Zhong, Danqi Chen NAACL 2021(North American Chapter of the Association for Computational Linguistics) URL: https://aclanthology.org/2021.naacl-main.5/ citations:53 What is this paper about? Paper contributions Key points Validate advantages and effectiveness Related work 1 Propose a simple and effective approach for named entity recognition and relation extraction ・ Learns two independent encoders ・ Insert typed entity markers in training relation model Outperforms all previous joint model on three datasets Wadden+: Entity, relation, and event extraction with contextualized span representations, EMNLP ‘19 ・ 8-16x speedup with a small accuracy drop
conll-2003 shared task: Language independent named entity recognition, CoNLL ‘03 [02] Ratinov+: Design challenges and misconceptions in named entity recognition, CoNLL ‘09 [03] Zelenko+: Kernel methods for relation extraction, EMNLP ‘02 [04] Bunescu+: A shortest path dependency kernel for relation extraction, EMNLP '05 Named Entity Recognition[01],[02] Relation Extraction[03], [04] 3 Input morpa is a fully implemented parser for a text-to-speech system
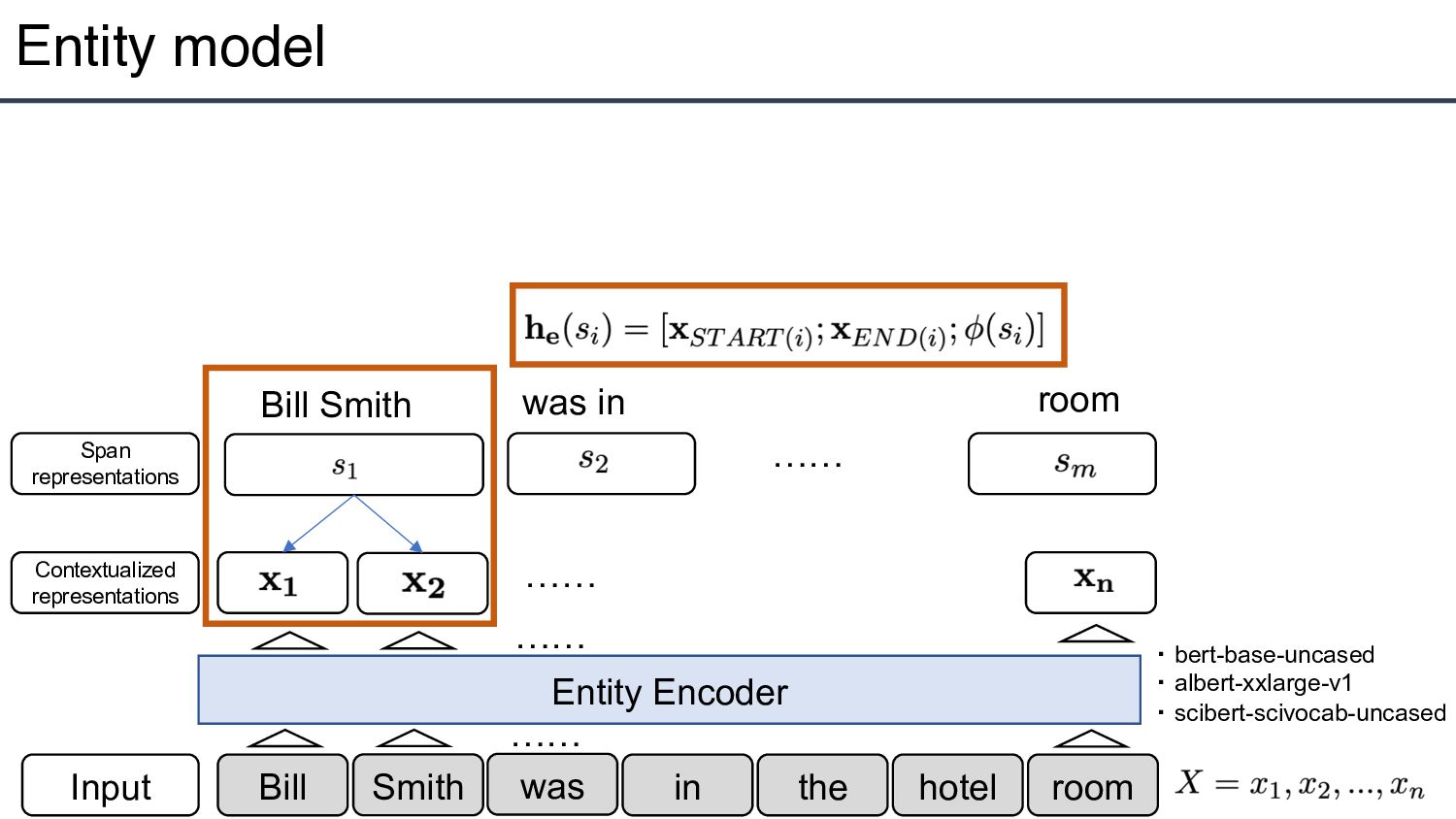
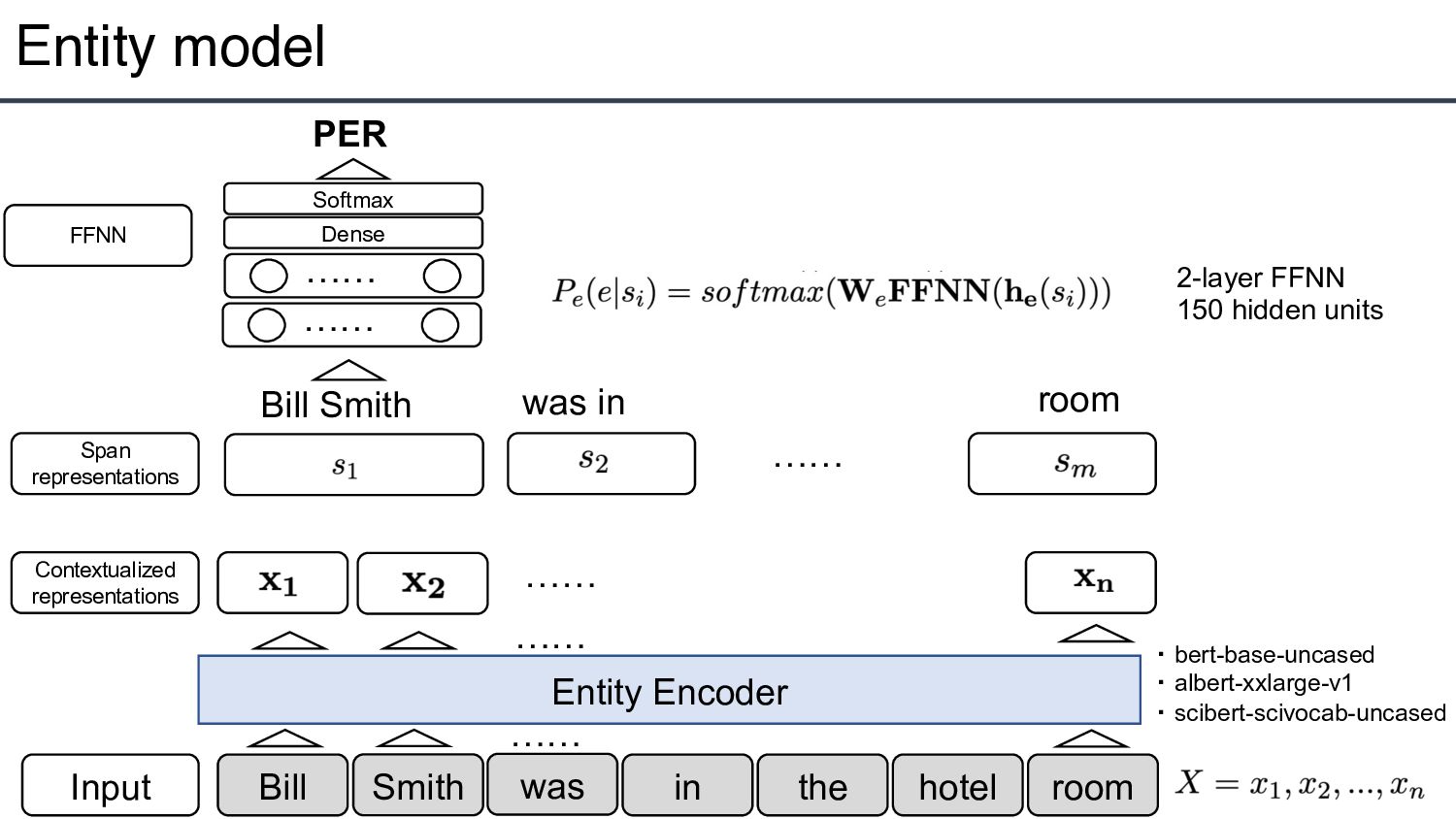
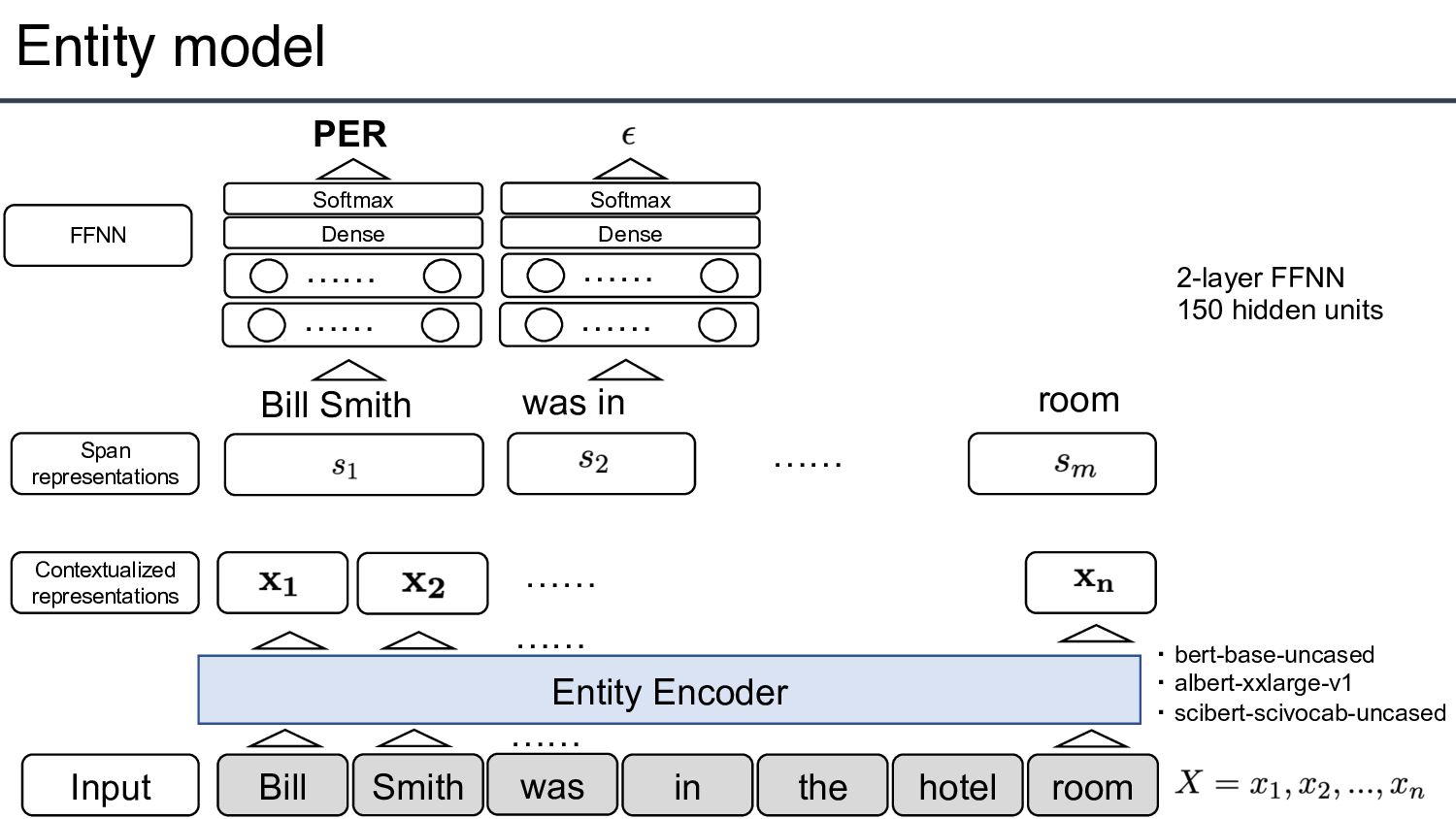
m spans, span is an ordered sequence of token X of up to length L=8, START(i) an END(i) denote start and end indices of 4 Output : span, : entity type : subject/object span, : relation type
Training entity model and relation model separately[05], [06], [07] Recently: end-to-end approach • modeling entity model and relation model jointly[08]~[17] • joint models can better capture the interactions between entities and relations [05] Zhou+: Exploring various knowledge in relation extraction, ACL ‘05 [06] Kambhatla+: Combining lexical, syntactic, and semantic features with maximum entropy models for information extraction, ACL ‘04 [07] Chan+: Exploiting syntactico-semantic structures for relation extraction, ACL-HLT ‘11 [08] Li+: Incremental joint extraction of entity mentions and relations, ACL ‘14 [09] Miwa+: End-to-end relation extraction using LSTMs on sequences and tree structures, ACL ‘16 [10] Katiyar+: Going out on a limb: Joint extraction of entity mentions and relations without dependency trees, ACL ‘17 [11] Zhang(a)+: End-to-end neural relation extraction with global optimization, EMNLP ‘17 [12] Zhang(b)+: Position aware attention and supervised data improve slot filling, EMNLP ‘17 [13] Li+: Entity-relation extraction as multi-turn question answering, ACL ‘19 [14] Luan+: Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction, EMNLP ‘18 [15] Wadden+: Entity, relation, and event extraction with contextualized span representations, EMNLP ‘19 [16] Lin+: A joint neural model for information extraction with global features, ACL ‘20 [17] Wang+: Two are better than one: Joint entity and relation extraction with table sequence encoders, EMNLP '20 5
two task [16] Luan+: A general framework for information extraction using dynamic span graphs, NAACL ‘19 The output vector as inputs to the relation propagation layer The output vector as inputs to the entity and relation prediction layer
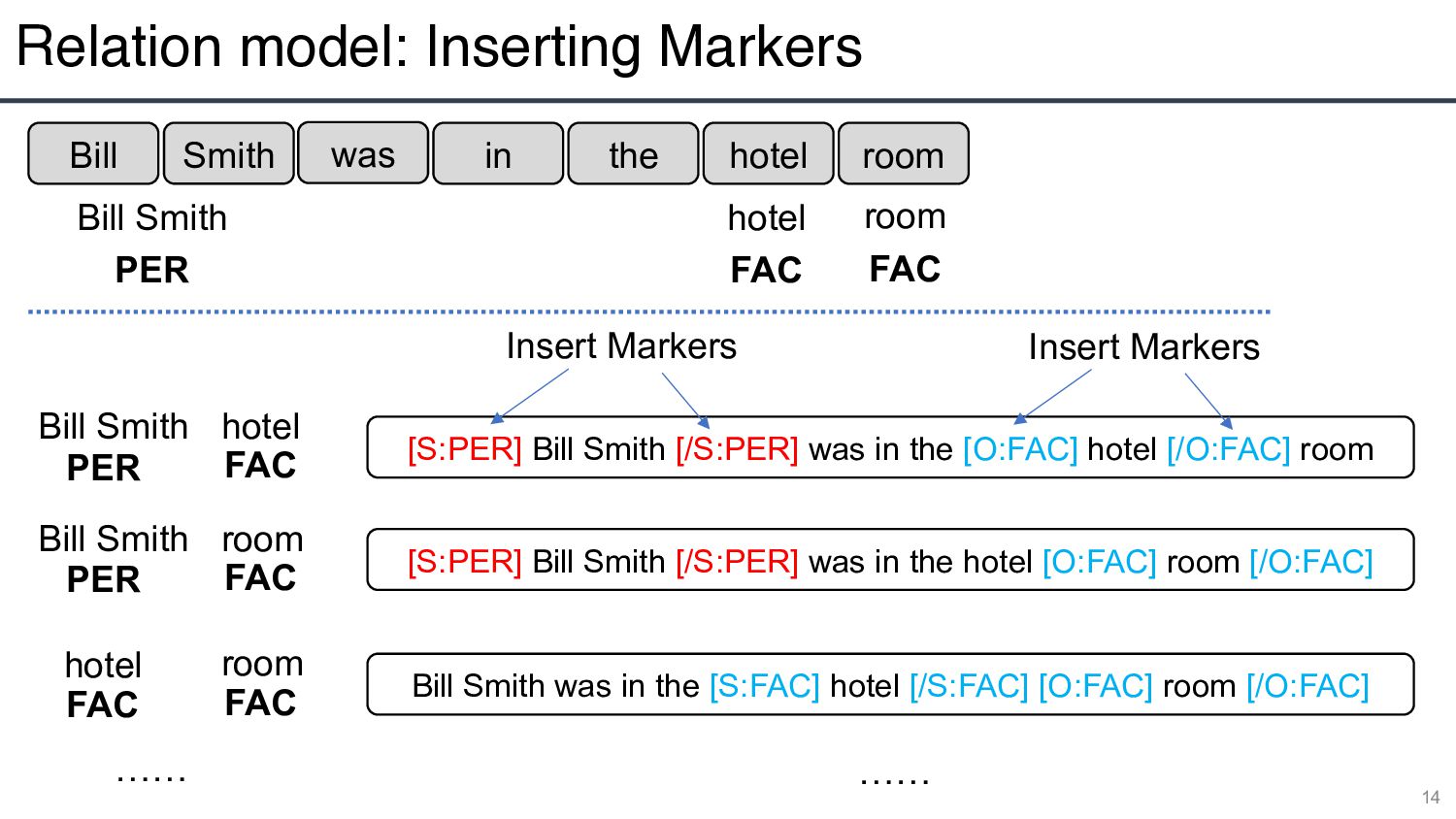
span representation with the entity and relation like the joint model?」 • → Learns two independent encoders • Insert typed entity markers in training relation model • An efficient approximation: 8-16x speed up with a small accuracy drop 7 [S:PER] Bill Smith [/S:PER] was in the [O:FAC] hotel [/O:FAC] room Insert Markers Insert Markers
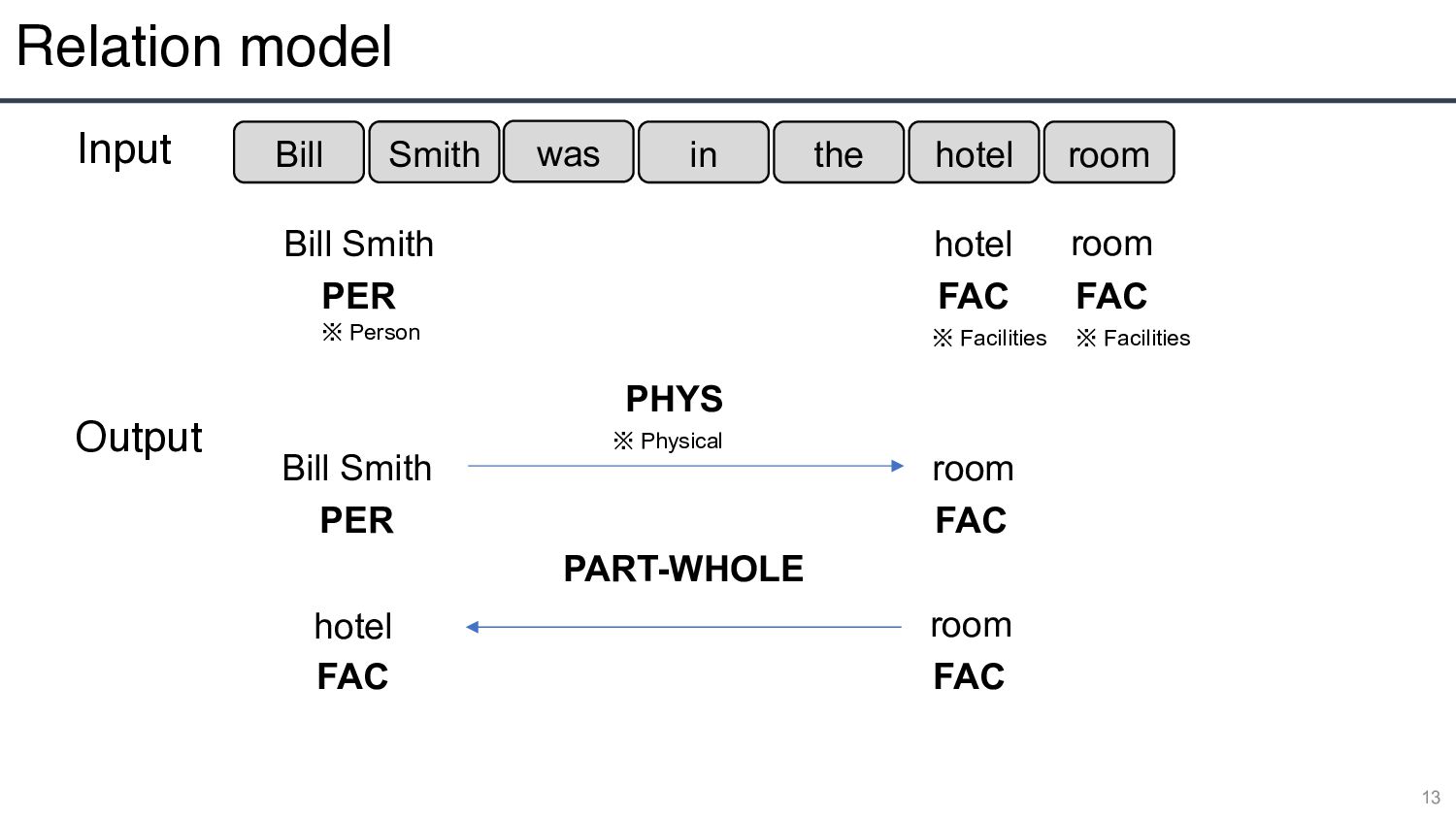
Bill Smith hotel room PER FAC FAC Input Output Bill Smith room PER FAC hotel room FAC FAC PHYS PART-WHOLE ※ Person ※ Facilities ※ Facilities ※ Physical
hotel room Bill Smith hotel room PER FAC FAC Bill Smith PER hotel FAC [S:PER] Bill Smith [/S:PER] was in the [O:FAC] hotel [/O:FAC] room Bill Smith PER room FAC [S:PER] Bill Smith [/S:PER] was in the hotel [O:FAC] room [/O:FAC] hotel FAC room FAC Bill Smith was in the [S:FAC] hotel [/S:FAC] [O:FAC] room [/O:FAC] …… …… Insert Markers Insert Markers
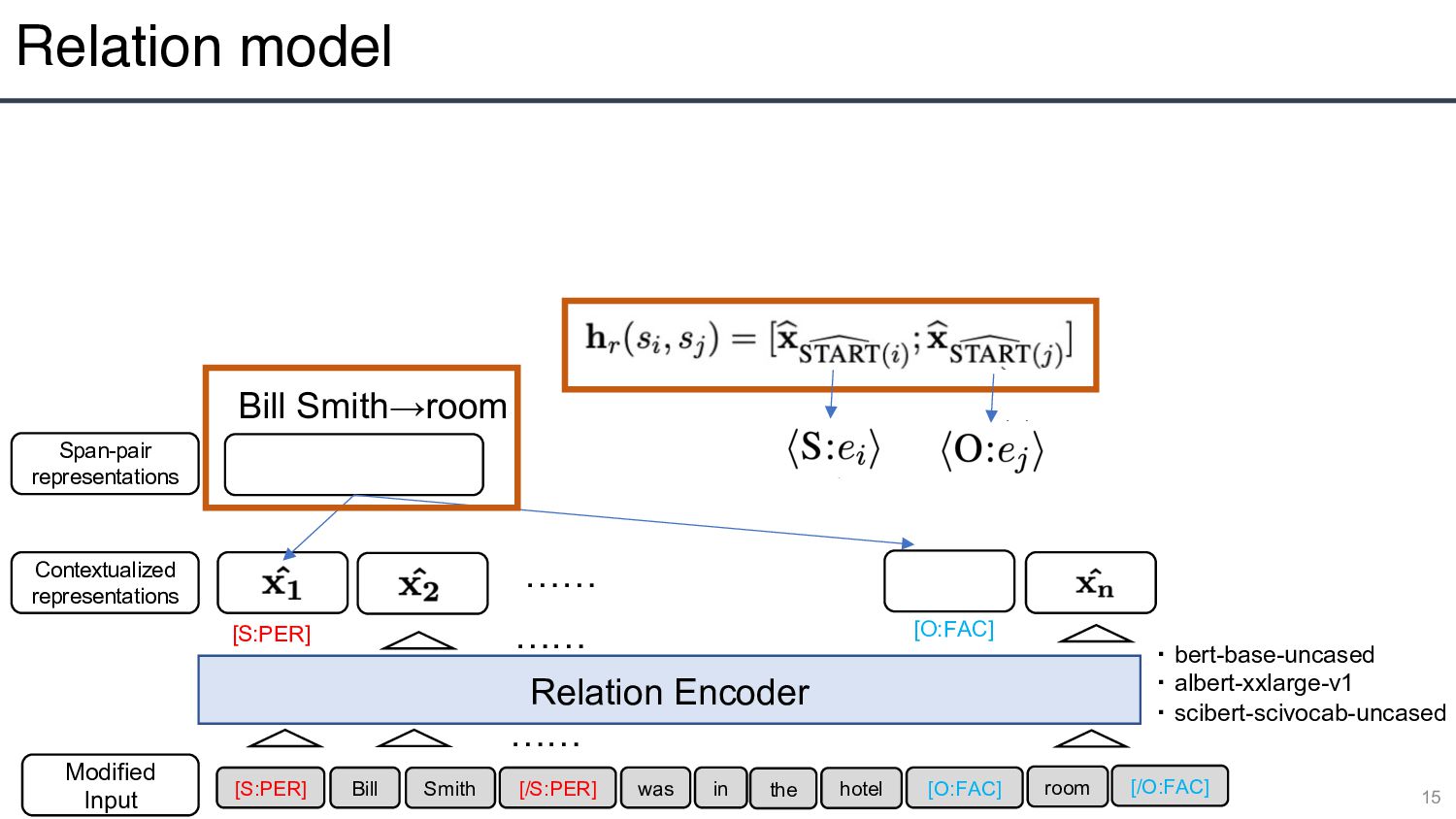
・ albert-xxlarge-v1 ・ scibert-scivocab-uncased Contextualized representations Span-pair representations …… Bill Smith→room …… [S:PER] Bill Smith [/S:PER] was in the hotel [O:FAC] [/O:FAC] room [O:FAC] [S:PER]
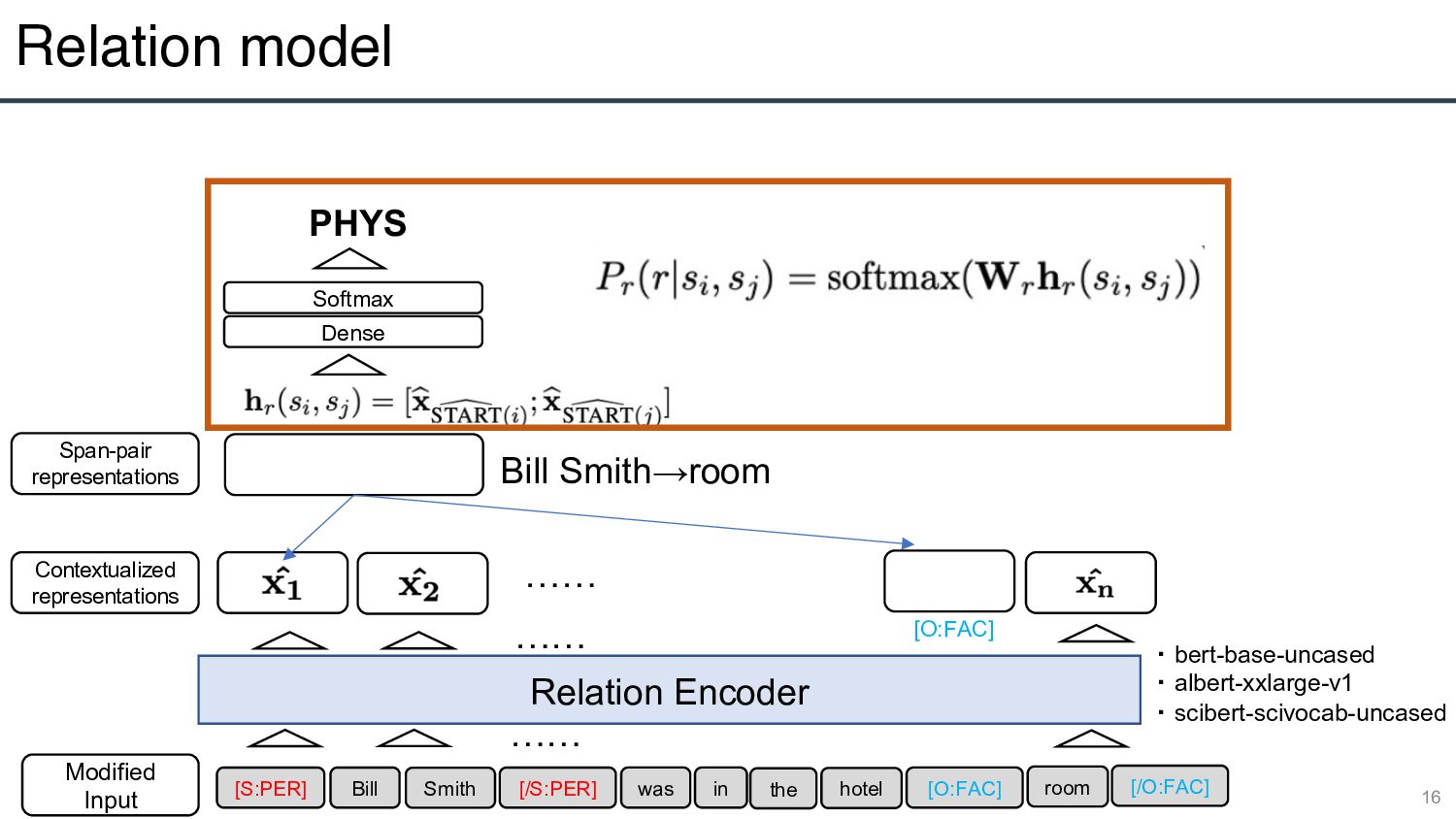
・ albert-xxlarge-v1 ・ scibert-scivocab-uncased Contextualized representations Span-pair representations …… Bill Smith→room …… [S:PER] Bill Smith [/S:PER] was in the hotel [O:FAC] [/O:FAC] room [O:FAC] Dense Softmax PHYS
• Related work • Add a 3-sentence context window[15] • This work • given an input sentence with n words augment the input with from the left context and right context → Entity: W=300, Relation: W=100 17 [15] Wadden+: Entity, relation, and event extraction with contextualized span representations, EMNLP ‘19 [16] Luan+: A general framework for information extraction using dynamic span graphs, NAACL ‘19
Recognition • span boundaries and the predicted entity type are both correct • Relation extraction • (1) boundaries evaluation(Rel) the boundaries of two spans are correct and the predicted relation type is correct • (2) strict evaluation(Rel+) predicted entity types also must be correct in addition Rel 20
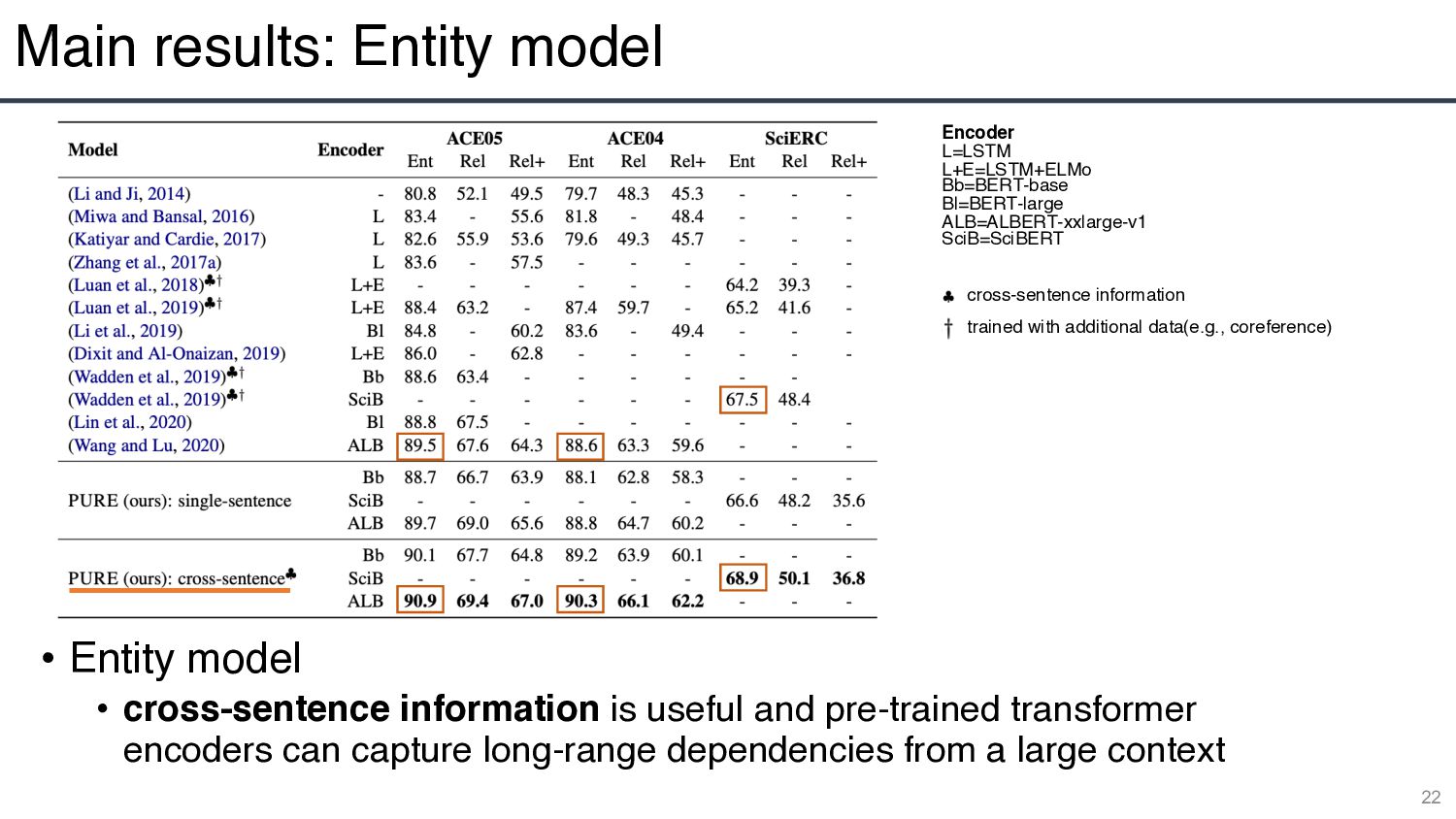
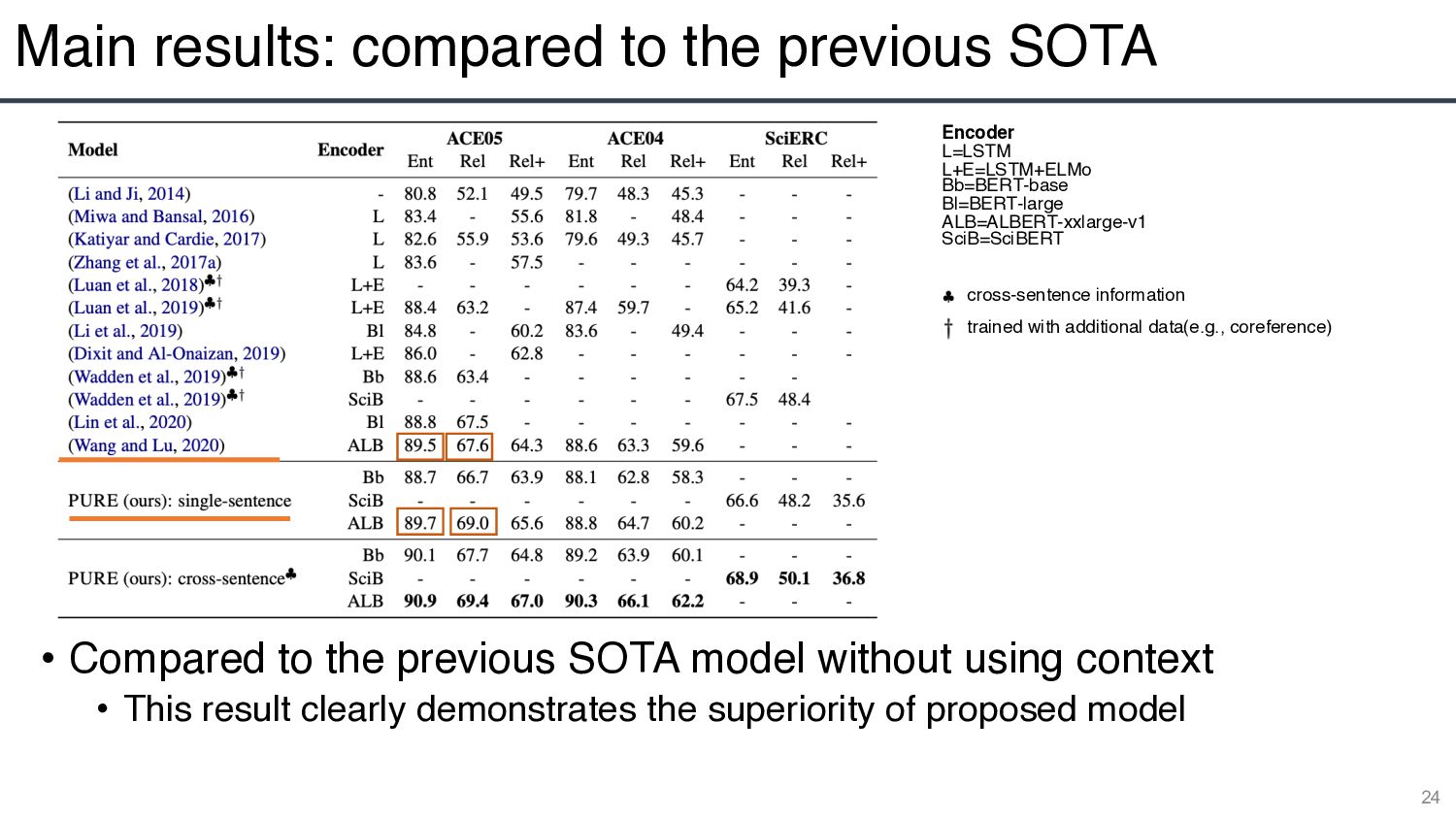
is useful and pre-trained transformer encoders can capture long-range dependencies from a large context 22 Encoder L=LSTM L+E=LSTM+ELMo Bb=BERT-base Bl=BERT-large ALB=ALBERT-xxlarge-v1 SciB=SciBERT cross-sentence information trained with additional data(e.g., coreference)
for entities and relations of different entity pairs, as well as early fusion of entity information in the relation model 23 Encoder L=LSTM L+E=LSTM+ELMo Bb=BERT-base Bl=BERT-large ALB=ALBERT-xxlarge-v1 SciB=SciBERT cross-sentence information trained with additional data(e.g., coreference)
the previous SOTA model without using context • This result clearly demonstrates the superiority of proposed model 24 Encoder L=LSTM L+E=LSTM+ELMo Bb=BERT-base Bl=BERT-large ALB=ALBERT-xxlarge-v1 SciB=SciBERT cross-sentence information trained with additional data(e.g., coreference)
[/S:PER] was in the hotel [O:FAC] room [/O:FAC] Typed markers Proposed method PHYS 72.6% Untyped markers 70.5% [S] Bill Smith [/S] was in the hotel [O] room [/O] PHYS No marker 67.6% Bill Smith was in the hotel room PHYS Relation F1 Markers + entity auxiliary loss[15],[16] 70.7% [S] Bill Smith [/S] was in the hotel [O] room [/O] PHYS PER FAC [15] Wadden+: Entity, relation, and event extraction with contextualized span representations, EMNLP ‘19 [16] Luan+: A general framework for information extraction using dynamic span graphs, NAACL ‘19
+ , • Two tasks have different input formats and require different features for predicting entity types and relations → separate encoders indeed learns better task-specific features
was in the [O:FAC] hotel [/O:FAC] room [S:PER] Bill Smith [/S:PER] was in the hotel [O:FAC] room [/O:FAC] Bill Smith was in the hotel room Bill Smith hotel room PER FAC FAC Bill Smith was in the [S:FAC] hotel [/S:FAC] [O:FAC] room [/O:FAC] …… One shortcoming of this approach is that need to run for every pair of entities
was in the [O:FAC] hotel [/O:FAC] room [S:PER] Bill Smith [/S:PER] was in the hotel [O:FAC] room [/O:FAC] [S:PER] Bill Smith [/S:PER] was in the hotel [O:FAC] [/O:FAC] room [S:PER] Bill Smith [/S:PER] was in the hotel [O:FAC] [/O:FAC] room [S:PER] Bill Smith [/S:PER] was in the hotel [O:FAC] [/O:FAC] room [S:PER] [/S:PER] [O:FAC] [/O:FAC] the same sentence in one run of the relation model → 8-16x speedup with only 1% accuracy drop
entity recognition and relation extraction • Learns two independent encoders • Insert typed entity markers in training relation model • An efficient approximation: 8-16x speed up with a small accuracy drop 31 [S:PER] Bill Smith [/S:PER] was in the [O:FAC] hotel [/O:FAC] room Insert Markers Insert Markers
{kind=link}
{kind=link}
![Introduction: Entity and Relation Extraction [01] Sang+: Introduction to the](https://files.speakerdeck.com/presentations/6265bf7d74a7426d80b0b8862c5407c1/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
![Introduction: Joint models 6 multi-task learning[16] shared span representations between](https://files.speakerdeck.com/presentations/6265bf7d74a7426d80b0b8862c5407c1/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Cross-sentence context • Cross-sentence help predict entity types and relations[15],[16]](https://files.speakerdeck.com/presentations/6265bf7d74a7426d80b0b8862c5407c1/slide_16.jpg){kind=link}
{kind=link}
![Experiments: Dataset • ACE04[18], ACE05[19] • a variety of domains](https://files.speakerdeck.com/presentations/6265bf7d74a7426d80b0b8862c5407c1/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Analysis: Importance of Typed Text Markers 26 [S:PER] Bill Smith](https://files.speakerdeck.com/presentations/6265bf7d74a7426d80b0b8862c5407c1/slide_25.jpg){kind=link}
{kind=link}
![Approximation model with batch computations 28 [S:PER] Bill Smith [/S:PER]](https://files.speakerdeck.com/presentations/6265bf7d74a7426d80b0b8862c5407c1/slide_27.jpg){kind=link}
![Approximation model with batch computations 29 [S:PER] Bill Smith [/S:PER]](https://files.speakerdeck.com/presentations/6265bf7d74a7426d80b0b8862c5407c1/slide_28.jpg){kind=link}
{kind=link}
{kind=link}