The final summary presentation of the project details for "Design of Distributed Software Applications".
Lots of challenges and fun in this course. According to RescueTime (https://goo.gl/keiw1p) I spent over 300 hours programming from January to April.
Code is at: https://github.com/tonglil/CPEN-431-2015.
{kind=link}
{kind=link}
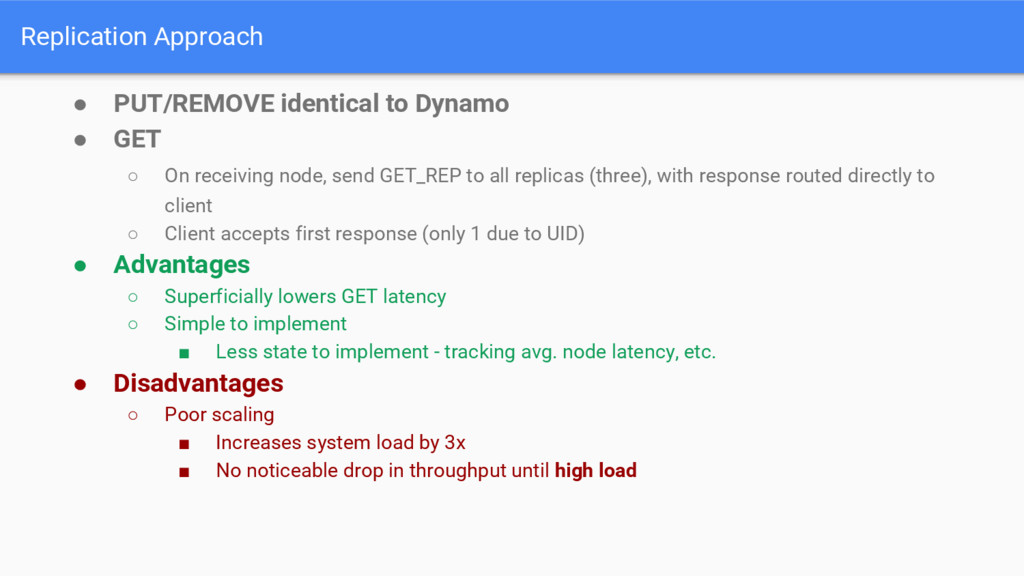{kind=link}
{kind=link}
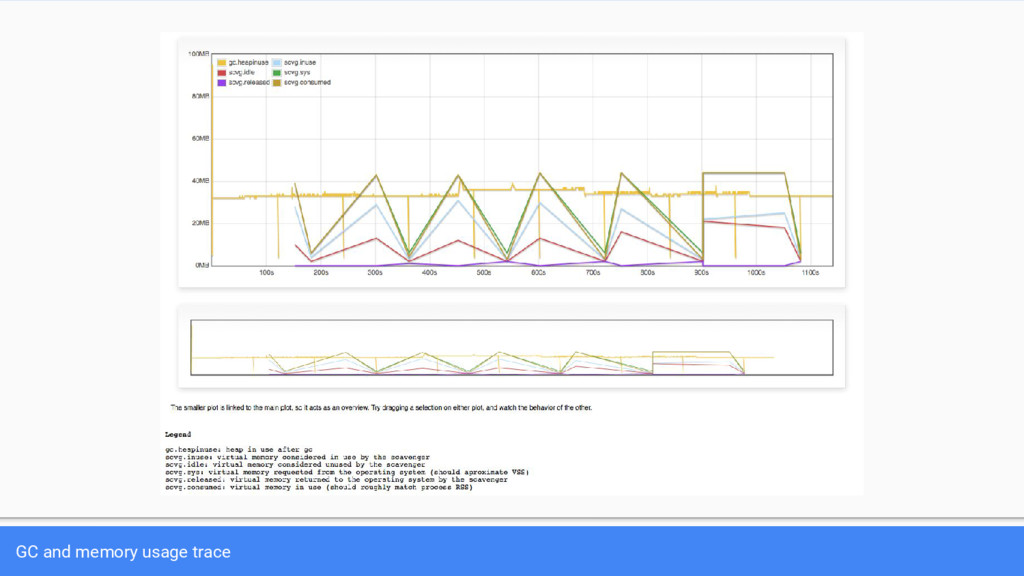{kind=link}
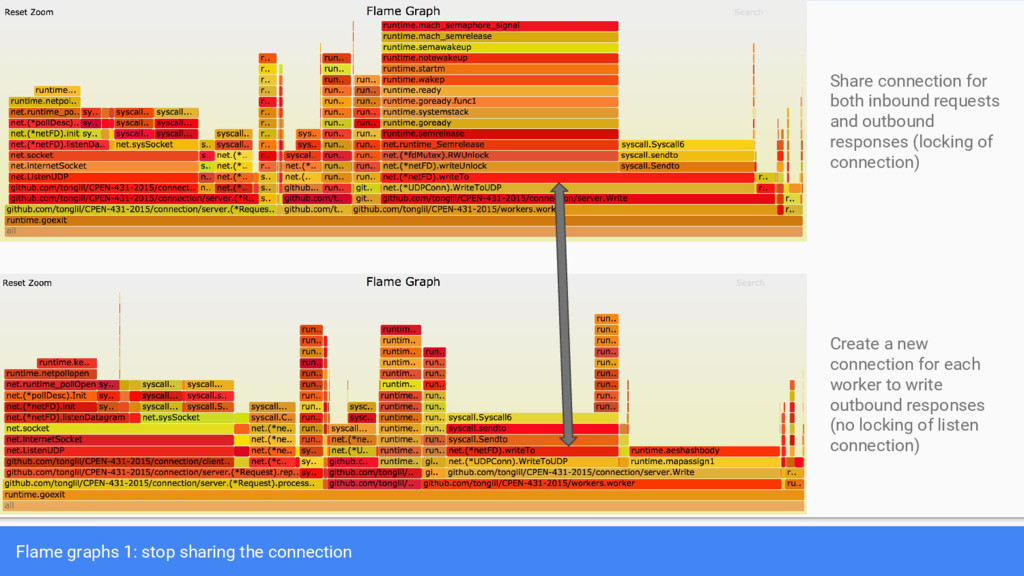{kind=link}
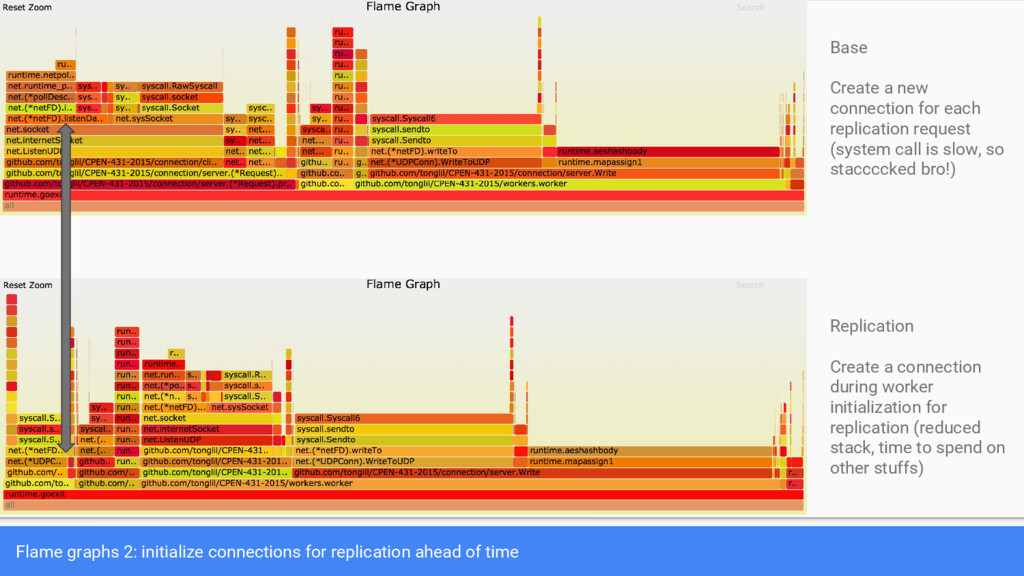{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}