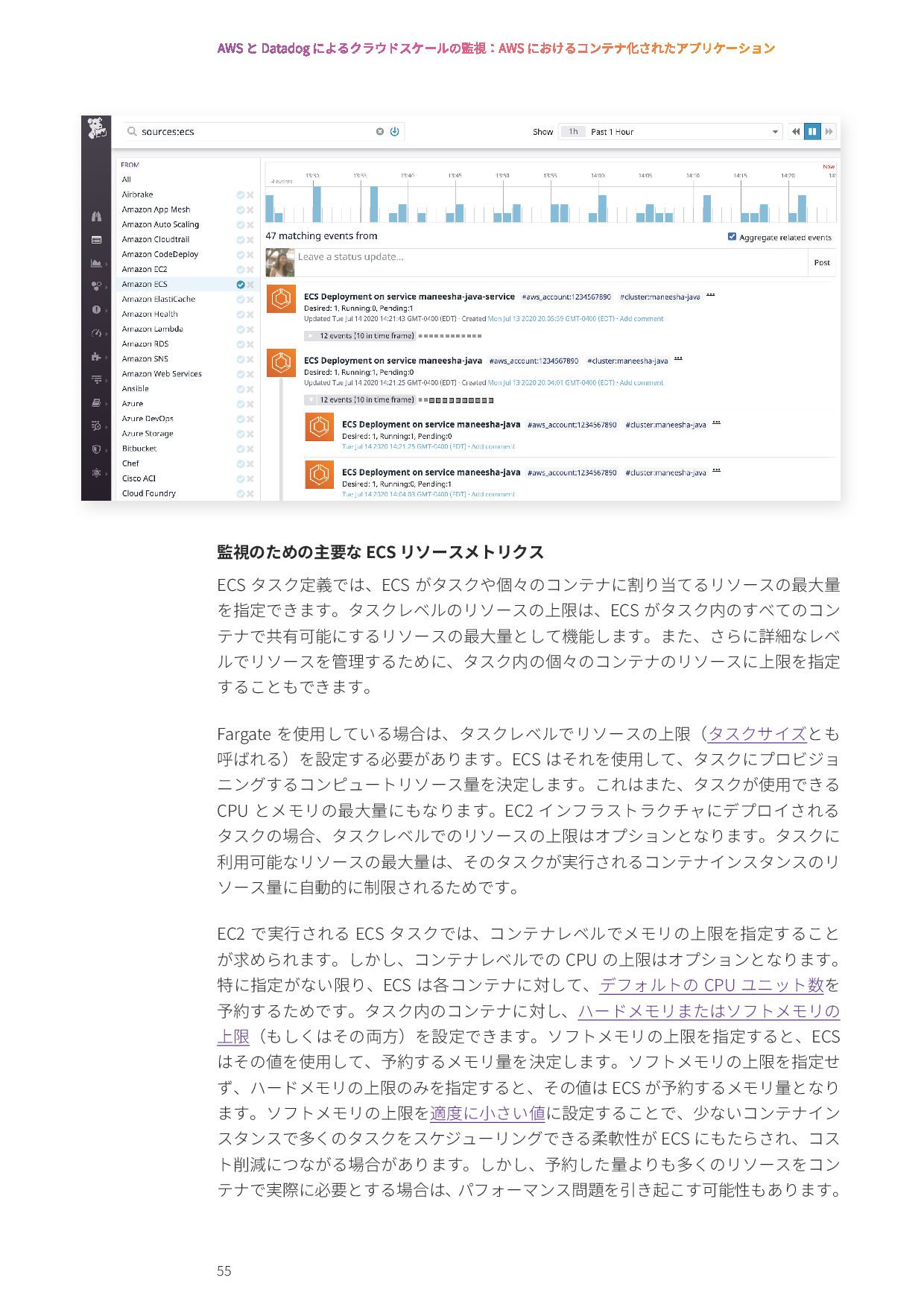{kind=link}
{kind=link}
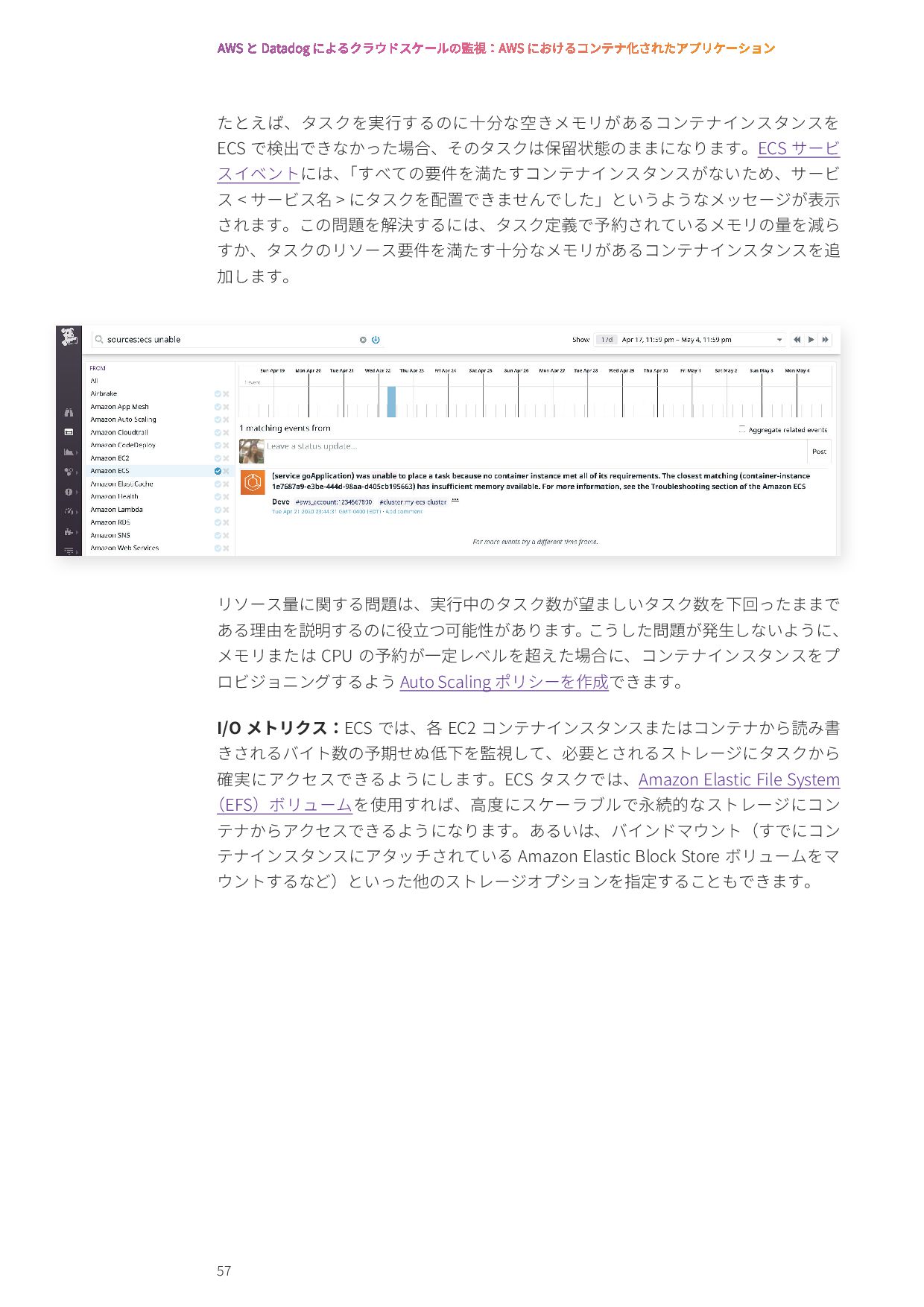{kind=link}
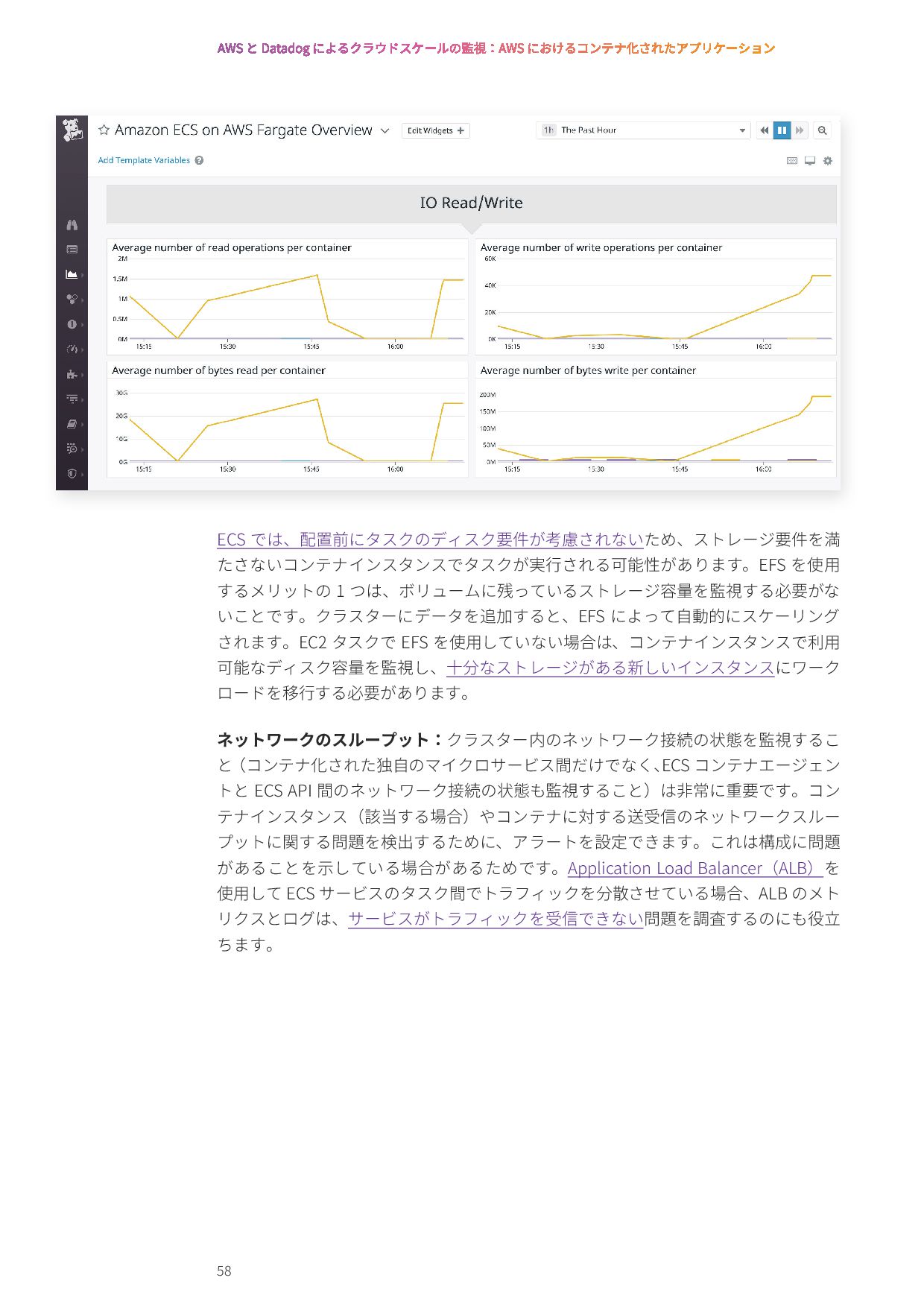{kind=link}
{kind=link}
{kind=link}
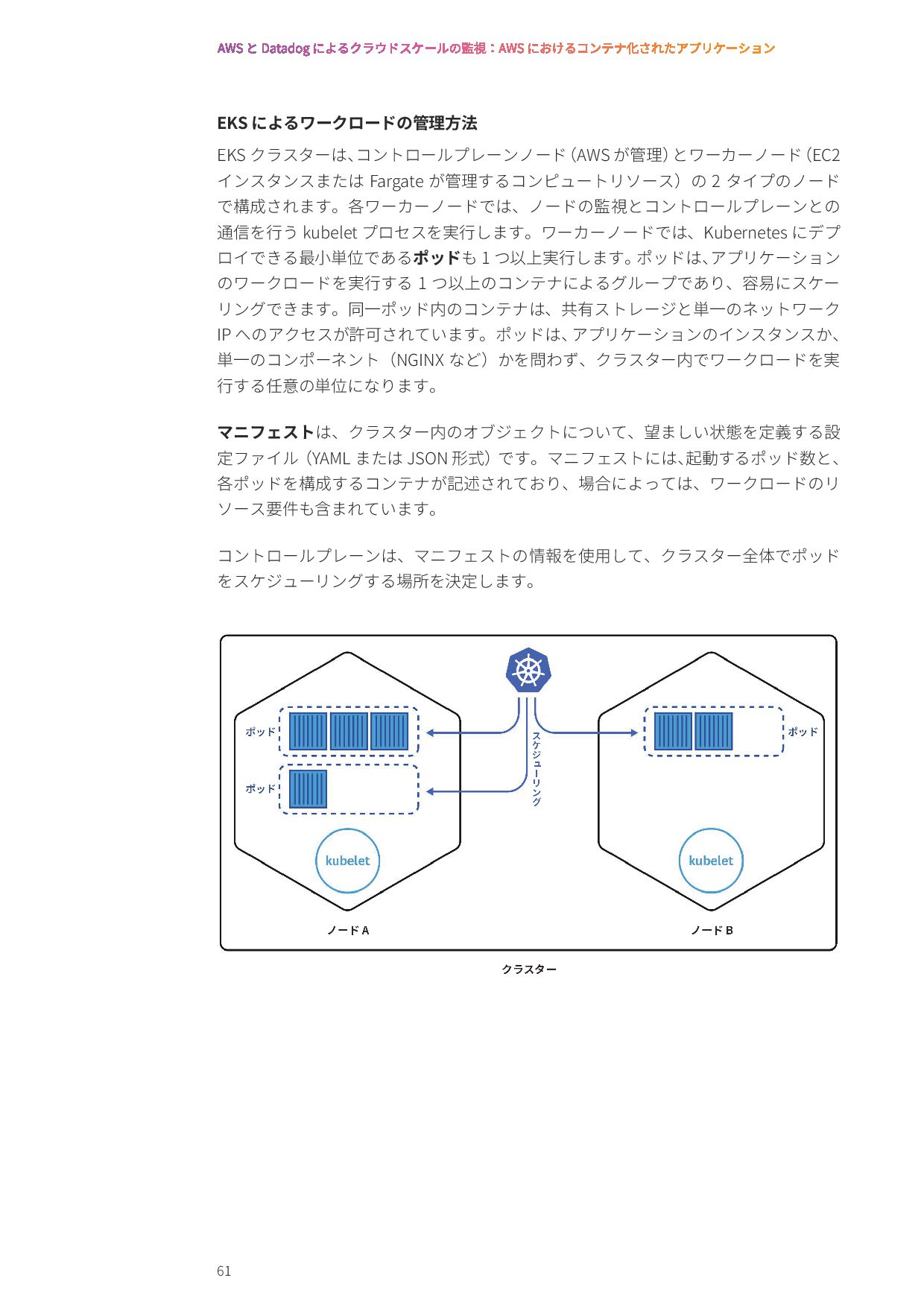{kind=link}
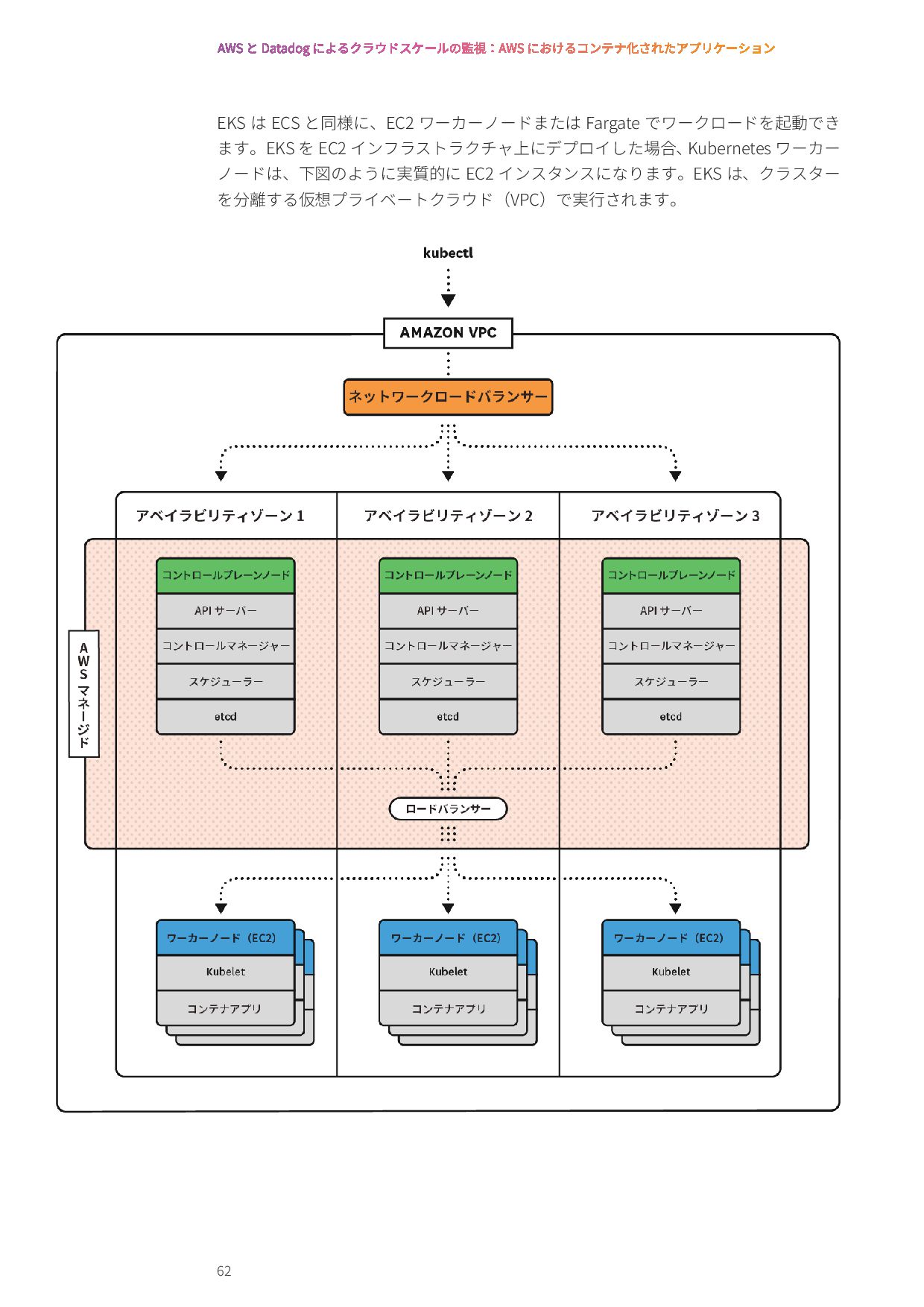{kind=link}
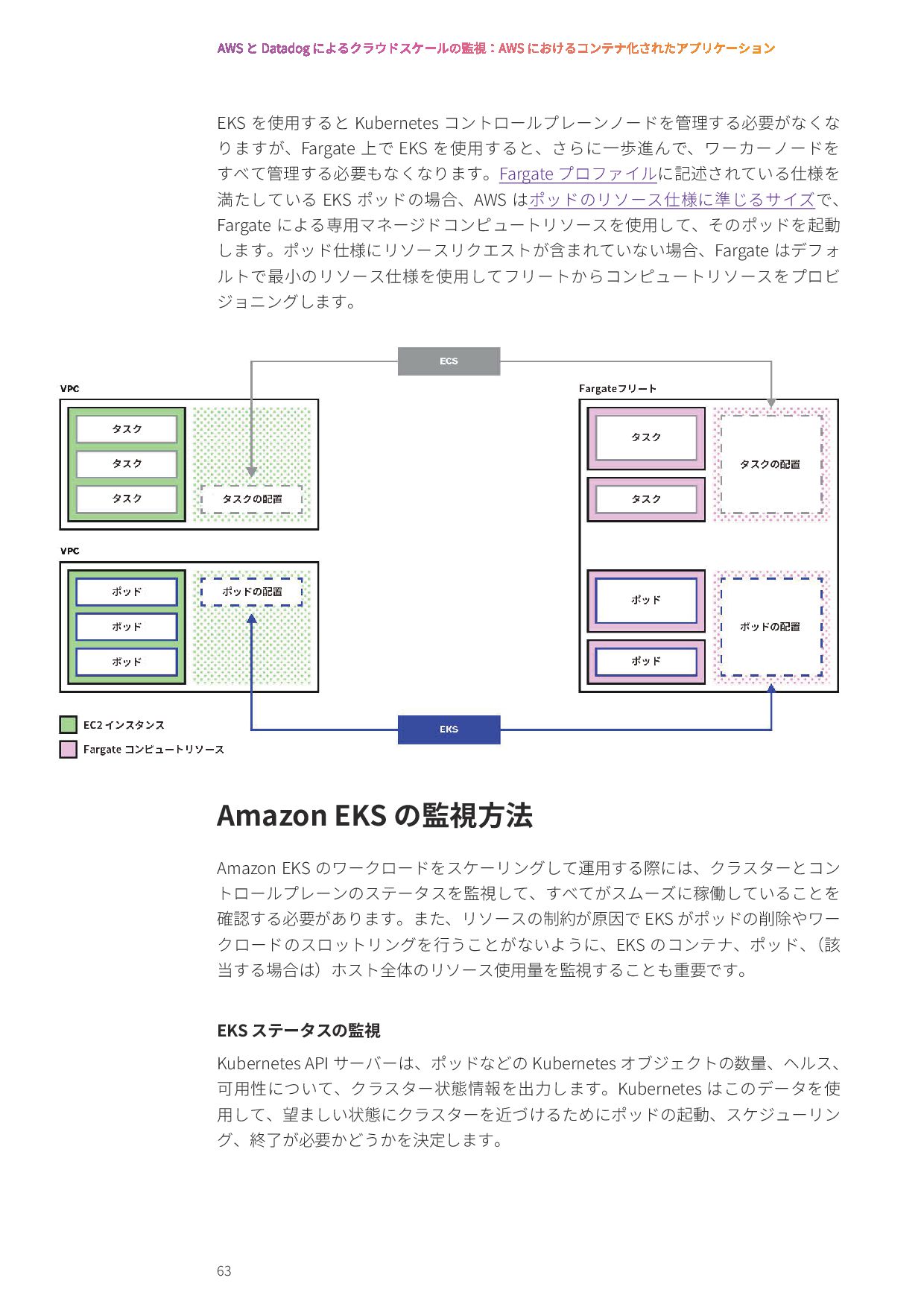{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
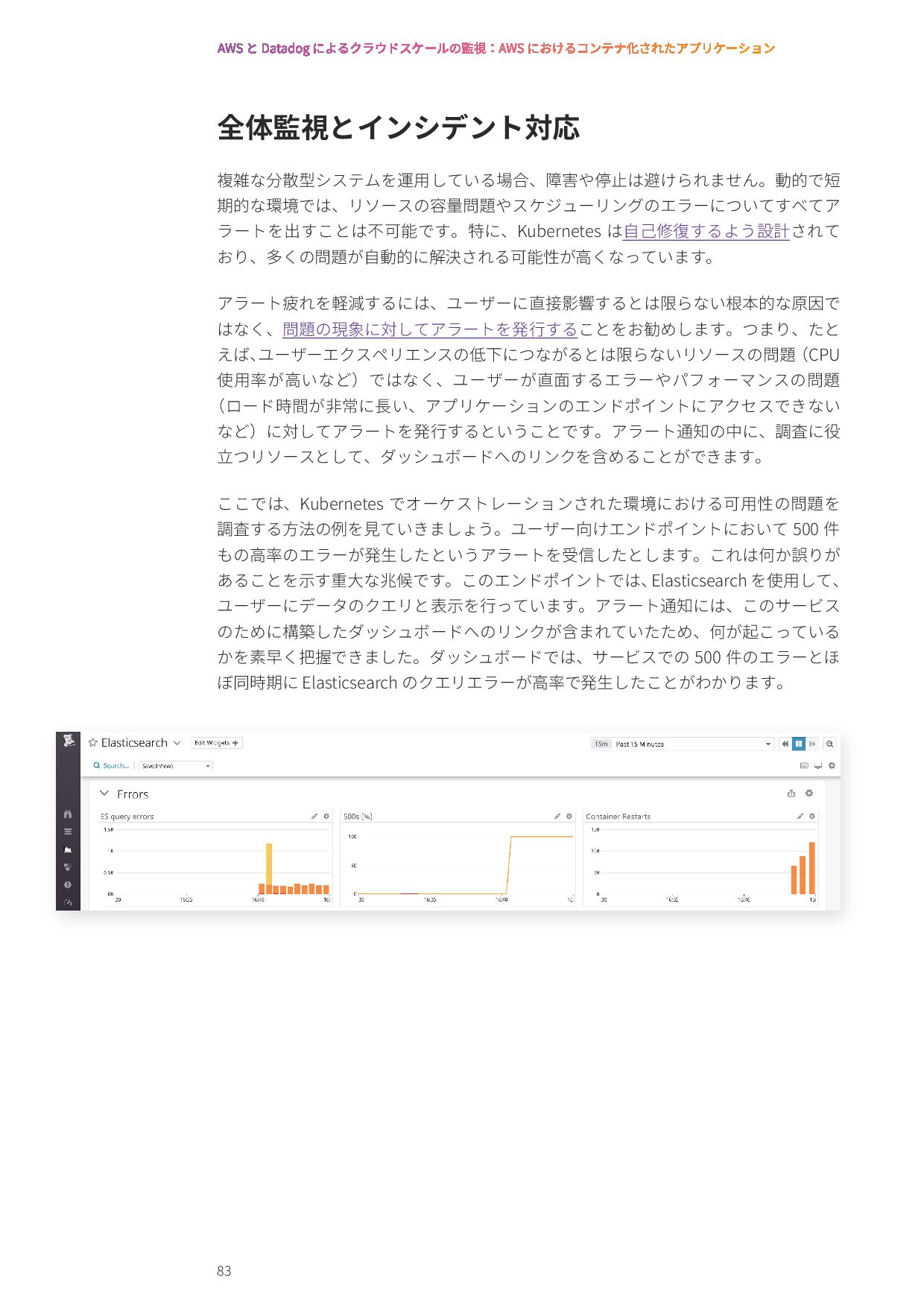{kind=link}
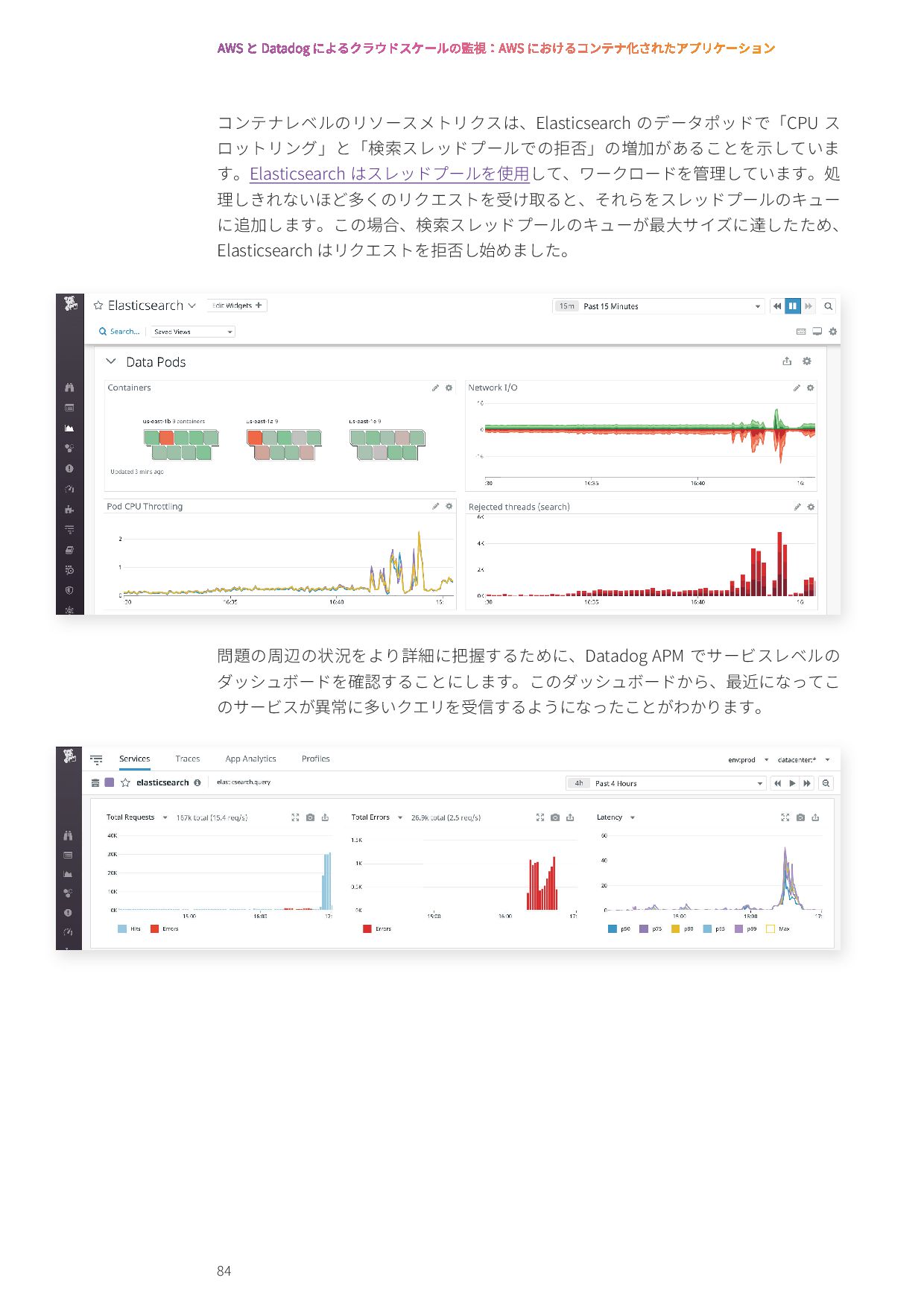{kind=link}
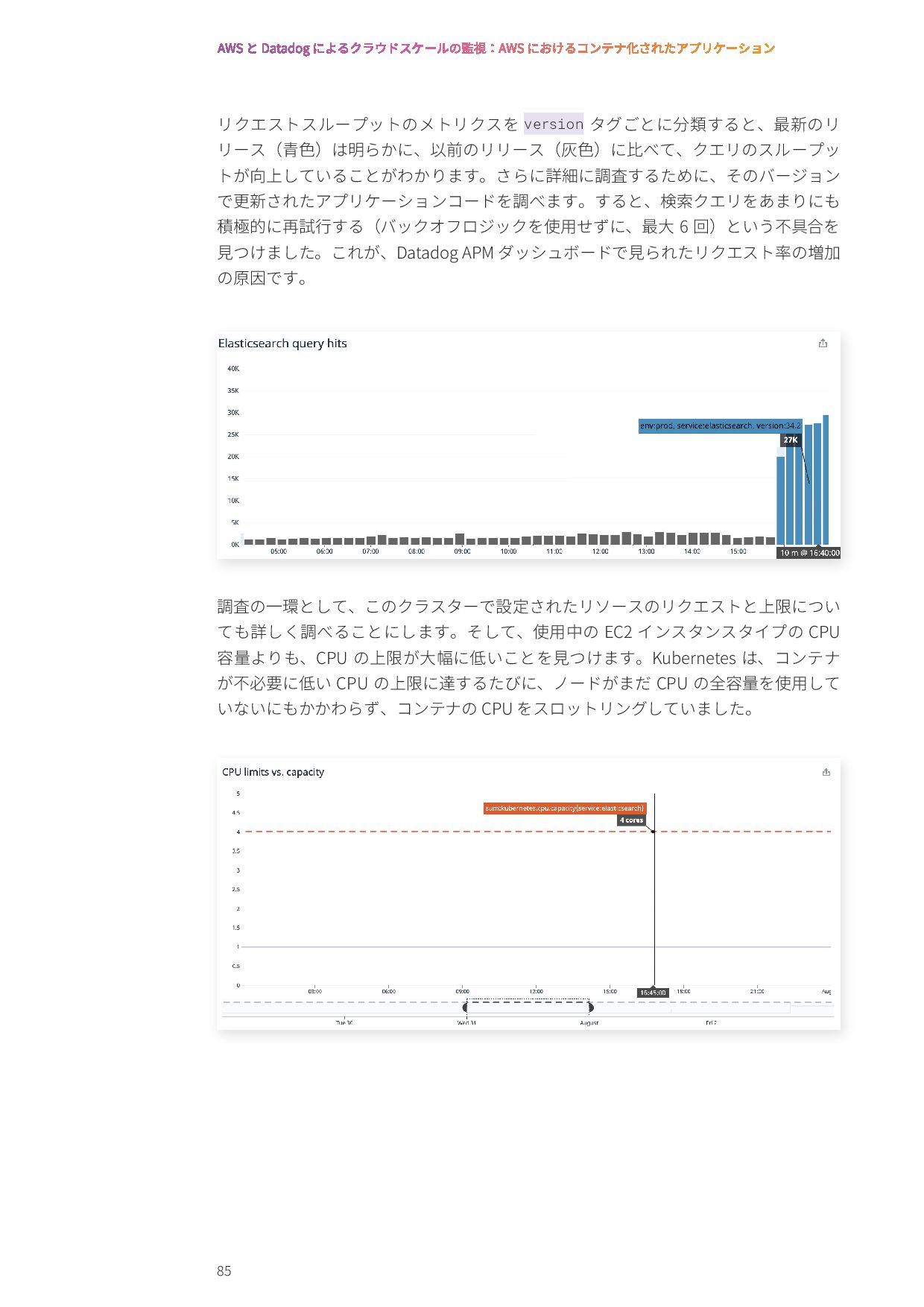{kind=link}
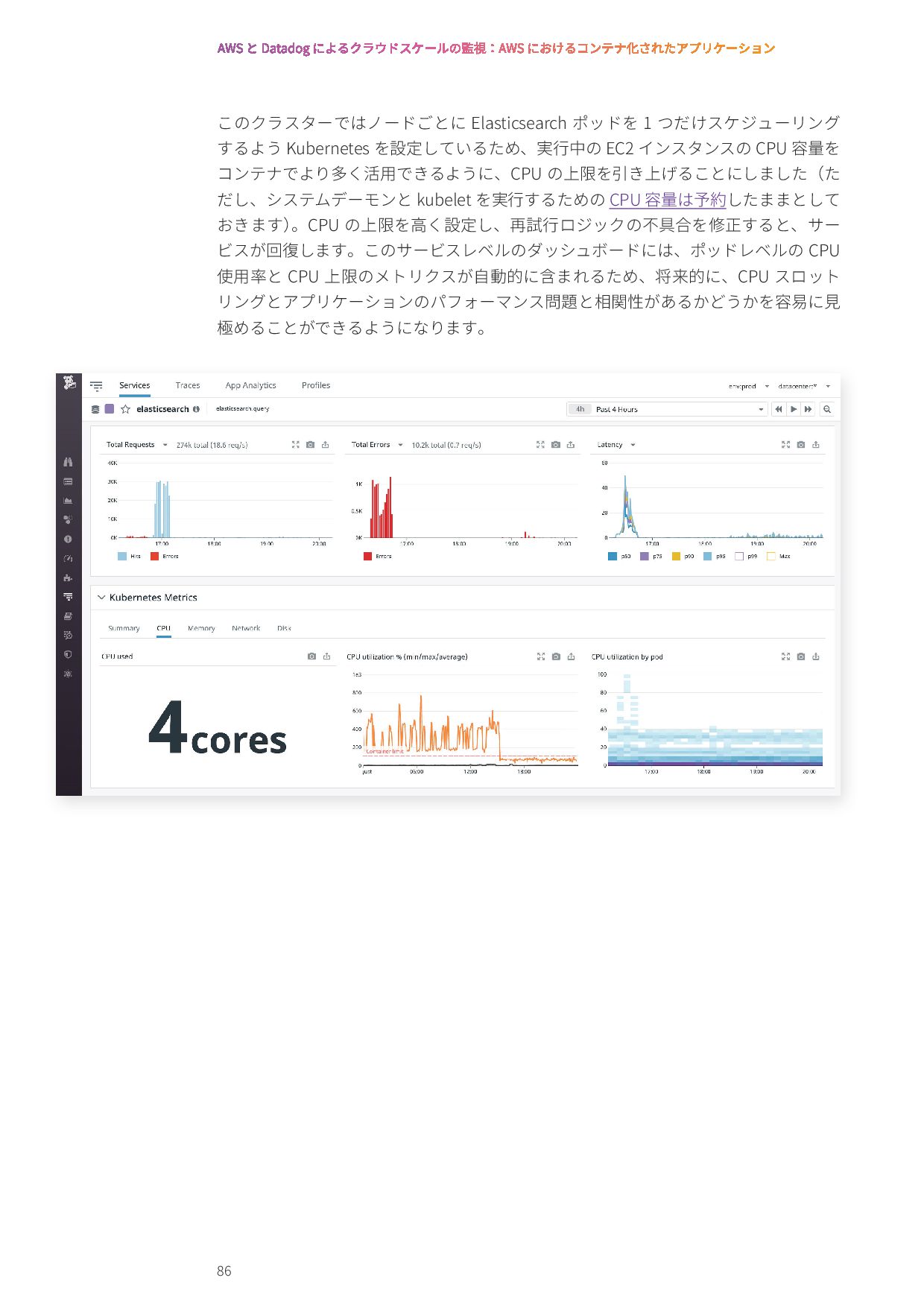{kind=link}
{kind=link}
{kind=link}