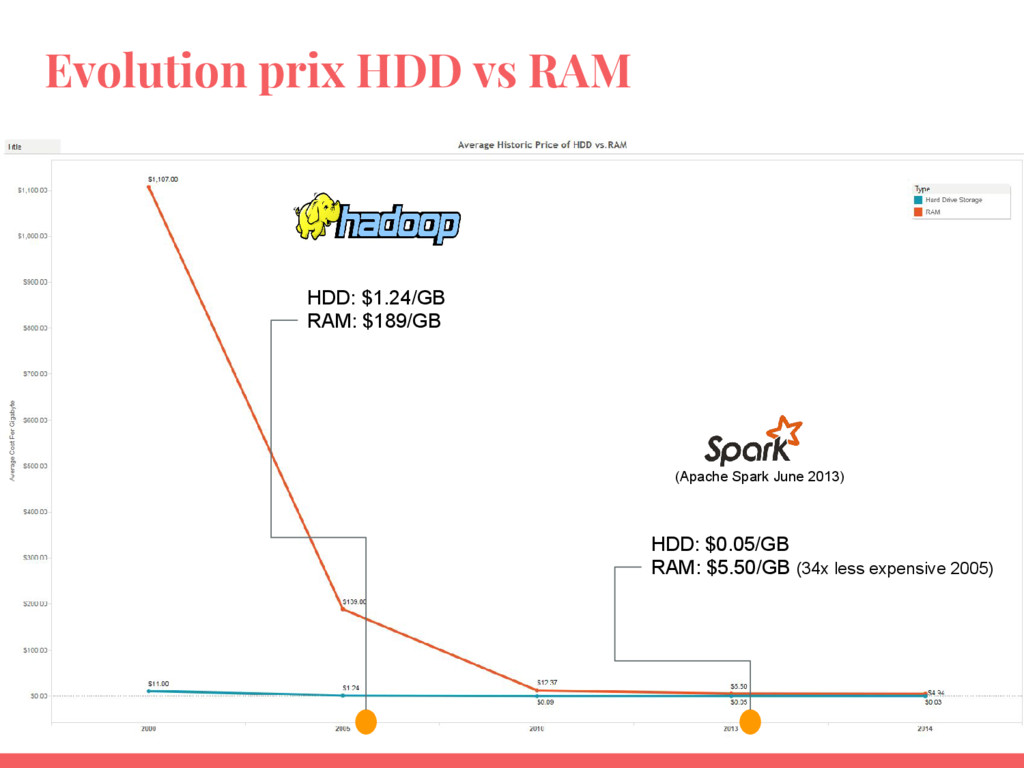
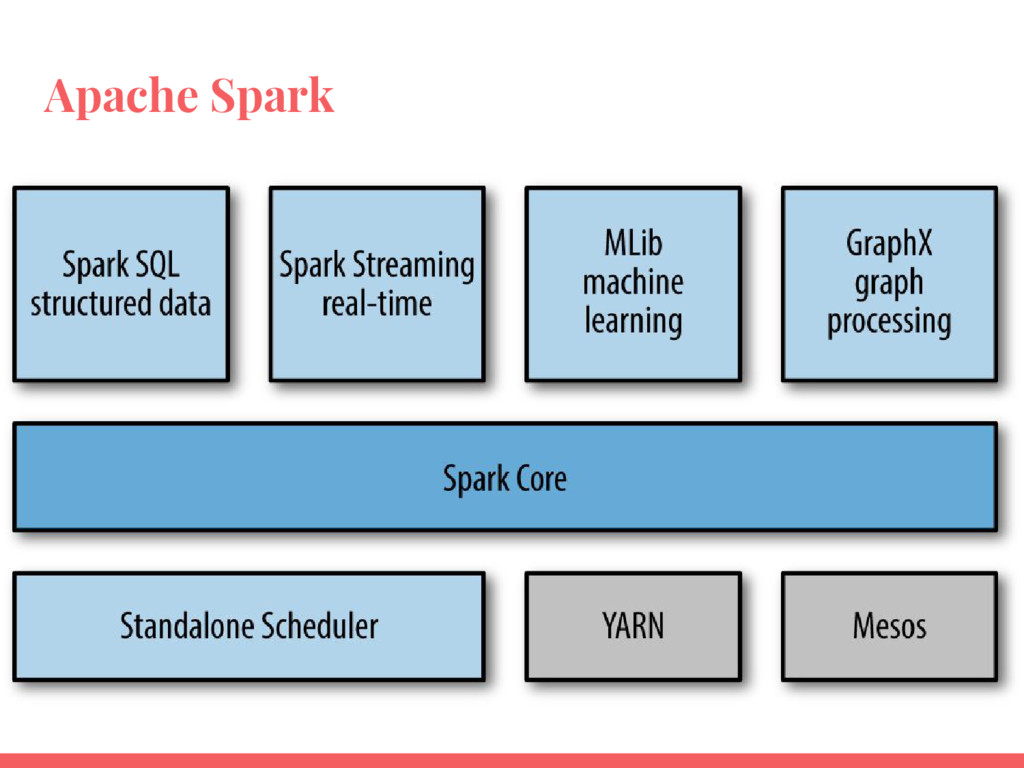
Apache Spark est un framework open source généraliste, conçu pour le traitement distribué de données. C’est une extension du modèle MapReduce avec l’avantage de pouvoir traiter les données en mémoire et de manière interactive. Spark offre un ensemble de composants pour l’analyse de données: Spark SQL, Spark Streaming, MLlib (machine learning) et GraphX (graphes).
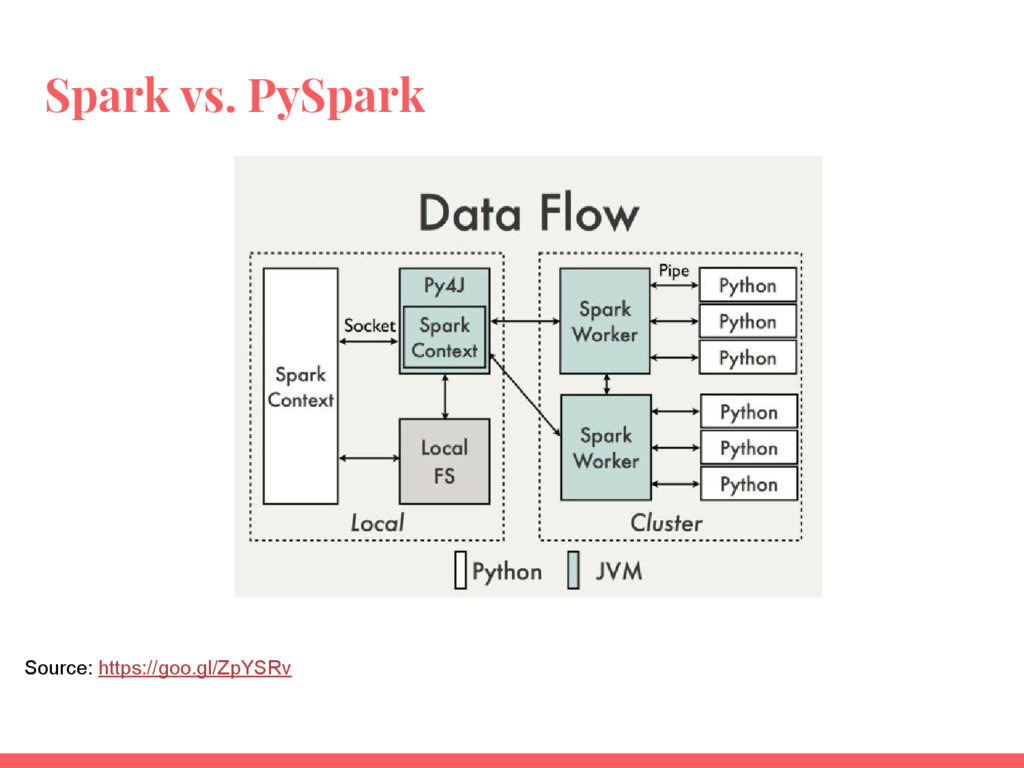
Cet atelier se concentrer sur les fondamentaux de Spark et le paradigme de traitement de données avec l’interface de programmation Python (plus précisément PySpark).
L’installation, configuration, traitement sur cluster, Spark Streaming, MLlib et GraphX ne seront pas abordés dans cet atelier.
A la fin de cet atelier, vous serez capable de :
- Comprendre les fondamentaux de Spark et le situer dans l'écosystème Big Data ;
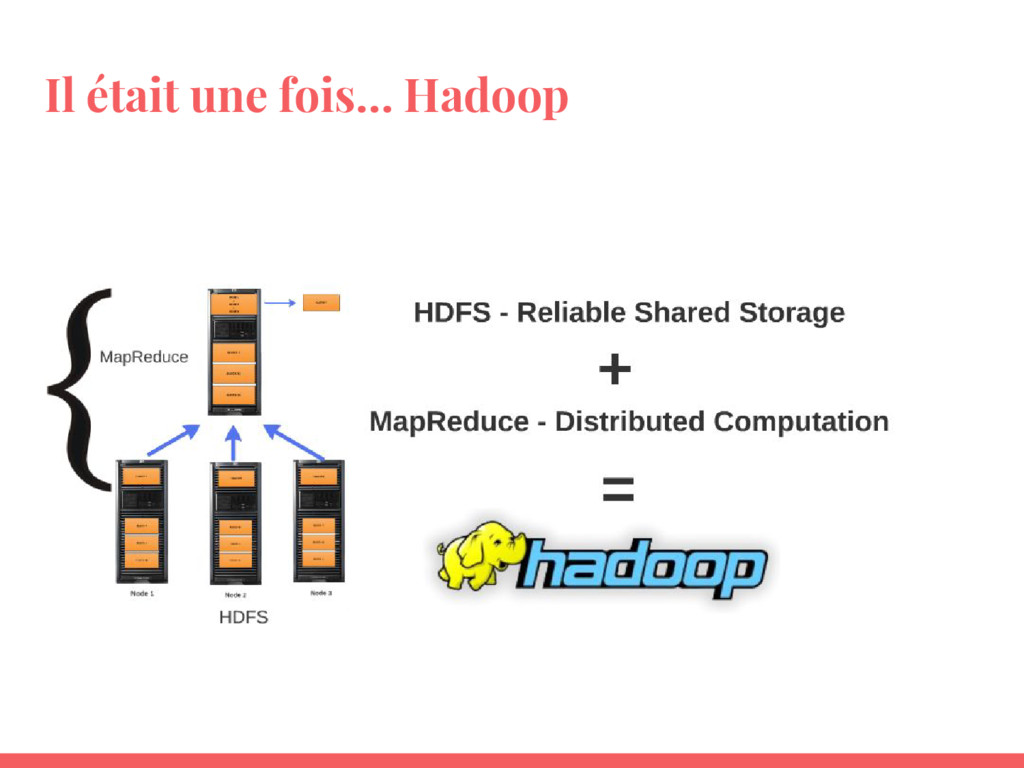
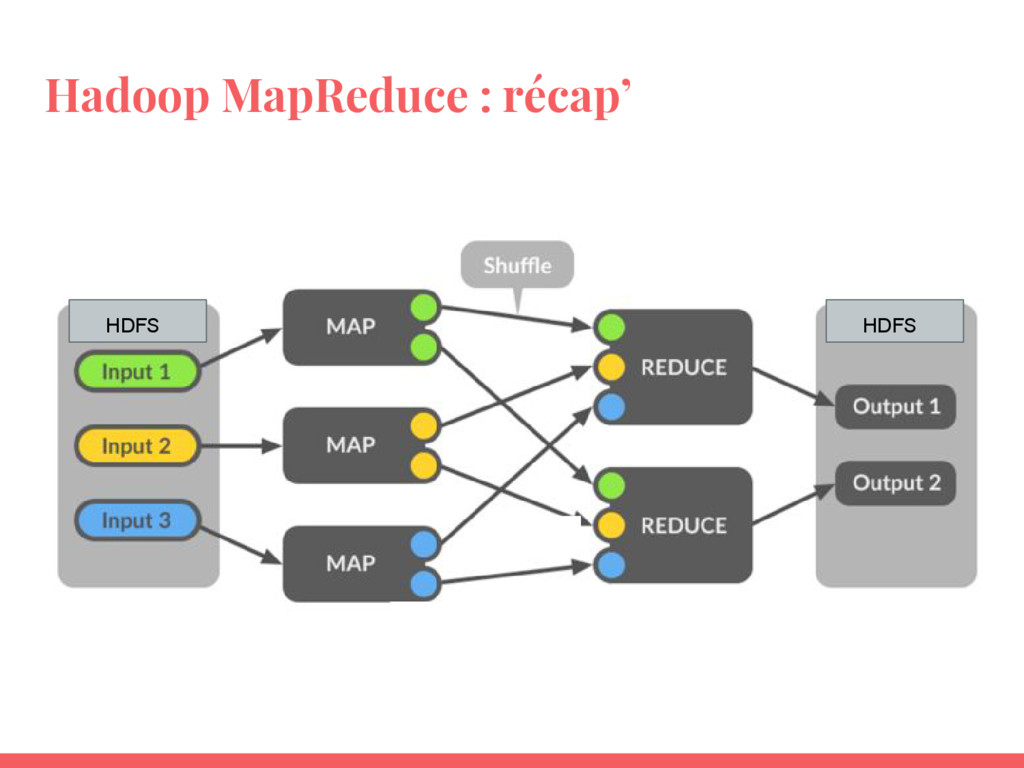
- Savoir la différence avec Hadoop MapReduce ;
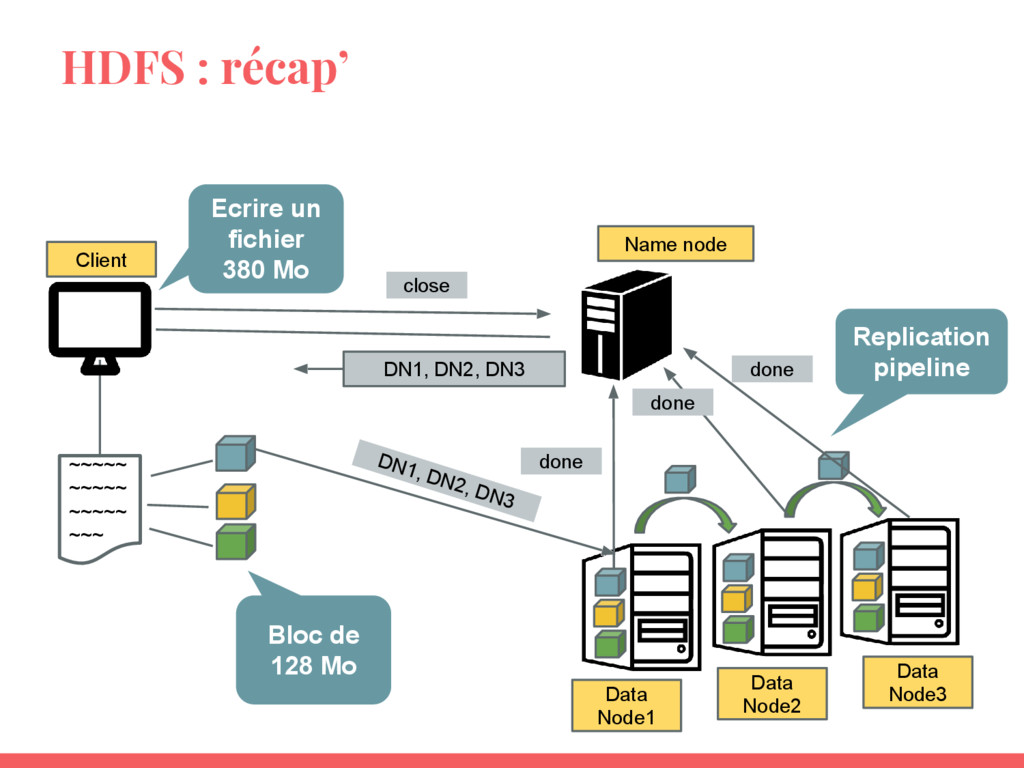
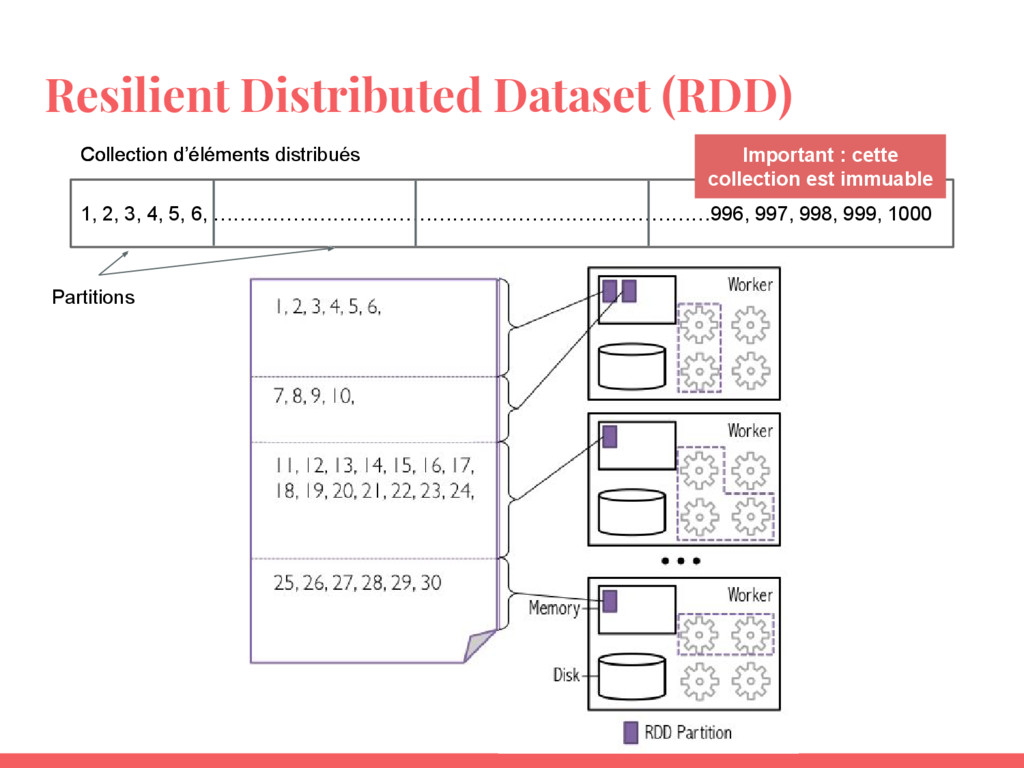
- Utiliser les RDD (Resilient Distributed Datasets) ;
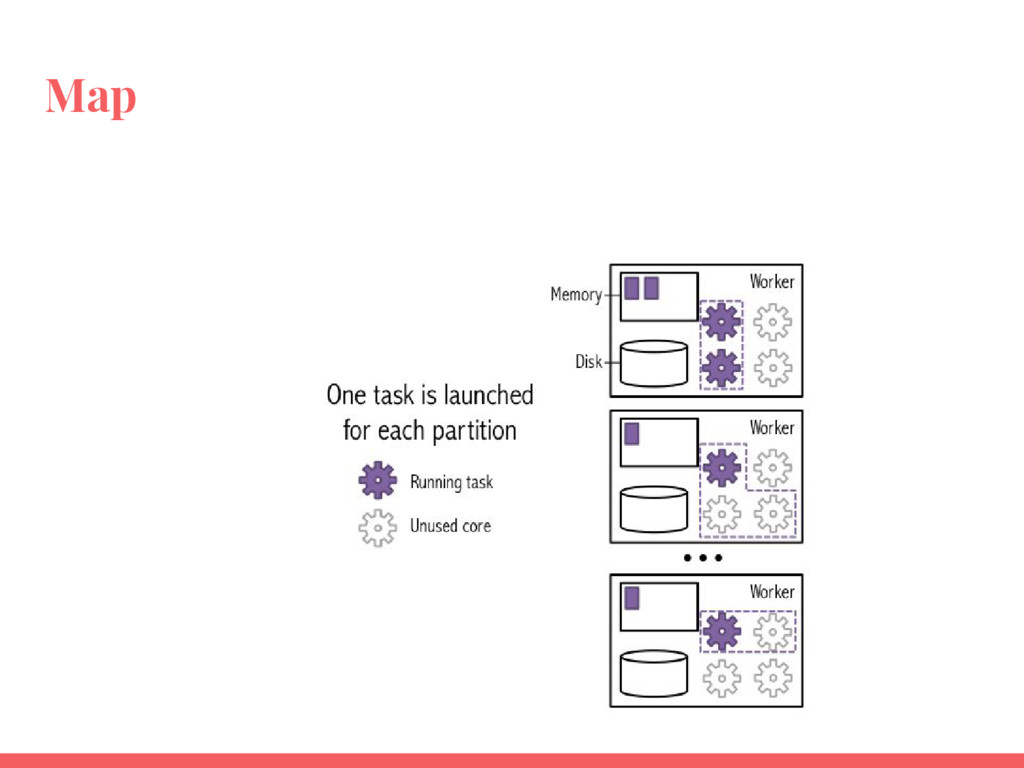
- Utiliser les actions et transformations les plus courantes pour manipuler et analyser des données ;
- Ecrire un pipeline de transformation de données ;
- Utiliser l’API de programmation PySpark.
Les TPs sont disponibles sous https://goo.gl/VLgQSk
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
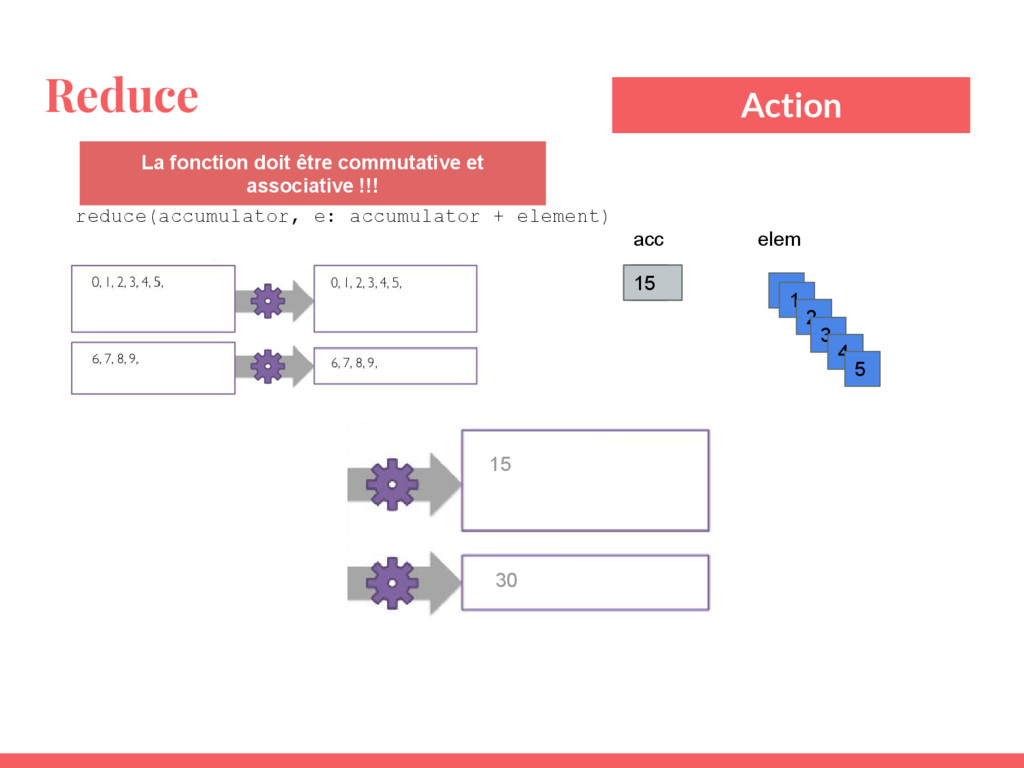{kind=link}
{kind=link}
{kind=link}
{kind=link}
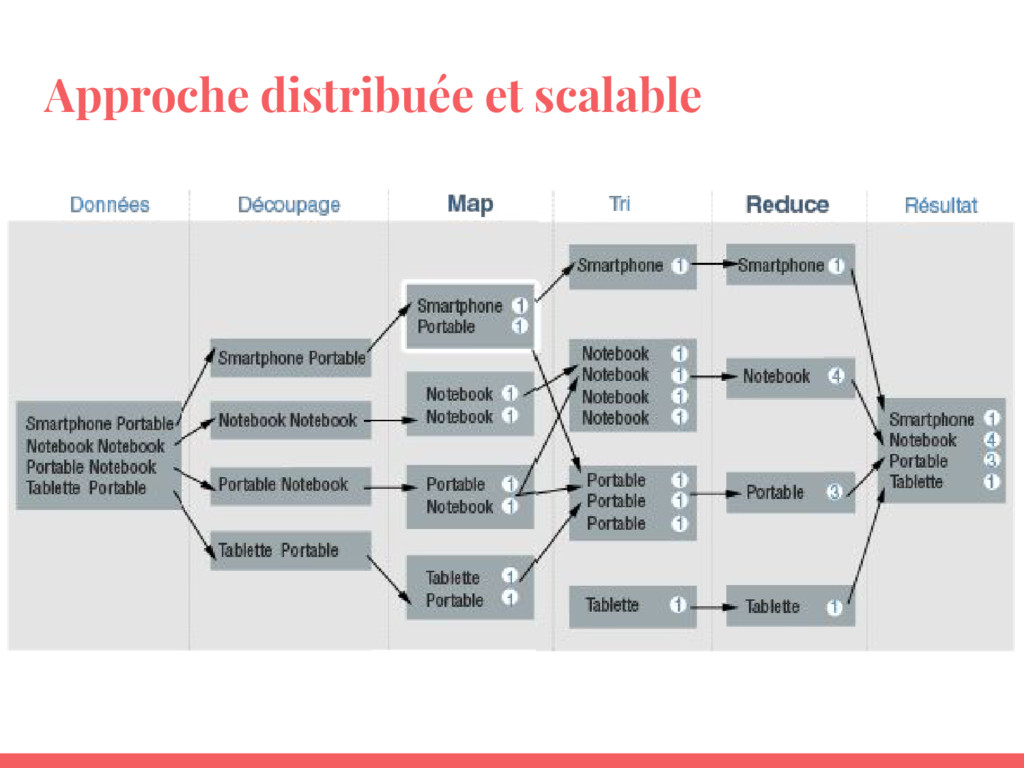{kind=link}
{kind=link}
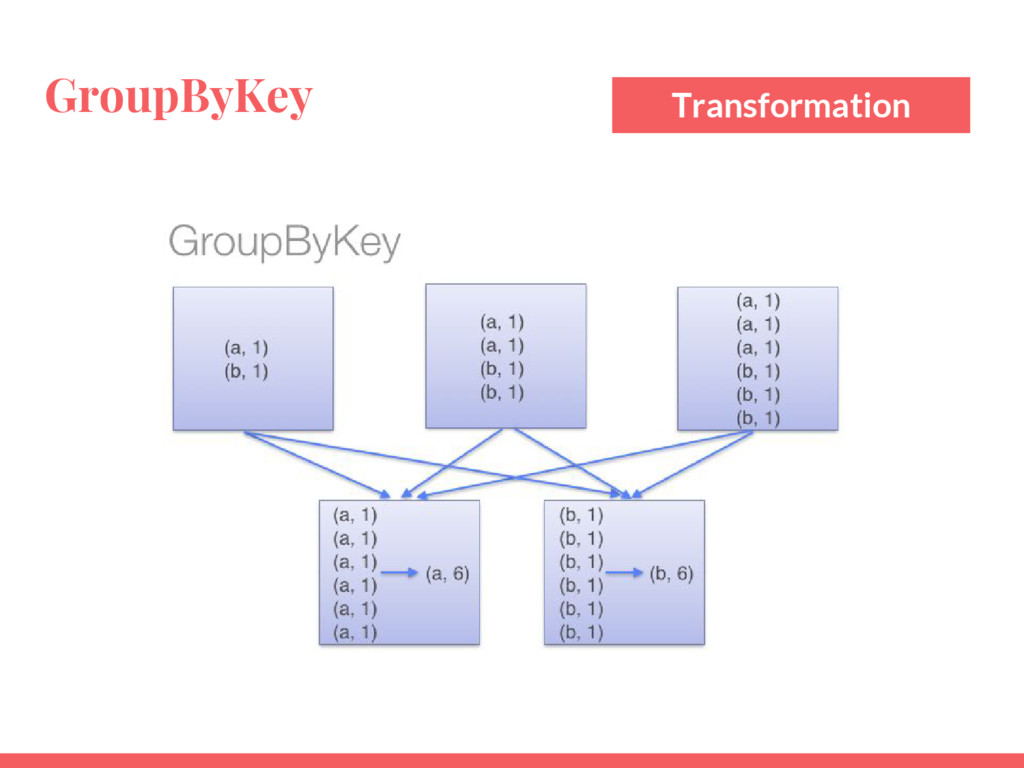{kind=link}
{kind=link}
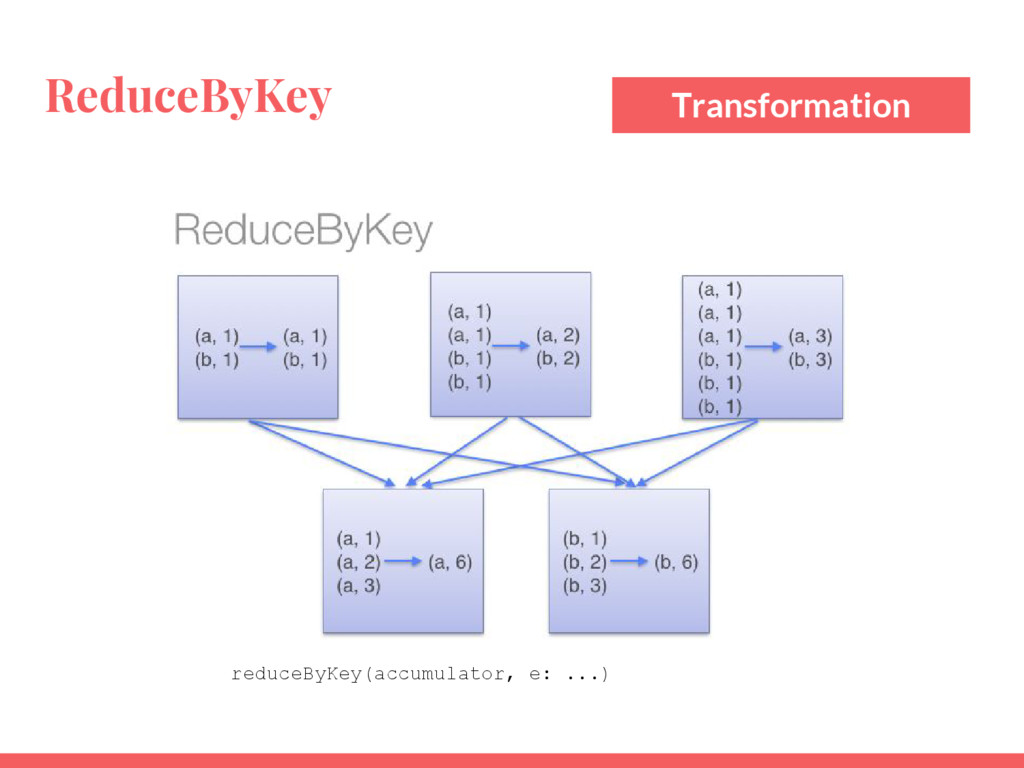{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}